大模型工具调用的"知行差距":它知道该调用工具,但就是不动手
写在前面
先抛一个让我有点意外的实验现象。
拿 Llama-3.2-3B-Instruct 跑一组算术题,把题目按它自己实际能不能做对来标"该不该用计算器"——这个模型自己做不出来的题,标成"该用工具",自己能稳定做对的,标成"不用工具"。然后再正经给它挂上 calculator 工具,让它自己决定调不调。
结果:该调不调、不该调却调 的样本占了 54.0%。
一半多。这不是工具调用能力差,这是工具调用决策几乎在抛硬币。
更奇怪的是,如果你训练一个线性 probe 去读这个模型在最后几层的 hidden state,问"这道题它内心觉得自己需要工具吗"——很多时候这个 probe 是能给出对的答案的。也就是说,模型 hidden state 里其实"知道"自己该调工具,但生成 token 的那一刻,这个信号没有传到决策上。
这就是这篇 NeurIPS 2026 投稿的核心发现:LLM 工具调用里有一个 知行差距。不是不知道,是知道了不去做。
论文信息
- 标题:Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
- 作者:Yize Cheng, Chenrui Fan, Mahdi JafariRaviz, Keivan Rezaei, Soheil Feizi
- 机构:马里兰大学
- arXiv:2605.14038(v1: 2026-05-13, v2: 2026-05-17)
- 链接:https://arxiv.org/abs/2605.14038
核心摘要
这篇论文做了三件事,每一件都挺有意思。
第一,重新定义"工具必要性"。之前的工作(MetaTool、SMART 这些)都是让人或者强模型给一道题打标签——"这题需要工具" 或 "不需要工具"。问题在于,这种标签是 model-agnostic 的,它假设工具必要性是题目本身的属性。但论文指出这个假设站不住脚:同一道题,GPT 级别的模型脑子里直接算就行,3B 小模型可能必须挂计算器。工具必要性应该是模型相关的。具体做法是:对每个模型,把题目跑 10 次(温度 0.7),10 次都做对就算"不需要工具",有一次错就算"需要工具"。
第二,把工具调用拆成 认知(cognition)和 执行(execution)两个阶段,并在 4 个模型、2 个数据集上量化两阶段的失配。结论是:算术题上必要性与行为的失配率达到 26.5% 到 54.0%,事实问答上是 30.8% 到 41.8%。这数字真的不小。
第三,用线性 probe 去解析 hidden state,发现 必要性方向 \(\mathbf{w}_c\) 和 行动方向 \(\mathbf{w}_a\) 在驱动下一个 token 生成的关键位置(最后一个 query token、靠后的层)几乎正交。再通过桑基图追踪每个样本的轨迹,定位到大部分错误集中在认知到行动的转换环节,而不是认知本身。
我读完的判断:这篇论文最值钱的地方不是定义新框架,而是把"模型为什么调错工具"这个工程问题,从"模型不知道自己几斤几两"的 meta-cognition 假说,重新归因到了"它其实知道,但生成层把信号丢了"。如果这个结论站得住脚,意味着 改进 RAG/Agent 工具调用,靠教模型更准地评估自己能力是治不了根的,得在 readout 这一层动手。
下面把这个故事讲细一点。
为什么模型无关的"工具必要性"是个伪问题
先聊一下背景。LLM Agent 这两年一个核心命题是 adaptive tool use:模型自己决定什么时候直接答、什么时候调外部工具。这事最早 Toolformer 那波就开始做,后来 MetaTool、SMART、ASA 一系列工作专门测模型的"自我感知能力"——它知不知道自己什么时候该求助。
这些工作有一个共同的隐含假设:工具必要性是题目的内禀属性。一道题"今天北京天气怎么样"显然要查 API,"把这段话改写得更正式"显然不用。然后让人类或者 GPT-4 当 judge 去标这些标签,再去测模型行为是否对得上。
这个范式有两个很硬的问题。
第一,它只能覆盖 明显 的两端。中间地带——比如 "23 × 47 等于多少"——对 GPT-4 来说脑子里就算了,对 Llama-3.2-3B 来说真的容易翻车。你给这道题打什么标签都不对。打成"需要工具",强模型根本不需要;打成"不需要",弱模型直接幻觉。
