SEIF:让模型自己出题考自己——指令跟随能力的自演化训练
核心摘要
我最近一直在思考一个问题:指令跟随(Instruction Following)能力到底要怎么持续提升?
数学和代码任务有 ground truth,可以做 self-evolve——模型自己出题、自己解、用 verifier 判分,闭环跑起来。但指令跟随是开放任务啊,没有标准答案,过去的训练 paradigm 要么靠人工标注、靠 GPT-4 之类的强 teacher(贵 + 不可持续),要么靠 self-play(但 instruction 难度是静态的,模型涨上来后再训练就没收益了)。
这篇 SEIF 给出了一个挺干净的解法。四个角色形成闭环:Instructor 出越来越难的指令,Filter 剔除矛盾/无效指令保数据质量,Follower 学着跟随这些演化的指令,Judger 在 constraint level 上提供 reward。Instructor 和 Follower 交替训练 + 共同演化——Instructor 用 reverse reward(指令越让当前 Follower答不对越好)变着花样难为 Follower,Follower 用正向 reward 学着满足越来越复杂的约束。
实验在 5 个不同规模的模型上跑(1.5B 到 14B),3 轮迭代后六个指令跟随 benchmark 上平均提升 2-5 个点,IFEval Pr.(L) 在 Qwen2.5-7B 上从 73.9 涨到 78.6。代码开源在 GitHub。
读完我觉得这篇最有意思的不是技术细节,而是把"对抗式 self-evolve"这个思路第一次干净地落在 instruction following 上——Instructor 想方设法出难题、Follower 想方设法答对,两个角色拉扯,谁也不依赖外部 teacher。这套范式如果成立,未来 open-ended task 的 post-training 可能要重新洗牌。
论文信息
- 标题:SEIF: Self-Evolving Reinforcement Learning for Instruction Following
- 作者:Qingyu Ren, Qianyu He, Jiajie Zhu, Xingzhou Chen, Jingwen Chang, Zeye Sun, Han Xia, Fei Yu, Jiaqing Liang, Yanghua Xiao
- 机构:复旦大学、蚂蚁集团
- arXiv:https://arxiv.org/abs/2605.07465
- 代码:https://github.com/Rainier-rq1/SEIF
为什么 instruction following 这个能力涨不动了?
我先讲讲这个问题的背景。
指令跟随这事看起来简单——让模型按你说的做。但当 instruction 包含多个约束的时候就难了。比如 "用 200 字写一篇文章,包含三个段落,每段第一个字必须是A/B/C,且不能出现'然而'这个词"——这种 multi-constraint instruction 是真实 user 场景里常见的,但很多模型直接歇菜。
行业里现在主流的训练方法有几种:
Paradigm 1:靠强 teacher。让 GPT-4 或 Claude 生成大量 instruction,用 distillation 或者 SFT 让小模型学。问题很明显——成本高、不可持续,而且上限被 teacher 卡死
Paradigm 2:Self-play 静态难度。模型生成 instruction、自己 follow、自己 judge。但难度是固定的——seed instruction 来自一个静态 pool,模型涨上来之后再训就没什么收益了
Paradigm 3:Self-evolve(这篇的思路)。让指令的难度随着模型能力一起演化。模型越强,指令也越难,永远在能力边界上训练

图1:第一行是 External-supervision 方法(依赖人或更强模型给反馈),第二行是 Previous Self-Play 方法(用静态难度 instruction),第三行是 SEIF 的 self-evolving 方法(Instructor 和 Follower 形成闭环训练)。最关键的区别是第三行的"双训练循环"——Instructor 和 Follower 各自有自己的训练 loop,互相驱动对方升级。
但 self-evolve 在 open-ended 任务上有三个核心难点:
- Instruction Difficulty Evolution:模型涨了之后,怎么自动生成更难的指令?
- Instruction Quality Assurance:指令变复杂之后,怎么避免约束之间互相矛盾?
- Reward Signal Acquisition:开放任务没有 ground truth,reward 从哪儿来?
