让 Web Agent 自学不停滞——WebEvolver 用一个共演化世界模型撑起多步 Look-Ahead
做过 Agent 自我训练的人,多半都撞过一堵墙。
第一轮 self-improvement,效果看起来贼香——模型熟悉了 action 格式,能稳稳输出合法的 click/type,成功率能涨好几个点。第二轮,再喂一批新采样的成功 trajectories,曲线开始往上飘但幅度变小。等到第三轮,曲线基本就贴着天花板趴在那儿了,再喂数据反而有点过拟合。
这不是某一篇论文里的特例,是这条路线绕不开的现象。OpenWebVoyager、ReST+ReAct、BAGEL 一类方法都明确观察到 self-improving loop 会 plateau。原因其实直觉上能猜到——你让 agent 沿着自己当下的 policy 去探索,反复采样、反复 SFT,相当于把模型推到自己分布里最甜的那块,越走越窄。新的 state、新的 action 没机会被探索,pretrain 阶段沉淀下来的那些 web 知识也没被真正调动出来。
这篇 EMNLP 2025 主会论文 WebEvolver 给的方案挺漂亮:再训一个 LLM 当世界模型(World Model),让它跟 policy 一起共演化(co-evolve)。世界模型不只是个推理时的小帮手,更是个虚拟 web 服务器——你不用真去点 GitHub、搜 Coursera,让 world model 直接给你"幻觉"出下一个 accessibility tree,policy 就能在这个虚拟环境里继续生成 trajectory,喂回去做 SFT。同时这个 world model 在 inference 阶段还能做多步 look-ahead,给 policy 选最好的 action。
效果是 WebVoyager 上从 self-improve 第三轮的 38.65% 提到 WebEvolver 的 42.49%,再叠加 WMLA(World Model Look-Ahead, depth=2)能到 51.37%——比 GPT-4o 直接做 agent 都高出一截。重点是整个 loop 用的全是 Llama-3.3-70B,没用任何更强模型蒸馏。
论文信息
- 标题:WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model
- 作者:Tianqing Fang, Hongming Zhang, Zhisong Zhang, Kaixin Ma, Wenhao Yu, Haitao Mi, Dong Yu
- 机构:Tencent AI Lab
- arXiv:2504.21024(v1:2025/04/23,v2:2025/08/21)
- 会议:EMNLP 2025 Main Conference
- 代码:github.com/Tencent/SelfEvolvingAgent
一、为什么 Web Agent self-improvement 会停下来
先把事情说清楚,避免有人没接触过这条线。
Web agent 的 self-improvement 是什么意思? 拿 OpenWebVoyager 那条路线举例:你有一个 backbone LLM(比如 Llama-3.3-70B),让它当 policy,配一套 web agent 框架(Cognitive Kernel、ReAct 那些),扔给它一批 query(比如"在 Coursera 上找一门 3D 打印课"),让它在 Playwright 控制的真实浏览器里点点点。每一步 agent 会读 accessibility tree(visible 的 DOM 元素结构),输出 thought + action(click [k] / type [k] xxx / scroll / goback / stop)。一条 query 跑完拿到一条完整 trajectory,再用一个评估函数(论文里用 Llama-3.3-70B 自己当 judge)判这条轨迹算不算成功,把成功的那批做 rejection sampling,留下来当 SFT 数据,回灌训 backbone。
