TokenSelect:把 KV Cache 的"块级粗筛"砸碎到 Token 级,128K→1M 上下文加速 23.84 倍
核心摘要
长上下文推理的痛点你只要做过就知道:模型预训练只学过 8K/32K 长度,硬塞 128K 进去要么直接乱码,要么 attention 那个 O(N²) 让显存和延迟一起爆炸。这两年的主流路线分两派——一派堆 post-training 把窗口拉长(贵),一派用稀疏注意力按"块"挑 KV Cache 进算(快但糊)。TokenSelect 这篇 EMNLP 2025 的论文做了一件听起来朴素但效果意外狠的事——把"块级筛选"砸碎到"Token 级筛选",再配上 head soft vote、Selection Cache、Paged Dot Product Kernel 三件套,让一个原本只支持 32K 的 Llama-3 在 1M 上下文上推理,attention 算子提速 23.84 倍,端到端 2.28 倍,RULER 128K 上的得分还能反超原模型。 我读完最直接的判断:这不是底层突破,但它把工业落地需要的三个细节(精度、kernel 效率、和 SGLang/vLLM 兼容)都拧到位了,是那种你做长上下文 serving 真的想抄一下的方案。
论文信息
- 标题:TokenSelect: Efficient Long-Context Inference and Length Extrapolation for LLMs via Dynamic Token-Level KV Cache Selection
- 作者:Wei Wu¹,Zhuoshi Pan²,Kun Fu³,Chao Wang¹,Liyi Chen⁴,Yunchu Bai¹,Tianfu Wang⁵,Zheng Wang³,Hui Xiong⁵,⁶†(*共同一作,†通讯)
- 机构:¹中国科学技术大学,²清华大学,³阿里云,⁴小红书,⁵香港科技大学(广州),⁶香港科技大学
- 会议:EMNLP 2025 Main
- arXiv:2411.02886v4(v4 更新于 2025 年 10 月)
一、为什么这事一直没解决好
先把场景拉回来:你拿一个 Llama-3-8B(预训练上下文 8K),喂进去一篇 128K token 的文档让它做 QA。会发生什么?
第一种死法是位置外推爆掉。模型在训练时根本没见过这么长的位置编码,RoPE 直接 OOD,输出基本是垃圾。RULER 128K 上 Llama-3-8B 原始能拿 0 分——是真的零,不是约等于零。
第二种死法是算不动。即使你用 NTK 插值、YaRN 或者长文本 post-training 把窗口扩到 128K 了,attention 还是 O(N²)。算一次完整 attention 在 128K 上能让 A100 跪给你看。
工业界这几年的主流处理是两条路:
路线 A:长文本 post-training。Yang et al.(Qwen2 团队)等做的就是这个——拿大量长文档继续训。问题是贵。论文 limitation 里也提到,复杂 benchmark 上 8B 模型用 8 张 A100 跑接近一天。
路线 B:稀疏注意力。这条路又分两个流派:
- 预定义稀疏模式:StreamingLLM、LM-Infinite、Big Bird——固定保留开头几个 token + 滑动窗口最近 N 个。简单粗暴,但代价是中间的长上下文信息基本丢光。
- 动态选择 KV Cache:H2O、SnapKV、InfLLM、QUEST、MInference——按某种"重要性"挑一部分 KV 进 attention。
TokenSelect 这篇就是冲着路线 B 的第二个流派去的,但他们的攻击点很具体:现有方法都在"块级"做选择,作者认为这个粒度根本不对。
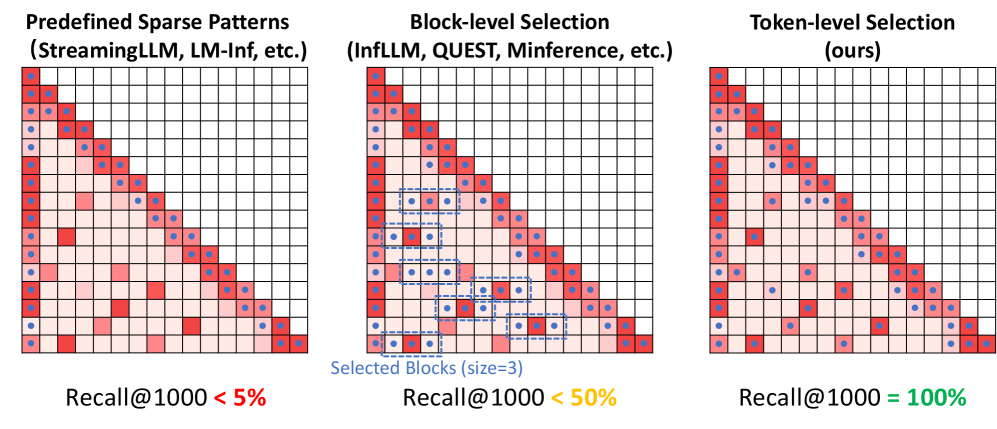
图 1:作者用 Recall@1000(在 1000 个 token 预算内召回多少真正关键的 token)做了个直观对比。红方块是 ground-truth 的 critical token,蓝点是各方法选中的 token。预定义模式只盯着对角线和左上角,长文中间的 critical token 几乎全漏;块级选择能覆盖一些"成簇"的 token,但论文里反复强调的"non-contiguous sparsity"——也就是真正重要的 token 是稀疏散点而非连续块——让块级选择漏掉超过一半。Token 级选择直接 100% 命中。
