扔掉向量库,让 Agent 直接 grep 原始语料库——一篇打破检索神话的论文
一段开场白
做 RAG 的人多多少少都有过这样的经历:
模型已经够聪明了,prompt 也写得很讲究,但 agent 在一个具体问题上就是绕不过去。回头查 trace,发现答案的那段话其实早就在某个文档里——只是它被 retriever 切成 chunk,embedding 出来的语义跟 query 不像,top-k 把它筛掉了;再或者,gold doc 明明拿回来了,但关键的那一行夹在 5KB 的 snippet 中间,agent 读着读着就读糊涂了。
你下意识的反应是:换个更好的 embedding 模型,或者再加一层 reranker。
最近读到的这篇论文(来自滑铁卢、UIUC、斯坦福、CMU、华盛顿大学等的大型联合作者团)给的回答完全相反——问题不在 retriever 不够强,问题在 retriever 这层接口本身。当 agent 已经强到能像研究员一样搜索语料的时候,把语料压成一个 top-k 候选列表的"低分辨率接口",反而成了瓶颈。 他们提出的方案极其极简:把 retriever、向量库、FAISS 索引全扔掉,让 agent 直接拿着 grep、find、bash 这些命令行工具,对着原始语料"暴力"翻找。
这种做法他们叫 Direct Corpus Interaction(DCI,直接语料交互)。
核心摘要
这篇论文要解决的不是"哪种 retriever 更好"的老问题,而是反过来问:当 agent 已经具备多轮推理、规划、反思能力的时候,它跟语料库之间最合适的接口是什么形态?
作者的答案是:在 agentic search 场景下,传统"query → top-k snippets → reason"的固定接口已经成了天花板。它压缩了 agent 对语料的访问粒度,过滤掉的证据后续再强的推理也救不回来。DCI 干脆撤掉这层接口,让 agent 直接用 shell 工具操作 raw corpus——grep 精确匹配、find 定位文件、head/tail 看局部上下文、管道串起来做组合查询。
效果硬得有点反常识:在 BrowseComp-Plus 上,同样的 Claude Sonnet 4.6 backbone,把 Qwen3-Embedding-8B 换成 DCI,准确率从 69.0% 提到 80.0%(+11 pp),同时 API 成本从 $1,440 降到 $1,016(省了 $424);在 multi-hop QA 六个 benchmark 上,DCI-Agent-CC 平均 83.0%,比最强 retrieval agent 高 30.7 个点;在 BRIGHT + BEIR 六个 IR ranking 任务上,平均 NDCG@10 是 68.5,比最强 reranker(ReasonRank-32B)还高 21.5 个点。
我的第一反应是怀疑实验设置——一个不用任何 embedding 的方案,居然能在 IR ranking 上把专门做 ranking 的方法按在地上摩擦?后面会展开讲为什么这事是合理的。
一句话评价:这不是又一个 RAG 增强 trick,而是把"检索"从一个 retriever-design problem 重新框成 interface-design problem。思路简单到几乎所有人都该早就想到,但作者把实验做得足够实、足够多、足够认真,足以让做 retrieval-augmented agent 的人重新审视自己的栈。
论文信息
- 标题:Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
- 作者(19 人):Zhuofeng Li, Haoxiang Zhang, Cong Wei, Pan Lu, Ping Nie, Yi Lu, Yuyang Bai, Shangbin Feng, Hangxiao Zhu, Ming Zhong, Yuyu Zhang, Jianwen Xie, Yejin Choi, James Zou, Jiawei Han, Wenhu Chen, Jimmy Lin, Dongfu Jiang, Yu Zhang
