LenVM:把"还剩多少 token"建模成 value——给 LLM 装上了一个 token 级长度刻度尺
核心摘要
你有没有遇到过这种尴尬:让 LLM 写"50 字以内的总结",它给你来 200 字;让它"用至少 800 字写",它 400 字就煞尾。Length control 是个老问题,但目前的所有解法——prompt 里加约束、训练时塞 length penalty、生成前用 predictor 估总长——全部停留在 sequence level。生成进行到一半,模型不知道自己"还该写多少"。
UCSC、Apple 等机构合作的这篇论文给出的方案叫 LenVM (Length Value Model):把"剩余生成长度"建模成一个标准的强化学习 value function——每生成一个 token 给一个常数负奖励,用 γ 折扣后得到一个 bounded、monotone 的 return 作为目标。supervision 零标注、稠密、无偏、可 scale,自动从采样的 rollout 里来。
效果让人有点惊讶:在 LIFEBench 的"严格等长"任务上,7B 开源模型套上 1.5B 的 LenVM,Length Score 从 30.9 干到 64.8,直接吊打 GPT-5.4、Claude Opus 4.6、Gemini-3.1-Pro 这些闭源旗舰。更狠的是 GSM8K 上 token budget=200 时,普通 truncate 只剩 6% 准确率,LenVM 引导下保持 63%。
一句话评价:这是把"经典 value learning"重新嫁接到 LLM 推理控制上的一篇范式型工作。
论文信息
- 标题:Length Value Model: Scalable Value Pretraining for Token-Level Length Modeling
- 作者:Zhen Zhang, Changyi Yang, Zijie Xia, Zhen Yang, Chengzhi Liu, Zhaotiao Weng, Yepeng Liu, Haobo Chen, Jin Pan, Chenyang Zhao, Yuheng Bu, Alkesh Patel, Zhe Gan, Xin Eric Wang
- 日期:2026/04/30
- arXiv:https://arxiv.org/abs/2604.27039
- 代码:https://github.com/eric-ai-lab/Length-Value-Model
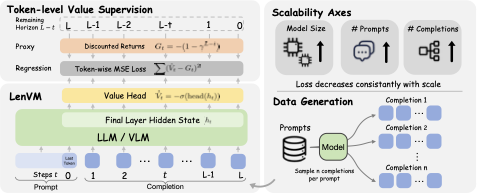
图1:把 autoregressive 生成看成 episodic 过程,每步给 -(1-γ) 的常数 reward,γ 折扣求 return,得到的 G_t = -(1-γ^(L-t)) 严格落在 (-1, 0),是剩余长度的单调有界变换。LenVM 头是个两层 MLP + sigmoid,输出 V(s_t) ∈ (-1,0)。
问题动机:现有 length control 全在"宏观尺度"
说实话,长度控制这事在工程里是个老痛点了。我之前做对话系统的时候,被产品经理盯着改了不下 10 次"输出别太长"——结果是什么呢?
- prompt 里写"50 字以内"——模型经常溢出,且不可控
- 训练时加 length penalty——sequence level,credit assignment 极差
- 生成前用 predictor 估总长——一次性决策,生成过程中没法调整
最大的问题不在某个具体方案上,而在所有现有方案都是粗粒度的。生成跑到第 30 个 token 的时候,模型其实可以"还剩多少能输出",但它没有这个内部信号。
LenVM 想解决的正是这个:"给我一个 token 级、稠密、连续的剩余长度信号。"
我看到这个 framing 的时候,第一反应是——这不就是 RL 里再标准不过的 value function 吗?果然作者就这么干了。
方法核心:把"剩余长度"变成 discounted return
一个非常优雅的 reduction
核心 trick 一句话讲清:
每生成一个 token 给一个常数负 reward:
那么从第 t 步开始的折扣 return 就是:
这个 G_t 有三个让人拍大腿的性质:
- bounded:始终在 (-1, 0),避免了 raw length 的 long-tail 问题(生成长度从几十到 32k+,直接回归会爆炸)。
- monotone:剩余越长,G 越接近 -1;越接近终止,G 越接近 0。是剩余长度的严格单调变换。
- Bellman 一致:\(G_t = r_t + \gamma G_{t+1}\),就是标准的 RL 值函数递推。
LenVM 直接学这个 V(s_t) = E[G_t]。监督信号四个好处:
- annotation-free:从采样的 rollout 直接计算,没有人工标注
- dense:每个 token 位置都贡献一个 target,不是 sequence 级一个
- unbiased:固定 rollout policy 下,realized G_t 是 V^π 的 unbiased MC 估计
- scalable:prompt × 每 prompt 采样数 = 训练数据,想要多少有多少
我看到这个 setup 的时候有点"对,就该这么做"的感觉——用 RL 的语言重新把 length modeling 形式化,所有 value learning 的工具立刻就能复用。
