并行推理别再各想各的:CPT 让多条思维链学会“共享情报”
你有没有遇到过这种很拧巴的推理场景:为了让模型做一道难题更稳,我们一口气采样 64 条思维链。GPU 烧起来了,token 也刷起来了,但很多分支其实在做同一件事——反复发现同一个约束、踩同一个坑、绕同一段弯路。
这很像开会解题。十个人被关在十个房间里,各自推演,结束后投票。这个流程当然能提升命中率,但如果第三个人已经发现“这里不能直接除以 \(x-y\)”,第七个人还得自己再摔一次。并行是并行了,情报没流动起来。
这篇 arXiv:2605.27030 的论文《Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling》盯住的就是这个问题。作者提出 Collaborative Parallel Thinking,简称 CPT:不训练模型,不加外部 verifier,而是在推理过程中从每条分支里抽取“可复用的中间情报”,去重后放进共享信息池,再广播给后续分支继续推理。说实话,我觉得它最有意思的地方不是“又做了一个推理框架”,而是把并行 test-time scaling 里一个长期被默认接受的低效设计挑了出来:分支之间不说话。
论文信息
- 论文标题:Share More, Search Less: Collaborative Parallel Thinking for Efficient Test-Time Scaling
- 论文链接:https://arxiv.org/abs/2605.27030
- arXiv ID:2605.27030
- 作者:Xinglin Wang, Hao Lin, Shaoxiong Feng, Peiwen Yuan, Yiwei Li, Jiayi Shi, Yueqi Zhang, Chuyi Tan, Ji Zhang, Boyuan Pan, Yao Hu, Kan Li
- 机构:Beijing Institute of Technology;Xiaohongshu Inc
- 提交日期:2026 年 5 月 26 日
- 代码与数据:https://github.com/WangXinglin/CPT
核心摘要
这篇论文解决的是并行 test-time scaling 里的“信息孤岛”问题:多条推理分支同时搜索同一道题,但中间发现只留在各自分支内部,其他分支无法及时复用,于是大量算力花在重复探索上。CPT 的做法很直接:每隔固定 token 步长同步一次,从各分支新生成片段中抽取简短信息单元,经过语义去重后写入共享信息池,再在合适时机广播给所有分支。实验在 HMMT24、HMMT25、AIME25、AIME26 上验证,CPT 在 Qwen3-4B-Thinking-2507 和 Qwen3-30B-A3B-Thinking-2507 两个模型尺度下,都给出了更强的 accuracy-latency Pareto frontier。我的判断是:这不是模型能力层面的底层突破,更像一个很聪明、工程味很浓的推理时协作协议。它的价值在于,把“多采样”从简单堆宽度,推进到了“边搜索边共享”。
问题不在并行,而在并行分支互相失联
Test-Time Scaling 这几年越来越常见。训练完模型后,在推理阶段给它更多计算预算:更长的思考、更宽的采样、更多候选答案、更复杂的搜索。数学推理里大家最熟的路线,是 Self-Consistency 式的并行采样:让模型生成多条 chain-of-thought,然后投票或筛选。
这个路线的直觉很漂亮。单条推理链可能走偏,多条链至少有机会覆盖不同路径。DeepConf 这类方法进一步用 confidence signal 去挑更可信的 reasoning traces;LeaP 则让推理路径之间出现一点 peer interaction,用别的路径来帮助自我修正。
但 CPT 这篇论文问了一个更基础的问题:
为什么我们要等所有分支都跑完,才让它们的信息发生关系?
