长篇小说推理卡壳怎么办?ComoRAG 让 RAG 学会"想到一半再去翻书"
核心摘要
读完《哈利·波特》整套书的人,被问"斯内普为什么杀邓布利多",脑子里发生的事情其实很复杂——你要想起邓布利多得了绝症、想起牢不可破的誓言、想起斯内普藏了一辈子的忠诚,再把这些散落在七本书里的线索拼起来,最后才能给出"这是忠诚不是背叛"的答案。
这事让现在的 RAG 系统很为难。一次性检索拿到的几个 chunk,要么相互矛盾("斯内普保护哈利"和"斯内普杀邓布利多"),要么根本不在同一条因果链上。多步检索的方法虽然能多查几次,但每一步之间没有"记忆",查完就忘,最后还是拼不出完整画面。
来自华南理工大学和微信 AI 的这篇 AAAI 2026 工作 ComoRAG,把人脑前额叶皮层(PFC)的元认知调控机制搬到了 RAG 里:模型答不出来时不直接放弃,而是基于过往的记忆生成新的"探查性查询",再去检索,再把新证据写进一个全局记忆池,循环 2 到 3 次直到能给出连贯答案。在四个 200K+ tokens 的长叙事 benchmark 上,相对最强 baseline 拿到了最多 11 个点的相对提升,EN.MC 从 64.6 涨到 72.9,叙事类问题上 F1 相对提升 19 个点。
我对这篇论文的判断是:它没有发明全新的检索算子,但把"卡住时该做什么"这件事讲清楚了。这是一个不需要训练、可以即插即用挂在 RAPTOR 或 HippoRAG 上的循环框架,工程价值大于理论新意,但价值确实不小。
论文信息
- 标题:ComoRAG: A Cognitive-Inspired Memory-Organized RAG for Stateful Long Narrative Reasoning
- 作者:Juyuan Wang, Rongchen Zhao(共同一作),Wei Wei, Yufeng Wang, Mo Yu, Jie Zhou, Jin Xu, Liyan Xu(通讯)
- 机构:华南理工大学未来技术学院 / 独立研究员 / 琶洲实验室 / 微信 AI(腾讯)
- 会议:AAAI 2026
- arXiv:https://arxiv.org/abs/2508.10419
- 代码:https://github.com/EternityJune25/ComoRAG
一、为什么传统 RAG 在长小说上不灵
先聊一个我自己在做长文档 QA 时碰到过的尴尬场景。
你有一本几十万 token 的小说,用户问"小说结尾 Trace 选择住在哪里"。这种问题在多步推理 QA 上看不出难度——单跳就能查到。但在叙事文本里它常常很难,因为"Trace"这个名字在书里出现了几百次,不同章节里他在不同地方住过,问题里隐含的"结尾"这个限定词,对应的是某个具体情节段落,而那个段落里可能根本没出现"住"或者"choose"这种关键词。
直接拿原 query 去做 dense retrieval,召回的全是 Trace 的对话片段,对解题没用。这就是论文里说的叙事推理的真正难点:不是连接离散事实,而是要持续构建并修订一个关于剧情、人物、动机演化的"心理模型"。
论文用一个 Harry Potter 的经典问题来串起整个故事——"斯内普为什么杀邓布利多"。我特别喜欢这个例子,它把传统 RAG 的几种失败模式一次性展示了出来。
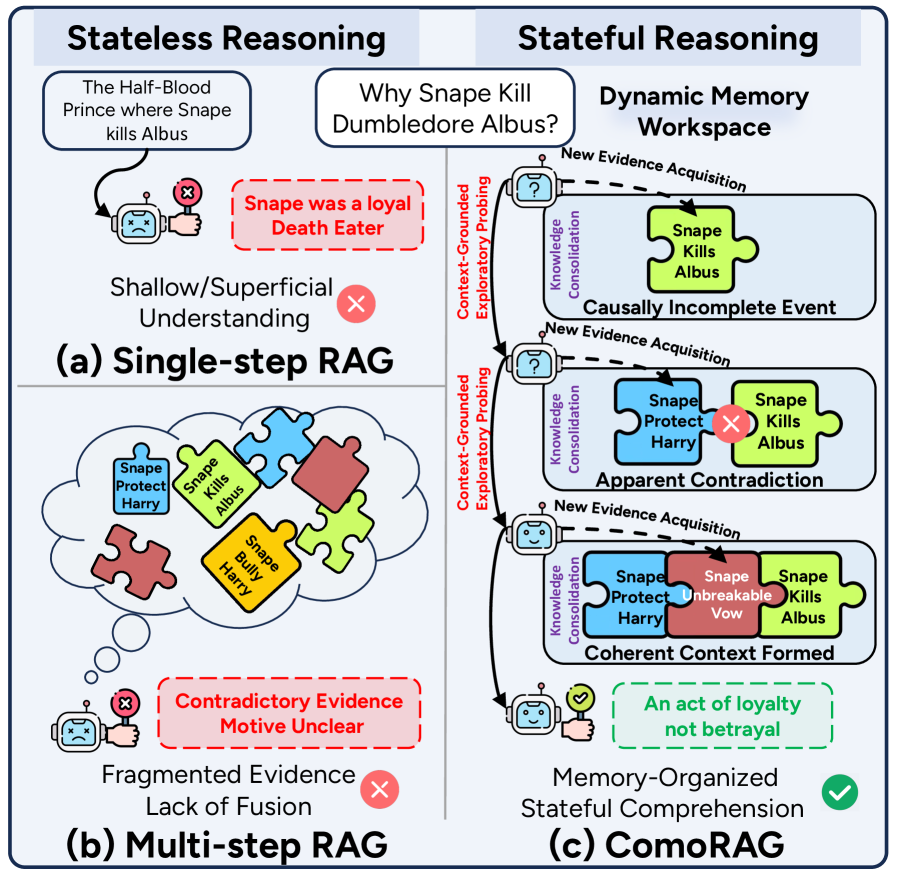
图1:三种 RAG 范式对比。ComoRAG 的核心区别在右侧——记忆工作区里的认知状态会随着检索轮次演化
