RethinkMCTS:让MCTS会"反省",把走歪的思路改对再继续搜代码
你有没有调过这种Agent——一开始写不出对的代码,于是它"反思"一下,把错误总结进memory,下一轮搜索带着这堆错误日志再写。结果呢,memory越堆越长,思路越绕越乱,有时候比第一轮还差。
这就是当前主流"搜索+反思"代码生成方法的真实状态。LATS、Reflexion那一套,看着合理,跑起来你会发现一个怪现象:错误日志加得越多,模型越"心累",反而开始绕弯。
EMNLP 2025这篇RethinkMCTS的切入点,正好是这个我自己实战时也踩过的坑。它的核心idea一句话——别再往memory里堆错误了,直接把那个写错的"思路节点"改掉,让搜索树沿着改正后的路径继续走。
核心摘要
代码生成这种高推理任务,单次生成往往不够,需要搜索+反馈迭代。问题在于:现有方法(LATS、Reflexion)要么直接在代码空间搜索,绕过了真正决定代码质量的reasoning过程;要么把错误堆进memory做"反思",让搜索路径里的错误节点永远留在那儿,越搜越累。
RethinkMCTS的做法是把MCTS的搜索动作从"代码"换成"思路"(thought),然后引入一个rethink机制——当某个节点对应的代码跑挂了public test,就用block-level的细粒度执行反馈,直接重写这个节点的thought本身,让搜索树后续从修正过的思路继续展开。配合public test pass rate和LLM自评的双重打分,搜索的方向感更稳。
数据上,APPS Comp.(最难的竞赛级)pass@1 从GPT-4o-mini的23涨到28,HumanEval从93.29涨到94.51。比LATS这种"反思流"在APPS Intro.直接高出9个点。token开销还更省——同等性能下比reflection少烧20-35%。
我的判断:这不是一篇底层突破,是一次"换个动作空间"的精巧重构。但rethink这个动作设计得真挺对——把"积累错误"换成"修正错误",节点级地修,不动祖先节点的奖励,工程上也很干净。值得在自己的代码Agent里试一下。
论文信息
- 标题:RethinkMCTS: Refining Erroneous Thoughts in Monte Carlo Tree Search for Code Generation
- 作者:Qingyao Li, Wei Xia, Xinyi Dai, Kounianhua Du, Weiwen Liu, Yasheng Wang, Ruiming Tang, Yong Yu, Weinan Zhang
- 机构:Shanghai Jiao Tong University, Huawei Noah's Ark Lab
- arXiv:https://arxiv.org/abs/2409.09584(v2版本,EMNLP 2025)
- 代码:https://github.com/SIMONLQY/RethinkMCTS
一、为什么"反思+搜索"这套组合拳越打越疲
先说背景。代码生成现在公认有两条增强路径:一是借助代码执行的反馈(pass/fail、报错信息),让模型自我修复;二是用搜索算法(典型如MCTS)探索多个生成可能。LATS这篇工作把两条路打通了——MCTS负责搜,每次失败的错误总结进memory,下一轮选代码时把memory喂进prompt当"教训"。
听上去很合理。问题在哪?
第一个问题:搜索粒度搜的是代码,没碰到真正的"思路"。
代码生成本质是个推理重头戏。同样的问题,"用嵌套循环O(n²)比较"和"先排序再相邻比较O(n log n)"是两种完全不同的reasoning。如果搜索动作直接是代码token或代码片段,模型其实是在"已经决定怎么想"的前提下挑细节。真正决定结果的——那个"决定怎么想"的步骤——根本没被搜索到。
CoT和Tree of Thoughts早就告诉我们,显式建模推理过程会带来更好的效果。但代码生成这个高推理需求的领域,迄今的搜索方法基本还在代码层操作。
第二个问题:反思机制说到底只是在"记账",不解决问题。
这是我觉得这篇论文最尖锐的一个观察。LATS、Reflexion这类方法的反思,做法是:失败了→总结错误→存进memory→下次prompt里带着。
但仔细想想:
- 错误的那个推理路径,还在搜索树里。下一次搜索还是可能选到它的子节点
- memory里的错误日志会越堆越长,到后面prompt负担巨大,模型反而抓不住重点
- 关键是——它没告诉模型怎么想才对,只告诉它"上次错在哪"
打个比方,你写代码bug了,老板的反馈是"你昨天那个写得不对",但不告诉你哪儿不对该怎么改。你只能自己猜。
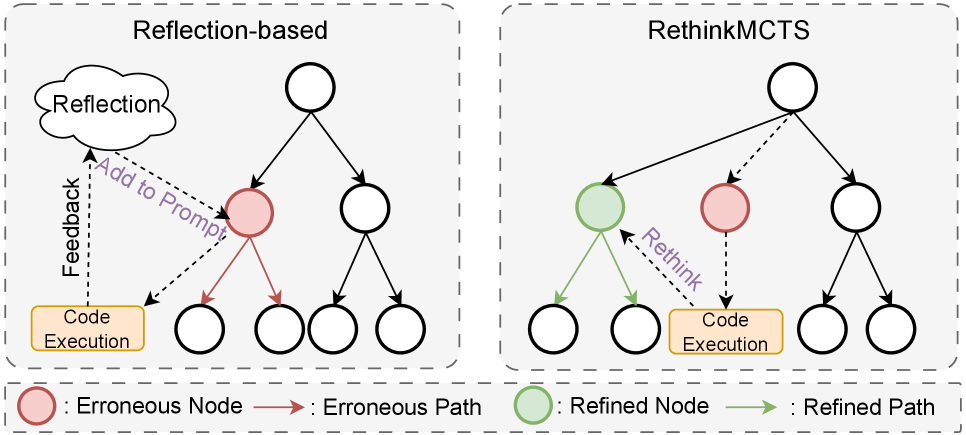
