Ψ-RAG:把 Tree-RAG 从"单文档玩具"推到"语料库级跨文档多跳"——比 RAPTOR 强 25.9%、比 HippoRAG 2 强 7.4%
核心摘要
Tree-RAG 这条路线(典型代表 RAPTOR)以前的定位有点尴尬——它擅长在一个长文档里做"分层摘要 → 多粒度检索",但一到跨文档多跳问答(一个问题需要在好几个文档里跳着找答案)就拉跨。
这篇 HKUST(GZ) 的 ICML 2026 工作把 Tree-RAG 的三个 fundamental 痛点都点了出来:
- 分布适配差:k-means 聚类隐含"球形分布"假设,对真实语料里偏态分布(少数文档主导)会引入大量噪声。
- 结构隔离:树索引的叶子节点之间没有显式连接,没法像 Graph-RAG 那样跳着走。
- 抽象太粗:上层节点全是高度凝练的摘要,反而把 token 级细节给"糊"掉了——查一个具体实体名时根本对不上。
Ψ-RAG 给的解法两件套:
- Abstract Tree Index:用"merge + collapse"迭代式建树,不预设聚类形状、自适应数据分布;同时给每个抽象节点配 summative + keyword 两种摘要。
- Multi-granular Agentic Retriever:检索+答题 agent,能判断当前信息够不够、要不要再检索、并能重写 query 加入语境关键词;同时融合 tree retriever + BM25 sparse retriever 两路结果。
