让 o1 学会自己上网查资料:Search-o1 给大推理模型补上的那块知识短板
写在前面
你有没有盯着 QwQ 或者 o1 的思考链看过几遍?
我之前调一个化学题的时候盯着 QwQ-32B 的输出愣了好久——这个模型已经"推"了三千多 token,反复出现"perhaps the structure is...""alternatively, it could be...""wait, let me reconsider..."。它不是不会推理,它是不知道某个分子的真实结构。然后基于这个猜测的结构,往下推三步,得出一个错误答案。
这是大推理模型(LRM)特有的尴尬:它的思考链越长,越能放大一个底层事实错误。一个没记牢的化学键、一个搞混的物理常数、一个引错的人物年代,会让后面整段精巧的"step-by-step"全部白干。OpenAI 的 o1、阿里的 QwQ-32B-Preview、DeepSeek-R1-Lite,这些 o1-like 模型在这件事上是一致的。
那篇看起来挺直接的解法——给它接个搜索引擎——其实没那么直接。Search-o1 这篇 EMNLP 2025 的工作就是在把这条路认真走通:让 LRM 在自己的长 CoT 里按需触发搜索,并且在搜索结果回来的时候别把推理链搞乱。
核心摘要
LRM 的长链推理放大了"知识不足"的副作用:模型一边推一边犯嘀咕,"perhaps"在 GPQA Diamond 上每条思考链平均出现 30.4 次。Search-o1 的解法说穿了是两件事:第一,用一对特殊 token <|begin_search_query|> / <|end_search_query|> 让 LRM 在思考过程中自己掏出查询,触发 Bing API 检索;第二,不直接把检索到的网页塞回主推理链,而是单独起一个"Reason-in-Documents"子进程(用同一个 QwQ-32B 跑),让它把噪声很大的网页内容压缩成一句精炼结论,再用 <|begin_search_result|> / <|end_search_result|> 注回主链。
结果:QwQ-32B 加上这套机制,GPQA Diamond 从 58.1 提到 63.6,AIME24 从 53.3 提到 56.7,GPQA Extended 上 57.9 的成绩全面超过物理学家、化学家、生物学家三类人类专家。多跳 QA 上比 standard RAG 平均高 29.6%。在 Top-k 缩放实验里,只检索 1 篇文档就能超过 Direct Reasoning 和检索 10 篇的 standard RAG。
