把 Reward Model 拆成五个"专科医生"——SRM 用工程套路在 RM 上又榨了 8 个点
核心摘要
工业界搞 RLHF 的人都知道一个尴尬事实:scalar RM 评分像一个不肯解释自己理由的黑盒打分器,给你一个 0.78,你不知道它到底在乎什么;GRM 想用 CoT 把理由生成出来,但又慢得离谱,部署根本扛不住。这篇 EMNLP 2025 Industry Track 的论文给了一个挺"工程"的方案——把 RM 拆成五个专门的旁支模型(Semantic / Entity / FactCheck / Style / Quality),每个用 LoRA 微调一个 LLaMA3-8B,先跑一遍生成结构化的辅助文本,再拼回原输入喂给标准 BT-RM。InternLM2-20B 上整体分从 56.4 涨到 64.3,幻觉率直降 5.5 个点,推理速度比 GRM 快约 4 倍(22.8s vs 92.5s / 1k 样本)。说实话,这个方案没什么底层突破,但它把"特征工程"这件被深度学习时代鄙视过一阵子的老活儿,重新搬到 RM 这个场景里,挺解决问题的。
论文信息
- 标题:Structural Reward Model: Enhancing Interpretability, Efficiency, and Scalability in Reward Modeling
- 作者:Xiaoyu Liu, Di Liang, Chang Dai, Hongyu Shan, Peiyang Liu, Yonghao Liu, Muling Wu, Yuntao Li, Xianjie Wu, Li Miao, Jiangrong Shen, Minlong Peng
- 机构:东北大学(Boston)、复旦大学、北京大学、吉林大学、北京航空航天大学、西安交通大学、百度
- 会议:EMNLP 2025 Industry Track
- arXiv:2509.25361
一个让人皱眉的工程现实
我自己之前在做 RLHF 项目的时候,碰到过一个特别让人头大的问题:reward 在涨,但生成质量肉眼可见在变差。
后来定位下来发现,scalar RM 给一个回答打 0.78,但你完全不知道它是因为内容好、还是只是因为风格"看起来像 chosen 样本"。等到 RL 把策略训得开始往那个错误信号上抄近路,你才发现 RM 早就被钻空子了。
更要命的是 bad case 诊断。线上来一个糟糕回答,scalar RM 说 0.4,你想知道是事实错了、还是语义没对齐、还是风格出戏,对不起,没有任何信号能告诉你。这就是工业界搞 RM 最痛的一个点:你不仅需要一个分数,还需要这个分数是怎么来的。
GRM 这条路按理说应该解决这个问题——让模型先输出一段 CoT 推理再打分,理论上"理由"就出来了。但实际部署的时候你会发现:
- 顺序解码慢得令人绝望
- 生成的 CoT 是不可控的,今天分析风格、明天突然纠结事实、后天又跑去聊用户体验
- 黑盒程度不比 scalar 强多少,因为你根本没法约束它必须从哪几个维度评估
这篇 SRM 的切入点就在这里——既然你想要"维度可解释 + 高效",那就预先把维度定死,每个维度训一个专门的小模型,然后并行跑就完了。
听起来朴素得几乎像在退步——这不就是把 NN 时代之前的特征工程拿回来用吗?但反过来想,工业界的需求恰好就是"可控、可诊断、可优化",自由生成的 CoT 反而是个累赘。
SRM 的核心思路:把 RM 拆成五个专科
一句话讲清楚
在 prompt 和 response 之外,再用 5 个专门的小模型生成 5 段结构化辅助文本,把这些拼到原输入后面,丢给标准 BT-RM 打分。结构化的好处是:每个维度有独立信号,bad case 出来就知道是哪个旁支没过关。
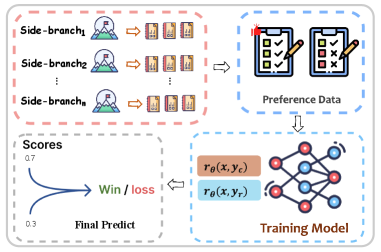
