BRIGHT-Pro 与 RTriever:把"推理密集型检索"从静态榜单拉回 Deep Research 真实战场
最近做 Agentic Search 系统的朋友应该都有这种感觉:榜单上看着很猛的 retriever,丢到真实 deep-research loop 里,agent 还是要搜五六轮、十几轮才肯停下来。我自己之前把一个 BRIGHT 榜上排名靠前的 embedder 接到一个多轮搜索 agent 里,第一反应是"这数据应该挺漂亮吧"——结果一看 trace,agent 在第七轮还在为同一个 aspect 换着花样搜,gold passage 早就在第二轮被取回了它自己没识别出来。
这就是 Yale + NYU + NUS 这篇新工作想戳破的事:单段排序的 NDCG,根本不能代表 retriever 在 agent loop 里的真实价值。
核心摘要
这篇论文做了三件事,环环相扣:
第一,提出 BRIGHT-Pro,一个把 BRIGHT 重新做了一遍的 expert-annotated benchmark——每个 query 不再只有 1-2 篇 gold,而是被拆成 2-5 个带权重的 reasoning aspect,每个 aspect 配一组互补的 gold passages,平均一个 query 有 7.13 篇正例、3.74 个 aspect。第二,把评测拉进了 agent loop,同时用 静态评测 + fixed-round agentic + adaptive-round agentic 三种协议,并提出一个叫 AER 的"答案质量 × 轮数惩罚"复合指标。第三,针对训练侧的"单正例"缺陷,做了一个 aspect 解耦的合成数据 pipeline RTriever-Synth,并基于 Qwen3-Embedding-4B 用 LoRA 训出 RTriever-4B。
关键结论挺有意思:BGE-Reasoner-8B 稳坐第一(α-nDCG@25 = 68.0,AER = 3.65),RTriever-4B 用 4B 参数挤进静态前 4、agentic 第 2-3,但更刺激的是——BM25 在静态榜上垫底(40.3),到了 agent loop 里直接反超一堆 8B 通用 embedder。这个反差几乎可以单独写一段论文。
值不值得花时间读?如果你做 RAG / Deep-Research / Agentic Search,强烈建议读,它给出的是一套新的评测哲学,不只是又一个 retriever。
论文信息
- 标题:Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
- 作者:Yilun Zhao、Jinbiao Wei、Tingyu Song、Siyue Zhang、Chen Zhao、Arman Cohan
- 机构:Yale、NYU、NUS(耶鲁、纽约大学、新加坡国立大学)
- arXiv:2605.04018(2026 年 5 月 5 日提交)
1. 问题动机:榜单和真实使用,哪儿断了?
先把背景捋一下。传统 IR 的舒适区是"factoid + single-hop"——查"喜马拉雅山最高峰多高"这种东西,BM25 就能打天下。但现在用户给到 LLM 的查询,越来越多是这种:
我家公猫最近总盯着墙发呆,没有别的异常行为。它是不是有什么健康问题?
这玩意 retriever 单步搜不出有用的东西——它需要的是一个 portfolio:外部刺激(墙上有虫、光影)+ 健康原因(视觉问题、神经问题)+ 行为学解释(猫天性 / 注意力)。每个 aspect 都要至少一篇 gold 才能拼出一份让人服气的答案。
业界目前两条路:
第一条路:把 retriever 做强。代表工作就是 BRIGHT 这个 benchmark,以及围绕它做的 ReasonIR、DIVER、BGE-Reasoner 等等。但论文指出 BRIGHT 的两个硬伤——gold passage 太少(每个 query 只标 1-2 个,且大多来自一两个 webpage),评估方式是孤立的(retriever 给一个 ranked list 就结束,不进 loop)。
