iTool:合成数据加越多越没用?哈工大+华为用 MCTS 找出"那一小片错",8B 反超 GPT-4o
核心摘要
合成数据训工具调用模型,有个特别让人头大的现象——前 30% 的数据加进去模型嗖嗖往上涨,再往后曲线直接趴窝。哈工大 SCIR 实验室和华为联合的这篇 EMNLP 2025 论文 iTool,把这个"训练增益衰减"问题拆穿后发现:错的不是整段回复,77% 的 bad case 都集中在参数名/参数值这一小片碎片。于是作者搞了一套"易到难课程式 SFT 热身 + MCTS 步级偏好对 + 迭代 DPO"的组合拳,把错误碎片精准揪出来反复打磨。最终 LLaMA-3.1-8B 基座,在 BFCL v3 上拿到 63.26% 的 overall,反超 GPT-4o-2024-08-06(62.19%)和 GPT-4-turbo(61.89%),复杂场景 Live 子集涨 3.3 个点,多轮 Multi-turn 涨 6.46 个点。一句话评价:思路漂亮,工程量真不小,MCTS 不是用来推理的、是用来挖错误数据的——这个用法挺值得借鉴。
论文信息
- 标题:iTool: Reinforced Fine-Tuning with Dynamic Deficiency Calibration for Advanced Tool Use
- 作者:Yirong Zeng¹, Xiao Ding¹(通讯), Yuxian Wang², Weiwen Liu³, Wu Ning², Yutai Hou², Xu Huang⁴, Duyu Tang², Dandan Tu², Bing Qin¹, Ting Liu¹
- 单位:¹哈尔滨工业大学 SCIR 实验室,²华为技术有限公司,³上海交通大学,⁴中国科学技术大学
- 会议:EMNLP 2025 Main
- arXiv:2501.09766v5
- 代码:github.com/zeng-yirong/iTool
一个让人皱眉的现象:合成数据真的越加越好吗?
先聊一个我自己之前做工具调用 SFT 时碰到过的怪事。
数据合成 pipeline 调好了,按 ToolACE 那种 self-evolution 的玩法批量生产工具调用样本,从 1 万条拉到 10 万条。前两万条加进去,BFCL Live 上肉眼可见地涨;继续加到五万,曲线开始走平;加到十万,简单题(Non-live)那条线还在缓慢爬,复杂题(Live)那条线基本就不动了。
当时我们组讨论了一下,结论比较模糊,有人觉得是数据多样性不够,有人觉得是模型容量到顶。后来这事就搁下了——反正复杂场景的提升空间,再怎么堆数据也挤不出来了。
iTool 这篇论文打动我的第一个点,就是它非常"轴"地把这个现象坐实了。
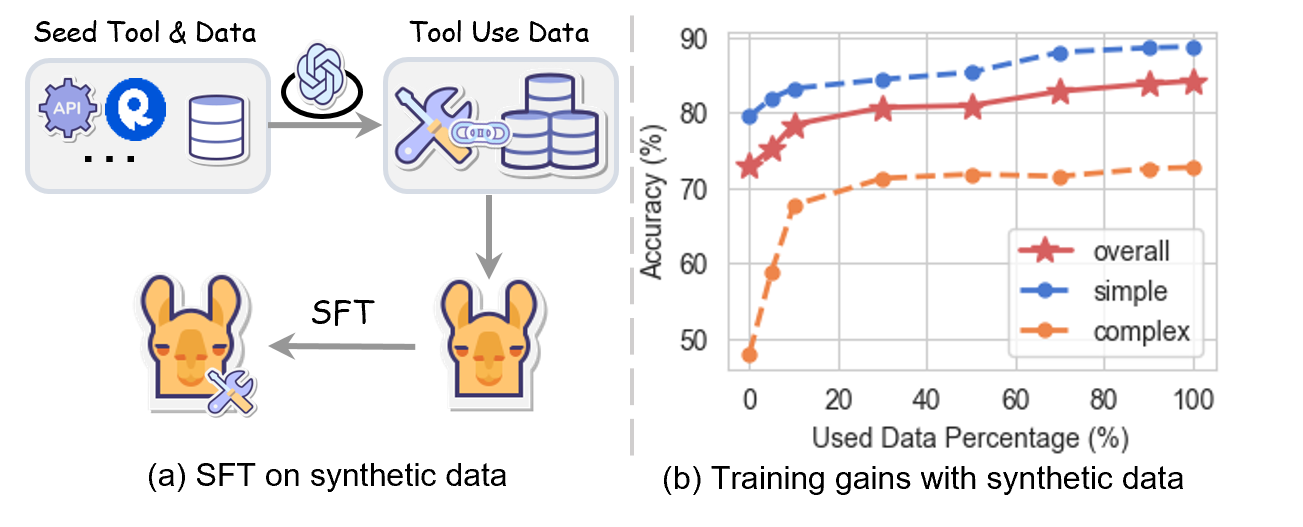
图1:(a) 合成数据走 SFT 流水线训练工具调用模型的标准做法;(b) 横轴是用了多少比例的训练数据(最大 100K),纵轴是 BFCL 准确率。蓝色 simple(Non-live)那条线还在涨,橙色 complex(Live)那条线 30% 之后基本拍平——红色 overall 也是。这就是论文要解决的"训练增益衰减"。
作者把 LLaMA-3.1-8B-Instruct 在 ToolACE 上分别用 0%、5%、10%、30%、50%、70%、90%、100% 数据做 SFT,画出来这条曲线。30% 是个明显的拐点,过了之后简单场景还能慢慢涨,复杂场景几乎纹丝不动。
这就有意思了。如果只是堆数据解决不了问题,那问题到底出在哪?