听起来很美——不用人工标注,模型自己滚雪球。但实际跑起来很快就停。论文给的解释,我觉得挺到位的:
第一,探索多样性下降——模型 overfit 到自己熟悉的那些 trajectory pattern,新的 state 和 action 越来越少被采样到。
第二,inference-time 探索(比如 tree search、MCTS)虽然能多样化,但每个 rollout 都要真去访问网站,开销巨大、收益边际递减。
第三,已有的 simulation/imagination 方法(WebDreamer、WMA)大多只支持 1-2 步 look-ahead,做不到长链条的 multi-step rollout,也就给不出连贯的"想象轨迹"。
我自己在做类似的项目时,第三点感受最深。WebDreamer 那种用 GPT-4o zero-shot 当 world model 的玩法,单步预测一个文字描述还行,要它连续生成 7 步 accessibility tree、每一步都结构化合法、还要前后逻辑自洽——基本是别想了。
WebEvolver 的反应是:那就别用 off-the-shelf 模型,专门 fine-tune 一个 world model,并且让它跟 policy 同步迭代。
二、方法核心:World Model 的双重人格
这张图是整个 paper 最值钱的地方,把整个 framework 摊得清清楚楚:
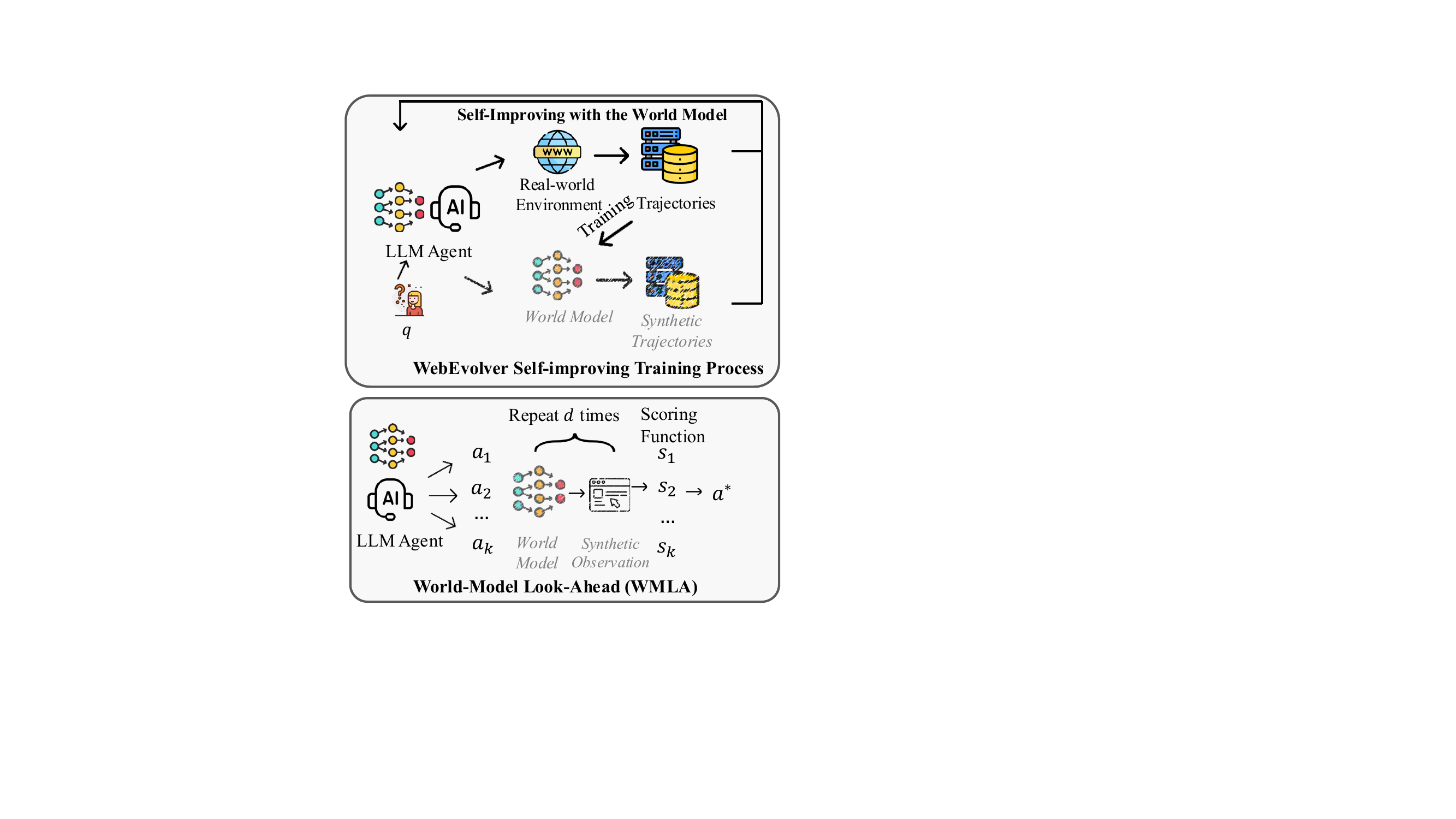
图 1:上半部分是 WebEvolver 训练流程——LLM agent 在真实 web 环境里跑,产出真实 trajectories;同时 world model 用这些 trajectories 训练,再反过来生成 synthetic trajectories 喂回训练数据。下半部分是 World-Model Look-Ahead——agent 同时采 k 个候选 action,每个都让 world model 想象 d 步未来,再用 scoring function 选最好的那条。
2.1 World Model 是怎么定义的
正式地讲,把 web agent 看成一个 POMDP \((\mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T}, \mathcal{R})\),state 是整个 web 后台,observation \(o_t\) 是 visible 的 accessibility tree,action \(a_t\) 是 click/type/scroll/goback/stop/restart 这几个原子操作,transition \(\mathcal{T}\) 就是浏览器实际执行那个 action 后跳到的下一个页面。
世界模型 \(\mathcal{M}_w\) 干的事很直白——用一个 LLM 把 transition 函数 \(\mathcal{T}\) 替换掉。给定当前 accessibility tree \(o_t\) 和动作 \(a_t\),让 LLM 直接生成下一个 accessibility tree \(\hat{o}_{t+1}\)。形式化地:
这里 \(c^w_t\) 是截断后的历史上下文(只留最新一步 observation 和过去几步的 action + 推理)。训练数据从哪来?从 self-improvement 收集的那批真实 trajectories 里直接转换——把 \(\tau = \{(o_0,a_0),\ldots,(o_t,a_t)\}\) 转成 world modeling 的形式 \(\tau_w = \{o_0, (a_0, o_1),\ldots,(a_{t-1},o_t)\}\),目标变成"基于动作和历史预测下一个 observation"。