训练目标
minibatch token 平均 MSE:
其中 \(G_t^{(n)} = -(1-\gamma^{L^{(n)}-t})\) 是从每条采样轨迹精确算出的。
模型上:LenVM head 是个两层 MLP + sigmoid,挂在 base LLM/VLM 的最后一层 hidden state 上。
推理时怎么用:四种玩法
玩法 1:硬约束等长解码(Equal To / At Most / At Least)
decoding 时,每步先用标准截断策略拿到候选集 𝒱_t,再用 LenVM 给每个候选 token 打分 \(\hat{v}(x) = \hat{v}_\phi(s_t \oplus x)\):
- Equal To:把目标剩余长度 L-t 转到 value 空间得到 v,选 argmin |v̂(x) - v|
- At Least:选最 negative 的 v̂,favor 长继续
- At Most:选最接近 0 的 v̂,favor 早点结束
LIFEBench 结果:
| 模型 | Equal To Deviation↓ | Equal To Score↑ | At Most ↑ | At Least ↑ |
|---|---|---|---|---|
| GPT-4o | 74% | 35.5 | 77.9 | 98.5 |
| GPT-5.4-thinking | 131% | 47.8 | 72.7 | 98.9 |
| Claude-Opus-4-6-thinking | 87% | 53.2 | 67.4 | 100.0 |
| Gemini-3.1-Pro-Preview | 91% | 49.3 | 70.7 | 100.0 |
| Qwen2.5-7B-Instruct (无 LenVM) | 71% | 30.9 | 98.5 | 89.1 |
| + LenVM(1.5B) | 44% ↓27pp | 64.8 ↑33.9 | 96.1 | 99.5 |
| Qwen3-30B-A3B-Instruct + LenVM(1.7B) | 57% | 67.2 ↑30.4 | 99.4 | 99.8 |
看到这个表格我愣了一下——7B 开源 + 1.5B value head ≈ 9B 参数,把闭源旗舰按在地上摩擦。这个数据在 "Equal To" 这个细颗粒任务上太能打了。
原因其实直觉上很清晰:闭源大模型靠 prompt 做长度控制,本质是粗粒度的;LenVM 在每个 token 级别给出"还剩多少"的精确信号,是细粒度的。控制颗粒度的代差,让小模型 + 长度控制器干翻大模型纯 prompt 方案。
玩法 2:性能-效率 trade-off(exponential tilting)
用 LenVM 给 base distribution 做指数倾斜:
β < 0 时 favor 更短的 continuation。β=0 退化为 base model。
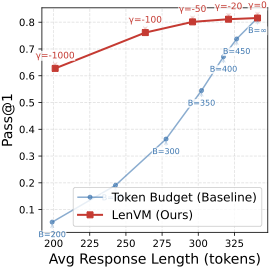
图2:Qwen2.5-3B-Instruct base + 1.5B LenVM。横轴是平均(截断后)生成长度,纵轴 Pass@1。蓝线是简单 token budget 截断方案,200 token 时只剩 6% Pass@1;红线 LenVM 引导在同样 200 token 处保持 63% Pass@1——差了一个数量级。
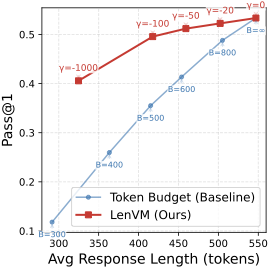
图3:MATH500 上的同款对比。LenVM 通过重新加权 token 选择,引导模型走它本来就拥有的"更短的成功路径",而不是粗暴地把超长的截断算错。
这里有个观察特别有意思:base model 本来就有能力用更短的思维链解题,只是 token 选择倾向于走长路径。LenVM 的作用是把模型的"短路径选择能力"激活——它没改 base model 的能力上限,而是改了实际走的路径。
玩法 3:first-token 总长预测
光是从 prompt 边界(s_0,还没生成任何 token),LenVM 就能给出预测的 total length——用 inverse \(L = \ln(1-\mu_u)/\ln \gamma\) 还原。这对 inference 的 scheduling、batching、KV cache memory planning 很有用。
玩法 4(论文留作 future work):作为 RL value baseline
LenVM 本质就是 length penalty 的 value function。PPO 训练时把它当 length-specific value baseline,可以做到 length 和 task 双路 advantage 解耦,credit assignment 比传统 sequence-level penalty 干净得多。
论文里这块只给了理论框架,没做实验——这是我觉得最有想象空间的下一步。
Scalability:value pretraining 的味道
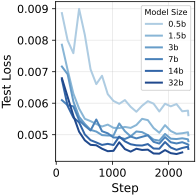
图4:从小模型到大模型,LenVM 的 length value 学习目标 test loss 单调下降。这是 scaling 的标志性曲线——意味着 LenVM 这套 supervision 是真正可 scale 的。
