Agent别再"想都不想就动手"了:SAND教大模型先在脑子里把候选动作走一遍
核心摘要
做过Agent调优的同学应该都碰到过这个尴尬:用专家轨迹SFT出来的Agent,看上去推理一套一套的,真实任务里却经常"想都不想就动手"——Thought里写了个看似合理的理由,Action就直奔一个错的动作而去。这篇EMNLP 2025的SAND(Self-taught Action Deliberation)想解决的就是这件事:让Agent在每一步committed到某个动作之前,先把几个候选动作在脑子里"走一遍",比一比再下手。整个流程是自学习的——不引入额外的人工标注,也不训单独的Reward Model,靠基座模型自己采样、自己评、自己合成思考过程,再迭代SFT回去。结果是Llama-3.1-8B在ALFWorld unseen上从71.6干到96.3,平均提升20%以上,关键是它没用任何inference-time search。一句话评价:思路很干净,对"什么时候该想、想什么"这件事给出了一个比硬上Best-of-N便宜得多的方案,工程上是可以直接借鉴的。
论文信息
- 标题:SAND: Boosting LLM Agents with Self-Taught Action Deliberation
- 作者:Yu Xia, Yiran Jenny Shen, Junda Wu, Tong Yu, Sungchul Kim, Ryan A. Rossi, Lina Yao, Julian McAuley
- 机构:加州大学圣地亚哥分校(UCSD)、Adobe Research、新南威尔士大学(UNSW)、CSIRO's Data61
- 会议:EMNLP 2025 Main,pages 3062–3077
- arXiv:2507.07441v2
- ACL Anthology:2025.emnlp-main.152
一、从一个让人皱眉的失败案例说起
先看作者放在论文开头的那张图,挺典型的:
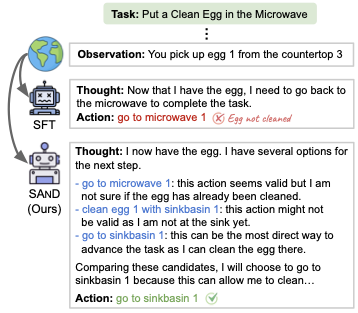
图1:SFT Agent 直接走向微波炉,理由是"我现在拿到鸡蛋了,得回微波炉去完成任务"——听起来挺顺,但鸡蛋还没洗。SAND Agent 先列了三个候选动作,每个都过了一遍判断,最后才选了"去水池清洗"这个对的动作。
任务是"把一个干净的鸡蛋放进微波炉"。Agent刚刚拿起了鸡蛋。
SFT训出来的Agent是怎么想的?"我现在拿到鸡蛋了,得回微波炉去完成任务。Action:go to microwave 1。"看上去逻辑没毛病——拿到东西,去目标地点。但鸡蛋还没洗,这一步就废了。
我之前在做交互式Agent的时候,这种case见过太多了。模型对"看上去合理"的动作有种近乎本能的偏爱。这个"近乎本能"的根源,其实是训练时的偏好——SFT只看到一条专家轨迹的推理 + 动作,模型学到的是"在这种状态下,输出这个动作的概率最高",而从来没有被要求在脑子里把别的候选动作过一遍。
你说我用DPO/preference optimization呢?也帮助有限。DPO比的是两条整轨迹的优劣,粒度太粗——它告诉模型"这条轨迹比那条好",但不会告诉模型"在第3步这个状态下,动作A比动作B好,因为A会让你下一步看到鸡蛋是脏的"。step-level的对比,常规的偏好学习根本碰不到。
这就是SAND要做的事情:在每个非trivial的决策步上,让Agent先把几个候选动作在内心走一遍,列出来比较,再下手。 而且整个学习过程不引入额外的人工标注、不引入PRM/价值模型,全靠基座模型自己采样、自己评论、自己合成"deliberation thought"。
二、为什么这件事不trivial:两个绕不开的核心问题
听起来"让模型多想想"很容易——Tree-of-Thought、Reflexion、Best-of-N,这条路上的工作不少。但真要落到Agent场景上,有两个坑:
第一个坑:动作空间往往很大,甚至无界。 ALFWorld有13个原子动作但要组合,ScienceWorld有19个,WebShop更夸张——商品检索query是自由文本。让模型每一步都对"所有可能的动作"deliberate,根本跑不动。
第二个坑:reward很稀疏。 多轮交互任务里,往往只有任务结束那一刻才知道成败。中间某一步选了哪个动作好哪个坏,没有step-level的监督信号。这也是PRM、Q-value model、Process Reward Model这一系列工作要解决的痛点——但训这些额外模型的代价不便宜。
SAND的回答其实就两句话:
- 什么时候deliberate? 用self-consistency判断——基座Agent对当前state采样N个动作,如果都一样,说明模型很确定,没必要想;如果有分歧,那就该停下来想想。
- 想什么、怎么想? 拿采样出来的几个候选动作,实际在环境里rollout执行一遍,根据执行结果(中间观察+最终reward)让基座LLM写一段critique;再把所有critique喂回基座LLM,合成一条"思考过程"。
这两个判断让SAND的开销卡在了一个比较甜蜜的点上——后面会看到,它平均只比SFT Agent多花2-3倍token,但比Best-of-N(5倍)省不少。
三、方法核心:四步走的自学习pipeline
整个框架可以用作者这张图概括:
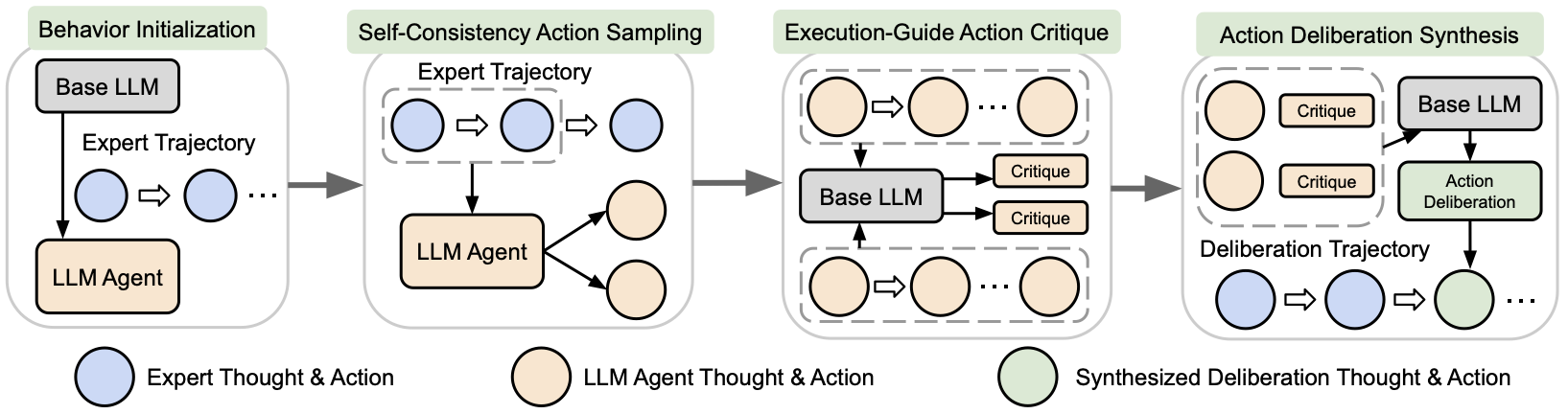
图2:从左到右依次是 Behavior Initialization(基座SFT热身)、Self-Consistency Action Sampling(基于专家轨迹分支采样N个候选动作)、Execution-Guided Action Critique(每个候选动作rollout后由基座LLM写评论)、Action Deliberation Synthesis(综合所有critique生成一段deliberation thought)。最后这条带绿色节点的"deliberation trajectory"就是迭代SFT的训练数据。
这套pipeline本质是个self-distillation的循环:用基座模型自己生成更高质量的训练数据,回头喂给自己。每一步都拆开聊聊。
3.1 行为初始化(Behavior Initialization)
老规矩,先在专家ReAct轨迹上做一轮SFT,让模型学会"思考-动作-观察"的基本格式和这个任务的basic behavior。损失函数就是标准的负对数似然:
这一步很常规,不展开。重点是后面的循环。
3.2 自一致性动作采样:决定"什么时候该想"
这是我个人觉得这篇论文最干净的设计。
对每条专家轨迹\(e\),作者用当前的Agent策略\(\pi_\theta\)重放一遍,在每一步的状态\(h_{t-1}\)上分支采样:以一个比较高的temperature(论文里是1.0)采样\(N=5\)个候选动作\(\hat{a}_t^{(1)}, \dots, \hat{a}_t^{(5)}\),加上原始专家动作\(a_t\),凑成一个大小为\(N+1=6\)的候选集。
然后定义一个"是否需要deliberate"的指示函数:
翻译成大白话——这6个动作里只要去重后还剩多个不同的,就该deliberate;如果6次采样全部撞上同一个动作,说明模型很确定,跳过。
这个idea借鉴了self-consistency在数学推理里的用法(一个问题让模型采样多次,如果答案高度一致就置信度高)。在Agent场景里这么用,挺巧妙的。它同时回答了两个问题:
- 什么时候想:分歧大的步就想,所有人投同一票就跳过;
- 想什么:就想这几个分歧的候选动作,不去随机探索整个动作空间。
而且因为采样的起点是专家轨迹上的真实状态,候选动作既贴近专家分布、又贴近当前模型策略分布,避免了在巨大动作空间里瞎逛的开销。
3.3 执行引导动作评论:决定"想得有没有信息量"
光列出几个候选动作还不够——你怎么知道哪个好哪个坏?要给基座LLM足够的信息去judge。
