δ-mem:一个 8×8 的矩阵,能给 LLM 当"长期记忆"吗?
核心摘要
LLM 长期记忆这个问题,最近一两年讨论得越来越多。Long-term assistant、long-horizon agent——核心需求都是模型要能跨 session 累积、复用历史信息。最直接的思路是扩 context window,但扩到百万 token 也不解决 context degradation——一旦上下文太长,模型自己就开始 "context rot" 选择性忽略关键信息了。
现在的 memory 方案分三派:
- Textual Memory(MemGPT 那类):把记忆存成文本注入 context。灵活但受 context 限制
- Outside-channel Memory(RAG-style):外部检索模块。模块化但和 backbone 对齐困难
- Parametric Memory(LoRA、prefix tuning):encoding 进参数。高效但 static,跟不上动态信息
这篇 δ-mem 走第四条路——给 frozen full-attention backbone 加一个 8×8 的 associative memory 矩阵,用 delta-rule 在线更新,readout 作为低秩 correction 直接修改 backbone 的 attention 计算。
效果:8×8 的 memory state(这个 size 离谱地小),平均分提升到 backbone 的 1.10×,比最强 non-δ-mem baseline 高 1.15×。在 memory-heavy 任务上提升更显著——MemoryAgentBench 1.31×,LoCoMo 1.20×,TTL 子任务从 26.14 几乎翻倍到 50.50。General capability 几乎不掉。
读完我的第一反应是:这又是把 Linear Attention / State Space Model 的思想,作为 plug-in 加到 frozen Transformer 上的尝试——但做得比之前几个工作都更干净。8×8 这个 size 真的让我有点震惊。
论文信息
- 标题:δ-mem: Efficient Online Memory for Large Language Models
- 作者:Jingdi Lei, Di Zhang, Junxian Li, Weida Wang, Kaixuan Fan, Xiang Liu, Qihan Liu, Xiaoteng Ma, Baian Chen, Soujanya Poria
- 机构:南洋理工大学、复旦大学、Mind Lab、上海交通大学、香港中文大学、香港科技大学(广州)
- arXiv:https://arxiv.org/abs/2605.12357
为什么单纯扩 context 不解决问题?
我先把这个问题的 framing 讲清楚。
LLM 作为 long-term assistant,每次对话进来时,model 需要"记得"之前几天/几周的交互。最 naive 的方案:把所有历史对话拼到 context 里。
这个方案的问题有两层:
第一层(性能层):Standard Softmax Attention 是 \(O(N^2)\) 复杂度。100K context 的 attention 是 10B 个元素,prefill 一次要几秒。生产场景里,每次对话都付这个代价不现实
第二层(更阴险的一层,质量层):Context rot / context degradation。这两年 paper 反复在证一件事——超长 context 里,model 自己会选择性忽略大部分信息,关键 token 经常 retrieve 不出来。OpenAI 1M context、Gemini 1.5 这些模型确实能"吞下" million token,但能不能"用好" million token,是完全不同的两件事
所以业界共识是:纯扩 context window 不解决 memory problem。需要更精巧的机制——用更紧凑的方式存储历史信息,动态更新它,让 backbone 在 test-time 能有效使用。
δ-mem 的核心 idea:Linear Attention State 作为"挂件"
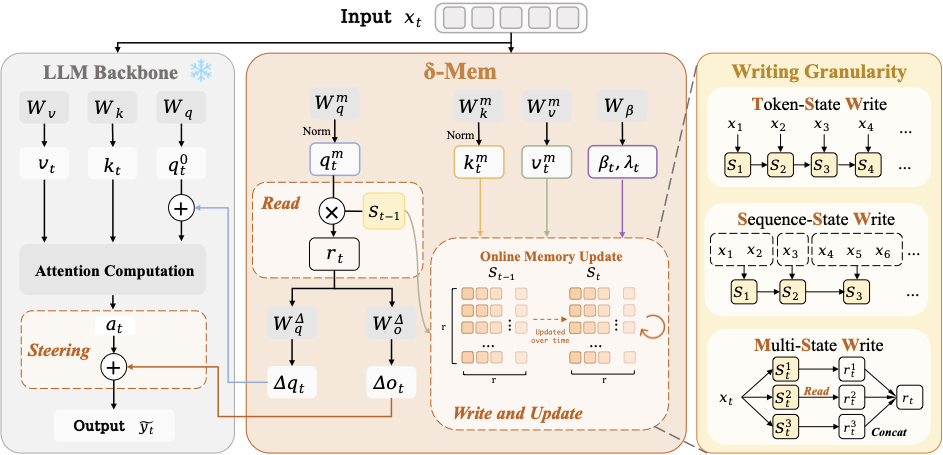
图1:左侧是 frozen Transformer backbone,进行标准 attention 计算。右侧是 δ-mem 模块——读取 previous state,生成 query-side 和 output-side 的 attention correction,然后用当前 token 的 KV 信息 update online state。下方展示三种写入粒度:Token-level (TSW)、Segment-level (SSW)、Multi-State (MSW)。整张图基本就是 δ-mem 的全部架构。
Memory State:一个 8×8 的矩阵
δ-mem 维护一个 fixed-size 的矩阵 \(S \in \mathbb{R}^{r \times r}\) 作为 online state。Memory key \(k_t \in \mathbb{R}^r\)、value \(v_t \in \mathbb{R}^r\) 都被投影到 \(r\) 维(实验里 \(r=8\)!)。
