当 LLM 不断"总结过去的经验",记忆反而变坏:Agentic Memory 的隐性陷阱
核心摘要
近两年 LLM agent 圈子里有个很受欢迎的范式:agent 把过去 trajectory 蒸馏成文本 lesson,存进 memory bank,下次任务从这里 retrieve;随着 agent 不断跑、不断 consolidate,memory 越来越精炼,agent 越来越强——所谓"无需参数更新的自演化 agent"。代表系统包括 Reflexion、ExpeL、AWM、ACE、Dynamic Cheatsheet、CLIN 等。
这篇论文做了一件让整个范式不安的事:系统地证明今天的 LLM 不是可靠的 memory consolidator。每一次 consolidation 都是一次有损重写——有用细节被丢、虚假规则被引入、原本有效的 abstraction 在反复 rewrite 中漂移。最 striking 的实验:
- 在 ARC-AGI 上挑出 19 道 GPT-5.4 无记忆情况下 100% 解出的题
- 把 ground-truth solution 喂给它做 consolidation
- 然后再让它解这些题——GPT-5.4 在 46% 的题上失败
输入是它自己解对过的题 + ground-truth 答案,consolidation 之后反而做不出来了。这不是 noisy trajectory 的问题,是 consolidation 步骤本身的问题。
实验跨 ALFWorld、ScienceWorld、WebShop、AppWorld 和作者新构造的 ARC-AGI Stream 五个环境,结论很一致:memory utility 先上升、后下降,最终甚至跌破 no-memory baseline。最 robust 的 baseline 反而是最朴素的 episodic-only——保留 raw trajectory 不做任何 abstraction,比所有 consolidator 都不差。
读完我的感受是:这是 2026 年最该被 agent 圈子认真看的"反范式"论文。它没有否定 "memory 有价值",但它否定了"每次交互都触发 consolidation"这种 architectural choice。
论文信息
- 标题:Useful Memories Become Faulty When Continuously Updated by LLMs
- 作者:Dylan Zhang 等
- arXiv:https://arxiv.org/abs/2605.12978
- 会议:NeurIPS 2026 投稿
现象描述:什么叫"useful memories become faulty"
我先把这个奇怪的现象讲清楚。考虑一个典型的 agentic memory 流程:
- Agent 收到一个 task
- Agent 自己解,或者直接用 ground-truth 演示(experience 来源)
- 把这次 trajectory distill 成一条 textual lesson(如"在 ALFWorld 里取物之前要先 open container")
- 存进 memory bank
- 下次遇到类似 task,retrieve 这些 lesson 注入到 prompt
现在的问题是 step 4——memory bank 不是只读的,它会不断被 LLM rewrite/merge/refine(这是 AWM、ACE 等系统的核心机制)。每次 rewrite 都让 LLM 看着现有 memory + 新 trajectory,吐出新一版 memory。
直觉上这应该越来越好:memory 越来越精炼,错误的 lesson 会被改正、相关的 lesson 会被合并。
但论文实验显示恰好相反:
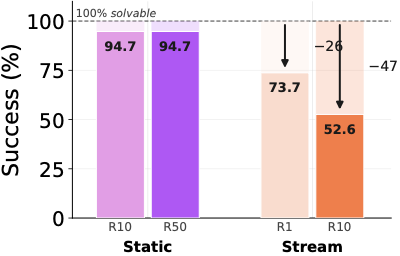
图1:19 道 ARC-AGI 题,GPT-5.4 在 no-memory 条件下 100% 解出。把 ground-truth solution 通过 consolidation loop 喂进去,再让它解这些题——准确率掉到 54%。这是最 clean 的实验:输入完全没有 noise,问题完全是模型自己能解的,consolidation step 本身把它搞砸了。
这个 100%→54% 不是 cherry-pick。在 ScienceWorld 上:分数先在 step 20 附近 peak,到 step 100 下降,降到比 no-memory baseline 还低。在 WebShop 上:AWM 在 8 个样本时是 0.64,扩到 128 个样本时跌到 0.20——而 no-memory baseline 就是 0.20。也就是说扩大 memory 把它自己的收益完全抹掉了。