拆开 bad case 看:错的不是回答,错的是"参数那一小撮"
作者做了第二件事——把所有 bad case 拉出来按错误类型分类。

图2:典型工具调用任务示例。多轮对话场景下,第二轮模型把 weather='unknown'(红字)这种错误参数填进去了——但你看整个 tool call 的结构其实是对的,错的就这么一小片碎片。
然后是关键的图 3:
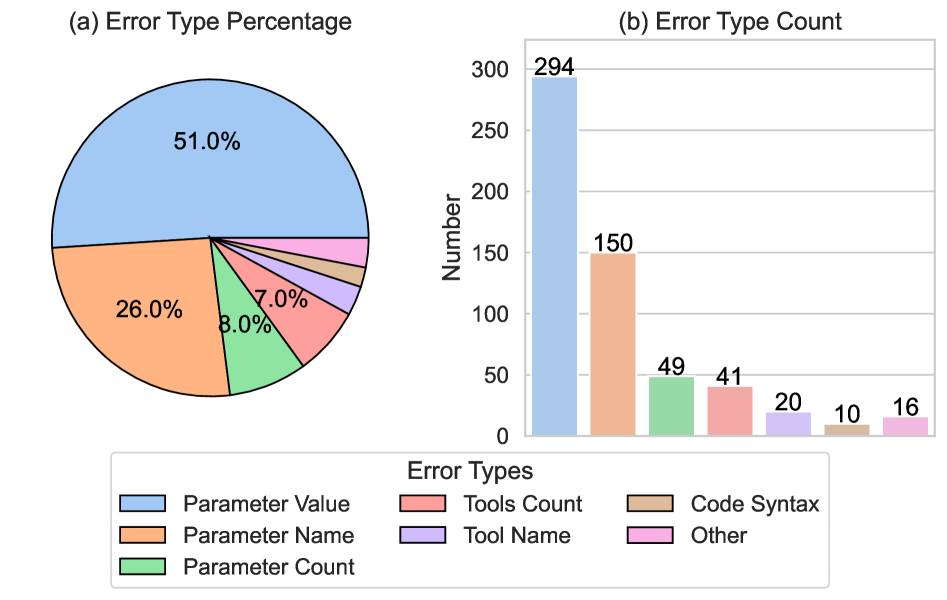
图3:(a) 饼图——参数值错 51%、参数名错 26%、参数个数错 8%、工具调用次数错 7%、工具名错少量、其他少量;(b) 柱状图给了具体数量:Parameter Value 错 294 次、Parameter Name 错 150 次。
看到这个分布我愣了一下。
77% 的错误都集中在参数名和参数值上。也就是说,模型其实知道要调哪个工具、知道大概该传几个参数,就是某个参数的具体值或者名字写错了。结构对、骨架对,肉错了一小撮。
这个观察给整篇论文定了调:既然错的是碎片,那就用步级(step-level)信号去精确定位、精确修补这些碎片,而不是用整条 trajectory 的 outcome reward 去更新整个回复。
说到这里,其实和 PRM(Process Reward Model)那条路线的精神是一致的——别用 sparse 的最终对错信号训练,要用密集的过程信号。但 iTool 没去训一个 PRM,而是用 MCTS 的 Q 值代替了 PRM——这个工程上的取巧值得展开聊聊,后面再说。
方法核心:热身 SFT + MCTS 偏好挖矿 + 迭代 DPO
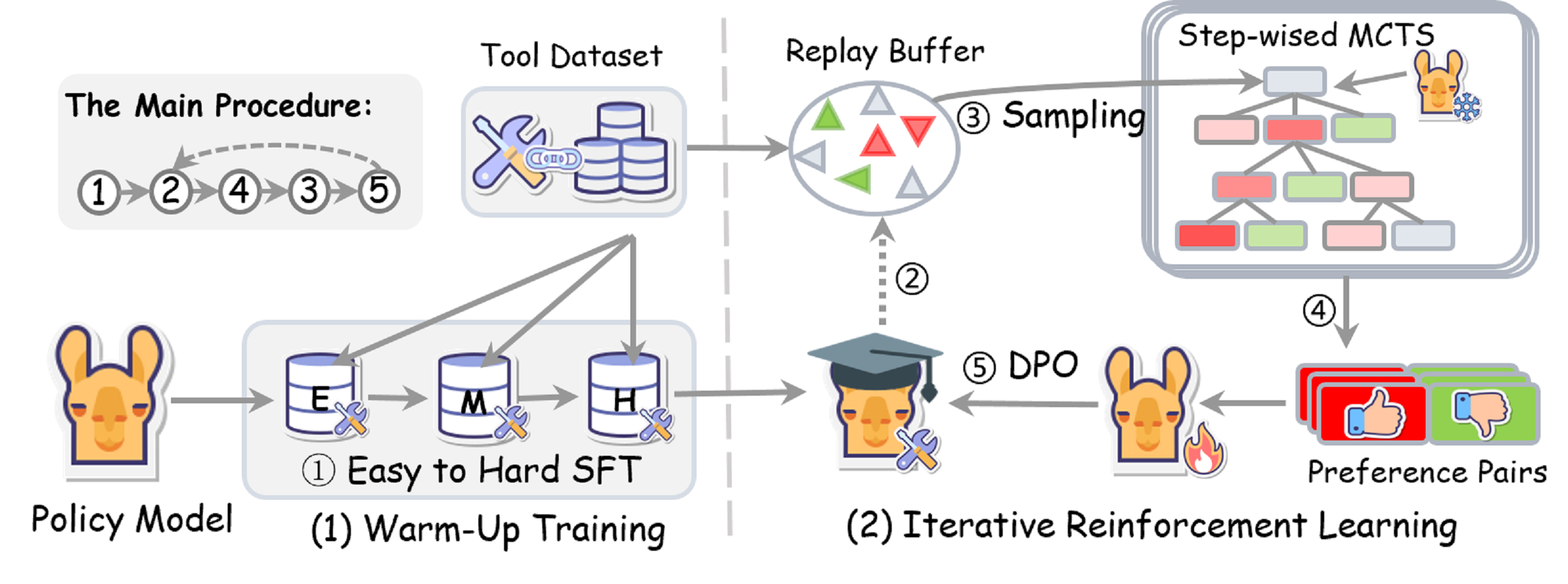
图4:方法总览。整套流程的执行顺序是 ①→②→④→③→⑤(注意第 4 步 step-wise MCTS 采样在第 3 步实际数据采样之前——MCTS 给出 fine-grained preference pairs 后才进入采样)。两段式架构:(1) Warm-Up Training 是冷启动,做 Easy→Medium→Hard 的课程式 SFT;(2) Iterative Reinforcement Learning 是核心,策略模型不停从 buffer 中挖出复杂样本,用 MCTS 探索响应路径,找出"高 Q 值的对"和"低 Q 值的错",通过 DPO 拉开差距。