效果:在 6 个跨文档多跳 QA benchmark 上,比 RAPTOR 平均高 25.9% F1,比 HippoRAG 2 高 7.4% F1,建索引比 OpenIE-based Graph-RAG 快 10×。第一次让 Tree-RAG 在跨文档多跳上和 Graph-RAG 平起平坐甚至超越。
一句话评价:Tree-RAG 的"复活之作"——把它从"长文档摘要场景特长生"提升到了多粒度通用 RAG 框架。
论文信息
- 标题:Hierarchical Abstract Tree for Cross-Document Retrieval-Augmented Generation
- 作者:Ziwen Zhao, Menglin Yang
- 机构:The Hong Kong University of Science and Technology (Guangzhou)
- 日期:2026/05/01(ICML 2026 accepted)
- arXiv:https://arxiv.org/abs/2605.00529
- 代码:https://github.com/Newiz430/Psi-RAG
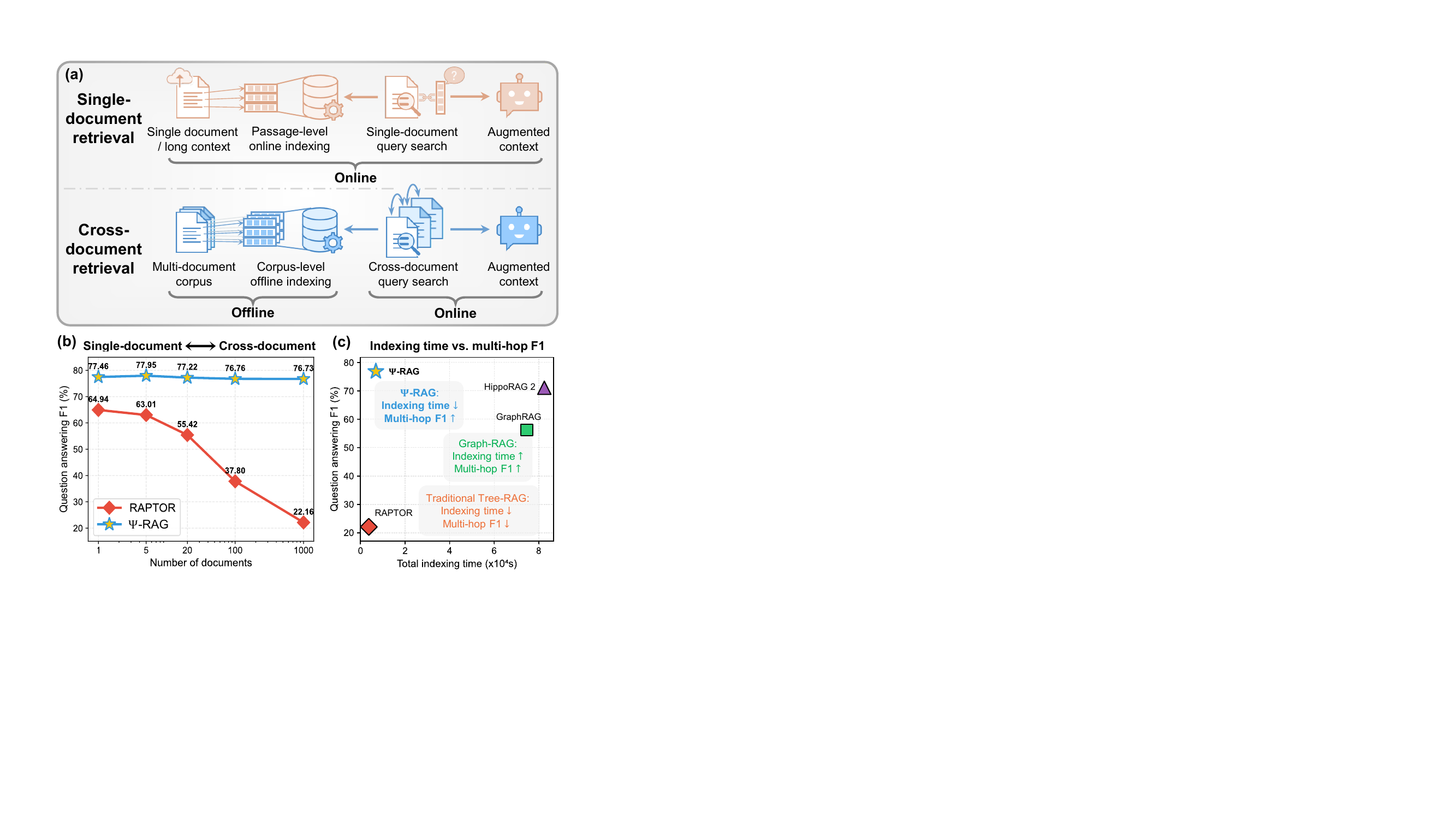
问题动机:Tree-RAG 在"corpus 级"上摔得很惨
做过 RAG 工程的同学应该对这个场景熟悉:
- 单文档 RAG:用户上传一个 PDF,问 "这份合同的违约金条款是什么"——传统 dense retrieval 都能搞定。
