MEML-GRPO 论文解读:异构多专家互学习破解 RLVR 的奖励稀疏
一句话先讲清楚
论文标题: MEML-GRPO: Heterogeneous Multi-Expert Mutual Learning for RLVR Advancement
arXiv 编号: 2508.09670,AAAI 2026
作者团队: Weitao Jia、Jinghui Lu、Haiyang Yu et al.
一句话总结: 这篇论文从 GRPO 的核心痛点切入——当一道难题的所有 rollout 都答错时,零奖励无法提供任何梯度信号。作者的解法是引入"异构多专家":用三个不同的 system prompt(ground truth 风格、DeepSeek-R1 风格、Doubao-1.5-thinking 风格)扮演三个专家,在同一个 base model 上各跑一组 rollout,再通过 KL 蒸馏让弱专家向强专家靠拢,并配一个 "Hard Example Buffer" 在最难的样本上做周期性 SFT 兜底。Qwen2.5-1.5B-Math 上平均涨 4.89 个点,Llama3.2-1B-Instruct 上平均涨 11.33 个点。
我读完之后第一反应是:这是一个把 KD(知识蒸馏)、ensemble、curriculum SFT 三件事打包塞进 GRPO 的工程化方案。它不是一个"漂亮的理论想法",而是一个"把已知好招数组合到一起去攻一个明确痛点"的系统工程。它的价值不在于发明新东西,而在于搞清楚 RLVR 在难题上的失败模式具体是什么样、并用一组组合拳让训练能继续往前推。
1. 为什么我特意挑这篇出来读
最近几篇 RLVR 论文我读下来有个共同的吐槽点:所有人都默认 group rollout 里至少有一个对、一个错的 rollout。GRPO 的优势归一化 \(\hat{A}_i = (R_i - \mathrm{mean}(R)) / \mathrm{std}(R)\) 在所有 rollout 都是 0 的时候直接 NaN/0,整个 batch 等于白训。
实际工程里这个问题非常常见。在 AIME / GPQA 这种难题上,1.5B 小模型 8 次 rollout 全错的概率非常高(从论文数据看,Llama3.2-1B 在 StrategyQA 上 baseline 准确率只有 54%,意味着至少 30%+ 的样本会出现 8 次全错)。这部分样本完全没有学习信号,相当于训练时的"哑火"。
这条线在 2025 下半年到 2026 初已经有过几次尝试解决: - DAPO 用 dynamic clip 让"少数几个对的"信号被放大 - DAPO-FT 给关键 forking token 加权 - Dr.GRPO 修了 GRPO 的 reward shaping bias - PPPO(前一篇刚解读)只优化前缀 token
但这些方法都不解决"全错时无信号"这个根本问题——它们改的是"有信号但信号弱"的情况下怎么放大信号,对"完全无信号"束手无策。