整个方法可以拆成两块来看。先看热身。
第一块:Easy-to-Hard 课程式 SFT 热身
作者先把训练集按三个维度切成 easy/medium/hard:
- a:候选工具集大小
- b:工具描述字符串长度
- c:响应中需要的工具调用次数
具体规则: - hard:a≥4 或 b\gt2000 或 c≥4 - medium:1\lta\lt4 或 b\lt2000 或 c\lt4
- easy:a≤1 且 b\lt1000 且 c≤1
然后按 easy → medium → hard 的顺序依次 SFT,三个阶段的学习率还做了对应的衰减:easy 5e-5、medium 2e-5、hard 1e-5。
这个设计有点像人学新东西的方式——先看简单例子建立模式,再去啃复杂的。
效果上确实有用:
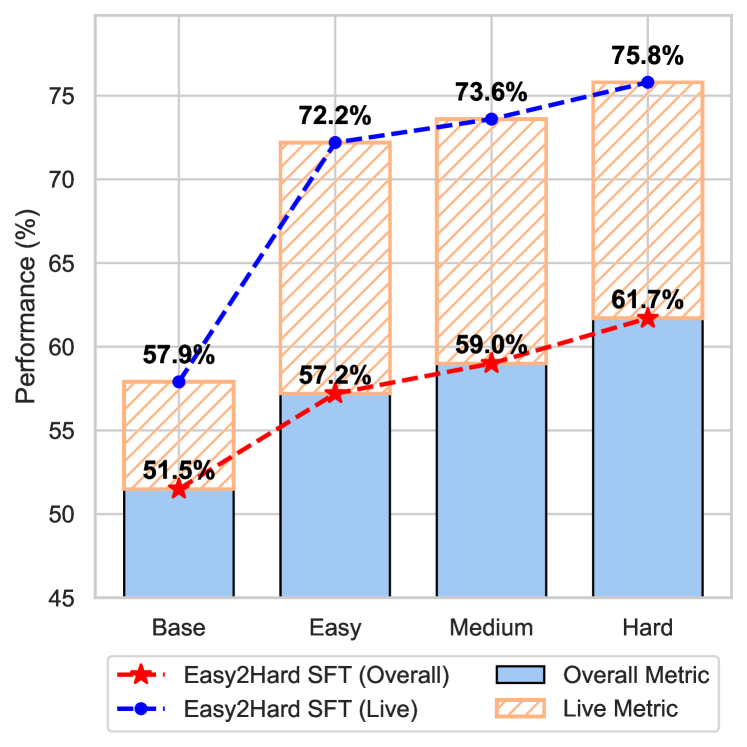
图5:纵轴是 BFCL 准确率,横轴是训练课程的四个阶段(base/easy/medium/hard)。蓝色实心柱是 overall,橙色斜线柱是 Live;红星折线是 overall metric 上的进展,蓝点折线是 Live metric。从 Base 直接做 hard 的 SFT 涨不上去,但通过 easy 阶段先建立基础再啃 hard,复杂场景从 57.9% 拉到 75.8%。
我看到这个图的第一反应是:"先学简单的"听起来像废话,但确实需要消融实验来证明它真的有用。从 base 直接上 hard 的 SFT,在 Multi-turn 这种场景上很容易学崩——这跟之前 OpenAI 在 GSM8K 上做 curriculum learning 的发现是一致的,只不过这里用在了工具调用上。
第二块:MCTS 偏好挖矿——这才是真正的活儿
热身完之后,进入核心的迭代强化学习。这块的逻辑链条是这样的:
策略模型 → 用困惑度 h 给 buffer 里的样本打分
→ 挑出 top 10% "复杂"样本
→ 对每个困难样本跑步级 MCTS
→ 从搜索树里拿到 (高 Q 步骤, 低 Q 步骤) 偏好对
→ 用 SimPO(DPO 变种)更新策略
→ 回到第一步重新打分
第一步:怎么定义"困难样本"?