在复杂数学题里,一条分支中途发现的东西,往往不是最终答案,而是某个约束、某个中间关系、某个失败方向。这些信息对其他分支很有用。问题是,传统并行采样把它们锁在各自轨迹里。直到最终投票,其他分支都不知道它们存在。
论文把这个现象叫 information isolation。我的理解更口语一点:大家都在同一个迷宫里找出口,但每个人都不能把“这条路是死胡同”写到公共白板上。
作者做了两个预实验来证明这不是想象出来的痛点。
一个是统计并行搜索过程中“新信息”和“重复信息”的变化。实验用 Qwen3-30B-A3B-Thinking-2507,在 HMMT24--25 上跑 64 条并行分支,每 1024 token 作为一个 search step,抽取信息单元并去重。结果很直观:独立并行采样越往后,重复信息越来越多,新信息越来越少。
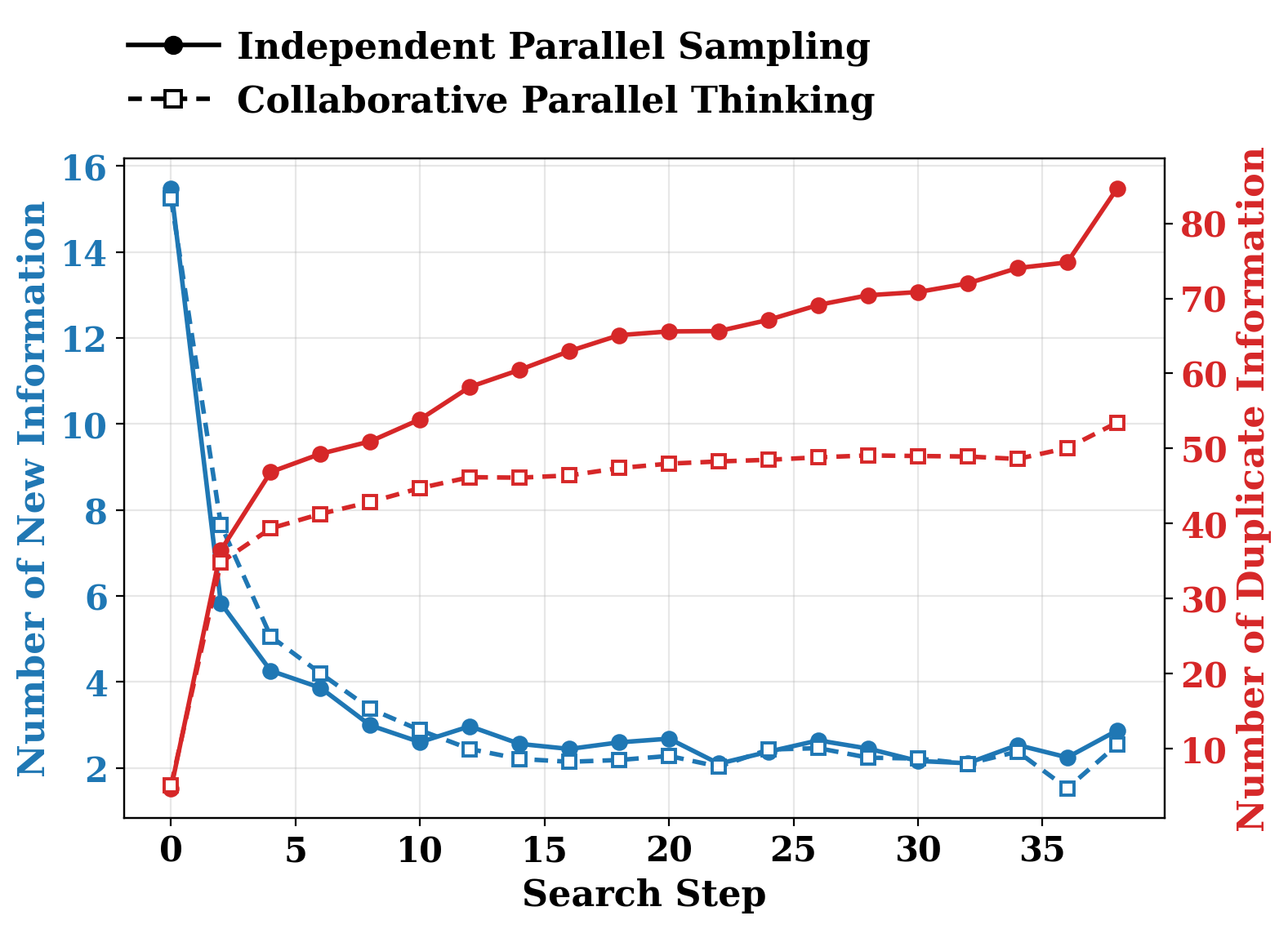
图里蓝线是每步发现的新信息数量,红线是重复信息数量。实线代表独立并行采样,虚线方块代表 CPT。独立采样在后期的红线一路上升,说明分支开始大量“重新发现别人已经知道的东西”。CPT 不能让重复完全消失,但明显把重复发现压低了,同时新信息数量没有崩掉。
另一个预实验更有说服力:作者把不同分支里抽出来的信息离线去重,然后按比例注入到初始上下文里,看推理是否变好。结果如下。
| 注入信息比例 | 0% | 20% | 40% | 60% | 80% | 100% |
|---|---|---|---|---|---|---|
| Pass@1 | 48.95 | 53.34 | 54.82 | 55.89 | 56.20 | 55.86 |
| Tokens | 26714 | 16805 | 14128 | 12792 | 11924 | 11412 |
| Latency | 395s | 269s | 235s | 223s | 219s | 220s |
看到这个表我第一反应是:这事确实值得做。把去重后的分支信息提前给模型,Pass@1 从 48.95 提到 56.20,token 从 26714 降到 11924,延迟从 395 秒降到 219 秒。这个提升不是靠答案泄漏,论文说这些信息都来自模型生成轨迹,没有 gold answer、外部 verifier 或人工标注。
这就把问题钉住了:分支内部确实产生了有用信息,只是传统并行采样没给它们一个及时共享的通道。
CPT 的核心想法:给并行分支一块黑板
CPT 的方法图很好懂。左边是传统 independent parallel sampling:每条分支独自搜索,缺什么信息自己找。右边是 CPT:分支阶段性把中间发现写到共享池,后面的搜索可以读到这块共享池。
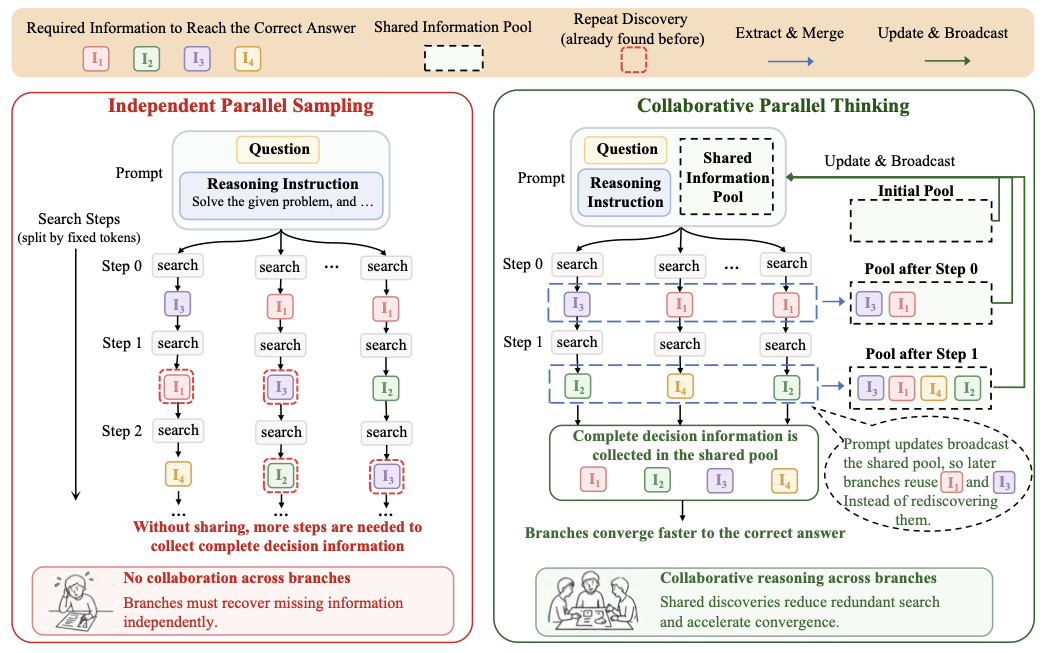
图中 \(I_1, I_2, I_3, I_4\) 可以理解为解出正确答案所需的关键中间信息。独立采样里,某个分支已经找到 \(I_1\),其他分支不知道,还会在后续步骤重新发现它。CPT 则把这些中间信息抽取、合并、去重,再广播回 prompt。等共享池里收集齐足够决策信息,分支更容易收敛到正确答案。
整个流程拆开看有三块。
协作式并行搜索:只在固定步长同步