MEML-GRPO 的切入点是从源头解决:与其在一个 prompt 下采 8 次 rollout 然后全错,不如换三个不同风格的 system prompt,每个采几次,至少有一个 expert 能给出正确解的概率会大幅提升。这是一个非常工程化但合理的思路。
2. 核心问题:reward sparsity 到底有多严重
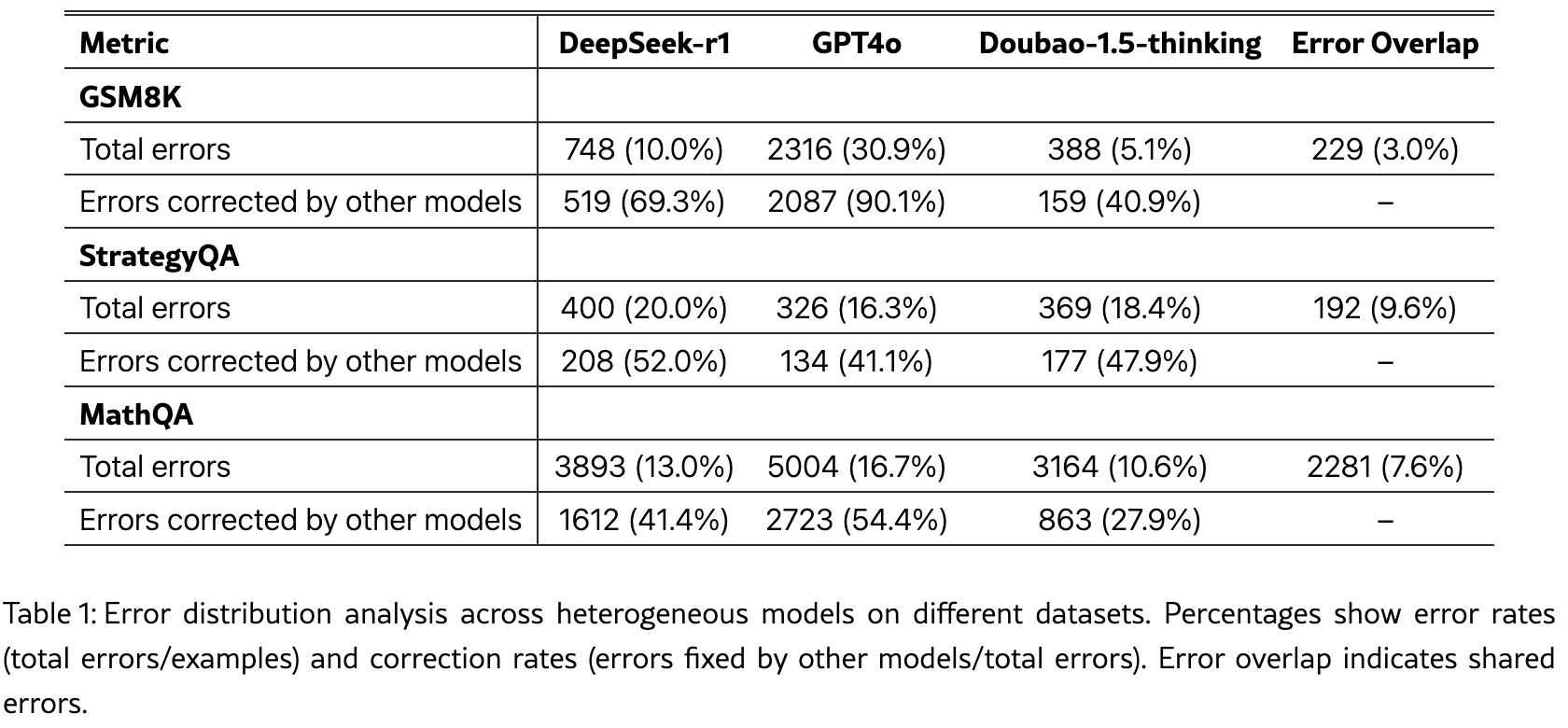
作者在 Introduction 里给出了一组很有说服力的统计:在 GSM8K、StrategyQA、MathQA 三个数据集上,分别让 Qwen2.5-1.5B-Math(按 Expert0 ground truth SFT 后的版本)、用 DeepSeek-R1 reasoning trajectory 训出的版本、用 Doubao-1.5-thinking 训出的版本各跑 8 次。
观察到的错误分布有两个关键点: 1. 错误并不重叠。三个 expert 出错的样本集合交集比预期小很多——GSM8K 上三个 expert 全错的样本只占总错误样本的 30% 左右。 2. 错误可以被互相纠正。一个 expert 答错的题目,有 60% 以上能被另一个 expert 答对。
这两个观察是 MEML-GRPO 的合法性基础。如果错误高度重叠(三个 expert 都在同一些题上一起翻车),那多专家就没意义;如果错误不重叠且可互纠,就有大量可挖掘的"集体智慧"红利。
实际看错误率的具体数字:StrategyQA 上 Expert1 的单独错误率是 30%、Expert2 是 28%、Expert0 是 35%。但至少一个 expert 答对的概率超过 90%。这就是 MEML-GRPO 能拿到 11+ 个点提升的根本红利来源——它把 base model 自己跑 8 次的"全错"率显著降下来了。
3. 方法:MEML-GRPO 怎么把"多专家"做成训练范式
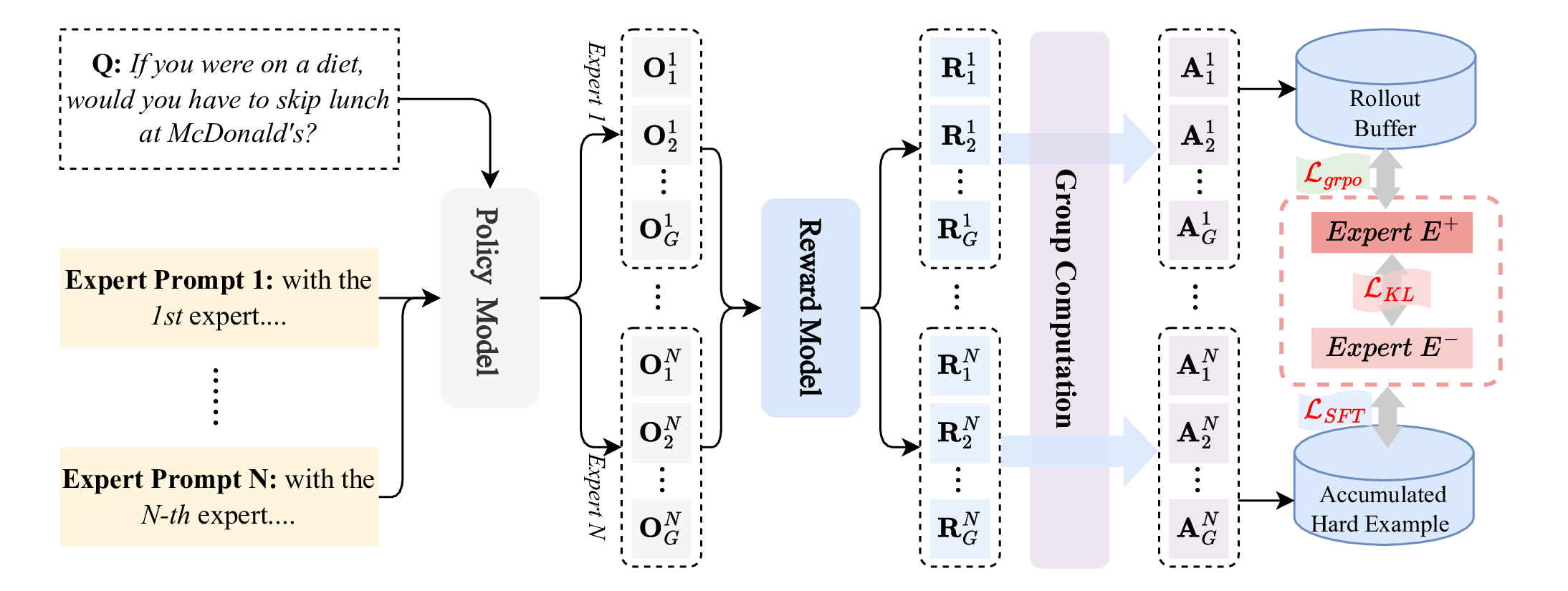
整个 pipeline 可以拆成三个部件:MEF、RIEL、Hard Example Buffer。
3.1 MEF:Multi-Expert Fine-tuning
第一步是把 base model 训成一个能"切换风格"的 multi-expert 模型。具体做法:
- 准备三个 system prompt:\(P_0\)(ground truth 风格)、\(P_1\)(DeepSeek-R1 风格)、\(P_2\)(Doubao-1.5-thinking 风格)。
- 收集对应的三套 reasoning trajectory:\(E_0, E_1, E_2\)(其中 \(E_0\) 是数据集自带的 ground truth,\(E_1\) 和 \(E_2\) 是用 DeepSeek-R1 和 Doubao-1.5-thinking 在训练集上生成的 off-policy 推理轨迹)。
- 用 SFT 方式训 base model,loss 是:
训完之后 base model 在不同 system prompt 下会展现不同 reasoning 风格——它实际上是一个"single model with multiple persona",而不是真正的 MoE 路由。这点要分清:MEML-GRPO 里没有真正的多模型并行,只是同一个模型在不同 system prompt 下被解读成不同 expert。
这个设计的好处是inference 成本和单模型一样——选最好的 expert prompt 就行,不用同时跑三套。
3.2 RIEL:Reinforced Inter-Expert Learning
第二步是 RL 阶段,这里才是 MEML-GRPO 的核心。每一步 training 做这些事:
- 对每个 question \(Q\),每个 expert 用对应的 system prompt 各采 \(G/3\) 个 rollout(论文里 \(G=8\),所以每个 expert 大约采 2-3 次,总共仍是 8 次)。
- 计算 GRPO loss:每个 expert 内部按 GRPO 标准流程算 advantage 和 policy gradient。
- 算"专家间互学习"的 KL 项:找出当前 batch 里表现最好的 expert \(E^+\) 和最差的 expert \(E^-\),让 \(E^-\) 的输出分布向 \(E^+\) 靠拢:
这里 \(O^+\) 是 \(E^+\) 给出的正确 rollout。这个 loss 的几何意义是:让弱 expert 学会在自己的 system prompt 下生成强 expert 的正确答案——它没有改变 system prompt,但改变了"在那个 prompt 下输出的分布"。
我觉得这个设计很巧妙的一点是:它不保持 expert 风格的多样性,只让弱者学会用自己的风格也能写出对答案——而不是把弱 expert 的 system prompt 替换成强的(那样会退化成单 expert)。这是 mutual learning 而非 model collapse。
3.3 Hard Example Buffer:兜底机制
第三步是为最难的样本兜底。即使有三个 expert,仍然有部分题目所有 expert 都失败——对这些样本,作者维护一个容量为 \(B = 64\) 的 buffer:
- 如果 expert \(i\) 在某个 \(Q\) 上 8 次 rollout 中错超过 \(K = 6\) 次,就以 \(K/G = 75\%\) 的概率把 \((Q, P_i) \to O_{gt}\) 加进 buffer。
- buffer 满了之后周期性地做一次 SFT:
这一步的本质是让 RLVR 学不动的样本退回 SFT 模式硬学一遍。在工程上是非常合理的兜底,因为 SFT 不需要 reward signal 是非零,只要有 ground truth 就能学。它相当于给 RLVR 加了一个 fallback channel。
3.4 总目标
三个 loss 加权求和,\(\lambda_1, \lambda_2\) 是超参。论文里没明确给 \(\lambda\) 的具体数值(这是个小遗憾,复现的人会比较烦),从训练稳定性看大概率是把 KL 和 SFT 控制在小系数(比如 0.1-0.3)。
4. 实验:数字到底有多漂亮