图1:左边是传统reflection-based方法,错误节点(红)会留在搜索树里,错误路径继续被探索,反思只是把错误"贴到prompt上"。右边是RethinkMCTS,发现错误节点后通过rethink把它改成正确节点(绿),后续搜索沿着改正过的路径展开。
这张图把两种范式的差别画得相当清楚。Reflection是"错误留着,旁边贴张便签";Rethink是"错误就地改掉"。
我之前在做一个代码Agent项目时,确实碰到过这个现象——用Reflexion的思路跑了多轮后,agent的输出反而开始震荡,每次都在两三个错误版本之间来回切。当时我的猜测是反思prompt太长导致模型注意力被冲淡。看完这篇论文,我觉得更本质的原因是:搜索路径里的错误节点没被清理,模型一直在"踩着错误的脚印"前进。
二、RethinkMCTS的三个核心设计
整个框架可以归结为三件事:搜思路而不是搜代码,用block级反馈做修正,用双重评估打分。
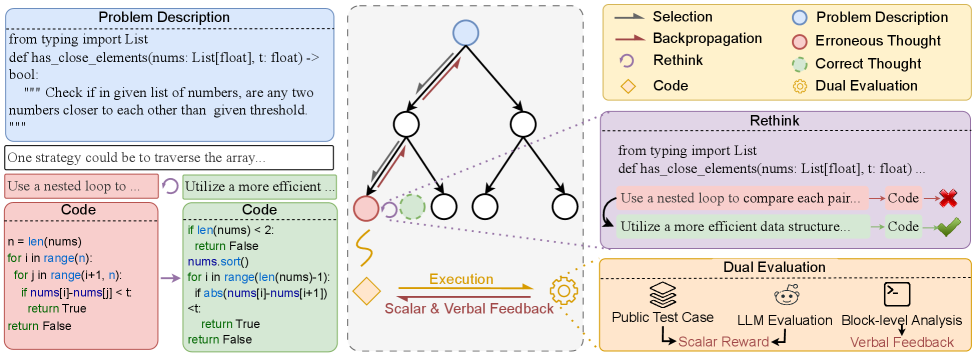
图2:RethinkMCTS框架总览。MCTS在思路空间中搜索(中间的搜索树,每个节点是一个thought),到叶节点后基于积累的thoughts生成代码并执行。如果失败,block-level分析作为verbal feedback反喂回去,rethink操作直接把错误的thought节点重写(图中红→紫色高亮的节点)。最终评估同时使用public test pass rate和LLM自评。
2.1 搜思路:把MCTS的动作空间换掉
传统PG-TD那类做法,MCTS的action是token或代码片段。RethinkMCTS把action定义为"下一步思路"——一段自然语言的reasoning step。
具体是怎么搜的?P-UCB打分公式还是经典那套:
其中 \(s\) 是"当前问题描述+已有thoughts序列",\(a\) 是新提的一个thought。\(p(a|s)\) 由LLM给出(每个thought生成时附带一个Reasonableness分),\(\beta\) 控制探索权重。这个数学结构和AlphaZero那套P-UCB一模一样,没什么花哨的。
关键是动作空间换了。在expansion阶段,LLM根据"问题+已积累的thoughts"提出k个候选thought(论文里k=3),每个带一个0~1的Reasonableness分(且总和为1)作为先验。搜到叶节点后,把当前路径上的所有thoughts拼起来作为"指导",再调一次LLM生成完整代码。
为什么这样做更好?看第6节的granularity实验——
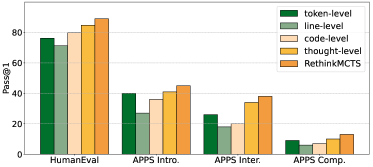
图4:在GPT-3.5-turbo上比较token-level、line-level、code-level、thought-level四种搜索粒度的pass@1。橙色(thought-level)整体最高,但论文里RethinkMCTS(金黄色)在thought的基础上加了rethink,进一步拉开差距。
有意思的是token-level居然能比line/code-level好。论文给了一个挺工程的解释:在rollout预算有限的情况下,token-level给早期token的约束最少,反而探索面更大。但thought-level整体最稳。
这个观察对自己做code agent有启发——如果你的搜索预算不够(rollout数受限),优先在reasoning层搜,别在代码细节上搜。
2.2 Rethink:直接重写错误节点
这是这篇论文最核心的贡献,也是名字的来源。
当某个节点的代码跑失败了public test,传统做法是把"失败"这件事记到memory;RethinkMCTS的做法是:
- 拿到block-level的执行反馈 \(f\)(具体是什么下面讲)
- 让LLM根据 \((s, f, z^{\text{old}})\) 生成新的thought \(z^{\text{new}}\)
- 就地把这个节点的thought替换掉,节点的子树丢弃,重新展开
注意一个细节——它只重写当前出错的节点,不动祖先节点。论文给了两条理由:
- 祖先节点已经累计了来自多个子节点的reward,重写会让这些奖励作废
- 祖先节点要么自己已经rethink过,要么当时没failure,没必要再动
这个设计挺克制的。我看过一些类似工作动不动就要重做整个trace,工程上巨贵。RethinkMCTS只动当前节点,配合MCTS"逐步增长"的特性——错误的节点最终都会有机会被refine——既保持了树的稳定,又解决了错误传染问题。
prompt也很直接(论文Appendix C.4):
Based on your previous thoughts and the new experience, please provide a new Thought to replace the previous thought. This new thought should avoid the mistake.