- arXiv ID:2605.05242(cs.IR, cs.AI)
- 提交日期:2026 年 5 月 3 日
- 链接:https://arxiv.org/abs/2605.05242
问题动机:retriever 到底卡住了什么
先把场景说清楚。
我们说的 agentic search,不是单轮问答里"问一句、retriever 返回 top-5、模型答一句"那种。它是像 Tongyi-DeepResearch、Search-R1、MiroThinker、Claude Code 这些系统在做的事情:agent 自己拆问题、自己改写 query、自己读中间结果、再决定下一步搜什么。比如 BrowseComp-Plus 这种 deep research 评测,问题往往是"找出某个 1987 年在内罗毕死于车祸的肯尼亚作家,他在 BBC 的访谈节目叫什么"——你需要先找出这个人是谁,再找他和 BBC 的关联文档,再定位那个具体节目名。
这种任务里,retriever 在每一轮做的事还是同一件:把整个 corpus 压成一个 top-k 候选列表,然后把这个列表喂回 agent。
作者的核心观察是:这层"top-k 候选列表"的接口,正在反过来限制 agent。 具体限制有几类:
- 精确字符串约束没法表达。 "找出包含 'Spider-Man in film' 但不包含 'Spider-Man 2' 的文档",semantic similarity 对这种 negation 和 exact match 几乎没招。
- 弱信号的组合(conjunction)做不了。 你想要"同时包含 'road accident' 和 'African author' 的文档",retriever 把两个信号都模糊化进 embedding,最后排序往往不是你要的。
- 早期被过滤掉的证据,再强的下游推理也救不回来。 这点其实最致命——retriever 是一个 lossy 的前置网关。
- 拿到 gold doc 也只能看 snippet。 Snippet 截掉的部分,正好可能是你下一跳的钥匙。
我自己在做 agentic RAG 的时候有过非常具体的踩坑:query "1987 年罗杰 · 瓦利博拉去世前接受的访谈",retriever 给我返回一堆"瓦利博拉的生平",但 agent 真正需要的那篇 BBC 访谈实录,因为正文密度大、字面相似度不足,被排在 top-50 之外。重写 query、加 reranker、上 hybrid,都救不了它——除非我自己拿 grep 直接搜这串关键字。
这就是论文要打的命门。
方法核心:从 query→retriever→top-k 到 grep→raw file→inspect
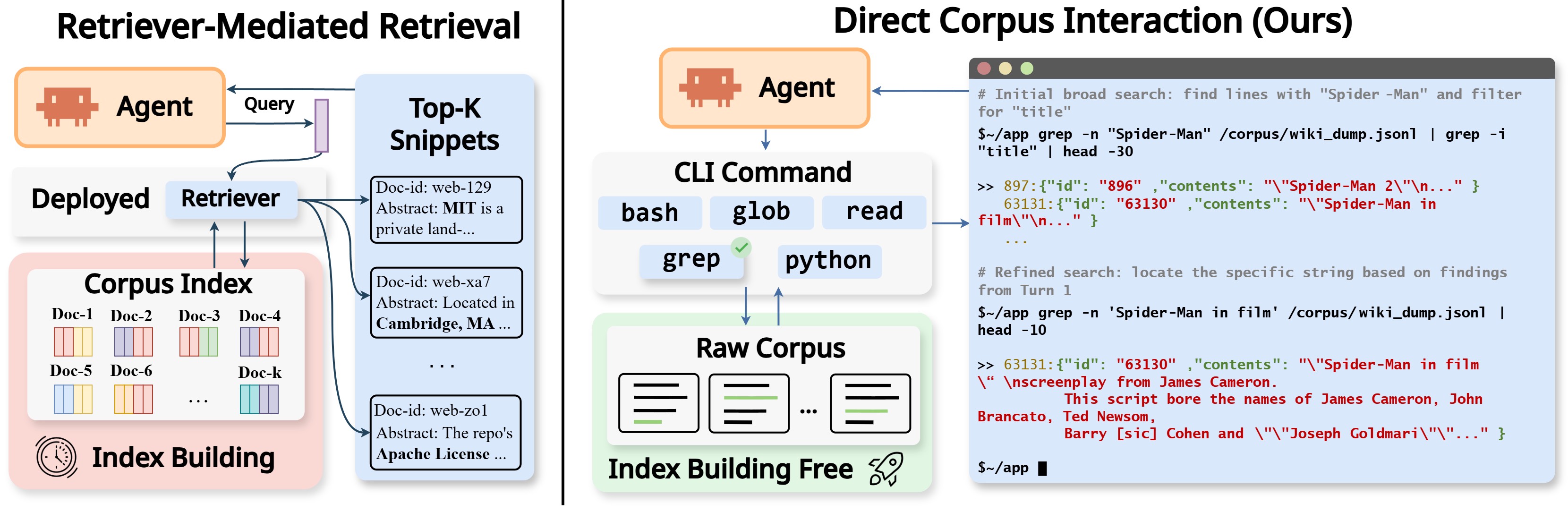
图 1:两种检索接口的对比。左边是传统流水线——先离线建索引,再 retriever 把 corpus 压成 top-k snippets 喂给 agent;右边是 DCI——agent 直接用 bash、grep、glob、read、python 等终端工具命中原始 corpus,没有任何 embedding 或向量索引介入。注意右下角那个"Index Building Free"的小图标,这是 DCI 的核心物理特性之一。
一句话讲清核心 idea
把 retrieval 这个动作从"一个 retriever 一次性返回 top-k",改成"agent 自己在 corpus 上跑一连串 shell 命令"。
就这么简单。没有 embedding 模型,没有 FAISS index,没有 retrieval API,没有离线预处理。Agent 想搜什么,自己 grep;想看完整文件,cat 一下;想做组合过滤,grep 'foo' file | grep 'bar' | head -5;想统计什么,写个一行 Python。
