当工具库膨胀到4万个,Agent该怎么"找工具"?UCLA这篇FitText把检索塞进了推理循环
核心摘要
做过 Tool-Use Agent 的人都知道一个现实问题:当你的 API 库从几十个长到几万个的时候,prompt 里塞 schema 这条路就直接走死了。退一步的常见做法,是先用用户原始 query 做一次向量检索拿 top-k 工具,然后把检索结果塞给 Agent 让它去用——所谓"先检索再行动"的静态方案。问题是,用户的话和工具的文档说的根本不是一个语言。"我的航班取消了帮我退款"和"Get the current status of a flight"中间隔着一道挺深的语义鸿沟,一次性检索基本没救。
UCLA 这篇 FitText 的切入点很干净:让 LLM 自己生成"伪工具描述"作为检索探针,并且把检索这件事直接嵌到 Agent 的推理循环里——什么时候检索、用什么 query 检索,由 Agent 根据当前任务理解动态决定。在此基础上更进一步搞了个 Memetic Retrieval:把候选描述当作种群跑演化算法,引入 crossover、mutation、fitness、tool memory 这一套。在 ToolRet(4.3 万工具)上把平均检索排名从 8.81 干到 2.78;在 StableToolBench(16,464 个 API)上端到端 pass rate 从 0.49 提到 0.73,绝对值涨了 24 个点。
但有个反直觉的发现挺值得聊:演化策略对基础模型的能力是高度依赖的。换成 Qwen3-30B 之后,Memetic 直接崩到 0.32,连最 baseline 的 Query Retrieval(0.348)都不如。你想想看,LLM 不够强,做演化只会放大噪声而不是炼出信号——这个观察其实把 AlphaEvolve 那条结论给反着验证了。
论文信息
- 标题:FitText: Evolving Agent Tool Ecologies via Memetic Retrieval
- 作者:Kyle Zheng, Han Zhang, Renliang Sun, Chenchen Ye, Wei Wang
- 机构:UCLA
- 提交日期:2026 年 5 月 4 日
- arXiv:2605.02411
- 会议:投稿 COLM 2026
为什么"先检索再行动"这套范式撑不住了
我之前在做一个内部 Agent 项目的时候踩过这个坑。最开始 API 池子不大,几十个工具直接灌 system prompt,Agent 表现还挺好。等到工具数量上 500 之后,模型开始幻觉 API 名、调错参数、context rot。改成 RAG 路线——先用 query 做一次向量检索,拿 top-20 工具塞进上下文——立刻好转,但用了一段时间又开始出问题:用户的需求经常是开头说一半,中间根据返回结果才意识到自己真正想要的是什么。一次性检索拿到的工具集合,到第三步基本就用完了。
这两条路,论文里把它们归纳得很清楚:
- Schema injection:把 candidate tools 写死在 prompt 里。规模一上来就是 context rot,且需要人工策展,不现实。
- Static root-query retrieval:用初始 query 检索一次。问题在于用户意图本来就是流动的,一次性检索根本捕不到完整需求。
两种范式的共同假设都是"任务一开始就能确定要用哪些工具",但真实的 Agent 任务里,工具需求是边推理边浮现的。
更糟的是中间的语义鸿沟。query 是高层目标导向的("帮我退款"),工具描述是功能说明书风格("获取航班当前状态"),通用 embedding 模型并没有针对这种跨域语义对齐做过训练。你直接拿 query embedding 去 cos 相似度,召回结果经常前几名都是"看起来沾边但用不了"的工具。