作者的做法是:对每个候选动作\(\hat{a}_t\),真的把它在训练环境里rollout执行一遍,得到完整的中间observation序列\(\hat{e}_t\)和最终reward \(r_t\)。然后把这些喂给基座LLM,让它写一段critique:
prompt设计得挺有讲究——它把这次rollout称为"Private Mental Simulations"(你在脑内做的仿真),让模型用第一人称写3句话以内的"Action Evaluation",而且禁止直接引用rollout的具体内容、也禁止提到自己得到了"外部帮助"。这是为了让生成的critique看起来像是模型的"内心判断",而不是单纯的rollout结果摘抄。
prompt里还特意鼓励模型记录"可复用的常识"(比如"鸡蛋一般会放在冰箱里"),这种 verbalized commonsense 比纯数值的MC估计要informative得多——也是这套方案比QLASS这类训Q-value model的工作更轻量的关键。
我个人觉得这个设计挺有启发的。它其实绕过了"训一个专门的PRM"这条贵路子,用基座LLM自己当critic。代价是每个候选动作都要真rollout一次(环境调用开销),但好处是critic不需要单独训练、不需要标签。在像ALFWorld、ScienceWorld这种调用便宜的环境里,这笔账划得来。
3.4 动作思考综合:把critique融成一段deliberation thought
有了所有候选动作 + 各自的critique,下一步是把它们捏成一段连贯的"思考过程"\(\tilde{z}_t\):
prompt里有个让我会心一笑的细节——它会告诉基座LLM最终的Action必须是\(a_t\)(专家动作),写的所有内容都要自然地导向这个选择。这其实是个"逆向合成"的小trick:先有正确答案,再让模型组织出导向这个答案的思考过程。这样合成出来的训练数据,既包含了对所有候选的分析、又保证了最终action是对的。
合成出来的轨迹\(\tilde{e}\)长这样:保留专家的observation \(o_t\)和action \(a_t\),但把原来的thought \(z_t\)替换为新合成的更长更深思熟虑的\(\tilde{z}_t\)。
注意作者在论文里特别说了一句:只有当\(\mathbf{1}_{\text{delib}}(t)=1\)那些步才有deliberation thought,其他步保留专家原本的简单thought。 这就让训练数据天然带有"什么时候该深思、什么时候直接动手"的信号——这点后面会反复用到。
3.5 迭代深思微调
把所有deliberation轨迹收集起来\(\mathcal{D}_{\text{delib}}\),再做一轮SFT:
然后把\(\mathcal{D}_{\text{exp}} \leftarrow \mathcal{D}_{\text{delib}}\),再开一轮采样-评论-合成-训练。论文做了\(I=3\)轮迭代。
inference时的关键点:训出来的Agent推理时不再做任何采样——不像Best-of-N那样真的在线展开多个分支。它在一次forward里把整个deliberation thought 加 final action 一起生成出来。也就是说,所有"采样多个候选 + 执行rollout + 合成评论"的开销,全部摊在了离线训练阶段。inference时它依然是一个普通的ReAct Agent,只是thought部分变长了、变得"会权衡"了。
这个设计是这篇论文真正划算的地方——把test-time的expensive search蒸馏成了模型本身的能力。
四、实验:数字会说话
4.1 主表:在两个交互式benchmark上压住SOTA
作者在ALFWorld和ScienceWorld上跑了主实验,分seen / unseen test set。