4.1 主表(GSM8K + StrategyQA + MathQA × Qwen + Llama)
我把主表关键行整理出来:
Qwen2.5-1.5B-Math:
| 方法 | GSM8K | StrategyQA | MathQA | 平均 |
|---|---|---|---|---|
| Expert1-SFT-GRPO | 73.1 | 62.5 | 71.8 | 69.1 |
| Expert1-SFT-Dr.GRPO | 76.1 | 64.5 | 73.3 | 71.3 |
| MoE-SFT-GRPO(Expert1) | 75.6 | 70.3 | 68.5 | 71.4 |
| MoE-SFT-Dr.GRPO(Expert1) | 77.7 | 69.3 | 74.2 | 73.7 |
| MEML-GRPO(Expert1) | 79.6 | 75.3 | 76.4 | 77.1 |
Llama3.2-1B-Instruct:
| 方法 | GSM8K | StrategyQA | MathQA | 平均 |
|---|---|---|---|---|
| Expert1-SFT-GRPO | 58.2 | 54.0 | 45.2 | 52.4 |
| Expert1-SFT-Dr.GRPO | 58.4 | 54.8 | 46.7 | 53.3 |
| MoE-SFT-GRPO(Expert1) | 57.1 | 53.8 | 55.2 | 55.3 |
| MoE-SFT-Dr.GRPO(Expert1) | 57.2 | 54.2 | 54.2 | 55.2 |
| MEML-GRPO(Expert1) | 61.0 | 63.3 | 58.4 | 60.9 |
我看这张表的几个观察:
- Llama3.2 上的提升幅度(+11.33 个点平均)远比 Qwen2.5-Math 上(+4.89 个点)大。这是 reward sparsity 假设的有力佐证——Llama3.2-1B 比 Qwen2.5-1.5B-Math 弱很多(GSM8K baseline 56% vs 76%),所以"全错 rollout"出现得更频繁,MEML-GRPO 的红利就更显著。
- StrategyQA 上的提升最大。Qwen 上 +13 个点(62.5 → 75.3),Llama 上 +9 个点(54.0 → 63.3)。StrategyQA 是 commonsense 推理,对 LLM 来说本来就更难,多专家覆盖红利最高。
- MoE-SFT-Dr.GRPO vs MEML-GRPO 的差距是 RIEL+HSFT 的真正贡献。MoE-SFT-Dr.GRPO 已经做了"多专家 SFT + Dr.GRPO",但 MEML-GRPO 多了 KL mutual learning 和 hard example buffer。Qwen 上这俩部件再涨 3.4 个点,Llama 上再涨 5.7 个点——证明这两个部件不是"锦上添花",是真正的核心组件。
4.2 消融:MoE / HSFT / IML 三个部件的贡献