- 跨文档 RAG:你建一个 100 万 token 的领域知识库,用户问"A 公司 CEO 在他 2024 年的演讲里提到的那个对手是谁的子公司"——这就需要在不同文档间多跳推理。
后者才是企业 RAG 产品的真实战场。但 Tree-RAG 在这里有几个老毛病:
痛点 1:k-means 假设和真实分布对不上
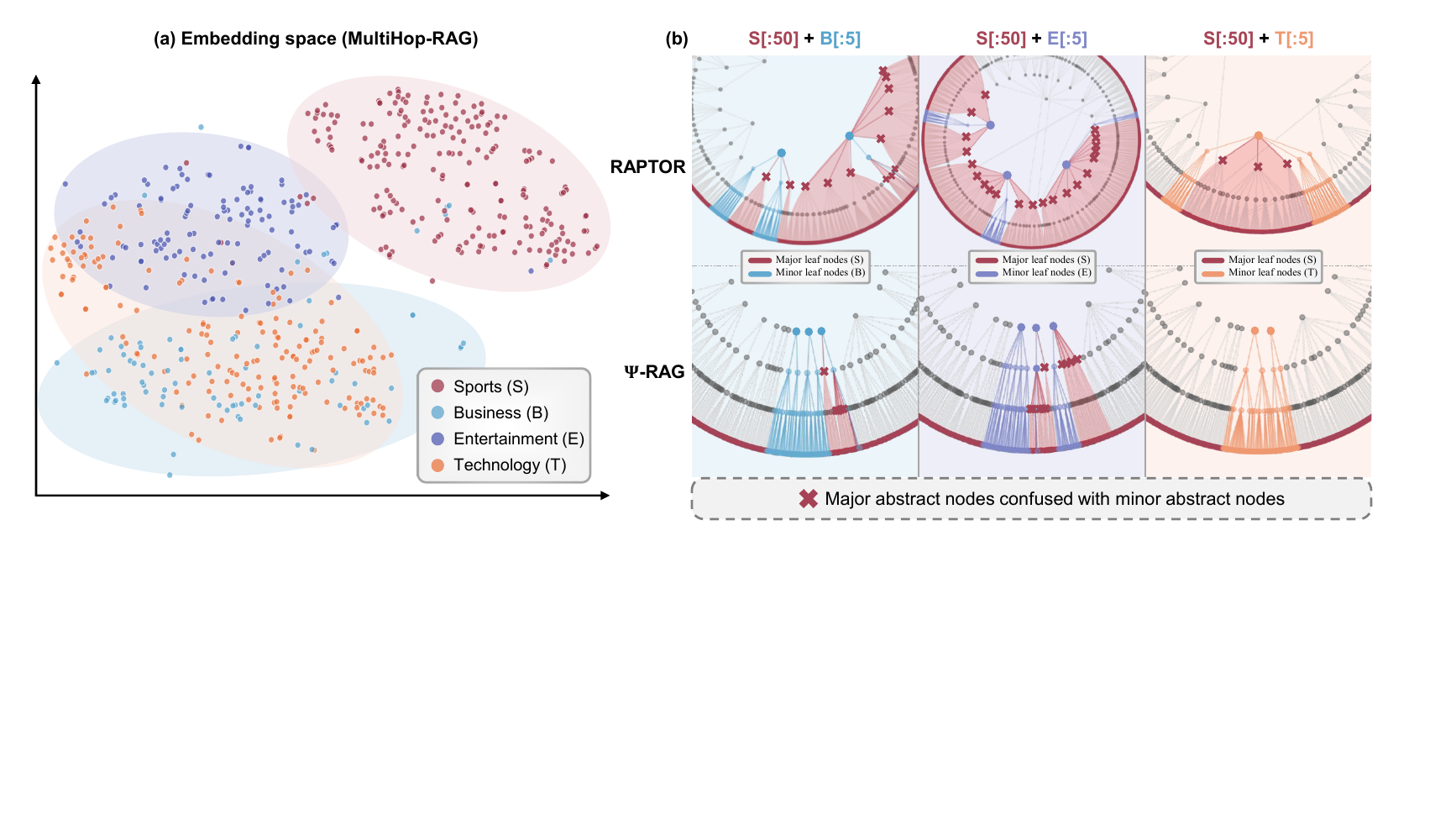
RAPTOR 用 k-means 聚类把 chunks 聚成簇、生成上层摘要节点。问题是 k-means 假设球形等密度分布——而真实领域语料是 highly skewed(少数热门主题文档多、长尾大量小簇)。
论文里用模拟数据展示了这个问题:当文档分布偏离均匀时,k-means 会把不相关的 chunks 强行聚成一簇,摘要 agent 拿到混杂上下文,生成的"summary"信息混乱——上游错了下游全错。
痛点 2:树是"孤岛",没法跨文档跳
Graph-RAG(GraphRAG / HippoRAG)天生支持多跳——节点之间有显式 edge,可以 walk。但 tree index 是 hierarchical 结构,叶子节点之间没有横向连接。
一个典型 multi-hop query:
"Who is the wife of the man who produced the documentary about the pop star who influenced Beyoncé?"
