部署即固化的Agent,怎么在线学新规则?ARIA给了一个能落地的答案
核心摘要
合规这种业务有个让人头疼的特点:规则三天两头变。今天监管刚加了一个新国家的制裁名单,明天又调整了 PEP(政治敏感人物)的 DOB 容忍策略——你训练好的模型部署上线那天起就是过时的。常见解法要么是定期拉新数据回炉做 SFT,要么把所有规则塞进 prompt 让模型现读,要么干脆全交给人工审。三个方案各有各的别扭。
NUS 联合 ByteDance 的这篇 EMNLP 2025 Industry track 论文给了第四种解法:让 Agent 自己识别"我对这个 case 没把握"、主动找人类专家提问、把答案吸收进一个带时间戳的知识库、还能自动检测新规则跟旧规则的冲突并标记过期。框架叫 ARIA(Adaptive Reflective Interactive Agent),已经在 TikTok Pay 1.5 亿月活的客户尽职调查(CDD)任务上跑起来了。在 11,846 个真实名单筛查案例上,ARIA + GPT-4o 在 B=1000 query 预算下做到了 Sensitivity 0.8910 / Specificity 0.8026,明显甩开 Reflexion、Self-Refine 等纯自我反思的方案。
我的判断:这不是一篇底层算法突破的论文,是一篇把"自反思 + Active Learning + 知识库版本管理"三件事缝合在一起、并且真的扛住了真实业务流量考验的工业整合论文。值得读,因为它给了你一个「部署后还能学」的 Agent 应该长什么样的完整工程参考。
论文信息
- 标题:Enabling Self-Improving Agents to Learn at Test Time With Human-In-The-Loop Guidance
- 作者:Yufei He, Ruoyu Li, Alex Chen, Yue Liu, Yulin Chen, Yuan Sui, Cheng Chen, Yi Zhu, Luca Luo, Frank Yang, Bryan Hooi
- 机构:National University of Singapore(1, 4, 5, 6, 11)、ByteDance Inc.(2, 3, 7, 8, 9, 10)
- arXiv:2507.17131
- 会议:EMNLP 2025 Industry Track
- 代码:github.com/yf-he/aria
为什么这个问题值得做
我之前在做风控相关项目的时候,被一类问题反复折磨过:模型上线那一刻就开始过时。
风控也好、合规也好、内容审核也好,规则不是写完就完事的。监管加新名单、新增一类绕过手段、内部策略组调整阈值,每周都在发生。你 base 在大模型上做了一套 RAG,知识库前一天还很准,今天突然遇到 KYC 新政策——模型根本不知道这条新规存在,要么瞎判,要么按老规矩判,给业务方各种 false negative。
工业界对这类问题,传统解法基本是这三种,每种都不让人爽:
| 方案 | 优点 | 痛点 |
|---|---|---|
| 离线 SFT / Offline Fine-tuning | 模型权重确实学到了 | 拉数据→标注→训练→部署一整个 cycle,新规则发布到生效要好几天甚至更长 |
| 大 prompt 塞规则 / Static RAG | 部署快 | 规则一多 context 撑不住,规则之间冲突时模型也不会主动求助;而且新规则灌进去还得人手 dedup |
| 纯人工审 | 准 | 慢,TikTok Pay 这种场景一个 case 平均 12 分钟,月活 1.5 亿的体量根本扛不住 |