给定问题 \(x\) 和模型 \(\pi\),CPT 启动 \(K\) 条并行 reasoning branches。第 \(t\) 个 search step 时,每条分支 \(i\) 有自己的私有推理历史 \(h_i^t\),系统还有一个问题级共享信息池 \(\mathcal{P}_t\)。
每个 search step 是固定长度的生成 chunk,论文默认主实验里是 2048 token。分支正常往下生成,不会被中途强行改写。等一个 chunk 生成结束,系统才临时同步,把新生成片段送去抽取信息。
这个设计挺关键。CPT 不是把所有分支揉成一条,也不是不断打断模型思考。它保留每条分支的私有历史,只是在 step 边界给它们读写共享池的机会。
共享信息池:抽取、去重、广播
直接共享完整 reasoning trace 太长,也太脏。CPT 让同一个 policy model 做信息抽取,把一段新生成内容压缩成几个信息单元,比如中间结论、约束、观察、反例、检查点。
核心抽取可以写成:
这里 \(\Delta h_i^t\) 是第 \(i\) 条分支在当前 step 新生成的片段,\(\mathcal{Z}_i^t\) 是抽出来的信息集合。
然后系统把候选信息写入共享池 \(\mathcal{P}_t\)。为了避免同一句话换个说法占满上下文,CPT 用 embedding 做语义去重。具体是用 all-MiniLM-L6-v2 编码信息单元,如果候选信息和池里已有条目的最大余弦相似度超过阈值,就认为重复。主实验默认去重阈值 \(\tau_{\mathrm{dup}}=0.75\)。
广播时,CPT 最多采样 \(M\) 条池内信息放进 input context 的 shared-information section。默认 \(M=512\)。
这里有个工程细节我挺喜欢:论文的 worker prompt 明确要求模型不要盲信黑板内容。黑板信息只是 optional intermediate guidance,遇到冲突要重新检查,而不是直接跟随。这一点很重要,因为分支抽取的信息可能有错。如果把共享池当真理来源,协作很容易变成集体幻觉。
自适应广播:别太早,也别太晚
共享不是越早越好。
如果一开始就广播,所有分支可能被早期不成熟的信息带偏,探索多样性下降。如果一直广播,又会引入同步和 prefilling 开销。CPT 用“新信息进入共享池的速率”控制什么时候开始、什么时候停止。
设第 \(t\) 步新加入池的信息数是 \(n_t\)。按窗口 \(W\) 求平均:
\(g_1\) 是第一个窗口的平均新信息数,\(r_j\) 衡量当前边际新信息收益相对开局下降了多少。主实验用 \(W=3\),开始阈值 \(\tau_{\mathrm{start}}=0.4\),停止阈值 \(\tau_{\mathrm{stop}}=0.1\)。
流程大概是三段:
| 阶段 | 分支行为 | 共享池行为 | 目的 |
|---|---|---|---|
| Probe | 独立探索 | 只写入,不广播 | 保留探索多样性 |
| Broadcast | 带共享池继续推理 | 写入并广播 | 复用跨分支发现,减少重复搜索 |
| FreeRun | 不再同步,跑到结束 | 停止更新广播 | 避免后期同步收益太低还继续付开销 |
这个调度其实很符合直觉:开局让大家先各自找线索,中段开始汇总情报,后期别再频繁开会。
理论部分:为什么“更多分支”不等于“更多有效信息”