| 模型 | Sci-Seen | Sci-Unseen | ALF-Seen | ALF-Unseen | 平均 |
|---|---|---|---|---|---|
| GPT-4o (prompting) | 60.0 | 56.0 | 78.6 | 83.6 | 69.6 |
| Llama-3.1-70B (prompting) | 72.6 | 70.2 | 78.6 | 73.9 | 73.8 |
| Llama-3.1-70B + MPO | 80.4 | 79.5 | 85.7 | 86.6 | 83.1 |
| Qwen-2.5-7B + SFT | 69.2 | 60.8 | 72.1 | 75.4 | 69.4 |
| Llama-3.1-8B + SFT | 75.6 | 65.1 | 79.3 | 71.6 | 72.9 |
| Llama-3.1-8B + ETO | 81.3 | 74.1 | 77.1 | 76.4 | 77.2 |
| Llama-3.1-8B + KnowAgent | 81.7 | 69.6 | 80.0 | 74.9 | 76.6 |
| Llama-3.1-8B + WKM | 82.1 | 76.5 | 77.1 | 78.2 | 78.5 |
| Llama-3.1-8B + ETO&MPO | 83.4 | 80.8 | 85.0 | 79.1 | 82.1 |
| Qwen-2.5-7B + SAND (Iter 3) | 84.0 | 69.0 | 90.7 | 94.8 | 84.6 |
| Llama-3.1-8B + SAND (Iter 1) | 86.6 | 77.5 | 92.9 | 91.8 | 86.0 |
| Llama-3.1-8B + SAND (Iter 2) | 88.7 | 78.2 | 94.3 | 94.0 | 88.8 |
| Llama-3.1-8B + SAND (Iter 3) | 85.7 | 79.1 | 94.3 | 96.3 | 88.9 |
表1:主实验结果(Average Reward),SAND 在 Llama-3.1-8B 上拿到 88.9 的平均分,比初始 SFT (72.9) 提升 16 个绝对点,超过 ETO&MPO 这种 Llama-70B + 多Agent的方案。
几个值得圈出来的点:
第一个,绝对涨幅是真大。 Llama-3.1-8B从SFT的72.9涨到88.9,绝对+16,相对+22%——作者在abstract里说的"average 20% improvement"是基于这个比例。这个幅度在Agent调优领域算"很能打"了。
第二个,unseen task涨幅更猛,甚至超过seen task。 ALFWorld unseen从71.6涨到96.3——这个数我反复确认了一下,是真的。一般我们看到模型在unseen上比seen表现更好都会先怀疑数据泄漏或者评估有水分,但这里作者给了个挺合理的解释:deliberation的本质是教Agent"先分析未知动作的影响、再下手",这种能力在unseen scenarios上反而比纯模式匹配更管用。
第三个,7B/8B模型超过了Llama-70B + MPO。 Llama-70B + MPO是个多Agent协同(meta planner + executor)的方案,平均83.1。SAND用单Agent的8B模型干到88.9——这个对比挺有意思,说明把"think harder"内化到模型里,比堆参数量、堆Agent数量可能更划算。
说实话,看到unseen涨这么猛我第一反应是"是不是evaluation有问题"。 翻了下论文,evaluation协议是温度=0、跟MPO baseline用同一套prompt,这部分应该没水分。比较合理的解释还是deliberation在OOD场景上的迁移性更好——毕竟模式匹配在unseen上很容易翻车,而"列候选-比一比"这个行为本身是任务无关的。
4.2 消融实验:哪个组件最重要?