下面这张图把问题讲得特别直观——上半部分是传统的 query-based 检索,召回了 IssueRefund 但缺了前置的 CheckFlightStatus 和 FindBookingInfo,直接 call 就 "error": "Missing booking information"。下半部分是 FitText 的做法:Agent 先生成一个"我大概需要查这个航班的状态、找订单"的 pseudo-tool description 去检索,拿到正确工具调完之后,根据返回结果再生成下一个"我现在需要确认退款条件"的描述继续检索。检索是动态、增量、跟着推理走的。
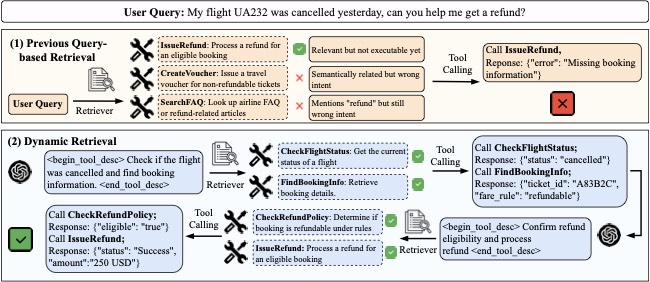
图1:传统 query-based 检索一次性失败的典型场景,对比 FitText 的动态检索如何分步召回 CheckFlightStatus → FindBookingInfo → CheckRefundPolicy → IssueRefund 这条正确链路
核心思路:让 LLM 写"伪工具描述"去检索
FitText 最核心的 idea 其实可以一句话说清楚:不要拿用户原话去检索,让 LLM 先想象"我现在需要的工具大概长什么样",把这个想象出来的工具描述当作 query 去检索。
这个思路其实在 RAG 圈子里有先例——HyDE、Query2Doc 都是先让 LLM 生成一个假设性回答,再拿这个回答去检索。FitText 是把它迁移到工具检索场景:因为生成 pseudo-tool 的过程要求模型显式去想"输入是什么、输出是什么、功能是什么",这种格式天然就比用户 query 更接近真实工具文档的语义空间。
形式化一点,给定 pseudo-tool description \(d\) 和工具库 \(\mathcal{C} = \{t_1, ..., t_n\}\),相关性算的就是 SimCSE 嵌入下的 cosine:
然后取 top-k 注入到 Agent 的 function schema 里。简单。但围绕"怎么生成 \(d\)、怎么用反馈迭代 \(d\)",论文给出了一个从快到慢的策略谱系:
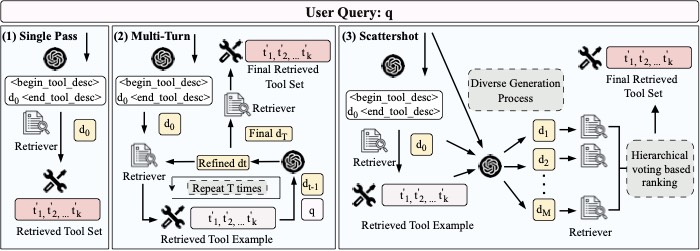
图2:Single-Pass / Multi-Turn / Scattershot 三种策略的工作流对比。Single-Pass 最快但容易错;Multi-Turn 用检索回来的真实工具示例来精炼 \(d\),但容易陷入局部最优;Scattershot 在高温度下平行采样 M 个不同的 \(d\),最后用层次投票聚合
Single-Pass:最 baseline 的版本
Agent 看到 query,生成一个 \(d_0\),检索一次,结束。这一步的意义在于证明:哪怕只生成一次伪工具描述,效果也比直接拿 query 去检索好——因为 \(d_0\) 已经在工具文档的语义空间里了。
Multi-Turn Refinement:用检索结果反过来教 LLM
Single-Pass 的问题是没法纠错。Multi-Turn 干的事就是让 Agent 把检索回来的真实工具描述(叫 exemplars \(\mathcal{B}^{(t)}\))作为参考,去精炼下一轮的 \(d^{(t)}\):
直觉很顺——你让模型看了一眼真实工具长啥样,下次它写描述就会更贴合实际词汇和粒度。温度调到 \(\tau \leq 0.7\) 保持收敛而不是发散。
但这条路是单轨迹的,\(d_0\) 起始位置不好就容易卡在局部最优。
Scattershot:population 级别的多样性
Scattershot 的解法是平行开 M 个不同的 \(d_i\),温度直接拉到 \(\tau = 1.5\) 鼓励多样化采样。每个 \(d_i\) 各自检索一遍,结果用层次投票聚合:被多个 description 共同召回的工具优先级最高,再考虑平均排名和平均相似度。