ARIA 想做的事情,说到底就是把第二种的"低延迟"和第三种的"准"结合起来:让 Agent 自己有意识地知道哪几个 case 需要去问人,问完了把这条新知识规整地存下来,下次再遇到类似情况就不用再问了。听起来像 Active Learning?是 Active Learning 的延伸——但加了几样东西:自我反思来决定何时问、知识库带时间戳和冲突检测、面对模糊回答主动反问澄清。
这就是这篇论文最值钱的角度:它不是在某个 reasoning benchmark 上多刷了几个点,而是在解决一个真实工业部署里"知识漂移"的问题。
ARIA 的整体架构:一句话讲完
ARIA 处理一个流式输入 \(x_1, x_2, \dots, x_N\),每个 case 都跑一遍如下流程:
- 初步判断:基于当前的知识库 \(\texttt{KR}_i\) 和 LLM 给出预判 \(\hat{y}_i\) 和推理 \(r_i\);
- 自我评估(IGS):自问自答几个反思问题,输出置信度 \(\text{conf}_i\) 和识别出的知识缺口;
- 决策:低置信度且预算 \(B\) 没用完 → 找专家提问;
- 知识吸收(HGKA):把专家答复结构化进 \(\texttt{KR}_{i+1}\),检测跟旧条目的冲突,必要时回头再问澄清。
下面这张图就是整个框架的可视化——左边是 IGS 的自我反思过程,右边是 HGKA 把人类反馈整合进知识库的过程。
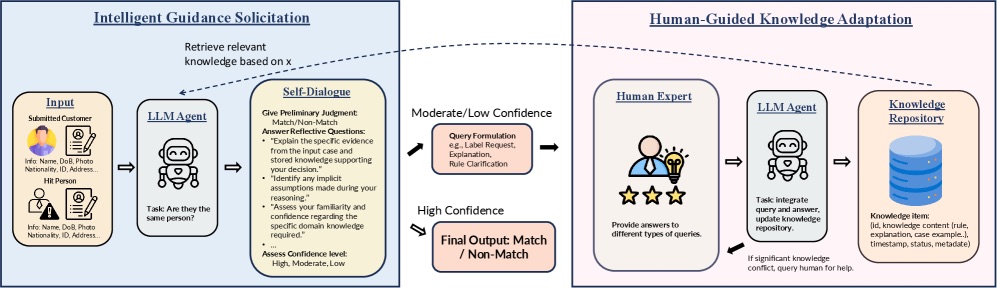
图1:ARIA 框架总览。左侧蓝框是 Intelligent Guidance Solicitation——LLM Agent 给出 Match/Non-Match 的初步判断后,通过 Self-Dialogue 回答"支持你判断的具体证据是什么""做了哪些隐含假设""你对相关领域知识有多熟悉""跟过去类似 case 的推理是否一致"等反思问题,自评出 High/Moderate/Low 三档置信度。中间置信度低的会触发 Query Formulation;右侧粉框是 Human-Guided Knowledge Adaptation——专家答复回来后,LLM Agent 整合进 Knowledge Repository,知识项含 id、内容(rule/explanation/case example)、timestamp、status、metadata 五个字段,遇到冲突会反向再问一次澄清
我读到这个图的时候,第一反应其实有点淡定——这种"模型自我反思 + 人类在回路"的架构图,过去两年看了不下二十种。真正决定 ARIA 能不能 work 的,是这两个模块各自的细节怎么落地。下面拆开看。
模块一:Intelligent Guidance Solicitation——什么时候应该问人?
很多 Active Learning 的方案在"何时 query"这个决策上很粗糙,要么按 logits 算个置信度阈值,要么用 entropy 排序选 top-K。这两种在传统判别模型上还行,对 LLM Agent 就有点尴尬:LLM 输出的 token 概率经常严重过拟合(自信地胡说八道),用 confidence threshold 卡得很容易漏掉真正该问的。
ARIA 的做法是把"评估自己"这件事,从一个标量阈值变成一段结构化的内部对话。Agent 给完初步判断 \(\hat{y}_i\) 之后,会被迫回答这几类问题(论文 Appendix A.2 给了完整列表,我挑几个有代表性的):
- 支持你判断的具体证据是哪些?输入里有没有冲突的指示?
- 你做了哪些隐含假设?这些假设在当前 case 里成立吗?
- 关于这个 case 需要的领域知识(比如"我熟悉公司关于可接受 DOB 差异的政策吗?关于中文人名变体的匹配规则我清楚吗?"),你的熟悉度是 High / Moderate / Low?
- 跟过去类似的案例对比,你的推理一致吗?
- 你检索到的知识库条目是 recently validated 还是 PotentiallyOutdated?