一次性检索(图1a)的问题:拿到"斯内普保护哈利"和"斯内普杀邓布利多"两段证据,模型直接懵了——这俩看起来就是矛盾的,没有第三段证据来调和,模型只能瞎猜。RAPTOR、HippoRAGv2 这类基于知识图谱或聚类摘要的方法说到底还是 one-shot 的,索引再花哨,查一次拿不到关键证据就没救。
多步检索(图1b)的问题:IRCoT、Self-RAG、MemoRAG 这些方法多查几次,但每次查询之间是独立的——查到"斯内普保护哈利"之后,下一步查询不会基于这个证据去主动找"为什么会有这种保护行为",而是按 CoT 推理或者预设的 reflection 机制走,结果就是检索到的证据像散点,没有围绕一个演化中的心理模型收敛。
ComoRAG 的做法(图1c):维护一个动态记忆工作区,里面存着每一轮检索的"过往证据 + 综合线索"。当某一轮答不出(Failure Signal)时,下一轮的探查 query 会基于"上一轮我们已经知道了什么、还缺什么"来生成。从"因果不完整事件"到"表面矛盾",再到"形成连贯上下文"——这个过程模拟人脑前额叶的 metacognitive regulation。
说实话,看到这个 motivation 我第一反应是"挺自然的,应该早就有人这么做了"。然后翻了一圈相关工作,发现确实有 IRCoT 和 MemoRAG 在做类似事情,但它们没把"记忆怎么演化"这件事形式化——IRCoT 是把 CoT 当中间 query,MemoRAG 是用一个压缩模型生成 clue。ComoRAG 把整个循环拆成了 6 个明确的算子,给后人提供了一个可以挂载、可以替换、可以做消融的脚手架。这个脚手架本身有价值。
二、方法核心:把人脑前额叶搬进 RAG 循环
ComoRAG 的整体架构如下图。看起来有点复杂,但拆开看每一步其实都很直观。
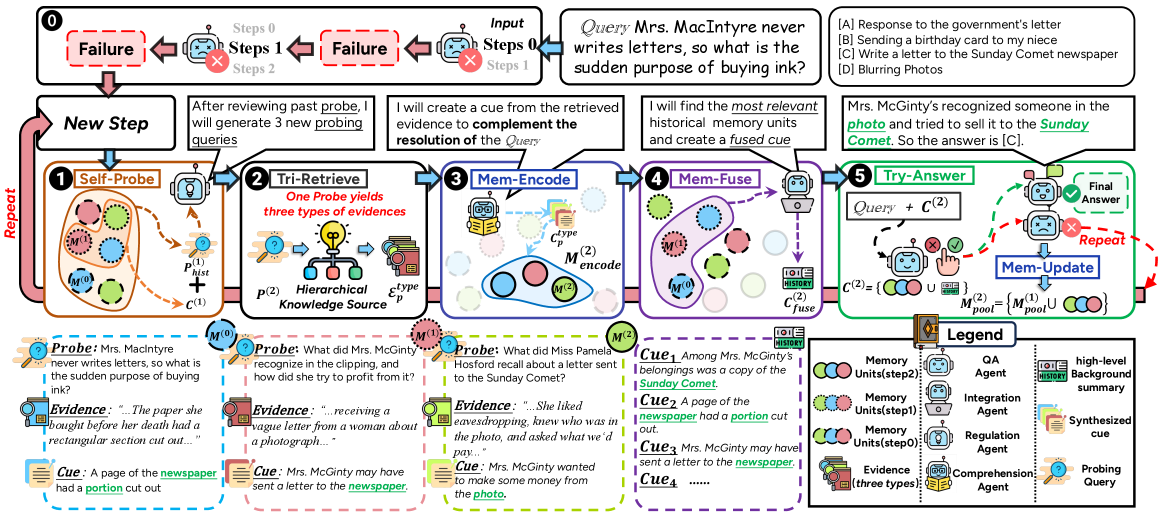
图2:完整框架。下方的 query 是 Mrs. McGinty 案例,最终在第 1-2 轮通过迭代探查找到"她想给报社写信"这条关键证据
整个框架分三块:分层知识源、动态记忆工作区、元认知控制循环。
2.1 分层知识源:把文本拆成三种"记忆类型"
模仿人脑里不同脑区存储不同类型记忆的设计,ComoRAG 把原始长文本预处理成三个互补的索引层。
Veridical Layer(真实层):原始 text chunk,外加 LLM 抽取的知识三元组(subject-predicate-object)。这部分对应人记的"具体事实"。论文里实验显示这是最关键的一层——消融掉后准确率掉 30 个相对点。
Semantic Layer(语义层):基于 RAPTOR 的 GMM 聚类递归摘要,形成一棵语义摘要树。对应"主题/概念性记忆"。
Episodic Layer(情景层):滑动窗口式叙事摘要,按时间线把连续或因果相关的事件聚合成"情节段"。对应"按情节展开的情景记忆"。这一层是 ComoRAG 比较有特色的设计——RAPTOR 和 HippoRAG 都没有显式建模时间/情节维度。
每一轮的 Tri-Retrieve 算子会同时在这三层上检索,每一层得到的证据走不同的处理通道。这种设计的好处是召回更全面,但代价是每一轮要做 3 倍的检索和 LLM 调用——ComoRAG 不是一个轻量级方案,这点要先说清楚。
2.2 动态记忆工作区:每次检索都生成一个"记忆单元"
每完成一次检索,框架会生成一个三元组形式的记忆单元 \(m = (p, \mathcal{E}^{type}_p, \mathcal{C}^{type}_p)\):