作者把这种粒度叫做 retrieval interface resolution(检索接口分辨率)——衡量的不是 retriever 能找到多少 gold doc,而是 agent 能以多细的粒度去探查、验证、迭代 corpus 内容。Top-k snippet 是低分辨率,shell 命令是高分辨率。
两个具体的 agent 实现
为了把"接口换了"和"agent harness 升级"这两个变量分开,作者搞了两套实现:
| 实现 | 底座模型 | 工具集 | 上下文管理 | 定位 |
|---|---|---|---|---|
| DCI-Agent-Lite | GPT-5.4 nano | 只有 bash + read | 自研轻量 runtime(Pi 改的),含 L0–L4 五档 context 管理 | 干净的最小变量,用来证明"是接口本身在涨点" |
| DCI-Agent-CC | Claude Sonnet 4.6 | Claude Code 默认工具集(禁用了 web-search、web-fetch、subagent,且屏蔽对评测数据目录的访问,防作弊) | Claude Code 内建 | 强 harness 配强模型,用来探性能上限 |
这里有个细节我挺欣赏的:DCI-Agent-CC 是直接拿现成的 Claude Code 来跑,没做任何 agent 训练或 RL fine-tune。坦率讲——这是一个零训练、即插即用的方案——你今天就能在自己的项目里跑。
Runtime 上下文管理:DCI 真正能跑起来的关键
如果你真的拿 grep 在一个 100K 文档的 corpus 上糊上去,立刻会撞到一个问题:tool output 爆炸。一次 grep 命中 300 行,开两个文件再 1000 行,几轮下来就把 model context window 撑爆了。
DCI-Agent-Lite 设计了三件套来应对:
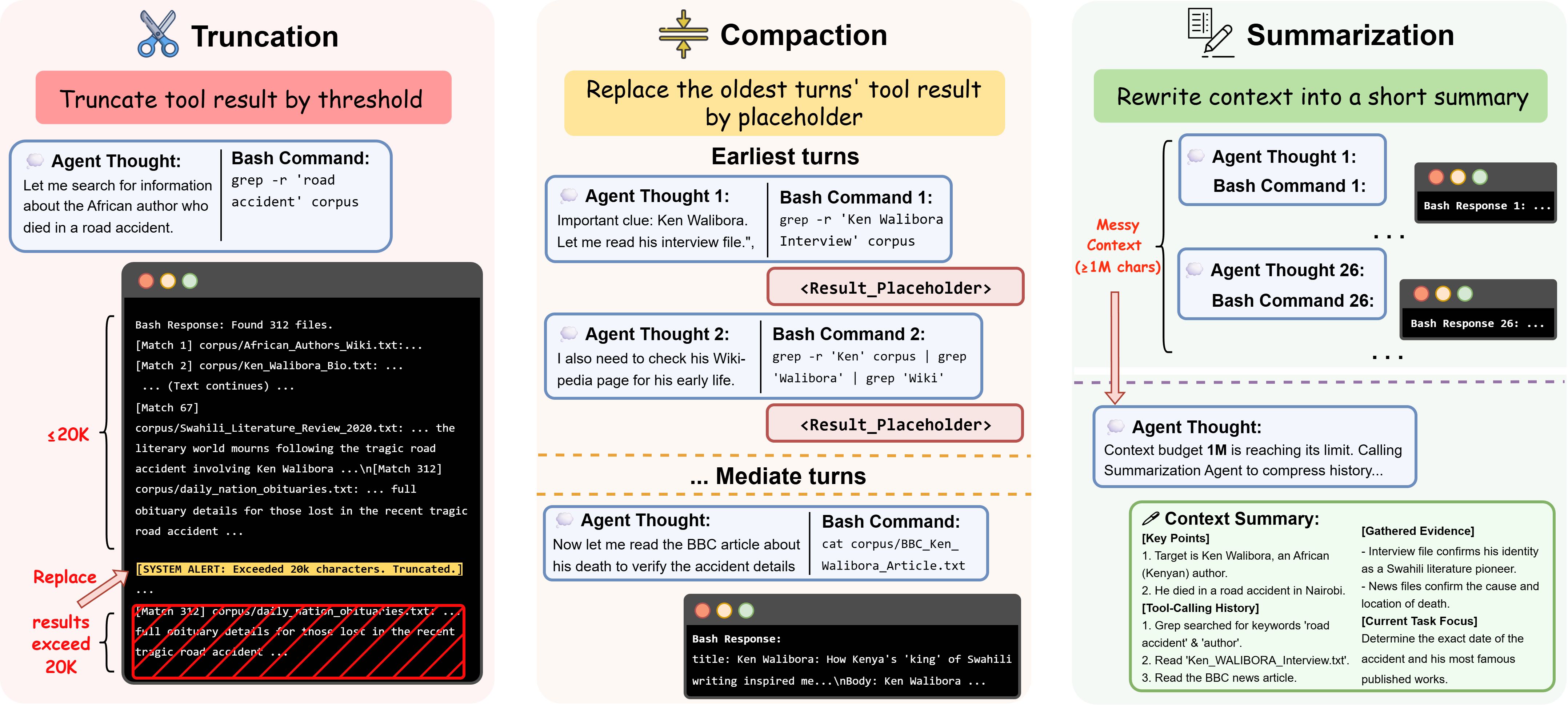
图 2:上下文管理的三种机制。左侧 Truncation——每个 tool result 超过 20K 字符就硬截断;中间 Compaction——把更早的 tool 输出整体置换成 placeholder,但保留"调用过这个工具"的结构;右侧 Summarization——把所有压缩过的历史让模型重写成一段总结,最近 20K token 保留原文。
三个机制按"激进程度"组合成 5 个 level:
| Level | 策略 | 用在哪 |
|---|---|---|
| L0 | 不做任何管理 | baseline |
| L1 | 只截断(50K 上限) | 最轻 |
| L2 | 只截断(20K 上限) | 更紧 |
| L3 | 20K 截断 + Compaction(累计 240K 触发,保留最近 12 轮) | 主实验默认 |
| L4 | 在 L3 基础上加 Summarization | 消融实验默认 |
后面会看到 L3 才是甜点,过激或过松都掉点。这种"非单调"的结果挺有意思,等下细说。
评测指标:Coverage vs. Localization
光看最终准确率,看不出 DCI 和传统 retriever 各自的失效模式。作者引了两个轨迹级(trajectory-level)指标:
- Coverage:trajectory 里有没有把 gold doc 至少 surface 一次出来。这是"广度"指标。
- Localization:surface 到 gold doc 之后,agent 能不能把证据缩到很小的一段。这是"深度"指标。
Localization 的定义稍微数学一点。给定 gold doc \(d^*\),agent 在某次观察中暴露了一段长度为 \(\ell\) 的 snippet,用 segment 数 \(\nu(\cdot)\) 做归一化,定义:
直觉是:暴露的 span 相对 gold doc 越小,分越高。你想想看,retriever 拉回来 5KB 的 snippet(不管多 relevant),分都会很低;而 DCI 用 grep -n 'keyword' file | head 精确命中 200 字符的段落,分会很高。