第二,它把"模型是否真的需要工具"和"裁判模型是否觉得它需要工具"混在了一起。论文里有句话挺刻薄的:之前的范式 "reflects the capacity of the judge rather than the tested model",反映的是裁判的能力上限,不是被测模型的。
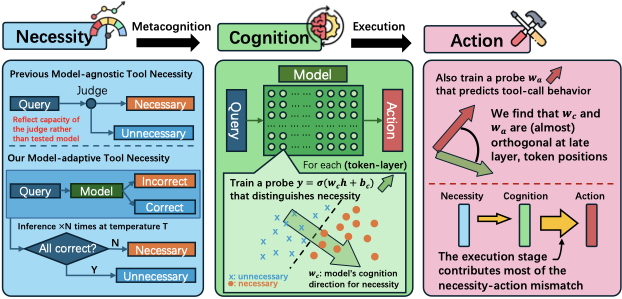
图1:左上是传统的 model-agnostic 范式——judge 给一个固定标签;左下是论文提出的 model-adaptive 范式——把题目拿到模型上跑 N 次,全对就标"不需要",否则标"需要"。中间是用线性 probe 在每一(token, layer)位置抓 cognition 方向 \(\mathbf{w}_c\)。右边是关键发现:训另一个 probe \(\mathbf{w}_a\) 抓 action 方向,发现两个方向在 late layer/last token 几乎正交,执行阶段贡献了大部分必要性与行动的失配。
论文的处理办法很朴素也很对:对每个模型 \(f\),独立跑 \(N=10\) 次推理,温度 0.7,不给工具。如果 10 次都做对,那这道题就在这个模型的"能力边界"内,标 \(n_f(x)=0\);只要有一次错,就标 \(n_f(x)=1\)。注意这里的细节:有一次错就算需要工具,这是个相当严的标准,背后的考量是"实际部署里偶尔做对不算可靠"。
这个定义带来的直接后果是,同一道题在不同模型上的标签会不一样。
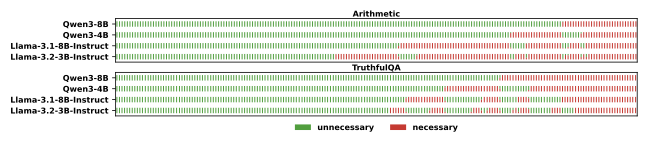
图2:横坐标是题目,按 Qwen3-8B 的能力排序(所以第一行红绿分得最干净)。下面三行是其他三个模型在同样题目集上的 necessary/unnecessary 划分。绿色是 unnecessary,红色是 necessary。可以看到三个模型的红绿分布完全不同——这就是 model-adaptive 的实证依据,同一道题对不同模型可以是完全不同的工具必要性标签。
这个图我盯着看了一会,第一反应是"好朴素好有说服力"。它把 model-agnostic 范式的根基直接砸了:如果同样题目在不同模型上分类完全不同,那拿一个统一标签去测所有模型,其实是在测模型和 judge 的拟合度,不是模型对自己能力的认知。
26.5% 到 54.0%:失配的规模到底有多大
定义清楚之后,作者在 4 个模型上做了实验:Qwen3-8B、Qwen3-4B、Llama-3.1-8B-Instruct、Llama-3.2-3B-Instruct。两个数据集:自建的 4000 题算术数据集(覆盖从一两步加减到多位数乘法、模运算、嵌套括号等),以及 TruthfulQA(817 题,挂 search API)。
把每个样本按 model-adaptive 必要性 \(n_f(x)\) 和模型实际是否调工具,分成 4 类:
- N-C(Necessary-Called):该调,也调了。对的。
- UN-NC(Unnecessary-NotCalled):不该调,没调。也对的。
- N-NC(Necessary-NotCalled):该调没调,工具 underuse。错的。
- UN-C(Unnecessary-Called):不该调却调了,工具 overuse。错的。
后两类加起来就是 end-to-end 失配。结果在下面这张表里:
| 模型 | 算术 N-C | 算术 N-NC | 算术 UN-C | 算术 UN-NC | 算术失配 | TQA N-C | TQA N-NC | TQA UN-C | TQA UN-NC | TQA 失配 |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-8B | 11.0% | 3.5% | 38.2% | 47.4% | 41.7 | 8.4% | 17.9% | 13.2% | 60.5% | 31.1 |
| Qwen3-4B | 6.3% | 14.5% | 12.0% | 67.1% | 26.5 | 12.6% | 18.7% | 23.1% | 45.5% | 41.8 |
| Llama-3.1-8B-Inst | 10.5% | 30.1% | 8.4% | 51.1% | 38.5 | 12.0% | 15.9% | 14.9% | 57.2% | 30.8 |
