Think-Search-Patch:让 7B-14B 模型把仓库级 bug 修出 GPT-4 三倍的命中率
修真实仓库里的 issue,跟刷 HumanEval 完全是两件事。
issue 通常跨文件、绕隐式调用链,关键代码就埋在几百行无关上下文里。文件级 RAG 一把梭把整页代码捞进窗口,模型看不出"问题在哪一行",更多时候是改错了位置。
EMNLP 2025 Industry Track 上天津大学 TJUNLP 联合小红书的 Think-Search-Patch(TSP) 给出的解法挺干脆:把修复过程拆成 Think → Search → Patch 一条三段流水线,索引粒度从文件砸到类/函数级,再用 SFT + 拒绝采样纠错的 DPO 把中间过程的低级错误磨平。
数字直白:TSP-Qwen2.5-Coder-14B 在 SWE-bench Lite 上跑到 8.33% 官方通过率,GPT-4(1106) 配文件级 RAG 只有 2.67%——绝对值依然不高(SWE-bench 本来就硬),但同表里 同一骨干 Qwen2.5-Coder-7B Instruct 从 0% 拉到 5%,这条对比说明工艺路线本身就有区分度。
这篇论文到底在解什么?
一句话:让中等体量代码模型在仓库级 bug 修复上"先搜对、再改对"。
作者把 SWE-bench 暴露的痛点归成两条——任务复杂度高(要同时做语义理解、缺陷定位、补丁生成)、上下文超长(关键片段被无关代码淹没)。窗口再大也救不了,噪声不变只是看得更累。
TSP 不发明新范式,而是把"检索增强"嵌进推理链:Think 阶段写 issue 分析、任务拆解、检索 query;Search 用 E5 在结构化索引里召回类/函数级片段;Patch 只在召回的小片段里定位与编辑。训练上分两阶段 SFT,再用 GPT-4o 当裁判做拒绝采样构造偏好对跑 DPO,并对检索进来的 token 做 loss mask——避免模型把外部代码"背"进权重。
我的判断:这不是底层突破,是把"细粒度索引 + 过程奖励对齐"两件被前人各做一半的事钉到同一张实验表里的扎实工程方案,对部署 7B/14B 代码 Agent 的团队是直接可抄的施工图。
论文信息
- 标题:Think-Search-Patch: A Retrieval-Augmented Reasoning Framework for Repository-Level Code Repair
- 作者:Bojian Xiong, Yikun Lei, Xikai Liu, Shaowei Zhang, Pengyun Zhu, Yan Liu, Yongqi Leng, Ling Shi, Meizhi Zhong, Yurong Zhang, Yan Gao, Yi Wu, Yao Hu, Deyi Xiong(通讯)
- 机构:天津大学 TJUNLP Lab + 小红书
- 会议:EMNLP 2025 Industry Track(pp. 1555–1566)
- 链接:ACL Anthology · 代码:
github.com/tjunlp-lab/TSP-framework - arXiv:未挂预印本,事实以 Anthology PDF 与开源仓库为准
三段流水线:把"先想再搜再改"写成可监督的轨迹
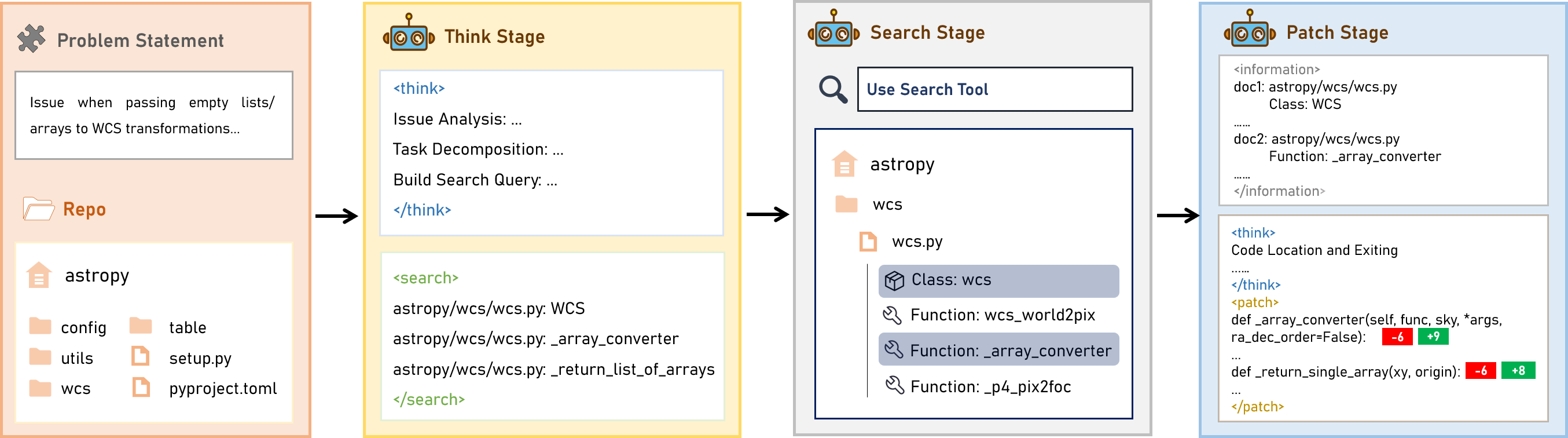
图 1:左侧 issue + 仓库树进入 Think 阶段;中间 Search 用工具在 wcs.py 等路径下命中类/函数;右侧 Patch 结合召回生成结构化补丁。