- \(p\):触发这次检索的探查 query
- \(\mathcal{E}^{type}_p\):从某一知识层(ver/sem/epi)检索到的证据集
- \(\mathcal{C}^{type}_p\):综合线索(synthesized cue),由一个叫 Comprehension Agent 的 LLM 生成,用一句话总结"这些证据如何能补充对原始 query 的理解"
记忆池 \(\mathcal{M}_{pool}\) 把所有轮次的记忆单元都存起来,每个单元的 cue 都做了 embedding,可以用来召回历史相关记忆。
我觉得这里最聪明的设计是把"原始证据"和"综合线索"分开存。证据是冗长的原文,线索是模型自己的一句话总结。后续轮次需要召回历史记忆时,是基于 cue 的 embedding 来匹配的——这相当于让模型对自己之前查到的东西做了一层抽象索引,减少了上下文负担,也避免了"过去的原文堆在 prompt 里把现在要看的证据挤出去"。
2.3 元认知控制循环:六个算子串起来
每一轮循环包含 6 个步骤,论文里每个算子都给了独立的命名:
| 算子 | 作用 | 触发时机 |
|---|---|---|
| Self-Probe | 基于历史 probing 和上轮失败原因,生成新一批探查 query | 上轮失败时调用 |
| Tri-Retrieve | 在三层知识源上同时检索 | 每轮初 |
| Mem-Encode | 把新检索的证据压成记忆单元(含 synthesized cue) | 每条证据 |
| Mem-Fuse | 召回历史记忆中与原 query 相关的 cue,融合成一个高层背景摘要 | 每轮中 |
| Try-Answer | 用本轮新证据 + 融合后的历史背景,尝试回答原 query | 每轮末 |
| Mem-Update | 把本轮新生成的记忆单元加进全局记忆池 | 每轮末 |
Self-Probe 这个算子是整个框架的引擎。它的输入是三样东西:原始 query \(q_{init}\)、完整的历史 probing 列表 \(\mathcal{P}_{hist}^{(t-1)}\)、上一轮所有 cue 集合 \(\{\mathcal{C}\}^{(t-1)}\)。输出是一组新的探查 query \(\mathcal{P}^{(t)}\):
工程上这个算子就是给 LLM 一个 prompt:你正在尝试回答这个问题,过去几轮你查了什么、得到了什么线索,但还没答出来,请生成几个新的探查方向。
Mem-Fuse 是另一个关键算子。当过去几轮已经积累了一堆记忆单元后,框架会用 \(q_{init}\) 的 embedding 去记忆池里捞出最相关的一批历史记忆,让一个 Integration Agent 把它们融合成一段背景摘要:
这一步的工程意义是:随着循环轮次增加,记忆池会越来越大,没法全部塞进 prompt。Mem-Fuse 就是动态地把"和当前问题相关的历史记忆"压缩成一个可以塞进 prompt 的背景。
最后 Try-Answer 把本轮的新证据 \(\mathcal{M}_{encode}^{(t)}\) 和融合后的历史背景 \(\mathcal{C}_{fuse}^{(t)}\) 一起给 QA Agent,要么给出最终答案、终止循环,要么给出 Failure Signal、进入下一轮。
整套循环最多跑 5 轮,但论文实验显示 2-3 轮就能拿到大部分增益(后面会看到)。
三、实验结果:长文本上的优势确实明显
