让 Agent 先「想清楚再动手」:StraTA 给长程 Agent RL 加上一层策略抽象
核心摘要
做过长程 Agent 的人都知道一个让人头疼的现象:模型在第 3 步看起来还挺有计划,到第 8 步就开始反复横跳,明明刚翻过的页面又点了一次,明明已经决定买 A 了又突然去搜 B。问题不在模型不够聪明,问题在它每一步都在重新决定整盘棋怎么下——既要决策当前动作,又要隐式地维持长程一致性,纯反应式的 RL 训练根本撑不住这种双重负担。
StraTA 这篇论文给出的方案非常直白:让 Agent 在动手之前,先用一句自然语言把"这个 episode 我打算怎么打"写下来,然后把这条 strategy 作为前缀绑在每一步的输入里。配上一个分层的 GRPO rollout 设计——多条策略 × 每条策略多次执行——再加两个小 trick(最远点采样保多样性、self-judgment 给中间步打负分),就把长程信用分配和探索这两个老大难问题同时往前推了一截。
效果:1.5B 的 Qwen 在 ALFWorld 拿到 90.7%、WebShop 拿到 82.5%,7B 进一步到 93.1% 和 84.2%;最难的 SciWorld 上以 63.5% 反超 GPT-5.1、Claude-4-Sonnet 等闭源模型,Lifespan 子集甚至刷到 100%。一个偏工程整合的方案,但整合得很有品味,思路对工业界长程 Agent 训练几乎可以直接借鉴。
论文信息
- 标题:StraTA: Incentivizing Agentic Reinforcement Learning with Strategic Trajectory Abstraction
- 作者:Xiangyuan Xue, Yifan Zhou, Zidong Wang, Shengji Tang, Philip Torr, Wanli Ouyang, Lei Bai, Zhenfei Yin
- 机构:香港中文大学、上海人工智能实验室、佐治亚大学、牛津大学、深圳河套研究院
- 提交日期:2026 年 5 月 7 日
- arXiv:arXiv:2605.06642
- 代码:github.com/xxyQwQ/StraTA
一、为什么纯反应式 Agent 总在长程任务上翻车
先聊一个实际场景。WebShop 这种任务,一句话买东西,比如"买一个青铜色的镜子,预算 170 美元以内,要有壁挂功能"。模型要做的事很朴素:搜关键词、翻页、看候选、点详情、加约束、最后确认。听起来不难,但你跑一下 Qwen2.5-1.5B 直接 prompting,成功率只有 2.9%;就算加上 ReAct,也才 9.1%。
这不是模型笨,是这个决策结构本身就反人类。
每一步只看当前 state 直接出 action。问题是这个 state 里只有当前这一页的内容、之前几步的对话历史,模型既要决定下一步要点哪个按钮,又要在每一步都重新推断整体策略是什么。两个任务搅在一起,结果就是 Figure 1(a) 里那种典型情况:第一步搜索"bronze mirror",第二步看到一个 170 美元的,第三步又去翻别的,第四步突然 back 到上一页——人在旁边看都急。
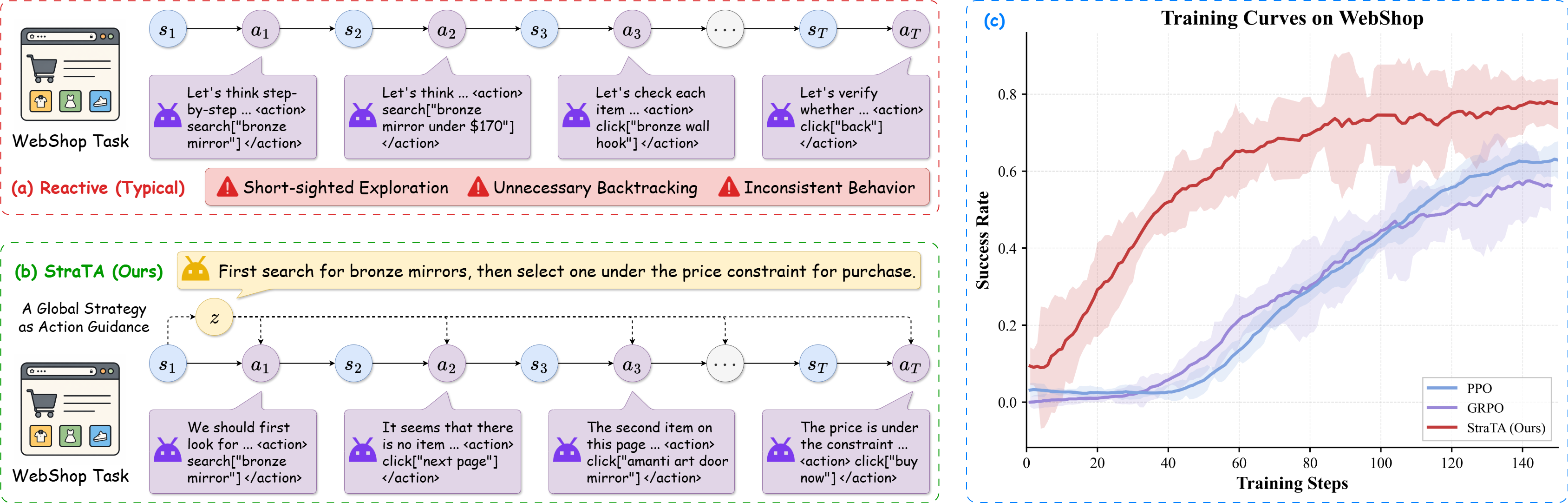
图 1:反应式 Agent vs. StraTA。右图是 WebShop 上的训练曲线,红色 StraTA 在 40 步左右就突破了 60% 成功率,PPO/GRPO 此时还在 10% 附近爬。这种 sample efficiency 的差距在长程任务里非常致命——多跑 100 步可能就是 8 张 H100 多烧一天的钱。(a) 反应式 Agent 每一步从局部状态生成动作,规划和执行同时进行,容易出现短视探索、不必要的回退和不一致的行为。(b) StraTA 先生成一条紧凑的全局策略,所有后续动作都基于该策略生成,行为更连贯一致。(c) 在长程 Agent 任务上,显式的策略指引明显改善学习效率和最终性能。