论文的理论分析不是最核心的卖点,但它给了一个很好的解释框架。
作者把并行分支产生的信息分成两类:
- aggregate path-wise information:每条路径单独看产生了多少决策相关信息;
- pooled global decision information:把多条路径的信息合并去重后,真正对全局决策有多少帮助。
两者的差,就是 redundant local information。
你想想看,64 条分支都发现“这里有个对称性”,path-wise information 看起来很大,但全局决策信息只增加了一次。剩下 63 次就是重复。
论文还给了一个高斯冗余模型,说明并行宽度 \(K\) 会被相关性压缩成有效宽度:
这里 \(\rho\) 是路径之间残余信息的相关性。若 \(\rho=0\),有效宽度就是 \(K\)。若 \(\rho\) 接近 1,再多分支也像一个信息源。
这条公式讲得很扎心:并行 rollout 数量不是免费的胜利。如果分支之间高度相关,名义上跑了 64 条,信息上可能没宽多少。
CPT 的目标不是让原始生成更花哨,而是让已经共享过的结论从“待探索残差”里移走,让后续分支少做重复工。
实验设置:它对比的是并行推理效率,不是所有搜索算法
论文主要在数学推理 benchmark 上测:HMMT24、HMMT25、AIME25、AIME26。模型是 Qwen3-4B-Thinking-2507 和 Qwen3-30B-A3B-Thinking-2507。
对比方法包括:
| 方法 | 核心思路 | 和 CPT 的区别 |
|---|---|---|
| Base Parallel Sampling | 直接并行采样多条 reasoning branches | 分支之间没有搜索时共享 |
| DeepConf | 用 confidence signals 识别并保留高质量 reasoning traces | 更偏后验筛选,不负责在线共享中间发现 |
| LeaP | peer-path routing,让路径之间发生自我修正式交互 | 有跨路径交互,但不是共享去重信息池协议 |
| CPT | 抽取分支中间信息,去重成共享池,并自适应广播 | 在线协作,目标是减少重复探索 |
作者没有和 Tree-of-Thoughts、MCTS、Self-Refine 这类顺序或结构化搜索方法硬比。这个选择是合理的。论文关注的是 latency-efficient parallel TTS,而很多树搜索和迭代修正方法会引入明显串行开销,比较口径不一样。
实验协议也比较清楚:并行 rollout budget \(K\in\{8,16,32,64,128\}\),报告 wall-clock latency;准确率有两个指标,Pass@1 看单条样本平均正确率,MV@K 看 \(K\) 条分支多数投票后的正确率。每个实验做 8 次独立运行取平均。CPT 的延迟包含生成、信息抽取、语义去重、上下文广播和最终聚合。
实现上,所有实验跑在 512 张 NVIDIA H800 GPU 的集群,每个 run 分到 8 张 GPU。采样超参跟 Qwen3-Thinking 官方推荐一致:temperature 0.6,top-p 0.95,top-k 20,最大生成长度 38k token。
坦率讲,这个实验资源门槛不低。所以它更像一个研究系统的验证,而不是你明天在单机服务里随便打开的开关。