读到这张图我的第一反应是:"Recall@1000 < 5% 是不是太极端了?" 但你想想 StreamingLLM 的设计——它就是固定保留开头 + 最近窗口,对于一个需要从 128K 中段精确 retrieve 一个 KV 对的任务(比如 R.KV passkey),这种模式确实就是抓瞎。后面表 1 的数据印证了这点,StreamingLLM 在 R.KV 上分数是 2.4%。
二、三个关键观察:把"块级假设"按在地上摩擦
这篇论文做对的第一件事是 motivation 给得很扎实。它不是张口就来"我们提出 X",而是先把现有方法的核心假设拆出来挨个怼。
观察 1:Attention 在 token 级是稀疏且非连续的
InfLLM、QUEST、MInference 这些块级方法都依赖一个隐含假设——critical token 倾向于聚集成连续块,所以按块筛就够了。作者直接把 attention score 的 heatmap 画出来反驳:
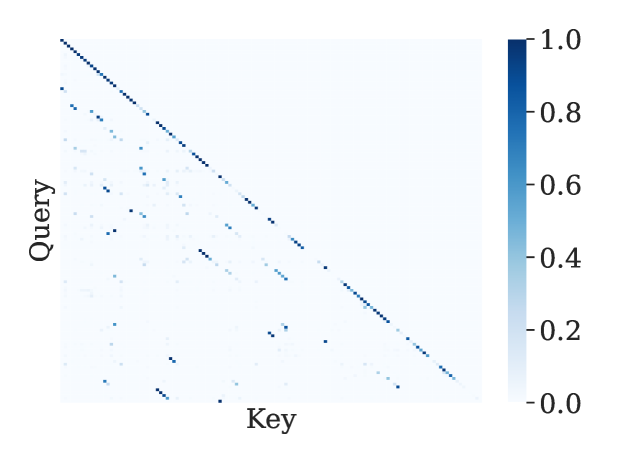
图 2(a):横轴是 Key 位置,纵轴是 Query 位置。除了对角线(local attention)外,真正关键的高分点(深蓝)是散点分布的,并不形成明显的连续区块。这就是论文反复说的 "non-contiguous sparsity"。
光指出现象还不够,作者用一个量化实验把"块级粗"这件事钉死:
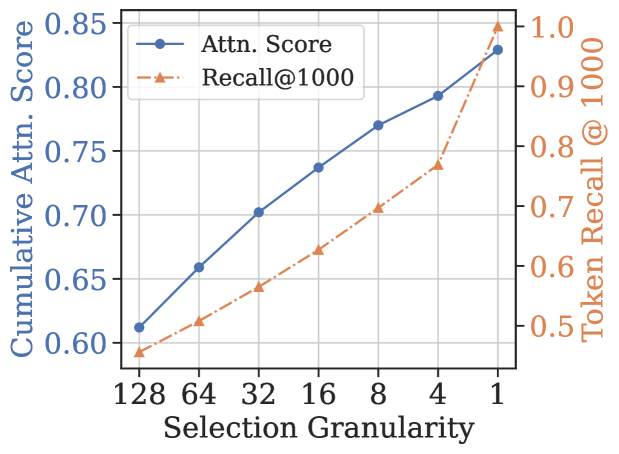
图 2(b):横轴的 Selection Granularity 是块大小,越往右块越小(1 就是 token 级)。Recall@1000 从块大小 128 时的约 0.45 直接拉到 token 级的 1.0。这是 TokenSelect 选 token 级粒度最关键的数据支撑——粒度细到极致,召回率提升 50+ 个百分点。
这里有个我觉得讲得很漂亮的细节:粗粒度块级选择会"误伤"。一个块里只要有一个 high-attention token,整个块都被纳入;反之,一个 high-attention token 如果落在低分块里,就会被整体丢弃。Token 级选择天然没这个问题。
观察 2:不能直接 top-k——head 之间的 logits 量级差太多
那是不是直接对 \(\mathbf{Q} \cdot \mathbf{K}^\top\) 做 top-k 就行?作者画了一张图劝你别这么干:
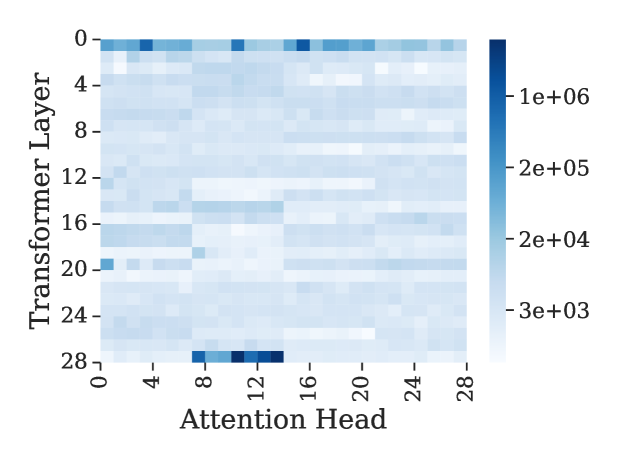
图 2(c):横纵轴分别是 attention head 编号和 Transformer 层编号,颜色深浅是 L1 norm。可以看到不同 head 的 logits 量级跨度从 3e3 到 1e6,差了三个数量级。如果直接把所有 head 的 logits 拼起来做 top-k,结果会被那几个 norm 巨大的 head 完全主导——其他 head 的"投票权"被吞掉了。
这是个很务实的发现。直觉上多头注意力就是要让每个 head 各自捕捉不同模式,但如果你把它们的 logits 直接 concat 做 top-k,相当于让"嗓门最大"的几个 head 决定全局。所以作者的设计目标变成了:保证每个 head 在 token 选择中的话语权独立。
观察 3:连续 Query 之间的相似度极高
如果对每个 Query 都做一次 token 选择,开销会把前面省下的算力全吃掉。作者做了第二个观察来挽救这个开销:
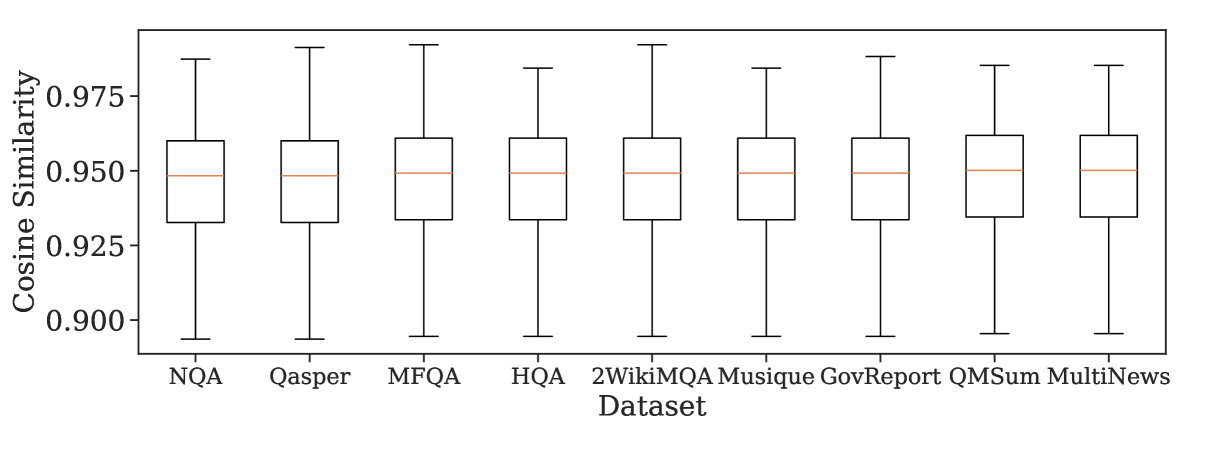
图 3(a):这个图我看了挺意外。9 个完全不同类型的任务(QA、摘要、多跳推理、代码),连续两个 Query 的 cosine similarity 中位数都死死卡在 0.945 左右,箱线图分布也几乎一致。这说明"连续 Query 高度相似"是 LLM decode 的普遍现象,不是某个任务的偶然属性。
更关键的是,Query 越相似,token 选择结果越一致:
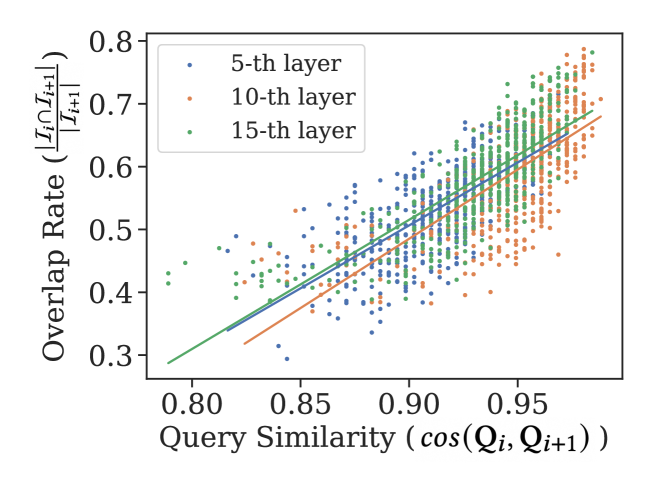