为什么这种"边走边想"的范式特别难训?两个原因,论文里讲得挺清楚:
长程探索难。每一步的状态空间是离散的、稀疏的,不同的开局策略会把后续轨迹带去完全不同的子空间。如果模型每一步只在局部贪心,它根本没机会真正"探索"过别的策略——它甚至不知道自己其实有不同策略可选。
信用分配难。环境只在 episode 结束时给一个 outcome reward。中间 50 步动作里到底是哪几步立功了?哪几步是无效内耗?传统 GRPO 把 trajectory 级别的 reward 平摊到每一步 token,相当于一锅端,好的坏的一起赏一起罚。
之前学界其实有不少工作在啃这两块——ArCHer 做层级 critic、GiGPO 引入 anchor state 做更细的信用分配、AgentGym-RL 在框架层做了一波系统化。但这些方法都还是反应式的,没有人正经地把"trajectory-level strategy"作为一个一等公民放进 RL 框架里训。
StraTA 做的事,就是把这个缺失的抽象层级补上。
二、StraTA 怎么做:从"边走边想"到"先想后走"
2.1 核心改动只有一行
原来:a_t ~ π(· | s_t)
现在:z ~ π(· | s_1) # 在 episode 开头先生成策略 z
a_t ~ π(· | z, s_t) # 之后每一步都把 z 拼在 state 前面
就这么简单。\(z\) 是一句自然语言,比如 "First search for bronze mirrors, then select one under the price constraint for purchase."——一句话讲清楚整个 episode 准备怎么打。
这个 \(z\) 在开头采样一次就冻住,后续不再更新,每一步动作生成时都把它拼在状态前面。模型的负担一下子被拆成两块:(1) 生成一个好策略;(2) 老老实实按策略执行。
读到这我第一反应是:这不就是 ReAct 把 think 提前到 episode 开头嘛?想了一下,差别其实挺本质的:
- ReAct 是每一步都 think + act,think 是局部的、临时的,每步都重写
- StraTA 是一次性给出全局 strategy,然后整段轨迹都被这条 strategy 锚住,相当于显式地把 high-level plan 和 low-level execution 分层
更关键的是 ReAct 是 prompting 时代的产物,StraTA 是把这套结构真的拿去做 RL 训练——并且专门为这套结构设计了一套分层 rollout。这就是接下来要聊的核心。
2.2 分层 GRPO rollout:让策略和动作各自竞争
光是改 forward pass 没用,关键是怎么训。
StraTA 在 GRPO 之上搭了一个两层的 rollout 结构:
每个任务:先采样 \(N\) 条策略 \(\{z^i\}\),每条策略下再 rollout \(M\) 条轨迹 \(\{\tau^{i,j}\}\),一共 \(N \times M\) 条轨迹。
实验里 \(N=4, M=8\),所以每个任务跑 32 条 trajectory。
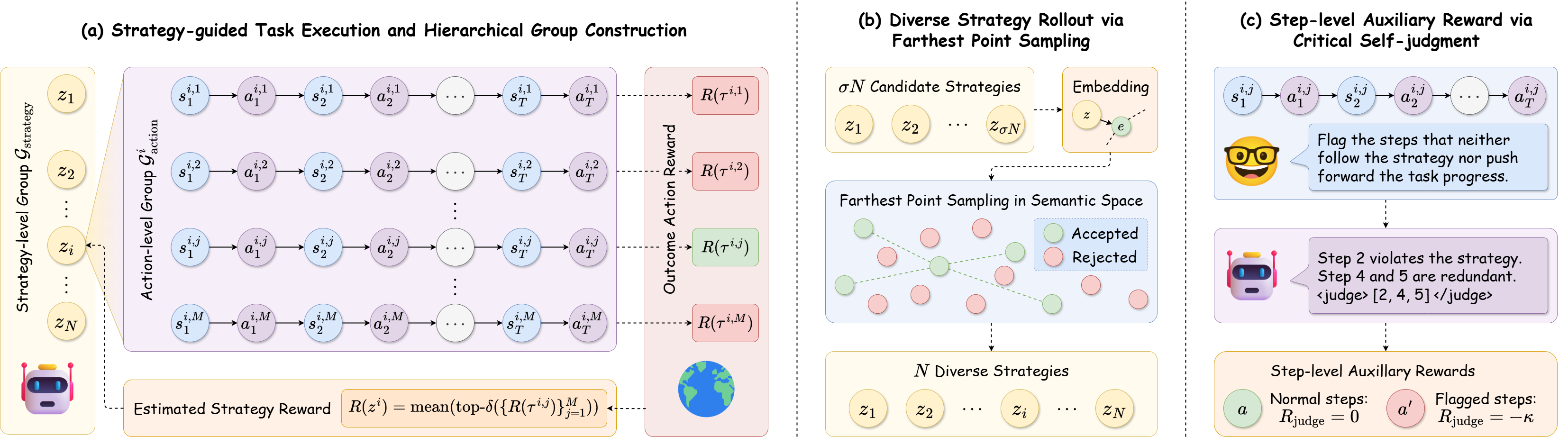
图 2:StraTA 三件套——分层 rollout 结构(左)、最远点采样保多样性(中)、self-judgment 给中间动作打负分(右)。这张图是这篇论文最值得反复看的一张。(a) 给定任务,StraTA 生成多个策略并为每个策略执行多次 rollout,构成层级化的 group 进行策略级和动作级优化。(b) 多样化策略 rollout 通过最远点采样在语义空间选取彼此差异最大的策略,提升策略空间的探索。(c) Critical self-judgment 识别那些既不遵循策略也不推动任务进展的动作步,赋予步级辅助惩罚以实现细粒度信用分配。