跟传统"一把梭文件级 RAG"对比,TSP 的关键转变是把 检索 query 的质量 前置成一等公民——后面搜得好不好,前面 Think 阶段就要写得够具体。
Search 阶段实现并不神秘:用 E5 文本嵌入做向量检索,按相似度从索引里捞候选。但真正决定召回质量的是 query:Think 把"症状描述"翻译成"该去哪个类、哪个函数附近找线索"之后,E5 才有机会把候选收窄到几个结构化单元,而不是大段文件文本墙。
索引粒度:用 AST 把文件砸成类/函数
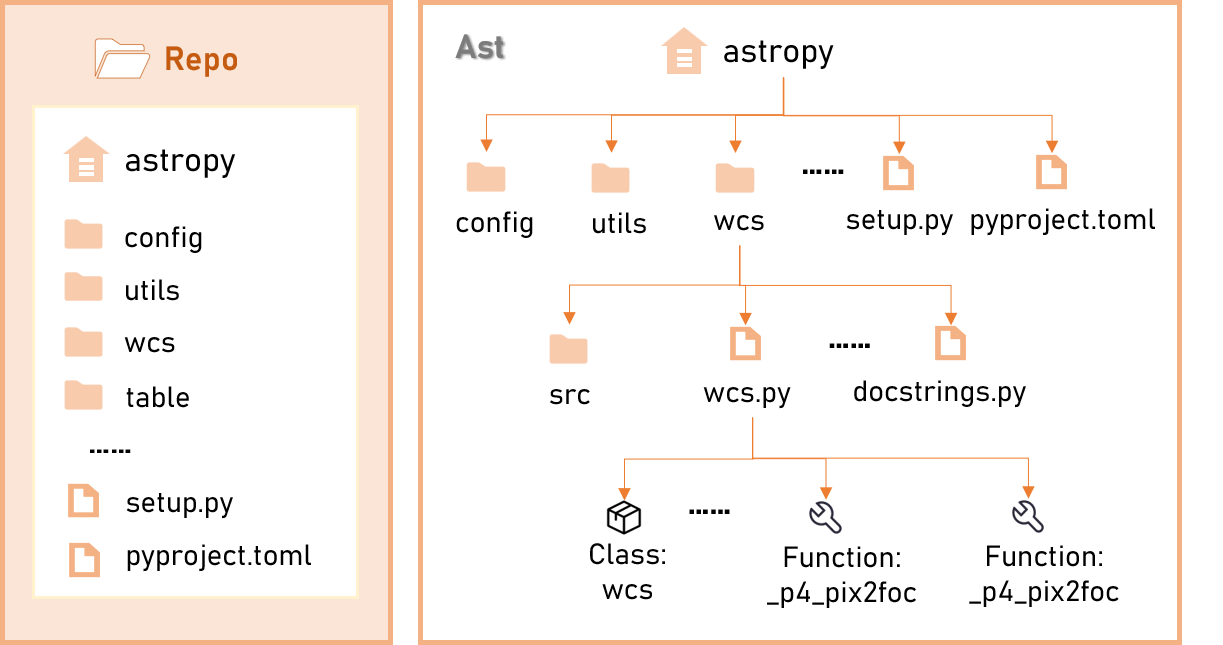
图 2:左侧仓库目录视图,右侧把 wcs.py 用 Python ast 解析后展开到类/函数节点。
入库前用 Python ast 解析,抽出 Class / Function 节点,连同路径与行号写成 path/to/file.py:Class 这种 可定位标识。检索单元变细,同一次命中夹带的废话就少。
论文报告:相对文件级 RAG,召回上下文的平均长度下降约 78%——具体到 token 预算:
| 检索方法 | 召回代码 token(Table 1) |
|---|---|
| 文件级 RAG | 16933.77 |
| TSP framework | 3724.56 |
这不是玄学压缩。检索单元换成结构化 AST 节点之后,"针在哪根稻草上"就比"针在哪堆稻草里"好回答太多。
TSP 数据集:把"过程"写进训练信号
数据来源沿用 SWE-Fixer 那条线:去掉 issue 含图片外链/外部文档的样本,再删掉描述太含糊指不到代码实体的样本。然后用 Qwen-Max 给每条样本生成检索 query,从 Oracle 文件里抽对应片段。
最终构建了 约 6 万条 TSP 样本。
里头一个挺工业的细节:作者拿出大约 5% 子集另外搭 E5 向量索引做 top-2 命中率自查,平均能到 约 80%——用这个回路反过来清洗 prompt 与数据。
说实话,这种"定期抽检检索 query 是否靠谱"的闭环放真实业务里就是质检线。论文的特别之处在于把它写进数据迭代流程,而不是丢给运维。
训练:分阶段 SFT + 纠错型 DPO
Stage-1:分阶段 SFT
不是一锅炖。先专门练 检索 query 的写作(只看 issue,不允许偷看 Oracle 答案),再练 给定召回后的补丁生成(输入里拼接 issue 分析 + 检索过程 + 召回片段)。
工程上用 Verl 跑 SFT,OpenRLHF 跑 DPO,硬件 16× NVIDIA H800。
Stage-2:纠错型 DPO
让 Stage-1 模型先 rollout 一批轨迹,里面自然夹杂着 query 含糊、定位跑偏等错误。再用 GPT-4o 当 LLM-judge 从三个维度打分与改写:检索 query 是否召回关键片段 / 中间推理是否自洽 / 编辑位置是否精确。
合格的纠偏轨迹当正例 \(y_w\),未修正的失败轨迹当负例 \(y_l\),喂给 DPO。
DPO 损失沿用 Rafailov 的形式化框架,对比偏好对在策略 \(\pi_\theta\) 与参考模型 \(\pi_{\mathrm{ref}}\) 之间拉大正负轨迹的对数几率差:
关键不是公式本身。关键在于:TSP 把中间检索与定位也纳进偏好学习,不只奖励最终补丁是否过 CI——这跟单纯 outcome-only 的 RL 信号是两件事。