图 3(b):横轴是连续 Query 的 cosine similarity,纵轴是前后两次 token 选择结果的 overlap rate。三个不同层(5/10/15)的趋势完全一致——Query 越相似,选出来的 critical token 重叠越多。这给了 Selection Cache 设计的直接依据:当连续 Query 相似度高于某阈值 θ,就直接复用上一次的选择结果。论文还给了一个引理证明:当 cos(Q₁, Q₂) > 某临界值时,top-k 选择结果完全相同。
三、TokenSelect 的设计:三件套 + 工程优化
把上面三个观察组合起来,TokenSelect 的设计就很自然了:
- Head Soft Vote:解决 head logits 量级差异问题
- Selection Cache:解决连续 Query 选择重复计算问题
- Paged Dot Product Kernel:解决 paged KV Cache 上 token 级选择的 I/O 瓶颈
整体架构看这张:
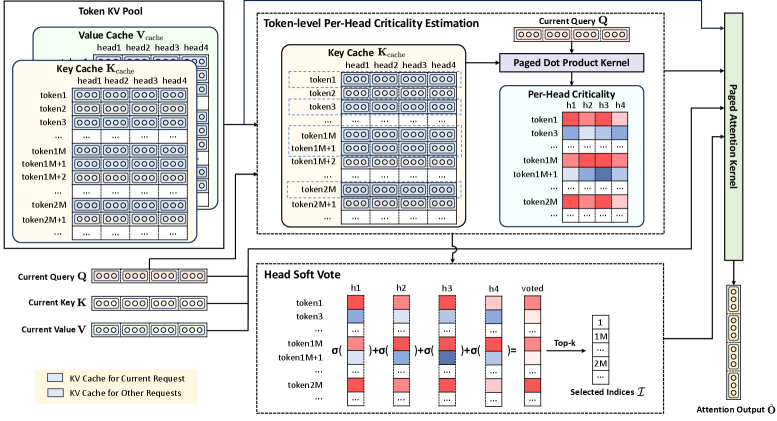
图 4:左边是 token 级 paged KV Cache 池(page size = 1,所以每个 token 独立寻址)。中间橙色框是 Paged Dot Product Kernel,对当前 Query 计算每个 head 在 KV Cache 上的相关度。下方虚线框是 Head Soft Vote——对每个 head 做 softmax 归一化后求和投票,得到 top-k 索引。右边把选中的 KV 喂进 Paged Attention Kernel 完成最终注意力。整个流程的关键是:KV Cache 物理上不动,只传递索引 I——这把 I/O 从 O(2kd) 降到了 O(k),是后面 23.84× 加速的根源之一。
3.1 Head Soft Vote:让每个 head 平等投票
最朴素的选择函数是直接 top-k:
刚才说过,这会被高 norm 的 head 主导。第二个改进是 hard vote——每个 head 各自选 top-k,最后看哪些 token 被最多 head 选中:
但 hard vote 是 0/1 投票,丢失了 token 在每个 head 内部的相对重要性,而且 scatter_add + 多次 topk 在 GPU 上效率很差。最终方案是 head soft vote——每个 head 对 logits 做 softmax 归一化后再求和:
为什么 softmax 是关键?因为 softmax 自带"相对量级归一化"——同一个 head 内部 logits 大小关系保留,但跨 head 的绝对量级被消掉了。这一步的消融数据非常能说明问题(后面表 4 会看到,R.KV 任务从 16.6 拉到 86.6 分)。
3.2 Selection Cache:连续 Query 共享选择结果
Decode 阶段每生成一个 token 就要做一次 selection,这个开销是真的会吃掉收益的。作者基于"连续 Query 相似"的观察设计了 Selection Cache:
Algorithm 1: Selection Cache
输入: 当前 Query Q, 缓存的上一次 Query C_Q, 缓存索引 C_I, 阈值 θ
1. if first_query 或 cos(Q, C_Q) < θ:
2. I ← S(Q, k) # 重新做选择
3. C_I, C_Q ← I, Q # 更新缓存
4. else:
5. I ← C_I # 直接复用
6. return I
逻辑朴素到几乎一行就能讲清楚——但前面那个 lemma 证明给了它理论保险:当相似度超过临界值时,top-k 选择结果一定相同。
Prefill 阶段不用 cache,作者用的是 chunk-wise 选择——把一个 chunk 内 c 个 Query 平均成一个 query,做一次选择,整 chunk 共享结果。这保留了 prefill 的 compute-bound 特性,避免变成 memory-bound。
3.3 Paged Dot Product Kernel:把 I/O 砸到 GPU 极限
这是工程上最值钱的部分。如果你做过 InfLLM 或 QUEST 的实现,会知道一个反直觉的事实——理论复杂度降下来了,实际跑起来一点不快。作者画了一张时间分解图把这事讲透了:
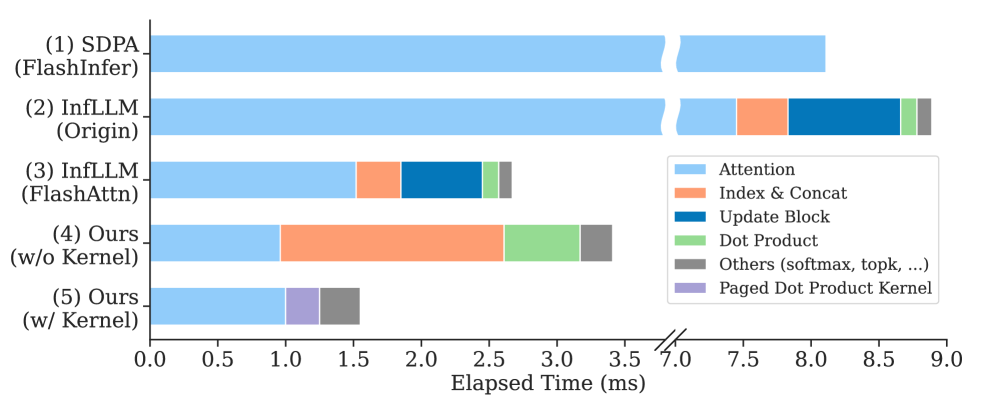
图 5:从上往下看——SDPA 全注意力(FlashInfer)8.1ms,InfLLM 原版 8.9ms 居然比 SDPA 还慢,FlashAttn 版的 InfLLM 降到约 2.7ms。但有意思的是 InfLLM 时间花在哪——蓝色 Update Block 和橙色 Index & Concat 占大头,dot product 本身(绿色)几乎可忽略。问题不是算 dot product 慢,是把选中的 KV Cache token 从 HBM 里拉出来、重新拼成连续内存这一步太重。Ours (w/o Kernel) 在 paged 化之后 Index & Concat 仍占大头;最下面 Ours (w/ Kernel) 把这部分用 Triton 写成专用 Paged Dot Product Kernel 后,整体压到 1.5ms 左右。
讲透这一点:现代 LLM 推理是 memory-bound 的,瓶颈在 GPU 的 HBM↔SRAM I/O,而不是计算。所以 TokenSelect 把 KV Cache 用 page size = 1 的 paged 方式管理后,token 选择只需要传索引(O(k) 的 I/O),不需要把实际的 K/V 数据搬来搬去(O(2kd) 的 I/O)。但即便如此,page size = 1 的逻辑连续 ≠ 物理连续,作者写了一个 Triton kernel 专门处理这种场景,把 dot product 计算和 paged 索引访问融合在一起,进一步把 I/O 降到极限。
这一段的工程意义在哪?它让 H2O / TOVA / SnapKV 这一类依赖历史 attention score 的方法(与 FlashAttention 不兼容)显得很被动。TokenSelect 的设计天然兼容 FlashAttention、Paged Attention、Tensor Parallelism、Prefix Caching 这些主流 serving 优化,论文里说基于 SGLang 实现,可以直接上线。
四、实验:精度上反超原模型,效率上 23.84×
接下来看数据。说实话作者实验做得挺扎实,三个 benchmark + 三个开源模型 + 一堆 baseline + 完整消融,覆盖度够看。
4.1 InfiniteBench 主表
| Methods | En.Sum | En.QA | En.MC | En.Dia | Code.D | Math.F | R.PK | R.Num | R.KV | Avg. |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen2-7B | 23.80 | 14.92 | 54.59 | 8.50 | 28.17 | 19.71 | 28.81 | 28.64 | 19.00 | 25.13 |
| NTK | 18.73 | 15.34 | 41.28 | 7.50 | 24.87 | 27.71 | 99.15 | 97.46 | 59.80 | 43.54 |
| StreamingLLM | 19.60 | 13.61 | 48.03 | 3.50 | 27.92 | 19.43 | 5.08 | 5.08 | 2.40 | 16.07 |
| InfLLM | 19.65 | 15.71 | 46.29 | 7.50 | 27.41 | 24.00 | 70.34 | 72.20 | 5.40 | 32.06 |
| TokenSelect | 22.62 | 18.86 | 54.31 | 7.50 | 30.20 | 21.71 | 100.00 | 100.00 | 86.60 | 49.08 |
| Llama-3-8B | 24.70 | 15.50 | 44.10 | 7.50 | 27.92 | 21.70 | 8.50 | 7.80 | 6.20 | 18.21 |
| InfLLM | 24.30 | 19.50 | 43.70 | 10.50 | 27.41 | 23.70 | 100.00 | 99.00 | 5.00 | 39.23 |