为什么这事儿可行?作者的核心 insight 是:Llama-3.3-70B 这种模型在 pretrain 阶段吃了海量 web 内容,它本来就隐含地知道 GitHub 的 sort by 菜单长啥样、Coursera 的搜索框点了之后会跳哪儿。fine-tuning 只是把这部分知识从"被动记忆"变成"主动按 accessibility tree 格式输出"。
这个角度其实挺关键的。它解释了为啥 world model 能涌现——不是从零学环境动力学,而是把模型本来就有的 web 常识激活出来。
2.2 World Model 的两个用途
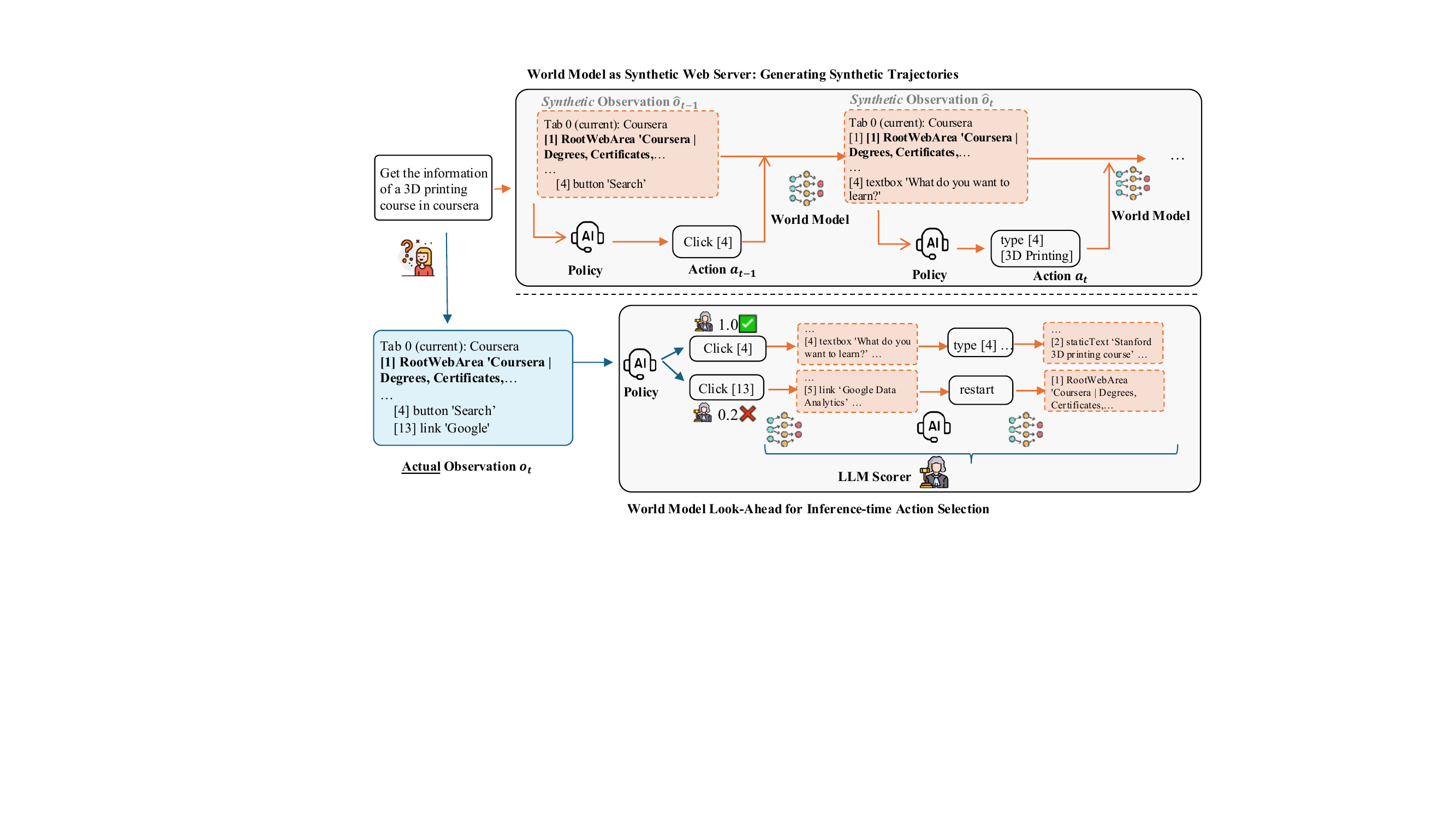
图 2:上半图,world model 当 synthetic web server——agent 给个 query "在 coursera 上查 3D printing 课程",从初始 observation \(o_t\) 开始,policy 给 action(Click [4] 搜索框),world model 想象出下一个 observation \(\hat{o}_{t-1}\),policy 接着输出 type [4] "3D Printing",world model 再生成 \(\hat{o}_t\),循环最多 7 步。下半图,inference 时 policy 同时采 \(k\) 个候选 action(Click[4]、Click[13]…),每个都让 world model 模拟接下来 \(d\) 步,最后用 LLM scorer 给每条想象轨迹打分(1.0 / 0.5 / 0.2),选分最高那个 action 真去执行。
用途一:Synthetic Web Server,给训练造数据。
只用真实 trajectory 训 self-improve,模型很快就跑到自己 policy 的舒适区里。这时候让 world model 顶替真实浏览器,policy 在虚拟环境里继续探索:每一步 policy 输出 action,world model 想象出下一个 accessibility tree,再输入给 policy,循环 7 步。生成的 trajectory \(\hat{\tau}\) 经过 rejection sampling(用 Llama-3.3-70B 当 judge)后并入训练集 \(D_w\)。
这里有个细节蛮聪明的:只用 self-improve 没成功的 query 来生成合成轨迹。已经能做对的 query 没必要再造数据,专攻啃不下来的硬骨头能更快补全 policy 的弱点。
有人会问,world model 自己会幻觉吧?生成的页面都不真实,训出来的 policy 不就废了?作者的解释是:
agent 学的是"如何根据当前 observation 输出合理 action",不是"完美预测下一个 state"。所以即便 world model 幻觉出一些不真实的网页结构,只要 trajectory 整体逻辑自洽(搜索框、按钮、点击、跳转的流程合理),policy 学到的 action distribution 反而会因为见过更多样的网页而更鲁棒。
我对这套说辞信一半。"多样性带来鲁棒性"在小规模下确实能成立,但当幻觉率高到一定程度,policy 学到的就是一些只在幻觉里成立的 action pattern,到真实网页上反而 transfer 不过去。论文后面 Table 2 显示 world model 在 depth>2 之后 STR/Sim/O/A 全线掉到 50% 以下,这其实是个挺强的警告——这也是为什么 inference-time look-ahead 把 depth 限在 2。
用途二:Inference-Time Look-Ahead(WMLA)。
这是论文起的名字 World Model Look-Ahead。流程:
- 当前观察是 \(o_t\),policy 采样 \(k\) 个候选 action \(a_t^{(1)}, \dots, a_t^{(k)}\)
- 每个候选 action 都让 world model 模拟接下来 \(d\) 步,得到 \(d\) 步的想象轨迹 \(\hat{\tau}_w\)