用模型自己的生成困惑度:
困惑度越高,说明模型对这条样本越不确定。每轮迭代取 top 10% 的高困惑度样本进入下一阶段。这其实是一个隐式的 active learning——让模型自己挑出"我学不会的东西"反复练。
第二步:步级 MCTS 怎么做?
这是论文最讲究的地方。MCTS 标配三阶段:
Select:用 PUCT 公式(AlphaZero 那一套)选下一个节点:
关键的工程细节是——步是怎么切的。作者强制用终止字符(逗号、句号、右括号)来分割,这样每一"步"刚好对应一个细粒度的语义单元,比如 weather='unknown' 就是一个完整的"参数赋值"步。这保证了 MCTS 的步级信号能精确定位到参数级别的错误。
Expand:在叶子节点扩展并打分。奖励由两部分组成:
其中 \(\mathcal{O}\) 是结果正确性,\(\mathcal{C}\) 是 LLM-as-Judge 的自评分(用论文 Appendix 里那个 Eval Prompt,让模型给 A/B/C/D 四档打分,对应权重 1.0/0.1/-1.0/-2.0,采样四次取加权平均)。
我看到这个奖励设计的时候稍微皱了下眉——\(\mathcal{O}\) 这一项要怎么算的? 论文没把 \(\mathcal{O}\) 的具体形式写得很清楚,估计是看当前路径能不能 rollout 出一个能匹配 ground truth 的完整响应。整体上还是 outcome 信号驱动的,只是通过 MCTS 把 outcome 摊到了每一步上。这是用 MCTS 替代 PRM 的妙处也是局限——便宜,但不如真正的 PRM 那么"懂"过程对错。
Backup:终态后从下往上更新 V、Q:
第三步:怎么挖偏好对?
每个内部节点都有一组孩子节点,作者从中挑 Q 值最高的 step 当 chosen,最低的 step 当 rejected,然后把从根到这个父节点的路径作为前缀。这样得到的偏好对就是"在同一个上下文下,这一步该这么走 vs 不该那么走"——天然的 fine-grained 信号。
而且作者做了几个数据清洗:相似度\gt95% 的对扔掉、Q 值差\lt0.1 的对扔掉、chosen 自身 Q\lt0.3 的对扔掉。这几个阈值看起来是经验性的,但确实能保证偏好对的"对比度"。
第四步:偏好优化用啥算法?
用了 SimPO(DPO 的 reference-free 变体),原因是省一份参考模型的显存:
附录里作者还对比了 DPO/IPO/ORPO/SimPO 四种算法,结论是 SimPO 略好(除了 ORPO 明显掉点之外,大家差不多)。
这套流程跑完一轮叫一个 iteration,作者发现 3 轮迭代是甜点,再多就过拟合掉点了。
一个工程细节:MCTS 参数
| 参数 | 值 |
|---|---|
| depth | 3 |
| width | 3 |
| simulation | 2 |
| iterations(树构造) | 5 |
| 探索系数 c | 1.0 |
| 温度 | 1.5 |
depth=3、width=3 这个搜索空间相当克制——27 个叶子节点的搜索树,配合 8×V100 单轮 7 小时的开销,工程上还撑得住。如果 depth=5 width=5,开销直接炸。
实验:8B 模型反超 GPT-4o,但读榜要小心
主结果:BFCL v3 leaderboard
这是论文最亮眼的一张表:
| Rank | Overall | Model | Non-live | Live | Multi-turn | Rel/Irrel |
|---|---|---|---|---|---|---|
| 1 | 63.26 | ♣ iTool-8B (FC) | 88.82 | 78.29 | 23.84 | 84.90/80.72 |
| 2 | 62.19 | ♠ GPT-4o-2024-08-06 (FC) | 86.15 | 75.43 | 25.00 | 63.41/82.93 |
| 3 | 61.89 | ♠ GPT-4-turbo-2024-04-09 (FC) | 88.80 | 76.23 | 24.88 | 73.17/79.76 |
| 4 | 60.47 | ♠ GPT-4o-mini-2024-07-18 (FC) | 83.72 | 70.19 | 27.50 | 80.49/71.77 |
| 5 | 60.44 | ♣ ToolACE-8B (FC) | 88.94 | 74.99 | 17.38 | 80.49/85.71 |
| 7 | 57.99 | ♣ xLAM-8x22b-r (FC) | 87.51 | 71.97 | 14.50 | 85.37/67.29 |
| 9 | 57.69 | ♣ Hammer2.0-7b (FC) | 88.54 | 69.79 | 14.75 | 95.12/68.46 |
| 27 | 50.15 | ♥ Llama-3.1-8B-Instruct (Prompt) | 81.15 | 57.93 | 11.38 | 78.05/41.62 |
♠ 闭源,♥ 开源基座,♣ 工具调用专门微调
怎么读这张表?