这套设计带来两类对比信号:
- 策略级对比:4 条不同的策略放在一个 group 里,分出哪条策略更靠谱
- 动作级对比:同一条策略下的 8 条 rollout 放在一个 group 里,分出在这条策略下哪些动作执行得更好
策略级 reward 是怎么算的?这里有个值得聊的细节:作者没有直接拿 8 条 rollout 的 outcome reward 做平均,而是取 top-\(\delta\) 部分的均值(\(\delta=0.5\) 时就是前 4 名的平均):
为什么?说实话我看到这里愣了一下,然后想明白了——这个设计很聪明。如果直接平均,策略 \(z^i\) 的得分会被早期训练阶段那些"动作还没学好"的低质量 rollout 严重拉低,导致策略本身的好坏被动作执行能力的噪声盖住了。取 top-\(\delta\),相当于让策略 reward 更接近"这条策略在最佳执行下能达到什么上限",是策略潜力而不是策略当前表现。
消融里 \(\delta\) 这一项的对比挺能说明问题:
| \(\delta\) | ALFWorld All | WebShop Score |
|---|---|---|
| 0.1 | 71.0 | 79.3 |
| 0.5 | 88.6 | 85.9 |
| 1.0 | 85.0 | 85.2 |
\(\delta=0.1\) 太极端只看最优一条,方差大不稳定;\(\delta=1.0\) 退化到普通平均,被噪声拖累;0.5 是甜点。这种参数选择能不能直接迁移到别的环境我不太确定,但这个 design choice 的方向是对的。
整个训练目标长这样:
策略和动作共享同一套参数 \(\theta\),两个 loss 加在一起,advantage 都用 GRPO 的 group-normalized 计算方式。整套训练完全兼容已有 GRPO codebase,迁移成本极低。
2.3 多样性问题:温度采样不够,要上最远点采样
这里是一个非常实在的工程发现。
直觉上你会说:4 条策略,把 temperature 调高一点不就有多样性了吗?作者试了,不行。LLM 在同一个 prompt 下即使开 T=1.2,生成的 4 条策略也常常是"语义上几乎重复"——可能就是换几个词的事。
这就坏了 GRPO 的核心机制。GRPO 的学习信号来自 group 内的相对比较,如果 4 条策略说到底是同一个意思,比较出来的 advantage 就没什么信息量。
StraTA 的做法是先过采样再筛选:先 sample \(\sigma \times N\) 条候选策略(实验里 \(\sigma=8\),所以采 32 条),然后用一个预训练的 sentence embedding 模型把每条策略编码成向量,最后在语义空间做最远点采样(FPS)选出 4 条彼此差异最大的策略:
每轮选一个:在还没选的候选里,找一个与已选集合最相似度最低的——也就是离已选集合最远的。这种贪心策略在 3D 点云里早就用滥了,没想到搬到 LLM 策略空间挺合适。
消融数据:
| \(\sigma\) | ALFWorld All | WebShop Score |
|---|---|---|
| 1 (无 FPS) | 81.9 | 79.3 |
| 2 | 83.1 | 73.9 |
| 4 | 83.1 | 77.9 |
| 8 | 88.6 | 85.9 |
\(\sigma=1\) 等价于不用 FPS,直接采 4 条;提到 8 倍过采样后涨 6.7 个点。计算开销呢?虽然过采样多生成 28 条,但策略生成只发生在 episode 开头,相对于后面几十步的动作 rollout 来说成本很小(论文里给了估算,约占总开销的 \(1/H\))。
