TurboRAG:把RAG的Prefill搬到离线,TTFT直接快9.4倍
核心摘要
做RAG最让人头疼的,不是召回不准,而是慢。每次query都得把召回的几个chunk拼起来跑一遍prefill,输入轻轻松松上万token,TTFT直接拉到秒级。这事儿在B端做客服、做搜索答案的场景上几乎是体验死结。
TurboRAG(Moore Threads AI出品,arXiv 2410.07590)的思路简单到让人有点意外——既然每个文档的KV Cache拼接出来跟原始一起prefill"差不多",那就把每个chunk的KV Cache提前算好存起来,在线时直接拼。问题剩下两个:注意力掩码不一样、位置编码错乱。作者用一套Independent Attention + Reordered Positions解决,再用50%文档QA数据微调一下Qwen2-7B,把准确率拉回到Naive RAG水平。最终在LongBench多文档QA上TTFT平均加速8.6倍、峰值9.4倍,在线计算量降低98.46%。
这篇论文不算"颠覆性",它真正值钱的地方在于把一个工程上一直被讨论的trick做成了完整的可复现方案,并且认真回答了"为什么可以这样做"。如果你正在做RAG服务化、卡在TTFT指标上,这篇值得花半小时读完。
论文信息
- 标题:TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text
- 作者:Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, Yaohua Tang
- 机构:Moore Threads AI(摩尔线程)
- arXiv:2410.07590v1
- 代码:https://github.com/MooreThreads/TurboRAG
为什么这件事值得做
先讲一个真实的工程痛点。