| TokenSelect | 26.99 | 21.32 | 45.85 | 8.00 | 27.41 | 28.29 | 100.00 | 97.29 | 48.40 | 43.90 |
表 1:InfiniteBench 主表(节选 Qwen2-7B 和 Llama-3-8B 部分)。R.KV 这一列是真正能拉开差距的——它要求模型从 128K+ 的上下文里精确 retrieve 一个特定的 UUID 对应的 value。这个任务对 token 级精度极度敏感,InfLLM 的块级选择只能拿到 5%,TokenSelect 在 Qwen2-7B 上拿到 86.60,差距是数量级的。
我读这张表最在意的不是平均分(虽然 49.08 vs 32.06 也很能打),而是 R.KV 这个 token 级 retrieve 任务——它把"块级粗筛"和"token 级精筛"的差距赤裸裸地放出来了。
但有个地方我必须吐槽:Qwen2-7B + TokenSelect 的 R.KV 86.60,到了 Llama-3-8B 上只有 48.40。作者在 limitation 里也提到 Yi-1.5-6B 不能正确背诵 UUID 字符串这种事——说到底 TokenSelect 是 training-free 的,它的天花板被底层模型的能力锁死了。Llama-3-8B 在 R.KV 上的能力本身就比 Qwen2-7B 弱,TokenSelect 救不了它。这个观察我觉得对工程落地很重要:TokenSelect 是放大镜,不是修复器。
4.2 RULER:更难的 benchmark
| Methods | 4K | 8K | 16K | 32K | 64K | 128K | Avg. |
|---|---|---|---|---|---|---|---|
| Llama-3-8B | 93.79 | 90.23 | 0.09 | 0.00 | 0.00 | 0.00 | 30.69 |
| StreamingLLM | 93.68 | 54.48 | 33.77 | 20.35 | 14.88 | 11.47 | 38.11 |
| InfLLM (4K+4K) | 93.79 | 86.11 | 64.33 | 45.39 | 33.13 | 27.81 | 58.43 |
| Ours (2K+512) | 93.73 | 82.92 | 71.92 | 65.38 | 59.35 | 33.39 | 67.78 |
| Ours (4K+4K) | 93.88 | 90.29 | 70.13 | 57.72 | 48.36 | 39.38 | 66.63 |
表 2:RULER 上的 Llama-3-8B 部分。注意原模型从 16K 开始直接归零——这就是位置外推爆掉的典型表现。TokenSelect 用 2K+512 的极小预算就把 128K 拉到 33.39,比原模型的 0 分高出整个量级。
这张表能看到 TokenSelect 的另一个核心价值——长度外推。它不需要任何长文本 post-training,靠 token 级选择 + 复用预训练的位置编码窗口,让 8K 训练的 Llama 能在 128K 上工作。
不过这里有个细节值得注意:4K+4K 在 Llama 上反而比 2K+512 平均分低一点。论文解释是模型上下文长度有限,扩大 token 预算反而带来分布外的位置编码,导致退化。这个观察很反直觉但合理——算的不是越多越好,要看模型能不能 handle 那么长的 attended context。
4.3 跟 post-trained 模型上的方法比
| Methods (on Llama-3-8B-Instruct-262k) | En.QA | En.MC | Code.D | R.PK | R.Num | R.KV |
|---|---|---|---|---|---|---|
| SDPA (262K full attention) | 12.40 | 67.30 | 22.10 | 100.00 | 100.00 | 14.40 |
| InfLLM (2K+512) | 7.00 | 37.00 | 20.50 | 100.00 | 100.00 | 0.50 |
| QUEST (2K+512) | 8.20 | 67.00 | 18.00 | 100.00 | 100.00 | 0.00 |