- 用一个 LLM scorer(这里用 GPT-4o)给每条轨迹打分 \(\{0, 0.5, 1.0\}\)(错 / 在轨道上 / 完成)
- 选分最高的那个 \(a_t^*\) 去真实环境执行
公式形式:
实操上有个小坑——SFT 后的 policy 输出分布会很尖,温度调到 0.7 也很难采到不同的 action。作者加了一句 prompt"请生成不同于 \(\{a_t^{(1)}, \dots, a_t^{(k-1)}\}\) 的 action"来强迫多样性。这种工程小细节其实挺值得借鉴的,很多人 SFT 完不知道怎么 sample diverse output,硬调 temperature 调不出来。
整个 WebEvolver 的训练流水线大致是这样:
iter 0: Llama-3.3-70B 直接当 policy,采样 trajectory,rejection sample → D_0
↓ SFT
iter 1: 得到 self-improve(1),再采样 → D_1; 同时把 trajectories 转成 world model 训练数据 → 训出 world model(1)
↓ SFT
iter 2: self-improve(2) + world model(2)
↓
合成阶段: 用 world model(2) + self-improve(1)(这俩组合最稳), 对失败的 query 跑 7 步合成 → 经 rejection sampling 得到 D_w
↓
最终: D_1 ∪ D_w 一起 SFT Llama-3.3-70B → WebEvolver
三、实验结果:哪些数字让我皱眉,哪些让我服气
3.1 主实验
WebVoyager 473 个 query 一共 11 个网站,Mind2Web-Live 53 个 query。论文给了挺细的 per-website 拆分,但我们直接看汇总(WV All 和 M2W Live):
| 方法 | WebVoyager (%) | Mind2Web-Live (%) |
|---|---|---|
| GPT-4o-mini | 32.55 | 16.98 |
| GPT-4o | 38.83 | 20.75 |
| Llama-3.3-70B (zero-shot) | 32.98 | 18.86 |
| self-improve (iter 1) | 38.68 | 15.09 |
| self-improve (iter 2) | 38.23 | 16.98 |
| self-improve (iter 3) | 38.65 | 16.98 |
| Synthetic Traj. (无 world model) | 38.98 | 18.86 |
| WebEvolver | 42.49 | 22.64 |
| + WebDreamer | 44.61 | 22.64 |
| + WMLA (\(d=1\)) | 46.24 | 28.30 |
| + WMLA (\(d=2\)) | 51.37 | 24.53 |
几个观察。
self-improve 确实从 iter 2 开始 plateau。WebVoyager 上 38.68 → 38.23 → 38.65,三轮基本横盘,符合作者论证的痛点。
纯加合成数据的 baseline 基本没用。Synthetic Traj. 那行(参考 LLM Agents Can Self-Improve)是不带 world model、用其它方式生成合成轨迹,WebVoyager 上才 38.98,跟 self-improve(3) 几乎一样。这说明 world model 不是简单的"再造点数据",关键在于这些数据带着真实 web 结构的语义先验。
WebEvolver 比 self-improve 第三轮涨了 3.84 个点(WebVoyager),5.66 个点(Mind2Web-Live)。算下来确实接近 abstract 里说的 "10% 提升"——不过严格讲 abstract 里的 10% 是相对值(42.49/38.65 - 1 ≈ 10%),不是绝对的 10 个点。这种话术稍微有点讨巧,但数字本身没问题。