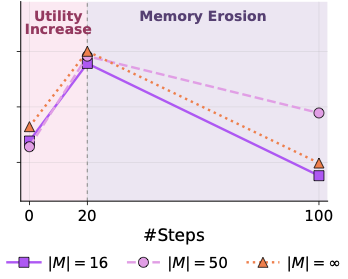
图2:ScienceWorld 上每个 memory size 的 score 都呈"先升后降"的形状,部分配置最终降到 no-memory baseline 以下。这是 utility curve 非单调的最直接证据。
三个机制:为什么 consolidation 会出错
论文把 faulty memory 的根源归结为三个 mechanism,每个都有具体实验佐证:
Mechanism 1:Misgrouping
Agent 把不同结构的 episode 错误地 pool 到同一个 abstraction step 里。异构 batch 比同构 batch 退化更快。
实验上:
- Static-Group(按 task family 分组 consolidate)> Static-All(所有 task 混着 consolidate)
- 在 streaming 设定下,heterogeneous batch 比 homogeneous batch 退化得更快
直观理解:当你让 LLM 看 5 个 ALFWorld 取物任务 + 5 个 WebShop 购物任务 同时做 abstraction,它会试图 unify 这两类——产生一些 over-generalized、对两边都没用的 lesson。
Mechanism 2:Lost Applicability Conditions
即使 grouping 对了,abstraction 步骤会剥离 lesson 的适用条件。
比如原 trajectory 里的 lesson 是"当 cabinet 是 locked 时,先 unlock"。但 LLM 在 consolidate 时简化成"先 unlock cabinet"——applicability condition "when locked" 被丢了。这条 over-generalized lesson 会干扰 neighbor task(cabinet 不 locked 时多此一举)。
Mechanism 3:Overfit to Seen Instances
当 input stream 比较 narrow(重复 task 多),abstraction overfit 到具体 instance,泛化到同 family 其他 task 时反而退化。
这跟 ML 里 overfit 的 dynamics 类似,只不过载体是 textual memory 而非 model parameter。
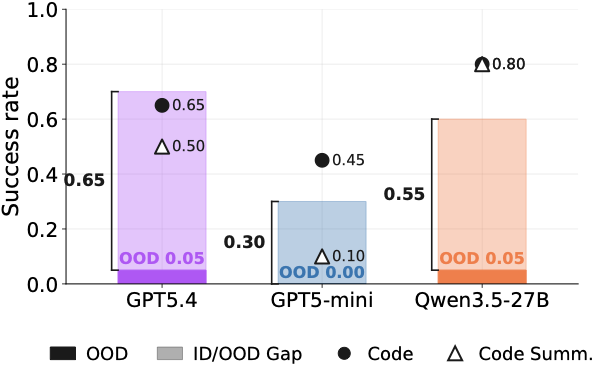
图3:在 ARC-AGI Stream 上,agent 反复看相同 task family 的 instance 后,memory overfit 到具体例子,导致同 family 其他 instance 表现下降。
Consolidation Schedule 本身是个独立变量
论文最有意思的一个 finding 是:同一份 trajectory pool,consolidation schedule 不同,最终 memory 质量天差地别。
具体对比:
- Static-All(所有 trajectory 一次 consolidate)
- Stream(按 batch 增量 consolidate)
- Static-Group(按 task family 分组 consolidate)
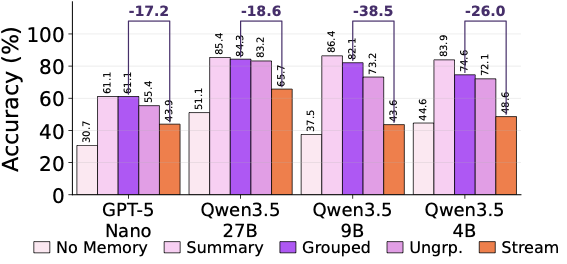
图4:固定 trajectory pool 的前提下,Stream(增量更新)的最终 memory 比 Static-All(一次性 batch 处理)更差。原因是早期 abstraction 会 anchor 后续的 rewrite——前期一个小错误,会被后续 consolidation 当成 context 反复 reference,errors 会复利累积。
这个结论对工业实践影响巨大。如果你的 agent 跑在生产环境里,按交互 streaming 更新 memory(绝大多数现有系统的做法)——你的 memory 一定比"周期性地 dump trajectory pool 然后一次性 consolidate"质量更差。
A strong memory is not a fixed point. 一个高质量的起始 memory,在持续 consolidation 下也会退化。论文用 GPT-5.4 做 Static-Group 得到一个 strong starting memory,然后用 GPT-5-nano 继续 stream consolidate 同一个 trajectory pool——utility 在三个 evaluator 上都一致下降。
