WebAgent-R1:8B小模型在网页操作上把o3拉下马,多轮RL把分从8.5%硬拉到44.8%
最近Web Agent这块挺热闹。Anthropic的Computer Use、OpenAI的Operator、各家开源的Browser-Use——表面上都在往同一个方向走:让模型直接操作浏览器,点按钮、填表单、读DOM。但你只要真上手做过就知道,这个方向最难的不是"能不能做出来",而是"怎么把模型在这些任务上训练到真的好用"。
更具体一点:单轮的数学题、写代码,DeepSeek-R1那套RL方案早就跑通了。可一到多轮的、能改变环境状态的网页操作,绝大多数玩家就开始卡。要么训不动,要么动了不收敛,要么收敛了但泛化崩。
Amazon和UVA这篇 WebAgent-R1 就是冲着这个空白来的。它给我最大的冲击不是名字里那个"R1",是结果——一个 8B 的 Llama-3.1,从 8.5% 的成功率被一路推到 44.8%,反手把 OpenAI o3(39.4%) 这种顶配闭源模型按在地上摩擦。3B 的 Qwen 也从 6.1% 干到 33.9%。这种幅度的提升,在 WebArena-Lite 上是真的少见。
读完之后我的第一反应是:这篇论文方法上不算多惊艳,但它把"端到端多轮 on-policy RL"这件事真的做work了,而且做得很干净。这才是工业落地最缺的。
核心摘要
WebAgent-R1 解决的是 Web Agent 的一个老大难:现有的 RL 训练方案要么走 SFT/Behavior Cloning 上限太低,要么走 off-policy(DigiRL、WebRL)需要 replay buffer、轨迹过滤、外挂 reward model 一堆杂活,破坏了智能体和环境的端到端交互。
作者的方案极其 minimalist:直接把 GRPO 扩展到多轮场景叫 M-GRPO,配两个工程 trick——动态上下文压缩(解决多轮 HTML 累积爆显存)和并行轨迹采样(一个 task 同时跑多条轨迹)——只用二元的任务成功/失败信号当 reward,再加一段 BC 当 warm-up。就这一套。
结果:Qwen-2.5-3B 6.1% → 33.9%,Llama-3.1-8B 8.5% → 44.8%,在 WebArena-Lite 上把 WebRL(42.4%)、o3(39.4%)、o4-mini(36.9%)全部超过;OOD 评测在 WebVoyager 五个新域名上从 prompting baseline 的 8.8% 拉到 32%。
我对这篇论文的真实定位:不是底层算法突破,是把 GRPO 多轮化的工程整合做到了一个可复现、可拓展的 baseline。但凡你在做 Web Agent / 浏览器智能体的训练,这套配方值得直接抄。它真正打动我的是,那些教科书上轻描淡写的细节——上下文怎么压、loss mask 怎么对齐、warm-up 要不要——它一个个解释清楚了,并且用消融把每一步的必要性都打透了。
论文信息
- 标题:WebAgent-R1: Training Web Agents via End-to-End Multi-Turn Reinforcement Learning
- 作者:Zhepei Wei (UVA, Amazon实习), Wenlin Yao, Yao Liu, Weizhi Zhang, Qin Lu, Liang Qiu, Changlong Yu, Puyang Xu, Chao Zhang (Georgia Tech), Bing Yin, Hyokun Yun, Lihong Li
- 机构:University of Virginia / Amazon / Georgia Institute of Technology