| MoE | HSFT | IML | Qwen 平均 | Llama 平均 |
|---|---|---|---|---|
| × | × | × | 70.1 | 54.3 |
| ✓ | × | × | 72.6 | 55.5 |
| ✓ | ✓ | × | 76.4 | 59.8 |
| ✓ | × | ✓ | 74.6 | 57.5 |
| ✓ | ✓ | ✓ | 77.3 | 61.8 |
这张表非常有信息量:
- 单加 MoE(多专家 SFT)只涨 2.5 / 1.2 个点,效果有限。说明"用三个 prompt 训"本身贡献不大。
- MoE + HSFT 涨 6.3 / 5.5 个点,是单组件贡献最大的。Hard Example Buffer 这种"看起来朴素的 SFT 兜底"实际上是最关键的——这印证了 reward sparsity 真的是大头痛点。
- MoE + IML 涨 4.5 / 3.2 个点,也不错,但比 HSFT 弱一些。
- 三者全开涨 7.2 / 7.5 个点,几乎是 HSFT 单独贡献的两倍多,说明三个部件正交、可叠加。
读到 HSFT 单独贡献最大这一行的时候,我有个不太舒服的感觉:这暗示 MEML-GRPO 的核心价值其实是"在难题上做 SFT 兜底",多专家和互学习只是辅助。如果是这样,那为什么不直接做"GRPO + 难题 SFT 混合训练"?多专家这套架构是不是有点重?这是值得后续研究跟进的关键点——可能"多 expert prompt"在这里更多是给 SFT 提供多样化的 trajectory(让 buffer 里的样本不全是 ground truth 单一风格),而不是真的靠 inter-expert 互学习。
4.3 训练动态:reward 曲线
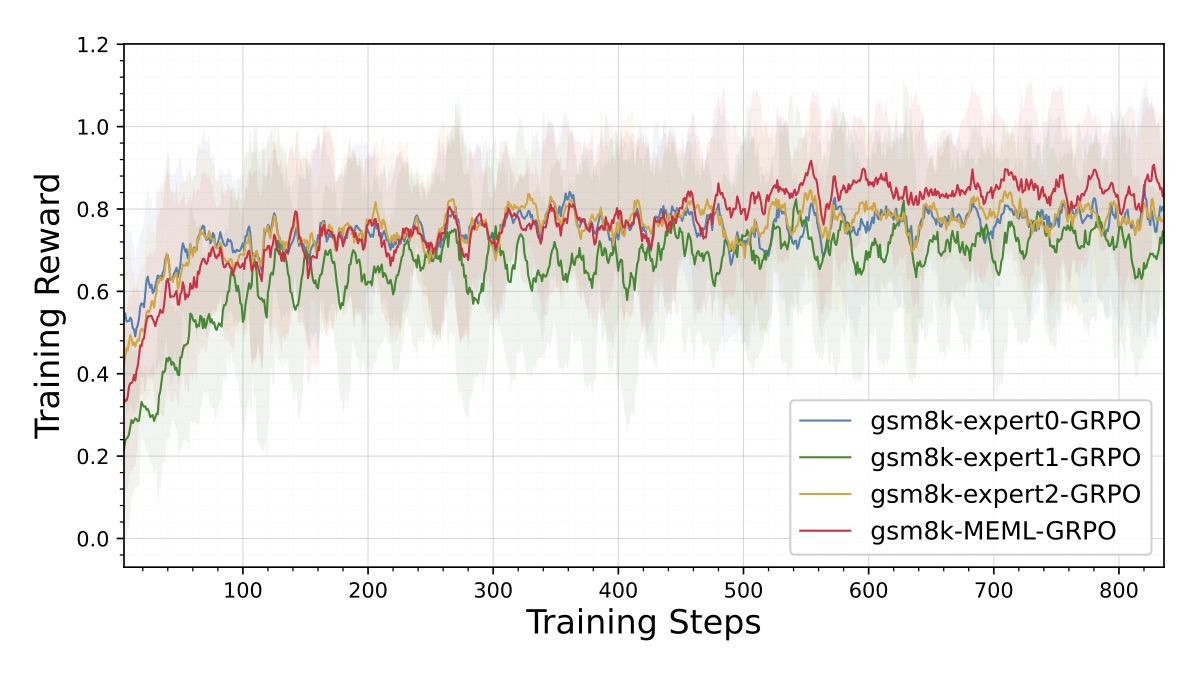
reward 曲线显示 MEML-GRPO 比 GRPO/Dr.GRPO 更早达到平台、且最终平台更高。这个曲线的形状和我之前的工程经验吻合:当 reward 信号变得更密集(不再频繁出现全错的零信号 batch),训练就会更稳、收敛更快。
具体看,GSM8K 上 GRPO 的 reward 在 step 100 左右达到 0.7 附近停滞,而 MEML-GRPO 在 step 80 已经超过 0.8,在 step 200 达到 0.85+。这种 ~5-10 个点的稳态优势在 RL 训练里是相当显著的。
4.4 与 Majority Voting 的对比
作者还跑了一组很有意思的对比:MEML-GRPO 训完后单 expert 推理 vs 训完后三个 expert 跑 majority voting。结论是 MEML-GRPO 单 expert 推理就已经追上甚至超过 majority voting。这意味着 inter-expert mutual learning 真的把"多 expert 的集体能力"内化到了单 expert 里——inference 时不需要跑多次。
这个对工程部署是个好消息。Majority voting 在 inference 时要跑 3 倍计算量,MEML-GRPO 可以零额外开销拿到等价或更好的效果。