为了把成本压下来,第二阶段还做了索引复用:同一仓库同一版本共用索引,采样 近 4000 条偏好对只构建 约 200 套 索引。
检索 token 的 loss mask
这个细节挺关键。流水线把外部代码片段拼进上下文之后,如果让它一起算 loss,模型会偷偷学到"背诵外部上下文"的奇怪动力学。
作者显式把检索片段从策略梯度里 mask 掉。听起来像枯燥的实现细节——上线玩过 RAG 微调的应该都懂:外部证据可以看,但不该被当成要复述的标签。
实验:怎么读这些数字
双轨评测
主线还是 SWE-bench Lite 300 例的官方 docker 跑测——单测全绿才记 1。论文不讳言这标准极度苛刻,小幅语义改进也可能记 0。
因此作者并行引入 LLM-judge 三维打分(0–100):上下文相关性、位置准确性、修复有效性。两条轨道一起看,才不至于把"没过测"和"完全胡写"混为一谈。
附录里还有个反向校验:从 TSP-Qwen2.5-Coder-7B 的输出里抽 100 条样本,让 5 名有软件工程背景的研究生与 GPT-4o 并行打分。这不是为了"证明裁判永远正确",而是回应一个现实质疑——LLM-judge 会不会自嗨。
主结果(Table 2 节选)
| 方法 | 模型 | LLM-judge | Pass rate (%) |
|---|---|---|---|
| RAG | SWE-Llama-7B | 27.5 | 1.3 |
| RAG | GPT-4 (1106) | — | 2.67 |
| RAG | Claude 3 Opus | — | 4.33 |
| RAG | Qwen2.5-Coder-7B-Instruct | 22.4 | 0 |
| RAG | Qwen2.5-Coder-14B-Instruct | 30.1 | 0.33 |
| TSP | TSP-Qwen2.5-Coder-7B | 48.1 | 5.0 |
| TSP | TSP-Qwen2.5-Coder-14B | 55.6 | 8.33 |
| TSP | TSP-deepseek-coder-6.7b | 40.1 | 4.33 |
| TSP | TSP-Mistral-7B | 40.5 | 3.33 |
这张表最值得盯的不是"小模型把大模型干翻"这种标题党。
值得盯的是:同一骨干 Qwen2.5-Coder-7B Instruct 在 RAG 配方下 Pass rate 是 0;换成 TSP 训练之后拉到 5.0%,LLM-judge 从 22.4 涨到 48.1。
如果瓶颈只在"模型不够大",同一骨干不该在两种训练配方之间差出整整一档。论文真正在说服人的是 流程与训练信号占了大头。
Search ACC:把"会搜"和"会改"拆开
| 模型 | Search ACC(命中目标函数/类) |
|---|---|
| Qwen2.5-Coder-7B-Instruct | 24.0 |
| Qwen2.5-Coder-14B-Instruct | 28.7 |
| deepseek-coder-6.7b-instruct | 25.1 |
| Mistral-7B-Instruct-v0.3 | 19.5 |
| TSP-Qwen2.5-Coder-7B | 50.7 |
| TSP-Qwen2.5-Coder-14B | 64.8 |
| TSP-deepseek-coder-6.7b | 40.1 |
| TSP-Mistral-7B | 38.6 |