| MInference | 12.90 | 65.90 | 22.30 | 100.00 | 100.00 | 12.80 |
| Ours (2k+512) | 9.70 | 68.00 | 19.00 | 100.00 | 100.00 | 20.60 |
| Ours on Llama-3-8B, no post-train | 21.32 | 45.85 | 27.41 | 100.00 | 97.29 | 48.40 |
表 3:跟那些必须先做 long-text post-training 才能用的方法比。最后一行有点离谱——TokenSelect 直接跑在原始 Llama-3-8B(8K 上下文)上,En.QA 反而比 post-train 过的 262K 模型 + 各种 baseline 都高。当然 En.MC 比 post-train 模型低不少,作者承认 post-training 和 TokenSelect 是正交的,可以叠加。
最后一行(在原始未 post-train 的 Llama-3-8B 上)的 R.KV 48.40 相比表上 post-train 版本的 0.5/12.8/14.4 等数据,差距大到我第一反应是不是有什么实验设置的差异。但仔细看论文的解释——R.KV 任务的关键是 "fine-grained retrieve",TokenSelect 的 token 级精筛 + head soft vote 在这个任务上确实有结构性优势,而 post-train 模型上的稀疏注意力方法因为粒度粗反而拖累了性能。
4.4 消融:head soft vote 才是真正的胜负手
| Selection Function \(\mathcal{S}\) | En.QA | En.MC | Code.D | R.PK | R.Num | R.KV |
|---|---|---|---|---|---|---|
| \(\mathcal{I}_{\text{topk}}\) | 15.15 | 45.85 | 28.43 | 100.00 | 98.47 | 16.60 |
| \(\mathcal{I}_{\text{head-vote}}\) | 17.01 | 45.85 | 28.68 | 100.00 | 100.00 | 22.40 |
| \(\mathcal{I}_{\text{head-soft-vote}}\) | 18.86 | 54.31 | 30.20 | 100.00 | 100.00 | 86.60 |
表 4:选择函数的消融。R.KV 列从 16.60 → 22.40 → 86.60,head soft vote 的提升幅度大到让人怀疑是不是结果错了。
R.KV 上从 hard vote 的 22.40 一跃到 soft vote 的 86.60,这 64 个点的提升基本上把 head soft vote 推到了"决定性创新"的位置。我的解读是:R.KV 任务里同一个 UUID 的 KV 在不同 head 上重要性差异巨大,hard vote 的 0/1 投票丢了这个信号,soft vote 用 softmax 归一化后能精确表达每个 head 内部的相对重要性,再求和投票就能命中真正关键的 token。
4.5 token 预算的影响
| \(k\) | En.Sum | En.QA | En.MC | Math.F | R.Num | R.KV |
|---|---|---|---|---|---|---|
| 128 | 21.23 | 10.46 | 41.48 | 18.00 | 100.00 | 13.40 |
| 512 | 21.60 | 13.31 | 40.17 | 21.71 | 100.00 | 45.60 |
| 2K | 22.62 | 18.86 | 54.31 | 21.71 | 100.00 | 86.60 |
| 4K | 24.09 | 21.11 | 51.53 | 21.71 | 100.00 | 88.00 |
| 16K | 26.54 | 23.04 | 62.88 | 28.16 | 100.00 | 72.00 |
表 5:选择 k 个 token 时的性能曲线。即使只选 128 个 token,TokenSelect 也能拿到不错的分数(比如 R.Num 100%)。k 增大到 16K 时大部分任务还在涨,但 R.KV 从 88 掉到 72——超过模型熟悉的窗口长度后效果开始反弹。