我的判断:这是一篇训练免费、纯推理时机制的工作。它不是底层突破,但把 "agentic search × long-CoT" 的工程范式打磨清楚了,是后续 Search-R1、ReSearch、R1-Searcher 这一整条 RL 训练搜索 Agent 路线绕不开的 baseline。值得一看。
论文信息
- 标题:Search-o1: Agentic Search-Enhanced Large Reasoning Models
- 作者:Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, Zhicheng Dou
- 机构:中国人民大学、清华大学
- arXiv:https://arxiv.org/abs/2501.05366(v1,2025 年 1 月)
- 代码:https://github.com/sunnynexus/Search-o1
- 会议:EMNLP 2025
为什么 LRM 比传统 LLM 更需要外部知识
这事儿一开始我也没太想明白。直觉上,你越擅长推理,对知识的依赖应该越低才对——你可以从更少的事实里推出更多的结论。Quaternion 群、林奇定理这些,会的人推几步就出来。
但 o1-like 模型走的是反方向。它学到的是"放慢思考、把每一步都展开来想"。这意味着每一个事实点都可能成为推理链上的支点。一旦某个支点是错的,后面的推理形式上再优雅也没救。
作者在 Figure 1 右图给了一个挺有冲击力的统计:
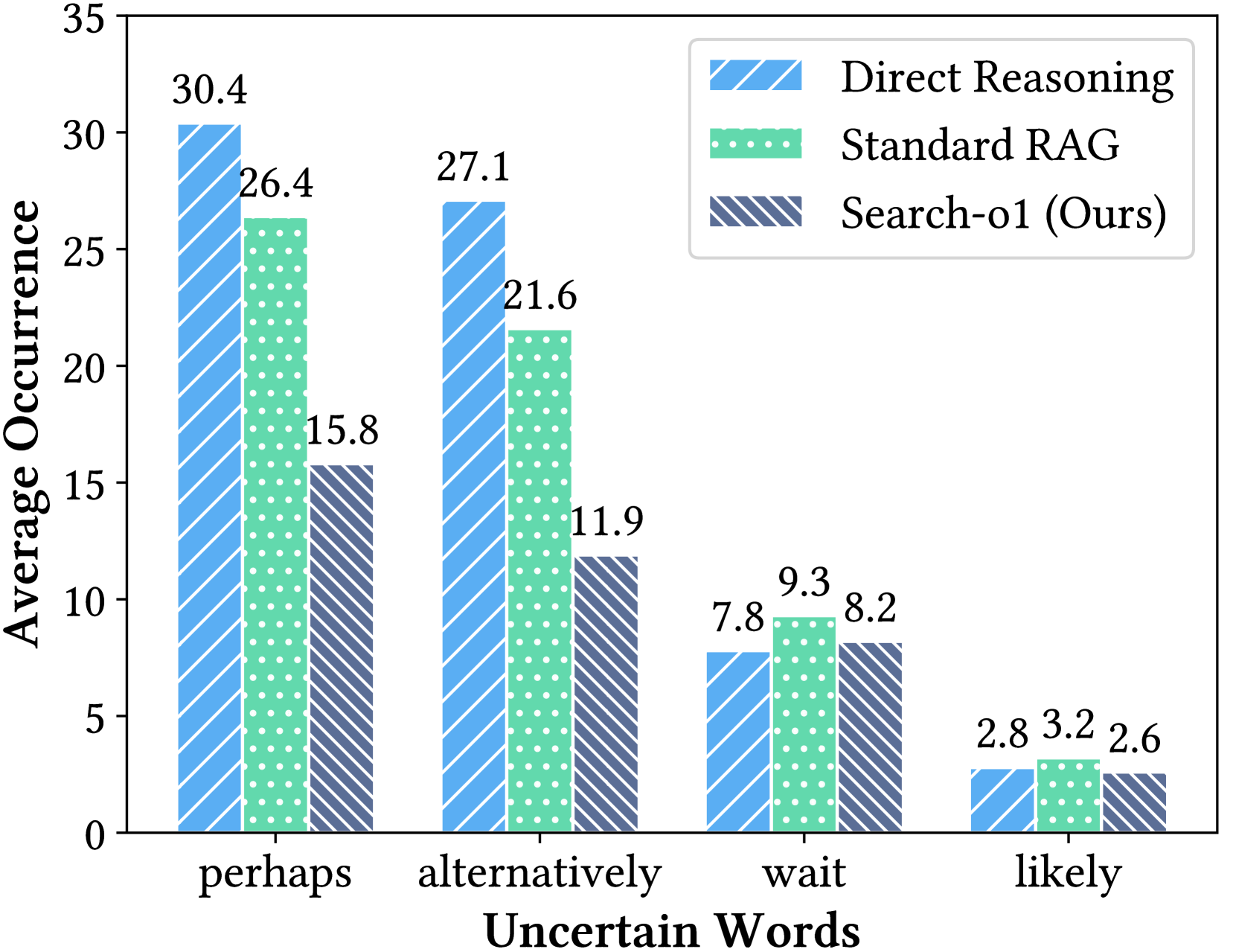
图1:QwQ-32B-Preview 在 GPQA Diamond(PhD 级别科学多选 QA)上每条 reasoning chain 中"不确定词"的平均出现次数。Direct Reasoning 模式下"perhaps"平均出现 30.4 次/题,"alternatively" 27.1 次/题——这是模型在"猜"。Standard RAG 一次性灌入 top-10 文档后只把"perhaps"压到 26.4,几乎没用;Search-o1 真正把 perhaps 压到 15.8、alternatively 压到 11.9,意味着模型在该查的时候确实查到了。
每条 GPQA 题平均说 30 次"perhaps"——这个数我看的时候是真的笑了一下。它不是说一两次"也许",是真的全程都在猜。然后基于猜到的化学结构往下推第三步、第四步。AIME 题里它会"perhaps the prime factorization is...",物理题里"perhaps the moment of inertia is...."。
回到一个朴素问题:为什么标准 RAG 救不了它?