这张表把 Pass rate 和检索精度解耦。SWE-Llama 在另一组实验里检索精度甚至直接是 0——不是模型坏,是训练目标过度偏向补丁生成、检索端过拟合到失效。TSP 把"检索"和"打补丁"放进两阶段独立训练之后,至少指标上把这两件事分开了。
消融(Figure 3)
| 设置(Qwen2.5-Coder-7B 系列) | Pass rate (%) | LLM-judge |
|---|---|---|
| Qwen2.5-Coder-7B-Instruct 基线 | 0.00 | 22.4 |
| 仅 Stage-1 SFT | 3.33 | 42.5 |
| Stage-2 DPO(去掉位置增强数据) | 4.33 | 44.6 |
| 完整 Stage-2 DPO | 5.00 | 48.1 |
涨幅不来自玄学超参。从 3.33 爬到 5.00 那一截靠的是 偏好数据是否覆盖了"定位错误"这类典型失败——把"找准编辑锚点"专门构造一批样本进去,模型才学得到。
哪些地方值得皱眉
SWE-bench 官方通过率依然是个位数。这不是 TSP 一家的问题,但读者若抱着"上线就能全自动修库"的期望会失望。
LLM-judge 与 GPT-4o 裁判带来额外成本与潜在偏见。三维打分再细致也不等于人类 PR review,附录里那 100 条人工对照只能算对冲,工业落地还得加规则兜底。
作者的 Limitations 写得坦白:流水线相比 Agent 多轮工具调用,复杂跨文档推理仍吃亏,未来或许要往"按任务复杂度动态扩展 Think-Search-Patch"的混合方向走。
这其实回到当下工业界的主流争论:先把固定管线打磨到极致,还是直接把决策权交给更重的交互式 Agent。TSP 选了前者,把 7B-14B 这档体量上的下限抬到一个能用的位置。
你能直接抄走的几条
要是你正在搭内部 Coding Agent,TSP 这篇可以当一张 checklist:
- 索引不要停在文件级:类/函数节点 + 稳定 locator(路径:符号)比整文件向量检索省 token、不易误导 Patch
- 训练数据要像流水线脚本一样分阶段:先单独把"写检索 query"训稳,再训"带证据改代码"
- 偏好数据别只盯最终补丁:中间 query 烂、位置错了,后面再怎么生成也是对空气输出。DPO 在这里是"纠偏中间态"
- RAG 微调记得 mask 外部证据:否则模型会学会复述检索块,而不是 使用 检索块
再补几条丑话:
- 检索模型不是摆设——换嵌入模型,索引、query、tokenizer、代码切分都得一起重对齐
- DPO 数据别全靠自动化——GPT-4o 裁判贵且有标签偏移风险,工业场景往往要叠一层"必须命中 golden 符号"之类的硬规则
- Pass rate 低不等于系统无用——SWE-bench 严格对齐单测全绿,但现实 CI 允许 PR 先开到"可讨论"状态。LLM-judge 三维分反而更接近"哪些样本值得人工接力"的排序指标
收尾
Think-Search-Patch 不是把 SWE-bench 刷爆的魔法。它是一份把检索增强真正写进推理链路与训练信号的工业配方:细粒度索引负责瘦身上下文,分阶段 SFT + 纠错型 DPO 负责把过程错误压下去。
如果你的痛点是 7B/14B 级别模型在仓库级任务上"搜不准、改不对",附录里的 prompt 模板和数据构造细节值得逐字读。
如果你要的是 几步就能啃下跨仓大规模重构——这篇自己也承认还不是那条路上的终极答案。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我