| Llama-3.2-3B-Inst | 13.2% | 39.0% | 15.0% | 32.9% | 54.0 | 7.1% | 20.1% | 12.7% | 60.1% | 32.8 |
(最后两列"失配"的单位为百分比)
几个观察。
失配规模本身够吓人。最低的 26.5%,最高的 54.0%,平均下来大概三到四成的工具调用决策是错的。如果你把这套模型直接部署成 Agent,意味着每三次用户提问就有一次工具用错——要么白调一次浪费 latency 和 token,要么该调没调直接幻觉。
过度调用 vs 调用不足,在不同模型不同任务上完全不一致。Qwen3-8B 在算术上是典型的 over-use(UN-C 38.2% 远高于 N-NC 3.5%),但同一个模型到了 TruthfulQA 上反过来变成 under-use。Qwen3-4B 也是类似的反转。Llama 两个模型在算术上都是严重的 under-use,3B 那个 N-NC 直接干到 39%——题目它自己做不对,工具放在面前也不调,硬着头皮直接答。
这种行为反复横跳的现象,作者的解读我比较认同:没有一个统一的偏置能解释这些 mismatch。不是所有模型都过度调用,也不是所有模型都不爱调用。每个模型在每个域上的 failure mode 都不一样,这就排除了"调一调 system prompt 就能解决"这种简单方案的可能性。
到这一步,问题已经很清楚了:为什么模型决策错得这么离谱?是它真的不知道自己几斤几两(认知错),还是它知道但是没去做(执行错)?
Probing:让 hidden state 自己开口说话
要回答上面这个问题,得能 分别看到 cognition 和 action 这两个阶段。论文用的工具是经典的线性 probing。
具体做法:对每个 (token position, layer) 位置 \((t, l)\),把模型在该位置的 hidden state \(h_t^{(l)}\) 拿出来,训一个线性分类器 \((\mathbf{w}_c, b_c)\):
label 是 model-adaptive 必要性 \(n_f(x)\)。\(\mathbf{w}_c\) 就是从"不需要工具"到"需要工具"的方向向量。然后再训一个一模一样的 probe,但 label 换成模型实际的 action(调还是不调),得到 \(\mathbf{w}_a\)。
因为类别不平衡,评估指标用 MCC(Matthews 相关系数)而不是 F1。MCC 大于 0.4 算中等以上效果。
扫遍所有 (token, layer) 位置,得到两张热力图。这里直接讲三个核心发现。
发现一:必要性可分性是任务相关的。在算术上,4 个模型的中后期 layer 都有大片 MCC > 0.4 的区域,说明 hidden state 里确实编码了"这道题超出我能力了"的信号。但到了 TruthfulQA,MCC > 0.4 的区域就明显变小,只有 Llama 系列在最后几个 token、中后层还能看到一些可分性。作者的解释是:算术题的难度直接体现在表面结构上(多位数、多括号、长链式),所以"难不难"信号比较容易在表征里建立。开放域事实问答就不一样了,"美国第三任总统是谁"和"日本第三十二任首相是谁"表面看起来差不多难,但模型对前者熟、对后者陌生,这种 epistemic uncertainty 不在表面结构上。
发现二:行动信号在哪里都很清楚。把 label 换成实际 action 重新训 probe,热力图几乎全亮——MCC > 0.4 的区域覆盖大部分 (token, layer) 位置。也就是说,模型马上要做什么动作,从 hidden state 里几乎随便哪一层都能读出来。这个其实和最近 "I am, therefore I think" 那篇的发现是一致的,action 在 transformer 内部是高度冗余编码的。
发现三:必要性方向和行动方向,在生成的临门一脚是正交的。这是论文最关键的一张图。
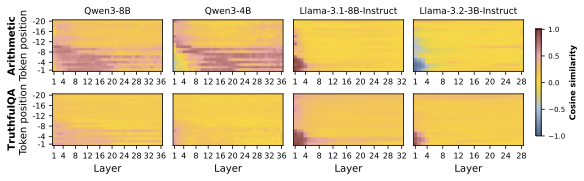
图3:每个格子是某个 (token, layer) 位置上 \(\mathbf{w}_c\) 和 \(\mathbf{w}_a\) 的余弦相似度。颜色越红越接近 1(同向),越蓝越接近 -1(反向),黄色接近 0(正交)。注意右下角——也就是最后一个 query token、最后几层——几乎全是黄色。这正是决定下一个生成 token 的关键位置。