- arXiv:2505.16421v2
- 代码:github.com/weizhepei/WebAgent-R1
为什么 Web Agent 训练这么费劲
先把问题讲清楚。
数学题、代码题这类单轮任务上,RL 训练范式已经被 DeepSeek-R1、Kimi-K1.5、Qwen-Math 这批工作打磨得很成熟了:sample 几条 trajectory,用 verifier 判对错,拿 binary reward 算 GRPO loss,干。
但是网页操作完全是另一回事。
第一个麻烦是观测特别长。一次浏览器返回的 simplified HTML 动辄几千 token,你跑 10 轮交互,上下文直接到 3-5 万 token 这个量级。在 8 张 A100-80G 上,batch size 还想保持能打的水平,光这一项就能给你训崩。
第二个麻烦是任务有时间相关性。论文里举了个特别精准的例子:先让 Agent 退出账户,再让 Agent 编辑用户资料。这俩动作有强依赖——退出登录后再访问 profile 页就是 404。如果你用 off-policy RL,训练数据来自一个"老版本"的 Agent(那个版本根本不会主动退出),新策略就没机会学会"退出后要重新登录"这个行为。这个例子读到的时候我愣了一下,因为这是真正会在生产环境出现的 bug,不是教科书举的玩具例子。
第三个麻烦是现有 RL 方案都太重。我之前调过 DigiRL 的 codebase,AWR 也跑过,包括去年 Tsinghua 的 WebRL:
- AWR (Peng et al. 2019):经典 advantage-weighted regression,off-policy
- DigiRL (Bai et al. 2024):双层 RL + 轨迹过滤
- WebRL (Qi et al. 2025):自我迭代课程学习 + 训练一个外挂的 ORM 来给 GPT-4 生成的新数据打分
它们都能 work,但都要外挂一堆东西——replay buffer、轨迹过滤器、外部 reward model、迭代式课程更新。每一项都是工程债。最让人皱眉的是 WebRL 居然要专门训一个 outcome reward model,相当于给原本就难训的 RL 又加了一层。
WebAgent-R1 的目标很纯粹:能不能像训单轮 R1 那样,直接用规则验证器给二元信号,端到端 on-policy,不需要任何额外组件?
方法核心:把 GRPO 搬到多轮
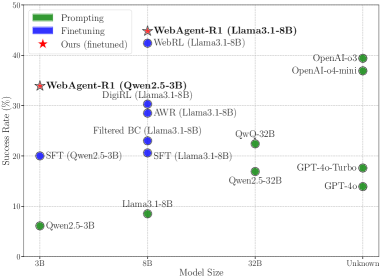
图 1:横轴是模型规模,纵轴是 WebArena-Lite 任务成功率。绿色是 prompting 基线,蓝色是 SFT/RL 微调方法,红色五角星是 WebAgent-R1。Qwen2.5-3B 从 5.3 一路飞到 33.9,已经超过 32B 的 QwQ;Llama-3.1-8B 拍到 44.8,把 o3 和 o4-mini 都甩在后面。这个图就是论文一切叙事的起点。
整个 WebAgent-R1 的训练流程可以分成两段:先 BC 做 warm-up,再上 M-GRPO 做端到端 RL。这个两段式没什么新意,关键是后半段怎么做的。
整体架构
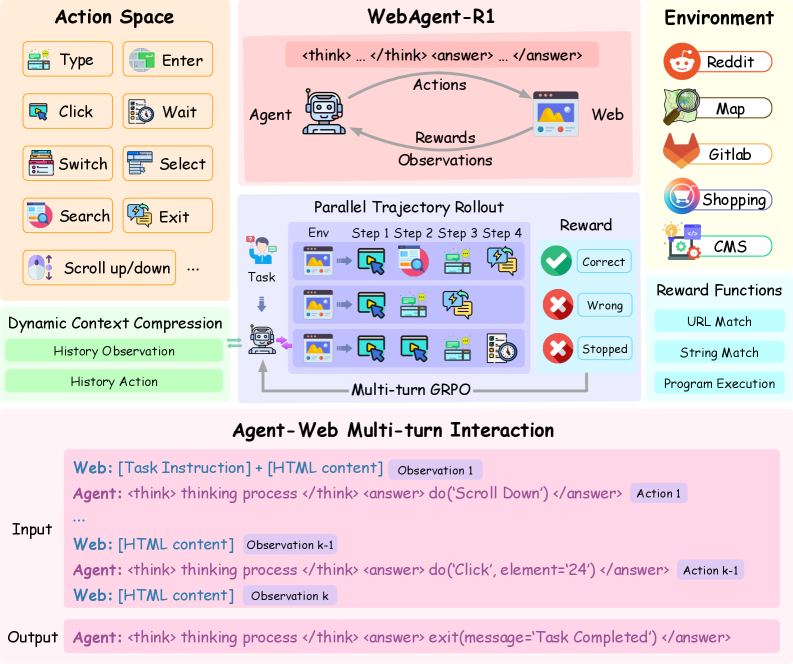
图 2 上半部分:动作空间是 Click / Type / Search / Hover / Scroll / Switch / Select / Wait / Exit 等 11 个原语,环境是 WebArena 提供的五个 self-host 网站(Reddit、GitLab、CMS、Map、Shopping)。中间最关键的两个机制:动态上下文压缩(左下绿色块,把老观测换成占位符)+ 并行轨迹采样(中间紫色块,一个任务并行跑 G 条轨迹)。下半部分给的是真实输入输出格式:Agent 用 \<think>...\</think>\<answer>do(...)\</answer> 的双段式回复,跟 R1 一脉相承。