这个 k=16K 时 R.KV 反而下降的现象很有意思,说明 TokenSelect 的有效工作区间是模型预训练上下文长度内。这也解释了为什么作者把 default 设到 k=2K 而不是更大。
4.6 效率:1M 上下文 23.84× 加速
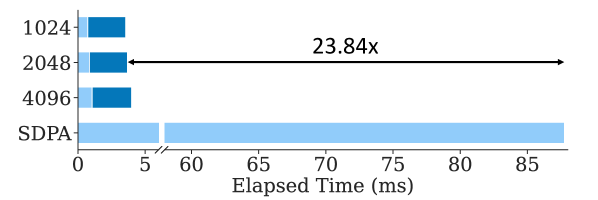
图 7(c):在 1M token 的 KV Cache 上,SDPA 全注意力大约 90ms,TokenSelect 用 2048 token 预算只需要约 4ms——23.84× 加速。注意这是单次 chunk prefill 的 attention 时间,不是端到端。
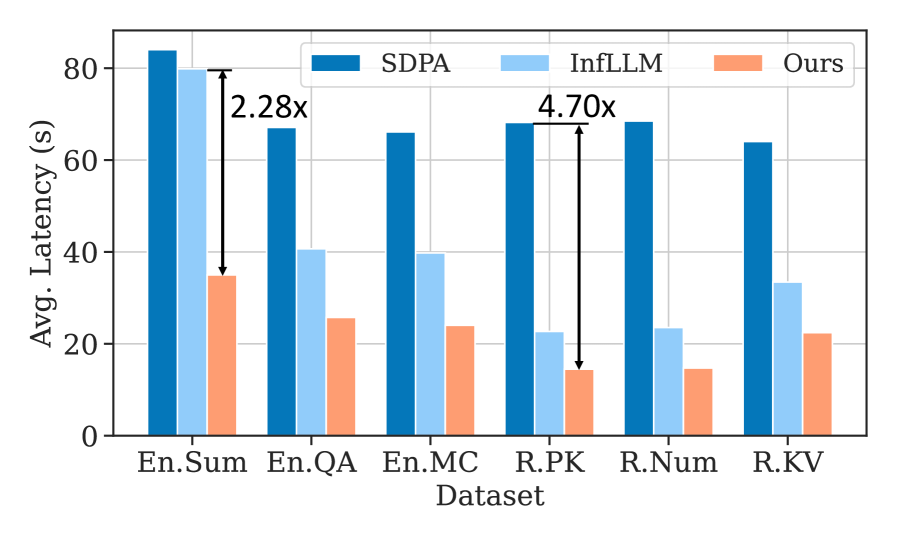
图 8:端到端 latency。在 R.PK 上 TokenSelect 比 SDPA 快 4.70×、比 InfLLM 快约 1.5×。整体看,TokenSelect 在所有任务上端到端 latency 都明显低于 SDPA 和 InfLLM。
4.7 极端长度:2M 上下文还能稳定外推
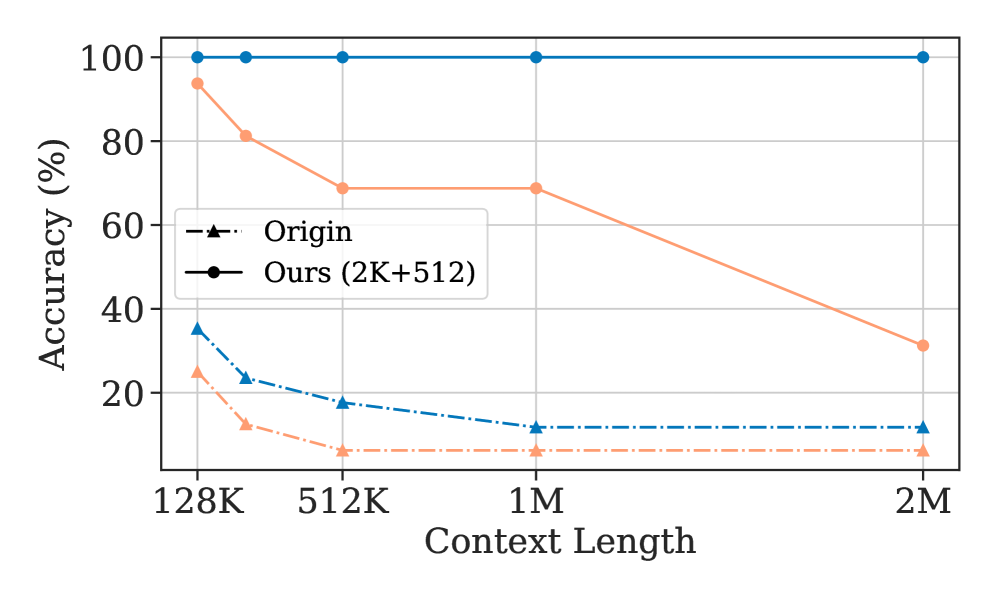
图 9:在扩展到 2M token 的 InfiniteBench 上,TokenSelect (2K+512) 在 R.PK 上一路稳在 100%,R.KV 从 128K 的 90+ 慢慢退化到 2M 的约 30%。原始模型从 128K 开始就基本归零。这张图最有冲击力的是:一个 8K 训练的模型经过 TokenSelect 包装后,在 2M 上下文上仍然能做精确 retrieve。
R.KV 在 2M 上掉到 30% 也算正常——这个任务对 token 级精度要求极高,2M 长度下选 2K token 已经接近极限了。
五、跟同期工作的横向对比
聊到这里,我想帮你把 TokenSelect 在长上下文加速这个生态位上摆一下。
| 方法类别 | 代表方法 | 选择粒度 | Query-aware | 训练 | Flash 兼容 | 长度外推 |
|---|---|---|---|---|---|---|
| 预定义稀疏 | StreamingLLM, LM-Infinite | 全局+局部 | ❌ | ❌ | ✅ | 部分 |
| 历史分数驱逐 | H2O, SnapKV, TOVA | Token | ❌ | ❌ | ❌ | ❌ |
| Block-level Query-aware | InfLLM, QUEST, MInference | Block | ✅ | ❌ | ✅ | ✅ |
| Token-level Query-aware | TokenSelect | Token | ✅ | ❌ | ✅ | ✅ |
| 长文本 post-training | Qwen2-Long, Llama-3-262k | - | - | ✅ | ✅ | ✅ |
表:长上下文推理方法横向对比。TokenSelect 占据的位置是"Token 级 Query-aware + training-free + 工程兼容"这个交集。
H2O 这一派(依赖历史 attention score)的最大问题是与 FlashAttention 不兼容——FlashAttention 为了降 I/O 不会把完整的 attention matrix 写出来。所以 H2O 等方法在工业 serving 系统里基本没法用。论文 Appendix E 里有 H2O 的对比数据:在 Llama-3-8B 上平均分只有 2.1,几乎全军覆没。这不是说 H2O 思路错了,而是它的实现方式跟现代 LLM serving 栈(FlashAttention + Paged KV Cache)从根上不兼容。
InfLLM/QUEST/MInference 都是 query-aware 但 block-level。TokenSelect 把粒度砸到 token 级,同时通过 paged KV (page size=1) 和专用 Triton kernel 让 token 级筛选的工程开销可控。这是它真正的 differentiator。
MInference 这个对比怎么看?