需要两跳:① "influenced Beyoncé" → Michael Jackson;② "produced documentary about MJ" → David Gest;③ wife of David Gest → Liza Minnelli。
Tree-RAG 一上来 dense 匹配 query 向量,最相似的 chunks 都和 "Beyoncé" "documentary" 有关,真正的主角 David Gest 根本没出现在检索结果里。
痛点 3:上层摘要太"模糊"
Tree-RAG 在顶层用了高度抽象的摘要节点,理论上是为了"高层语义匹配"。问题是当用户查一个具体实体("Beyoncé 是哪一年的出生"),dense vector 在 query 和 abstract summary 之间根本对不上——抽象 summary 已经把具体年份、人名都糊成一团了。
Ψ-RAG 的方案:树结构 + Agent 检索
1. 抽象树索引——"merging + collapse"代替 k-means
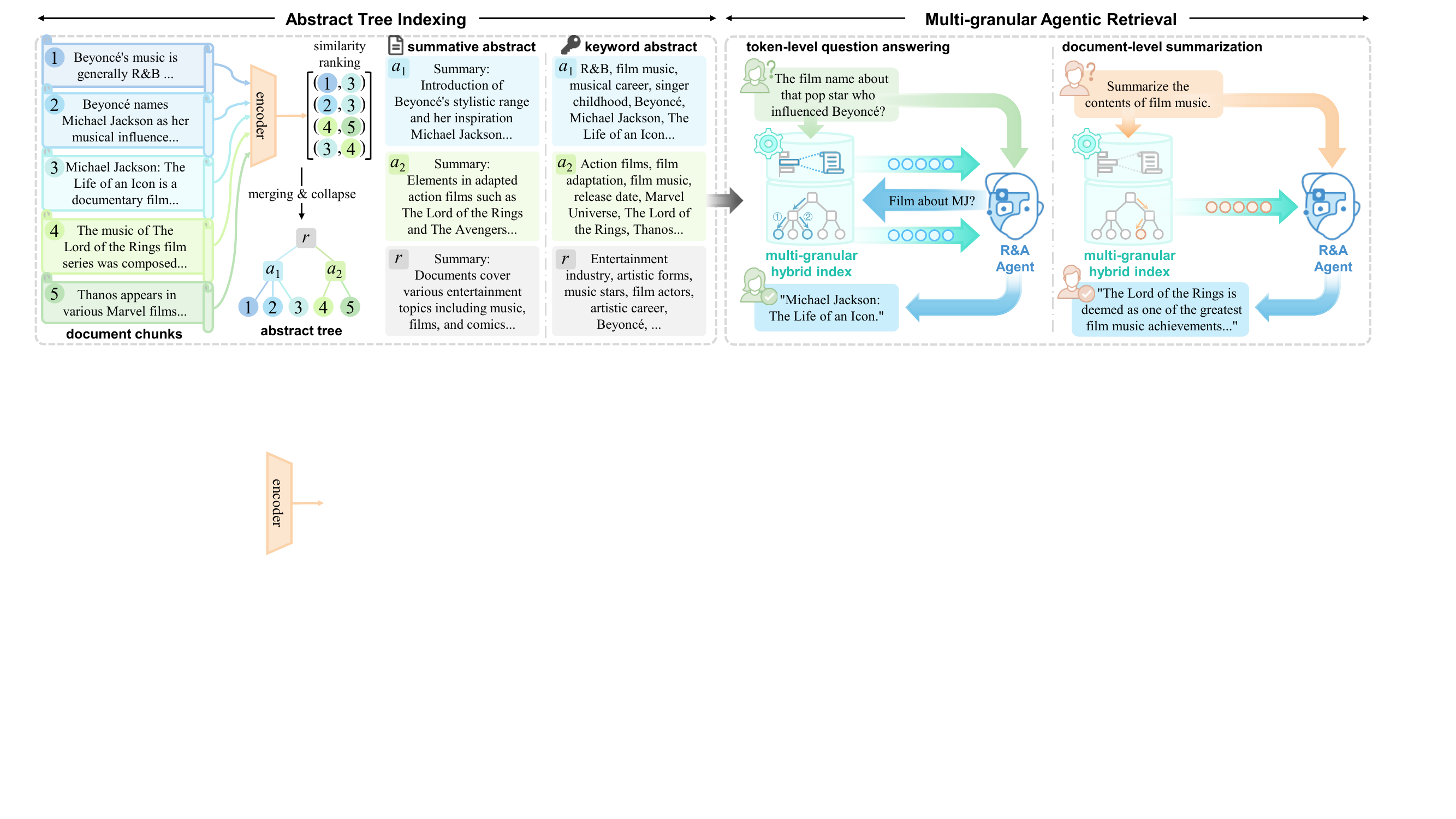
Ψ-RAG 的整体流程:左边 Abstract Tree Indexing(构造抽象树 + 抽象 agent 生成摘要)、右边 Multi-granular Agentic Retrieval(R&A agent + 树检索 + 稀疏检索)。
建树过程完全不预设簇数和形状:
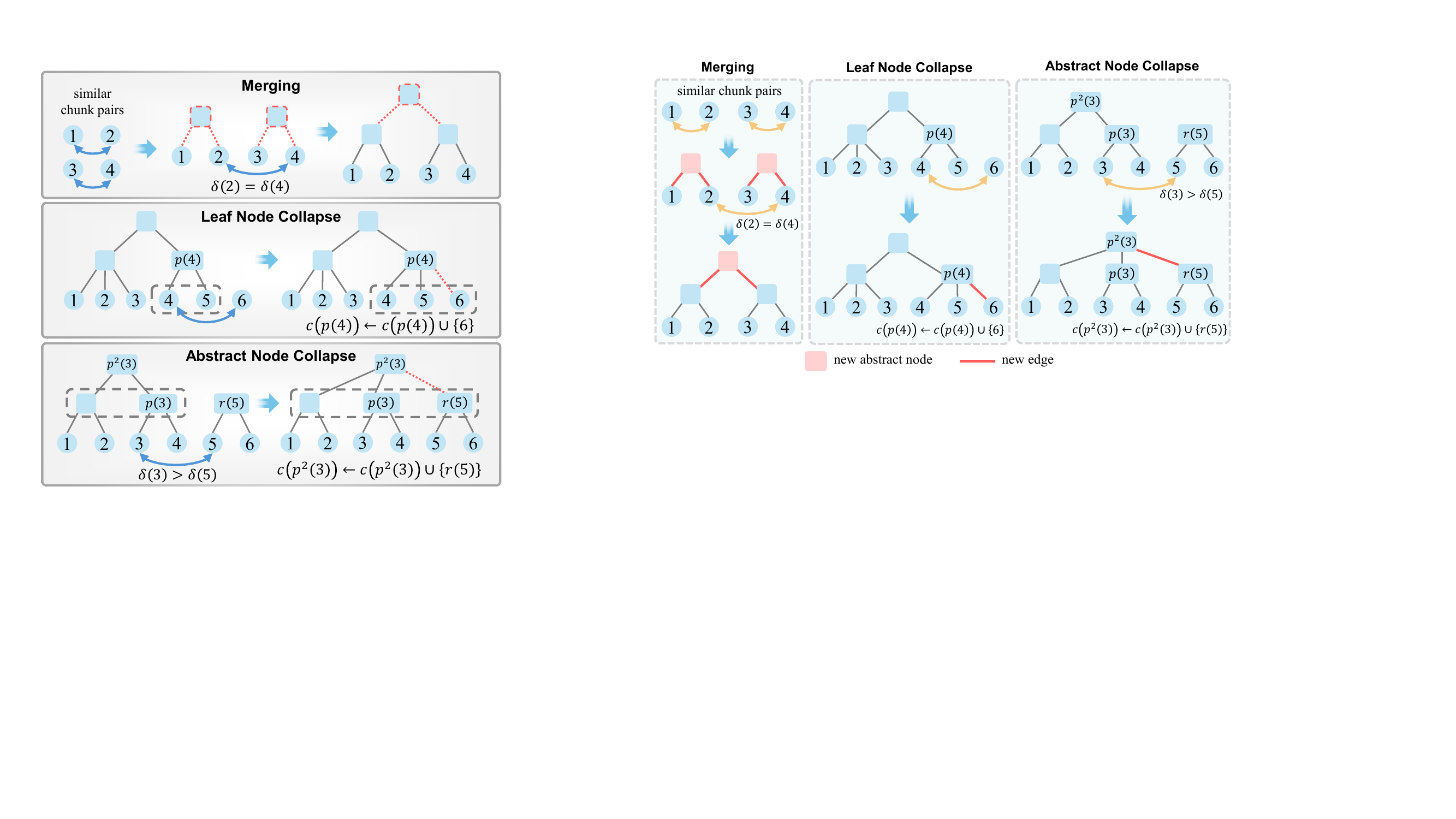
三种操作:(a) merging:两个孤立 chunk 配对、新建抽象父节点;(b) leaf node collapse:一个 chunk 挂到另一个 chunk 已有的父节点下;(c) abstract node collapse:两个已有子树合并或对齐深度。黄色箭头标示当前处理的 chunk pair。