作者把SAS(Self-consistency Action Sampling)和EAC(Execution-guided Action Critique)分别去掉,看效果掉多少。
| 方法 | Sci-Seen | Sci-Unseen | ALF-Seen | ALF-Unseen |
|---|---|---|---|---|
| Llama-3.1-8B | ||||
| Base | 47.7 | 42.2 | 22.9 | 28.4 |
| SFT | 75.6 | 65.1 | 79.3 | 71.6 |
| SAND w/o SAS | 70.3 | 62.0 | 85.7 | 77.3 |
| SAND w/o EAC | 78.6 | 73.7 | 85.0 | 86.6 |
| SAND (full) | 86.6 | 77.5 | 92.9 | 91.8 |
表2:消融实验。w/o SAS = 不做自一致性采样、直接让基座LLM在context里凭空想出N个候选动作;w/o EAC = 不执行rollout、直接基于N个候选动作合成思考。
这张表挺能说明问题:
w/o SAS甚至会拖累性能。 Llama-3.1-8B + SAND w/o SAS 在 Sci-Seen 上反而比 SFT 低了5.3个点。作者的解释挺接地气——他们看了失败case的trajectory,发现没有自一致性采样的话,基座LLM在context里凭空想出来的N个"候选动作"经常和任务goal完全不相关,甚至会出现"反复重复同一个候选动作直到撑爆context"的退化行为。
这个发现其实有点反直觉——你可能想"反正都让基座LLM想,让它直接想N个候选不也一样吗?"实际上不一样:基座LLM在没有prior signal的情况下,并不知道哪些动作是模型当前真实纠结的、哪些是无关的。Self-consistency采样提供的是"当前策略真实分布上的不确定性"这个信号,这是基座模型自己想不出来的。
w/o EAC的损失小一些。 不做rollout、直接让基座基于动作字符串本身做critique,结果还是比SFT好(在Llama上78.6 vs 75.6 on Sci-Seen),但比full SAND差了约10个点。这说明rollout提供的grounded信息(执行后看到了什么、最终reward多少)确实让critique质量上了一个台阶——这跟我们之前在Agent项目里的经验一致,纯靠模型self-evaluate是有上限的,必须给真实的环境反馈。
4.3 deliberation rate随迭代的变化:模型真的学会"什么时候该想"了吗?
这是论文里我个人最喜欢的一组分析。作者把ScienceWorld unseen tasks按基座模型的reward分布切成三档:Hard、Medium、Easy。然后看每一档上Agent的"deliberation rate"(一个trajectory里有多少步触发了深思)。
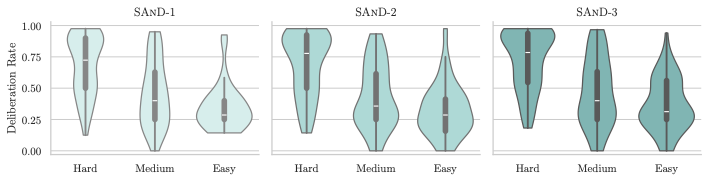
图3:从左到右是迭代1、2、3的deliberation rate分布。Hard任务上median稳定在0.75左右且随迭代逐渐变宽,Easy任务上median稳定在0.30左右——模型真的学会了"难任务多想、简单任务少想"。
看图:
- Hard任务上中位数稳定在0.75左右——大部分step都触发深思
- Easy任务上中位数稳定在0.30左右——大部分step跳过深思直接动手
- 从iter 1到iter 3,Hard band的小提琴顶部还在变宽,意思是越来越多的Hard task会触发更高比例的deliberation
这就回应了前面方法里的设计——因为训练数据里"deliberation thought"只在inconsistent的步上才出现,模型自然学到了"当我对动作没把握时才需要长篇大论的深思"。这个"自适应深度"是从数据分布里emergent出来的,不需要在inference时显式控制。
我觉得这个分析比单纯刷分有价值多了。它证明了SAND不是"无脑加长每一步thought",而是真的让模型学到了元能力:自己判断什么时候该谨慎、什么时候可以快速。
4.4 step-level reward与deliberation rate的相关性
作者还画了个柱状图+折线图,展示每一步的平均reward(柱子)和平均deliberation rate(折线)。
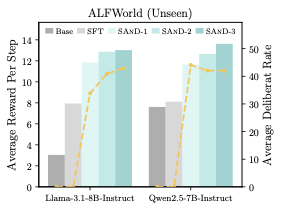
图4:随着SAND迭代,per-step reward 和 deliberation rate 同时上升,且deliberation rate的提升伴随着任务完成更早、step效率更高。
从图上能读出几个信息:
- per-step average reward在每一轮SAND之后都在涨,且Iter 1涨幅最大、后面涨幅递减——self-distillation的典型收敛pattern;
- deliberation rate也在涨——说明模型越来越愿意在关键步上花心思;
- 两条线一起涨,说明deliberation的边际收益是正的,不是"为了deliberate而deliberate"。
4.5 推理开销:贵不贵?