读到这块的时候我皱了一下眉——这些问题说到底还是让 LLM 自己评估自己。LLM 自我评估靠不靠谱本身就是个开放问题。但 ARIA 这套做法跟单纯的 confidence prompt 不一样的地方在于:它把"我不确定"具体化成"我哪里不确定"。一个回答"Moderate confidence with specific uncertainties: I lack certainty regarding the current policy on handling missing nationality information"的 Agent,跟一个只输出"confidence = 0.6"的 Agent,给出的是完全不同质量的信号——前者直接告诉你接下来该问什么。
论文 Appendix B.1 有一个非常具体的例子。User "Li Xiaoming" DOB 1985-03-12,Watchlist 命中 "Li Xiao Ming" DOB 1985-03-12 但国籍未知。Agent 给出 True Match 的初判,但在 self-dialogue 里坦白:「我熟悉空格忽略规则,但缺乏关于"watchlist 国籍缺失对 match 信心的影响"的明确规则。这块我的置信度只有 Moderate」。Agent 自己暴露了知识漏洞,反过来直接形成了对人类专家的具体提问。这一段我觉得是整个 IGS 模块设计上最漂亮的地方——它把不确定性从一个数字变成了一段可以直接追问的文本。
不过坦率讲,这套机制的天花板取决于 base LLM 自我反思的质量。GPT-4o 还行,Qwen2.5-7B 这一档模型做这种五问五答的内部对话,效果未必稳。论文 Table 1 也确实显示了这一点:ARIA + Qwen2.5-7B 的提升幅度比 ARIA + GPT-4o 小一档。
模块二:Human-Guided Knowledge Adaptation——怎么管这本越来越厚的笔记?
如果 IGS 解决"何时问",HGKA 解决的是"问完了怎么存"。这块才是 ARIA 跟普通 Active Learning 拉开差距的核心。
知识库 \(\texttt{KR}\) 里每个条目都是一个结构化对象,最关键的是几个字段:
- kid:唯一 ID
- K:知识内容(规则、解释、案例示例)
- ts_added / ts_validated:添加时间和最近一次验证时间
- S:状态,三档枚举 { Valid, PotentiallyOutdated, Superseded }
- M_meta:元数据(来源、被谁取代等)
新知识进来的时候,HGKA 跑一套冲突检测和状态更新:
- 语义检索:用 embedding 在 \(\texttt{KR}\) 里找到跟新知识 \(K_{\text{new}}\) 相关的旧条目集合 \(\texttt{KR}_{\text{rel}} = \{k \mid \text{Sim}(K_{\text{new}}, k.K) > \tau_{\text{sim}}\}\)
- LLM 比较:对每个 \(k_{\text{old}} \in \texttt{KR}_{\text{rel}}\),让 LLM 判断 \(K_{\text{new}}\) 与 \(k_{\text{old}}.K\) 是 contradicts / supersedes / updates / consistent 中的哪一种
- 状态迁移:
- 如果 supersedes:\(k_{\text{old}}.S \leftarrow \texttt{Superseded}\),记录被谁取代
- 如果 conflicts but ambiguous:\(k_{\text{old}}.S \leftarrow \texttt{PotentiallyOutdated}\)
- 澄清反问:如果新规则模棱两可(比如"对常见姓名允许 pinyin 变体"——这条到底替代了"必须精确匹配"还是只是个例外?),HGKA 主动生成 query 再问一次专家
Appendix B.2 那个例子很有意思。原来知识库里有 Rule_045(2025-04-10):"中文姓名必须 exact pinyin match"。专家 2025-05-05 给的新指示是 Rule_123:"对中文姓名,minor pinyin variations 比如 Zhang vs Zang 在其他识别因素匹配的情况下可接受,不再严格要求 exact match"。HGKA 检索到 Rule_045,用 LLM 比较后判定 supersedes,把 Rule_045 标记为 Superseded by Rule_123,并把 ts_validated 更新到当前时间。下次再有 case 检索到 Rule_045 的时候,因为 status = Superseded,权重直接降为 0,不会再误用。