WMLA 的额外提升非常猛。 depth=2 时 WebVoyager 51.37%——比 GPT-4o 直接当 agent 都高 12.54 个点。如果这个数能 reproduce,那对 70B 模型 + Llama 系列做 web agent 来说,等于打开了一条"用世界模型替代真实浏览器试错"的路。
和 WebDreamer 比赢了。 WebDreamer 是用 GPT-4o 当 world model + scorer,WebEvolver 用自己训的 world model + GPT-4o scorer,整体涨了 4.76 个点。这条对比非常关键——它直接说明了 fine-tune 一个领域内 world model 比直接用 GPT-4o zero-shot 想象要靠谱。
3.2 自演化曲线
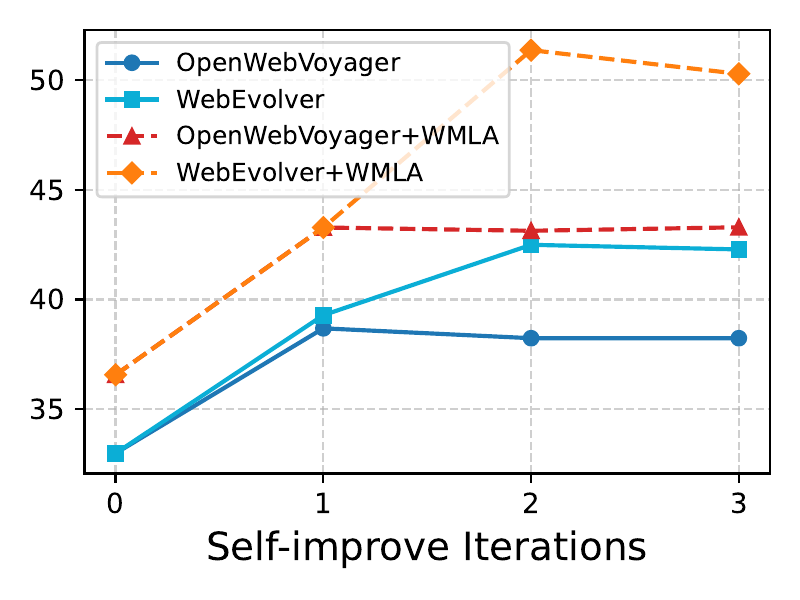
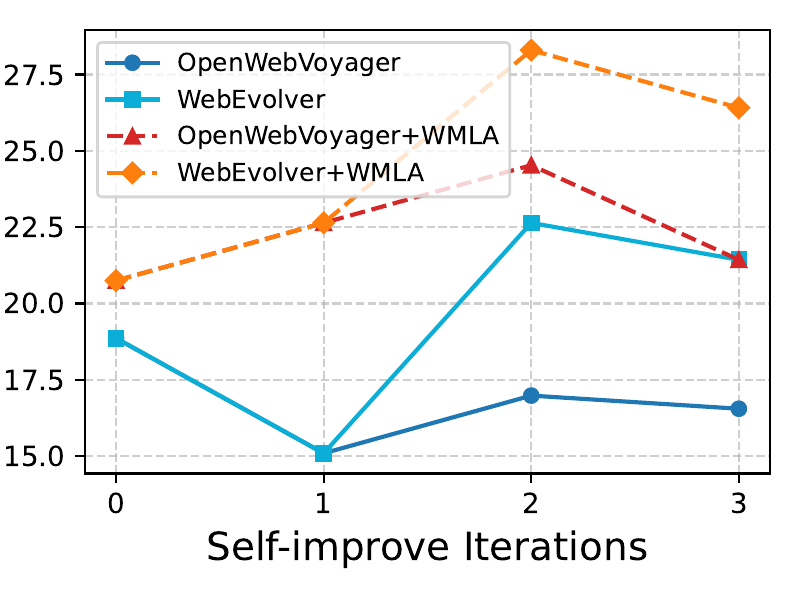
图 3:左图 WebVoyager、右图 Mind2Web-Live。蓝色实线是 OpenWebVoyager(纯 self-improve),蓝色方块是 WebEvolver(自演化训练,无推理时 look-ahead),红色虚线是 OpenWebVoyager+WMLA,黄色虚线是 WebEvolver+WMLA。
这两张图最有意思的地方是 Mind2Web-Live 那张——OpenWebVoyager 的纯 self-improve 第一轮反而掉了(18.86 → 15.09),到第三轮才勉强爬回 16.55,根本没收敛到 zero-shot 之上。WebEvolver 在第二轮直接拉到 22.64。
我看到这个图的第一反应是有点怀疑:会不会是 Mind2Web-Live 只有 53 个 query 太少,方差太大?但作者在论文里也提到 "我们在大致相同的时间窗口内做了两次实验取平均",至少做了点稳定性处理。
另一个观察是 WMLA 的红线(叠在原 OpenWebVoyager 上)和黄线(叠在 WebEvolver 上)差距挺大——这说明 WMLA 不只是简单的"采几个 action 选最好的",它和 policy 的质量乘起来才有效。policy 弱的时候,再 look-ahead 也救不回来。
3.3 World Model 的内在评估
| Model | All (STR / Sim / O/A) | Depth=1 | Depth=2 | Depth=3 | Depth\(\geq\)4 |
|---|---|---|---|---|---|
| GPT-4o | 40.62 / 33.26 / 37.85 | 41.24 / 35.73 / 40.21 | 38.20 / 32.58 / 36.70 | 36.99 / 31.96 / 37.44 | 42.41 / 32.91 / 37.45 |
| Llama-3.3-70B | 39.04 / 32.25 / 38.77 | 43.64 / 39.51 / 34.83 | 39.33 / 34.83 / 41.95 | 39.73 / 33.33 / 41.55 | 36.85 / 27.99 / 35.16 |
| world model (iter-1) | 49.23 / 37.83 / 43.15 | 55.44 / 44.91 / 50.52 | 53.03 / 39.77 / 46.59 | 53.70 / 40.28 / 46.30 | 43.76 / 33.33 / 37.73 |
| world model iter-2 | 56.79 / 44.77 / 51.82 | 75.96 / 63.56 / 72.86 | 57.80 / 45.14 / 52.32 | 51.24 / 35.82 / 45.27 | 50.54 / 39.94 / 45.31 |
STR 是 accessibility tree 结构合不合法(XML 解析能不能过),Sim 是和真实网页内容的相似度,O/A 是整体功能和语义连贯性,都是用 GPT-4o 自动打分归一到 0-100。