SEIF 这套设计基本上是对症下药。
四个角色,一个闭环
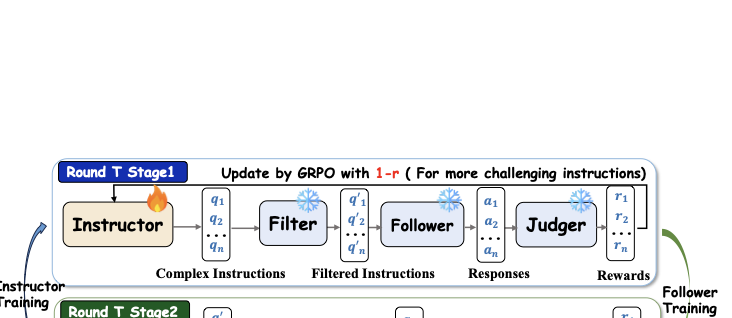
图2:SEIF 的两阶段训练流程。Stage 1 是 Instructor 训练——Instructor 用 reverse reward(\(1-r\))训练,目的是生成当前 Follower 答不对的指令。Filter 把矛盾/无效指令滤掉。Stage 2 是 Follower 训练——Follower 用正向 reward(\(r\))训练,学着满足新的复杂指令。同色块表示同源参数——Filter 和 Judger 都是从最新的 Follower 复制初始化的。两个阶段交替进行,下一轮 Instructor 又会被基于新的 Follower 重新挑战。
Filter 和 Judger 怎么解决"无 ground truth"的问题?
这个设计我觉得是 SEIF 最巧妙的地方。Filter 和 Judger 都是从当前 Follower 派生出来的,参数冻结:
- Filter \(Q_t\):给一个 evolved instruction \(x\),输出 0/1,1 表示保留,0 表示这条 instruction 自相矛盾或无意义。零 reward gating
- Judger \(J_t\):对每个 (instruction, response) 对,在 constraint level 上判定每个约束是否满足。对一个有 K 个约束的指令,给出 K 个二值标签 \(s_k \in \{0, 1\}\),然后 reward 就是满足率:
注意这是 constraint-level 满足率,不是 instruction-level 通过/不通过——这样 reward 更密集、信号更细。
最关键的是——Judger 和 Filter 不是另外训练出来的,是直接从最新 Follower 复制初始化的。这就解决了"reward model 跟不上模型能力"的问题——你的 Follower 提升一次,Judger 也跟着升级一次,永远是用最强的"自己"评判自己。
这个设计很 elegant,但也带来一个潜在 risk——判官和被判都是同一个模型,会不会形成默契? 也就是 Judger 对 Follower 的错误过于宽容。论文里没明确讨论这个风险,但实验数据看起来确实涨了,所以至少在这个 setup 下问题不严重。可能是因为 Filter 和 Judger 是冻结的 snapshot——它们和当前训练中的 Follower 不是同一份参数,有一定的 decoupling。
Instructor 的"反向 reward"
这是 SEIF 的另一个关键设计。Instructor 的 reward:
翻译过来就是:指令越能让当前 Follower 答不上来,Instructor 的 reward 越高。但前提是指令本身得有效(\(Q_t(x) = 1\))。如果 Filter 判定这个指令矛盾,直接零分——不奖励"故意出错题"的取巧。
这就是经典的 adversarial training 思路。Instructor 在搜索"当前 Follower 能力边界附近的指令"——太简单的没用(reward 低),矛盾的也没用(被 Filter 滤掉),只有那种"对 Follower 来说有点难但能做"的指令才有最高 reward。
Follower 的正向 reward
简单直接——Follower 生成的 response 满足越多 constraint,reward 越高。
注意这里有个细节——Judger \(J'_t\) 是从训练前的 Follower \(F_{\theta_t}\) 复制的,不是从更新中的 Follower 实时取的。这避免了"训练过程中 reward model 自己也在变"的不稳定问题。
整个训练流程
每一轮迭代 \(t\):
- Instructor 训练阶段:冻结当前 Follower \(F_{\theta_t}\),从它派生出 Filter 和 Judger。Instructor 用 GRPO 优化生成更难的指令
- Follower 训练阶段:用更新后的 Instructor 生成新指令,Follower 用 GRPO 在这些新指令上训练
- 下一轮:用更新后的 Follower 派生新的 Filter 和 Judger,重新进入 Stage 1
整个流程不依赖任何外部 supervision——只需要一个 base model 和一批 seed instruction,剩下的全自演化。
GRPO 这边没有什么特别,就是标准的 group-relative advantage:
实验结果:5 个模型 × 6 个 benchmark