第二条路:堆 agent loop。也就是各家在做的 Deep Research——LLM agent 反复 plan、search、read、synthesize,靠多轮把单步 retriever 的不足"凑回来"。问题是这玩意贵啊:每多搜一轮 = 多一次 LLM call + retrieval call,端到端延迟和 API 费用噌噌涨。
两条路其实是同一个问题的两半:如果 retriever 真的能在一两步内把 reasoning-ready 的证据组合一次性给齐,agent 就不需要那么多轮。但要训出这种 retriever,先得有一个能正经评估"是不是真的给齐了"的 benchmark——这正是 BRIGHT-Pro 切入的点。
说实话我看到这套问题陈述的时候挺被打动的,因为它没有装作"我又要刷一个新榜",而是认真地把"评测—训练—部署"这三个层面错配的根源点出来了。这种把问题先讲透的论文,往往后面的方法不会太烂。
2. 方法总览:一张图把全文看完
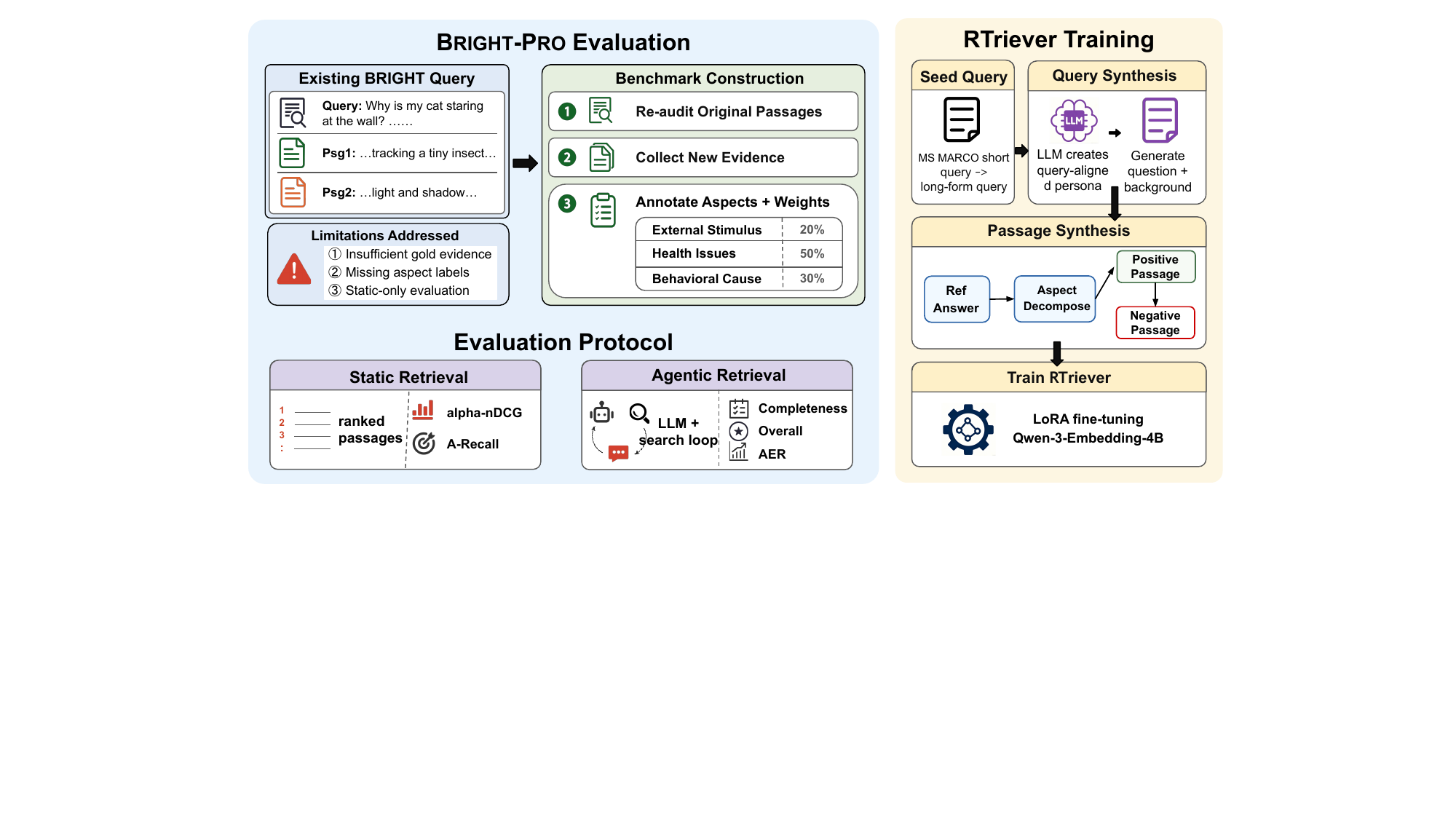
图1:左半边是 BRIGHT-Pro 评测——基于已有 BRIGHT query,三步重做(重审原始 passage / 收集新证据 / 标注 aspect + 权重),并配两套评测协议(静态 + agentic)。右半边是 RTriever 训练——MS MARCO 短 query 改写成长 query,从参考答案出发做 aspect 分解,每个 aspect 实例化为一篇 positive passage,再做 positive-conditioned 的 hard negative,最后 LoRA 微调 Qwen3-Embedding-4B
这张图把整个工作的两个支柱一次性铺开了。左边解决"怎么评",右边解决"怎么训",两者中间的桥梁是同一个核心理念:reasoning 是要被分解到多个 aspect 上的,retriever 的价值在于覆盖完整 aspect set,不是把同一个 aspect 反复刷高。
下面分别拆。
3. BRIGHT-Pro:把 gold 标到位,把评测搬进 loop
3.1 数据构建:三步重做 BRIGHT
为什么是 BRIGHT 而不是从零搞新数据?因为 BRIGHT 的 StackExchange 子集已经覆盖了七个 reasoning-intensive 领域(生物、地球科学、经济、心理、机器人、Stack Overflow、可持续生活),query 是真实用户写的,主题广。但 gold 标注做得不够细——所以 BRIGHT-Pro 是在原始 BRIGHT 上做三步重做:
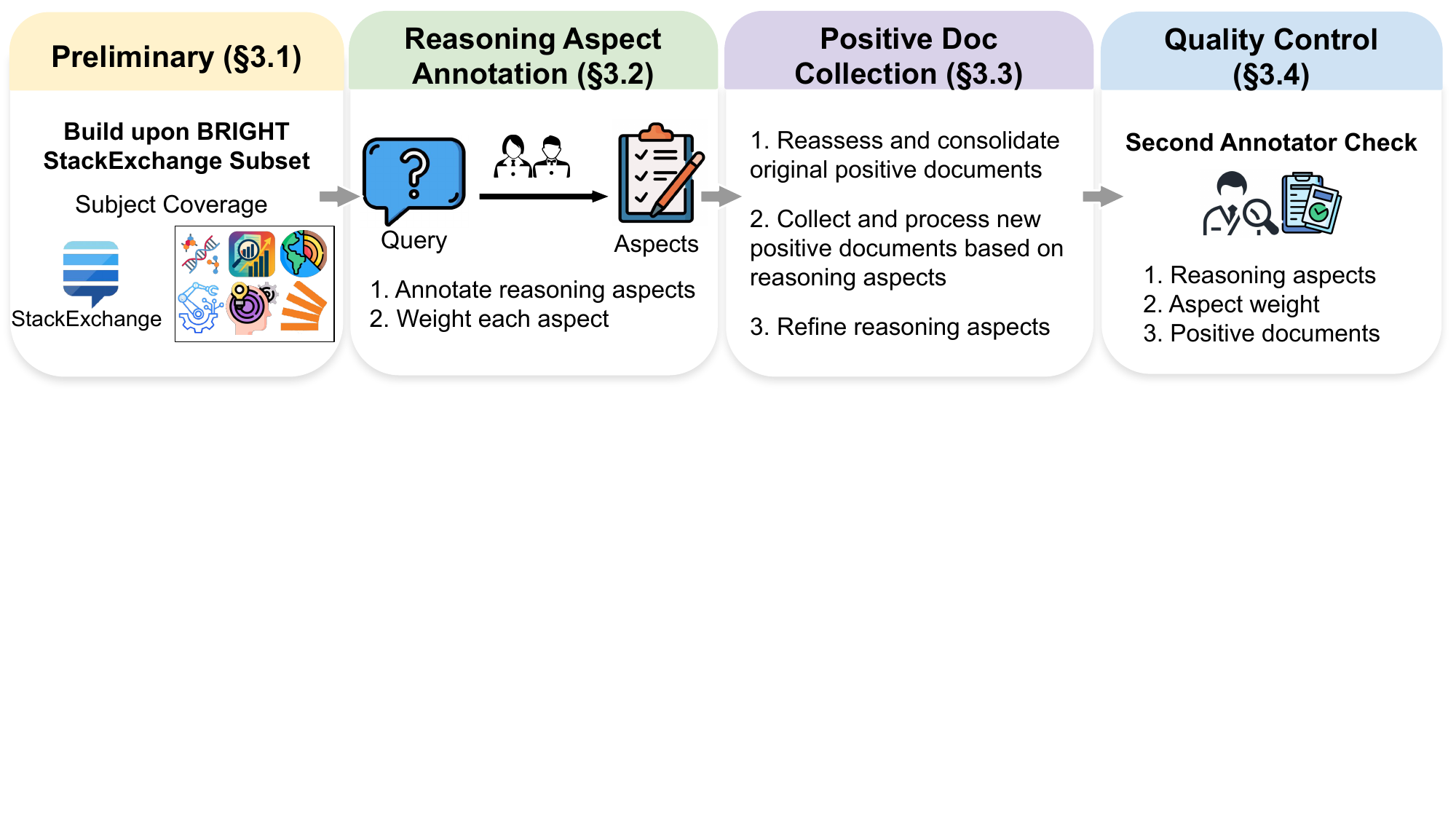
图2:BRIGHT-Pro 数据构建分四阶段——基于 BRIGHT StackExchange 子集,先做 reasoning aspect 标注(拆 aspect + 打权重),再做 positive doc 收集(审旧的、收新的、精修 aspect),最后由第二位标注员做质量审查
第一步:Reasoning Aspect 标注。领域专家(每个学科找对应背景的人)先看 query,独立思考——这个问题要被一个有公信力的人回答清楚,需要哪些"前提知识 / 视角"?这些前提就是 aspects。每个 aspect 给一两句 rationale 解释为什么必须有它。
第二步:Aspect Weight 标注。aspect 之间显然不是等权的——猫的健康问题在"它在盯啥"这个 query 下,权重应该大于"猫的注意力机制"。论文用 Likert 1-5 打分,再归一化成权重 \(w_a \in [0, 1]\),且 \(\sum_a w_a = 1\)。这步设计有两个好处:一是评测可以加权计分,二是防止 retriever 通过堆砌低价值 snippets 来刷分——这个细节我觉得挺关键的,很多 benchmark 没注意。