主结果:CPT 的优势主要体现在 latency 和 token frontier
主实验图看起来信息量很大:四个 benchmark,两种模型,Pass@1 和 MV@K 两类指标,横轴是 latency。
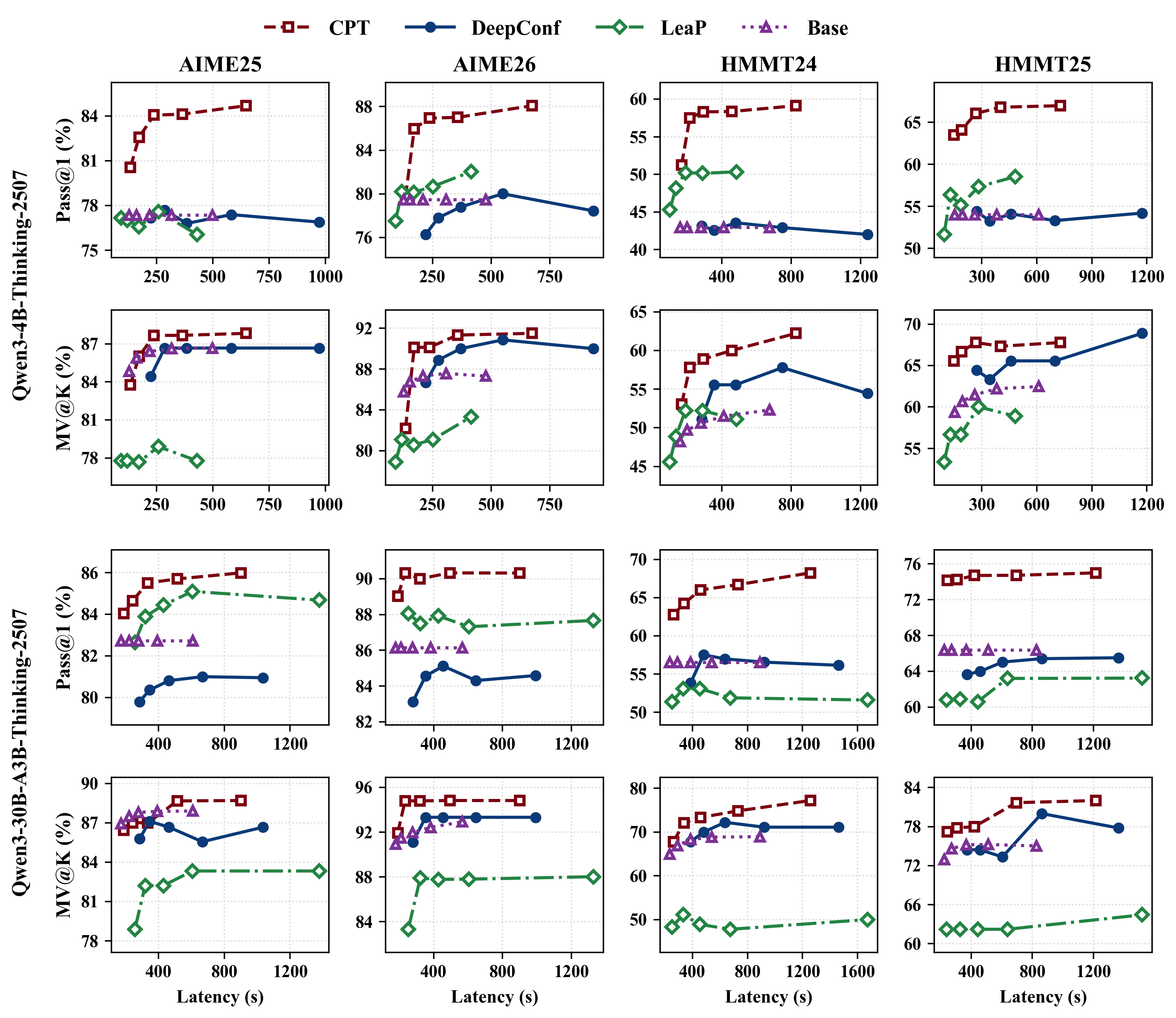
红色虚线方块是 CPT。多数子图里,红线都压在其他方法上方,也就是同等延迟下准确率更高,或者达到同等准确率所需延迟更低。这个结论在 Qwen3-4B 和 Qwen3-30B-A3B 两个尺度上都成立。
我不太想把这解读成“CPT 碾压所有推理方法”。更准确的说法是:在论文设定的并行采样预算和数学推理任务里,CPT 把分支之间的中间信息利用起来,改善了 accuracy-latency trade-off。
图里还有一个细节值得看:CPT 不只是 MV@K 更好,Pass@1 也提升了。这说明它不是简单让多个分支更一致然后投票更稳,而是单条分支本身也因为读到了共享情报而更容易走到正确路径。
论文还在 appendix 里看了 tokens 和 FLOPs。
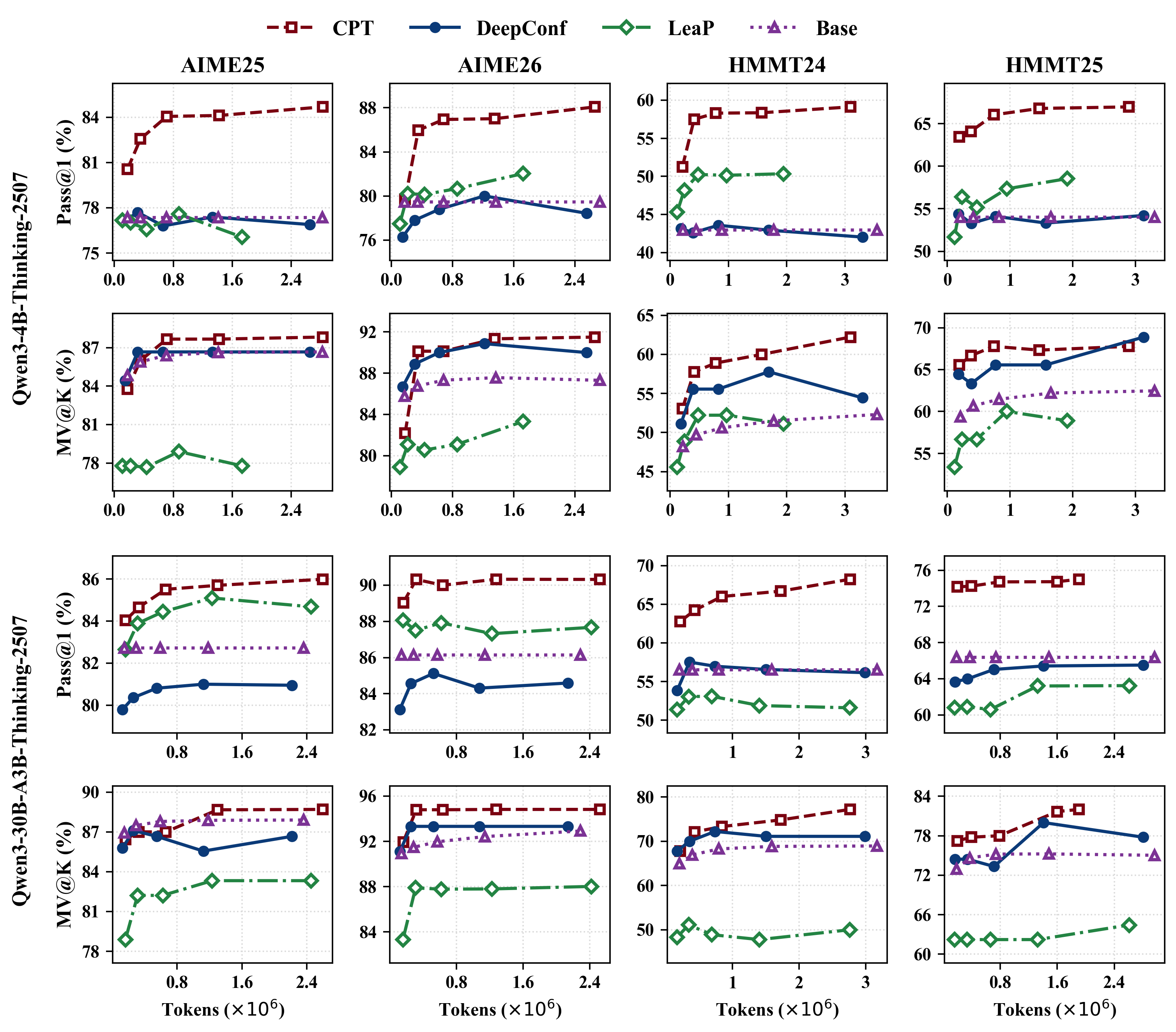
token 维度上,CPT 的表现也很好。这个符合预期:既然减少重复发现,模型自然少生成一些“绕圈”的推理文本。
但 FLOPs 维度就没这么完美了。论文自己也承认,CPT 通过 prompt-level broadcasting 更新共享信息池,标准 decoding 实现可能要重新 prefill 更新后的 context。这会引入额外 FLOPs。也就是说,CPT 在 wall-clock latency 和 generated tokens 上很有吸引力,但如果你的瓶颈是纯 FLOPs 或 prefilling 成本,它还不是终局方案。
这个地方我觉得作者讲得比较诚实,没有把开销藏起来。
消融实验:什么时候分享、分享多少、怎么去重
CPT 的几个超参很容易让人担心:广播太早会不会带偏?信息池太大是不是污染上下文?去重阈值随便设会不会不稳?论文做了几组消融。
广播时机:中段共享最好
在 Qwen3-4B-Thinking-2507、64 并行样本下,作者在 HMMT24 和 HMMT25 上扫了 start threshold 和 stop threshold。
| Benchmark | 设置 | Pass@1 | Tokens | Latency |
|---|---|---|---|---|
| HMMT24 | \(\tau_{\mathrm{stop}}=0\), \(\tau_{\mathrm{start}}=0.4\) | 57.86 | 1.52M | 482s |
| HMMT24 | \(\tau_{\mathrm{stop}}=0.10\), \(\tau_{\mathrm{start}}=0.4\) | 58.35 | 1.57M | 457s |
| HMMT24 | \(\tau_{\mathrm{stop}}=0.30\), \(\tau_{\mathrm{start}}=0.4\) | 56.75 | 1.54M | 395s |
| HMMT25 | \(\tau_{\mathrm{stop}}=0\), \(\tau_{\mathrm{start}}=0.4\) | 66.94 | 1.43M | 410s |