之前在做一个文档问答的内部应用,召回top-5的chunk,每个chunk大概1500-2000个token,拼起来加上system prompt和query,输入大概在10K左右。Qwen2-7B在A100上跑这种长度的prefill,TTFT在800ms-1.5秒之间。线上一上量,p99飚到2秒+,体验直接拉胯。
这里面藏着一个让人很难受的事实——每个chunk的KV Cache,其实算了很多遍。同一个高频片段(比如某条政策、某个产品介绍),一天可能被几千次query召回,每次召回都要重新prefill一次。
更难受的是,prefill的计算复杂度跟序列长度的平方相关。10K的输入,每次都得跑一次完整的O(n²),而其中真正"新"的部分只有那个百来token的query。
这其实是RAG架构在系统层面一直没被很好解决的一个尾巴。论文把这个痛点拆成了三句话:
- 重复计算:高频chunk被反复召回,反复算KV Cache
- TTFT高:拼接后的长上下文prefill是平方复杂度,首字延迟动辄秒级
- 吞吐受限:单卡显存被长context挤满,batch size上不去
这三个问题的根都在一个地方——prefill是在线做的,针对的是拼接后的长文本。如果能把这一步搬到离线、变成针对短chunk的独立计算,那这三个问题就能一起解。
那能不能这么做?这就是TurboRAG要回答的问题。
TurboRAG的两个关键观察
直觉上这事儿不行。因为"分别算每个chunk的KV Cache"和"拼起来一起算"在数学上就是不等的——前者每个chunk内部能看到的token只有自己;后者chunk之间有完整的cross attention。把前者的KV Cache直接拼起来当成后者用,理论上模型应该崩。
但作者基于两个观察,认为这事儿"差不多能行":
观察一:RAG里chunk之间的cross attention其实非常稀疏。
我第一次看到这个论断的时候是有点怀疑的——这听起来太"为我所用"了。但作者给了Figure 2的可视化,让我至少觉得这个观察是站得住脚的。
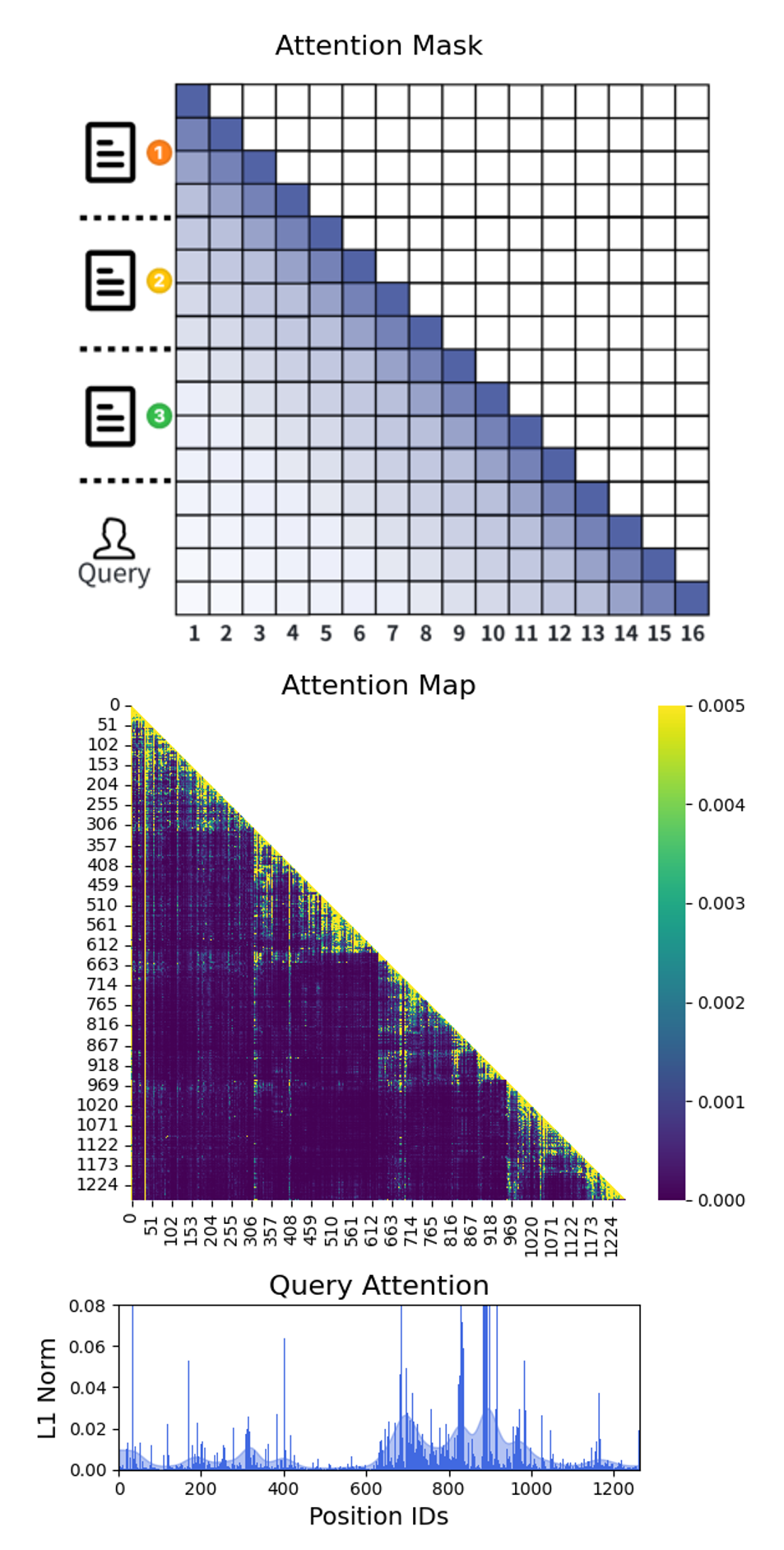