Trick 一:动态上下文压缩
这是工程上最实用的一笔。
直觉很简单:在第 \(t\) 步,Agent 真正需要详细看的只是当前观测 \(s_t\),之前的 \(s_1, s_2, ..., s_{t-1}\) 已经过去了,留下来只是为了给当前决策提供"我做过什么"的上下文。所以作者把历史 observation 全部替换成一个占位符 token——就一行 ** Simplified html **——但完整保留所有历史 action。
形式化一下:原始历史是 \(h_t = (s_1, a_1, s_2, a_2, ..., s_t)\),压缩后变成 \(h_t = (s'_1, a_1, s'_2, a_2, ..., s_t)\),其中 \(s'_i\) 就是几个 token 的占位符。
这个 trick 的好处是上下文长度从 \(O(t \cdot |s|)\) 直接掉到 \(O(|s| + t \cdot |a|)\)。在 WebArena 上 \(|s|\) 是几千 token、\(|a|\) 才几十 token,压缩比能到十倍以上。
但有个坑:上下文动态变化了,loss mask 必须跟着同步更新——只在当前 action token 上算 loss,不能误把占位符或者历史 action 也算进去。这步处理不好就训崩。论文里这个细节交代得不算很详细,估计实际复现要踩一次。
Trick 二:并行轨迹采样
GRPO 本身就需要 group 内多条轨迹算相对优势,但单轮场景下是"一个 prompt 多个 response"——只跑一次 forward。多轮场景下,同一个 task 你要采 \(G\) 条独立轨迹,每条轨迹要跟环境真的交互 \(T\) 步。如果串行跑,G=8、T=10 的话就是 80 次 LLM forward + 80 次环境 step,慢得令人发指。
作者的做法是:G 条轨迹并行 rollout。每个 task 同时开 G 个 environment instance,G 条轨迹同步推进。底层用 vLLM 做 LLM 推理(GPU memory utilization 0.7,tensor parallel 1)。
这个做法在工程上其实是绕开 WebArena 的 docker 环境隔离做了一些工程适配的,论文里没细说,但只要你做过 WebArena 评测就知道这个事不简单。能并行起来,训练时间能砍一大块。
Trick 三:M-GRPO,多轮版本的 GRPO
数学上是 GRPO 的自然扩展。GRPO 原来是这样:对一个 prompt \(q\),采 \(G\) 个 response,每个 response 一个 reward \(r_i\),组内做 z-score 当 advantage:
到多轮场景,一条轨迹 \(\tau_i\) 由若干 action \(a_{i,1}, a_{i,2}, ..., a_{i,|\tau_i|}\) 组成,每个 action 是一段 token 序列。M-GRPO 的 loss 长这样:
外面三层平均:先按轨迹平均,再按轨迹内 action 数平均,再按 action 内 token 数平均。\(\tilde{A}\) 用 PPO 那套 clip 操作做稳定。