作者用一个很容易被忽略的现象说了这事儿。标准 RAG 是在收到题目的瞬间,做一次检索,把 top-10 文档拼到 prompt 前面,然后让模型推。问题是 LRM 的推理是个多步过程,每一步可能需要不同的知识。你在第 0 步检索的"chemical structure of trans-Cinnamaldehyde"可能解决了第 3 步的疑惑,但模型在第 7 步又开始想"E/Z 异构体在 Grignard 试剂中的反应机理",这时候已经没有上下文支撑了。
Figure 2 的对比很值得细看:
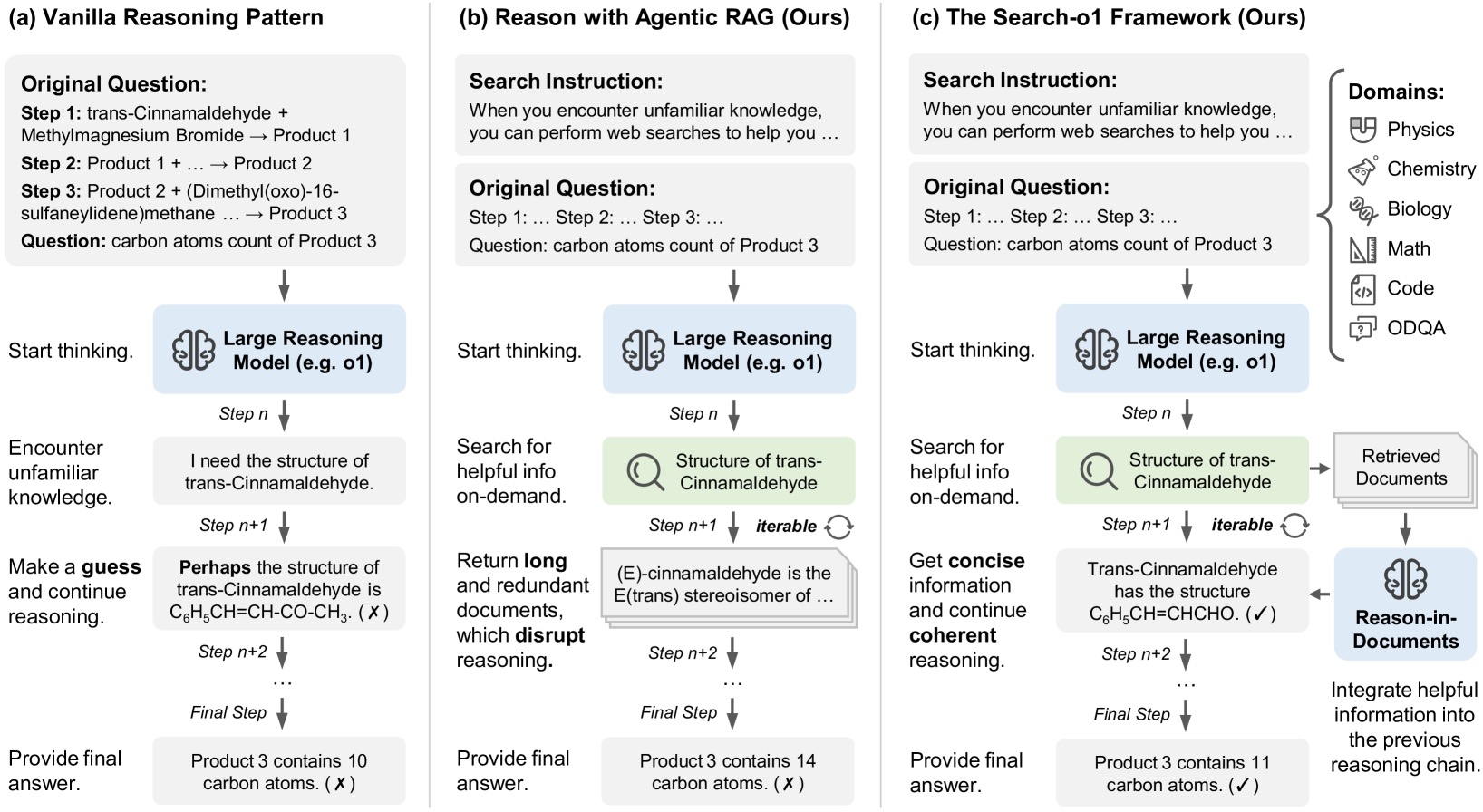
图2:三种推理范式的对比。(a) 直接推理直接对 trans-Cinnamaldehyde 的结构胡猜(C₆H₅CH=CH-CO-CH₃,错),最后数出 10 个碳原子。(b) Agentic RAG 让模型自己发起搜索,但返回的网页冗长拖沓,把"Step n+1"塞进去之后下面的推理被噪声淹没,最后数成 14 个碳原子,还是错。(c) Search-o1 在搜索和推理之间加了一个 Reason-in-Documents 提炼层,模型只看到精炼后的"Trans-Cinnamaldehyde has the structure C₆H₅CH=CHCHO",然后顺利数出 11 个碳。
这个图我第一眼看的时候觉得"嗯就这样",仔细想才发现一个细节挺关键:panel b 和 panel c 的差别不在于检索本身,而在于"检索结果如何回到推理链"。如果你直接把 top-10 网页内容(每个几千 token、夹杂广告导航代码)灌回去,QwQ 这种被精调到深度反思模式的模型,会被噪声彻底带跑——它会开始思考"这个网页里说的'trans-Cinnamaldehyde 是肉桂的主要成分'到底跟我现在数碳原子有什么关系?",然后顺着这条岔路一去不返。
说实话这是我之前在做带工具的 Agent 时栽过的坑。早期我们试过把 Google search 的 snippet 直接往 prompt 里塞,模型经常跑去解读 snippet 的 metadata 而不是回答原题。后来加了一层"先让模型用一个独立 prompt 把 snippet 摘成结论再注回去",立刻就好了。Search-o1 的 Reason-in-Documents 就是这个套路的系统化实现——只不过它用的是同一个 LRM 模型本身做摘要,而不是另起一个小模型。
方法核心:把搜索变成 LRM 的一种"内置语法"
Agentic 搜索机制
机制本身朴素得不能再朴素。给 QwQ-32B-Preview 一段 system instruction:
当你遇到不确定的知识点时,写
<|begin_search_query|> 你的查询 <|end_search_query|>。系统会调 Bing API 检索,把结果用<|begin_search_result|> ... <|end_search_result|>包起来返回给你。你可以重复这个过程,最多 N 次。
这就是全部的"agentic"。没有训练,没有 RL,没有 SFT。纯 prompt + 解码时拦截。模型在 decode 到 <|end_search_query|> 这个 token 的时候,inference engine 把生成截停,提取出查询字符串,调 Bing Web Search API(top-10 文档)+ Jina Reader API(拉网页全文),然后……
如果不做任何处理,把全文塞回去,就是 RAgent baseline 的玩法。Search-o1 在这里多走了一步。
Reason-in-Documents:让 LRM 自己消化检索结果
每次检索完,框架会单独再起一次 LRM 调用(用的还是 QwQ-32B),prompt 大致是:
你的任务:基于以下输入提取并整合相关信息——
- Previous Reasoning Steps: {主推理链到目前为止的内容}
- Current Search Query: {刚才的查询}