| 模型 | Stage | IFEval Pr.(L) | CFBench ISR | FollowBench HSR | WritingBench Avg | AgentIF CSR | Multi-IF Avg |
|---|---|---|---|---|---|---|---|
| Qwen2.5-1.5B | BASE | 43.6 | 22.0 | 34.6 | 44.8 | 42.8 | 31.7 |
| Qwen2.5-1.5B | Iter3 | 47.5 (+3.9) | 24.0 (+2.0) | 36.6 (+2.0) | 45.6 (+0.8) | 47.5 (+4.7) | 32.0 (+0.3) |
| Qwen2.5-7B | BASE | 73.9 | 47.0 | 55.1 | 57.2 | 54.2 | 59.0 |
| Qwen2.5-7B | Iter3 | 78.6 (+4.7) | 51.0 (+4.0) | 59.0 (+3.9) | 63.8 (+6.6) | 60.5 (+6.3) | 61.9 (+2.9) |
| Llama-3.1-8B | BASE | 73.8 | 34.0 | 53.8 | 53.4 | 59.5 | 47.5 |
| Llama-3.1-8B | Iter3 | 78.4 (+4.6) | 36.0 (+2.0) | 57.3 (+3.5) | 47.4 (-0.1) | 57.4 (+4.0) | 62.4 (+2.9) |
| Distill-Qwen-14B | BASE | 74.9 | 55.0 | 51.2 | 61.0 | 54.5 | 53.0 |
| Distill-Qwen-14B | Iter3 | 80.0 (+5.1) | 60.0 (+5.0) | 54.0 (+2.8) | 62.1 (+1.1) | 58.2 (+3.7) | 56.8 (+3.8) |
| R1-0528-Qwen3-8B | BASE | 79.7 | 66.0 | 60.4 | 76.1 | 57.4 | 48.4 |
| R1-0528-Qwen3-8B | Iter3 | 81.9 (+2.2) | 69.0 (+3.0) | 66.2 (+5.8) | 76.5 (+0.4) | 62.6 (+5.2) | 53.2 (+4.8) |
读这张表的几个观察
观察 1:所有 5 个模型在大部分 benchmark 上都涨了,且涨幅 +3 到 +5 个点很稳定。说明这套 self-evolve 是通用的,不依赖某个特定 backbone
观察 2:在已经很强的 R1-0528-Qwen3-8B 上还能涨 5 个点(FollowBench HSR 60.4→66.2),这是个挺让人 surprised 的结果。一般来说越强的模型越难训涨,这说明 SEIF 的边界搜索机制确实在找到 underlying 的能力 gap
观察 3:Llama-3.1-8B 上 WritingBench 掉了 0.1 个点——这是唯一的负向。我猜是因为 evolved instruction 的分布偏向"complex constraint following",对自由 writing 类任务略有不利。这是 task distribution drift 的典型表现
观察 4:和 GPT-4o、Claude-Opus 这些强 baseline 比,SEIF 训出来的 7B/8B 模型在 IFEval Pr.(L) 上已经能接近或超过——但其他 benchmark 上还有差距。说明这套方法在"严格约束跟随"上提升明显,但在更 open-ended 的能力上(writing quality、agentic)还有空间
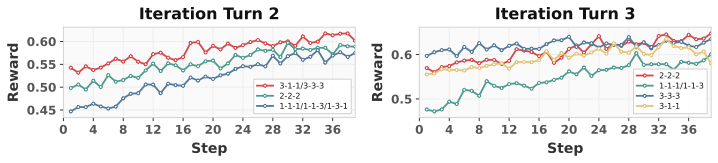
图3:训练 stage 内部和跨 stage 的能力变化。可以看到 Iter1 提升最猛,Iter2 边际收益递减,Iter3 又有一次稳定上涨。论文里给出的实践建议是:"早期 stage 充分训练打基础,后期 stage 适度训练避免 overfit"——和我们一般做 SFT 的经验是吻合的。
Constraint type 的细化分析

图4:横轴是不同 constraint type(如长度限制、格式约束、内容禁忌等),纵轴是模型,颜色深浅表示提升幅度。可以看出 SEIF 在格式类约束(如指定段数、长度)上提升最猛,在语义类约束(如要求特定语气、风格)上提升相对小一些。这个差异是合理的——格式约束的 reward 容易客观判定(数段数、数字数),语义约束本身 Judger 自己也判得不准。
我的判断:值不值得读?