这个指标后面会成为 DCI 涨点的核心解释——DCI 不是找到更多 gold doc,而是在找到的 gold doc 里把证据砸得更准。
实验结果:硬数字,硬到有点不真实
BrowseComp-Plus:agentic deep research
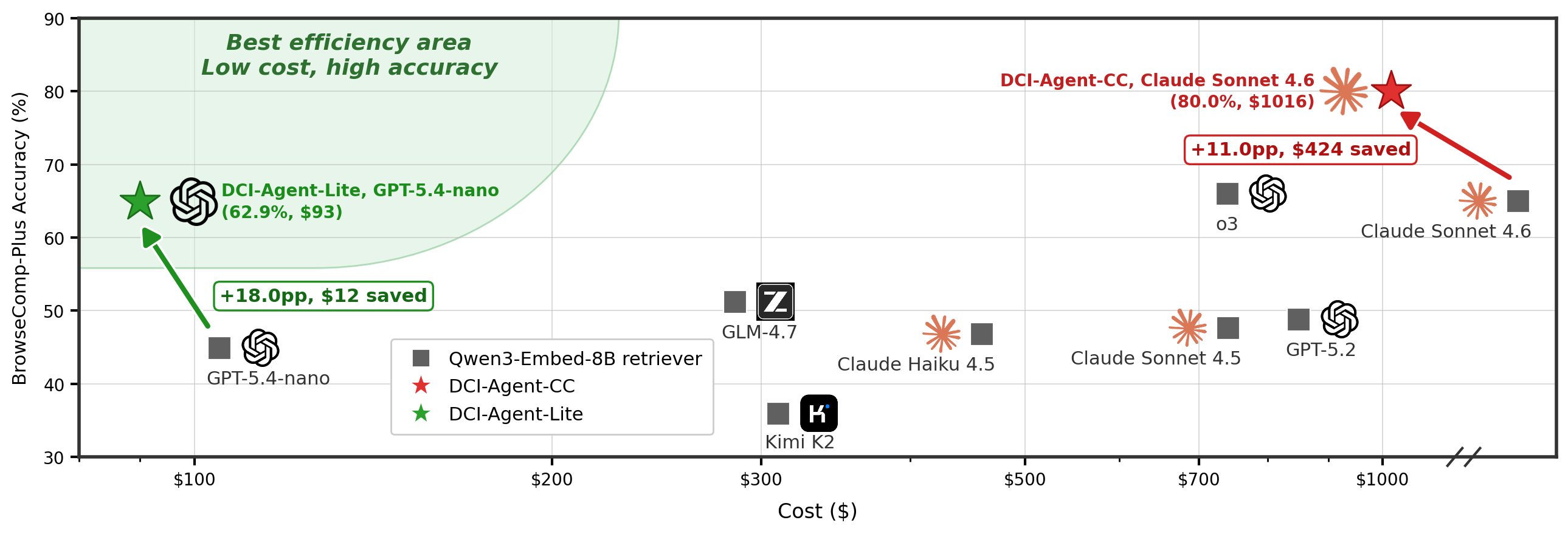
图 3:BrowseComp-Plus 的成本-性能 Pareto 图。红星 DCI-Agent-CC 在 80.0% 准确率、\(1016 成本的位置上,比同模型 retriever baseline(Claude Sonnet 4.6 + Qwen3-Embed-8B:65% 左右,\)1440 成本)涨 +11pp 同时省 $424;左下角绿星 DCI-Agent-Lite 用 GPT-5.4 nano 在 $93 成本下做到 62.9%,跟用 Claude 4.6 / o3 配 retriever 的方案打得有来有回。
几个关键数字(都来自论文 §5.2 + Pareto 图):
- DCI-Agent-CC(Sonnet 4.6):80.0% 准确率,$1016 成本
- 同 backbone retrieval baseline(Sonnet 4.6 + Qwen3-Embed-8B):69.0%,$1440
- DCI-Agent-Lite(GPT-5.4 nano):62.9%,$93
- 最强 retrieval baseline(GPT-5 + Qwen3-Embed-8B):71.7%
这里值得多看一眼的是 Lite 这一档。它用 nano 级模型 + bash + read,成本只有 GPT-5 retrieval 方案的 1/8 左右,但准确率只低 8.8 个点。如果你在生产环境关心单 query 成本,这个权衡是相当离谱的。
Multi-hop QA:六个数据集全面碾压
| 模型 | NQ | Trivia | Bamboogle | HotpotQA | 2Wiki | MuSiQue | 平均 | Δ |
|---|---|---|---|---|---|---|---|---|
| R1-Searcher-7B | 58 | 50 | 54 | 46 | 40 | 24 | 45.3 | -7.0 |
| Search-R1-32B | 56 | 46 | 52 | 44 | 50 | 32 | 46.7 | -5.6 |
| ZeroSearch-7B | 26 | 30 | 18 | 10 | 18 | 4 | 17.7 | -34.6 |
| Verl-Tool-Search-7B-DAPO | 56 | 44 | 32 | 50 | 32 | 12 | 37.7 | -14.6 |
| ASearcher-Local-14B(最强 retrieval baseline) | 56 | 58 | 62 | 58 | 56 | 24 | 52.3 | — |
| DCI-Agent-Lite(GPT-5.4 nano) | 72 | 84 | 72 | 72 | 68 | 40 | 68.0 | +15.7 |
| DCI-Agent-CC(Sonnet 4.6) | 78 | 96 | 80 | 88 | 82 | 74 | 83.0 | +30.7 |
+30.7 pp 的平均提升,特别是在 MuSiQue 这种 4-hop 任务上从 24 → 74。说实话看到这个数我愣了一下,下意识去查了一下 ASearcher 的 setup——确认 corpus 都是 2018 Wikipedia dump、E5 embedding 建索引,没有不公平的地方。
不过这里有一个需要打个问号的地方:DCI-Agent-CC 用的是 Sonnet 4.6,比 ASearcher 的 14B 底座强太多。也就是说"+30.7"里有相当一部分是底座强带来的,不全是接口本身。作者其实在 RQ2/RQ3 里专门做了 controlled comparison(同底座下的 DCI vs. retriever),那部分数据更说明问题,下一节会展开。
IR Ranking:DCI 居然能干翻 reranker?