这张图我看的时候在脑子里反复确认:最后一个 query token 的 late layer,正是 LM head 读取并决定下一个 token 的位置。如果在这里 \(\mathbf{w}_c\) 和 \(\mathbf{w}_a\) 是同向(cosine 接近 1),意味着"该不该调工具"的认知会被直接读成"调还是不调"的动作,模型表现就应该一致。如果是正交(cosine 接近 0),就意味着即使中间层把"我能力不够"的信号编码得很清楚,这个信号也没有进入决定下一个 token 的子空间。
更微妙的是,Qwen3-8B 和 Qwen3-4B 在 中间层 还能看到一些红色——也就是 cognition 和 action 在中间层是有部分耦合的。但耦合到了最后一层就崩了。论文用的词是 "alignment collapses at the position that drives generation"。我觉得这个说法挺贴切的:模型脑子里那个对的信号没传到嘴边。
桑基图:把错误归因到具体阶段
光知道两个方向正交还不够,得回答 哪个阶段贡献了大部分错误。论文用了一个我觉得相当聪明的可视化——桑基图(Sankey diagram)。
每个样本沿 \(x \to z_f(x) \to a_f\) 的路径走一遍,最后落到 4 类之一:
- 绿色:两阶段都对
- 红色:只有 stage 1(cognition)错
- 橙色:只有 stage 2(execution)错——这就是 knowing-doing gap
- 紫色:两阶段都错但相互抵消(错错得对)
这里 cognition 是用 last query token、last layer 的 necessity probe 读出来的——故意选这个位置,是因为它和驱动下一个 token 的位置是同一个。
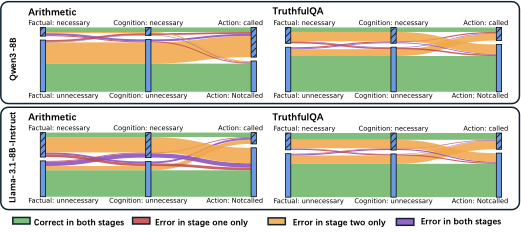
图4:每个面板从左到右三列分别是 Factual(实际必要性)、Cognition(probe 读出的内部认知)、Action(实际行动)。绿色流是两阶段都对,红色是 stage 1 only error,橙色是 stage 2 only error(knowing-doing gap),紫色是两阶段都错。橙色流明显比红色粗——这就是核心发现:错主要错在执行阶段。
四个面板里,橙色的"只有 execution 错"流量都比红色"只有 cognition 错"明显宽得多。Qwen3-8B 和 Llama-3.1-8B-Instruct 上这个差距非常显眼,橙色甚至接近绿色的宽度。
这个结论的含义其实挺颠覆的:模型 hidden state 里的"我该不该调工具"判断大部分时候是对的,错主要错在没把这个判断转换成正确的 action。
这一下就把过去几年大家做的事情打了个问号。MetaTool、ASA、SMART 这一类工作,核心都是想提升模型的 self-awareness/meta-cognition——让它更准地知道自己几斤几两。但如果 cognition 已经基本对了、错主要错在 execution,那继续在 cognition 上加训练数据收益有限。
这不是 confidence 不够:一个挺扎心的额外发现
读到这里你可能会想:会不会是橙色那部分样本里,cognition probe 给出的判断本身就 不太确定——比如 sigmoid 输出在 0.5 附近徘徊?如果是的话,那其实还是 cognition 不够强的问题,只是表现形式从"判错"变成"判得不自信"。
作者也想到了这个反驳,专门做了一张密度图。
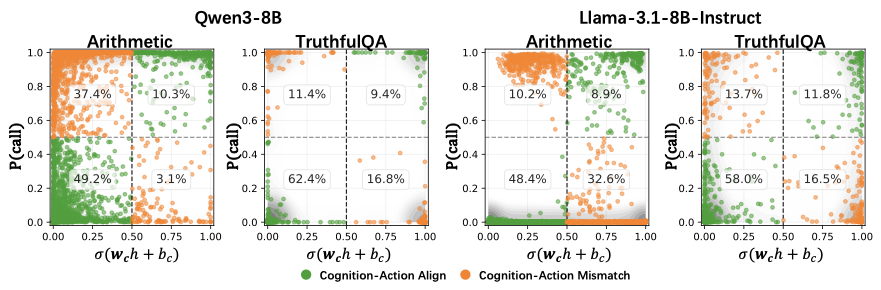
图5:橙色点是 cognition-action mismatch 的样本,绿色点是 align 的。如果 mismatch 是因为 cognition 不确定,橙色点应该集中在 x ≈ 0.5 附近;但实际上橙色点大量分布在 x 接近 0 或 1 的两端区域。这意味着即使内部强烈表态"我需要工具"或"我不需要工具",最终的 action 还是可能反过来。
数字很直白。Qwen3-8B 在算术上,左上角(cognition 说"不需要工具"但 P(call) > 0.5,也就是模型反而调了)占 37.4%;右下角(cognition 说"需要工具"但 P(call) < 0.5,模型不调)占 3.1%。Llama-3.1-8B-Instruct 在 TruthfulQA 上更对称,左上 13.7%,右下 11.8%。