5. 我的批判性思考
5.1 这篇论文的强项
- 诊断准确。reward sparsity 是 GRPO 在难题上的真痛点,MEML-GRPO 直接对症下药。
- 多组件协同设计。MEF + RIEL + HSFT 三件套不是独立招数堆砌,而是有逻辑闭环:MEF 提供多样性、RIEL 让多样性可迁移、HSFT 兜住最难的尾部。
- 跨模型族验证。Qwen2.5-Math(强 baseline)和 Llama3.2(弱 baseline)都跑了,提升幅度的差异本身就是 reward sparsity 假设的佐证。
- inference 成本不增加。这是和 majority voting / model ensemble 的关键区别,对工业落地很友好。
5.2 我有保留的地方
-
Expert 的本质是 prompt-conditioned 同一个模型。不是真正的异构模型,所以专家间互补的上限被 base model 自身能力限制。如果 base model 完全不会某个题,三个 prompt 都给不出正确解,MEML-GRPO 就退化成 GRPO + HSFT。
-
HSFT 的贡献最大但论文叙事弱化了。从消融看,Hard Example Buffer 是单组件贡献最大的(+5-6 个点),而论文标题强调的 Mutual Learning 单独只有 +3-4 个点。如果改成 "Hard Example Curriculum + Multi-Prompt RLVR" 可能更能反映核心贡献,但叙事上没那么吸引。
-
System prompt 的设计敏感性没讨论。三个 expert prompt 是怎么设计的?换成另外三个会怎么样?这块是 reproducibility 的关键,但论文里没看到 prompt 的详细描述(要等附录或代码 release)。
-
HSFT 的触发频率会受任务难度影响。论文里写 "\(K=6/8 = 75\%\) 概率写入 buffer",对 GSM8K(easy)来说 buffer 大概率永远填不满;对 AIME(hard)来说 buffer 会快速填满频繁触发 SFT。这种"任务自适应"是有意为之还是巧合?没说清。
-
Dr.GRPO 已经修了 GRPO 的 reward shaping bias,但 MEML-GRPO 是基于 GRPO 还是 Dr.GRPO? 论文似乎是基于 GRPO 的。如果直接把 MEML 的思路套到 Dr.GRPO 上,是不是能再涨一波?这个组合实验缺失。
-
三个 expert 是否最优?为什么不是 5 个、10 个? 多专家数量的 scaling 没有跑。直觉上随着 expert 数增加,错误覆盖会更全,但 SFT 阶段的混合训练复杂度也会上升。这是 trade-off 但没回答。
5.3 这篇论文最大的启示
RLVR 的下一阶段瓶颈可能不在 algorithm,而在 data diversity。MEML-GRPO 最深的洞察是:当训练样本本身的解法多样性不足时(base model 自己采样几次都是同一种思路),RL 很难突破能力上限。它解决这个问题的方式是引入"外部 expert reasoning trajectory"(DeepSeek-R1、Doubao-1.5-thinking 生成的解题路径)作为多样性来源。