2.4 Critical Self-Judgment:让模型自己当 critic 给中间步打分
第二个 trick 解决的是信用分配。
GRPO 的标准做法是把 trajectory-level outcome reward 广播到所有动作步:
这个简单粗暴的做法有个明显问题——奖励了"恰好成功"的轨迹里所有动作,包括那些其实是无效内耗、机会主义、与策略毫无关系的动作。模型可能学到"哎,我上次胡乱试了几下结果运气好成功了,那这几下乱试也是好动作"。
StraTA 的做法是让 Agent 在 rollout 完成后回过头自己审视一遍:
Prompt:你刚才的策略是 \(z\),这是你执行的轨迹 \(\tau\),请把那些既不符合策略、也没有推进任务进展的步骤标出来。
被标出的步骤集合记为 \(\mathcal{I}^{i,j}\),这些步骤会在原来的 reward 基础上扣一个 \(\kappa\) 的惩罚(实验里 \(\kappa=0.1\)):
这里有几个值得注意的设计选择:
- 判断由 agent 自己做,不引入额外的 judge 模型——既避免了 reward hacking 的额外攻击面,又省了 inference 资源
- judging step 本身不接收 reward——避免模型学会"通过故意写差的判断来获取额外信号"这种漏洞
- 只惩罚不奖励——只对明显的"垃圾步"扣分,不试图给"好的中间步"打正分。这个设计很谨慎,因为正向打分容易引入偏差,负向只是过滤明显的噪声
\(\kappa=0.1\) 这个值也挺值得品的。从消融里看:
| \(\kappa\) | ALFWorld All | WebShop Score |
|---|---|---|
| 0.01 | 84.5 | 81.0 |
| 0.1 | 88.6 | 85.9 |
| 1.0 | 87.1 | 78.9 |
太小(0.01)相当于没用;太大(1.0)反而把 WebShop 拖下来 7 个点——惩罚太重会让模型变得过于保守,不敢做探索性动作。0.1 是平衡点。
说实话,self-judgment 这个套路在 RLHF 时代已经被玩烂了(self-rewarding 那一系列),但用在 agentic RL 里做中间步信用分配而不是整体 reward modeling,倒是个不错的角度。
三、实验:好看的数字背后值得多看几眼
3.1 主表:1.5B 打过 GiGPO,7B 直接做掉所有闭源模型
ALFWorld + WebShop 上的主结果(节选关键行):
| 方法 | 模型 | ALFWorld All | WebShop Score | WebShop Succ |
|---|---|---|---|---|
| Claude-4-Sonnet | Closed | 72.9 | 23.7 | 18.4 |
| GPT-5.1 | Closed | 55.7 | 31.2 | 22.2 |
| GiGPO | 1.5B | 86.7 | 83.1 | 65.0 |
| StraTA | 1.5B | 90.7 | 91.1 | 82.5 |
| GiGPO | 7B | 90.8 | 84.4 | 72.8 |
| StraTA | 7B | 93.1 | 91.2 | 84.2 |
几个我觉得值得多看一眼的点:
1.5B 模型把 7B 闭源模型拉下马。Claude-4-Sonnet 在 ALFWorld 拿到 72.9%,StraTA 1.5B 拿到 90.7%——一个开源 1.5B 能在长程任务上反超顶级闭源模型 18 个点,背后真正的功臣不是"我们的 1.5B 比 Claude 强",而是"针对长程任务的专门 RL 训练 vs 通用 prompting"。这个 gap 其实是闭源模型在 specialized agent 任务上的固有短板。