这个公式从信用分配角度其实有个隐含假设:整条轨迹的成败被均匀分摊到每一个 token 上。一条 10 步的轨迹拿了 reward=1,第 1 步的某个错误 click 跟第 10 步的最终 exit 拿到的 advantage 是一样的。从理论上讲这肯定不是最优的——你完全可以训一个 step-level reward model 来更细粒度分配。但作者明确说了,这是 minimalist 设计,留给未来工作。
我喜欢这种坦诚。比起那些把 ORM 当作"创新点"硬塞进来的方案,先把 baseline 立起来再说优化,这个判断更有研究品味。
不同 RL 方案的对比:
| 方法 | 试错学习 | On-Policy | 不需 Replay Buffer | 不依赖外部信号 |
|---|---|---|---|---|
| Behavior Cloning | ✘ | ✘ | ✓ | ✓ |
| AWR | ✘ | ✘ | ✘ | ✓ |
| DigiRL | ✓ | ✘ | ✘ | ✓ |
| WebRL | ✓ | ✘ | ✘ | ✘(需 ORM) |
| WebAgent-R1 | ✓ | ✓ | ✓ | ✓ |
四项全绿,在表里就这一行。这种"四个钩"的对比表挺常见,写论文的人都会用。但这次我看完表格还是觉得作者说得没错——确实只有他们这一套是真正干净的。
实验:从 8.5% 到 44.8% 是怎么涨上来的
主表如下,WebArena-Lite 上五个网站的成功率(SR):
| 模型 | 方法 | GitLab | CMS | Map | Shopping | 平均 SR | |
|---|---|---|---|---|---|---|---|
| Qwen2.5-3B | Prompting | 5.3 | 13.3 | 5.7 | 0 | 4.4 | 6.1 |
| Llama3.1-8B | Prompting | 5.3 | 10.0 | 5.7 | 15.4 | 8.9 | 8.5 |
| Qwen2.5-32B | Prompting | 10.5 | 20.0 | 20.0 | 19.2 | 17.8 | 16.9 |
| GPT-4o | Prompting | 10.5 | 10.0 | 20.0 | 20.0 | 11.1 | 13.9 |
| GPT-4o-Turbo | Prompting | 10.5 | 16.7 | 14.3 | 36.7 | 13.3 | 17.6 |
| QwQ-32B | Prompting | 15.8 | 33.3 | 25.7 | 15.4 | 20.0 | 22.4 |
| OpenAI o3 | Prompting | 36.8 | 46.7 | 45.7 | 38.5 | 33.3 | 39.4 |
| OpenAI o4-mini | Prompting | 47.4 | 43.3 | 45.7 | 26.9 | 28.9 | 36.9 |
| Qwen2.5-3B | Behavior Cloning | 42.1 | 16.7 | 22.9 | 26.9 | 11.1 | 20.0 |
| Qwen2.5-3B | WebAgent-R1 | 26.3 | 53.3 | 48.6 | 26.9 | 24.4 | 33.9 |
| Llama3.1-8B | Behavior Cloning | 36.8 | 6.7 | 20.0 | 33.3 | 17.8 | 20.6 |
| Llama3.1-8B | Filtered BC | 52.6 | 20.0 | 31.4 | 23.3 | 8.9 | 23.0 |
| Llama3.1-8B | AWR | 57.9 | 26.7 | 31.4 | 26.7 | 17.8 | 28.5 |
| Llama3.1-8B | DigiRL | 57.9 | 26.7 | 37.1 | 33.3 | 17.8 | 30.3 |