- Searched Web Pages: {top-10 网页的内容拼接}
如果网页里有用,输出 "Final Information [精炼后的结论]"
如果没有,输出 "Final Information No helpful information found."
这个子调用产出的"Final Information"就是被注回主推理链的内容。它的字数被压到几句话以内,主推理链的连贯性不会被破坏。
我把核心的推理循环用伪代码写一下,可能比看公式直观:
def search_o1_inference(question, model, search_api):
seq = INSTRUCTION + question
while not seq.endswith(EOS):
new_tokens = model.generate(seq, stop=["<|end_search_query|>", EOS])
seq += new_tokens
if seq.endswith("<|end_search_query|>"):
query = extract_query(seq)
docs = search_api(query, top_k=10)
refined = model.generate(
build_reason_in_docs_prompt(seq, query, docs),
stop=[EOS]
)
seq += f"<|begin_search_result|>{refined}<|end_search_result|>"
return seq
这个流程里有几个地方值得拎出来说。
第一,主推理链和文档消化是同一个 LRM。作者没有引入额外的 summarizer 或者小模型,QwQ-32B 既负责长链推理,又负责文档摘要。这个选择在工程上有现实意义——部署时只需要维护一份权重,但代价是每次检索都多一次完整的 32B forward。
第二,搜索结果不是直接注入"原始文档",而是注入一段"对当前推理状态有用的提炼"。这个区别我觉得是 Search-o1 跟同期 ReAct 系工作的核心差异。ReAct 那一支也允许多轮搜索,但它通常把 observation 原样塞回去,让 LLM 自己挑信息。LRM 的 CoT 太长了,一旦 observation 进来就会反客为主。
第三,整个流程是 batch 化的。作者特别强调了 batch inference:每次解码到一个 batch 里若干 sequence 都触发了 search,所有 query 一起发给检索 API,返回的所有文档一起做 Reason-in-Documents 子调用,然后所有结果一起注回。这个工程设计在跑实验吞吐量上影响很大——单条样本顺序跑会被 RAG 的网络延迟拖死。
一个被低估的设计选择:special token 而不是 function call
QwQ-32B 没有原生的 function calling 能力,所以作者不能用 OpenAI 那种 JSON schema 工具调用。他们的替代方案是用 special token 包围查询字符串。这个选择看起来土,但在 LRM 上反而合适——LRM 的 CoT 本来就是流式的自然语言生成,special token 是这条流上很自然的"暂停 → 切换上下文 → 恢复"标记,比硬塞 JSON 解析层要顺滑。
后续的 Search-R1(2025 年 3 月)、ReSearch、R1-Searcher 等 RL 训练版本几乎都沿用了 Search-o1 这套 special token 协议。能成为事实标准,说明这个设计选对了。
实验:从科学题到代码题,跑了一圈
主实验:复杂推理任务
作者选了三个量级的硬仗——GPQA Diamond(PhD 级科学多选题)、三个数学竞赛集(MATH500 / AMC23 / AIME24)、LiveCodeBench(编程题,2024 年 8-11 月新题,避开污染)。所有 32B 的方法用 QwQ-32B-Preview 当 backbone,温度 0.7,最大 32k tokens,Bing API top-10 文档。