3.1 主实验:4 个 benchmark 全部刷过
实验在四个长叙事 benchmark 上做:NarrativeQA(58k tokens 平均)、EN.QA 和 EN.MC(来自 ∞BENCH,200k+ tokens)、DetectiveQA(侦探小说,100k+)。所有方法用 GPT-4o-mini 作为 LLM backbone,BGE-M3(0.3B)作为检索器,公平对齐。
| 类别 | 方法 | NarrativeQA F1 | EN.QA F1 | EN.MC ACC | DetectiveQA ACC | MC Avg |
|---|---|---|---|---|---|---|
| LLM | GPT-4o-mini 直接读全文 | 27.29 | 29.83 | 30.57 | 30.68 | 30.63 |
| Naive RAG | BGE-M3 (0.3B) | 23.16 | 23.71 | 59.82 | 54.54 | 57.18 |
| Naive RAG | NV-Embed-v2 (7B) | 27.18 | 34.34 | 61.13 | 62.50 | 61.82 |
| Naive RAG | Qwen3-Embed-8B | 24.19 | 25.79 | 65.50 | 61.36 | 63.43 |
| Enhanced RAG | RAPTOR | 27.84 | 26.33 | 57.21 | 57.95 | 57.58 |
| Enhanced RAG | HippoRAGv2 | 23.12 | 24.45 | 60.26 | 56.81 | 58.54 |
| Multi-step | Self-RAG | 19.60 | 12.84 | 59.83 | 52.27 | 56.05 |
| Multi-step | MemoRAG | 23.29 | 19.40 | 55.89 | 51.13 | 53.51 |
| Multi-step | RAPTOR+IRCoT | 31.35 | 32.09 | 63.76 | 64.77 | 64.27 |
| Multi-step | HippoRAGv2+IRCoT | 28.98 | 29.27 | 64.19 | 62.50 | 63.35 |
| Ours | ComoRAG | 31.43 | 34.52 | 72.93 | 68.18 | 70.56 |
几个值得停下来想想的点:
第一,ComoRAG 用 0.3B 的 BGE-M3 干掉了用 8B Qwen3-Embed 的 Naive RAG。 EN.MC 上 72.93 vs 65.50,这说明在长上下文叙事任务上,单纯加大 embedding 模型并不是出路,迭代推理结构才是。这个发现挺值钱的,意味着工程上不需要去硬上更大的 embedding 模型,省下来的算力可以花在 LLM agent 上。
第二,LLM 直接读全文的成绩特别难看——MC 平均才 30.63,几乎就是瞎猜(4 选 1 是 25%)。这印证了"lost in the middle"问题在 200K tokens 这个尺度上有多严重,也说明长文本任务上 RAG 不只是省算力,是真的有信号优势。
第三,IRCoT 加在 RAPTOR 和 HippoRAGv2 上确实有不小提升,已经是 ComoRAG 之外最强的 baseline。但 ComoRAG 在 EN.MC 上比 RAPTOR+IRCoT 高了 9.17 个点,这个差距相当于 IRCoT 相对 RAPTOR 的提升再翻一番。