这是个绕不过去的问题——deliberation天然要写更长的thought。作者老老实实给了token开销表。
| 方法 | ALFWorld | ScienceWorld |
|---|---|---|
| SFT | 498.3 | 800.0 |
| SAND (Iter 1) | 1,314.2 (2.6×) | 2,411.9 (3.0×) |
| SAND (Iter 2) | 1,105.8 (2.2×) | 2,522.1 (3.2×) |
| SAND (Iter 3) | 1,146.2 (2.3×) | 2,253.6 (2.8×) |
表3:每个任务平均 token 数。括号里是相对 SFT 的倍数。
平均比SFT多花2-3倍token。和Best-of-5(5倍开销)比,确实划算。而且注意Iter 1到Iter 3的token数还在轻微下降——说明随着模型越来越会判断"什么时候该想、什么时候不该想",平均开销在自适应缩减。
我觉得这个开销在工程上可以接受。如果你的Agent现在每个任务平均500 token,加上deliberation变成1300 token,但任务成功率从70%干到95%——大多数业务场景这账都划得来。
4.6 与PRM/Q-value model派的对比(附录里的彩蛋)
作者还在附录里跟QLASS、AgentRM这些"训单独value/reward model + test-time search"的方案做了个对比。
| 方法 | 训Base Agent | 训单独PRM/Value | Inference策略 | WebShop | ALF Unseen | Sci Unseen |
|---|---|---|---|---|---|---|
| QLASS (Llama-2-7B) | ✓ | ✓ | 6 actions/step | 70.3 | 82.8 | 66.4 |
| AgentRM-BoN (Llama-3-8B) | ✓ | ✓ | Best-of-5 traj | 71.0 | 94.8 | 76.1 |
| AgentRM-Beam (Llama-3-8B) | ✓ | ✓ | 25 actions/step (5×5 beam) | 75.3 | 96.3 | 82.6 |
| SAND (Llama-3.1-8B) | ✓ | ✗ | 1 action/step (no sampling) | 72.4 | 96.3 | 79.1 |
表4:SAND vs PRM/Q-value 派对比。SAND 不训单独的reward/value模型、inference时也不做任何采样,但效果跟训了PRM + 跑5×5 beam search的AgentRM-Beam几乎打平。
这张表是我觉得这篇论文真正"漂亮"的地方。SAND不训第二个模型、inference时一次forward搞定,效果跟AgentRM-Beam(训了PRM + 跑5×5=25 actions/step)打平甚至更好。这件事的价值在于:
- 离线把贵的事情做完:所有的rollout、critique、合成都在training time
- inference时回归普通Agent:没有额外延迟、没有额外模型load
- 可以叠加test-time search:作者也提到这两条路是orthogonal的,未来想用PRM-guided search可以叠加在SAND-tuned Agent上面
五、我的判断:好在哪、问题在哪
5.1 真正打动我的几个设计
self-consistency作为"何时deliberate"的信号——这个idea非常cheap但非常对。 它不需要训额外的controller,不需要规则,就用模型自己采样的分散程度判断置信度。简单而漂亮。
用基座LLM做critic + 真rollout作为grounding——避开了训PRM的痛苦。 训PRM要标step-level数据,又贵又难标。SAND相当于把"PRM的功能"分解成"基座LLM的语言能力 + 环境真实反馈"——前者免费、后者只在training time调用,inference时全部shut off。
逆向合成deliberation thought——告诉模型"最终答案必须是\(a_t\)"再让它组织思考过程。 这个设计避免了"合成的思考过程导向了一个错误的最终action"这种数据污染问题。属于典型的"知道终点后再生成路径"的synthesis trick,挺老实的。