意思是:memory 不是 fixed point。即使你已经有一个完美的 memory,你只要继续让 LLM rewrite,它就会变坏。
解决方案:Two-Process 架构 + 由 agent 自己决定 Retain/Delete/Consolidate
论文不只描述问题,还给出了一个很认知科学风格的解药:
借鉴神经科学里的 Complementary Learning Systems (CLS) 理论——人脑有 fast episodic store(海马体)和 slow schema-forming store(皮层),两者架构上分离,consolidation 是 gated 的(只在 schema fit 时触发),不是每次都强制。
论文设计的 ARC-AGI Stream 实验里,agent 在每一步可以选择三种 meta-action:
- Retain:保留 raw episode 在 episodic buffer
- Delete:删掉无用的 raw episode
- Consolidate:触发 abstraction(写入 abstract store)
对比两种 regime:
- Auto:agent 自己决定是 retain 还是 consolidate
- Force:每次交互都强制 consolidate,episodic entry 不保留
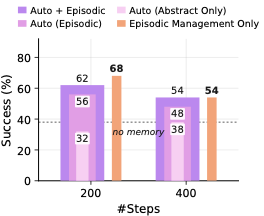
图5:纯 episodic store 的 utility 接近 Auto;只用 abstract store 反而 collapse 回 no-memory baseline。Force 在两个 backbone 上都 underperform Auto。结论:episodic-first,abstraction 应该 opt-in。
实验观察:
- Episodic store 贡献了大部分增益:移除 episodic 只保留 abstract lesson,accuracy 掉回 no-memory baseline
- Episodic-only(关闭 abstraction)match 或 exceed Auto:在他们的实验里,根本不做 abstraction 都行
- Force 全程低于 Auto:强制 consolidation 损失大于压缩收益
而且看 agent 自己的行为:给它选择权,它 by default 把 episodic buffer 占满,让 abstract store 保持稀疏。也就是说,模型自己也"知道" episodic evidence 更可靠,只是被人工设定 forced 进 rewrite loop。
跟现有 agentic memory 系统的关系
论文点名挑战了好几个流行系统的核心假设:
| 系统 | 假设 | 论文观点 |
|---|---|---|
| CLIN | Update memory after every interaction | 强制 consolidation 是问题源头 |
| Agent Workflow Memory (AWM) | Abstract workflow 越精炼越好 | Stream consolidation 比 one-shot 差 |
| Dynamic Cheatsheet | Cheatsheet 不断 refine | Refine 过程是 lossy rewrite |
| ACE | Continuous experience compression | Compression 会 overwrite evidence |
注意论文不是说这些系统完全没用——它们在短期、small-scale 上常常 work(utility 早期上升)。问题是长期、large-scale 上 utility 下降,而且现有 paper 的 evaluation 往往只看短期。
论文的建议非常 actionable:
- Episodic and abstraction stores should be architecturally distinct,不要塞进一个 rewrite loop
- Consolidation 要 gated,由 agent 自己决定何时触发,而不是每次交互都触发
- Episodic-only baseline 要被当作 must-have control——任何 abstract-memory 方法都应该 outperform 它,否则你的 abstraction 没贡献
我的判断:值不值得读?