| HMMT25 | \(\tau_{\mathrm{stop}}=0.10\), \(\tau_{\mathrm{start}}=0.4\) | 66.79 | 1.47M | 403s |
| HMMT25 | \(\tau_{\mathrm{stop}}=0.30\), \(\tau_{\mathrm{start}}=0.4\) | 64.58 | 1.42M | 354s |
这里能看出一个 trade-off:停止太晚,开销上来;停止太早,准确率掉。\(\tau_{\mathrm{stop}}=0.1\) 是相对均衡的选择。
start threshold 的结果也很有意思。\(\tau_{\mathrm{start}}=1.0\) 相当于立刻广播,但并不是最好。在 HMMT24 上,\(\tau_{\mathrm{start}}=0.5\) 的 Pass@1 是 58.78,\(\tau_{\mathrm{start}}=1.0\) 只有 53.05;HMMT25 上,\(\tau_{\mathrm{start}}=0.4\) 是 66.79,\(\tau_{\mathrm{start}}=1.0\) 是 63.37。
这验证了一个朴素但容易被忽略的点:协作不能变成过早同步。太早开共享池,分支还没探索出足够互补信息,就开始互相影响,反而损失多样性。
广播大小:512 条信息在这里最合适
在 HMMT25 上,作者扫了每次广播最多插入多少条信息,也就是 \(M\)。
| Broadcast Size \(M\) | 32 | 64 | 128 | 256 | 512 | 1024 |
|---|---|---|---|---|---|---|
| Pass@1 | 61.65 | 61.93 | 63.68 | 64.03 | 66.79 | 65.32 |
| Tokens | 1.53M | 1.48M | 1.43M | 1.42M | 1.42M | 1.42M |
| Latency | 429s | 411s | 408s | 407s | 402s | 385s |
\(M\) 增大通常会提升 Pass@1,但到 1024 反而掉一点。我的理解是,共享信息太少不够用,太多又会让 context 变嘈杂。512 在这组任务上比较甜。
不过这里也有一个工程问题:不同任务的信息密度不一样。数学题里的中间约束可能短而有用,开放问答或代码任务的信息形态会复杂很多。固定 \(M=512\) 是否泛化,需要更多任务验证。
去重阈值:太低会误杀,太高会放水
语义去重阈值 \(\tau_{\mathrm{dup}}\) 的消融如下。
| 相似度阈值 \(\tau_{\mathrm{dup}}\) | 0.65 | 0.70 | 0.75 | 0.80 | 0.85 |
|---|---|---|---|---|---|
| Pass@1 | 62.60 | 64.57 | 66.79 | 65.92 | 66.66 |
| Tokens | 1.51M | 1.48M | 1.46M | 1.46M | 1.47M |
| Latency | 383s | 385s | 402s | 400s | 405s |
阈值太低,会把“相关但不相同”的有用信息过滤掉;阈值太高,又让重复信息混进共享池。0.75 在 HMMT25 上最好,但 0.80、0.85 也没崩,说明方法对这个超参不算极端敏感。