Depth=1 上 iter-2 拿到 75.96 / 63.56 / 72.86,碾压 GPT-4o zero-shot。这是这套方法的命门——你要让世界模型在多步 imagination 里有意义,至少单步预测得靠谱。
但 depth>2 就开始崩盘。iter-2 在 depth=3 的 STR 已经掉到 51.24,Sim 到 35.82。这跟主表里 WMLA 在 d=3 收益消失完全一致。说到底,这个 world model 的"想象寿命"大概就是 2-3 步,再长就是噪声了。
合成轨迹却用了 7 步——这看起来矛盾。我理解的原因是:rejection sampling 在兜底。生成的 7 步轨迹要先过 reward 评估(Llama-3.3-70B 判断有没有完成 query),不合理的轨迹直接被砍掉,留下来的就算前面有点幻觉但整体逻辑还说得过去。你想想看, rejection sampling 把 long-horizon hallucination 的代价从训练阶段转移到了"合成数据数量减少"上。这是个挺工程化但有效的妥协。
3.4 跨域泛化
| 模型 | GAIA Level 1 | GAIA Level 2 | SimpleQA |
|---|---|---|---|
| Llama 3.3-70B | 19.2 | 10.9 | 36 |
| iter 1 | 26.9 | 15.6 | 44 |
| iter 2 | 26.9 | 12.5 | 45 |
| WebEvolver | 30.7 | 17.2 | 48 |
| + WMLA | 34.6 | 17.2 | 58 |
GAIA-web 是从 GAIA 里抽出来的需要多步 web 导航才能解的子集,SimpleQA 这里是把它改造成 web 搜索任务。注意这里 train data 里完全没有 bing.com 的 trajectory(用 Bing 替代 Google 是因为 CAPTCHA),所以这是真正的 out-of-domain 评估。
SimpleQA 从 36 涨到 58(+22 个点),跨域增益挺夸张的。Level 2 题(需要更深推理 + 更多步交互)增益就有限,这跟 paper 也明确承认的"我们的 backbone 主要学 action generation,复杂 reasoning 还得靠外部 LLM 拆任务"对得上——Level 2 任务里他们用 GPT-4o 拆子任务、做计算,WebEvolver 只负责导航执行那段。
3.5 一个具体例子
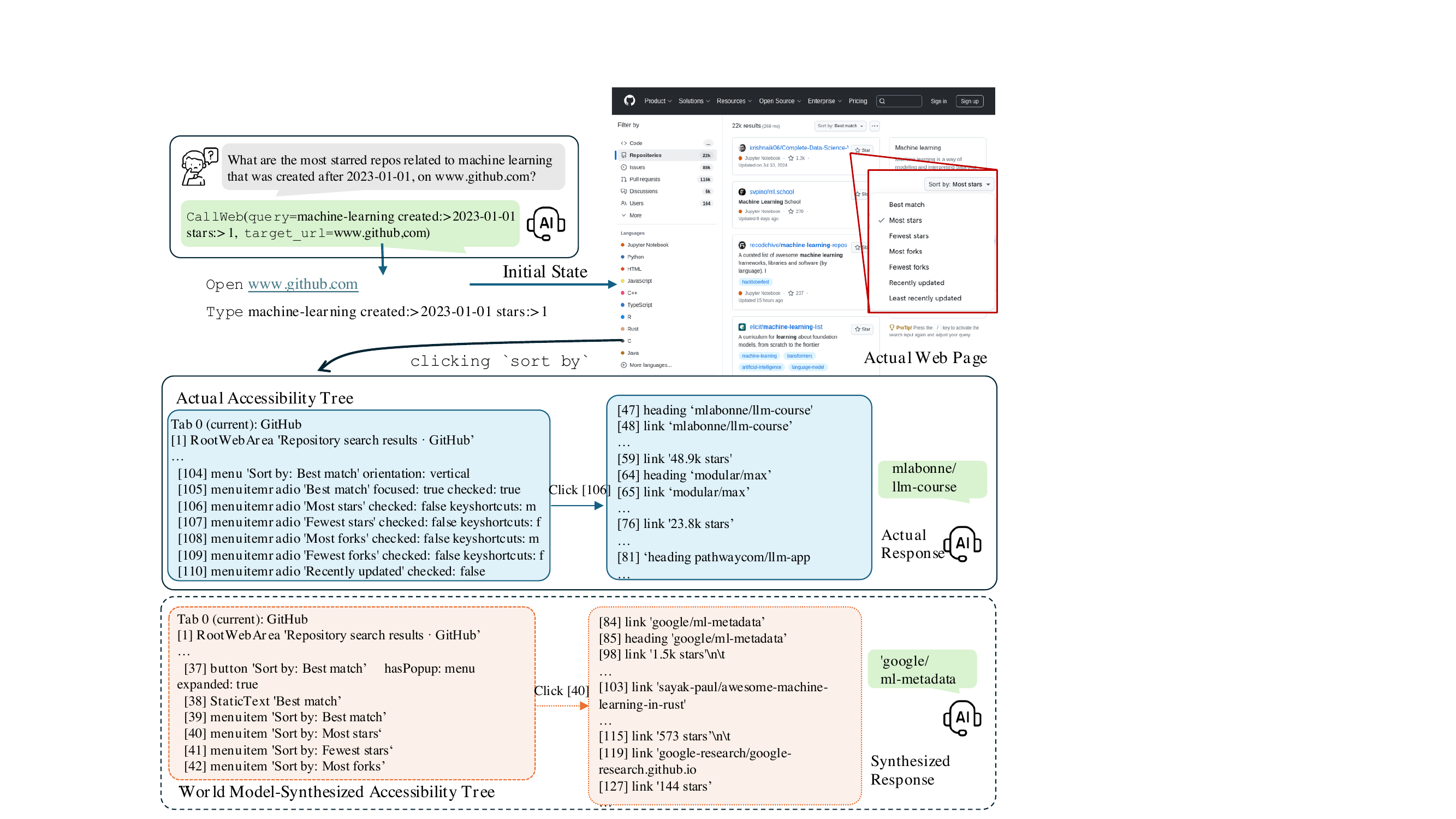
图 4:query 是"在 github.com 上找 2023-01-01 之后创建的、最多 star 的机器学习仓库"。左上是 agent 起步的实际 accessibility tree(含 sort by 下拉菜单展开后的 menuitemradio 列表:"Best match"、"Most stars"、"Fewest stars"…)。右下是 world model 在没见过该具体页面的情况下,自己生成的 accessibility tree——它准确预测出了 GitHub 搜索结果的结构,包括 sort by 菜单的内容、各个 repo 的 star 数链接。
这例子是论文里我最喜欢的一段。因为它直接证明了"LLM 在 pretrain 阶段确实记下了 GitHub 这种主流网站的结构知识"——world model 没专门见过点 sort by 后会展开什么菜单,但生成的 menuitemradio 列表(Best match、Most stars、Fewest stars、Most forks…)跟真实 GitHub UI 几乎一模一样。
这才是这套方法能 work 的根本——不是从零学环境,是把 LLM 已有的 web 常识激活成可生成的格式。
3.6 分支因子消融
| \(k\)(采样多少候选 action) | WebVoyager (%) |
|---|---|
| 2 | 48.62 |