主表如下(Pass@1 指标,加粗为 32B 模型最佳):
| Method | GPQA Physics | GPQA Chemistry | GPQA Biology | GPQA Overall | MATH500 | AMC23 | AIME24 | LiveCodeBench |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-32B | 57.0 | 33.3 | 52.6 | 45.5 | 75.8 | 57.5 | 23.3 | 22.3 |
| QwQ-32B(Direct) | 75.6 | 39.8 | 68.4 | 58.1 | 83.2 | 82.5 | 53.3 | 33.0 |
| Llama3.3-70B | 54.7 | 31.2 | 52.6 | 43.4 | 70.8 | 47.5 | 36.7 | 34.8 |
| GPT-4o † | 59.5 | 40.2 | 61.6 | 50.6 | 60.3 | - | 9.3 | 33.4 |
| o1-preview † | 89.4 | 59.9 | 65.9 | 73.3 | 85.5 | - | 44.6 | 53.6 |
| RAG-QwQ-32B | 76.7 | 38.7 | 73.7 | 58.6 | 84.8 | 82.5 | 50.0 | 24.1 |
| RAgent-QwQ-32B | 76.7 | 46.2 | 68.4 | 61.6 | 85.0 | 85.0 | 56.7 | 26.8 |
| Search-o1(Ours) | 77.9 | 47.3 | 78.9 | 63.6 | 86.4 | 85.0 | 56.7 | 33.0 |
几个数我来掰开看看。
GPQA Diamond 从 58.1 → 63.6(+5.5)。这是个 PhD 级别的科学题集合,每道题都需要某个具体的事实点(化合物结构、物理常数、生物机制)。Search-o1 在所有三个子领域都涨,特别是生物从 68.4 涨到 78.9(+10.5)——生物题里通常需要查具体的生物名词、解剖学结构这些东西,纯推理猜不出来。
MATH500 从 83.2 → 86.4(+3.2),AIME24 从 53.3 → 56.7(+3.4)。数学题涨幅小是预期之内的——AIME 这种题更多是组合数学和数论的推导,外部知识帮助有限。但能涨说明至少没把模型搞得更差。
LiveCodeBench 33.0 → 33.0。这个数是真的让我皱眉。代码题完全没受益。作者没在正文里把这个数据吃透——我猜原因是 LiveCodeBench 的题目大多是算法题(数据结构、动态规划这种),需要的是"想清楚算法"而不是"查个语法",搜索引擎对此帮不上忙。但有意思的是 RAG-QwQ 反而掉到 24.1,RAgent 掉到 26.8——说明在不需要外部知识的领域强行加 RAG 是负收益的。Search-o1 至少做到了"不被搜索拖累"。
对比 o1-preview 73.3 vs Search-o1 63.6。差了将近 10 个点。但你要注意这两个模型完全不在一个量级——o1-preview 是 OpenAI 闭源模型,参数量未公开但估计远大于 32B,而且经过了大规模 RL 训练。Search-o1 是用一个 32B 开源模型 + 推理时搜索,硬是把性能拉到 GPT-4o(50.6)之上。这个比较就比较公平了:在不调权重的前提下,给开源 LRM 接搜索能多榨出 5+ 个点。
跟人类专家比
GPQA 还有一个 Extended Set(546 题),论文比 Diamond 大一档。作者在上面做了一个"模型 vs 人类专家"的对比:
| Method | Physics | Chemistry | Biology | Overall |
|---|---|---|---|---|
| 物理学家 | 57.9 | 31.6 | 42.0 | 39.9 |