第三步:Positive Doc 收集。先把 BRIGHT 原来的 positives 拉出来重审,能对上某个 aspect 的留下挂上去,挂不上的丢掉;然后让标注员根据每个 aspect 主动去找新的 evidence。最后第二位标注员审查 aspect / 权重 / 正例三方面的一致性。整体 weighted Cohen's κ 达到 0.742,算是稳定的标注质量。
最终数据规模看起来是这样:
| 子集 | Query 数 | 总文档 | 平均正例 / query | 平均 aspect / query | Query 平均词数 |
|---|---|---|---|---|---|
| Biology | 103 | 59,513 | 7.81 | 3.94 | 92.6 |
| Earth Science | 115 | 123,575 | 7.44 | 3.83 | 82.2 |
| Economics | 99 | 52,240 | 7.81 | 3.71 | 123.5 |
| Psychology | 100 | 54,741 | 7.07 | 3.84 | 116.2 |
| Robotics | 101 | 63,920 | 6.17 | 3.71 | 218.8 |
| Stack Overflow | 115 | 109,188 | 4.60 | 3.32 | 172.0 |
| Sustainable Living | 106 | 63,142 | 9.25 | 3.86 | 116.9 |
| 总计 | 739 | 526,319 | 7.13 | 3.74 | 131.4 |
739 个 query,52 万文档库,平均每个 query 7 篇 gold + 3.7 个 aspect。这个规模比 BRIGHT 原版"一两个 webpage"的 gold 设定,密度高了一个量级。
3.2 评测协议:三套度量打组合拳
这一节是这篇论文我最喜欢的部分,它把 retriever 的评测彻底搬进了真实使用场景。
静态评测。沿用传统 IR 的"给一个 ranked list 算指标",但主指标用 α-nDCG@25(新颖性惩罚 α=0.5)—— \(\alpha\)-nDCG 这个指标在 IR 圈不算新,但在 reasoning 检索这块用得不多。它的核心是:已经覆盖过的 aspect,再被覆盖时折扣分数。也就是说,retriever 把同一个 aspect 的 10 篇 passage 全顶到前面,得分会被惩罚——你必须给不同 aspect 都摆一篇。辅助指标是 Weighted Aspect Recall (A-Recall@k),以及作为 diagnostic 的 NDCG@k / Recall@k。
Fixed-Round Agentic 评测。把 retriever 接到统一的 LLM agent 上(GPT-5-mini 或 Qwen3.5-122B-A10B),agent 严格搜 R∈{1, 2, 3} 轮,每轮拿 top-5。每轮后都让 agent 基于"累计证据"出一个答案。报 cumulative α-nDCG@5R + reasoning completeness(用 LLM-as-Judge 按 aspect 加权打 {0, 0.5, 1})+ overall quality(1-5)。
Adaptive-Round Agentic 评测。这是我觉得最有意思的协议——agent 自己决定什么时候停。这一下就把"轮数"变成了一个可观测变量。论文为此提出 AER(Efficiency-Quality Reward):
其中 \(OQ\) 是最终回答的 overall quality,\(R\) 是搜索轮数,\(\gamma = 0.05\)。这个公式的工程直觉很直接:质量高但你要搜 10 轮,跟质量稍低但 3 轮搞定,到底谁更值得部署?AER 给你一个数。
为了控成本,所有 agentic 实验在 175 个 query(每个 task 25 个)的固定子集上跑。
4. RTriever:怎么训出能"凑齐 aspect"的 retriever
这部分讲训练侧的 gap 和论文的解法。
4.1 痛点:现有合成数据的"单正例"陷阱