这些 mismatch 样本里很大一部分都不在 0.5 附近的"犹豫区",而是在 0 或 1 附近的"我心里很清楚"区。
我看到这里愣了一下。这意味着 不是模型没拿定主意所以执行抽风,而是 它已经拿定主意了,但执行还是抽风。这个比"cognition 不准"严重多了,说明 cognition 和 execution 之间真的有一个机械层面的、和置信度无关的信道断裂。
P(call) 这里是个细节巧妙的定义:
它把 tool token 的 logit 和最强非 tool token 的 logit 做了归一化。这样不管词表多大,都能压到 [0,1] 区间,并且 P(call) > 0.5 等价于 greedy 解码会真正生成 tool token。这个定义比直接看 softmax 后的 tool token 概率更稳健,因为它过滤了词表大小的影响。
我的判断:哪些站得住,哪些可以再追问
读到这里,我得说几个我觉得这篇论文做得挺漂亮的点,以及几个我还有疑问的地方。
漂亮的地方:
第一,model-adaptive 必要性的定义朴素但对路。\(N=10\) 次全对算"不需要",是个很严的标准,但它把以前那种"judge 给一个固定标签"的范式打开了。我之前在做 RAG 系统调优的时候就碰到类似的纠结——同一个 query 让 GPT-4 来判该不该检索是一回事,让你部署的小模型自己来判是另一回事,因为它们的 capability boundary 完全不同。这篇论文相当于把这种工程直觉做成了可量化的实验。
第二,两阶段分解 + 桑基图归因。把 end-to-end 失配拆成 cognition 错和 execution 错两类,再用桑基图直观显示比例,这个分析框架很清爽。橙色流明显粗于红色流是个干净的实证结果,不靠任何 fancy 的统计推断。
第三,正交性这个发现。\(\mathbf{w}_c\) 和 \(\mathbf{w}_a\) 在 late layer/last token 几乎正交——这是个 mechanistic 层面的具体观察,比"模型 self-awareness 不够"这种含糊的归因要 actionable 得多。它直接指向了一个工程上可以干的方向:既然 action 方向 \(\mathbf{w}_a\) 在 hidden state 里非常容易读出来,那拿 cognition probe 当 trigger、用 activation steering 沿 \(\mathbf{w}_a\) 推一下,理论上就能强行修正 execution 错误。论文 abstract 里其实提了这个 inference-time intervention 的思路(用 activation steering),但正文这个版本把篇幅主要给了 diagnosis,干预实验留给了后续。
我的疑问:
第一,\(N=10\) 这个阈值的鲁棒性。这个标准不算松,模型只要 10 次错 1 次就算"需要工具"。如果换成 \(N=5\) 全对、或者 \(N=20\) 至少 18 次对,必要性标签会变多少?继而失配率会变多少?论文 appendix 应该有,但我读的这版正文只点了 N 和 T 越大越严这一条,没给敏感性分析。我担心如果阈值变化对结论冲击很大,那 26.5%-54.0% 这个数就有点取决于阈值本身。
第二,probe 的天然局限。线性 probe 能读出来不代表模型 internally 真的"知道",反过来读不出来也不代表它真的不知道。论文做了 4 个模型的扫描,结论看起来挺一致,但 probing 方法学上的争议(probe 能学到的信息和模型实际使用的信息不是一回事)依然存在。我觉得这是个该承认的边界。
第三,TruthfulQA 上的 cognition 可分性其实没那么强。论文自己也提了 TQA 上 MCC > 0.4 的区域比算术小很多。在 TQA 上说 cognition 已经"基本对了,只是没传到 action",这个论证强度比算术上要弱一些。如果 cognition 本身就读不太出来,那"execution 错占主导"的归因就要打折扣。
第四,只测了 4 个开源模型。Qwen3、Llama 这两个家族是开源主流,但 GPT-4o、Claude 这种闭源模型上是不是同样的故事,论文没法回答。这不是论文的锅(开源是 probing 的前提),但作为读者要意识到结论的外推边界。
工程启发:如果你也在做 Agent,这篇论文给到的启示
抛开学术贡献不谈,几个我觉得对工程实践有直接启发的点。