WebShop 的提升幅度比 ALFWorld 大得多。1.5B 上 WebShop succ 从 GiGPO 的 65.0% 涨到 82.5%,足足 17.5 个点。我猜原因是 ALFWorld 已经是个被刷得很高的榜(GiGPO 已经 86.7%),上限有限;而 WebShop 的搜索-比较-决策结构更需要"全局策略"——你必须先想好"先搜哪个关键词、找到候选后怎么过滤"才能高效完成。这正是 StraTA 最适合发挥的场景。
SciWorld 上反超闭源模型:
| 方法 | Measure | Test-Cond | Find | Chem-Mix | Lifespan | All |
|---|---|---|---|---|---|---|
| GPT-5.1 | 32.1 | 46.5 | 41.8 | 69.6 | 38.3 | 43.0 |
| Claude-4-Sonnet | 45.4 | 54.7 | 60.3 | 45.6 | 90.0 | 57.4 |
| ScalingInter (7B) | 34.0 | 55.4 | 88.6 | 0.0 | 73.3 | 57.0 |
| StraTA (7B) | 55.7 | 54.4 | 78.6 | 16.3 | 100.0 | 63.5 |
SciWorld 的 Lifespan 子集 100% 这个数字看着确实漂亮,但要警觉一点:Lifespan 任务的本质是"判断生物的寿命阶段",本身可能存在题目空间小、答案模式固定的问题。我倾向于把它看作"好的策略让模型不会跑偏"的证明,而不是"模型变聪明了"的证明。
更值得看的是 Chem-Mix 这个子集——所有 RL 方法(PPO、GRPO、ScalingInter)都拿了 0 或个位数,StraTA 拿到 16.3%。这是一个非常硬核的化学实验任务,长程依赖很强,零分基本意味着 RL 训练完全没学到东西。StraTA 是第一个在这个子集上拿到非平凡分数的方法。
不过 Chem-Mix 的 16.3% 客观说也还远没到能用的程度,作者在 conclusion 里也承认了"strategy 一旦固定就难以适应环境的剧烈变化"——这正是 SciWorld 这种科学实验任务的核心难点。
3.2 消融:两个组件几乎是正交贡献
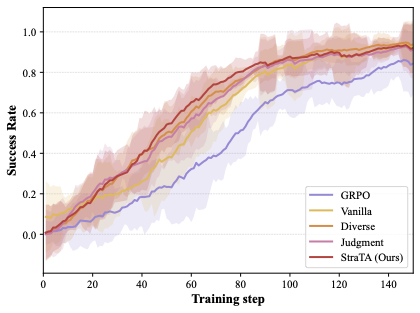
图 3:消融训练曲线。GRPO baseline(紫色)一直是最低,Vanilla(仅分层 rollout,黄色)已经显著超过 GRPO,加入 Diverse(橙色)让收敛速度变快但终点没明显提升,加入 Judgment(粉色)让终点提升明显但前期不快,全套 StraTA(红色)兼具两者优势。
| Variant | ALFWorld All | WebShop Score |
|---|---|---|
| GRPO baseline | ~75.5 | ~80.0 |
| Vanilla (仅分层 rollout) | 79.0 | 76.0 |
| + Diverse | 87.9 (+8.9) | 75.9 (-0.1) |
| + Judgment | 81.9 (+2.9) | 79.3 (+3.3) |
| Full StraTA | 88.6 (+9.6) | 85.9 (+9.9) |
这张消融数据挺有意思——Diverse 主要帮 ALFWorld,Judgment 主要帮 WebShop。
为什么?我的猜测是:ALFWorld 是 embodied 任务,环境状态空间相对小但策略多样性很关键("先去厨房 vs 先去客厅"差很多),所以 FPS 帮助大;WebShop 的策略空间本身比较收敛(无非就是搜-筛-买),但中间动作的冗余度很高(无效翻页、重复点击),所以 self-judgment 帮助大。