State 存的是 key→value 的 associative memory:
也就是说,给定一个 key,state 矩阵能"预测"出对应的 value。这本质上是个线性回归。
State 的更新用 delta-rule learning(SGD on online regression loss):
注意中间这个 \((v_t - S_{t-1} k_t)\)——它是残差。如果 state 已经能很好预测 \(v_t\),残差接近 0,update 几乎为 0;如果预测得很差,残差大,update 大。这就是 delta rule 的本质——按预测误差更新。
加上一个 forget gate(受 Qwen-Next gated retention 启发):
\(\lambda_t\) 控制保留多少旧记忆,\(\beta_t\) 控制新写入强度。
这其实就是 Linear Attention / SSM 的 mathematical structure
如果你熟悉 Linear Attention、Mamba、RetNet 这一脉工作,应该立刻能看出来——这就是 Linear Attention 的 state update。RWKV、Mamba、DeltaNet(DeltaRule)、Gated RetNet——这些都是用一个 fixed-size matrix state 维护历史信息,复杂度 \(O(N)\)。
δ-mem 的"新意"不在 state 更新机制本身——那是 borrowed 的——而在于怎么把这个 state 挂到 frozen full-attention backbone 上。
Readout:Low-Rank Correction
每次 generate 一个新 token,δ-mem 先读 state:
然后把 read vector \(r_t\) 通过两个 linear mapping 投回 backbone 的 attention space:
Query-side correction:加到原始 query 上 $\(\tilde{q}_t = q_t^0 + \frac{\alpha}{r} \Delta q_t\)$
Output-side correction:加到 attention output 上 $\(\tilde{y}_t = a_t + \frac{\alpha}{r} \Delta o_t\)$
这个 design 我觉得很 clever。Backbone 完全 frozen,δ-mem 只在 attention input 和 output 两个位置注入低秩修正。这就保证了: - 训练只需要 δ-mem 的参数(很小) - General capability 不受影响(backbone 没变) - δ-mem 的影响范围 controllable(通过 α/r)
注意 \(W_q^\Delta, W_o^\Delta\) 是固定的(train 完不变),但 \(r_t\) 来自动态的 state \(S_{t-1}\)——所以同一组参数在不同历史下会产生不同的 steering 信号。这是它和 static adapter(如 LoRA)的本质区别。
三种写入粒度
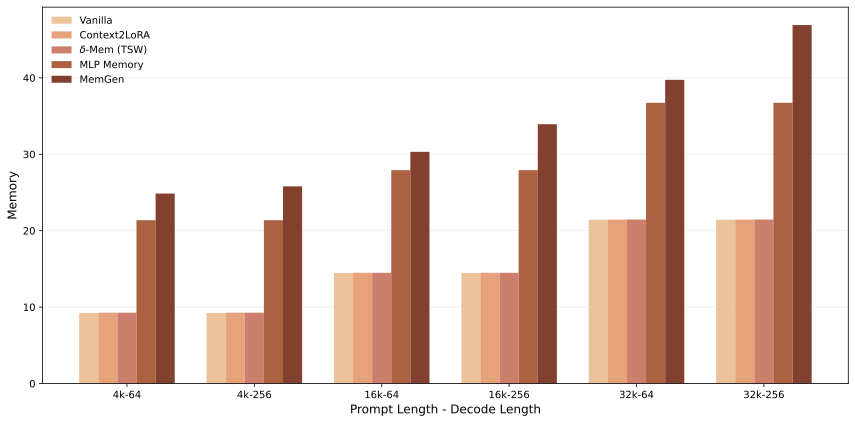
图2:左侧 TSW(Token-State Write)——每个 token 都更新一次 state,最细粒度。中间 SSW(Sequence-State Write)——按 message segment 平均后写入,更稳定。右侧 MSW(Multi-State Write)——多个 sub-state 并行,每个 sub-state 学不同类型信息,最后 concat readout。
TSW:每个 token 都触发 state update。最细但容易受 format token、重复表达的 noise 影响
SSW:按 message segment(如一条 user message)平均后写一次。更稳定,但会损失 token-level 细节
MSW:把 state 分成 N 个 parallel sub-state,每个独立 update:
这种 organization 让不同的 sub-state 可以学习不同类型的信息(事实/偏好/任务进度),减少 single state 的内部干扰
Training
训练用标准 SFT loss。关键 trick:context tokens 只 write 到 state 里,不作为 backbone 的 explicit input。Backbone 只看 query Q 和 response Y,但有 δ-mem state 提供历史信息。
这个设计很关键——它强迫 δ-mem state 真的 encode 了历史信息,因为 backbone 在 prediction 时看不到 history 的 text。
实验结果
我没翻完整 table,但论文摘要给的关键数字:
- 平均分:1.10× backbone,1.15× 最强 non-δ-mem baseline
- MemoryAgentBench:1.31×
- LoCoMo:1.20×
- TTL 子任务:26.14 → 50.50(接近翻倍)
8×8 的 memory state size 确实让人 surprised——这个 size 比一个 sentence 的 embedding 还小,居然能 encode 那么多历史信息?