| Llama3.1-8B | WebRL | 63.2 | 46.7 | 54.3 | 36.7 | 31.1 | 42.4 |
| Llama3.1-8B | WebAgent-R1 | 47.4 | 56.7 | 57.1 | 23.1 | 44.4 | 44.8 |
几个我比较在意的点:
3B 模型干掉 32B:Qwen2.5-3B + WebAgent-R1(33.9)已经超过 Qwen2.5-32B prompting(16.9)和 QwQ-32B(22.4)。在小模型上打 RL 是真划算。
8B 模型干掉 o3:Llama3.1-8B + WebAgent-R1(44.8)> OpenAI o3(39.4)。这个对比有点不太公平——o3 是闭源黑盒、prompting 用的,没经过 WebArena 训练;8B 经过了 BC + RL 两轮 in-domain 训练。但这也恰好是论文要传达的点:对于 web 这种 domain-specific 任务,"在域内训过的 8B 小模型" 比 "在域外刷分的最强通用模型" 更靠谱。
对 WebRL 的提升:8B 上 44.8 vs 42.4,涨了 2.4 个点。这个差距其实没有想象中夸张。换个视角看:WebAgent-R1 是端到端、不需要 ORM 的;WebRL 需要训一个外挂 ORM 来给 GPT-4 数据打分。在工程价值上,能用更简洁的方法做到稍好的效果,已经够说服我了。
但还要注意:Reddit 上 WebAgent-R1 反而比 BC 低(47.4 vs Llama BC 36.8 不算低,但 vs WebRL 63.2 差得明显)。这个域上 WebRL 的优势挺扎实的。作者没在正文中专门解释这点,我猜可能是 Reddit 任务对长 context 推理更敏感,而 R1 的动态压缩在某些 case 下损失了关键的历史观测信息。这是个值得追的开放问题。
训练动力学:三阶段是个有意思的现象
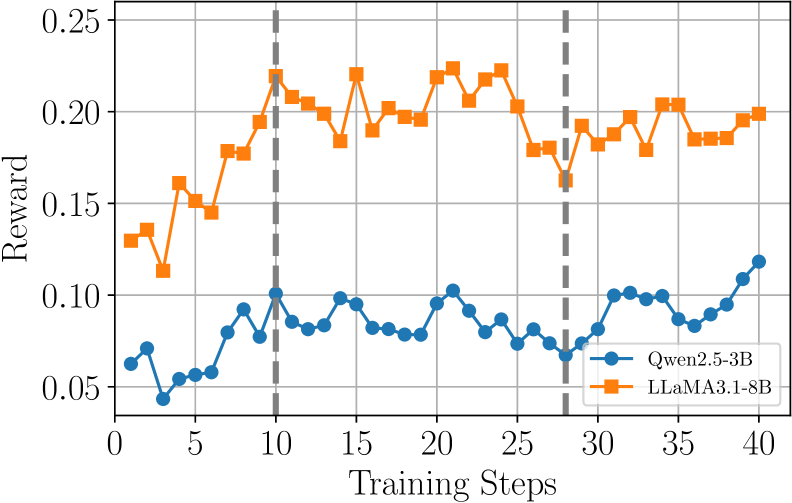
图 3:横轴 training step,纵轴 group 内平均 reward。橙色是 Llama-3.1-8B,蓝色是 Qwen-2.5-3B。两条灰色虚线把训练过程分成三段:(1)step 0-10 快速涨分(BC warm-up 之后的"初步技能掌握");(2)step 10-28 reward 反而往下走(探索阶段,模型在尝试新策略,平均成功率短暂下降);(3)step 28+ 稳定回升(学到了更好的策略)。
第二阶段那个掉头我盯着看了好一会儿。
很多人看到 RL 训练 reward 下降就觉得是训崩了,这里恰恰相反——作者认为这是策略探索的体现。从 step 10 到 step 28,模型在尝试一些之前 BC 没见过的动作组合,部分尝试失败导致平均 reward 下降,但成功的尝试为后面的 reward 回升积累了"new skill"。
这个解释合不合理?我觉得至少跟现象自洽。如果你看 trajectory length 和 # of interactions 的同期曲线(论文 Figure 3b/3c),第二阶段轨迹明显变长了,说明模型确实在尝试更复杂的多步行为。reward 下降是因为这些复杂尝试失败率高;第三阶段轨迹长度回归正常但成功率拉起来,说明模型把"该长则长,该短则短"学会了。
这个三阶段范式让我想到了 R1-Zero 那些 RL 训练曲线里的 "aha moment"。Web 任务上的"aha"显然没那么浪漫,但底层逻辑是一致的——从模仿到探索到稳定,是 on-policy RL 的内在节奏。
最关键的消融:为什么 Zero 模式不行