| 方法 | Bio. | Earth. | Econ. | Robotics | ArguAna | SciFact | 平均 | Δ |
|---|---|---|---|---|---|---|---|---|
| BM25 | 18.9 | 27.2 | 14.9 | 13.6 | 31.5 | 15.8 | 20.3 | -26.7 |
| OpenAI text-emb-3-large | 23.3 | 26.7 | 19.5 | 12.8 | 58.1 | 58.1 | 33.1 | -13.9 |
| GTE-Qwen2-7B | 30.6 | 36.4 | 17.8 | 13.2 | 62.7 | 75.3 | 39.3 | -7.7 |
| Rank-R1-14B | 31.2 | 38.5 | 21.2 | 22.6 | 31.3 | 72.2 | 36.2 | -10.8 |
| Rank1-32B | 49.7 | 35.8 | 22.0 | 22.5 | 57.6 | 74.8 | 43.7 | -3.3 |
| ReasonRank-32B | 58.2 | 48.9 | 36.6 | 33.9 | 28.7 | 75.5 | 47.0 | — |
| DCI-Agent-Lite | 60.0 | 50.8 | 32.3 | 42.4 | 81.9 | 72.7 | 56.7 | +9.7 |
| DCI-Agent-CC | 77.1 | 69.0 | 46.8 | 56.8 | 85.3 | 75.7 | 68.5 | +21.5 |
NDCG@10 平均比专门做 reasoning rerank 的 ReasonRank-32B 还高 21.5。
这事坦率说挺反直觉。我想了一下,比较能 make sense 的解释是:BRIGHT 本身就是为"需要推理才能 rank 正确"的场景设计的,问题往往是"哪篇文档对回答这个 problem 最有帮助",而不是"哪篇跟 query 最相似"。在这种 setup 下,让 agent 边搜边读边判断,比让 reranker 一次性打分更合理——reranker 拿到的只是一段 snippet,agent 拿到的是 grep 后的精确上下文 + 局部展开能力。
但这里也要点一下论文的一个潜在 caveat:DCI-Agent-CC 平均要跑 26.33 次 Bash + 13.94 次 Grep(见图 4),每个 query 的工具调用数是 reranker 的几十倍。这不是公平的"single forward pass"对比——它是"花更多算力换更好结果"的对比。论文承认了这点(见 RQ4 的 scaling 实验),但放在正文表里没特别强调成本维度,这一点稍微有点选择性叙事。
为什么 DCI 涨点?层层剥开
这才是这篇论文最有意思的部分。作者做了 5 个 RQ 来拆解 DCI 的增益来源。
RQ2:DCI 多出来的对题,到底赢在哪?
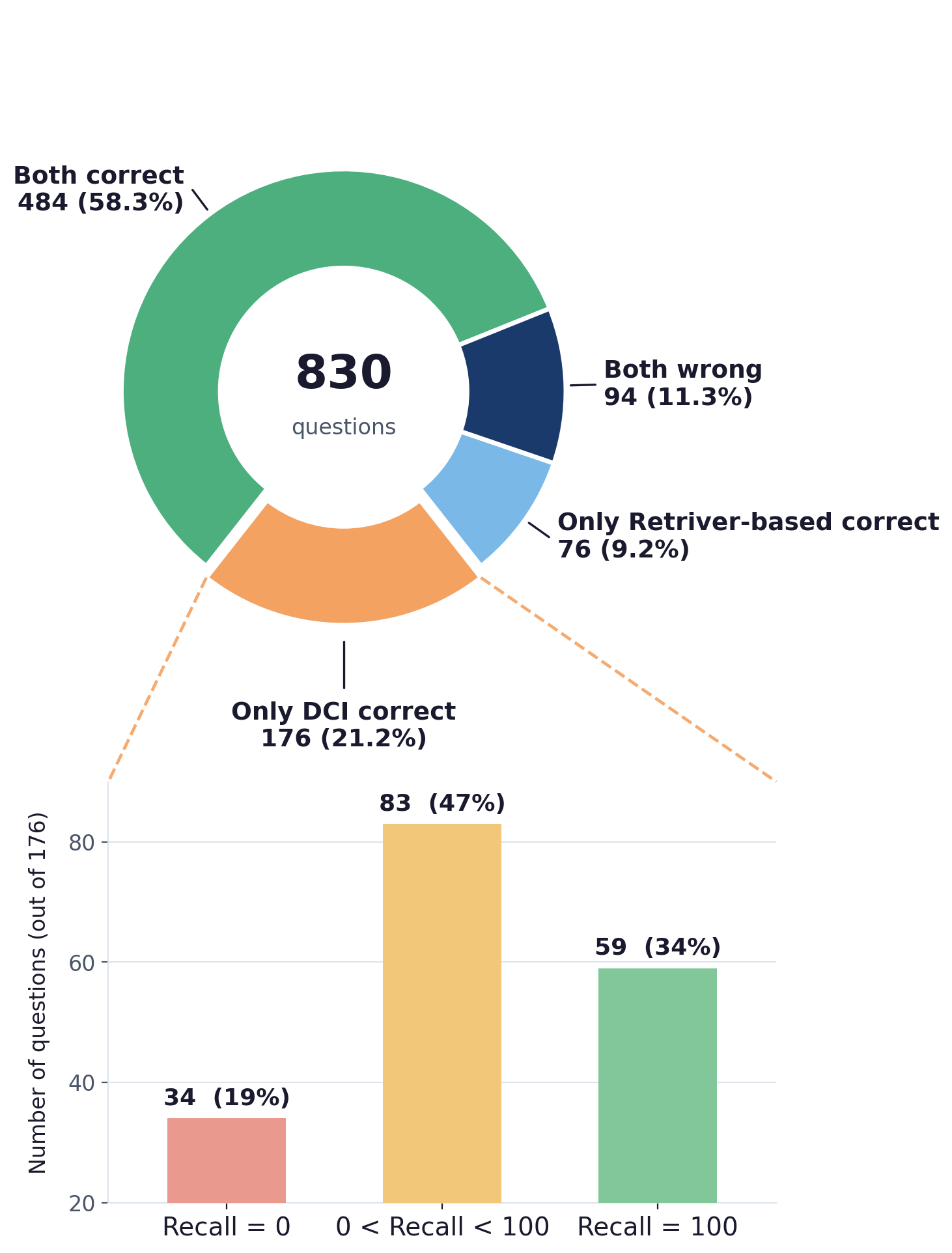
图 4-左:830 道题里两边都对的 484 题(58.3%)、只有 DCI 对的 176 题(21.2%)、只有 retriever 对的 76 题(9.2%)、都错的 94 题(11.3%)。下方柱状图把 176 道"只有 DCI 对"的题按 retriever 的 gold-doc recall 切片——只有 34 道(19%)是 retriever 完全没找到 gold doc;83 道(47%)retriever 部分召回;59 道(34%)retriever 已经完整召回了所有 gold doc,但仍然答错。
这个图对我冲击挺大。