现有 reasoning 检索的训练数据(ReasonIR、DIVER 用的合成 corpus),通常是 (query, 一篇 positive, 一堆 hard negatives) 这种格式。对比学习目标是把那一篇 positive 排到最前面。结果就是 retriever 学到的是"找出 一篇 相关文档",而不是"找出能 一起 答完 query 的一组互补文档"。
这个问题在 BRIGHT-Pro 上立刻暴露——文章里有个挺扎眼的数据:ReasonIR-8B 虽然是 reasoning-trained 的 8B 模型,但在 α-nDCG@25 上只拿了 41.0,排在 13 个 retriever 里的倒数第 3。原因就是它的合成 pipeline 优化的是"single-passage 信号",不是 multi-aspect coverage。
我之前给一个客户做内部知识库的 retriever,碰到的现象其实是一模一样的——top-5 召回里有 4 篇都是同一个 aspect 的 paraphrase,剩下 1 篇还跑题了。当时我以为是数据多样性不够,现在看其实更深层的原因是训练目标只在乎"那 1 篇是不是排第一"。
4.2 合成 pipeline:从参考答案反推 aspect
RTriever-Synth 的思路有一个特别值得拎出来的设计选择:不从 query 直接合成 positive,而是先合成一个完整的 reference answer,再从答案反推 aspect。
完整流程:
Stage 1 - Query 改写。从 MS MARCO 抓 query 作种子,配上 PersonaHub 的 persona,让 LLM 把短查询改写成长 query + 背景的 DeepResearch 风格 post。再用一个分类器把每个 query 打成 factual 或 analytical。
Stage 2 - Aspect 分解 + Positive 生成。对每个 analytical query: 1. 先让 LLM 给一个完整的 self-contained reference answer 2. 再让另一个 LLM 把这个答案拆成 2-3 个 non-overlapping 的 aspect,每个 aspect 写明白它在答案里担当哪一块 3. 每个 aspect 出一个 passage blueprint(rationale、passage type、source、title、3 句 TL;DR) 4. 用专门的 passage realization call 把 blueprint 实例化成完整 passage
这一步的妙处在于"每篇 positive 都是 load-bearing 的"——它必须承担 reasoning chain 的某一段,单独看回答不全 query,合起来才行。
Stage 3 - Positive-Conditioned Hard Negative。这才是真正的设计亮点。Hard negative 不是从 corpus 里随便挑相似的,而是 看着 positive 的 title 和 TL;DR,让 LLM 生成"主题相关、词汇相近,但故意 缺 那个关键 aspect"的 passage。每个 negative 都被显式指定要回避哪个 aspect。
这个 hard negative 的构造方式我看了挺久——它其实是在告诉 retriever:别只学 topical similarity,要学到 aspect-level 的 relevance。挺漂亮的设计。
4.3 训练配置
- 从 100 万 MS MARCO query 里抽 14 万,过滤后得到 14 万 (query, positives, negatives) bundle
- 每步训练随机抽一个 positive + 一个 negative
- LoRA 微调 Qwen3-Embedding-4B:rank \(r=16\),scaling \(\alpha=32\),挂在所有 linear projection 上,原 embedding 参数冻结
- 损失:InfoNCE,温度 \(\tau = 0.02\),in-batch negative 也用