5.2 几个我会皱眉的地方
第一,self-consistency的判断标准其实有点粗糙。 作者用的就是"6次采样里去重后是否>1",这是个二元flag。在动作空间稍大或temperature稍高的场景下,几乎每一步都会触发分歧——那deliberation就退化成"每步都做"了。论文里没看到对N、temperature的敏感性分析,这块其实挺关键。
第二,rollout的开销在training time也不是免费的。 每个候选动作要在环境里完整跑到结束。ALFWorld、ScienceWorld这种文本环境调用便宜,但放到Web Agent或者真实API调用场景,rollout成本会爆炸。WebShop那一组实验作者把N从5降到3,部分应该也是出于这个考虑。
第三,"专家动作必须是终点"这个假设挺强的。 论文里也意识到了这点,提了个optional的expert switch机制——如果Agent探索出比专家更好的轨迹就替换。但作者在ScienceWorld上主动关闭了这个switch,因为发现训练集上的"shortcut"反而会hurt测试集表现。这其实暴露了self-distillation的老问题——模型可能学到训练集特有的捷径。
第四,对比的SOTA其实不算最强baseline。 ETO&MPO是2024-2025年的工作没错,但同期一些用RL(不只是DPO)做Agent training的方案没进表里。如果要比信息密度,跟RFT/RLAIF系的方案对比可能更公平。当然这有点苛刻,论文里至少跟PRM派做了附录对比,态度是诚恳的。
第五,"unseen比seen还高"这个现象需要更细致的分析。 作者只给了一个直觉解释,但没有更深入的实验验证(比如对unseen tasks按"动作组合是否在训练集出现过"再细分,看deliberation的增益主要来自哪类unseen)。这个观察本身很有价值,但解释可以再扎实一点。
5.3 这套思路对工程的启发
如果你现在在做Agent调优,我觉得SAND至少有三件事可以直接抄:
- 用self-consistency作为"是否需要更深思考"的廉价信号——不一定要做整套pipeline,就这一个trick用在你现有的Agent上做in-context的early-exit或budget分配,应该就有效果
- 训练数据里混合"长思考"和"短思考"轨迹,让模型从分布里学到自适应深度,而不是统一做长CoT
- 把test-time的expensive search蒸馏到training time——这是个通用思路,不只SAND,DeepSeek-R1那条线也是这个哲学
我自己最近在做一个工具调用Agent的项目,碰到的痛点就是模型对"call哪个工具"的判断不够稳——之前我们的方案是上Best-of-3 sampling,开销有点重。看完这篇我觉得可以试试用SAND风格的离线合成把决策过程内化掉。
六、收尾:一类越来越普及的"先想后做"范式
回头看这篇论文在AI Agent这条线上的位置——它不是底层突破,更像是把"自我蒸馏 + step-level critique + 自适应深思"这几条相对成熟的思路,在Agent场景下做了一次非常干净的整合。
如果说o1/R1那条线证明了"教模型思考更长能换来更好的reasoning",那SAND证明的是"把这套思考方式拓展到带环境交互的Agent场景上,靠合成数据 + 迭代SFT就能work"。这两个方向其实在向同一个地方汇——让模型把'内在的deliberation'当成默认行为,而不是靠inference-time hack来实现。
对于做产品落地的人来说,这条路最大的吸引力是:训练成本不便宜(要做rollout),但部署时跟普通Agent一样轻。在LLM推理服务越来越卷的今天,这个性价比其实挺关键的。
最后留一个我自己也没想清楚的问题——SAND的核心assumption是"专家动作就是最优的",但在很多真实场景里专家轨迹本身是noisy的(人类标注者也会犯错、自动化生成的expert也未必最优)。如果把"基于专家动作的deliberation合成"换成"基于自我探索找到的更优动作的deliberation合成",会不会让模型走得更远?这就走到了RL的领地——SAND的下一步,也许就是和policy优化更深度地结合起来。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我