强推,尤其是如果你在做 agentic memory、agent self-improvement、long-horizon RL,或者在工业上跑长期 agent。
亮点:
- 范式级的批判:这是 agentic memory 领域第一篇系统化地 question "update-after-every-interaction" 的论文。这种 paradigm-level critique 在 AI 文献里很罕见
- Clean experiment:100%→54% 的 ARC-AGI 实验把 input quality 完全 control 住,是经典的"isolate the bug"实验设计。读到这里我直接想 standing ovation
- 多 environment 跨验证:ALFWorld + ScienceWorld + WebShop + AppWorld + ARC-AGI Stream——结论的 robustness 不可否认
- 认知科学的理论根基:CLS 理论的引用不是装饰,是真的指导了 architecture design
- 可执行建议:episodic-only baseline、grouped consolidation、agent-gated abstraction——三条都是工程上立刻能 adopt 的
问题/局限:
- 没解决根本的 scaling 问题:episodic accumulation 长期下 buffer 无限增长。论文承认这是 open problem 但没给方案
- 没测 retrieval 这一边的影响:实验中所有 memory entry 都注入 context。但实际系统通常用 retrieval(top-K),retrieval quality 也会影响实际效果
- 没区分 LLM 的能力 vs 范式问题:可能 GPT-5.4 不够好,未来更强的 LLM 真的能做好 consolidation?论文不能完全排除这个 hypothesis
- Abstract store 完全没用?:感觉这个 conclusion 太激进。某些 long-horizon task(如几百步 plan)应该是需要 abstraction 才能装下的——只看 episodic 也不行
- 缺乏 mechanism 层面更深的分析:三个 mechanism(misgrouping、lost conditions、overfit)是 high-level 的描述,但 inside LLM 的 attention/representation 层面到底发生了什么没有展开
对工程实践的建议:
- 如果你在 deploy agentic memory 系统:立刻去 measure utility curve 是不是非单调的,如果是,把 consolidation 频率降下来或加 episodic baseline
- 新系统设计:默认 episodic-first,abstraction 作为 opt-in、且 group by task family
- Benchmark 改造:对比时一定加 episodic-only control,不只是 no-memory baseline
- Stream → Batch 切换:如果你的应用允许,周期性地把 trajectory pool dump 出来做 one-shot consolidation,不要每次交互都 update
收尾
这篇论文的位置很微妙——它不是在某个 benchmark 上又涨了几个点的"渐进改进"工作,而是在 question 整个 agentic memory 范式的 architectural choice。
对于一个研究方向能不能 sustain,这种"反范式"的工作非常关键。它会强制整个社区重新思考一些被默认的假设。
我看完最深的一个 reflection 是:"自我演化的 LLM agent"在 2024-2025 是个特别 hype 的概念——大家都觉得"agent 不断从经验学习、无需参数更新地变强"是个 obvious 的方向。这篇论文给出了一个让人 sober 的提醒:LLM 当前还做不好 consolidation 这件事,不要 over-design 一个建立在错误前提上的复杂系统。
下一步该追的问题:
- 能不能让 LLM 学会"何时该 abstract"?论文说 agent 自己倾向于不 abstract——这是个 reasonable 默认,但 long-horizon 任务里 abstract 应该是必要的
- 架构上 episodic 和 abstract 分离后,retrieval 怎么协调?什么时候应该用 episodic、什么时候用 abstract?
- 未来更强的 LLM 真的能做好 consolidation 吗?这是 fundamental capability 问题还是 fundamental impossibility?
如果你在做 agent,请认真看这篇,至少把 episodic-only baseline 跑起来。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我