具体算法: 1. 所有 chunk 编码成 dense vector 2. 计算所有 pair 的余弦相似度,降序排序 3. 从最相似的 pair 开始迭代: - 都没父节点 → merge(建新抽象节点) - 一个有父节点 → leaf collapse(挂到现有树) - 都有父节点且 root 不同 → abstract node collapse(合并子树或对齐深度) 4. 跑 n-1 步把所有节点串成单棵树 5. rebalance:子节点过多的节点拆分(避免摘要 agent 上下文过长)
好处:完全 data-driven,没有 k 这个超参,也不假设球形分布——稀疏 / 偏态语料也能合理切。
每个抽象节点配两种摘要: - Summative abstract:连贯段落(保留逻辑和实体关系) - Keyword abstract:高密度关键词(保留实体共现)
实验结果显示 summative 略胜 keyword——说明实体之间的逻辑关系比单纯关键词覆盖更重要。
2. R&A Agent + Hybrid Retrieval——给 Tree 配一对"轮子"
这是论文我个人觉得最有工程价值的部分。
R&A Agent 的工作流:
1. 初始检索 → 拿到 top-k chunks
2. Agent 评估: "信息够吗?"
├─ <answer> 标签 → 回答
└─ <retrieve> 标签 → 生成新 query → 再检索 → 回到 2
3. 达到 i_max 次还不够 → 返回 "Not mentioned"
关键不只在"会重试",而在 agent 能重写 query 加 contextual descriptor:
原始 query: "Who is the wife of David Gest?"
↓ 重写
新 query: "Who is the wife of **the American film producer** David Gest?"
加入 "American film producer" 这个同位语,让: - 稀疏检索(BM25)有更多关键词命中 - 树检索能定位到正确的高层抽象节点("film industry" / "music documentary")