读到这块我有个明显的体感:这个设计其实就是把软件工程里的版本控制思路搬到了知识库。带时间戳的 entry、状态机迁移、依赖关系的 superseded_by 链——很像 git 的 commit history。我以前自己做 RAG 的时候,最痛的就是知识库灌了一年之后,里面同一个事实有三五条措辞略有差异的条目,模型检索回来一锅炖,给出一个似是而非的答案。ARIA 这套机制如果工程上做扎实了,可以从根本上把这个问题解掉。
但问题也很明显:LLM 来做 contradicts/supersedes/consistent 的判断本身就不是 100% 可靠的。你给两条 PEP DOB 政策,LLM 可能判错关系,导致旧规则没被正确标 Superseded,新旧规则同时 active,下次检索的时候模型懵了。论文消融实验里 w/o KR Conflict Resolution 的版本性能下降明显(B=100 时 Sensitivity 从 0.8333 掉到 0.8012),但反过来想,这也说明这个模块本身就是误差源之一。
时间感知的知识检索:让"过期但没删"的条目权重自然降下来
光有 status 标记还不够。一个有 1000 条规则的知识库,里面可能有 30 条 PotentiallyOutdated 的,其中很多其实大部分场景下还能用——直接 0 权重也不合适。
ARIA 用一个三因子相乘的检索打分:
其中:
- \(W_S\):状态权重,Valid 是 1.0,PotentiallyOutdated 是某个 \(w_{\text{po}} \in (0, 1)\),Superseded 直接 0
- \(S_T = \exp(-\lambda \cdot (t_{\text{current}} - k.ts_{\text{validated}}))\):指数衰减的时效性分数,越久没被验证过的越低
- \(S_R\):经典的语义相关度
三者相乘,意味着任何一个因子拉胯,整体就拉胯。Superseded 直接归零,老掉牙的 Valid 条目时效分会衰减,跟当前 case 不相关的高时效条目语义分会低。这种乘性结构在工程上其实是个挺保守的设计——没人会因为一个高 status 高 recency 的条目压过当前最相关的内容而出问题。
工程上更值得注意的细节:\(\lambda\) 是个超参,调小了过期规则压不下去,调大了刚验证过几天的规则就被当成老古董。论文没给具体数值,估计要按业务节奏调。
实验:哪些数能站住脚
TikTok Pay 真实数据(核心战场)
数据集:11,846 个按时间序处理的真实 CDD 名单筛查 case,正样本(Match)只有 156 个,极度不平衡。指标:Sensitivity(正例召回)和 Specificity(负例正确率)。
| 方法 | 模型 | Sens. (B=100) | Sens. (B=1000) | Spec. (B=100) | Spec. (B=1000) |
|---|---|---|---|---|---|
| Static Agent | GPT-4o | 0.7051 | 0.7051 | 0.6539 | 0.6539 |
| Offline Fine-tuning | Qwen2.5-7B | 0.6603 | 0.6987 | 0.6492 | 0.6791 |
| RAG Agent | GPT-4o | 0.8013 | 0.8333 | 0.7051 | 0.7462 |
| Self-Refine | GPT-4o | 0.7244 | — | 0.6821 | — |
| Reflexion | GPT-4o | 0.7692 | — | 0.6902 | — |
| Multi-Agent Debate | GPT-4o | 0.7628 | — | 0.6970 | — |
| Random Querying | GPT-4o | 0.7949 | 0.8590 | 0.6994 | 0.7667 |
| Simple Uncertainty | GPT-4o | 0.8013 | 0.8718 | 0.7218 | 0.7853 |
| ARIA | Qwen2.5-7B | 0.7756 | 0.8397 | 0.7154 | 0.7795 |
| ARIA | GPT-4o | 0.8333 | 0.8910 | 0.7423 | 0.8026 |
我盯着这张表看了几遍,几个观察:
第一,ARIA 跟 Simple Uncertainty 之间的差距,可能比表面看起来重要。 B=1000 下,ARIA 比 Simple Uncertainty 高 1.92 个 Sensitivity 点和 1.73 个 Specificity 点。听起来不大?但要意识到 Simple Uncertainty 已经是个挺强的 active learning baseline 了。能在它头上再加近 2 个点,说明结构化 self-dialogue + 知识库版本管理这套组合拳确实拉开了一档。