iTool-8B 在 overall 上确实拿了第一,比 GPT-4o 高出 1.07 个点,比 ToolACE-8B(同样是 LLaMA-3.1-8B 基座)高 2.82 个点。Live 子集比 ToolACE-8B 涨了 3.30 个点,Multi-turn 涨 6.46 个点。
但说实话,Multi-turn 23.84% 这个绝对数还是非常低。GPT-4o-mini 拿了 27.50%(Multi-turn 反而是 GPT-4o-mini 的强项),iTool 在多轮场景上虽然比同类微调模型强了不少,但绝对水平离能放心用还差很远。
另外,Rel/Irrel 这两个指标有点反直觉——iTool 的 Irrel(识别不该调工具的能力)80.72,但 ToolACE-8B 是 85.71;xLAM-7b-r 的 Rel 是 97.56;这块其实没赢。论文在表 1 里把 Rel/Irrel 单独挂出来但没在正文重点强调,可能是因为这个维度上 iTool 没占便宜。
API-Bank 上的一致提升
| Model | API-Bank L1 | API-Bank L2 |
|---|---|---|
| GPT-4o-2024-05-13 | 76.19 | 42.96 |
| GPT-4o-mini-2024-07-18 | 74.69 | 45.93 |
| ToolACE-8B | 75.94 | 47.41 |
| iTool-8B | 78.89 | 52.87 |
API-Bank 这张表更干净,iTool 在 L1(已知 API 调用)和 L2(从工具列表里检索调用)上都拿了最优。L2 这块涨了 5+ 个点比较扎实——这个场景考的就是模型在多个候选工具里做选择的能力,跟论文核心要解决的"复杂场景下的参数错误"高度一致。
模块消融:每一块都不白加
| Models | Non-live | Live | Multi-turn |
|---|---|---|---|
| Base Model | 81.15 | 57.93 | 11.38 |
| + base SFT | 88.94 ↑7.8 | 74.99 ↑17 | 17.38 ↑6.0 |
| + IRT | 88.86 ↓0.1 | 76.51 ↑1.5 | 20.65 ↑3.3 |
| + warm-up SFT | 88.35 ↓7.2 | 75.84 ↑17.9 | 19.65 ↑8.3 |
| + IRL (iTool) | 88.82 ↑0.5 | 78.29 ↑3.2 | 23.84 ↑4.2 |
| Total Δ vs Base | ↑9.5 | ↑21.2 | ↑12.5 |
我盯着这个表看了一会儿,有个发现想说一下。
warm-up SFT 这一行的 Non-live 是降的(88.35,比 base SFT 的 88.94 低)——也就是说,课程式 SFT 在简单场景上反而稍微伤了一点。但好处是 Live 涨到 75.84、Multi-turn 涨到 19.65。这是个 trade-off:简单题略让一点,把复杂题的难关啃下来。
最后加上 IRL(迭代强化学习),Live 拉到 78.29、Multi-turn 拉到 23.84。整体 vs base SFT 在 Live 上 +3.30、在 Multi-turn 上 +6.46——这就是论文摘要里说的"complex scenarios 涨 6.5%"的来源(指 Multi-turn)。
值得提一下的是,iTool 比 base SFT 训练时间多了 2.8 倍:
| Model | Live | Multi-turn | Time Cost |
|---|---|---|---|
| Base Model | 57.93 | 11.38 | 0h |
| SFT Baseline | 74.99 | 17.38 | 10h |
| iTool | 78.29 ↑3.30 | 23.84 ↑6.46 | 28h (×2.8) |
3 倍时间换 6 个点的 Multi-turn 提升——这个性价比看起来值,但真要部署到生产环境,得看 Multi-turn 那 6 个点对你的业务关键不关键。
MCTS 真的在起作用吗?