Hybrid Retrieval:tree retriever(dense + 多粒度)+ sparse retriever(BM25)双路,agent 决定是用 reranker 融合还是用 RRF 融合。 - Tree 解决"高层语义/长文档结构" - BM25 解决"具体实体名/精确 keyword" - Agent 决定何时偏向哪一边
这套设计直接解决了三个痛点——结构隔离用 agent 多次检索补救、抽象太粗用 BM25 兜底、分布适配用新建树算法。
实验:跨文档多跳上的"全面胜利"
主结果
在 6 个 token-level QA benchmark(HotpotQA、2Wiki、MuSiQue、MultiHop-RAG、NQ、PopQA)上:
| 对手 | Ψ-RAG 的 avg F1 优势 |
|---|---|
| RAPTOR | +25.9% |
| HippoRAG 2 | +7.4% |
| HippoRAG 2 + Q3 reranker | +9.9% |
| 在 2Wiki 上对 RAPTOR | +54.78% |
更值得注意的几个观察:
- RAPTOR 在 corpus 级真的不行:在 5/6 数据集上甚至输给 DPR(无 reranker),PopQA 上 F1 掉 30%+。这是 tree-RAG 之前一直没被正式承认的弱点。
- Ψ-RAG 是第一个在跨文档多跳上稳定超越 Graph-RAG 的 Tree-RAG——Tree-RAG 这条线终于有了"真正能打"的代表。
- 索引效率 10× 优于 OpenIE-based Graph-RAG——后者要先 LLM 抽实体三元组,I/O 重;Ψ-RAG 的 merge-collapse 只要 embedding + 少量 abstract LLM calls。
在 NarrativeQA 和文档摘要(QMSum、WCEP)上也是 SOTA——这是 Tree-RAG 的传统强项,没丢。
Ablation:每个组件都掉肉
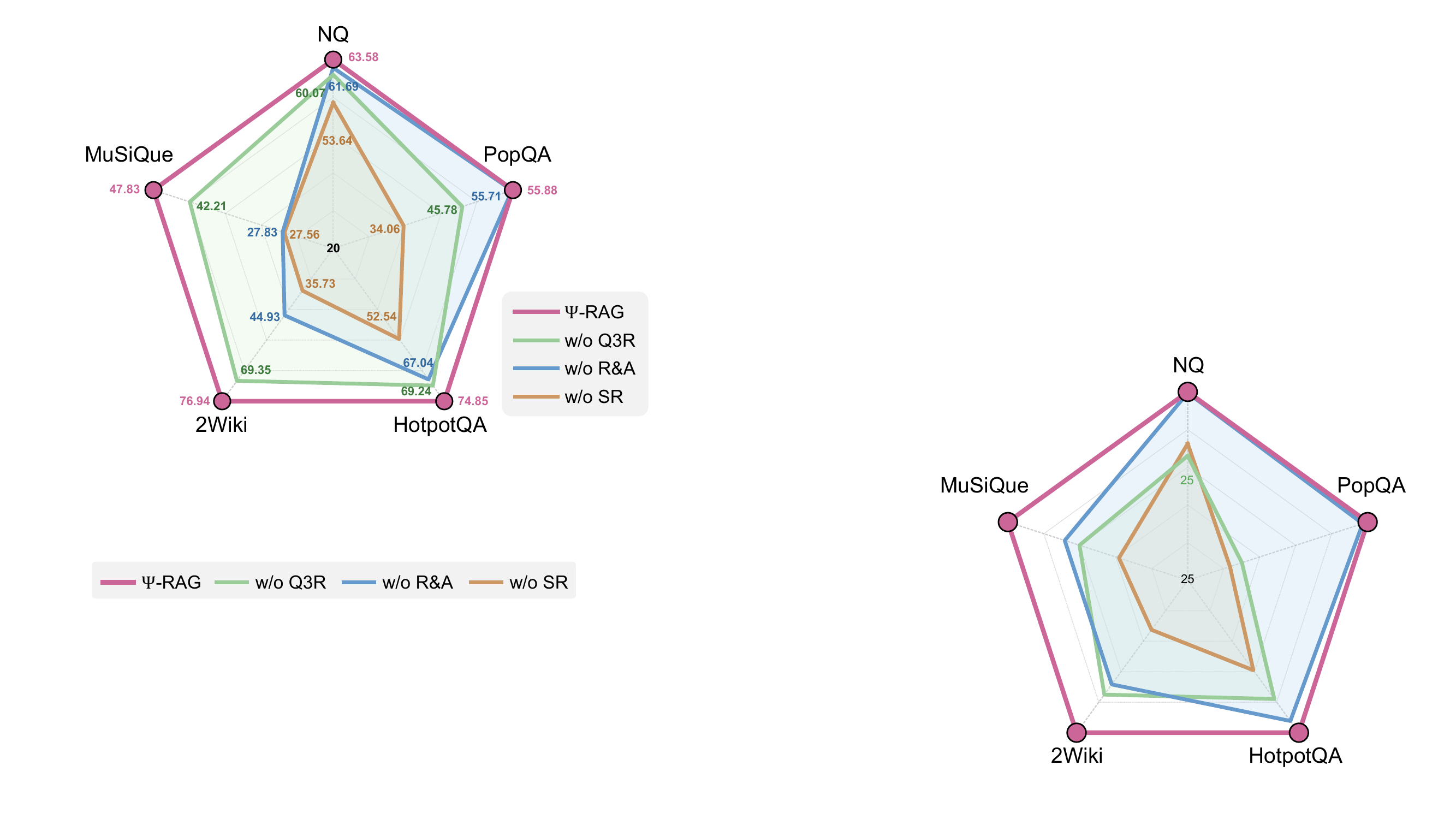
消融研究的 F1 表现:去掉 R&A agent、sparse retrieval、reranker 后的各项性能下降。