| 化学家 | 34.5 | 72.6 | 45.6 | 48.9 |
| 生物学家 | 30.4 | 28.8 | 68.9 | 37.2 |
| QwQ-32B(Direct) | 61.7 | 36.9 | 61.0 | 51.8 |
| RAG-QwQ-32B | 64.3 | 38.3 | 66.7 | 54.6 |
| Search-o1(Ours) | 68.7 | 40.7 | 69.5 | 57.9 |
这张表挺值得品的。Overall 上 Search-o1 的 57.9 已经超过最强的化学家(48.9)9 个点。在物理(68.7 vs 物理学家 57.9)和生物(69.5 vs 生物学家 68.9)上都赢了对应领域的人类专家。
但化学这一栏(40.7 vs 化学家 72.6)差距巨大。化学是个高度依赖隐性经验和图式化推理的学科——很多反应机理你查文档查不到,只能在脑子里画 Lewis 结构、推电子流向。这块是检索增强的盲区。
我的体感是:搜索能补"事实记忆"的不足,但补不了"领域 schema"的不足。化学家的优势恰恰在于后者。
Top-k 缩放分析
Figure 3 这个实验我看到的时候有点意外:
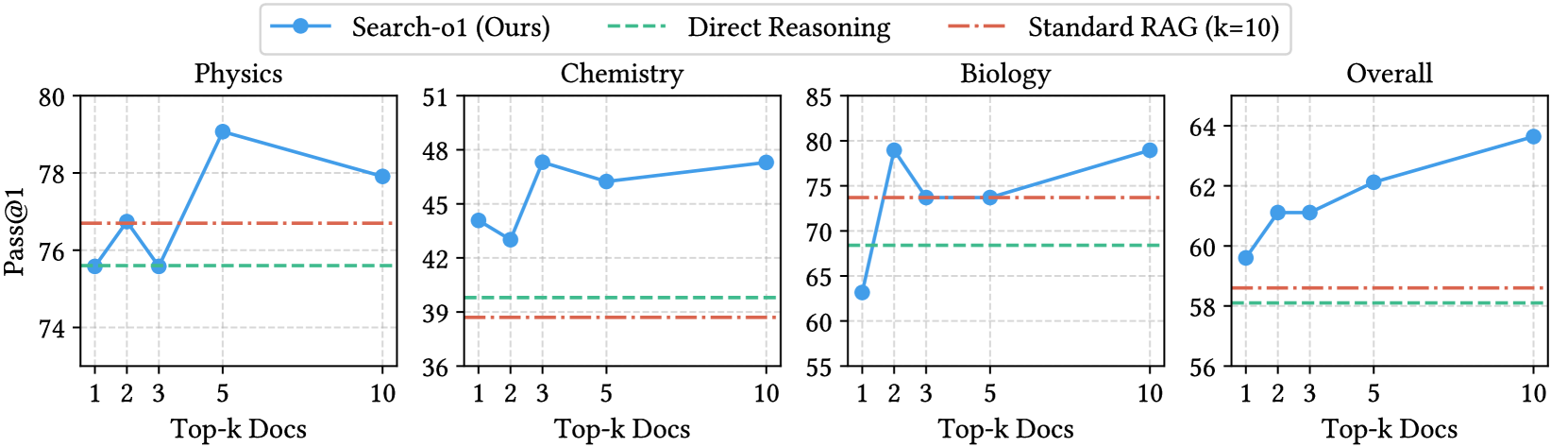
图3:缩放分析。横轴是每次搜索返回的文档数 k,纵轴 Pass@1。蓝色实线为 Search-o1,绿色虚线为 Direct Reasoning(无检索),红色点划线为 Standard RAG(k=10)。可以看到 Search-o1 即使 k=1 在 Physics、Biology、Overall 上都已经超过 Direct Reasoning 和 Standard RAG(k=10)。
Search-o1 在 k=1 时,Overall 就到了 59.5,已经超过 Standard RAG k=10 的 58.6。这事儿挺说明问题的——standard RAG 一股脑灌 10 篇文档,效果还不如 Search-o1 在合适的步骤精准查 1 篇。从 k=1 到 k=10 还能持续涨到 63.6,说明这套 Reason-in-Documents 机制确实能消化更多的文档而不被噪声淹没。
但 Chemistry 这一列在 k=1 时是 44 多分,比 Standard RAG(k=10)还低一点。说明化学题对检索的"信息密度"更敏感——一篇文档可能不够给出足够的反应机理细节。
开放域 QA:multi-hop 才是主战场
| Method | NQ EM | TriviaQA EM | HotpotQA EM | 2WIKI EM | MuSiQue EM | Bamboogle EM |
|---|---|---|---|---|---|---|
| Qwen2.5-32B | 22.8 | 52.0 | 25.4 | 29.8 | 8.4 | 49.6 |
| QwQ-32B(Direct) | 23.0 | 53.8 | 25.4 | 34.4 | 9.0 | 38.4 |
| RAG-QwQ-32B | 29.6 | 65.6 | 34.2 | 35.6 | 10.6 | 55.2 |
| RAgent-QwQ-32B | 33.6 | 62.0 | 43.0 | 58.4 | 13.6 | 52.0 |
| Search-o1(Ours) | 34.0 | 63.4 | 45.2 | 58.0 | 16.6 | 56.0 |
单跳 QA(NQ、TriviaQA)上 Search-o1 跟 RAgent 几乎打平——这符合作者的判断:单跳问题一次检索就够,Reason-in-Documents 的边际收益不大。
多跳 QA 是 Search-o1 真正能拉开差距的地方。HotpotQA 从 RAG 的 34.2 → 45.2(+11),MuSiQue 从 10.6 → 16.6(+6),都是大幅提升。多跳问题本来就是"问题 → 查 A → 根据 A 推出需要查 B → 查 B → 得出答案"这个范式,跟 Search-o1 的"边推边查"是天作之合。