成本拆解:信息抽取不贵,prompt 更新才是麻烦
CPT 多了抽取、去重、广播,开销从哪里来?论文给了组件级统计,64 并行样本下延迟单位是秒,FLOPs 单位是每题 PFLOPs。
| Benchmark | Model | Sampling 延迟 | Info Extract 延迟 | Dedup & Filter 延迟 | Sampling PFLOPs | Info Extract PFLOPs |
|---|---|---|---|---|---|---|
| AIME25 | Qwen3-4B | 307.90 | 35.65 | 18.16 | 112.43 | 1.66 |
| AIME25 | Qwen3-30B-A3B | 420.37 | 61.59 | 29.44 | 81.99 | 1.70 |
| AIME26 | Qwen3-4B | 291.00 | 39.79 | 21.92 | 107.11 | 1.50 |
| AIME26 | Qwen3-30B-A3B | 415.13 | 50.42 | 24.86 | 82.02 | 1.80 |
| HMMT24 | Qwen3-4B | 368.43 | 56.75 | 26.95 | 138.52 | 1.62 |
| HMMT24 | Qwen3-30B-A3B | 607.90 | 83.55 | 34.46 | 141.12 | 2.64 |
| HMMT25 | Qwen3-4B | 331.72 | 44.42 | 22.39 | 120.02 | 1.50 |
| HMMT25 | Qwen3-30B-A3B | 582.40 | 75.03 | 32.27 | 132.76 | 2.35 |
抽取本身的 FLOPs 相比 sampling 很小。真正麻烦的是 prompt-level broadcast 带来的 context 更新。标准实现里,更新共享信息区可能需要重新 prefill,FLOPs 会被拉高。
所以如果我要把 CPT 用到线上系统,会优先考虑两件事:
一是让共享池更小、更准,不要把 512 条都硬塞进去;二是做 cache-aware 的上下文更新,避免每次广播都把 prefix 重新算一遍。论文 limitations 里也提到,未来可以设计 attention-level 或 cache-aware 机制来降低这个成本。
我怎么看这篇论文
我觉得 CPT 最打动人的地方,是它把并行推理的低效说清楚了。
过去我们经常把 test-time scaling 讲成“花更多算力换更高准确率”。但这里的关键不是多花,而是怎么花。独立并行采样的默认接口太粗糙:生成一堆分支,结束后聚合。中间过程完全没有通信。
CPT 把通信加进来了,而且加得比较克制:
- 不训练模型;
- 不需要外部 reward model;
- 不改写分支私有轨迹;
- 只共享抽取后的中间信息;
- 用自适应策略避免过早或过晚广播。
这个方案工程上有吸引力,因为它不要求重训基础模型,也不依赖复杂 verifier。只要你已经有并行采样系统,理论上就能加一个“抽取—去重—广播”的协作层。
但它的问题也很明显。