这是我读这篇论文时最兴奋的部分。
DeepSeek-R1-Zero 当时给整个圈子的震撼是"不需要 SFT,纯 RL 就能涌现 reasoning"。所以一个自然的问题是:Web Agent 上能不能也搞一个 R1-Zero?直接拿 base 模型上 RL,跳过 BC 这一步。
作者真去试了,结果叫 WebAgent-R1-Zero。
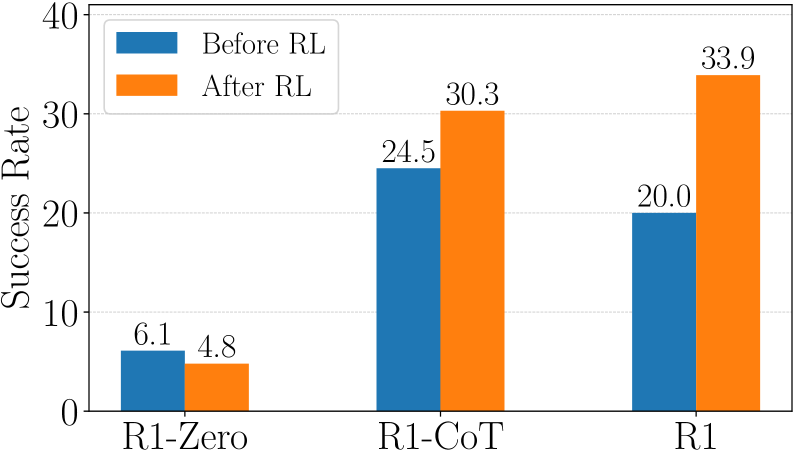
图 4:横轴是三个变体,纵轴 SR。蓝色是 RL 之前(即 BC checkpoint 或 base 模型),橙色是 RL 之后。最关键的发现:R1-Zero 不仅没涨,反而从 6.1 跌到 4.8——纯 base 模型直接上多轮 RL 是会崩的。R1-CoT(用 QwQ-32B 蒸馏的长 CoT 数据 BC)涨到 30.3,标准 R1 涨到 33.9。
R1-Zero 直接崩了。从 6.1 跌到 4.8。
为什么?我的理解是这样的:单轮数学题里,base 模型已经会说"我们一步一步算",问题只是说得对不对,二元 reward 能给到稀疏但有效的信号。但在 web 任务里,base 模型连 do(action="Click", element="7") 这种 DSL 都不会输出,每次 rollout 一万次有九千次连合法 action 都生成不出来,reward 全是 0,根本没有梯度信号让它"学到东西"。
所以在 Web Agent 这边,跳过 BC 的路目前走不通。BC 不是优化的目标,BC 是把模型的输出分布从"随机生成自然语言"挪到"生成可执行的 web action"上的必要起点。这个洞察对所有想做 agentic RL 的人都是重要警示。
R1-CoT 这个变体也很有意思。作者用 QwQ-32B 给 BC 数据生成详细的 long chain-of-thought("我现在该点哪个元素,因为...所以..."),用这个增强数据做 BC,得到一个会"长篇大论思考"的初始模型,再上 RL。
| 变体 | RL 前 SR | RL 后 SR | 单轮回复长度 | 交互次数 |
|---|---|---|---|---|
| R1-Zero | 6.1 | 4.8 | 短 | 少 |
| R1-CoT | 24.5 | 30.3 | 长 | 多 |
| R1 | 20.0 | 33.9 | 中 | 中 |
这里有个反直觉的发现:R1-CoT 的最终成绩反而比 R1 差(30.3 vs 33.9)。
按常理来说,让模型先学会详细思考再做决策,应该能涨更多吧?但实验上不是。作者给出的解释是:long-CoT 让模型在每一步都生成大量 reasoning token,但 web 任务的 reward 是基于最终成败的,这些中间 reasoning 没有直接监督信号——模型可能学到了"详细思考的形式"但没真的提高了"决策准确性"。
这个发现挺打脸"思考越多越好"那派的。在 web agent 这种 on-action 评估的场景下,过度思考可能是负担而不是优势。这个现象值得跟 OpenAI 那边 o3/o4-mini 的实际能力放一起再思考下。
Test-Time Scaling 的新姿势
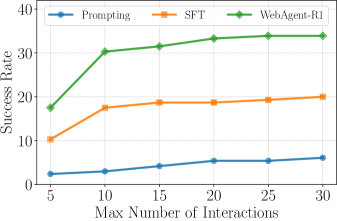
图 5:横轴是允许的最大交互轮数(5、10、15、20、25、30),纵轴 SR。蓝色 prompting baseline 几乎没变化,橙色 SFT 涨幅有限,绿色 WebAgent-R1 从 5 轮的 17 一路涨到 30 轮的 34,几乎线性放缩。
这是论文给出的另一个有意思的角度。