图1(Causal Attention):上排是标准RAG的下三角注意力掩码示意;中间的Attention Map是真实跑一个4-chunk + query实例的注意力分数;底下是query对所有context位置的L1注意力。可以明显看到中间的Attention Map呈现出"块对角"的稀疏结构——每个chunk主要在关注自己内部,chunk之间的attention score基本是黑色(接近0)。
这就是观察一的核心证据。在标准的全连接causal attention下,模型其实已经"自发"地不去做太多chunk间的cross attention了。所以哪怕你强行把chunk之间的attention全mask掉,对模型最终的判断影响有限。
观察二:RoPE只关心相对位置。
这点稍微学术一点,但很关键。RoPE(旋转位置编码)的核心性质是:两个token之间attention score的位置贡献,只跟它们的位置差有关,跟绝对位置无关。
那对于一个chunk内部,无论你是单独算它(位置从0到l)还是放在长上下文里算(位置从offset到offset+l),chunk内部任意两个token的相对距离都是一样的。所以chunk内部的KV Cache,单独算和拼起来算,数学上是等价的——前提是后续注入位置信息的时候,能用上正确的相对位置。
这两个观察组合起来就是TurboRAG的全部底气:观察一说"chunk间cross attention可以丢",观察二说"chunk内KV Cache可以单独算"。两个加起来,"离线预算KV Cache + 在线拼接"这条路就通了。
Pipeline:把prefill拆成离线+在线两段
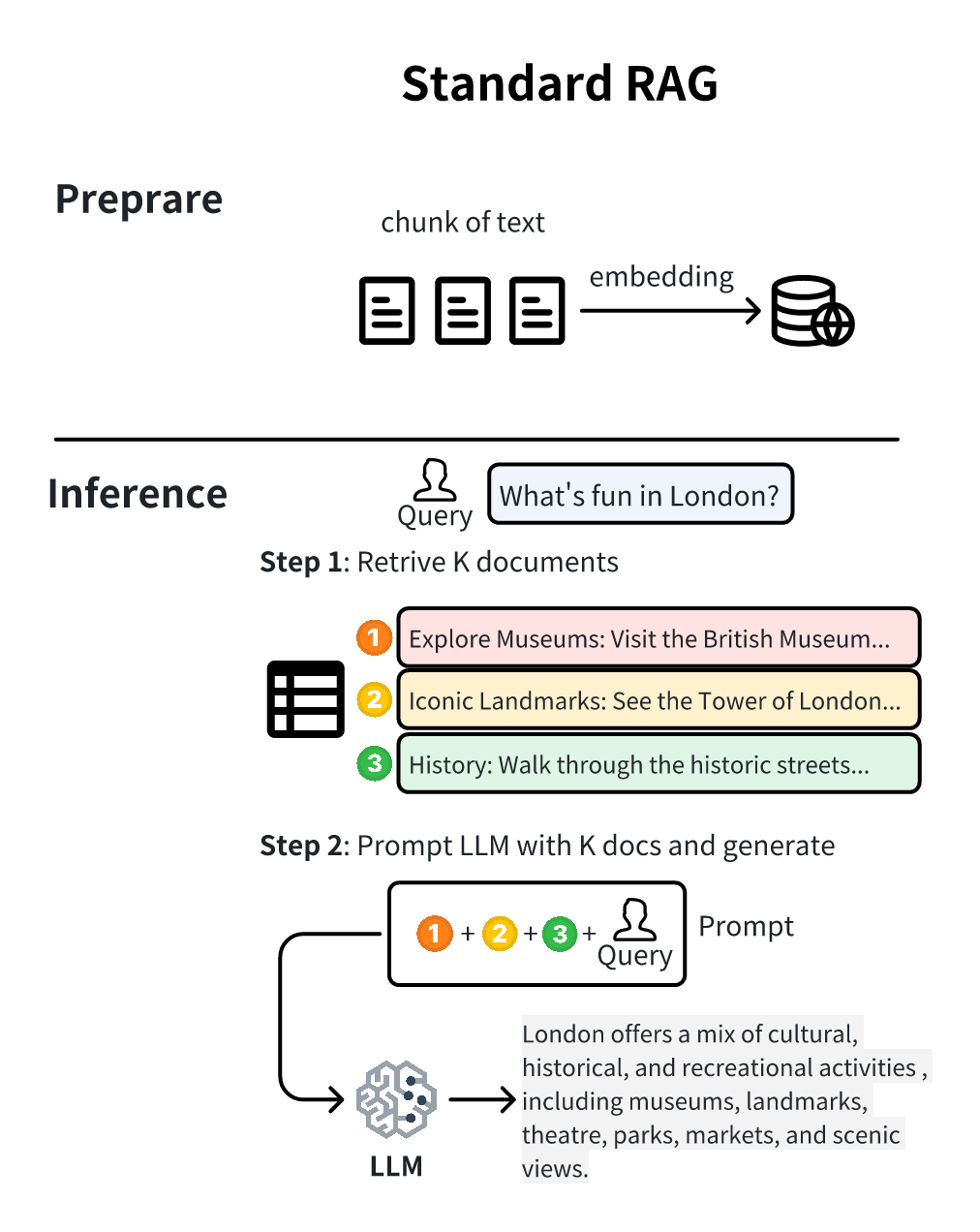
图2-a(Standard RAG):标准RAG的两阶段流程。Prepare阶段只算embedding存向量库;Inference阶段先召回top-k文档,然后把文档+query拼成长prompt送给LLM做完整的prefill+decode。所有重活儿都在线做。
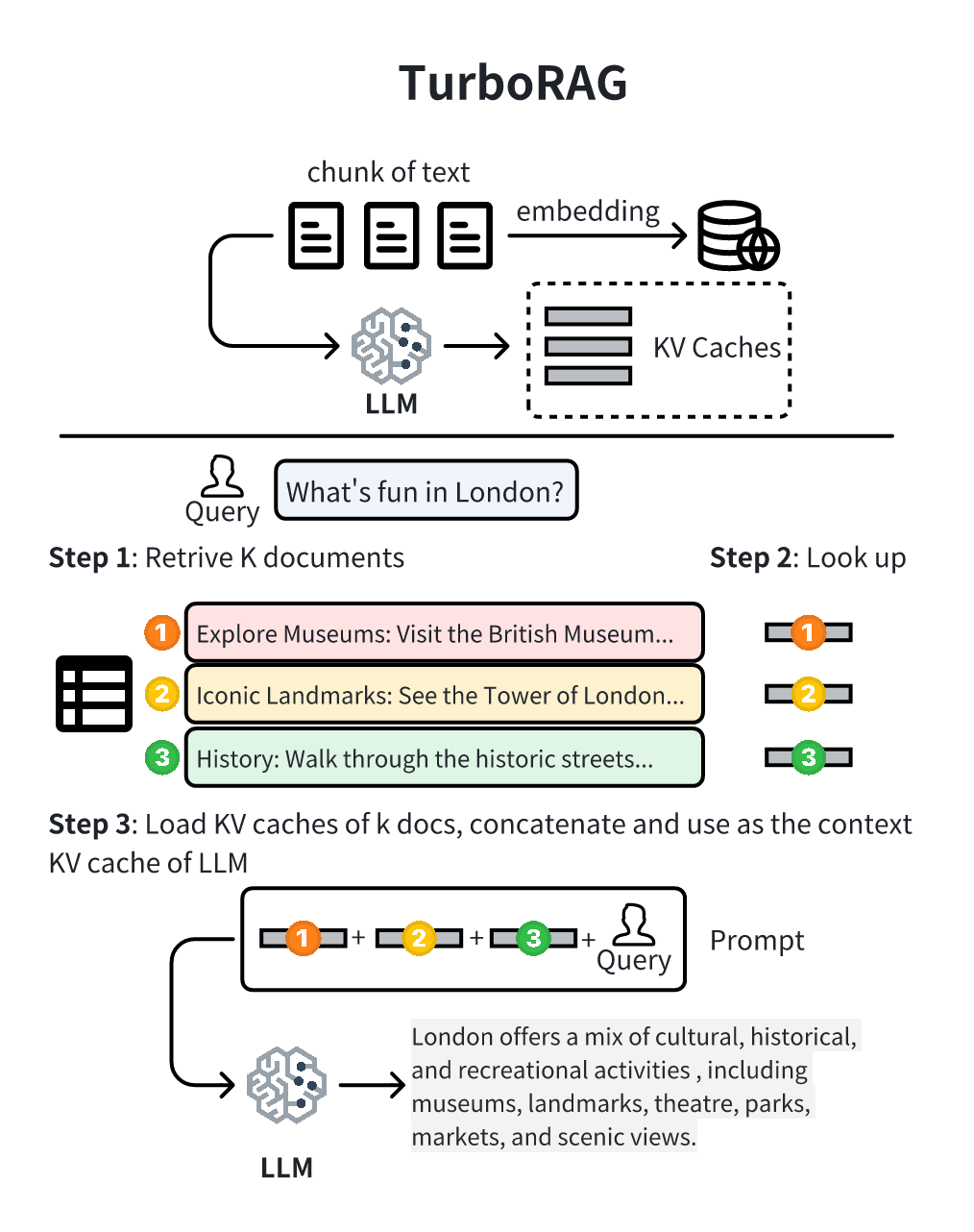