论文标题里的 "Scalable Value Pretraining" 不是夸张——LenVM 的训练数据是 OpenCodeReasoning-2 (1.42M) + WildChat (529k) + DeepMath-103K,规模本身就接近 SFT 级别。重要的是 supervision 完全自动,不需要标注 / 不需要 reward model / 不需要 preference data。
这一点工程上特别值得注意:LenVM 是当前少数能"无监督 scale value learning"的设定之一。RM、PRM 都受限于标注成本,LenVM 把这个瓶颈干掉了。
消融实验:几个判断都挺准
论文做了四个消融,我挑两个最关键的:
(a) Length-space 表示:对比 4 种 target——raw length + softplus、normalized length + sigmoid、log length + softplus、discounted return + sigmoid。结论:discounted return 一骑绝尘。原因是它和 autoregressive 的 Bellman 递推天然对齐,而 log length 只是 static scale transform,少了递推一致性。
(b) 折扣因子 γ:γ 大的时候压缩长 horizon 更激进,在生成早期预测更准;γ 小的时候 resolution 集中在末尾,在生成末尾预测更准。实践经验:让 99 分位长度 L_0.99 满足 1-γ^L_0.99 = 0.99,让几乎所有 horizon 都映射到 target space 的高分辨率区。
这个 γ 的选择经验我觉得挺有工程价值——比照着"95/99 分位的长度匹配高分辨率区间"这个 rule of thumb 来调,比盲调容易得多。
我的判断
亮点:
- 方法上有真正的优雅:把 length modeling 用 value function 形式化,不是工程 trick,是 reframe。一旦你接受这个 framing,annotation-free + dense + unbiased + scalable 全是自然推论。
- 数据让人服气:7B + 1.5B 干翻 GPT-5.4-thinking 这种结果不常见。Length Score 从 30.9 → 64.8 这种幅度,不是 marketing 数字。
- 应用面广:硬约束解码、性能效率 trade-off、长度预测、RL value baseline——一个模型四种用法。
- 工程友好:base model 不动,挂一个外置 value head 就能 work。1.5B 的 value head 引导 30B 的 base 也 work。
问题:
- 推理 latency 没正面对比:LenVM-guided decoding 每步要多一次 forward。论文承认"extra inference latency"是存在的,但没给具体数。生产环境部署的时候这个开销是真问题。
- RL 训练只画了饼:第 5 章整章是 commented out 的 RL 设计——理论框架给了,实验没跑。"LenVM 当 RL value baseline" 这个最有想象力的应用还是 future work 状态。
- 依赖 fixed rollout policy 假设:value 目标是 policy-conditioned 的。如果你换 base model 或 sampling 设置,理论上 LenVM 应该重新训。论文里没系统讨论这个 transferability。
- VLM 的实验偏少:只在 MathVista 上跑了一个 VL trade-off,long-context VL 任务(视频、长文档)的表现如何完全没测。
工程启发
如果你在做:
- 长度敏感的生成任务(摘要、字幕、代码块、答案模板):LenVM 是个非常实用的 inference-time 工具,特别是"等长"这种 prompt 控制不住的场景。
- 推理 cost 压缩:在 reasoning 类任务上想砍掉一半 token 又不丢精度,LenVM 的 exponential tilting 是个 Pareto 最优的选择。
- batching/scheduling 系统:first-token length prediction 给了一个非常便宜的 ETA 信号,对动态 batching、KV cache 预分配的工程化都有直接帮助。
- RLHF 团队:把 length 当成独立的 reward channel,配 LenVM 当 value baseline,可以让训练更稳定。这块论文还没做实验,但留下的设计空间是开放的。
最后说一个我自己的担心——LenVM 这种"细粒度控制器"的范式可能不止用在 length 上。任何具备 token 级单调性质的 metric,都可以套用相同 reduction:style intensity、verbosity、formality、专业度。我觉得 2026 接下来这条线会有不少跟进工作,"轻量 value head + 大 base model" 可能会成为一种新的推理控制范式。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我