不过我得指出一个可能存疑的点:所有 RAG 方法的 LLM context length 都被 cap 在 6k tokens。这个限制对 ComoRAG 是友好的——它本来就是按 chunk 工作;但对 Naive RAG 来说可能压制了潜力。如果允许 32k context,单纯把 Naive RAG 的 top-k 拉大,差距会缩小多少?这是论文没回答的。
3.2 长度敏感性:越长的文本,优势越大
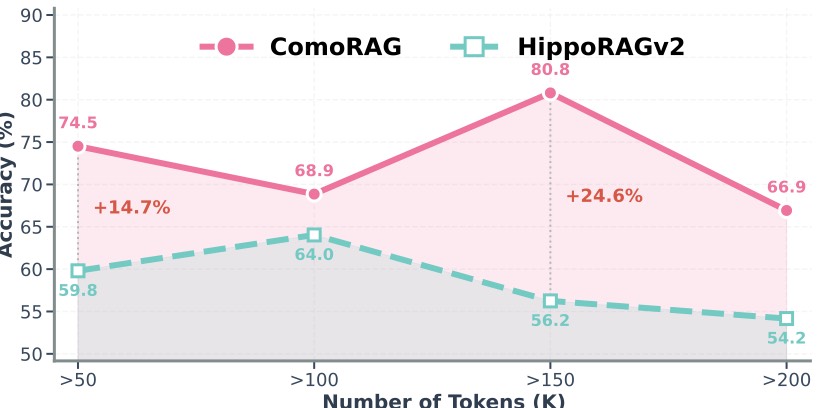
图3:横轴是文档 token 数,纵轴是准确率。文档越长,ComoRAG 的领先优势越大
这张图比主表更能说服我。在 > 50K 的子集上 ComoRAG 比 HippoRAGv2 高 14.7 个点;到了 > 150K 这个段,差距拉大到 24.6 个点。
为什么?因为越长的文档里,stateful reasoning 才越重要——线索分散在更远的距离上,one-shot 检索越没戏。这个 trend 印证了 ComoRAG 的设计假设:迭代检索的价值随上下文长度单调增长。
不过 > 200K 这个段反而又掉下来了,论文里没解释。我猜可能是 > 200K 的样本里有一部分本身就是 GPT-4o-mini 推理能力的硬天花板(即使给完整证据也答不出),无论怎么迭代都白搭。
3.3 消融实验:每一块都不能拿掉
| 方法 | EN.MC ACC | EN.QA F1 | EN.QA EM |
|---|---|---|---|
| ComoRAG(完整) | 72.93 | 34.52 | 25.07 |
| —— Index 消融 —— | |||
| w/o Veridical(去真实层) | 51.97 | 22.24 | 15.88 |
| w/o Semantic(去语义层) | 64.63 | 30.82 | 22.65 |
| w/o Episodic(去情景层) | 64.63 | 31.48 | 21.47 |
| —— Retrieval 消融 —— | |||
| w/o Metacognition(去记忆工作区) | 62.01 | 26.95 | 18.53 |
| w/o Regulation(去 Self-Probe) | 55.02 | 27.95 | 20.59 |
| w/o Both(退化为 one-shot) | 54.15 | 25.64 | 17.35 |
几个观察:
Veridical Layer 是命门。拿掉真实层(原文 chunk + 三元组)后,EN.MC 直接掉到 51.97,比 baseline 还差。这个结果其实告诉我们:语义摘要和情节摘要是锦上添花,原文 chunk 才是底盘。这一点和我的工程直觉吻合——再好的摘要也是有损压缩,关键事实最终还得回到原文确认。
Regulation(Self-Probe)比 Metacognition 更关键。w/o Regulation 比 w/o Metacognition 掉得更多(55.02 vs 62.01)。也就是说,"主动生成新探查 query"这件事的价值高于"维护记忆工作区"。这个发现挺反直觉的——我原本以为记忆机制是核心,结果探查机制才是。
两个一起拿掉,掉到 54.15,相当于退化成 one-shot。这个数字和 RAPTOR、HippoRAGv2 在同个 benchmark 上的成绩对得上,说明消融基线是合理的。
3.4 迭代收敛分析:2-3 轮就够了