R1 在数学题上的 test-time scaling 是"让模型生成更长的思考链"。WebAgent-R1 给的是一个完全不同的 scaling 维度:让 Agent 跟环境多交互几轮。
从 5 步放宽到 30 步,prompting 模型基本无效(它就那么些招),SFT 模型缓慢涨(学过的招也有限),但 RL 训练后的 R1 几乎是"给我多少步我就用多少步",性能持续涨。
这背后其实是个很简单的道理:RL 训练让模型学会了在更长的 horizon 上规划——会回退、会重试、会换路径。给它的步数越多,它能从失败中恢复的次数就越多。这跟 prompting 模型那种"一锤子买卖"的行为模式完全不一样。
工程启发:如果你部署的是 RL 训过的 Agent,可以适度放宽 max steps 来交换更高的成功率。这是个免费的 scaling lever。
Thinking Format 的意外加成
| 模型 | 思考格式 | SR | 单步回复长度 | 交互次数 |
|---|---|---|---|---|
| Qwen2.5-3B | 无 | 3.2 | 139 | 6 |
| Qwen2.5-3B | 有 | 6.1 | 142 | 17 |
| Llama3.1-8B | 无 | 4.8 | 43 | 7 |
| Llama3.1-8B | 有 | 8.5 | 39 | 11 |
| o4-mini | 无 | 15.9 | 56 | 5 |
| o4-mini | 有 | 36.9 | 57 | 10 |
让模型用 <think>...</think><answer>...</answer> 这种双段式输出,比直接生成 action 强得多。最夸张的是 o4-mini,从 15.9 飞到 36.9,+21 个点。
但要注意,回复长度并没有显著变化(o4-mini 56 → 57),变的是交互次数——5 → 10。也就是说,思考格式让模型变得更敢于多轮试探、不那么容易过早 exit。
这点跟 R1-CoT 那个反直觉的发现一起看,挺有启发:对 web 任务,"思考"的价值不在于让单步 reasoning 更长更细,而在于让 Agent 在多步规划上更有耐心。
OOD 泛化:换个网站还能打吗
把在 WebArena 五个域上训好的模型,丢到 WebVoyager 五个完全没见过的域(Allrecipes、Amazon、Arxiv、Coursera、Google Map)上测:
| 域 | Prompting | SFT | WebAgent-R1 |
|---|---|---|---|
| Allrecipes | 0% | 4% | 28% |
| Amazon | 4% | 4% | 24% |
| Arxiv | 20% | 20% | 24% |
| Coursera | 16% | 16% | 44% |
| Google Map | 4% | 16% | 40% |
| 平均 | 8.8% | 12% | 32% |
OOD 域上 RL 模型的优势比 in-domain 还要明显。SFT 在新域上几乎没涨(毕竟它就是在 5 个旧域上拟合训练数据),RL 模型在新域上反而展现出更强的迁移能力。
我的解读:RL 训出来的 Agent 学到的不是"在 Reddit 上怎么操作",而是"在网页上怎么探索和试错"。这种能力是任务无关的,能直接迁移。SFT 学的更像是"在 Reddit 上具体的点击模式",换个网站就懵了。
这个对比挺打脸 SFT 派的。但坦白说,OOD 评测的样本量不大(每个域 25 个左右任务),数字本身的方差需要打个折扣。32% 这个数感觉还可以再多跑几个 seed 验证。
我的几点判断