图3-b(TurboRAG):在Prepare阶段除了算embedding,还多做一件事——用LLM对每个chunk提前跑一遍prefill,把每层的KV Cache都存下来。Inference阶段,召回的不仅仅是文档原文,还有它们对应的KV Cache;直接把这些KV Cache拼起来当作context,模型只需要为新增的query做prefill即可。
整个流程其实非常对称:
| 阶段 | Standard RAG | TurboRAG |
|---|---|---|
| 离线 | 算embedding | 算embedding + 算KV Cache |
| 在线召回 | 拿chunk文本 | 拿chunk文本 + 拿KV Cache |
| 在线prefill | 对完整prompt(chunks + query)做prefill | 拼接chunks的KV Cache,只对query做prefill |
| 在线decode | 一样 | 一样 |
最关键的变化在"在线prefill"那一行——原来要算的是几千上万token的二次复杂度,现在只算query那百来token,剩下的KV Cache是直接load进来的。
两个不一致:Attention Mask和Position ID
但事情没完。直接拼接KV Cache会导致两个跟原始计算"不一致"的地方,这俩才是论文的技术核心。
不一致一:Attention Mask
标准的causal attention下,query对所有context都有完整的注意力,context内部的token也能跨chunk互相attend。但如果chunks是离线独立prefill的,chunk之间根本没算过cross attention——你硬是把它们拼起来当成完整KV Cache用,相当于隐式假设"chunk间的attention=0"。
作者把这种隐式假设显式化,叫做 Independent Attention:每个chunk只能attend到自己内部,但query可以attend到所有chunk和自己。