- 5 epoch,peak lr \(1 \times 10^{-5}\),5% warmup,bf16 + DeepSpeed ZeRO-2
- 2 张 NVIDIA B200,per-device batch 384,effective batch 768
- 序列长 2048
整体训练成本相当克制——14 万样本 + 2 张 B200 + LoRA,跑 5 个 epoch。这个配置在工业界基本是一个 retriever 团队一周就能复现的量级。
5. 实验:榜单和 agent loop,分数会打架
5.1 静态评测:reasoning-trained 阵营压通用阵营
先看静态 α-nDCG@25 的总榜:
| 排名 | Model | BRIGHT NDCG@10 | BRIGHT-Pro α-nDCG@25 |
|---|---|---|---|
| 1 | BGE-Reasoner-8B | 33.8 | 68.0 |
| 2 | DIVER-4B-1020 | 30.6 | 63.7 |
| 3 | DIVER-4B | 28.9 | 59.9 |
| 4 | RTriever-4B (ours) | 27.7 | 55.3 |
| 5 | INF-Retriever-Pro (7B) | 26.3 | 53.8 |
| 6 | Qwen3-Embedding-8B | 23.7 | 49.5 |
| 7 | Instructor-XL (1.5B) | 18.9 | 46.3 |
| 8 | OpenAI Embed-3L | 17.9 | 45.8 |
| 9 | GTE-7B | 22.5 | 45.5 |
| 10 | GritLM (7B) | 21.0 | 44.1 |
| 11 | ReasonIR-8B | 24.4 | 41.0 |
| 12 | BM25 | 14.5 | 40.3 |
| 13 | EmbeddingGemma-300M | 18.9 | 39.4 |
几个观察:
第一,reasoning-trained 阵营和通用阵营之间出现明显断层——BGE-Reasoner、DIVER 双子、INF-Retriever-Pro、RTriever-4B 这五个在 α-nDCG@25 上集中在 53-68 区间,跟下面的 Qwen3-8B / OpenAI / GTE 拉开了 4-14 分。
第二,训练目标比参数量重要。RTriever-4B 只有 4B,却把 Qwen3-Embedding-8B(同源 backbone 的更大版本)甩开 5.8 分。这个 delta 几乎完全归功于训练数据——把 single-positive 换成 aspect-decomposed positives。
第三,ReasonIR-8B 摔得很惨——8B 参数 + reasoning-trained 的招牌,在 BRIGHT NDCG 上还有 24.4,但在 α-nDCG@25 上掉到 41.0。论文给出的解释是它的 pipeline 优化的是 BRIGHT-style 单段信号,不是多 aspect 覆盖。这个结果其实就是 BRIGHT-Pro 这把"新尺子"想暴露的事情——老榜上看着不错的模型,在新维度上可能完全不在状态。
我对这个对比的态度是:结论是真的,但要小心 RTriever-4B 跟 BGE-Reasoner-8B 之间 12.7 分的差距。BGE-Reasoner 是更大模型 + 更精细的训练,RTriever 在 4B 体量下做到第 4 已经很不错,但论文标题不至于换成"我们 SOTA 了"——它自己也很坦诚。
5.2 Fixed-Round Agentic:榜单顺序开始翻车
用 GPT-5-mini 当 agent,每个 retriever 跑 1-3 轮,看累计 α-nDCG 和最终答案质量:
| Model | R3 α-nDCG@15 | R3 Compl. | R3 Overall |
|---|---|---|---|
| BGE-Reasoner-8B | 63.04 | 4.42 | 4.31 |
| DIVER-4B | 53.08 | 4.38 | 4.29 |