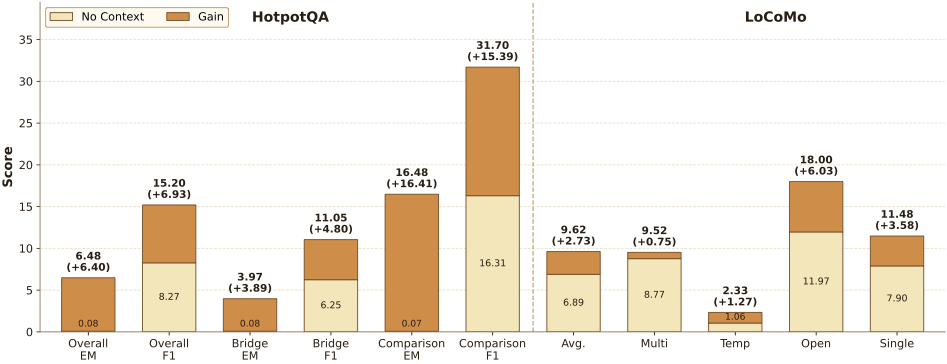
图3:在 explicit history 被移除的情况下,δ-mem 能从 8×8 state 中 recover 多少 context 相关信息。从结果看,即使没有 text history,model 通过 state readout 也能找回大部分关键信息——证明 OSAM 确实在压缩存储有用信号。
我的判断:值不值得读?
推荐,特别是如果你在做 long-term agent / memory system。
亮点:
- 8×8 这个 size 离谱地小——如果数据是真的,那 LLM 的 working memory 的有效维度可能比我们想象的低很多
- Backbone frozen + 低秩 correction 是个非常 clean 的设计。可以直接 plug 到任何 attention model 上
- Delta-rule 的 mathematical structure 是 well-understood 的——可以借鉴 Linear Attention / SSM 的所有理论结果(如 LRR、state space stability 等)
- Three writing granularity 提供了灵活性。Token / Segment / Multi-State 适合不同场景
问题:
- 8×8 这个 size 太小,让我对结果有怀疑。8×8=64 个参数能 encode 长 session 的历史?这中间是不是有什么我没看到的细节?比如是不是每层都有自己的 state?如果每层一个,假设 32 层,那就是 32×64=2048 个参数——这就合理多了
- General capability 评估有限。只测了 IFEval 和 GPQA。对于一个 modify attention computation 的方法,应该测更全面的 benchmark
- 延迟成本没充分讨论。每个 token 都要 read + update state,加上 query/output correction——这个 overhead 是多少?图里有 TPS 数据但摘要没强调
- 和 SSM/Linear Attention 的关系没说清楚。本质上 δ-mem 就是一个 Linear Attention head 作为 frozen Softmax Attention 的补充。这个 framing 没在 related work 里充分展开
- Delta rule 在 LLM 长 context 下的稳定性——理论上 SSM 在长 sequence 上有 stability 问题(vanishing / exploding state norm)。8×8 state 在持续 update 下会不会 collapse?
对工程实践的启发:
- 不要总是想着扩 context window。Augment with compact state 可能是更优解
- Delta-rule learning 的思路可以广泛应用——任何需要 online update 的场景都可以考虑
- Frozen backbone + low-rank correction 是个 powerful pattern,比 LoRA 更适合 dynamic adaptation
- 三种写入粒度的选择:对话场景用 SSW,agent trajectory 用 MSW,token-level 任务用 TSW
收尾
这篇论文我觉得在 long-term memory for LLM 这个方向是一个有 elegance 的工程探索。它的核心 insight——用 Linear Attention 的 state 作为 frozen Transformer 的"挂件"——其实在 RWKV、Hymba 这些 hybrid 架构里早就有了,但 δ-mem 做得更 minimal、更 plug-and-play。
回头看 LLM memory 这个方向:
- MemGPT 思路:text-based memory,retrieval 进 context
- LongRoPE / context extension:扩展位置编码
- RAG:外部检索
- Mamba / SSM:换 backbone 架构
- δ-mem:frozen backbone + lightweight state
每种方法都有自己的 trade-off。我觉得 δ-mem 这条路最适合的场景是——已经 deploy 了一个 frozen 商用大模型,想给它加 long-term memory 但不能改 backbone。这是个非常实际的需求。
下一个值得追的问题:
- 8×8 是不是 floor?能不能更小?或者必须更大才能 encode 更复杂的 history?
- State 是否需要 distill from longer context?类似 prefix tuning 的思路,先用长 context 训出来一个 representative state
- 跨 session 的 state persistence:state 怎么 save、load、merge?对 long-term assistant 来说这是关键工程问题
如果你在做需要 long-term memory 的 agent 系统,这篇值得仔细看一下,尤其是 implementation details 部分。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我