它告诉你:DCI 比 retriever 多答对的那 176 题里,足足 142 题(81%)retriever 其实已经把 gold doc 拿回来了,但 agent 没用好。 也就是说,DCI 的真正胜场不是"找到更多文档",而是"找到之后用得更深"。
那 59 道 recall=100 还答错的题尤其说明问题——retriever pipeline 因为 snippet 截断、读错文件、抓错决定性那一行而失手;DCI 因为可以直接 grep -n + sed -n '100,200p' 把那一行钉死在屏幕上而过关。
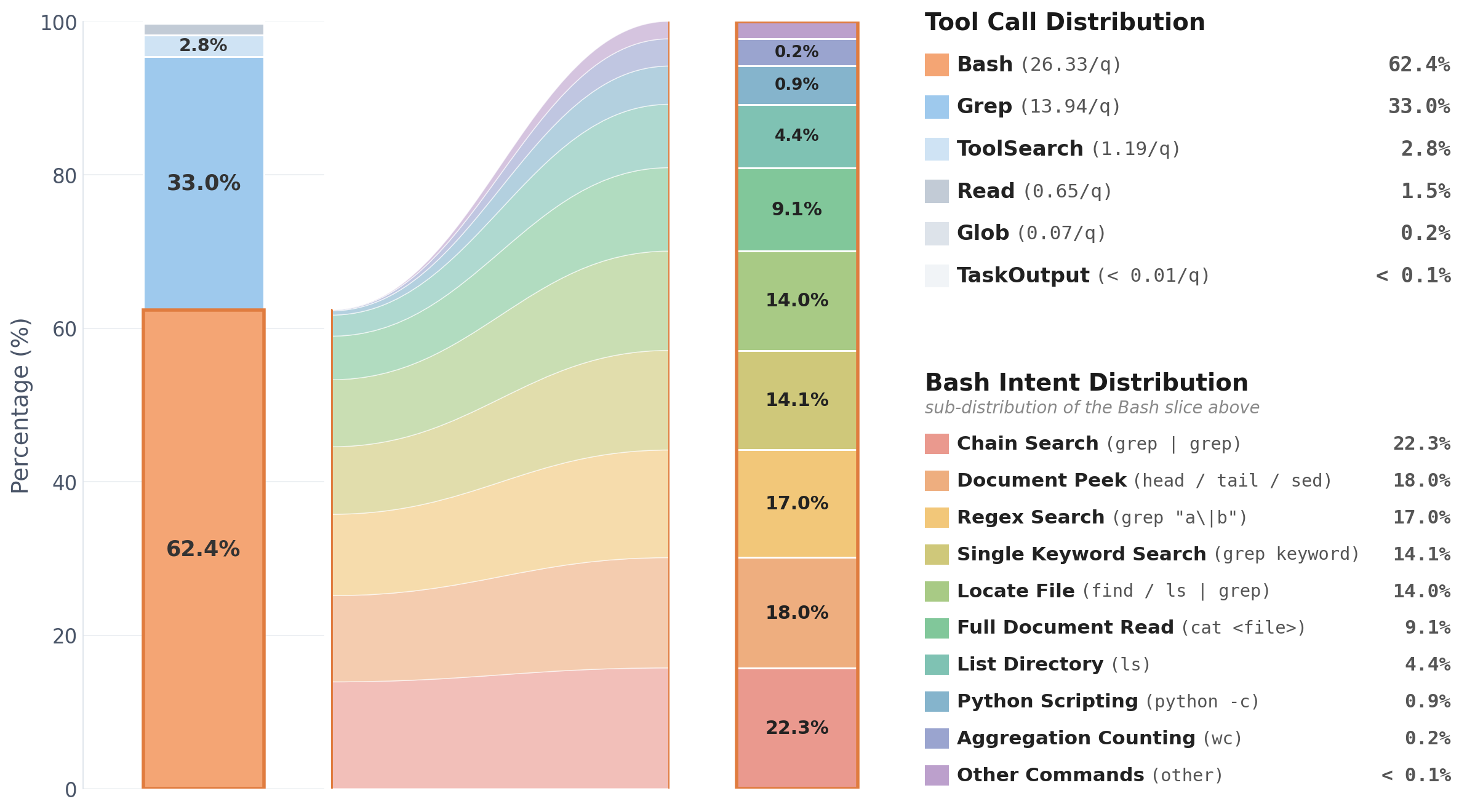
图 5:工具调用与 Bash 意图分布。Bash 占 62.4%,平均每 query 26.33 次;Grep(Claude Code 内建的快速搜索)占 33.0%,13.94 次/query。Bash 内部前四大用法分别是 chain search(管道串 grep,22.3%)、document peek(head/tail/sed 看局部,18.0%)、regex 匹配(17.0%)、locate file(14.0%)。完整文件读取只占 9.1%。
最后这个分布特别有说服力——agent 真正在干的事是"链式搜索 + 局部窥视",而不是"把整个文件吞下去"。 这其实就是高分辨率检索接口在行为层面的样子:你不需要一次性看一大段,你需要的是"先 grep 关键词,再 head 看上下文,再 grep 一个更精确的,再 sed 钉到具体行"。
这个发现的工程启发是:如果你要让自家 agent 也走 DCI 路线,核心要保证 chain pipeline 能跑通——grep | grep | head 这种组合的可达性,比单个 tool 是否花哨重要得多。
RQ3:Coverage 输了但 Localization 大胜
| 方法 | tools/q | cost/q | cov-any | cov-mean | cov-all | localization | Acc |
|---|---|---|---|---|---|---|---|
| BM25(GPT-5.4 nano) | 19.07 | $0.053 | 63.0 | 42.8 | 17.0 | 23.5 | 32.0 |
| Qwen3-Embed-8B(GPT-5.4 nano) | 17.55 | $0.050 | 74.0 | 56.7 | 28.0 | 21.7 | 45.0 |
| DCI-Agent-Lite(L4,GPT-5.4 nano) | 35.35 | $0.102 | 70.0 | 28.0 | 1.0 | 48.4 | 73.0 |
这张表的精彩之处在于:
coverage_mean:DCI 28.0 vs Qwen3 56.7——DCI 在"召回多少 gold doc"这件事上是输的,输得还挺惨。coverage_any:70.0 vs 74.0——但"是否至少找到一篇 gold doc"两边持平。localization:48.4 vs 21.7——DCI 一旦找到,能把证据精度做到 2 倍。- Acc:73.0 vs 45.0——最终对题率 +28。
作者用一句话总结:"DCI trades exhaustive gold-chain recovery for high-resolution local progress." 翻译过来就是——DCI 不追求把所有 gold doc 都找全,它追求的是"找到一篇就榨干一篇"。
考虑到 BrowseComp-Plus 的题目通常只有 1-4 个 gold doc,这种"任何一个 anchor 都行,找到了就钉死"的策略反而是最优解。
RQ4:corpus 一变大,DCI 撑得住吗?