作者一句话总结:"agentic RAG 在 multi-hop 上比 standard RAG 平均高 23.2%"——这个数字其实是 RAgent 已经做到的,Search-o1 在 RAgent 基础上又加了 5.3%,提升来自 Reason-in-Documents 这一刀。
一些不那么漂亮的细节
写到这儿要泼点冷水了。Search-o1 不是没有问题。
计算成本。每个问题,主推理链跑一遍 32B forward。每次触发搜索,再跑一遍 32B forward 做 Reason-in-Documents。如果一个问题平均搜 5 次,总共要跑 6 次 32B 推理。这个开销在批量评测里靠 batch 摊掉了,但在实际部署里会非常贵。论文跑 GPQA Diamond(198 题)用了 8 张 A800,作者没给具体的端到端延迟数字——我推测一道题至少几十秒到一分钟。
搜索质量是个外部依赖。Search-o1 用的是 Bing Web Search + Jina Reader。Bing 返回的 top-10 在科学题上质量不一定能跟得上:你查"trans-Cinnamaldehyde structure"还行,查"E/Z stereochemistry of α,β-unsaturated ketones in Grignard addition"就未必。论文没有讨论"换检索引擎效果会变多少",但这个变量对最终精度影响很可能比 Reason-in-Documents 更大。
没有训练。这是优点也是缺点。优点是任何 LRM 都能套这套机制,门槛低;缺点是模型并没有学会"我什么时候该搜、查询怎么写最有用"这种策略,全靠 prompt 引导。你能从 Figure 1 看到 Search-o1 把"perhaps"压到 15.8 已经很好,但仍然有 15.8 次——意味着模型有相当一部分该查的时候没查。
后续工作(Search-R1、ReSearch 等)就是冲着这个缺点去的:用 RL 训练让模型学会更聪明的搜索策略。从这个角度看 Search-o1 是个"过渡形态"——把 agentic search 这件事的工程框架定下来,告诉大家"行得通",然后把进一步优化的空间留给 RL。
LiveCodeBench 上没涨。这个数实际上揭示了一个边界:搜索增强对"知识密集"型任务(科学 QA、多跳 QA)有效,对"算法密集"型任务(数学竞赛、算法题)效果有限甚至无效。作者在正文里没把这层意思说透,但读者应该自己意识到。
化学题的"专家差距"。 已经说过了——领域 schema 类的能力不是搜索能补的。如果你的实际场景是化学反应预测、药物发现这种,Search-o1 不太能帮上你。
跟同期工作怎么比
2024 年底到 2025 年初,"o1-like + 搜索"这条路上有几篇关联工作:
| 工作 | 时间 | 训练方式 | 核心思路 |
|---|---|---|---|
| MindSearch | 2024-07 | Prompt-only | 多 Agent 并行搜索 + 结果汇总 |
| ReAct(早期范式) | 2022 | Prompt-only | Thought-Action-Observation 三段式 |
| Search-o1 | 2025-01 | Prompt-only | LRM + special token 触发搜索 + Reason-in-Documents 摘要 |
| Search-R1 | 2025-03 | RL(PPO/GRPO) | 训练模型学会何时搜、怎么搜 |
| ReSearch | 2025-03 | RL | 思考链中引入搜索 token,端到端训练 |
| R1-Searcher | 2025-04 | RL(两阶段) | 先 SFT 再 RL,小模型也能学会搜索 |
Search-o1 的位置很清楚:它是这条线上第一篇把 LRM + 多轮搜索 + 文档精炼整套机制系统化做出来的工作,而且做的是 prompt-only。后面那些 RL 工作几乎都把 Search-o1 当作 baseline 来比。