强烈推荐,特别是如果你在做 post-training。
亮点:
- 把对抗式 self-evolve 干净地落到 open-ended 任务上。这块过去主要是 verifiable task(math、code)的天下,SEIF 证明了 open-ended 也能搞
- Filter + Judger 都从 Follower 派生这个设计非常 elegant。解决了"reward model 跟不上"的问题,且训练上极简——不需要单独维护 reward model
- Constraint-level reward 比 instruction-level pass/fail 要密集得多,是 instruction following 训练的关键 trick
- 实验泛化性好。5 个模型 6 个 benchmark,覆盖度比很多论文要广
问题:
- Judger 是 Follower 自己的副本——这个 self-judge 设定有 reward hacking 风险。论文没充分讨论。理论上 Follower 可能学到"生成的 response 在 Judger 看起来是 100%,但实际不符合 instruction"。实验数据涨了不代表这种风险不存在
- seed instruction 的质量决定了演化的上界。论文没充分讨论 seed instruction 是怎么挑的、不同 seed pool 对结果的影响。这点对复现很关键
- Compute 成本不透明。两个角色交替训练,3 轮迭代,相比直接 SFT/DPO 应该贵很多。论文没明确报告训练 token 数和 compute budget
- Instructor 训练的稳定性? 用 reverse reward(\(1-r\))训练,理论上很容易 collapse 到极端 case——Instructor 学会出"格式上有效但语义无意义"的指令骗过 Filter。论文里 Filter 应该挡住了一部分,但这种 adversarial 训练的稳定性始终是个问题
- 没有跟 Magpie、Crab-DPO 这些 self-play 方法的更细致对比。表里只有最终分数对比,没看 training dynamics、数据效率等更深层的差异
对工程实践的启发:
- 如果你在做 instruction following,self-evolve 比静态 SFT 更值得尝试。但要做好"Filter 必须严格"和"Judger 周期性更新"两个细节
- 对 reward model 的"派生"思路值得借鉴。与其单独训一个昂贵的 reward model,不如让 reward model 跟着 policy model 一起涨
- Constraint-level reward 是开放任务训练的关键。把 instruction 拆成 K 个原子 constraint,分别判定再聚合,比 binary outcome reward 信号丰富得多
收尾
这篇论文我觉得最有价值的不是"涨了 5 个点"这个结果,而是它为 open-ended task 的 self-evolve 提供了一个干净的 template:
- 4 个角色分工
- Filter/Judger 派生于 Policy
- 对抗式 reward shaping
- 交替训练
这个 template 应该可以推广到 dialogue quality、creative writing、agentic task 等其他开放任务上。我会盯着这个方向的后续工作,特别是有没有人把这套思路搬到 multi-turn agentic scenario 上——那才是真正难啃的硬骨头。
下一步如果有人能解决"Judger self-judge bias"和"Instructor reward gaming"这两个问题,self-evolve 这条路可能真的会替代很多依赖外部 teacher 的训练 pipeline。我对这个方向的乐观度比读论文之前要高。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我