多智能体 LLM 的 RL 该往哪走?这篇 84 篇综述把"编排轨迹"作为新单元
核心摘要
LLM 单智能体的 RL 这两年已经基本走熟——RLHF、PPO、GRPO、reward modeling 都有比较成熟的 recipe。但多智能体 LLM(LLM-MAS)的 RL 还在野蛮生长——Kimi Agent Swarm、OpenAI Codex、Anthropic Claude Code 都在生产里跑,但学术界还在"用单智能体框架硬套"。
这篇综述提出一个非常清晰的视角——Orchestration Trace(编排轨迹):
把多智能体系统的运行看成一个 temporal interaction graph——事件包括 sub-agent spawning、delegation、communication、tool use、return、aggregation、stopping。这个 graph 才是 RL 真正要优化的对象,不是单个 agent 的 trajectory。
基于这个视角,论文系统盘点了三个技术轴:
- Reward design:归纳出 8 大 reward family,特别新的是"编排相关"的——parallelism speedup(并行加速)、split correctness(任务拆分正确性)、aggregation quality(聚合质量)。
- Credit & signal assignment:8 种 credit-bearing unit,从 token 到 team。论文一个尖锐发现——显式 counterfactual message-level credit 几乎没人做。
- Orchestration learning:拆成 5 个 sub-decision——何时 spawn、委派给谁、怎么 communicate、怎么 aggregate、何时 stop。截至 2026/05/04,没有任何论文显式 RL 训练"何时 stop"这个决策。
更值得读的部分——学界 vs 业界的 scale gap: - 学界论文:通常 2-3 个 agent、trace 长度 < 50 step - 业界 deployment(Kimi K2.5/2.6):上百个 sub-agent、trace 长度数千 step - 这个 gap 不是学术评测体系的"独立验证",而是"被边缘化的事实"
整体而言:这是一篇非常重的 review/position paper,84 篇精选 + 显式 inclusion/exclusion log + 公开 schema 工件——写给所有想做 LLM-MAS RL 的人的地图。
论文信息
- 标题:Reinforcement Learning for LLM-based Multi-Agent Systems through Orchestration Traces
- 作者:Chenchen Zhang
- 机构:Independent Researcher
- 日期:2026/05/04
- arXiv:https://arxiv.org/abs/2605.02801
- 代码 / Artifact:https://github.com/xxzcc/awesome-llm-mas-rl
- 84 entry tagged paper pool
- 32 record exclusion log
- corpus 统计脚本
- 可重放编排轨迹的 JSON schema
(注:本图来自论文 HTML 内联 SVG 转换的 PNG)
图1:Paper map。三条输入传统(single-agent LLM RL、classical MARL、industrial agent systems)汇入"orchestration trace"作为共享对象,向下组织三个技术轴(reward / credit / orchestration learning)以及 systems、benchmarks、safety 等横向章节。这是整个 survey 的 mental model。
为什么"现在"是搞 LLM-MAS RL 的关键时点
作者第 1.1 节 "Why now" 给的几个理由我都很 buy:
- Frontier 实验室都在跑生产级 MAS——Kimi Agent Swarm(K2.5/K2.6)、OpenAI Codex agent harness、Anthropic Claude Code sub-agents。这些不是 demo,是真在 prod 跑的系统。
- 生产数据回流:业界 deployment 产生了海量真实的编排轨迹,但这些数据学界看不到。学术 benchmark 和生产规模出现了越拉越大的 gap。
- Single-agent RLHF 边际收益递减:单 agent 能力曲线在饱和,下一波 capability gain 必须从 system-level(多 agent 协同)来。
- PARL(Kimi)等首个公开报告:少数 frontier lab 开始 publish 部分系统细节(reward 公式、训练 regime),给了学界一个着力点。
LLM-MAS 不是 Classical MARL
这是非常关键的论点。Classical MARL(多智能体强化学习,比如 MADDPG、QMIX)假设的: - agent 数量固定 - 每个 agent 的 policy 形式同质 - 通信协议结构化 - trajectory 长度有界
LLM-MAS 全反过来: - agent 数量动态生成(一个 orchestrator 决定 spawn 几个 sub-agent) - 不同 agent 角色异质(planner / executor / critic) - 通信靠自然语言 message,结构高度灵活 - trace 长度变化巨大(几十 step ~ 数千 step)
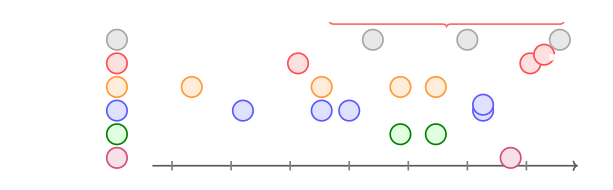
图2:2024 Q4 到 2026 Q2 的代表性 LLM-MAS 工作时间线。横轴是 arXiv 提交日期,纵轴按 credit-bearing unit(团队 / 编排器 / 角色 / 智能体 / 回合 / 消息 / token)分组。几乎全部最近工作集中在 agent 级和 turn 级,message 级和 orchestrator 级的训练方法极少。
这张时间线信息密度极高——一眼看出社区在哪里集中刷点、哪里是 white space。
核心抽象:Orchestration Trace 是什么
定义
Orchestration Trace = 一个 temporal interaction graph,事件类型包括: - spawn:orchestrator 生成新 sub-agent - delegate:orchestrator 把子任务派给某个 agent - communicate:agents 之间发 message - tool use:agent 调外部工具 - return:sub-agent 把结果返还给上级 - aggregate:orchestrator 把多个子结果合并 - stop:决定整个任务结束
这个 trace 是个 DAG(变形 tree),不是简单序列。论文 §3.2 把它形式化为 Dec-POMDP 的扩展——变长、可分支、节点异质。
Reward-Credit Dual
论文 §3.5 引入了一个我觉得非常巧的 framing——reward 和 credit 是同一件事的两面:
- Reward:环境(或代理裁判)发给某个事件/单元的信号
- Credit:把整体结果(task success)反向归因到某个事件/单元
例:team 完成任务 +10,怎么把这 +10 分到每个 sub-agent、每条 message、每个 token?这是 credit assignment 问题。同样地,给每条 message 单独定义一个 reward function 是 reward design 问题。
两者本质同构——区别只是 bottom-up 给 reward vs top-down 拆 credit。
技术轴 1:Reward Design(8 大家族)
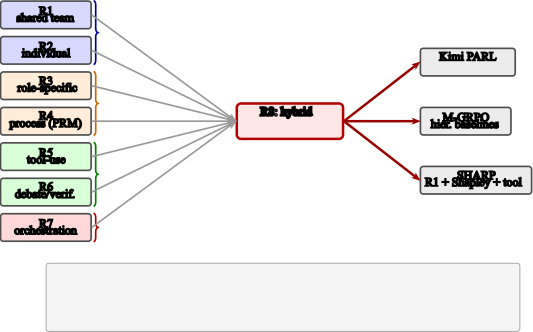
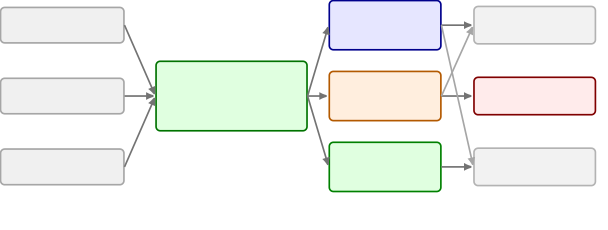
图3:Reward family composition。R1-R7 七个原始 family 归入四个语义层(outcome / structured / process / system),通过 R8 hybrid weighting 复合出 method-specific 的 reward 函数。