| 3 | 51.37 |
| 5 | 50.73 |
\(k=3\) 是甜点,\(k=5\) 反而略降。作者的解释是大多数 state 下其实"实质性不同"的 action 选项就那么几个,多采反而采到些近重复的,被 scorer 拍到差不多分,浪费推理算力。这个判断我认同——web agent 不像围棋,每个 state 下合理 action 通常 2-5 个就到顶了。
四、我的判断:亮点、警告、和它该怎么往下走
4.1 真正打动我的地方
第一,"co-evolving"这个设定切中了 self-improvement 停滞的根因。前面说过 plateau 的本质是探索受限,单纯加更多真实 trajectory 的成本爆炸。WebEvolver 用一个能持续进化的 world model 把"虚拟探索"成本压到了几乎只有 LLM 推理开销,这是真正的 leverage。
第二,Llama-3.3-70B 全栈,不依赖 GPT-4o 蒸馏。这点对工业落地很重要——很多 self-improve 工作偷偷在 reward judge 那一环用 GPT-4o,相当于 free distillation。这篇 paper 严格在 self-improve loop 内只用 Llama-3.3-70B 当 judge,干净。inference 阶段的 WMLA scorer 才用 GPT-4o,那是另一层逻辑。
第三,把 WebDreamer 和 WMA 这条"用 LLM 做 world model"的线推到了"co-train"的高度。前两者都是把 world model 当成推理时插件,WebEvolver 把它放到训练 loop 里当数据生产者,这是定性的差别。
4.2 让我警觉的地方
第一,rejection sampling 在兜底,方法的实际复杂度被掩盖了。 7 步合成轨迹里多少被 reject 掉论文没给完整数字。如果接受率只有 10-20%,那 world model 的 "depth>2 就 degrade" 其实是个挺严重的瓶颈,方法的样本效率被 reject rate 严重稀释。
第二,文本 accessibility tree 的设定回避了视觉。 真实 web agent 越来越往 multimodal 方向走(claude computer use、GPT-4o vision),accessibility tree 在很多动态页面、shadow DOM、canvas-based UI 上是缺失或残缺的。这套方案能不能迁到截图模态?world model 要生成下一帧截图,难度不在一个量级。
第三,对 hallucination 的辩护偏弱。 "幻觉提升多样性"听起来漂亮,但缺乏定量分析——比如对比"完全真实数据训练" vs "纯合成数据训练" vs "混合训练"在 OOD 网站上的失败模式分布。现在只能从最终精度涨了来反推幻觉是 net positive,但这是个 confounded 的结论,因为合成数据本身的覆盖范围更广。
第四,self-improve 评估用的 judge 是 Llama-3.3-70B 自己。 这相当于模型可能学会"按 Llama 的 judge 偏好作答"而不是"按真实任务完成度作答"。这个问题在 RLHF 里被广泛讨论过——self-judge 容易导致 mode collapse 到 judge 的偏好上。论文没在这一点上做深入分析,是个小遗憾。
4.3 跟同期工作对比,处于什么位置
| 维度 | WebDreamer | WMA | WebEvolver |
|---|---|---|---|
| World Model 来源 | GPT-4o zero-shot | fine-tune 一个 WM | fine-tune + 与 policy co-evolve |
| 用途 | inference 时 1-step look-ahead | inference 时多步(最多 d=3) | 训练 + inference 双用 |
| 是否改进 policy 模型本体 | ❌ | ❌ | ✅(生成 trajectory 回灌训练) |