图1:SRM 整体架构。左上是多个并行的 Side Branch(旁支模型),中部把生成的辅助信号注入偏好对,右下用标准 BT 损失训练 RM。注意,"并行"这个词是关键——这是 SRM 相对 GRM 的根本效率优势。
五个旁支模型分别盯什么
作者基于工业场景的"高频 bad case 模式",把维度切成了五种。这不是拍脑袋拍出来的——他们做了 N-fold 交叉验证 + 归因分析,把高频问题归到这 5 类下面:
| 旁支模型 | 盯的核心问题 | 工业 bad case 占比 | 实现方式 |
|---|---|---|---|
| SB-Semantic | 语义对齐——表面词匹配但意图错位 | 38.7% | LoRA-tuned LLaMA3-8B,输出语义关联分析 |
| SB-Entity | 实体背景缺失——专有名词、领域知识断层 | 22.1% | 结合知识图谱做实体关系扩展 |
| SB-FactCheck | 事实一致性——回答里的硬错误 | 15.4% | 输出可验证性分析文本 |
| SB-Style | 风格语调失配——技术问题口语回答 | 9.8% | 分析 prompt 与 response 的风格一致性 |
| SB-Quality | 重复 / 低多样性 | 13.2% | 输出多样性与创意维度评估 |
注意这个 38.7% 的 SB-Semantic 占比——工业场景中超过三分之一的 bad case 都卡在"看起来是这个意思但其实不是"这种深层语义错位上。这跟我自己的工程感受是一致的:搜推场景下,"防水蓝牙耳机"和"防汗运动耳机"的差别,scalar RM 真的捕捉不到。
旁支模型怎么训出来的
这一步其实是论文里我比较欣赏的设计——不是直接用人工标注,而是用了一个挺巧的数据引擎:
- BoN 采样:在大规模 prompt-response 数据集上做 Best-of-N 采样,每个 (p, r) 生成 M 个候选辅助文本 \(a^{(i)}\)
- LLM-as-a-Judge 过滤:用一个 LLaMa3-8B 的判官模型(论文里写的是基于 o1 风格)给每条 \((p, r, a^{(i)})\) 打分,过阈值 \(\tau\) 才保留
- MLE 微调旁支:用过滤后的高质量三元组 \((p, r, a)\) 训对应的旁支模型
损失函数就是一个标准的 MLE:
这个设计有意思的地方在于——辅助文本本身没有人工 ground truth,是靠"采样 + 过滤"撬动的。质量阈值 \(\tau\) 是个工程超参,调得过严数据不够,调得松就引入噪声。论文没披露具体阈值数值,这块其实还挺关键的。
怎么把信号注入主 RM
旁支训完之后,对每个 (chosen, rejected) 偏好对,5 个旁支并行跑,把每个旁支生成的辅助文本拼到原 response 后面:
然后这俩增强后的输入丢给标准 RM,按 Bradley-Terry 偏好建模:
其中 \(P(r_c \succ r_j | p) = \frac{e^{s_c}}{e^{s_c} + e^{s_j}}\)。
整个过程 RM 这一侧没有任何架构改动——它还是那个 BT-RM,只是输入被五个旁支"加料"过了。这是 SRM 最讨喜的工程性质:完全兼容现有的 RM 训练 / 推理流水线,只是前面加了 5 个旁支。
一张图把流程看清楚
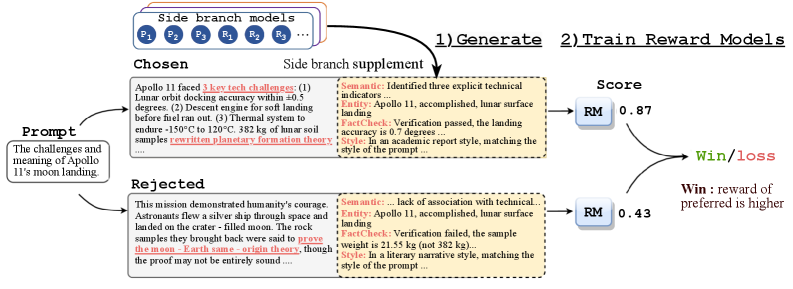
图2:SRM 流程实例。论文里举了一个"阿波罗 11 号登月挑战"的例子——Chosen 给出技术细节准确的描述,Rejected 引用了"重写行星形成理论"这种事实漂移内容。五个旁支并行注入 Semantic / Entity / FactCheck / Style 等维度信号后,主 RM 给 Chosen 打 0.87,Rejected 0.43,Win 信号清晰。这就是结构化信号的价值——不只给一个分,还告诉你 FactCheck 这关 Rejected 没过。