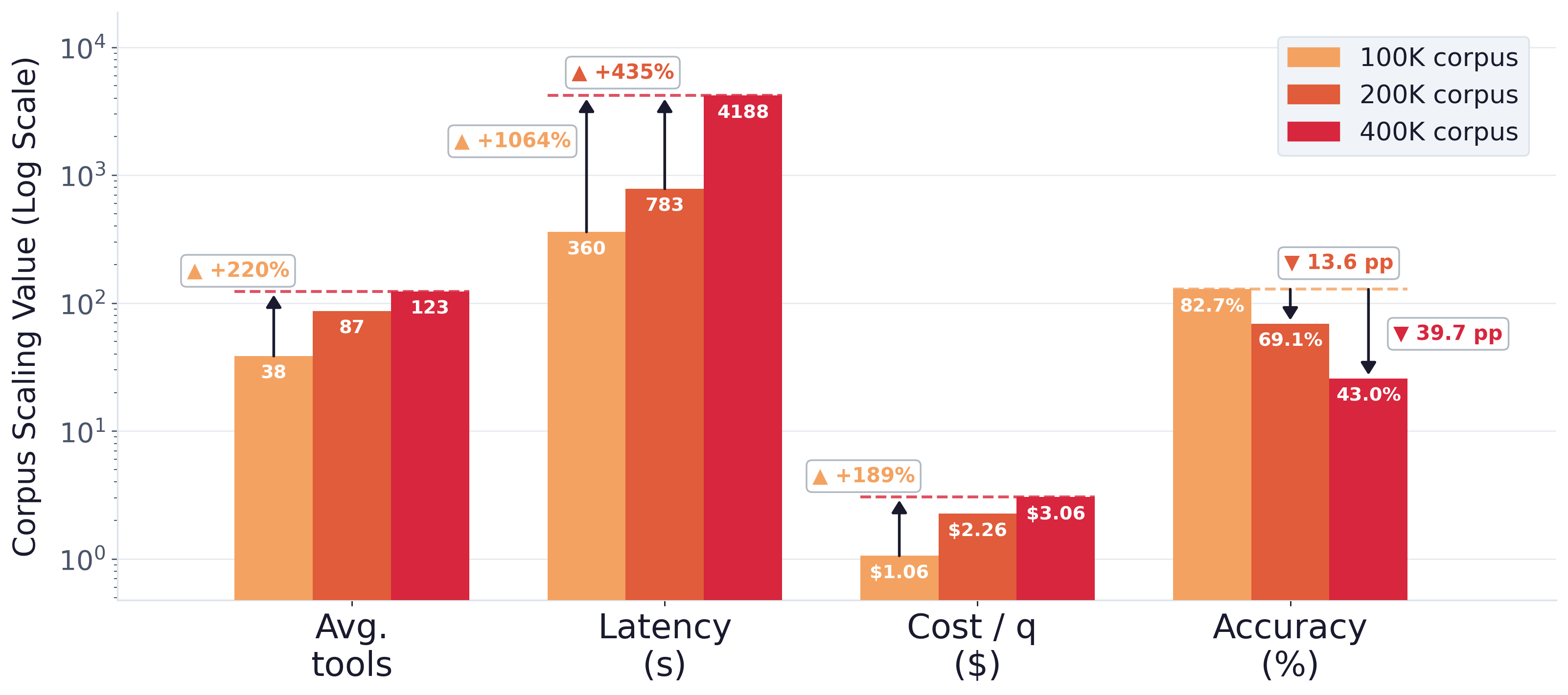
图 6:corpus scaling。100K→400K,平均工具调用 38→123(+220%),延迟 360s→4188s(+1064%!),单 query 成本 \(1.06→\)3.06(+189%),准确率从 82.7% 跌到 43.0%(-39.7pp)。
这是 DCI 的命门,作者很坦诚地放在了正文。
DCI 在 corpus depth 上很 scale,但在 corpus breadth 上不 scale。 一旦候选空间变大到 400K 级别,agent 找到第一个 anchor 的成本指数级上涨,最后撑不住。
这里我有个判断:DCI 不是要替代 retriever,它的真正用法是"在已经知道范围"的场景里——比如代码仓库(Claude Code 本来就是这么用的)、企业内部 wiki、单个产品的文档集合。在百万级以上的 open-web 场景,它要么需要先用一个粗的 retriever 把候选缩到 100K 以内(hybrid 方案),要么就是 latency / cost 都不能接受。
论文也暗示了这个判断——他们说 DCI 特别适合"local, heterogeneous, continually evolving corpora",潜台词就是大规模静态语料还是 retriever 的主场。
RQ5:上下文管理的"非单调"现象
| Level | tools | latency | cost | retained-cov | Acc |
|---|---|---|---|---|---|
| L0(不管) | 28.54 | 2226 | $0.072 | 26.9 | 72 |
| L1(50K 截断) | 29.00 | 1820 | $0.072 | 31.3 | 75 |
| L2(20K 截断) | 29.95 | 4413 | $0.059 | 27.2 | 69 |
| L3(20K + Compaction) | 36.89 | 8712 | $0.111 | 27.0 | 77 |
| L4(L3 + Summarization) | 35.35 | 4531 | $0.102 | 28.0 | 73 |
注意 L1 retained-cov 最高(31.3),但 Acc 是 75 而不是最高的 77;L3 retained-cov 反而比 L1 低(27.0),Acc 却最高(77)。
作者的解释挺漂亮——保留更多 verbatim 证据 ≠ 保留正确的"working state"。L3 用 placeholder 替换早期 tool result,反而保留了"调用过这个工具"的结构信号,让 agent 在多跳推理时更容易接续;而 L4 又过激地总结掉一切,丢了细节。这是个甜点曲线,不是单调上升。
这个发现对做 long-horizon agent 的人有直接启发:不要无脑加更激进的 context 压缩,"选择性遗忘"比"激进压缩"重要。
RQ6:工具集要多花哨才够?