这其实是把 off-policy reasoning data 显式地接入到 RLVR 训练。从这个角度看,MEML-GRPO 和 Distillation 的边界在变模糊——它不只是 RL,而是 "RL + 选择性蒸馏 + 难题 SFT" 的混合体。
未来一两年我猜会有几个方向:
- 更多 expert 来源:把 GPT-5、Claude 4、Gemini 3 等不同 frontier 模型的 reasoning trace 都纳入,看 expert 多样性能不能继续 scale。
- Expert 自动发现:与其手工设计 system prompt,不如用某种 contrastive / clustering 方法自动找到"互补的 reasoning style"。
- MEML-GRPO × PPPO:MEML 解决 sparsity,PPPO 解决前缀重要性。两个正交,组合应该能再涨一波。
6. 这篇论文怎么和最近读的几篇串起来
最近读的 RLVR 系列论文呈现出明显的"分工":
| 论文 | 痛点 | 解法 |
|---|---|---|
| GRPO | (baseline) | group relative baseline |
| DAPO | clip 不均匀 | dynamic clip |
| Dr.GRPO | reward shaping bias | bias correction |
| MEML-GRPO | reward sparsity(全错无信号) | 多专家覆盖 + 互学习 + 难题 SFT |
| PPPO | token 位置不均匀 | prefix gradient mask |
| LLMdoctor | token reward 不均匀 | face prompt Δ_t |
| GenPRM | step credit assignment | process reward model |
这张表横着看,可以发现 MEML-GRPO 攻击的是"训练数据/采样多样性"维度,而其他论文攻击的是"训练算法/credit assignment"维度。两条线是正交的——你完全可以把 MEML 的多专家采样塞进 PPPO 的前缀优化里,理论上两者红利都能拿到。
我个人觉得 2026 这一年 RLVR 方向最大的趋势是:框架层面会出现"标准 GRPO + 一组可插拔扩展"的工程化形态。MEML-GRPO 的 mutual learning + hard buffer、PPPO 的 prefix mask、Dr.GRPO 的 bias correction、DAPO 的 dynamic clip——这些会被整合成 modular 的训练 plugin,研究者可以根据任务难度按需开关。如果这种生态形成,MEML-GRPO 这篇会作为"reward sparsity 解决方案"成为标配组件之一。
7. 给想跟进这个方向的同行一些建议
-