实验:数字到底有多硬
主实验表
主实验在 RM-Bench、JudgeBench、IFBench 三个公开基准上跑,base 模型选了 InternLM2-7B-Reward、InternLM2-20B-Reward、Llama3-8B Instruct,对照组是 ArmoRM、Skywork-Reward、INF-ORM-70B、GPT-4o 等业界主流 RM。
| Model | RM-Bench Normal | RM-Bench Hard | JudgeBench | IFBench Simple | IFBench Normal | IFBench Hard | Overall |
|---|---|---|---|---|---|---|---|
| ArmoRM-Llama3-8B-v0.1 | 76.7 | 34.6 | 51.9 | 72.3 | 66.2 | 59.5 | 56.5 |
| Skywork-Reward-Llama-3.1-8B-v0.2 | 78.0 | 31.8 | 57.8 | 78.7 | 69.2 | 59.8 | 58.1 |
| Skywork-Reward-Gemma-2-27B | 82.7 | 35.1 | 55.8 | 87.2 | 68.4 | 56.1 | 59.2 |
| Openai-GPT-4o | 71.4 | 27.9 | 64.6 | 85.1 | 66.2 | 54.4 | 56.3 |
| Llama3-8B Instruct | 9.3 | 20.2 | 2.6 | 12.8 | 12.8 | 13.6 | 11.3 |
| + side-branch SRM | 75.4 | 39.5 | 59.4 | 77.1 | 63.6 | 56.1 | 60.8 |
| internlm2-7b-reward | 72.6 | 19.9 | 56.2 | 74.5 | 61.7 | 55.7 | 52.0 |
| + side-branch SRM | 78.4 | 46.8 | 58.7 | 75.1 | 66.9 | 62.2 | 63.1 |
| internlm2-20b-reward | 74.4 | 26.1 | 61.7 | 74.5 | 68.4 | 58.7 | 56.4 |
| + side-branch SRM | 79.1 | 47.4 | 59.8 | 76.5 | 68.7 | 64.6 | 64.3 |
几个值得停下来看一眼的数字:
- InternLM2-20B:56.4 → 64.3,整体涨 7.9 个点。其中 RM-Bench Hard 子集从 26.1 飙到 47.4,涨了 21 个点——这是真正的难题集合,能拉这么多说明侧支真的帮到 RM 看清细节
- InternLM2-7B:52.0 → 63.1,涨 11.1 个点
- Llama3-8B Instruct:11.3 → 60.8,看起来涨了快 50 个点,吓人
但说实话,第三条数据我得吐槽一下。Llama3-8B Instruct 不是一个 RM,它是个 Instruct 模型,直接拿来当 RM 用 baseline 是 11.3% 太低了——这个 baseline 本身就不公平。真正公平的 baseline 是 InternLM2-7B/20B-Reward 这两条。+11.1 / +7.9 才是 SRM 真实的"增益天花板"。这个数依然能打,但远没有 +50 那么炸裂。