第一个问题是共享信息的可靠性。论文 prompt 里要求模型保守抽取,不要写 unsupported claims,这很好。但模型生成的中间信息天然可能带错。错信息一旦进入共享池,会影响所有分支。作者用“不要盲信黑板”的 worker prompt 缓解这个问题,但这不是完全解决。尤其在开放式任务里,错误中间结论可能更难被分支自行纠正。
第二个问题是任务范围。论文主实验集中在数学推理,数学题的中间信息比较结构化:约束、公式、反例、缺失 case。这种信息很适合被抽成 bullet。换成长文 Agent、代码仓库修改、多模态推理,什么信息值得共享、怎么去重、怎么避免污染,都会复杂很多。
第三个问题是系统实现成本。CPT 在延迟 frontier 上很漂亮,但 FLOPs 视角有隐性代价。prompt-level broadcast 是最容易落地的实现,却不是最便宜的实现。真正想在大规模服务里跑,可能要把共享池做成更底层的 attention/cache 机制,而不是纯 prompt 拼接。
还有一个我没完全确定的地方:CPT 提升 Pass@1 的一部分,可能来自“给分支提供了更强的上下文提示”,而不只是减少重复探索。论文用信息统计和注入实验已经做了不少验证,但想彻底拆开“复用有用信息”和“上下文提示改变模型行为”这两件事,可能还需要更细的 causal analysis。
对工程实践的启发
如果你正在做推理增强系统,我觉得 CPT 至少给了三个很实在的启发。
第一,别只盯 rollout 数量,要看有效信息宽度。
64 条分支不一定比 16 条强很多,关键是它们是否真的探索了互补信息。如果分支高度相关,增加采样数就是在放大重复劳动。
第二,中间信息比最终答案更值得共享。
很多系统到结束时才做 voting、rerank、verifier。CPT 提醒我们,推理过程中出现的局部发现、失败路径、约束关系,可能更早产生价值。尤其是数学、代码、规划任务,中间状态的复用很重要。
第三,共享要克制。
全量共享完整轨迹听起来简单,但上下文爆炸、噪声污染、分支坍缩都会来。CPT 的抽取、去重、自适应广播,实际上是在回答一个工程问题:什么信息值得进入公共通道,什么时候进入,进入多少。
如果让我把它改成一个生产系统,我会试这几件事:
- 用更强的结构化抽取格式,比如把 insight、pitfall、derived constraint 分开存;
- 给共享池加置信度和来源分支数,不让单条分支的脆弱结论直接影响所有人;
- 在广播时做任务相关的检索,而不是随机采样最多 \(M\) 条;
- 用轻量 verifier 或 consistency check 过滤高风险黑板信息;
- 优化 KV cache,让广播不必每次触发大规模 prefill。
收尾:并行推理需要的不只是更多分支,而是更好的协作协议
这篇论文的标题 “Share More, Search Less” 起得挺准。它没有说“想得更久”,而是说“少搜一点重复的东西”。
我的整体判断是:CPT 是一个很值得关注的 test-time scaling 工程方向。它不是万能药,也没有解决推理可靠性的全部问题;但它指出了并行采样里一个真实且昂贵的浪费:分支之间的信息隔离。
未来的推理系统,很可能不会只是单模型多采样再投票,而会更像一组协作中的解题者:有人探索,有人记录,有人检查,有人读公共白板继续往下走。
CPT 往这个方向迈了一步。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我