| 方法 | 工具集 | tools | cost | Acc |
|---|---|---|---|---|
| Qwen3-Embed-8B 检索 agent | retriever | 18 | $0.050 | 45 |
| DCI-Agent-Lite(只 read + grep) | 两个 | 19 | $0.036 | 61 |
| DCI-Agent-Lite(开放 bash) | 全 shell | 35 | $0.102 | 73 |
最朴素的结论:
- 只给
read + grep,DCI 已经比 retriever baseline 高 16 个点,且工具调用数几乎一样(19 vs 18)。 - 开放完整 bash 再涨 12 个点,但成本翻 3 倍。
这非常重要——它告诉你 DCI 的增益不是来自 bash 这个"全能瑞士军刀",而是来自"高分辨率接口"这件事本身。哪怕只给 grep + read 这种最简陋的能力,agent 也能比走 retriever 走得更准。这等于把"DCI 涨点是因为 bash 太强了"这种 confounder 切掉了。
我的判断:值得跟,但要看清边界
我被打动的地方
第一个,是把"检索"重新框成"接口设计"。 过去十年 IR 圈和 RAG 圈花了无数力气在"哪种 embedding 更好""哪种 reranker 更准""怎么 hybrid"上。这篇论文绕到背后问了一句:"你们都默认 retriever 必须存在,但凭什么?"对于一个已经会反思、规划、试错的 agent,把 corpus 压成 top-k 列表反而是在浪费它的能力。这种思路上的"reframe",比任何一个增量改进都值钱。
第二个,是实验的诚实度。 作者主动报了 corpus scaling 的崩塌(RQ4,400K 准确率从 82.7% 跌到 43%),主动报了 context 管理的非单调甜点(RQ5),主动报了 retriever 在 recall=100 时 DCI 仍然胜出的 case(这就是 retriever 后端没充分利用),主动用 only read+grep 这种极简对照(RQ6)把 bash 这个 confounder 切掉。这种"我把自己方法的命门也告诉你"的写法,比通篇 "+5pp" 的论文可靠太多。
第三个,是它"今天就能用"。 不需要训练 agent,不需要 RL,不需要重做 retrieval pipeline。Claude Code 这种现成的 CLI agent 直接拿来跑就行。这是少见的"理论框架 + 现成实现"的同步交付。
我皱眉的地方
关于公平性。 DCI-Agent-CC 用 Sonnet 4.6 比 ASearcher-Local-14B 的底座强太多,"+30.7 pp" 里底座贡献的比例没拆清。当然作者在 RQ2-RQ3 用同底座做了 controlled 对比,但正文表格的对比方式还是会让不仔细看的读者觉得 DCI 涨点全靠接口。
关于规模。 400K 文档准确率就掉到 43%——这是个 hard limit。如果你的语料是企业级的 N 千万文档,DCI 单独跑不行。论文在 discussion 里轻描淡写带过这件事,没说清"什么时候应该 DCI、什么时候应该 hybrid、什么时候只能 retriever"。这块算是空白。
关于成本叙事。 Pareto 图里 DCI-Agent-Lite 的成本优势很猛($93),但那是因为 GPT-5.4 nano 便宜。如果你切到 Sonnet 4.6(CC 版本),成本就是 $1016——比 retriever baseline 省了 $424,但这是大模型 + 多轮工具调用的绝对值。在一些中小型项目里,这个绝对值仍然不小。
关于"被 retriever 卡住"这件事的普适性。 在 BrowseComp-Plus 这种"故意设计来考验 retriever 极限"的 benchmark 上,DCI 的接口优势会被放大。但在大多数日常 RAG 场景(FAQ、客服、文档问答),retriever 其实已经够用。论文里"retriever 是瓶颈"这个判断,是不是会被有些团队当成"我们也该上 DCI"的盲目跟风理由——这是个问题。
工程落地建议
如果你的 agent 满足下面三个条件,这事值得直接试:
- 语料是本地的、可遍历的(代码库、内部 wiki、单个数据集),且规模在 100K 文档量级以内。
- 任务需要多步推理 / 精确字符串匹配 / 弱信号组合,retriever 的 top-k 不够用。
- 能接受 latency 在分钟级(DCI 的 tool calls 数比 retriever 多一个数量级)。
如果你的语料是百万级以上 open-web 数据,别幻想纯 DCI 能跑通——先用一个粗 retriever(甚至 BM25)把候选压到 100K 以内,再让 agent 走 DCI。这其实是个很自然的 hybrid 设计,但论文里没明说。
如果你想从最小成本开始验证——拿 Claude Code 或者类似的 CLI agent,禁掉 web-search,让它在一个目录上跑你的 query 集合。一个下午就能跑出对比数据。
写在最后
我自己之前做 multi-hop QA 的时候有过一个非常反直觉的体验:很多 case retriever 已经把 gold doc 拿回来了,agent 还是答错。当时下意识归咎为 "agent reasoning 不行",开始堆 CoT、堆 self-reflection、堆 verifier。
这篇论文把这条 debug 思路彻底重写了——不是 agent reasoning 不行,是 retriever 的接口本身在 truncate 你的 agent。 把这层接口换掉,agent 的能力立刻被放出来了。
最后留一个让人不舒服的问题:当语料库的规模继续涨,agent 的能力也继续涨,那个最优"接口分辨率"会怎么演化?是 retriever + DCI 的 hybrid?还是会出现某种新的中间形态(比如 corpus 上的某种结构化索引但不做 embedding 压缩)?
这篇论文给出了一个明确的方向,但它显然不是终点。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我