我看到 Llama3-8B Instruct 这一行的时候第一反应是有点皱眉的——把 11.3% 的 base 拉到 60.8% 写进主表,多少有点用低难度参照系冲分的意思。当然作者也写了 "internlm2-7b 提升 11.1%" 这种相对实在的数字,但主表里那个 Llama3 数据放在那里,视觉冲击力实在太强。
消融:哪个旁支最值钱
这一块是论文里我觉得最有信息量的部分。
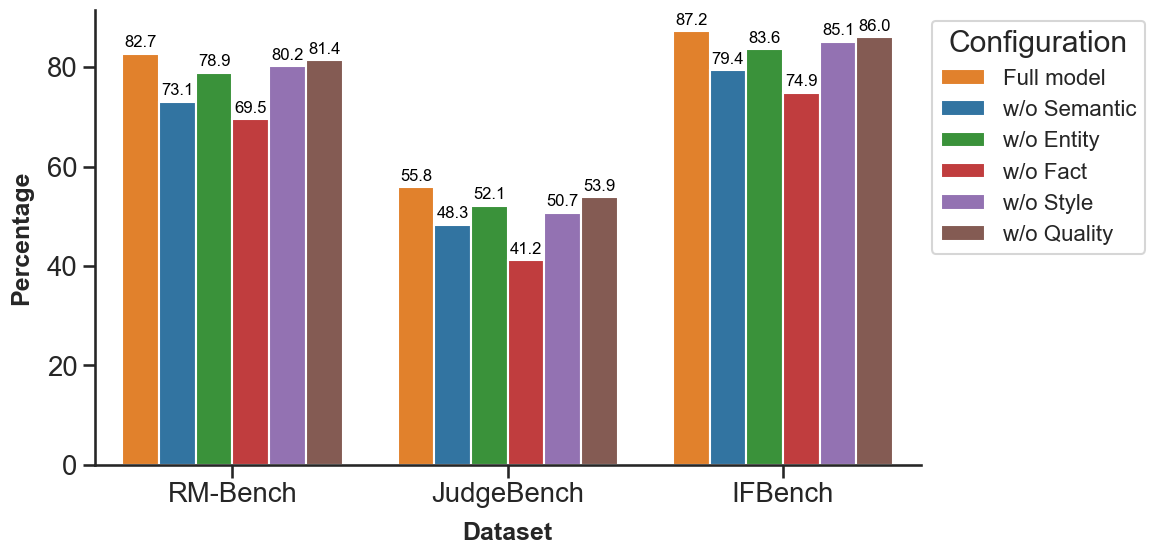
图3:消融柱状图。橙色是 Full SRM,后面五个分别是逐个移除 Semantic / Entity / Fact / Style / Quality 后的剩余性能。结论一目了然——红色(移除 FactCheck)掉得最猛。
具体掉点幅度:
| 移除模块 | RM-Bench 掉点 | JudgeBench 掉点 | IFBench 掉点 |
|---|---|---|---|
| w/o Fact-Checking | -13.2% | -14.6% | -12.3% |
| w/o Semantic | -9.6% | -7.5% | -7.8% |
| w/o Entity | -3.9% | -3.7% | -3.4% |
| w/o Style | -2.5% | -5.1% | -2.1% |
| w/o Quality | -1.3% | -1.9% | -1.2% |
读到这里我有个挺直觉的判断:FactCheck 是真正的杀手锏。三个 benchmark 上掉点最厉害的都是它,尤其是 JudgeBench 这种偏知识与推理的集合,砍掉 FactCheck 直接掉 14.6 个点。这跟工业现实是对得上的——大多数 critical bad case 都是事实硬错误。
Semantic 排第二也合理。Style 和 Quality 的边际贡献最小,2 个点以内,存在感主要在风格敏感的场景。
这个消融最大的工程启示是:如果资源不够搞五个旁支,先上 FactCheck + Semantic 这两个,能拿到大部分增益。这是论文里没有显式说但数据非常清晰的结论。
工业 deployment 上的真实数字
论文还在 1.8M 偏好样本的工业训练集上跑了一组对照实验,用 InternLM2-20B 作 base,分别在 DPO / PPO / GRPO 三种 RL 算法下对比 Vanilla-RM 和 SRM。测试集是 15 万条 black-box 真实样本。
| RL 方法 | RM 类型 | Accuracy | Knowledge | Hallucination↓ | Creativity | Complex |
|---|---|---|---|---|---|---|
| DPO | Vanilla-RM | 78.1 | 78.8 | 14.5 | 75.2 | 61.2 |
| DPO | SB-RM | 81.6 +3.5 | 81.9 +3.1 | 8.6 −5.9 | 79.5 +4.3 | 67.5 +6.3 |
| PPO | Vanilla-RM | 81.7 | 80.6 | 15.1 | 77.8 | 62.7 |
| PPO | SB-RM | 84.0 +2.3 | 82.1 +1.5 | 8.8 −6.3 | 81.7 +3.9 | 68.9 +6.2 |
| GRPO | Vanilla-RM | 82.2 | 80.6 | 13.7 | 78.5 | 62.9 |
| GRPO | SB-RM | 84.4 +2.2 | 82.4 +1.8 | 8.2 −5.5 | 82.8 +4.3 | 68.4 +5.5 |
幻觉率从 13~15% 一律压到 8.x%,这是这组实验里我觉得最有工程价值的数字。SB-FactCheck 在线上是真起作用的。复杂推理 +5.5 ~ +6.3 也很扎实。