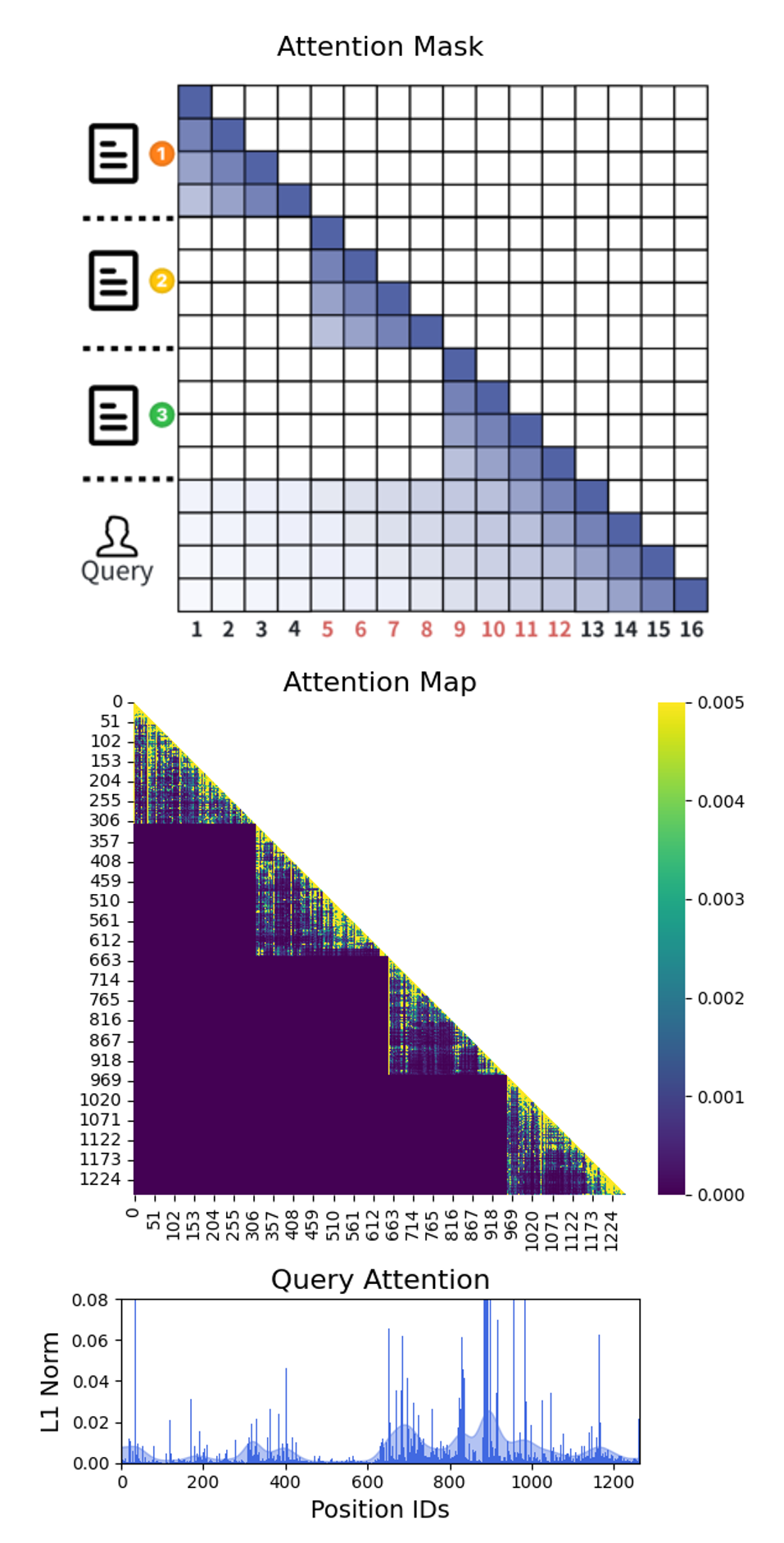
图4(Independent Attention + Reordered Positions):上排显示新的attention mask——3个chunk之间的attention全部置零(mask matrix中chunk块之间的方格全空),但query部分(图中Query行)依然能attend到所有chunk。中间的Attention Map可以看到非常明显的块对角结构——chunk间的attention score整体被压成黑色。最下面的Query Attention分布跟Causal Attention版本对比变化非常小,依旧集中在包含答案的那个chunk附近。这是关键的实验证据:mask掉chunk间attention后,query对相关chunk的关注度几乎没变。
这张图我看了好几遍。它做的其实是一件挺有说服力的事情:通过对比Causal和Independent两种setting下query对context的attention分布,证明mask掉chunk间attention对最终的query→context attention pattern影响微乎其微。这就把观察一从直觉变成了实证。
不一致二:Position ID
这块是论文里我觉得最值钱的一个细节。
每个chunk独立算KV Cache时,它的position ID是从0开始的。3个chunk拼起来后,组合起来的position ID序列是 [0,1,...,l, 0,1,...,l, 0,1,...,l]——每个chunk都从0开始,作者管这叫 Composite Positions。
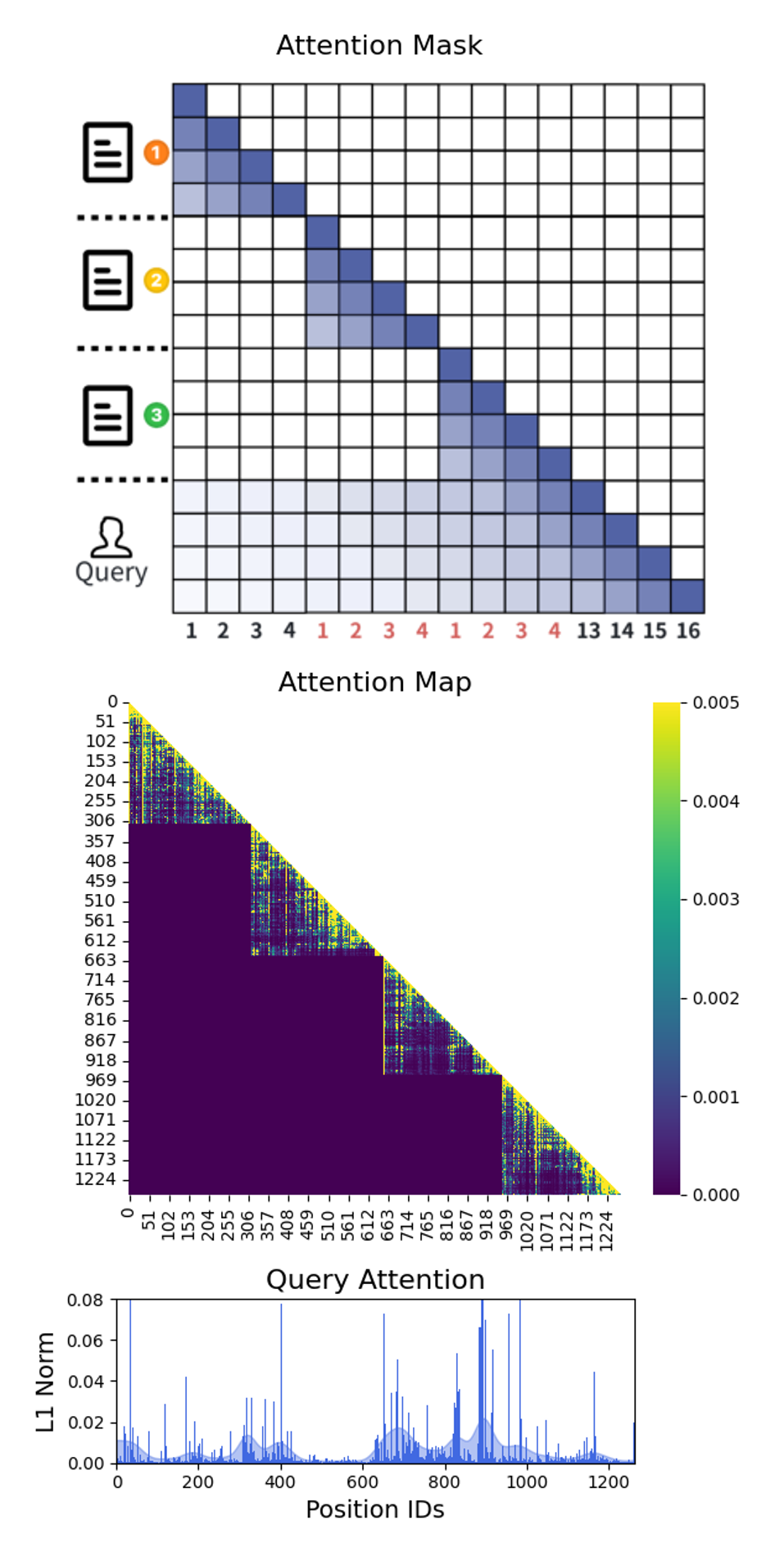