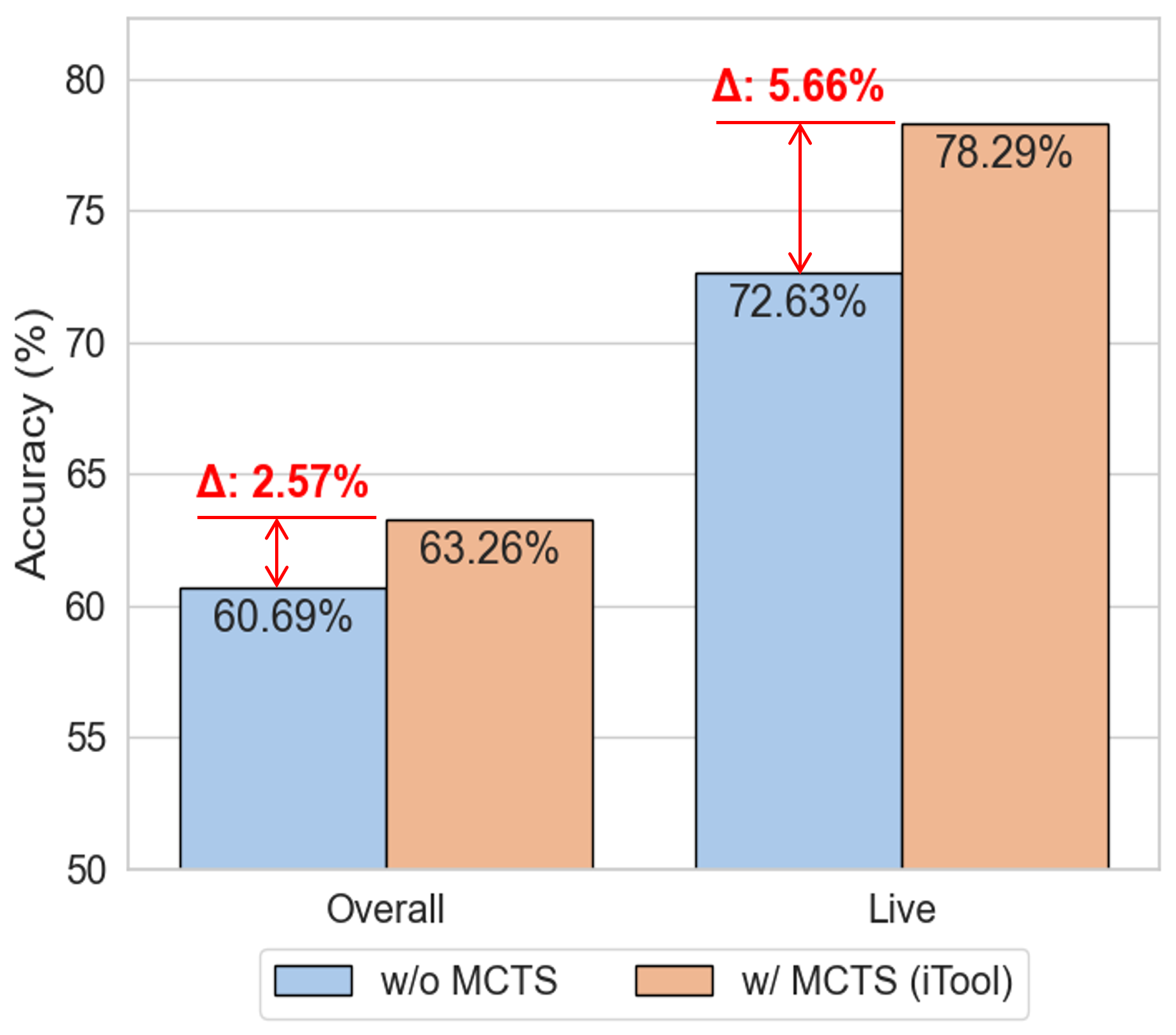
图6:消融 MCTS 的对比。w/o MCTS(蓝色)是用策略模型直接采样四次、取概率最高最低的两条作为偏好对;w/ MCTS(橙色)是 iTool 完整版。Live 子集的差距 5.66% 比 Overall 的 2.57% 大得多——说明 MCTS 主要在复杂场景下贡献。
这个对比很关键。如果只是用 self-sampling 的高低概率对当偏好数据,效果显著差一截。MCTS 的价值不在搜索本身,而在于通过 Q 值给出了一个比"概率"更靠谱的偏好排序信号。
迭代次数的甜点
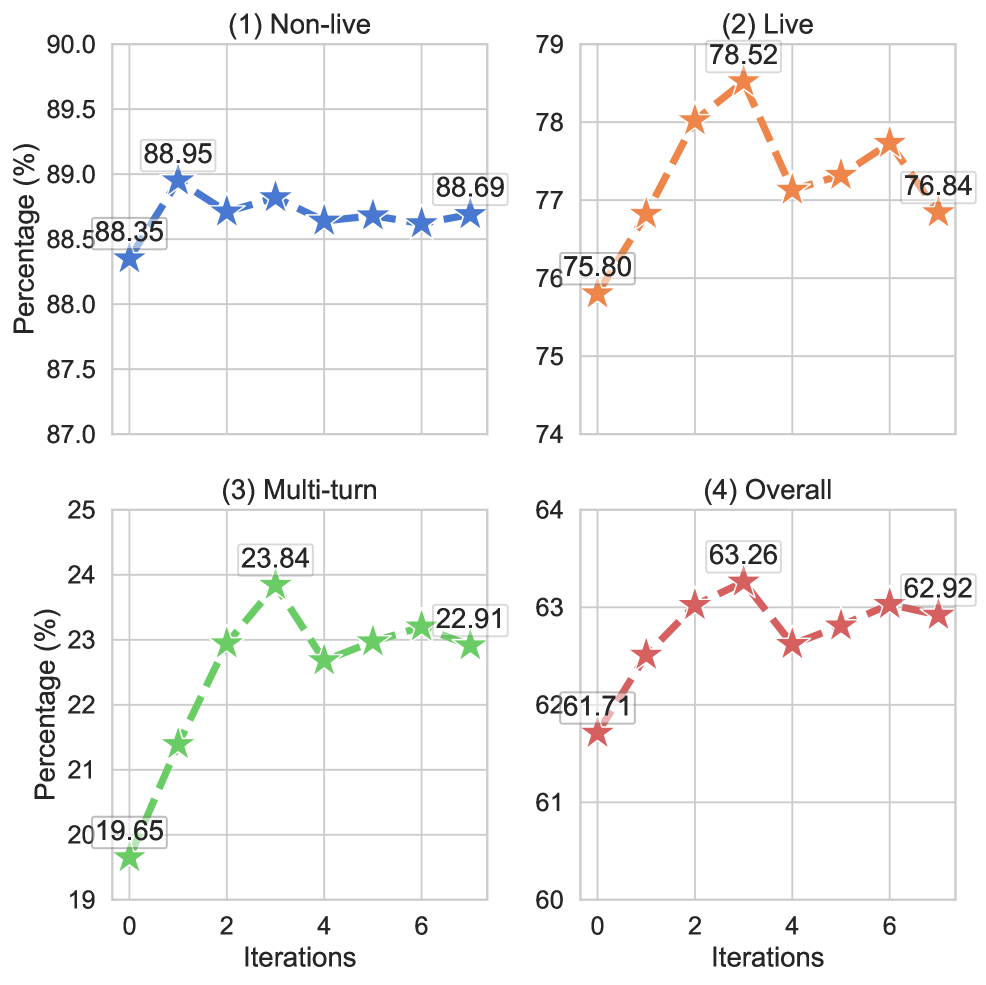
图7:横轴是迭代轮数(0 是只做 warm-up SFT 的起点)。四个子图分别是 Non-live/Live/Multi-turn/Overall。Live 第 3 轮 78.52% 是最高点(注意这个数比表 1 的 78.29% 略高,论文最终选的是综合最优 checkpoint),Multi-turn 也是第 3 轮 23.84% 最高。再继续迭代,所有指标都在掉。
迭代 3 轮是甜点。继续迭代会过拟合——MCTS 探出来的偏好对开始重复,DPO 训练边际收益变负。
训练增益曲线:iTool 真的"打破了衰减"了吗?
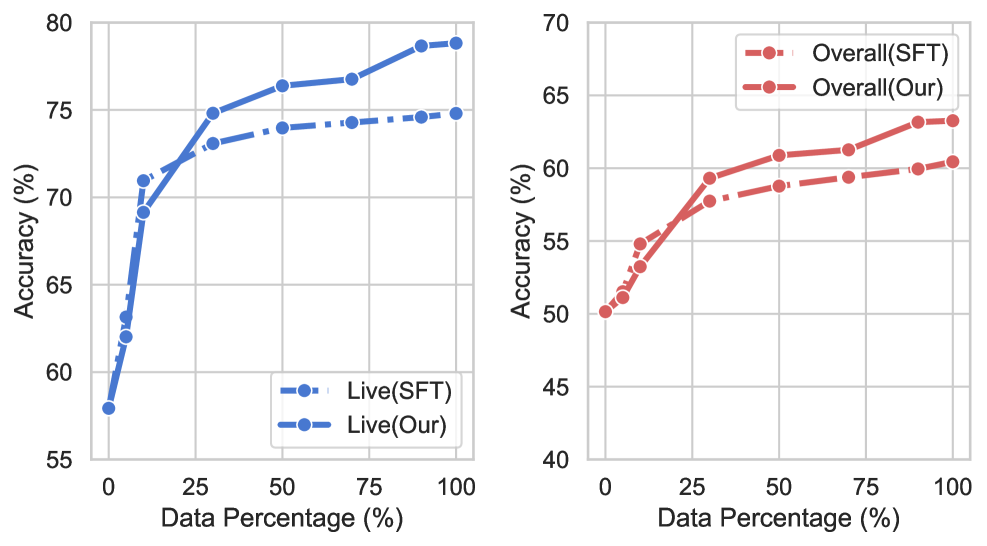
图8:左图是 Live 子集,右图是 Overall。蓝/红虚线是 SFT baseline,蓝/红实线是 iTool。SFT 在 30% 数据之后曲线趴窝,iTool 还能继续往上爬——这是论文最重要的支撑论据,证明 MCTS 偏好挖矿确实给"用更多合成数据"开了一条新路。