还有一点比较重要:在 DPO / PPO / GRPO 三种算法下,SRM 的相对增益基本一致(+2 到 +6 区间)。这说明这套结构化信号是 RL 算法无关的——你换底层优化器,它的 alpha 还在。这点对工业落地非常重要。
推理效率:4 倍速度优势是怎么来的
这是论文 Appendix D 的数据:
| Method | Public Dataset | Industrial Dataset |
|---|---|---|
| Scalar RM | 18.7s / 1k | 21.3s / 1k |
| GRM | 92.5s / 1k | 106.1s / 1k |
| SRM | 22.8s / 1k | 25.4s / 1k |
Scalar RM 是 18.7s,SRM 是 22.8s——多了 4 秒,因为多跑了 5 个旁支。但旁支可以并行,所以总耗时不会线性叠加。GRM 因为是 sequential decoding,必须把整个 CoT 一个 token 一个 token 解出来才能拿到 reward,所以慢了 4 倍多。
我在公司之前部署 GRM 类方案的时候,最痛的就是 latency。一个 GRM CoT 平均要解 200-500 token,按 50 tokens/s 算就是 4-10 秒一个样本,根本扛不住线上流量。SRM 这种"固定数量旁支并行"的设计,把"自由生成的不可预测 latency"换成了"K 个固定生成长度的并行 latency",这个工程性质远比想象中重要。
一个比较走心的 case study
论文 Table 3 给了一个特别能说明问题的对比例子:
Prompt: "Discuss the health effects of daily caffeine consumption."
Chosen(事实更新、有引用): "Moderate caffeine intake (300-400mg/day) may enhance cognitive performance. Recent studies suggest potential cardiovascular benefits when consumed without added sugars (NIH, 2023)."
Rejected(引用了 1995 已撤稿的研究): "Coffee causes heart disease and bone loss. A 1995 study proved caffeine directly weakens bones (Journal of Old Medicine)."
| 维度 | 原始 RM | SRM |
|---|---|---|
| Semantic Understanding | 检测到 1995 研究过时,时效性问题 | 现代研究与 prompt 语义高度相关 |
| Entity Expansion | <咖啡; 缺点; 刺激肠胃> | <咖啡; 益处; 降低心血管疾病风险> |
| Fact Checking | 验证失败,标记为 2005 年已撤稿 | 验证通过 |
| 主 RM 评分 | r_c: 0.52, r_j: 0.68 ❌ | r_c: 0.91, r_j: 0.32 ✅ |
| 最终判定 | 错误:偏向 Rejected | 正确:偏向 Chosen |
这个 case 把 SRM 的价值讲得最清楚——原始 RM 看到 Rejected 写得"煞有介事、有研究编号、有具体数字"就给了高分;SRM 的 FactCheck 旁支独立验证之后,发现引用的研究已被撤稿,把分压下来了。结构化信号对抗"伪权威感"是个真实存在的问题,不是 paper 里堆出来的虚假优势。
几点比较冷的判断
写到这里我想把一些我对这篇论文的真实看法说一下。
这是工程整合还是底层突破?