两个组件几乎是正交的——这种"加哪个都涨、加在一起涨更多"的消融,比那种"组件之间互相打架"的消融舒服多了。
3.3 计算开销:意外地便宜
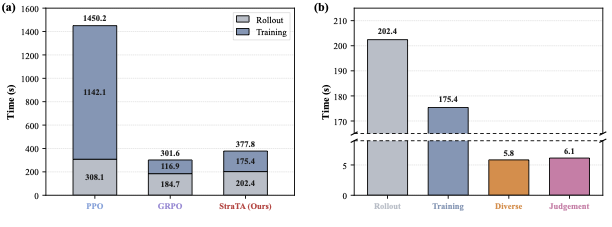
图 4:性能开销。PPO 每步 1450 秒(包含 critic 训练开销),GRPO 302 秒,StraTA 378 秒——只比 GRPO 多 25%,远低于 PPO。其中 Diverse 5.8 秒、Judgment 6.1 秒,几乎可忽略。
这张图是 StraTA 的另一个隐藏卖点。我之前看到分层 rollout(\(N \times M\))这种设计,第一反应是"算力得贵成什么样"。结果作者解释得很到位:相对于带 critic 网络的 PPO(1450s),StraTA(378s)反而便宜 4 倍,因为 GRPO 系列方法本来就不需要 critic。而相对于 group size 同样为 32 的标准 GRPO,StraTA 的额外开销主要是策略生成(开头一次)和 self-judgment(结尾一次),相对于动辄几十步的 trajectory 占比很小。
这个 "expensive in design, cheap in compute" 的特性,对工业界落地是非常友好的。
四、我的判断:方法很简单但很扎实,工业落地几乎可以直接抄
这篇论文最值得借鉴的几个点
1. "策略 + 执行"分层这个抽象本身就是个朴素但被忽视的设计。坦率讲,这种 high-level/low-level 分层在传统 hierarchical RL 里是常识,但在 LLM agent RL 里大家不知怎么都默认用纯反应式。StraTA 把它显式化、结构化,并且证明了这种结构能直接被 GRPO 吃下去——这种"把熟悉的旧 idea 用对地方"的工作,往往比花哨的新算法更有价值。
2. Top-\(\delta\) 策略 reward 这个 trick 是我个人最欣赏的 design choice。它解决了一个很实际的问题——策略潜力 vs 策略当前表现的混淆——而做法极其轻量。如果你在做任何"先决策再执行"的 RL 训练,这个想法都值得借鉴。
3. 最远点采样保策略多样性 是个非常工程化的解法。LLM 采样多样性不足是老问题了,平时大家是靠调温度、加 nucleus sampling 这种参数级方案。StraTA 在 embedding 空间显式做 FPS,相当于把多样性问题从"概率分布的尾部"搬到了"语义空间的覆盖度",思路明显更直接。
4. self-judgment 只惩罚不奖励 这个保守设计,避免了正向 reward hacking。我之前在做 RLHF 的项目里遇到过类似坑——加了 step-level positive reward 后模型学会刷分,最后整体表现反而下降。这里的负向设计是一个"防御性优雅"。
一些我觉得需要打问号的地方
策略一旦冻结就不能改这个限制。作者自己也承认,对环境剧烈变化的任务(比如游戏里突然出现新元素)这个设计会变得很僵硬。我在想,如果在 episode 中段加一个 "strategy revision" 的机制——比如允许 agent 每隔 K 步重新评估一次策略——会不会能进一步提升?这是个挺自然的扩展方向。
自我判断的可靠性问题。论文用的 backbone 是 Qwen2.5-1.5B/7B,self-judgment 也是这个模型自己做。1.5B 的模型真的有能力可靠地判断"这一步是否符合策略"吗?我对这点保留怀疑。如果 self-judgment 本身有较多噪声,那 \(\kappa=0.1\) 的小权重设计其实也是在间接承认这一点——只敢轻微地用这个信号。如果换成更大模型甚至 GPT-4 当 judge,效果会不会更好?论文里没有这块对比,是个遗憾。