第一,end-to-end 工具调用准确率作为 metric 是有水分的。如果你只看"工具调用决策准确率"这一个数,27%-54% 的 misuse 会被一个聚合数字盖住。论文这种把样本拆成 4 类(N-C / N-NC / UN-C / UN-NC)的做法,应该成为评测 Agent 的标配——尤其是 N-NC 和 UN-C 反映的是完全不同的 failure mode,前者是"该求助不求助导致幻觉",后者是"瞎调工具浪费 latency",对产品的危害也不一样。
第二,model-adaptive 必要性可以拿来构造训练数据。如果你要用 RL 或 SFT 教模型 adaptive tool use,用 model-agnostic 标签会有大量噪声——强模型不需要工具的题目被标成"需要",反而会教模型 over-call。改用 \(n_f(x)\) 标签(每个模型对自己的题集跑 N 遍生成),训练信号会干净很多。
第三,knowing-doing gap 暗示了一种新的干预路径。既然 cognition 大体上是对的,那不需要 retrain 模型,只需要在推理时拿 cognition probe 读出"该调工具"的信号、然后用 activation steering 沿 \(\mathbf{w}_a\) 推一下生成层,理论上就能修复大部分 N-NC 错误。这种 inference-time、training-free 的干预方式,对线上系统调优来说成本很低。论文 abstract 里提到了这个方向但正文没展开,我猜后续版本应该会补。
第四,对 RAG 系统的启示。RAG 里一个核心问题是"什么时候检索、什么时候直接答",本质就是工具调用决策。如果这篇论文的结论可以迁移,那意味着调 RAG 的"检索触发器"不应该只盯 confidence 阈值(因为 mismatch 不集中在低 confidence 区),而要看 hidden state 上更结构化的信号。
最后
这篇论文给我的最大触动其实不是数字本身,而是它把"模型工具调用为什么调不对"这个看起来很表面的问题,挖到了 hidden state 几何结构这一层。从"模型不知道自己几斤几两"到"它其实知道,只是嘴边的子空间和脑子里的子空间正交",归因路径完全变了。
如果未来 Agent alignment 的主线真的从"提升 meta-cognition"转向"修复 cognition-to-action 通路",这篇论文应该会被回头当成一个转向点引用。
当然,正交性这个发现到底是结构性的还是训练 artifact,N=10 阈值的鲁棒性怎么样,闭源大模型上是不是同样的故事——这些问题都还得等更多工作。但作为一个把"知行差距"在 LLM 工具调用上具体化、量化、机械化的工作,我觉得已经做得很扎实了。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我
参考文献
- Cheng, Y., Fan, C., JafariRaviz, M., Rezaei, K., & Feizi, S. (2026). Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use. arXiv:2605.14038.
- Huang, Y., et al. (2024). MetaTool Benchmark for Large Language Model.
- Qian, C., et al. (2025). SMART: Self-aware Agent for Tool Overuse Mitigation.
- Li, Y., et al. (2025). Adaptive Tool Use via Representation Probing.
- Zou, A., et al. (2025). Representation Engineering: A Top-Down Approach to AI Transparency.
- Yang, A., et al. (2025). Qwen3 Technical Report.
- Grattafiori, A., et al. (2024). The Llama 3 Herd of Models.
- Lin, S., et al. (2022). TruthfulQA: Measuring How Models Mimic Human Falsehoods.