| Multi-step rollout 长度 | 1-2 | \(\leq 3\) | 训练时 7(rejection 兜底),推理 2 |
| 依赖闭源模型 | 是(GPT-4o) | 部分 | 仅 inference scorer 用 GPT-4o |
把这张表放出来后能看清楚 WebEvolver 的真正贡献:不是发明 world model 这个概念(WebDreamer / WMA / WKM 早就探索了),而是把 world model 从一次性的 inference plugin 升级成训练 loop 里的协同演化模块。这是个工程上很顺、idea 上有递进的工作。
五、几个工程层面的启示
如果你也在做 agent self-improvement,这篇 paper 至少给了三个直接可借鉴的点:
一、self-improvement 停滞了,不要无脑加数据,先看探索是不是收窄了。 如果 reward judge 给的合格率第二轮开始下降、新增的 trajectory 跟旧的越来越像,说明 policy 缩进自己的舒适区。这时候加一个能"造分布外样本"的机制(world model 是一种,温度增大 + 行动重采样也是一种)比单纯加 query 更有效。
二、用领域内训练的 LLM 当 world model 比 zero-shot 大模型靠谱,但要忍受短链条。 65% 左右的 1-step 预测准确率(WebEvolver iter-2 在 Sim 上拿到 63.56),看起来不算高,但对于"生成够用的多样化训练数据"已经够了。不要追求 long-horizon imagination 完美,那是个更难的问题。
三、SFT 后 policy 输出过于 sharp,温度采样不够多样,可以用 prompt 强制差异化。 "请生成不同于 \(\{a^{(1)}, \dots, a^{(k-1)}\}\) 的 action"这种简单技巧,比改 inference 框架要轻量很多。
六、收尾
我对 WebEvolver 整体评价是:扎实、思路自然、效果可验证,是 EMNLP 2025 主会里那种"读完不会拍案叫绝、但你会忍不住想抄"的工作。
它没有发明新的范式,是把"world model + agent"这条 RL 老路在 LLM Web agent 场景下做完了一次完整的工程化整合——training loop、inference look-ahead、合成数据、内在评估、跨域泛化都给齐了。这种"systems paper"在大厂研究院做出来正常,在学术界做出来反而更稀缺,因为需要稳定的 web infra 和大模型训练 budget。
往下看的话,几个方向都很值得继续做:
- Multimodal world model:把 accessibility tree 换成 screenshot + DOM 的混合表示,挑战 vision-language world model
- Long-horizon coherence:现在 depth>2 就崩,能不能引入显式的页面状态记忆(类似 memory-augmented LM)让 world model 在 5+ 步还合理
- 替代 SFT 的 RL 训练:现在是 SFT + rejection sampling,本质还是 imitation。如果改成 GRPO/PPO 这种直接优化 reward,再叠加 world model 当 critic,可能能再上一个台阶
- 更严谨的 hallucination 分析:定量评估 "幻觉合成数据带来的多样性增益" vs "合成数据上的 spurious pattern",这是当前实验最薄的地方
如果你也在做 web agent 或者更广的 agent self-improvement,这篇值得抽时间精读一下。代码已经开源在 github.com/Tencent/SelfEvolvingAgent,可以直接拿 Cognitive Kernel + Llama-3.3-70B 复现。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我