| RTriever-4B (ours) | 50.79 | 4.37 | 4.25 |
| GTE-7B | 52.68 | 4.33 | 4.23 |
| DIVER-4B-1020 | 51.56 | 4.33 | 4.16 |
| Qwen3-8B | 51.75 | 4.26 | 4.10 |
| BM25 | 51.48 | 4.25 | 4.12 |
| Instructor-XL | 43.48 | 4.26 | 4.14 |
| ReasonIR-8B | 44.90 | 4.16 | 4.11 |
| GritLM (7B) | 47.05 | 4.24 | 4.07 |
读这张表的时候我愣了一下——DIVER-4B 反超了它的更新版本 DIVER-4B-1020(Overall 4.29 vs 4.16)。在静态榜上 1020 是赢的,到 agent loop 里反过来了。论文没有给出特别清晰的因果,只是说"static rank 和 answer rank 在 top-tier 以下会 diverge"。
更刺眼的是 BM25——静态评测时 40.3 垫底,到 R3 agent loop 里 α-nDCG@15 蹿到 51.5,已经能跟一堆 8B 通用 embedder 五五开了。论文给的解释是:LLM 在多轮中会主动改写 query,把抽象意图翻译成具体关键词,BM25 的"词汇匹配硬伤"被 LLM 给弥补了。
这条结论对工程的启发很直接:如果你已经有一个能写好 follow-up query 的 LLM agent,BM25 加上下文重写可能比花大钱跑 8B embedder 更划算。当然,前提是你的 agent 写 query 写得过 LLM-issued follow-ups——这本身又是另一个变量。
5.3 Adaptive-Round:AER 揭穿"质量高但磨蹭"的模型
按"mean AER across GPT-5-mini and Qwen3.5" 排序:
| Model | Agent | #R | Compl. | Overall | AER |
|---|---|---|---|---|---|
| BGE-Reasoner-8B | GPT-5-mini | 5.10 | 4.63 | 4.43 | 3.65 |
| Qwen3.5 | 4.14 | 4.22 | 3.99 | 3.44 | |
| RTriever-4B (ours) | GPT-5-mini | 6.01 | 4.53 | 4.43 | 3.51 |
| Qwen3.5 | 4.89 | 4.26 | 4.06 | 3.38 | |
| BM25 | GPT-5-mini | 5.73 | 4.50 | 4.42 | 3.53 |
| Qwen3.5 | 5.21 | 4.19 | 4.01 | 3.31 | |
| DIVER-4B | GPT-5-mini | 5.91 | 4.57 | 4.46 | 3.53 |
| Qwen3.5 | 5.56 | 4.20 | 4.02 | 3.29 | |
| DIVER-4B-1020 | GPT-5-mini | 5.61 | 4.54 | 4.43 | 3.56 |
| Qwen3.5 | 6.57 | 4.18 | 3.96 | 3.11 | |
| Qwen3-8B | GPT-5-mini | 6.27 | 4.52 | 4.49 | 3.50 |
| GTE-7B | GPT-5-mini | 6.67 | 4.62 | 4.51 | 3.44 |
| GritLM (7B) | GPT-5-mini | 7.03 | 4.51 | 4.47 | 3.36 |
| ReasonIR-8B | GPT-5-mini | 7.17 | 4.48 | 4.42 | 3.31 |
这张表把 AER 的价值彻底体现出来了。GTE-7B 是 Overall 最高的(4.51),但它要搜 6.67 轮才能搜到,AER 直接掉到 3.44——比 RTriever-4B(3.51,6.01 轮)和 BGE-Reasoner(3.65,5.10 轮)都差。