这个设计挺合理的——pseudo-tool description 本质是个 noisy hypothesis,sampling 多个互补的版本可以覆盖更广的 description 空间。
Memetic Retrieval:把上面两条路缝起来跑演化
Scattershot 的问题在于"打一枪就走"——M 个候选生成完直接投票,前面几代的信号没被用起来。Memetic 的思路就是:既然每个 \(d_i\) 都有 fitness——用检索质量度量,那就让它们跑多代演化。
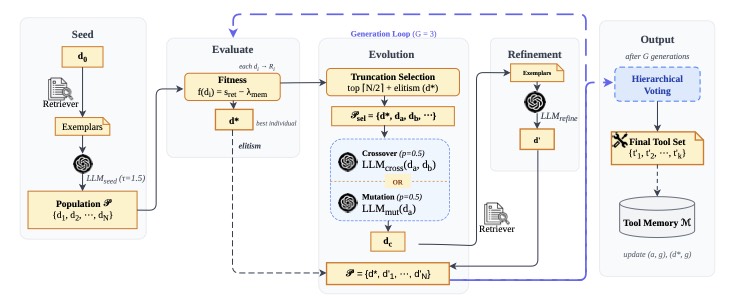
图3:Memetic Retrieval 的完整工作流。每代选出 top N/2 + 精英,剩下名额用 crossover(50% 概率)或 mutation(50% 概率)填,新生成的 offspring 再走一轮 Multi-Turn 风格的 local search 精炼,然后进入下一代。共跑 G=3 代
整套机制最有意思的是 fitness function:
前半部分 \(s_{\text{ret}} = 0.7 \sigma_1 + 0.3 \bar{\sigma}_3\) 是 top-1 加上平均 top-3 的 cosine 相似度,奖励高质量召回。后半部分是基于 Jaccard 相似度的 memory penalty——如果你这次召回的工具集和 tool memory \(\mathcal{M}\) 里之前召回过的某一组重合超过 30%,就扣 0.5 分。
这个设计巧在哪?两个层面互补:retrieval score 在嵌入语义层面打分,Jaccard penalty 在工具集合的语法层面打分;前者保质量,后者保多样性。同时由于 API 输出本来就有随机性,这个 memory 是 soft taboo(软禁),不是 hard ban——记录"不要再钻这个方向",但不是"绝对不能再来"。
种群层面看,penalty 隐式地协调了整个 population 朝未探索区域走。从工程上讲,这个设计避免了我之前在做类似系统时遇到的一个老问题:population 跑着跑着所有个体都收敛到同一个局部最优。
实验:到底涨了多少
检索-only 的纯比拼:ToolRet
ToolRet 有 4.3 万个工具,分 Code / Customized / Web / ToolBench 四个域。论文报告 NDCG@5、Precision@5、Recall@5、Comprehensiveness@5 四个指标,最后给一个跨指标的平均排名。
挑关键的看:
| 策略 | GPT-4.1-mini Avg Rank | Qwen3-30B Avg Rank |
|---|---|---|
| Query Retrieval(baseline) | 8.81 | 8.81 |
| Single-Pass | 6.41 | 5.62 |
| Multi-Turn | 3.91 | 3.44 |
| Scattershot | 4.25 | 3.94 |
| Memetic | 2.78 | 5.84 |
几个值得划重点的现象:
只要把 query 换成 LLM 生成的 pseudo-tool description,全面碾压。哪怕是最简单的 Single-Pass,也把平均排名从 8.81 干到 5.62—6.41。这印证了"语义鸿沟"这个 motivation 不是伪命题。
Multi-Turn 和 Scattershot 各有所长。Multi-Turn 在 Web 和 ToolBench 这种"工具描述比较规范、相似度高"的域上更猛——迭代精炼有信号可学;Scattershot 在 Code 和 Customized 这种"用法变化大、措辞分散"的域上占优——多样化采样能覆盖更广的 phrasing。这个分裂其实挺合理,论文没有粉饰说"我们方法到处都最强"。