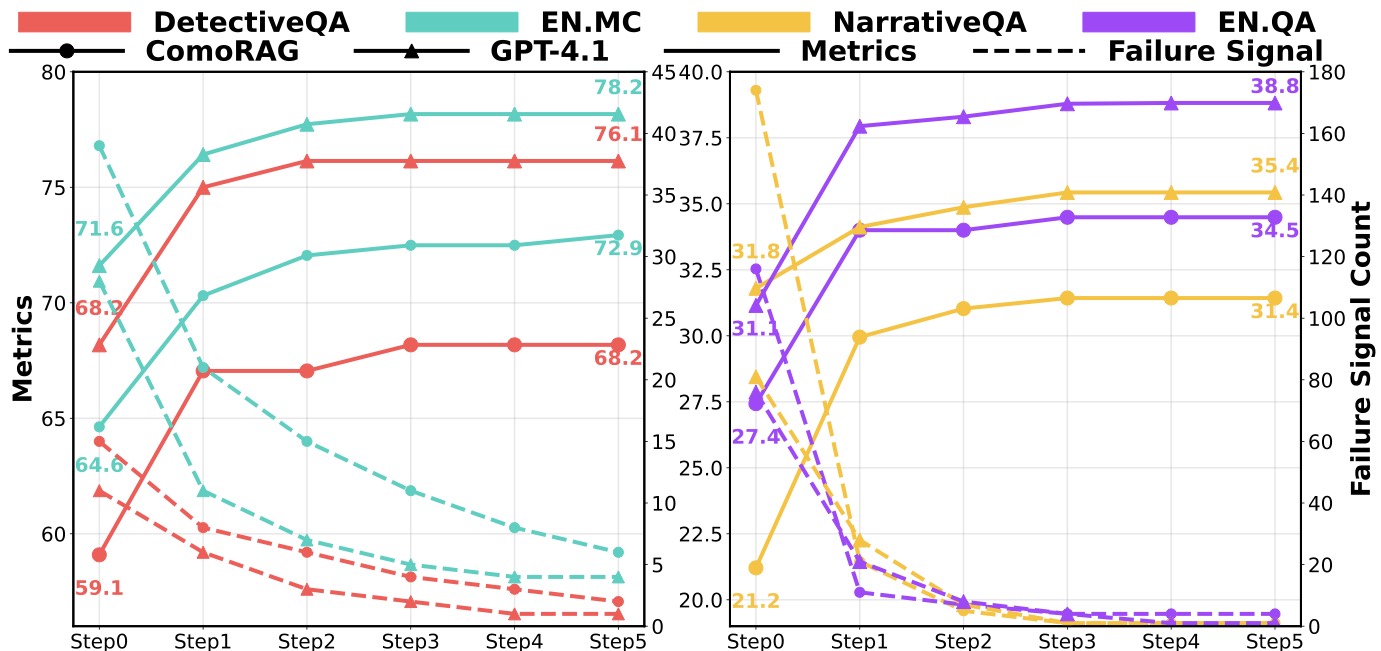
图4:迭代收敛性。绝大部分增益发生在 step1-2,step3 之后趋于平稳,Failure Signal 数也在 step3 后基本归零
EN.MC 上 step0(单步)只有 64.6,step1 涨到 70.3,step2 到 72.0,之后就基本平了。论文说大部分提升在 2-3 轮内完成——这个发现工程上很重要,意味着实际部署时设最大 5 轮其实有点保守,3 轮足矣,能省掉 40% 的 LLM 调用。
另一个细节:换成 GPT-4.1 当 backbone 后,整体曲线整体抬升(EN.MC 从 72.9 到 78.2),但收敛速度更快——step1 就接近天花板。说明更强的 LLM 不仅推理上限高,元认知效率也高,少几轮就能想清楚。
3.5 即插即用:挂在别的 RAG 上也涨
| 方法 | NarrativeQA F1 | EN.QA F1 | EN.MC ACC | DetectiveQA ACC |
|---|---|---|---|---|
| ComoRAG(默认 GPT-4o-mini) | 31.43 | 34.52 | 72.93 | 68.18 |
| ComoRAG + Qwen3-32B | 32.17 | 35.29 | 74.24 | 69.32 |
| ComoRAG + GPT-4.1 | 35.43 | 38.82 | 78.17 | 76.14 |
| HippoRAGv2 单独 | 23.12 | 24.45 | 60.26 | 56.81 |
| HippoRAGv2 + ComoRAG 循环 | 29.12 | 31.76 | 68.56 | 63.64 |
| RAPTOR 单独 | 27.84 | 26.33 | 57.21 | 57.95 |
| RAPTOR + ComoRAG 循环 | 30.55 | 34.31 | 69.00 | 62.50 |
把 ComoRAG 的元认知循环挂到 RAPTOR 上,EN.MC 直接从 57.21 涨到 69.00,相对提升 21%。挂到 HippoRAGv2 上,EN.MC 从 60.26 涨到 68.56。这个结果非常有工程价值——如果你已经在用 RAPTOR 或 HippoRAG 跑生产,ComoRAG 不是要替换你的索引,而是给你的检索过程套一个外壳。
我觉得这是这篇论文最 sellable 的卖点。它没在和 RAPTOR / HippoRAG 抢生态位,而是宣称"我可以让你们都变得更强"。
3.6 按 query 类型分析:叙事问题上优势最大
论文把所有问题分成三类:
- Factoid(事实型):单条信息就能答,例如"Octavio Amber 信什么宗教"
- Narrative(叙事型):需要理解情节进展作为背景,例如"Trace 在小说结尾选择住在哪"
- Inferential(推断型):需要超越字面文本去推断动机,例如"Nils 第一次去 Aiden 公寓的主要原因是什么"
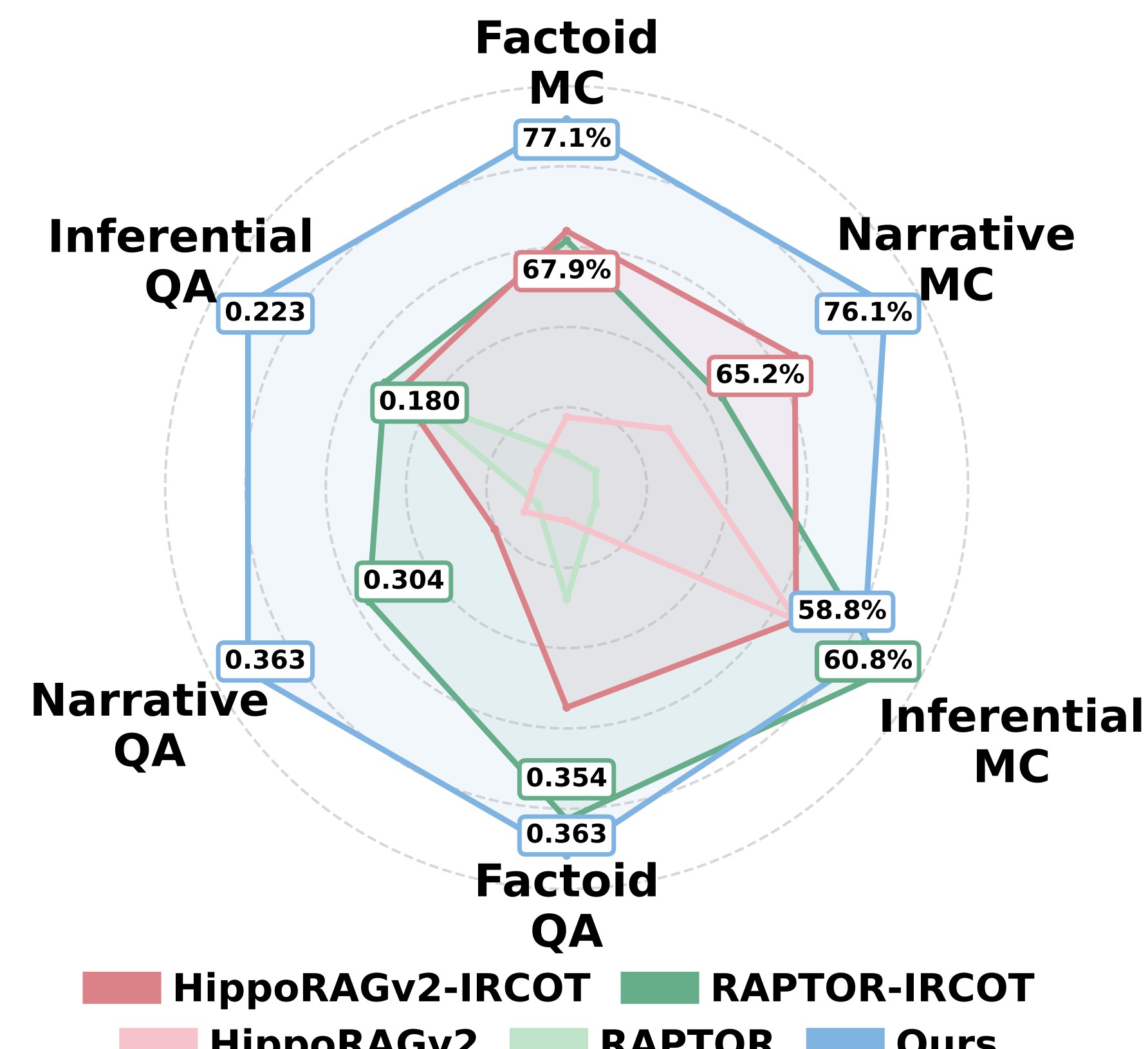
图5:六个维度(三种 query 类型 × QA/MC)的对比。ComoRAG 在所有维度上都领先,但叙事和推断类的领先幅度最大
更直观的是下图——各 query 类型在不同处理阶段的解决比例:
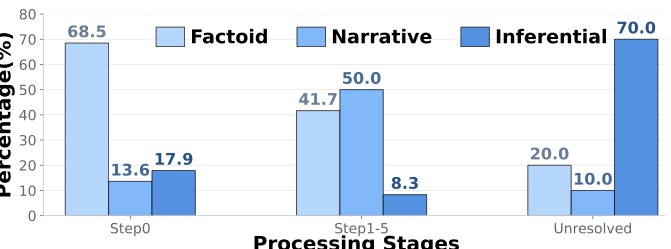
图6:分阶段的 query 类型构成。一次检索就能搞定的主要是事实型,迭代循环主要在啃叙事型,剩下啃不动的主要是推断型——这恰好对应 LLM 推理能力的天花板