几个关键发现:
- 去掉 R&A agent:multi-hop QA 上平均掉 ~20% F1。这是 agent 多轮检索的核心价值——multi-hop 几乎完全依赖它。
- 去掉稀疏检索:PopQA 掉 21.82%,2Wiki 掉 41.21%。这两个数据集大量"具体实体名"短问题,BM25 才是正解。
- 去掉 reranker(改用 RRF):差距很小。说明 reranker 提升不是决定性的——可以用非参 RRF 省 inference 成本。
- R&A agent 在 single-hop 上也涨点:NQ +1.89% F1。这来自 query 重写——把"上下文不足"的查询补全。
我的判断
亮点:
- 诊断特别准:把 Tree-RAG 在"corpus 级跨文档"上的三个 fundamental 缺陷讲清楚了。这本身就是个贡献——之前一直被忽视。
- 建树算法优雅:merging + collapse 完全 data-driven,没有 k 这种 nasty 超参,适配偏态语料。这是工程上最关键的属性。
- Agent 设计有 system 思维:R&A agent 不光是"会调工具",还能重写 query 加 context。后者在我看实战中价值更大。
- 全任务覆盖:token-level QA(单跳 + 多跳)、passage-level 因果推理、document-level 摘要——一个框架打天下,这种通用性 GraphRAG 还做不到。
- 完全开源 + 不需要微调:直接套自家语料就能用,工程友好。
问题:
- R&A agent 没说成本:每个 query 多轮检索 + LLM 决策,相比 RAPTOR 的"一次 top-k"贵不少。论文里没看到详细的 token cost 报告。
- i_max 是个超参:检索次数上限设多少?设小了多跳搞不完、设大了浪费成本。论文里默认 5,但没看到 ablation。
- rebalance 标准是什么:节点子节点太多就拆——拆的标准(阈值多少)会显著影响树的形状和检索效果。