SciWorld 上和闭源模型的对比有点取巧。GPT-5.1 用的是裸 prompting,从来没见过 SciWorld 的 demonstration;StraTA 是在 SciWorld 上专门训过的。这个对比说明的是"专门训练 vs 通用能力"的差距,不是"模型本身的能力高低"。文章里"outperforming frontier closed-source models" 这个 framing 我觉得有点过——更准确的说法应该是"专门训练的小模型可以在 specialized 任务上超过通用大模型",这是个常识,不算 StraTA 独有的功劳。
和最近的层级 RL 工作的对比缺失。论文 related work 里提到了 ArCHer、HiPer、HiERarchy 等做层级信用分配的工作,但实验里没有任何直接对比。GiGPO 已经是相对 close 的对比基线,但更晚的层级方法没出现。我猜可能是同期工作来不及,但如果要让这篇论文在 reviewer 眼里更稳,加几个层级 baseline 的对比会更扎实。
工程启发:如果你也在训长程 Agent
如果你正在做 LLM agent RL,无论是 web 操作、code agent 还是 tool use,几个可以直接拿走的东西:
- 把 trajectory-level strategy 显式化:在 episode 开头让模型生成一个 plan,后续每步把 plan 拼在前面。这个改造一两行代码就能搞定,但收益可能很大。
- 分层 rollout 是免费午餐:在 GRPO 框架下,把 group 拆成 strategy-level group + action-level group,几乎不增加成本但能让两个层级的优化都拿到信号。
- 多样性别只靠温度:如果你做 group-based RL 而 group 内多样性不够,先试 oversample + FPS,不行再想别的。
- 中间步信用分配先做减法:与其费劲设计 process reward model,不如先用 self-judgment 过滤明显的垃圾步,效果可能就够了。
五、收尾
长程 Agent 的 RL 训练这两年是显学,从 ArCHer 开始大家都在啃信用分配和探索这两个老大难。StraTA 这篇没有发明什么花哨的新东西,但把"策略-执行"分层这个朴素的人类经验显式化,并且配上了一套能让 GRPO 吃下去的训练结构——这种把熟悉的 idea 用对地方的工作,往往比追求新颖的工作更有持久影响力。
我个人的判断:这套思路有相当大概率会成为未来 long-horizon agent RL 的默认设计之一。"先想后做"这件事在人类身上是常识,在 agent RL 里被忽视了这么久才被正经端上桌——某种程度上也反映了这个领域目前还有很多"显而易见但没人做"的低垂果实。
至于"先想后做"够不够支撑下一代 agent?显然不够。Agent 还需要在执行过程中调整策略、需要反思和重启、需要在不确定环境下做风险评估。但 StraTA 至少把第一步走稳了——把 strategy 从隐式变成显式,从此之后 strategy 才能真正被讨论、被优化、被改进。
值得花半小时认真读一遍。
参考资料
- 论文原文:arXiv:2605.06642
- 代码仓库:github.com/xxyQwQ/StraTA
- 相关基线:GiGPO (arxiv.org/abs/2505.10978)、AgentGym-RL、GRPO (DeepSeek-Math)
- 评测环境:ALFWorld、WebShop、SciWorld
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我