Memetic 在纯检索任务上的优势没那么压倒性。GPT-4.1-mini 下平均排名 2.78 确实最好,但在 Qwen3-30B 下反而掉到 5.84,比所有其他策略都差。这个反差是后面 ablation 分析的重点。
端到端工具调用:StableToolBench
真正能体现"动态检索 + 演化"价值的是端到端任务,因为这里有 tool execution feedback 这个真信号。StableToolBench 把任务按所需工具数分成 G1(单工具)、G2(多工具)、G3(最复杂)三档:
| 策略 | G1-I | G1-T | G1-C | G2-I | G2-C | G3-I | Avg |
|---|---|---|---|---|---|---|---|
| Query Retrieval | 0.56 | 0.56 | 0.53 | 0.42 | 0.48 | 0.42 | 0.49 |
| Single-Pass | 0.59 | 0.60 | 0.61 | 0.55 | 0.57 | 0.51 | 0.57 |
| Multi-Turn | 0.61 | 0.59 | 0.69 | 0.51 | 0.51 | 0.48 | 0.56 |
| Scattershot | 0.69 | 0.61 | 0.63 | 0.56 | 0.55 | 0.53 | 0.59 |
| Memetic | 0.72 | 0.69 | 0.78 | 0.70 | 0.76 | 0.75 | 0.73 |
24 个绝对点的提升。这个数字单看还行,但放到 StableToolBench 这个相对成熟的 benchmark 上是相当能打的。
更有说服力的是G2/G3 这类需要多工具协同的复杂任务上的提升:从 0.42—0.48 干到 0.70—0.76,绝对增益 22—34 个点。论文里有句话我特别认同:"Memetic turns that ambiguity into an exploration signal by searching over alternative pseudo-tool descriptions rather than committing to a single rule-based match." 多工具任务的难点恰恰在于 query 模糊、单一规则匹配不稳定,演化搜索把这种模糊性当成了探索信号。
但同时我也注意到一个细节:Multi-Turn 在 G2/G3 上反而不如 Single-Pass(0.51 vs 0.55,0.48 vs 0.51)。论文的解释是单轨迹精炼容易收敛到局部最优,复杂任务下反而被"精炼"带偏。这个反直觉现象其实是 Memetic 之所以需要 population-based 设计的最强证据。
真正有意思的两个发现
发现 1:检索才是瓶颈,不是 planning
这个 claim 我第一次看到的时候挺意外的。我们这个圈子过去两年一直在 planning-centric 的范式里打转——什么 ToolChain、ReAct 加强版、Agent 的 reflection 机制等等。FitText 的消融做了一个很关键的对照:scaling analysis model 能在所有策略上稳定提升检索质量,但 scaling planner 不行*——这里的 analysis model 指的就是写 pseudo-tool description 的那个 LLM。
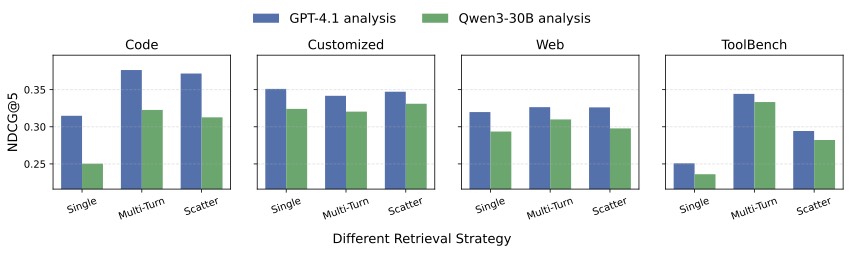
图4:Analysis model(生成 pseudo-tool description 的 LLM)从 Qwen3-30B 升级到 GPT-4.1 之后,Single-Pass / Multi-Turn / Scatter 三种策略在 Code / Customized / Web / ToolBench 四个域上的 NDCG@5 几乎全线上涨,尤其在 Code 和 ToolBench 上提升明显