你想想看,部署一个 GTE-7B + agent loop 的系统,你的端到端成本会比 RTriever-4B 高约 11%(轮数比),换来的是 1.8% 的质量提升。在生产环境里这种 trade-off 大概率不划算。
还有一个不太显眼但挺重要的现象:换 agent backend 时,top-tier retriever 排名稳定,lower-tier 排名乱跳。DIVER-4B-1020 在 GPT-5-mini 上排第 2(AER 3.56),换 Qwen3.5 后掉到第 7(AER 3.11)。RTriever-4B 反而在 Qwen3.5 上更稳,升到第 2。这说明 lower-tier retriever 的表现和 agent 的兼容性强相关——选型时只看一个 agent 上的数据,很容易误判。
5.4 Qualitative Analysis:五种 agent 故障模式
论文还分析了 175 条 RTriever-4B + GPT-5-mini 的 adaptive trace,总结出五种典型 pattern,挑三个我觉得最有共鸣的说说:
Evidence Deprivation + Speculative Reasoning。retriever 完全没召回到 gold,LLM 还是得答,于是开始"听上去合理但其实是编的"。论文给的例子是 Gazebo Garden 那个问题,13 轮没召回任何 gold,agent 错误地推断那个 plugin 已经 deprecated 了。这种 case 对生产环境最危险——幻觉了用户都不知道。
Repetition Bias。早期几轮 retriever 锁定到一个 topic-adjacent cluster,后续无论 agent 怎么改写 query,retriever 都把同一批 passage 翻来覆去丢出来。论文的例子里 12 轮搜了 60 个 slot,只有 28 个 unique doc。这种情况下加轮数不仅没帮助,还在浪费 token。
Aspect Tunnel Vision。query 是多 aspect 的,但 retriever 只往一个 aspect 钻。agent 的 query 每轮都不一样,但语义上其实在同一个 aspect 里打转。Gold 在另一半 aspect 上,永远碰不到。
这三种 pattern 都是 静态评测压根察觉不到的失败模式——retriever 在 top-5 里贡献了"看起来还行"的 passage,但在 loop 里被 lock-in 了。这恰恰是 BRIGHT-Pro 想暴露的事情。
6. 我的判断:这篇论文到底好在哪、问题在哪
6.1 真正有价值的地方
评测哲学的升级。这是这篇论文最值钱的部分——它把 retriever 的评测从"静态 ranked list"拉到了"agent loop 里的端到端 utility"。AER 那个公式不复杂,但它解决了一个所有 Deep Research 团队都遇到的现实问题:质量高的 retriever 如果要烧 10 轮才达到那个质量,对生产没意义。
Aspect 化的设计贯穿评测和训练。BRIGHT-Pro 标 aspect 权重、RTriever-Synth 从参考答案反推 aspect、α-nDCG 惩罚 aspect 重复,这三件事是 同一个理念 在三个层面的落地。理念一致性高的论文,工程上更容易迁移。
坦诚地报告了 BM25 的逆袭。要是换个团队可能就把 BM25 的结果藏起来——"我们做了个 4B 模型超越了一堆 8B"——但作者大方地告诉你 BM25 在 agent loop 里能上桌。这种对自己工作的相对定位很清醒。
6.2 我觉得有点 weak 的地方
RTriever-4B 没有打到 SOTA。静态榜第 4,agentic 榜第 2-3,没法说是"开创性"。它的真实贡献其实在于 数据合成 pipeline——证明了"aspect-decomposed positives + positive-conditioned hard negatives"这套 recipe 能让 4B 模型挤进 reasoning-trained 第一梯队。但如果你只看模型分数,差距还是在的。