- vs GraphRAG 的边界还可以再压:Ψ-RAG 在多跳上比 HippoRAG 2 高 7.4%,但 HippoRAG 2 是显式建图的代表。如果引入 entity-level graph hint 到树里(混合结构),可能能再上一层。
- 多语种 / 跨模态没讨论:现在的方案是文本-only。真实企业语料里有大量表格、PDF、混合格式——这块的处理论文没碰。
工程启发
如果你在做:
- 企业知识库 RAG 产品:把 Ψ-RAG 的"merge-collapse 建树" + "Agent retrieve" 这一套作为下一版的演进方向。比 GraphRAG 的 OpenIE 成本低、比 RAPTOR 的 k-means 更稳。
- 跨文档多跳的工作流(合同审查、研报分析、调研报告):至少要有 multi-hop agent retrieval 这一层。一次 top-k 在这些场景下基本是死路。
- 混合检索的设计:dense + sparse 是个老话题,但 Ψ-RAG 的 agent-driven 融合(让 agent 决定何时偏向 BM25)比固定权重 RRF 更智能。可以借鉴。
- 稀疏分布的领域语料(医疗、法律、长尾产品):k-means 这类聚类方法都不太合适,merging + collapse 这种 data-driven 的层次构建值得试。
- 索引成本敏感的项目:相比 GraphRAG 的 LLM-based entity extraction,Ψ-RAG 只在抽象节点上调 LLM,整体索引成本可控得多——10× 加速是真金白银。
最后说一个个人 takeaway:
RAG 的下一站不是"更强的 retriever",而是"更聪明的 retrieval workflow"。 Ψ-RAG 把建索引、重写 query、多轮检索、稀疏密集融合编织成一个 agent-orchestrated 流程,本质上是把"retrieval as a function call"演化成"retrieval as a multi-step program"。这条路才刚刚开始走。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我