我特别想强调一个判断:如果你今天要做一个搜索增强的推理产品,从 Search-o1 起步是合理选择。它不需要你训练,能快速部署,效果立得住。等你的业务跑起来、有了真实数据之后,再考虑用 RL 去训练一个更聪明的搜索策略。这是一个非常清晰的工程演进路径。
反过来如果你直接去抄 Search-R1 或者 R1-Searcher,没有真实业务数据做 reward signal 的话,RL 训出来的策略很可能比 Search-o1 还差。
我自己的几点工程启发
第一,two-stage RAG 应该成为默认。 把"检索"和"消化"拆成两个独立的 LLM 调用,对长上下文模型尤其重要。现代 RAG 系统里很多人把 retrieval 拼接到 prompt 就完事,省了一次 LLM 调用。这在 32k 以下的短上下文里没问题,但你的主链路是 LRM 的长 CoT 时,必须加这一道消化层。否则模型会被 retrieval 噪声带跑——这件事我亲自踩过坑,Search-o1 的 (b) → (c) 对比就是最直观的证据。
第二,special token 是 LRM 调用工具的天然接口。 不要硬上 function calling JSON。如果你的 backbone 是 QwQ、R1 这种走长 CoT 路线的模型,让它在 CoT 里直接吐出 <|begin_search_query|>...<|end_search_query|> 这种标记,再用流式拦截器解析,比强行 JSON 解析顺滑得多。
第三,agentic 不一定要 agent 框架。 Search-o1 没有用 LangGraph、AutoGen、CrewAI 这些 agent 框架。它就是一个带 stop token 拦截的简单循环。从我自己的经验看,agent 框架在原型阶段能快速搭出来,但到了"我要把吞吐打满"的阶段,你会发现框架的抽象层在拖你的后腿。Search-o1 这种 native 实现在 batch 化、错误处理、monitoring 上更直接。
第四,对"agentic 是否需要 RL"持一个开放心态。 看完 Search-o1 的实验我有点动摇——如果一个 prompt-only 的方案能在 GPQA 上把 QwQ 拉到超过人类专家,那 RL 的边际收益到底有多大?后续 Search-R1 的论文里给了一些 RL 提升的数字,但 ROI 是不是真的高、是不是值得为此搞一套 RL 训练流水线,需要你结合自己的业务来算。Prompt-only 至少是一个很强的"做不做 RL"决策的对照基线。
最后
Search-o1 不是一篇"惊艳"的论文。它没引入新的训练目标,没设计新的 loss,没刷一个全新的 benchmark。它就是把"LRM 边推边查"这件事的工程范式定下来——special token 触发搜索、独立子调用消化文档、batch 化推理框架。
但工程范式定得对,比"惊艳"重要得多。它的特殊 token 协议成了后续 RL-based search agent 的事实标准;它的 Reason-in-Documents 设计被后续工作普遍沿用;它对"agentic search 能在多跳 QA 上拿 +29.6%"的实证给整个方向提供了信心基线。
我的整体评价:这是一篇做实事的论文,而不是讲故事的论文。如果你正在做需要外部知识的推理 Agent——RAG 产品、研究助手、领域问答——Search-o1 应该是你绕不开的起点参考。
更深一层的问题它没有回答:LRM 究竟应该在多大程度上依赖外部知识?什么时候搜、什么时候靠内部记忆推?这件事有没有一个最优策略? 这个问题需要 RL 来回答,而 RL 又需要好的 reward signal 来训。这条路再走下去就是 2025 这一年陆续涌现的 Search-R1 / ReSearch / R1-Searcher 那一系列工作了。
但那是另一篇文章的事了。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我