第二,Reflexion / Self-Refine 这类纯自反思方法在这个任务上其实没太多优势。 Reflexion 的 0.7692 比 Static Agent 的 0.7051 高一些,但跟 ARIA 的 0.8910 完全不是一个量级。这给我的启发是:纯靠模型自己反思去解锁能力上限,在专业领域知识严重缺失的场景里就是不够用。你必须真的有外部知识注入这个 loop,光让 LLM 反复自我对话不解决问题。
第三,Qwen2.5-7B + ARIA 在大部分 budget 下能压过 GPT-4o + Static / Self-Refine。 B=1000 时 ARIA-Qwen 的 0.8397 已经超过了 GPT-4o-Reflexion 的 0.7692。这个数挺能打的——它告诉你,正确的 framework 设计能让小模型借助人类知识吃到大模型的红利。
不过我得吐槽一下评估方式。Specificity 的绝对值看着确实涨到了 0.8026,但真实合规场景容许的误杀率往往要求几个 9。一个 1.5 亿月活的支付平台,0.8026 的 Specificity 意味着接近 20% 的合规用户被误判 Match——这绝对不是能直接放生产的水平。论文最后部署的版本应该是把 ARIA 当一道初筛 + 人类终审的搭子在用,而不是端到端取代人。这一点论文里其实有点轻描淡写。
消融:每个组件值多少分
| 变体(B=100) | Sensitivity | Specificity |
|---|---|---|
| ARIA(完整) | 0.8333 | 0.7423 |
| Labels-Only ARIA | 0.7949 | 0.7139 |
| w/o Self-Dialogue | 0.8141 | 0.7319 |
| w/o KR Conflict Resolution | 0.8012 | 0.7128 |
| w/o Temporally-Informed KR | 0.8333 | 0.7341 |
读完这张表我下了几个判断:
- KR Conflict Resolution 是最关键的组件:拿掉它 Sensitivity 降 3.21 个点,Specificity 降 2.95 个点,是单点损失最大的。这个数据印证了"知识库不会自动保鲜"这个直觉。
- Self-Dialogue 比想象中重要但没那么离谱:拿掉它两个指标都降 1-2 个点。说明结构化反思有用,但不是不可替代——退化成简单 confidence 阈值也能维持基本盘。
- Labels-Only 的下降是整体最严重的(除 KR Conflict):说明只拿标签不要解释和规则的话,Agent 学到的东西非常表层。这一条对工程实践很有意义——别以为 Active Learning 只问标签就够,让专家给一段解释,价值远高于给一个 Y/N。
- w/o Temporally-Informed KR 的 Sensitivity 居然没降:只 Specificity 降了一点。坦白讲,这个结果让我有点意外,按理说时间衰减应该更重要才对。可能是数据集时间跨度不够长、或者过期规则比例不高的缘故。
效率对比:12 分钟 vs 0.4 分钟
| 方法 | Sens. | Spec. | AHT |
|---|---|---|---|
| Human Experts | 1.0 | 1.0 | 12 min |
| ARIA (B=50) | 0.8013 | 0.7151 | 0.13 min |
| ARIA (B=1000) | 0.8910 | 0.8026 | 0.23 min |
| ARIA (B=3121, Full Oracle) | 0.9428 | 0.8814 | 0.41 min |
Full Oracle Access 的 0.9428 / 0.8814 是这个表里最亮眼的数。B=3121 大概意味着对每 4 个 case 就问一次专家,AHT 还能压到 0.41 分钟。算下来人力开销大概只有原来的 3-4%。
但这个对比我觉得有点设置上的不公平——人类是从零审一个 case 要 12 分钟,包括读用户资料、查名单上下文、整理判断;而 ARIA 调用人类专家是回答一个具体的"这条规则在这种情况下怎么办"的封闭问题,本身就快得多。论文也提了一句"reviewing a case from scratch is time-consuming, whereas answering a query from an agent is much faster",但这个比例差异确实有点偏向 ARIA。
CUAD 公开数据集:法律条款分类
| 方法(B=2000) | Accuracy |
|---|---|
| Static GPT-4o | 0.4872 |
| RAG Agent | 0.5735 |
| Reflexion | 0.4995 |