MInference (NeurIPS 2024) 是 Microsoft 的,主打 prefill 加速。论文 Appendix H 给了端到端 prefill latency 对比:
| Length | FlashAttn-2 (vLLM) | MInference (vLLM) | TokenSelect |
|---|---|---|---|
| 50K | 7.717 | 7.540 | 5.712 |
| 100K | 21.731 | 14.081 | 12.088 |
| 128K | 32.863 | 18.827 | 15.920 |
| 200K | OOM | OOM | 26.500 |
| 300K | OOM | OOM | 43.406 |
Appendix H:A100 单卡,Llama-3-8B 上 prefill 延迟。TokenSelect 在 200K/300K 上下文上还能跑,FlashAttn-2 和 MInference 都 OOM 了。
200K 之后 vLLM 的 FlashAttention-2 和 MInference 都 OOM 了,TokenSelect 还能跑——这是 paged KV Cache 管理 + 选择性稀疏带来的额外好处。
六、Selection Cache 阈值怎么调
这块作者花了不少笔墨。Selection Cache 的核心权衡是:降低相似度阈值 θ → 命中率上升 → 速度更快,但可能影响精度。
| \(\theta\) | En.QA | R.PK | R.KV | Avg. |
|---|---|---|---|---|
| 0.5 | 17.83 | 100.00 | 0.20 | 38.69 |
| 0.7 | 18.08 | 100.00 | 4.40 | 39.53 |
| 0.85 | 18.15 | 100.00 | 68.20 | 46.94 |
| 0.9 default | 18.86 | 100.00 | 86.60 | 49.08 |
| 0.95 | 18.54 | 100.00 | 86.20 | 49.05 |
| 1.0 (no cache) | 18.68 | 100.00 | 86.84 | 49.15 |
Appendix I 表 9:Selection Cache 阈值对性能的影响(Qwen2-7B)。R.KV 任务对 θ 极度敏感——θ 从 0.9 降到 0.85,R.KV 从 86.60 直接掉到 68.20。但大部分其他任务对 θ 不敏感。
R.KV 这种 fine-grained retrieve 任务对 selection 的动态性要求最高——每个新 Query 都需要精确选 token,缓存复用就会出问题。其他相对松的任务(如摘要、QA),θ 调到 0.5 都还能保持精度,只是会稍微下降。
工程上的 takeaway:任务对 retrieve 精度要求越高,θ 应该设得越高。论文给的默认 0.9 是一个偏保守的安全值,实际部署时如果你的应用场景允许,可以试试 0.85 来换更高的 cache 命中率。
七、我对这篇论文的判断
聊一下我的整体看法,分褒贬两面。
值得抄的地方
第一,token 级选择的方向选对了。作者用 Recall@1000 这个简单指标把"块级 vs token 级"的差距量化得清清楚楚(图 2b),这件事用一张图说服了我。后续如果你做长上下文加速,"先看选择粒度够不够细"应该是第一个要 check 的事。
第二,head soft vote 是个低调的硬创新。从消融实验看(R.KV 16.60 → 22.40 → 86.60),这个看似简单的"softmax + 求和"步骤是性能提升的最大单点贡献。把多 head 的话语权用 softmax 归一化后再投票 这个 trick 我觉得在很多需要"多头共识"的场景都能复用。
第三,工程实现完整且可上线。基于 SGLang 实现、与 FlashAttention/Paged KV/Tensor Parallelism 兼容、Triton kernel 优化到位。这是绝大多数学术论文做不到的——很多 token 选择方法(如 H2O)方法上很优雅,但实现上跟现代 serving 栈不兼容,落地难度极大。TokenSelect 反过来——idea 不算颠覆,但工程上拧得极紧。
我觉得需要打折的地方
第一,R.KV 的极致提升可能有点选择性 sampling 的味道。InfiniteBench 里 R.KV 是 token 级 retrieve 任务,TokenSelect 的 token 级选择天然适配。表 1 平均分 49.08 看起来很惊艳,但去掉 R.KV 这一列,TokenSelect 跟 InfLLM 在很多任务上的差距会缩小很多。摘要类(En.Sum)、对话(En.Dia)、Math.F 上 TokenSelect 并没有显著优势。这不是说论文方法不行,而是它的精度优势主要在 fine-grained retrieve 任务上。
第二,性能受底层 LLM 能力锁死。Yi-1.5-6B 在 R.KV 上的 0% 分(不能正确复述 UUID),TokenSelect 也救不了。这个方法是"放大镜"——好模型用了更好,但弱模型上不能凭空变强。Limitation 里作者也承认这一点。
第三,与 long-context post-training 的关系作者讲得有点保守。论文说"orthogonal",但实际上 long-context post-training 后的模型本身对长 attention 有更好的归纳偏置,TokenSelect 的"选 k 个最重要的 token"这个动作可能就不是最优策略了。从表 3 看,post-train 过的 262K 模型用 TokenSelect 反而比直接用 SDPA 在某些任务上下降(En.MC 从 67.30 降到 68.00,差不多平;En.QA 从 12.40 降到 9.70,下降)。所以"叠加 post-training" 不一定 1+1>2。
第四,对比的 baseline 主要是 H2O/InfLLM/QUEST/MInference。这些都是 2024 上半年的工作。同期还有 SparQ、ShadowKV、RetrievalAttention 等,论文表 3 提到了 RetrievalAttention 但只在小范围对比。如果跟 ShadowKV 等同期方法做更全面的对比会更有说服力。
这篇论文对工程的启发
如果你正在做长上下文 LLM serving,我会推荐你重点看这三件事:
- 检查你的稀疏注意力方案的选择粒度——块级还是 token 级。如果是块级,可以试试参考 TokenSelect 的 paged KV (page size=1) + Triton kernel 实现,把粒度砸到 token 级;
- 如果用了 multi-head 投票机制,确保用 softmax 归一化,不要直接 concat logits 做 top-k。这是个很容易踩的坑;
- 如果你的应用场景有连续相似 Query(比如多轮对话、长文档逐段问答),可以考虑加一个 Selection Cache 之类的复用机制,但要根据任务对 retrieve 精度的敏感度调阈值。
八、收尾
长上下文这块其实卷得很——Qwen3 的官方版本已经是 128K 起步,Llama-4 的多模态版本支持 1M+,Gemini 2.5 Pro 支持 2M。在这种背景下,"如何在已有模型上以较低成本实现长上下文推理"会越来越重要——毕竟不是每个团队都能负担长文本 post-training。
TokenSelect 给的答案是 training-free 的,工程友好的,能把 8K 模型外推到 1M+ 还保持基本可用的精度。它不是底层突破——token 级稀疏选择这个想法不新,但作者把"为什么块级不行 → token 级可行 → 工程上怎么实现"这条链条扎扎实实串起来了。
最后留个开放问题:当原模型本身就是 1M context 训练出来的(如未来的 Qwen3-1M),这种 training-free token 选择还有多大价值? 我猜会变成"在原模型基础上进一步降低推理成本"的角色,而不再是"突破长度限制"的角色。但 23.84× 的 attention 加速,不管在哪种场景下都很值钱。
代码:作者论文里没贴明确的 GitHub 链接,但提到基于 SGLang 实现,等正式开源的话工业落地应该会很方便。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我