如果你的 base model 在目标任务上 baseline 准确率低于 60%,强烈建议加 Hard Example Buffer。这是 MEML-GRPO 里 ROI 最高的部件,工程上只是给 RLVR 加一个 SFT side channel,复杂度不高。
-
多专家 prompt 的设计要追求风格差异而非答案差异。论文里 ground truth、DeepSeek-R1、Doubao-1.5-thinking 三种 reasoning style 是真的不同——一个偏简洁直接、一个偏长链 CoT、一个偏 reflective thinking。如果你的三个 prompt 风格高度相似,错误重叠会很严重,红利就拿不到。
-
System prompt 的引入会改变 inference 时的行为。MEML-GRPO 训完之后选最好的 expert prompt 推理,这意味着部署时也要带上 system prompt。如果你的 production 不允许带 system prompt,这套方法的迁移会有问题。
-
buffer 的容量和触发条件要根据任务难度调。\(B=64, K=6/8=75\%\) 是论文给的默认值,但在更难任务上 buffer 会过快填满频繁触发 SFT,反而干扰 RL 学习的稳定性;在更简单任务上 buffer 永远填不满 HSFT 实际不工作。这是个超参敏感点。
-
如果只能选一个组件来做,我会选 Hard Example Buffer。Multi-Expert SFT 和 Mutual Learning 的工程复杂度都不低,而 HSFT 只是一个"难题 SFT 旁路",可以快速集成到现有训练框架。
写在最后
MEML-GRPO 是那种我读完会有点矛盾感的论文——一方面,它的核心想法(多专家覆盖 + 兜底 SFT)非常工程化、不算"理论上的优美";另一方面,它实打实地解决了 RLVR 在难题上的关键痛点,跨两个模型族都拿到 5-11 个点的提升。这种"思路朴素但效果扎实"的论文在 AAAI 2026 这一波里其实少见,大部分 RLVR 论文都在追求更精巧的 advantage 估计或更花哨的 reward shaping。
我个人觉得 MEML-GRPO 最大的启示不是任何一个技术细节,而是它逼着我们承认一件事:当前 RLVR 框架在很多任务上不是调不好,而是无法启动——base model 在难题上根本采不到正确答案,再好的算法也没辙。这种问题不是改 loss 函数能解决的,必须从数据多样性、外部知识注入、curriculum 等系统层面去解决。
从这个角度,MEML-GRPO 的真实贡献是把"什么时候 RLVR 该收手、退回 SFT"这个工程问题给量化、参数化、自动化了。Hard Example Buffer 就是那个"自动决定何时退回 SFT"的机制。这个洞察大概率会比论文里的 KL mutual learning 更长寿——未来即使有更好的多专家方案,"难题 SFT 兜底"这套思路也会被继承。
我读完后写在笔记本上的一句话是:RL 不是万能的,承认 RL 学不动的样本、给它一个 fallback,反而让 RL 整体更好用。