七个原始 family 是:
| 类别 | Family | 示例 |
|---|---|---|
| Outcome | R1: Task success | 答对题 +1 |
| Outcome | R2: Verifier reward | 测试用例通过率 |
| Structured | R3: Format/structure | 输出符合 JSON schema |
| Structured | R4: Aggregation quality | 聚合结果一致性 |
| Process | R5: Trace coherence | 推理步骤合理 |
| Process | R6: Communication efficiency | message 数量 / 长度 |
| System | R7: Parallelism speedup | wall-clock 加速比 |
R7(并行加速)特别重要——单 agent RL 完全没这个概念。但在 MAS 里,orchestrator 如何拆任务直接决定 wall-clock 时间,不优化这一项就意味着你拿不到 MAS 的核心优势。
Kimi PARL 是个绝佳的工作例
论文 §6.2 详细拆解了 Kimi PARL 的 reward:
三项含义: - r_perf:传统的 task success - r_parallel:并行 speedup 奖励(critical path 越短越好) - r_finish:能正常 finish 的额外奖励(避免无限延展 trace)
这种"显式编排奖励"是 LLM-MAS RL 区别于 single-agent 的最大特征。学界目前 vast majority 还停留在 r_perf 一项。
Reward Hacking 在 MAS 里更恶劣
论文 §6.3 强调一个新问题:
- Single agent 的 reward hacking:模型学会钻 reward function 漏洞
- MAS reward hacking:多个 agent 合谋作弊——例如几个 sub-agent 互相确认错误结果,让 aggregator 错认为达成共识
这种"群体作弊"在 single-agent setting 完全没有对应。
技术轴 2:Credit Assignment(8 层 unit)
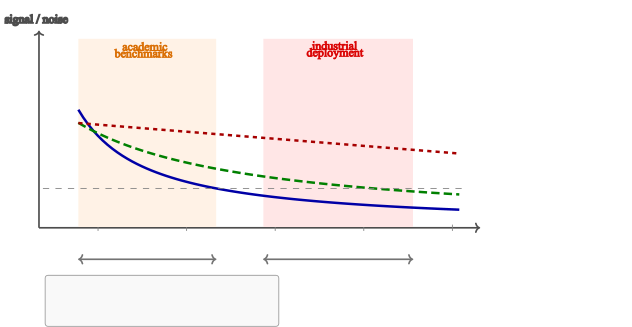
图4:三种 credit scheme 在 trace 长度 T 增长时的 per-step signal-to-noise。Uniform terminal credit(蓝)随 T 增长信号变稀;structured rewards(绿)和 dense per-step credit(红)维持更好的信噪比。蓝线是 qualitative warning 而非证明的 rate。
8 层 credit-bearing unit(粗 → 细):
- Team:整个 MAS 团队
- Orchestrator:编排器本身
- Role:某个角色(planner / executor / critic)
- Agent:单个 agent 实例
- Turn:一个 agent 的一轮交互
- Message:一条具体的 message
- Action:单步 action
- Token:每个生成的 token
论文核心发现——Message-level 的 explicit counterfactual credit 几乎没人做。
什么叫 counterfactual message credit?
"如果把 message m 从 trace 里抠掉,最终结果会变差多少?" —— 这才是 message 真正的 credit。
但实际工作里大多数还是把 team-level reward 平均分配给每条 message,没人做严格的 counterfactual 归因。
这是个明显的 white space——whoever 第一个把 counterfactual message credit 做出来,paper 直接 publish 顶会。