图5(Independent Attention + Composite Positions):注意上排attention mask下面那一排数字——前4位是1,2,3,4(黑色),中间是1,2,3,4(红色,因为是第二个chunk重新从1开始),再后面又是1,2,3,4(红色),最后query是13,14,15,16(黑色)。这种"重置"的位置编码方式实现起来最简单(直接用每个chunk单独算的KV Cache),但它会让相对位置失真。
这种做法的问题是什么?想象query在位置13,第二个chunk里某个token在位置3。RoPE会把它们当成"相对距离10"来算attention。但在原始的拼接prefill里,这两个token的真实位置差应该是 13 - (l + 3) = 13 - 7 = 6(假设l=4)。位置差错了,attention pattern就错了。
所以作者的另一个方案是 Reordered Positions——在线拼接KV Cache时,重新把所有chunk的位置编码连成 [0,1,...,l, l+1,...,2l, 2l+1,...,k·l],每个token的位置都跟它在拼接后的真实位置对应。
这里RoPE的一个性质又派上用场了:因为RoPE是在K上后施加的(公式上是先算K再乘上位置编码),你只需要在保存KV Cache时保存还没旋转的K,在线拼接的时候按新位置重新做一次RoPE就行。计算上几乎没多少开销。
两套方案,作者都做了实验对比,结果是Reordered Positions全面优于Composite Positions——这其实印证了"相对位置对RoPE是真的重要"这件事。
微调:让模型适应新的注意力模式
光改attention mask和position ID还不够。预训练LLM从来没见过Independent Attention这种结构,直接用会掉点。
作者构造了如下格式的训练数据:
You are an accurate and reliable AI assistant ...
<|doc_start|>{chunk_1}<|doc_end|>
<|doc_start|>{chunk_2}<|doc_end|>
<|doc_start|>{chunk_3}<|doc_end|>
...