| Simple Uncertainty | 0.5789 |
| ARIA + GPT-4o | 0.6358 |
13,101 个合同条款,41 类。ARIA 在 B=2000 下做到 0.6358,比静态 GPT-4o 的 0.4872 高 14.86 个绝对点。Active Learning baseline Simple Uncertainty 也才 0.5789,ARIA 比它再高 5.69 个点。
这里有一个不能忽视的细节:CUAD 实验里"人类专家"是用更强的 LLM 模拟的(论文提了 GPT-4 Turbo / Claude 3 Opus / Gemini 1.5 Pro)。这意味着 ARIA-Qwen 的 oracle 是 GPT-4 级别的模型,所以"小模型借助专家"这一招的实际收益里,有一部分其实是"小模型借助大模型做 Active KD"。这跟真实人类专家在回路场景的迁移性怎么评估,论文没说太透。
我的几个判断
这是一篇"工程对了"的论文,但不要把它当成算法突破来读
ARIA 的每一个组件——self-dialogue 反思、active learning、带时间戳的知识库、LLM 做语义比较——单独拎出来都不算新。论文最值钱的贡献是把这几样组合成一套能在 1.5 亿月活业务上跑起来的工程范式,并且每个组件都有清晰的消融数据来证明它配比合理。EMNLP Industry track 的定位也吻合这一点:不是搞底层突破,而是把已有研究端到端落到一个真实场景。
对工程师的启发清单
如果你也在做需要持续吸收外部知识的 Agent,这篇论文值得你借鉴的具体做法:
- 置信度评估别只用 logits。结构化 self-dialogue 输出的不确定性比标量 confidence 信息量大太多,尤其是当你需要后续决定"问什么"的时候。
- 知识库要带版本控制。不是简单的 RAG document store,而是带 status / timestamp / superseded_by 的结构化 entry。一旦业务规则会变,这个机制几乎是必选项。
- Active learning 不要只问标签。让 oracle 给解释、给规则、给反例,单点信息量翻几倍。
- 设计澄清反问机制。专家给的回复不是 100% 清楚的,模糊的时候不要自己脑补,而是再问一次。这点 ARIA 通过 active clarification query 做得挺好。
- 检索打分用乘法而不是加法。Status × Recency × Relevance 的乘性结构能让任何一个维度拉胯都直接降分,比 weighted sum 鲁棒。
这套方案不解决的问题
- 几个 9 的合规场景还是不够。0.80 的 Specificity 是初筛级别,离能直接 auto-decision 的水平还差得远。
- 专家供给瓶颈。整套机制的天花板就是人类专家的响应速度和质量。如果业务流量×query rate 超过专家容量,方案直接退化成普通 RAG。
- 知识库长期演化的无限漂移。论文没讨论运行半年、一年之后 KR 里几千条 entry、其中大半是 PotentiallyOutdated 状态时怎么治理。这个我估计是后续工作要面对的。
- 冲突检测靠 LLM。LLM 判 supersedes / contradicts / consistent 这种细粒度关系本身就有错误率,论文也没给这个模块的准确率数据。
写在最后
读完整篇论文我的整体感受是:这是一个让人觉得"对,正经业务里就该这么做"的工程方案。
它没有那种让人惊艳的 idea,没有重新定义 SOTA 的 benchmark 数字,但它把一个真实工业场景里"部署后还能学"这件事,从架构、组件、消融、效率四个维度都做扎实了。如果你正在做合规、风控、客服、法律辅助这类需要持续吸收专家知识的 Agent,这篇论文给的不只是一个想法,而是一份可以直接对照实现的施工图。
行业上一个值得关注的趋势是:Test-Time Learning 这个词最近一年在 LLM 圈被不同流派的论文反复使用,但真正能在 production 里跑起来的方案目前并不多。ARIA 算一个,主要因为它没有去搞"参数更新"这种危险动作,而是把"学习"这件事从 weights 转移到了一个有版本控制的知识库。这种思路在工业落地上保险得多——你随时可以回滚一条 entry,但你没法回滚一次梯度下降。
对了,还有一件事得说清楚——这篇论文的"持续学习"严格意义上发生在知识库层面而非模型权重层面,所以它说到底是 RAG 的进化版而不是 online learning。这个区分挺重要的。如果你期待的是模型参数本身能随业务漂移而更新,那 ARIA 不是你要找的方案;但如果你能接受"权重保持冻结、外挂知识库不停长大并自我维护"这种范式,那 ARIA 几乎是目前能找到的最完整的工程参考之一。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我