这个发现的意义在于:它把 Agent 改进的注意力从"让模型规划得更聪明"重新拉回到"让模型能找到对的工具"。如果你的工具召回阶段就丢了关键 API,下游 planner 再聪明也没用。
我之前自己做项目时也有类似感觉——很多看起来像是"模型 reasoning 不行"的失败案例,深究一下其实是工具召回阶段就召错了。FitText 这个观察算是把它系统化地说出来了。
发现 2:演化只对足够强的基础模型有效
这个发现是这篇论文最让我皱眉、也最值得后续工作深挖的地方。Memetic 在 GPT-4.1-mini 下 pass rate 73.4%,换成 Qwen3-30B 直接掉到 32.2%——比静态 Query Retrieval 的 34.8% 还低。
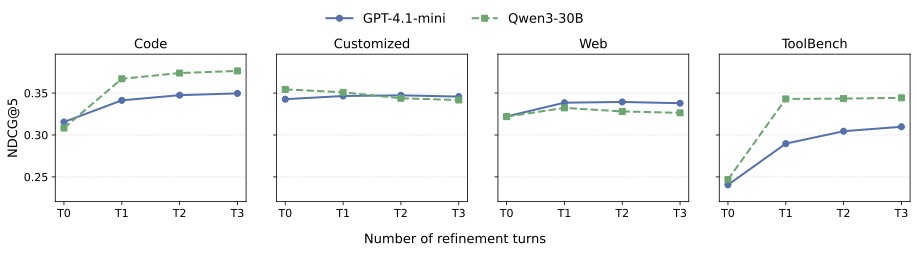
图5:Multi-Turn 精炼轮数从 T0 到 T3 的曲线。横向看,单轨迹精炼很快就 plateau;纵向对比两个基础模型,Qwen3-30B 在某些场景下精炼曲线还更陡,但这种局部表现不能掩盖它在 Memetic 框架下整体崩塌的事实
论文给出的解释:当基础模型不够强时,diversity-generating moves 和 depth-generating moves 会一起退化——前者指 crossover、mutation、更大种群,后者指迭代精炼——更深的精炼和更大的种群都在主动降低 pass rate,而不是提升。演化搜索把代际之间的噪声放大了,而不是炼出信号。
这反过来等于说:LLM 必须强到能当一个"称职的语义算子",crossover 出来的 offspring 要在意义层面合理、mutation 不能产生胡言乱语、refinement 真的要带来质量提升。任何一环掉链子,整个演化循环都会变成噪声放大器。
这个发现挺残酷的——对工业界用开源模型部署 Agent 的同学是个直接的警告。Memetic 这套方法不是 plug-and-play 的,你得先掂量你的基础模型够不够格。论文里把这个比作 AlphaEvolve 结论的"反向版本"——AlphaEvolve 证明前沿模型能把 diversity 复合成 discovery,FitText 证明弱模型只能把 diversity 复合成 noise。
说实话,这个反向结论的工程意义比 Memetic 本身的 SOTA 数字还重要。它给了一个明确的部署边界:用 GPT-4.1-mini 这个级别及以上的基础模型再上 Memetic,否则老老实实用 Multi-Turn 或 Scattershot。
我对这篇工作的判断
先说我喜欢的几点:
问题切得很准。"工具检索是 Agent 性能的真瓶颈"这个 claim 是这篇论文最值钱的洞察之一。过去两年大家在 planner、reflection、self-critique 上花了太多力气,retrieval 这一侧的工程化投入相对不足。这篇文章用消融数据给了一个清晰的方向。
伪工具描述这个抽象很优雅。把 LLM 用作 query rewriter 不新鲜,但把它特化成"生成符合工具文档风格的伪工具描述"是个干净的特化。对工程来说,这意味着不需要对 retriever 做任何改动——直接把 LLM 当 query 改写器接进去就能用,零训练成本,model-agnostic、orthogonal 这些设计目标真的兑现了。
Memetic 的 fitness function 设计有想法。语义层 + 语法层的双层 penalty 配合 soft taboo 的 tool memory,是个能反复借鉴的工程模式。我觉得这套机制单独拎出来用在别的"基于 LLM 的搜索"场景(prompt optimization、code search 等)也挺有迁移空间。