Question: {query}
特殊token <|doc_start|> 和 <|doc_end|> 用来标识chunk边界,训练时attention mask和position id就按图4或图5的方式设置。
训练数据的配比是50%文档QA + 50%通用(25%通用对话 + 10%推理 + 10%代码 + 5%其他)。文档QA这部分包含了glave-rag-v1(51K)、HotpotQA(17.8K)、PubMedQA(22K)、TAT-QA(29.8K)等等公开数据集,加起来18个数据集。基座是 Qwen2-7B,32×A100 80GB,batch size 256,学习率1e-5,AdamW。
整套配置走的是非常标准的SFT流程,没有什么花活儿。这其实是论文的一个隐含贡献——用很轻的微调就把方法落地了,没要求重训RoPE,没改架构,对工程友好。
实验结果
文档QA准确率:跟Naive RAG基本打平
RGB Benchmark的结果是这样的(中文部分截取):
| Model | Noise=0.2 | 0.4 | 0.6 | 0.8 | Avg. |
|---|---|---|---|---|---|
| gpt-4o-2024-08-06 | 98.3 | 98.0 | 96.6 | 87.7 | 95.2 |
| Naive RAG(Qwen2-7B SFT) | 99.0 | 98.0 | 96.7 | 87.3 | 95.3 |
| TurboRAG-composite w/o finetune | 98.3 | 96.3 | 93.7 | 79.0 | 91.8 |
| TurboRAG-reordered w/o finetune | 98.0 | 96.7 | 93.3 | 81.3 | 92.3 |
| TurboRAG-composite | 99.0 | 97.3 | 96.0 | 86.7 | 94.8 |
| TurboRAG-reordered | 98.7 | 97.3 | 96.0 | 90.7 | 95.7 |
英文部分类似,TurboRAG-reordered avg 96.8、Naive RAG 98.2、GPT-4o 98.2。
几个值得抠的细节:
第一,没有微调直接拼KV Cache,平均掉点4-5%,最坏情况(noise=0.8)能掉接近20%。这印证了"模型确实需要见过新的attention pattern才能work",光靠观察一的"差不多"是不够的。
第二,微调之后reordered的平均分(95.7)甚至超过了Naive RAG(95.3)和GPT-4o(95.2)。这点其实有点反直觉——你把信息丢了(chunk间cross attention),怎么反而能更高?我的理解是,独立的注意力反而让模型在高noise(无关chunk很多)的场景下不容易被噪声chunk之间的"误导性关联"带跑偏。0.8 noise下reordered的90.7远超Naive RAG的87.3就是这个迹象。
第三,composite一直比reordered差,且差距在难任务上更大。这个观察跟RoPE的相对位置性质完全自洽——位置差信息一旦失真,模型对长context的处理就跟着崩。
LongBench的多文档QA也验证了这点:
| Subcategory | Context tok | Naive | Turbo-comp | Turbo-reord | TTFT Naive | TTFT Turbo-reord | Speedup |
|---|---|---|---|---|---|---|---|
| musique | 16349 | 22.12 | 23.64 | 27.37 | 1610ms | 171ms | 9.4x |
| 2wikimqa | 7553 | 35.02 | 34.28 | 39.51 | 709ms | 101ms | 7.0x |
| dureader(zh) | 10642 | 34.57 | 33.37 | 33.03 | 1007ms | 116ms | 8.7x |
| hotpotqa | 13453 | 40.21 | 35.78 | 45.28 | 1333ms | 147ms | 9.1x |
| Avg. | 11999 | 32.99 | 31.76 | 36.29 | 1165ms | 134ms | 8.6x |
注意musique和hotpotqa上TurboRAG-reordered反超Naive RAG接近5个点。这俩任务都是要求多跳推理的,按理说跨chunk的attention应该重要,但实际效果反而是Independent Attention更好——这反过来说明在Naive RAG的全连接attention里,chunk之间的noise可能反而是干扰项。
通用能力回归测试
OpenCompass上的回归测试结果:
| Model | MMLU | TriviaQA | GSM-8K | MATH |
|---|---|---|---|---|
| Naive RAG | 69.57 | 56.90 | 79.12 | 39.54 |
| TurboRAG-reordered | 70.73 | 56.47 | 79.45 | 40.58 |
| Δ | +1.16 | -0.43 | +0.33 | +1.04 |
基本无差异,甚至大多数任务还略涨。说明引入Independent Attention并没有把通用能力训坏。
Batch Scaling:吞吐才是真王炸
| Batch | Metric | Naive | Turbo(含H2D) | Speedup | Turbo(不含H2D) | Speedup |
|---|---|---|---|---|---|---|
| 1 | TTFT (ms) | 711 | 175 | 4.1x | 44 | 16.1x |
| 2 | TTFT (ms) | 1408 | 325 | 4.3x | 56 | 25.1x |
| 4 | TTFT (ms) | 2842 | 666 | 4.3x | 97 | 29.3x |
| 6 | TTFT (ms) | 4373 | 928 | 4.7x | 134 | 32.6x |
| 8 | TTFT (ms) | 5812 | 1429 | 4.1x | 177 | 32.8x |
| - | TFLOPs(任意batch) | 100% | 1.54% | - | 1.54% | - |
最值钱的数字是 TFLOPs降低98.46%。这个数据等价于:同样的GPU能跑大得多的batch、扛住高得多的并发。文档QA这种平均输入1万token、输出几十token的场景,prefill本来就是绝对的算力大头,TurboRAG基本上把这块给抹平了。