这张图我反复看了几遍。实线(iTool)和虚线(SFT)大概在 25-30% 数据附近交叉,过了之后两条线分开。iTool 的曲线斜率没有像 SFT 那样早早趴下,说明 MCTS 偏好挖矿确实从合成数据里挖出了"SFT 没用上的信息"——不是数据不够多,是 SFT 这个学习方式没把数据榨干。
但要保持冷静——右图 Overall 上两条线的差距其实不算大(最大差距 \lt3 个点)。真正拉开差距的是 Live 子集(左图)。所以 iTool 的"打破衰减"效应主要体现在复杂场景上,简单题已经 saturate 了。
跨数据集和跨基座的泛化
| 数据集 (类型) | LLaMA3.1-8B SFT | LLaMA3.1-8B iTool | Δ | LLaMA3.2-3B SFT | LLaMA3.2-3B iTool | Δ |
|---|---|---|---|---|---|---|
| ToolACE † | 46.18 | 51.06 | +4.88 | 40.36 | 46.85 | +6.49 |
| xLAM † | 42.74 | 48.47 | +5.73 | 37.72 | 42.14 | +4.42 |
| BFCL-half ‡ | 41.32 | 44.97 | +3.65 | 34.65 | 36.82 | +2.17 |
† 合成数据,‡ 非合成数据
合成数据上涨 4.42 ~ 6.49 个点,非合成数据上涨 2.17 ~ 3.65 个点。这个对比挺有意思——iTool 在合成数据上的增益明显更大,因为合成数据里的"参数错误模式"更密集,MCTS 能挖出的偏好对也更有价值。真实数据里参数错误本来就少,可挖空间小。
跨基座的另一组数据(表 4):在 Llama-3.2-3B 上 iTool 比 base 涨 18%,在 Qwen2.5-7B 上达到 63.93% overall。3B 基座 + iTool 干到 62.93% overall——比原版 GPT-3.5-Turbo 还高,挺夸张的。
我的判断:这篇论文值不值得细读?