但也有几个地方让我不太满意:
对比的 baseline 不够强。论文主要对比的是 Query Retrieval 这种 vanilla baseline,但同期工作里 ToolRerank、COLT、AnyTool、MCP-Zero 这些方法都没在主表里出现。Related Work 里提了一下,但没给硬对比。Memetic vs Single-Pass 涨 14 个点很漂亮,但 Memetic vs ToolRerank 是几个点?这个数字论文没给,我是觉得有点回避。
Memetic 的复杂度成本说得太轻描淡写。论文末尾一句"that cost is paid once at retrieval time and amortized across the episode"就把成本话题带过去了。但 Memetic 一次检索要跑 G=3 代、每代 N=6 个体、每个个体还要做 LLM-driven crossover/mutation/refinement,token 开销和延迟都是 Single-Pass 的几十倍。在生产环境里,retrieval latency 直接影响用户体验,这个 trade-off 应该被更详细地讨论。
"Memetic 在弱模型下崩盘"的现象虽然诚实地说出来了,但没有给出可操作的边界。到底多强算"competent semantic operator"?是 70B 起步?还是要 GPT-4 级别?没有给一个量化标准,工程上很难直接拿来用。
工程上的几点启发
如果你正在做 Tool-Use Agent,这篇论文有几个直接可借鉴的点:
第一,先把"先检索再行动"改成"边推理边检索"。哪怕不上 Memetic 这么重的方案,光是把检索 trigger 从"开局一次"改成"Agent 主动请求"就能拿不少收益。论文的 strategy trigger 机制(用 <begin_tool_desc> 这种特殊 token 让 Agent 显式发起检索)是个干净的实现模式。
第二,Single-Pass 是性价比极高的 quick win。不需要任何复杂 infra,就让 LLM 在检索前先生成一段 pseudo-tool description,效果就比直接拿 query 检索好不少。这是个真的零成本的优化。
第三,别盲目上 Memetic。如果你的基础模型不是 GPT-4 级别,Multi-Turn 或 Scattershot 大概率是更稳的选择。Memetic 是上限更高但下限更低的方案,需要先测一下你的模型在 crossover/mutation 这种 high-level 操作上的可靠性。
第四,tool memory + Jaccard penalty 这套机制可以单独拿出来用。哪怕不做演化搜索,光是加一个"避免重复召回相似工具集"的 soft penalty,对长链 Agent 任务也很有用——避免 Agent 反复在同一批工具上打转。
收尾
这篇论文我读完最大的感受是:它认真回答了一个被忽视的问题,而且回答得相当克制。没有"我们最早"、没有"颠覆",把 retrieval 这个 Agent 上游环节的天花板捅高了一截,同时也老实地告诉你这套方法在哪些情况下会翻车。
对我个人而言,最值得带走的是两个观察:检索是 Agent 的真瓶颈、演化方法对基础模型能力的高度敏感性。前者重新校准了我对 Agent 改进路径的优先级判断;后者给开源模型部署演化算法泼了一盆冷水,但这盆冷水浇得很必要。
如果你也在做 Agent 工具调用相关的工作,这篇论文值得花一两小时认真读一遍——尤其是方法部分关于 fitness function 和 strategy trigger 的设计细节,比 paper 摘要里看到的要丰富得多。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我