坦率讲,这是工程整合。SRM 的核心思想——多个专门评估器并行 + 信号融合——并不新鲜。LLM-as-Judge 时代有 Prometheus 系列、有 Self-taught Evaluator、有 Critique-out-Loud、还有 Wang et al. 2024 的 ArmoRM(多目标 RM 路由)。
SRM 的新意主要在两点: 1. 维度切分基于工业 bad case 归因,不是拍脑袋——SB-Semantic 占 bad case 38.7% 这种数据是从真实场景提炼的,这个"Defect-Centric"方法论挺值得借鉴 2. 保持主 RM 不变,旁支以辅助文本注入——这是个有点反直觉但很聪明的设计。比起改主 RM 架构,用文本注入的方式让整个东西可以无痛替换现有 RM 流水线
但从底层贡献角度,这不是 GRPO 那种"改了 RL 目标函数"级别的贡献。
5 个 LoRA 旁支的成本被低估了
论文一直强调 SRM 比 GRM 高效,但有个事实 paper 里没强调:SRM 训练 + 部署 5 个 LLaMA3-8B LoRA + 1 个主 RM,参数量上比 scalar RM 多了不是一点。虽然推理可以并行,但你要养这一堆模型——5 套数据采集、5 次 LoRA 训练、5 个推理服务实例(或共享 GPU 时分复用),这个工程成本不低。
如果你的场景没那么大流量,老实点用一个 7B 的 GRM 然后 batch 推理,可能反而简单。SRM 真正适合的是高吞吐 + 维度可控诊断需求强的工业场景——搜推、风控、客服 QA 这种。
拼接长度问题(论文自己也承认了)
论文 Limitations 里写得很坦白:5 段辅助文本一拼,输入序列就长了。如果每段 100-200 tokens,5 段就是 500-1000 tokens。叠在原 prompt+response 后面,主 RM 的有效上下文就被挤压了。在长文本评估场景下,这个 concat 方案估计会爆。论文也提到"future work 探索更高效的融合机制",这个口子留得诚实。
评测集选取我有点想吐槽
主表把 Llama3-8B Instruct(base 11.3%)放进来跟 SRM(60.8%)对比,视觉上确实震撼,但这是拿"未经任何 RM 训练的 Instruct 模型"作 baseline,太不公平。真正能说明 SRM 价值的是 InternLM2-7B/20B-Reward 这两条对比的 +11.1 / +7.9。这个增益放到 RewardBench 类基准上其实不算夸张,业界 ArmoRM、Skywork-Reward 这种正经 RM 工作也能做到类似量级,只是它们用的是不一样的路径(多目标头 / 数据增强)。
所以 SRM 最值钱的卖点不是"分高",而是"模块化可解释 + 比 GRM 快 4 倍 + 维度可独立优化"这个组合包。把它和 ArmoRM 这类多目标 RM 比,SRM 的优势在于"信号生成可以是文本而非分数",灵活度更高;劣势在于工程开销更重。
对工程同学的几点启发
我自己看完论文,觉得这几个 takeaways 比较值得放进工具箱:
- Bad case 归因驱动设计:SRM 的五个旁支不是凭直觉拍的,是 N-fold CV + 归因得出来的。如果你也在搞 RM,先把线上 bad case 分类聚类,看它们集中在哪些维度,再去决定要不要做结构化信号
- 如果资源紧张,先做 FactCheck + Semantic 两个旁支:消融数据非常清楚,这两个贡献 70%+ 的增益
- 辅助文本注入比改主 RM 架构更稳:保持下游 BT-RM 不变,你就可以无痛升级现有 RM pipeline。这个设计哲学值得借鉴
- LLM-as-Judge 数据过滤是必备一环:BoN 采样产生的辅助文本质量参差不齐,靠人工审不现实,用一个稍强的 LLM 过滤是 cost-effective 的工业方案
- GRM 在线部署延迟超预期是常态:如果你还在用 GRM 跑线上 RM 评估,SRM 这种"固定数量并行旁支"的思路至少可以测一测,4 倍 speedup 是真实可期的
收尾
SRM 不是一篇会让你拍案惊奇的论文,它没有提出新的 RL 目标函数、没有重新定义 reward 建模范式。但它把"工业 RM 在 GRM 黑盒和 scalar 浅薄之间该怎么走"这个问题给出了一个相当扎实的工程答案。
读完之后我有种"嗯,下次自己做 RM 项目这思路得放进选项"的感觉。它把"特征工程"这个词在 LLM 时代的位置摆正了——不是 ML 旧时代的遗物,而是当你需要可控、可诊断、可分维度优化的时候,依然是最直接的解法。
这类方法可能会成为未来工业级 RM 部署的一个常见范式:scalar RM 做基线,GRM 做难 case 兜底,SRM 这种结构化方案做主力。每种各有各的甜蜜区。
至于这篇论文有没有把所有问题都解决——当然没有。维度切分粒度是不是合适、辅助文本拼接的长度爆炸怎么办、旁支模型本身的偏差怎么校正、不同领域是不是要重新设计旁支——这些都还是开放问题。但 paper 把"为什么要走结构化路线"这件事讲清楚了,这就够了。
如果你也在做 RM 相关的工作,这个思路值得放在备选方案里。尤其是如果你的场景是搜索、推荐、客服、内容审核这种单领域 + 评估维度相对清晰的场景,SRM 的工程性价比可能比你想象的高。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我