先说让我觉得漂亮的地方。
第一,把"训练增益衰减"这个工程界都心照不宣的现象,用一组干净的实验拍实了。30% 数据是个明显的拐点这件事,之前我自己模糊地感觉到,但没见过这么清楚的曲线。光这张图就值得这篇论文存在。
第二,bad case 分类的洞察非常工程。77% 错误集中在参数名/参数值这件事,倒推出"应该用步级信号修补碎片"的方法论,整条逻辑闭环。不是先定方法再找问题,是先看到问题再去想方法——这种工作我个人很认。
第三,MCTS 用法的取舍合理。用 MCTS 当数据挖矿工具而不是推理工具,避开了 inference-time MCTS 那种推理成本爆炸的问题。Q 值代替 PRM 也是工程上的取巧——训一个真正的 PRM 要标注海量步级数据,代价远比跑 MCTS 高。论文用 LLM-as-Judge + outcome reward 凑了一个粗粒度的步级信号,算够用,但不算精。
再说几个我觉得有问题或者打折的地方。
第一,训练成本不便宜。28 小时 8×V100 一个迭代周期,3 轮 84 小时。比 SFT 多 2.8 倍,对中小团队来说不是个轻量方案。论文在 Limitation 里也承认了这一点。
第二,Multi-turn 绝对水平还是低。23.84% 听起来比 SFT 涨了 6 个点很厉害,但放在 GPT-4o-mini 的 27.50% 旁边就显得没那么强了——而且这是 BFCL Multi-turn 这种合成 benchmark 上的数,真实多轮场景的工具调用要远比 BFCL 复杂。
第三,对 BFCL v3 这个 benchmark 本身有依赖。所有的 ablation 几乎都围绕 BFCL,API-Bank 只在 main result 出现一次。如果 BFCL 的评估方式存在偏差(比如对参数错误特别敏感),iTool 的优势会被放大——而 iTool 恰恰就是针对参数错误设计的。有点"为评估指标量身定做"的味道,这块如果能加一个真实业务 trace 的评估会更有说服力。
第四,关于"打破衰减"的措辞要打个折扣。从图 8 看,iTool 也没把曲线变成线性,只是把拐点从 30% 推到了 50% 附近,过了 50% 增益依然在收窄。所以更准确的说法是"延缓衰减"而不是"打破衰减"。
和同期工作的位置比较。
工具调用这个领域今年同期还有几个值得关注的工作: - ToolACE(华为同组的前序工作):把数据合成做到极致,靠 self-evolution 把工具复杂度往上推 - xLAM 系列(Salesforce):把 MoE 工具调用模型规模化 - Hammer(字节):通过工具描述的语义增强减少幻觉
iTool 和这些工作不是同一条赛道——它解决的是"假设你已经有一堆合成数据,怎么把它榨干"。所以 iTool 大概率会成为这些数据合成工作的下游搭配——ToolACE 负责造数据,iTool 负责把数据训透。这个组合用法挺合理的。
工程启发:如果你也在搞工具调用 SFT
读完这篇论文,几条可以直接拿去试的工程启发:
-
先做 bad case 分类。不要先入为主地假设模型哪里弱。把错误样本按维度切开看,往往能发现"问题集中在某一小撮"——这跟 iTool 的洞察一脉相承。
-
Easy-to-Hard 课程式 SFT 几乎是免费午餐。三档分桶按 a/b/c 三个维度切就行,学习率分别衰减,实现成本低、效果稳。哪怕你不做后面的 RL,光这块也能拉一两个点。
-
如果合成数据已经堆到瓶颈,别再加数据,加偏好挖矿。你可以不上 MCTS 这么重的方案,先试简单的 self-sampling + outcome reward 构造偏好对——iTool 的 ablation(图 6)告诉你,这种弱版本也能涨 2-3 个点。MCTS 只是把上限拉得更高一点。
-
SimPO over DPO。论文附录的对比里 SimPO 在工具调用任务上略好,关键是省一份显存——4-bit QLoRA + SimPO 的组合在消费级 GPU 上也能跑动。
-
3 轮迭代是甜点。不要贪心。继续迭代是负收益。
最后说一句
iTool 这篇论文最值钱的地方,不是 MCTS 也不是 SimPO,而是"先把问题诊断清楚再开方"的方法论。先把训练衰减这个现象坐实,再把错误模式拆解到参数级别,最后才是步级偏好挖矿。一头一尾的工作做扎实了,中间用什么算法反而成了选择题。
如果 2025 年有人问我"工具调用 SFT 涨不动了怎么办",这篇论文是我会推给他先读的几篇之一。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我