Agentic 评测只用了 175 个 query。这个样本量为了控 API 成本可以理解,但 7 个 task 每个 25 query,统计意义上不是特别强。AER 的排名差异有时候只在 0.05 量级,这个样本下波动可能盖过 signal。
LLM-as-Judge 用的是 GPT-5。判 agent 答案质量的是 GPT-5,agent 之一也是 GPT-5-mini。同一个家族的模型自己评自己家族的输出,会不会有偏?论文没做交叉验证(比如用 Claude 做 judge 对比一下)。这个我也只能算一个"质疑"而不是"硬伤"——因为目前业界都是这么做的,全是 GPT 系 evaluator。
与 BGE-Reasoner 的差距没有挖透。RTriever-4B 在静态榜上比 BGE-Reasoner 低 12.7 分,论文归因于参数量(4B vs 8B),但没做"把 RTriever-Synth 数据丢给 BGE-Reasoner backbone 再训一次"这种关键对照实验。所以读者其实没法判断:到底是数据 pipeline 不够好,还是 backbone size 拉不开?
6.3 对工程的启发
如果你在做 Agentic Search / RAG / Deep Research,这篇论文有几个直接可拿的东西:
第一,retriever 选型要看 AER,不只是 NDCG。如果你的产品是按轮数收费 / 按延迟约束,AER 比单纯的 Compl 重要。
第二,BM25 不要轻易扔。如果你的 agent loop 已经能产出高质量 follow-up query,BM25 在 agentic 协议下能跟 8B 通用 embedder 五五开。混合检索(dense + sparse)依然是被低估的选择。
第三,合成数据时,不要再用 single-positive 套路。Aspect-decomposed 的 reference-answer-first 这套,比直接从 query 合成 positive 在多 aspect query 上明显更强。RTriever-Synth 的 prompt 设计 paper 没放完整的,但 idea 不复杂——值得自己内部数据试试。
第四,关注 retriever 在 agent loop 里的 failure mode。论文那五种 pattern(早期高效、证据剥夺、重复偏差、aspect 隧道视觉、提早成功后犹豫)几乎是所有 RAG 系统的通病。评测时如果只看 final answer accuracy,看不到这些 pattern。建议加 retrieval trace 的 qualitative review。
7. 收尾
这篇论文不是那种"我们刷了榜你来抄"的工作,它更像是给整个 reasoning retrieval / agentic search 社区递了一把更锋利的尺子。BRIGHT-Pro 的 multi-aspect 标注 + agentic 协议,可能会成为接下来一年里这个领域大家事实上的对照标准——尤其是 AER 这个指标,工程上太顺手了。
RTriever-4B 本身不算 SOTA,但合成数据 pipeline 给了一个清晰的样板。如果你有内部的 reasoning-intensive query 数据,把 query 改写 + aspect 分解 + reference-answer-first positive 合成这一套照抄一遍,大概率比纯 single-positive 的训练管线强。
最后忍不住吐槽一句——论文里 GTE-7B 是 Overall 最高但 AER 最低那个对比,让我想起之前调过的一个客户系统:模型选最大的,效果"刚好够用",但每次回答要等 12 秒。客户问"是不是该上更大的模型",我说不,先把多轮的轮数砍下来。砍完之后 AER 升了 30%——这就是 BGE-Reasoner 那种"质量+效率双优"的真实价值。
值得读,值得参考,值得抄 pipeline。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我