读完整篇论文,我的整体感受是:这是一篇典型的"工程整合做对了就能赢"的论文。底层算法(GRPO)不是它的,BC warm-up 不是它的,二元 outcome reward 也不是它的——但把这些拼到一起,配上动态上下文压缩 + 并行采样这两个工程 trick,做成一个能 reproduce 的 Web Agent RL baseline,这个事的价值我觉得是被严重低估的。
亮点: 1. 干净的 baseline:不需要 ORM、不需要 replay buffer、不需要轨迹过滤——复现门槛因此极低。开源代码 + 一个 8 卡 A100 节点就能跑。 2. R1-Zero 的失败是有价值的负样本:直接告诉所有想跳过 BC 的人,在 agentic 场景下这条路目前走不通。这个"反向贡献"对社区有用。 3. Test-time scaling 的新维度:增加 max interactions 而不是 token 数,这个方向之前没人系统做过实验。
让我皱眉的地方: 1. Reddit 域上反而打不过 WebRL(47.4 vs 63.2),论文没给出令人信服的解释。 2. R1-CoT < R1 这个发现需要更深的分析:是 CoT 本身的问题,还是 QwQ-32B 蒸馏出来的 CoT 质量问题?换 R1 自己生成的 CoT 会不会不一样? 3. Reward 太稀疏:整条轨迹只在最后给一个 0/1 的信号,credit assignment 全靠组内 normalize。论文坦诚说了这是 minimalist 选择,留给未来。但谁先把 step-level reward shaping 做漂亮,下一篇 SOTA 就是谁的。 4. 评估规模偏小:WebArena-Lite 全集只有 165 个测试任务(5 个域 × 33),WebVoyager OOD 也就一两百个任务。在这种规模下 ±2 个点的差距能不能稳定复现,我心里没那么有把握。希望后续大家用同一份代码多跑几个 seed 确认下。
值不值得读: - 如果你做 web agent / 浏览器自动化,强烈建议精读,他们的代码值得直接抄。 - 如果你做 LLM agent 的 RL 训练(不限 web),值得读 method section,特别是动态上下文压缩和 M-GRPO loss 的实现细节。 - 如果你只关心算法创新,可以扫一遍主结果就够了,没有让人眼前一亮的算法 idea。
工程启发
如果你正在做类似的 Web Agent / Tool-use Agent 训练,这篇论文给我的几个直接 take-away:
- 不要跳过 BC。在 agentic 场景下,base 模型的输出分布跟 action space 之间存在巨大 gap,不靠 BC 拉对齐,纯 RL 没有梯度信号。
- 历史观测可以激进压缩。多轮场景下,过去的 observation 留个占位符就够了,action 历史才是关键。能把 context 砍掉 90%,训练成本直接降一个量级。
- on-policy 比 off-policy 在交互场景更香。off-policy 的 replay buffer 在状态依赖强的环境下会引入分布偏差,得不偿失。
- 多走几步比想得更深更值钱。Test-time 的 budget 优先给"交互次数"而不是"思考长度"。
- OOD 评测要做。在原域上的 SOTA 不能说明问题,换个域立刻露馅的方法多得是。
最后想说一句,今年 Agent + RL 这个赛道明显进入了"工程整合密集发力"的阶段。WebAgent-R1、Search-R1、SWE-Gym 这些工作风格都很像——不追求底层突破,而是把已有的算法干净地缝在一起,用扎实的工程把效果做出来。这个风格的论文越多,离真正能上线生产的 agent 就越近。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我