这张图我特别喜欢,它把 ComoRAG 的价值定位讲得清清楚楚:
- Step 0(单步)解决的问题里 68.5% 是 Factoid——一次检索就能搞定的全是事实查询,这部分 ComoRAG 没什么独特优势
- Step 1-5(迭代)解决的问题里 50% 是 Narrative——叙事推理才是元认知循环的主战场
- Unresolved(5 轮还没解决)里 70% 是 Inferential——这部分主要是 LLM 自己的推理能力天花板,再多轮也没用
在 EN.QA 的叙事类问题上,ComoRAG 相对最强 baseline 取得 19% 的相对 F1 提升,EN.MC 上 16% 的准确率提升。这个数字相当能打。
四、几点批判性思考
聊完亮点,说几个我觉得需要打问号的地方。
第一,对比设置可能略偏向 ComoRAG。
所有 RAG 方法的 context length 都被限制在 6k——这对单步检索方法不太友好。Naive RAG 通常会受益于更长的 context(比如塞 top-20 而不是 top-5),但这里被 cap 死了。如果 baseline 也允许 32k context 重新评测,差距会缩多少?论文没给。
不过转念一想,公平对比本来就是相对的——论文已经做到所有方法用同样的 LLM backbone、同样的 embedding 模型、同样的 chunk size,再扩 context 反而会引入 LLM 自身长文本能力的混淆变量。这个 trade-off 我能接受。
第二,计算成本被刻意淡化了。
论文几乎没讨论 ComoRAG 的 LLM 调用次数。每一轮要做:Self-Probe(1 次)+ Tri-Retrieve(3 路检索)+ Mem-Encode(3×|P| 次 LLM 调用生成 cue)+ Mem-Fuse(1 次)+ Try-Answer(1 次)。如果 |P| = 3,每轮就是 1 + 0 + 9 + 1 + 1 = 12 次 LLM 调用,跑 3 轮就是 36 次。相比 RAPTOR+IRCoT 大约 3-5 次的水平,ComoRAG 贵了一个数量级。
这是个真问题。论文里没有 cost-effectiveness 的对比,只在 Appendix 里偷偷给了 token 消耗。生产环境部署时,ComoRAG 在 EN.MC 上比 RAPTOR+IRCoT 高 9 个点的代价,可能是 7-10 倍的 LLM 调用费用。这个交易划不划算,看场景。如果你做的是高价值长文档分析(法律、金融、医学文献),划得来;如果是 C 端轻量问答,可能不行。
第三,"前额叶皮层"这个类比的认知科学价值有限。
论文反复强调 PFC 和元认知调控的灵感来源,引了不少认知神经科学论文。我觉得这个类比对论文 framing 有帮助,但不要太当真——三层知识源对应"不同类型记忆"是工程上合理的拆分,但说成"模仿不同脑区"是 over-claim 了。Veridical / Semantic / Episodic 这三个名字在认知科学里有明确定义,论文里的实现其实就是 chunk + 聚类摘要 + 滑窗摘要,和 Tulving 的情景记忆理论隔着十万八千里。
但话说回来,研究领域里用脑科学做 framing 是常态,不应该因此就否定方法价值。把它当成一个有启发的设计原则,而不是严格的认知建模。
第四,case study 和 qualitative example 偏少。