如果KV Cache需要从CPU内存通过PCIE传到GPU(H2D),加速比从单batch的16x缩水到4x左右——通信开销吃掉了一大块算力优势。如果能预热到显存里,加速比就回到20-30x级别。这其实给工程部署提了个非常实际的提示:把热门chunk的KV Cache做分级缓存,用LRU或者frequency-based策略尽可能多地驻留在GPU显存。
一些没那么舒服的地方
我对这篇论文整体是比较肯定的,但有几个地方想说一下。
第一,存储成本论文没正面回答。
KV Cache的体积是不小的。以Qwen2-7B为例,32层、kv_head=4、head_dim=128,每个token的KV Cache在FP16下是 2 × 32 × 4 × 128 × 2 bytes ≈ 65KB。一个2000-token的chunk就是130MB。如果你的知识库有100万个chunk,全量预计算需要 130TB 的KV Cache存储。这可不是个小数。论文提到"如果有压力可以只缓存高频chunk",给了一个混合方案的口子,但没做实际的存储/命中率/性能trade-off实验,这块是个明显的缺口。
第二,"first work"的说法值得打个问号。
论文Related Work里写"to the best of our knowledge, this is the first work...redesign inference paradigm of the current RAG system by transforming the online computation of KV caches for the retrieved documents into offline processing"。
实际上和它非常接近的工作至少有:
- RAGCache(arXiv 2404.12457,2024年4月):提出knowledge tree组织KV Cache的多级存储,TTFT提升4x。论文确实在Related Work里提了一句"only focuses on intermediate results and does not analyze model accuracy"。但RAGCache先于TurboRAG半年。
- CacheBlend(arXiv 2405.16444,2024年5月):解决"被复用的chunk不一定是prefix"的问题,通过选择性重算少量token的KV来修复,TTFT提升2.2-3.3x,且不需要微调模型。
- PromptCache(更早的工作):提出modular attention的概念,让prompt的不同片段可以重用cache。
TurboRAG的差异化在于:(a) 完整地解决了attention mask和position ID不一致的问题;(b) 通过微调把准确率拉回基线;(c) 加速比在LongBench这种长文档场景下做到了行业leading的8.6x。但说"first"是有点过了。
第三,必须微调是一个不小的门槛。
这跟CacheBlend那种training-free的方案对比起来是个明显的劣势。微调本身是有成本的:你得有训练资源、得维护一个跟原模型不一样的权重、得保证你的finetune数据能覆盖业务场景。对于已经有自己专业领域微调模型的团队,要不要再为TurboRAG重新训一遍?这是个工程决策。
第四,Independent Attention会不会真的丢东西?
虽然论文用一个case的可视化来说明chunk间attention很稀疏,但这是不是普适的?在某些任务(比如多跳推理需要在chunk A里找到线索、再去chunk B里查证),强制把chunk间attention置零有没有可能掉点?HotpotQA和musique的反超结果说明在这俩benchmark上没问题,但这不代表所有场景。我的感觉是,TurboRAG对那种"每个chunk是独立信息单元、答案聚合靠query的"场景非常友好(FAQ、产品手册、政策问答),对深度推理类场景就要谨慎一些。
工程上能拿走什么
如果你也在做RAG服务化,这篇论文有几个东西可以直接拿走:
第一,离线KV Cache是个真实可工程化的优化点。 不一定要上TurboRAG的全套,哪怕你只缓存top 1%-10%的高频chunk的KV Cache,都能对TTFT产生肉眼可见的优化。
第二,Independent Attention + Reordered Positions这套配置是关键。 如果直接拼KV Cache不微调,掉点是不可接受的。但如果做了对应的微调,效果是真能打平甚至略微超过Naive RAG的。<|doc_start|> <|doc_end|> 这套special token设计也很值得借鉴。
第三,KV Cache的分级缓存是必须的。 PCIE带宽是瓶颈,论文的batch scaling实验已经把这点说清楚了。在线服务一定要有显存级别的KV Cache LRU + 内存级别的KV Cache LRU。
第四,关注同期工作。 RAGCache、CacheBlend、FusionRAG都是同一类问题的不同解。如果你不能/不想微调,CacheBlend是更友好的选择;如果对吞吐和TTFT的极致追求大于对模型独立性的需求,TurboRAG值得一试。
收尾
RAG的优化一直分两条路。一条是上层的——更好的retrieval、更聪明的rerank、更精准的prompt。另一条是下层的——更快的prefill、更省的算力、更高的吞吐。这两条路最近一年都在卷,但下层这条因为牵扯到模型推理基础设施,进展往往比上层慢。
TurboRAG的价值在于把下层这条路上"预计算KV Cache"这个一直被讨论的trick做成了完整方案,并且认真处理了attention mask和position ID这两个看似小、实则致命的细节。这种"把简单idea做透"的工作,工程上的价值往往比一些花里胡哨的"创新"更高。
如果你团队的RAG业务正好卡在TTFT指标上、卡在GPU吞吐上,又正好用的是基于RoPE的开源模型(Qwen、Llama这一系列),TurboRAG值得花两天时间在自己业务数据上跑一遍。如果数据够、算力够,这8.6x的加速很可能是真的能拿到手的。
但如果你的业务深度依赖chunk间的多跳推理,或者你不想再为RAG单独维护一份微调权重,CacheBlend这种training-free的方案可能更合适。
工程优化没有银弹,永远是trade-off。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我