技术轴 3:Orchestration Learning(5 个 sub-decision)
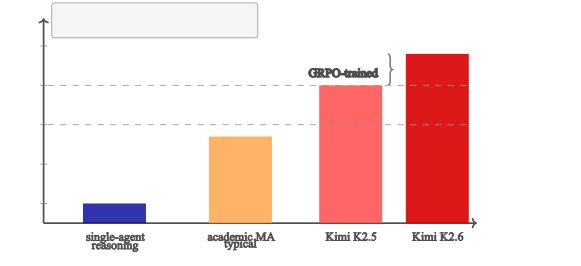
图5:Rollout cost 在不同 operating regime 下的相对代价图。Team size 和 trace length 共同决定 rollout 成本。展示了不同协作 topology 在 cost 上的差异。
五个 sub-decision:
| Sub-decision | 学界进展 | 评价 |
|---|---|---|
| O1: When to spawn | 有几篇 | 多数靠启发式 |
| O2: Whom to delegate to | 较多工作 | 主要用 LLM judge |
| O3: How to communicate | 一些工作 | 缺 message-level RL |
| O4: How to aggregate | 有进展 | 主要靠 ensemble heuristic |
| O5: When to stop | 零工作 | 完全 white space |
O5(停止决策)的缺失是个严重的工程问题——
- 不知道何时停 → trace 无限延展 → token 成本爆炸
- 学界 stop heuristic 都是 hand-coded("达到 N step 就停")
- 没有显式 RL 训练 → 模型永远学不会"我已经够确定了,可以收尾了"
我自己做 agent 系统对这一点感受非常深——agent 不知道何时停是头号问题。
学界 vs 业界的 Scale Gap
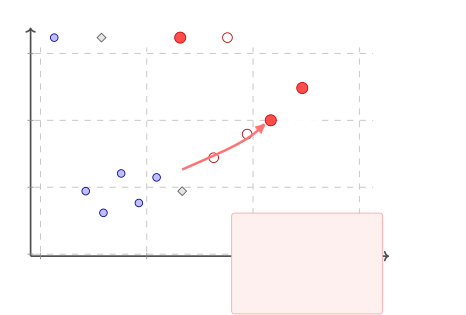
图6:业界-学界规模差距。蓝点是学术 LLM-MAS RL 方法的典型公开评测规模,红点标注 Kimi 报告中同时披露 team size 和 long trace length 的设置。横轴 team size、纵轴 trace length,两条云之间存在数量级差距。
这张图非常震撼——
- 学界 cloud:team size 2-5、trace length 10-100
- Kimi cloud:team size 几十到上百、trace length 数千
差距是数量级的。这有几个含义: 1. 学术评测 setting 对生产 MAS 几乎不 transferrable 2. 业界训出来的能力学界完全没机会 reproduce 3. MAS-native benchmark 严重缺失——下一步社区的关键投资点
论文反复强调一个 disclaimer:这个 gap 不是"业界训了好东西、学界 reproduce 失败"的独立验证——业界从不公开训练 trace,所以学界无法 verify Kimi 真训了那么大规模。这个 gap 只是"被披露的 deployment envelope" vs "公开的学术评测 regime" 的差距——一种"我们知道什么我们不知道"的清醒。
这种谨慎度的写法非常专业。
Topology 分类与系统设计
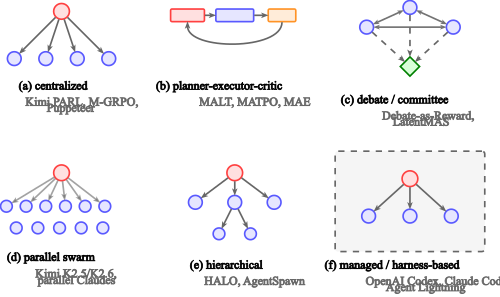
图7:六种 recurring LLM-MAS 拓扑示意图。红色 ○/方框 = orchestrator/planner、蓝色 ○ = sub-agent/executor、橙色方框 = critic、绿色菱形 = aggregator。涵盖 Master-Slave、Pipeline、Mesh、Hierarchical、Critic-Loop、Federated 等。
这张图给了 MAS 设计的"风格选项"——每种拓扑对应不同的 reward / credit / orchestration 设计选择。论文 §4 详细列了每种 topology 在已有工作里的代表。
Harness Boundary
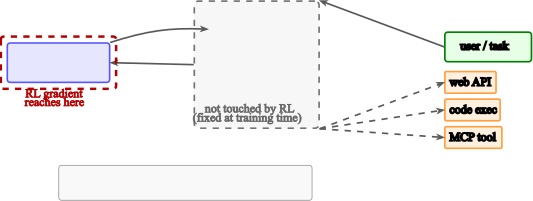
图8:Harness(虚框)包裹可训练 LLM π_θ,提供 prompt template、tool registry、execution runtime。梯度只流向 θ,harness 在训练期间是冻结的。
这个 framing 重要在哪?