论文给了一个 Mrs. McGinty 的案例(图 2 下方),从"为什么买墨水"出发,迭代到"她给报社写信"。但这只是一个 cherry-picked 的成功案例。我想看的是失败案例分析——5 轮还没解决的那 30% 推断型问题里,模型卡在哪里?是 Self-Probe 生成的 query 不好,还是 Mem-Fuse 把关键证据淹没了,还是 Try-Answer 的 prompt 没给够提示?这些 failure mode 分析对工程落地比成功案例更有价值。
五、工程启发:什么样的系统该考虑 ComoRAG
聊完技术,最后给点工程视角的判断。
适合用 ComoRAG 的场景:
- 长文档(100K+ tokens)的复杂推理 QA,单次检索召回率确实不够
- 容忍较高 LLM 成本(比如每个 query 几十次 LLM 调用)
- 已经在用 RAPTOR / HippoRAG 但效果到顶,想找个低改动的提升方案
- 业务上明确以"叙事性"或"推断性"问题为主——事实型问题用 ComoRAG 性价比不高
不太适合的场景:
- 短文档或中等长度(\< 50K)的 QA,one-shot retrieval 已经够用
- C 端高 QPS 场景,循环带来的延迟和 cost 受不了
- 评估指标只看简单事实回忆,元认知循环没有发挥空间
可以借鉴的设计点(即使不直接用 ComoRAG):
- 三层知识索引的拆分思路——把"原文 + 主题摘要 + 情节摘要"分开存,比单一索引更鲁棒
- synthesized cue 作为记忆抽象——别把原始证据反复塞 prompt,让 LLM 先压成一句话再做 embedding
- Failure Signal 触发的循环——而不是固定多轮检索,让 LLM 自己判断"够不够答"
- Mem-Fuse 的相关历史召回——记忆池不是越来越大就越好,要按相关性动态筛选
我的整体判断是:这是一篇工程导向的好论文。它没有突破性的新算法,但把"长叙事 RAG 卡住时该做什么"这个问题拆得很清楚,给出了一个可复现、可挂载、可消融的框架。如果你在做长文档 RAG 系统,值得花两个小时把代码翻一遍——即使最后不直接用,这套元认知循环的拆分方式也会改变你思考多步检索的方式。
最后一个观察是关于研究趋势的。从 2023 年的 IRCoT,到 2024 年的 Self-RAG / MemoRAG,再到 ComoRAG,多步检索的研究在沿着一个很清晰的方向演化:从多查几次,到知道为什么要再查一次。下一步可能是什么?我猜是 ComoRAG 的元认知循环和 agentic RAG 合流——把 ReAct 风格的 tool-use 结合进来,让模型不仅能在文档内迭代,还能跨工具(搜索、计算、查 KG)协同。不过那是另一篇论文的故事了。
参考文献
- ComoRAG 论文:https://arxiv.org/abs/2508.10419
- 代码仓库:https://github.com/EternityJune25/ComoRAG
- RAPTOR (ICLR 2024):递归聚类摘要的 RAG 方法
- HippoRAGv2 (NeurIPS 2024):基于 PageRank 的知识图谱 RAG
- IRCoT (ACL 2023):交错 CoT 与检索的多步 RAG
- MemoRAG (2024):双系统架构的长上下文 RAG
- ∞BENCH (ACL 2024):超长上下文评测
- NarrativeQA:长叙事问答数据集
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我