- LLM-MAS 训练的真实 unit 是 (model weights + harness),但 harness 是冷冻的
- harness 的设计选择对 final policy 影响巨大——同样的模型在不同 harness 里行为完全不同
- 学界论文很少标准化 harness(每个团队自己造),导致结果 几乎不可对比
安全与对抗鲁棒性
图9:LLM-MAS 的 attack surface。橙色节点是 vulnerability 入口(prompt injection、tool poisoning、message spoofing),红色边是攻击路径,蓝色框是 defense layer。
MAS 比 single-agent 多出来的攻击面: - Message spoofing:一个 compromised agent 给其他 agent 发恶意 message - Aggregation manipulation:篡改最终聚合结果 - Role escalation:sub-agent 试图获取 orchestrator 权限
而Steerability(可引导性)是 under-addressed 问题——既要让 system 听用户的,又要防 prompt injection 把整个 MAS 劫持。这两个目标天然冲突,目前没有好方案。
我的判断
亮点:
- Orchestration trace 这个 framing 非常好:把 MAS RL 的所有问题统一到一个数据结构上,避免每个 paper 自己造概念。
- 三轴分类清晰:reward / credit / orchestration learning 三个独立技术轴,每个再细分子问题——这种 taxonomy 是综述的最大价值。
- 5 个 sub-decision 拆得有用:spawn / delegate / communicate / aggregate / stop。每个都对应一篇可发的论文。
- 明确标 O5(when to stop)零工作:直接告诉读者一个明显的 white space。这种坦诚很难得。
- 学界-业界 gap 量化:把"scale gap"显式化为图,并且非常谨慎地区分 disclosure gap vs. independent verification——这种 epistemic rigor 是 1st-tier 综述的标志。
- 可复用 artifact:84 篇 paper pool + JSON schema 公开,下游研究可以直接 build on。
问题:
- 没有原创方法:这是 survey/position paper,本身不提出新算法。需要看下游工作。
- 业界证据深度有限:因为业界不公开 raw trace,论文只能基于 Kimi / OpenAI / Anthropic 的 public report,无法 verify 训练细节。
- 某些 framing 还偏 conceptual:比如 "counterfactual message credit" 很有启发,但具体 algorithmic recipe 还没人做。
- 没覆盖闭源工作的实证 head-to-head:因为根本没办法 reproduce。
- 个人作者作品,risk 单视角:综述往往多作者交叉视角更鲁棒。
工程启发
如果你在做:
- LLM agent 产品(agent harness / multi-agent app):把"orchestration trace"作为内部数据结构的 first-class 概念。把每一次任务执行都 dump 成可重放的 trace JSON——后期训练 / 评测 / debug 都 trivial。
- MAS RL 研究:盯住三个 white space——O5 何时停止、counterfactual message-level credit、parallelism speedup reward。任何一个做出来都是顶会论文。
- agent 评测系统:MAS-native benchmark 严重不足。如果你做评测产品,按照论文 §9.4 的"good MAS-native benchmark"四维度(trace shape、credit unit、scale envelope、failure taxonomy)设计,会很有竞争力。
- 安全研究:MAS attack surface 是个新世界——message spoofing、aggregation manipulation、role escalation 都缺少系统的 defense。先做 attack lib,再做 defense lib。
- 生产 agent 系统:盯住 trace length 这个核心 cost driver。每多一倍 trace 长度,rollout cost 倍增、debug 难度上升、错误传播放大。主动让 agent 学会"早收尾" 比任何算法 trick 都有用。
最后一个个人 takeaway:
LLM 的下一波 capability 不会来自更大的模型,而是来自更聪明的 orchestration。Kimi PARL 是个 signal——他们的 K2.5 系列在 agentic benchmark 上的猛涨,主要不是 base model 进步,是 orchestration 训练把"系统能力"激发出来了。
接下来 12-18 个月,任何团队想做 SOTA agent 产品,都得在 orchestration RL 上下苦功。这篇综述就是地图。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我