注意末尾——"replace the previous thought"。它就是赤裸裸地告诉模型:把上一句话改了。不是"接着写",不是"补充思考",是**改掉**。
### 2.3 Block-level反馈:让"反馈"真有信息量
光说"代码错了"是没用的反馈。论文这里继承了LDB(Zhong et al., 2024)的思路——把代码切成basic block,跟踪每个block的变量状态,让LLM对每个block打"correct/false"标签并解释。
举个论文Appendix里的真实例子。问题:找n的最大真除数(小于n)。模型的代码:
```python
def largest_divisor(n):
for i in range(int(math.sqrt(n)), 0, -1):
if n % i == 0 and i < n:
return i
return 1
跑 largest_divisor(15),期望返回5,实际返回3。
光看这个错误信息,模型可能瞎改半天。block-level分析做的事是:
- BLOCK-0:循环初始化 i=3。正确——平方根开始没毛病
- BLOCK-1:检查
n % i == 0 and i < n。错误——3确实是15的因数,但不是最大的 - BLOCK-2:
return 3。错误——应该continue找更大的因数
这套分析的关键不是"告诉你哪儿错了",而是"告诉你为什么错"。它已经定位到了根因——循环方向反了,应该从更大的数开始。
把这个塞进rethink prompt,模型就能给出"应该从n//2开始向下找"这样的修正thought。
工程上这个block-level的实现有个隐藏成本——你得跑一遍代码、构建CFG、追踪变量状态,再让LLM分析。token开销会涨。论文Table 5里RethinkMCTS的input token是123207,是PG-TD的4-5倍。但作者的态度是:"我们不是来优化token的,我们是来生成更好代码的"——这个taking挺直接,反正o1也是这样烧tokens的。
2.4 Dual Evaluation:public test不够用怎么办
MCTS评估节点需要一个标量reward。最直接的做法是用public test pass rate。但这有个问题——很多代码能过public test但过不了private test。HumanEval平均只有2.8个public test,APPS平均27.52个,单看public test根本区分不出谁更对。
所以作者加了一个LLM self-evaluation:
只有当代码通过了所有public test时,才让LLM额外打一个"这代码看起来对吗"的分(范围-1到1)。论文用的是 \((a, b) = (0.8, 0.2)\)。
这里有个细节挺值得琢磨——为什么 \((0.8, 0.2)\) 而不是 \((1.0, 0.2)\)?看Table 3的对比:
| \((a, b)\) | APPS Intro. Pass@1 | APPS Inter. Pass@1 | APPS Comp. Pass@1 | HumanEval |
|---|---|---|---|---|
| (0.8, 0.2) | 59 | 49 | 28 | 94.5 |
| (1.0, 0.2) | 60 | 53 | 27 | 92.7 |
| (1.0, 1.0) | 60 | 54 | 24 | 91.5 |
\((0.8, 0.2)\) 的设计哲学是:通过全部public test的代码,最高分0.8+0.2=1.0;没全过的代码,分数最高0.99。也就是说,public test的pass率不到100%的代码,理论上仍然可能比一个全通过但LLM打分极低的代码总分高。
为什么这样反而能多探索?因为如果用 \((1.0, b)\),所有"全过public test"的代码总分恒大于1.0,而搜索树会立刻向这些节点倾斜,那些 pass率 0.95 但LLM明显感觉很对的reasoning路径会被早早抛弃。
这个trade-off挺微妙。表面看是个超参,实际是探索和利用的边界控制。\((0.8, 0.2)\) 在最难的APPS Comp. 上效果最好,因为难题更需要不被public test假阳性误导。
三、实验结果:到底涨了多少?
3.1 主实验:APPS + HumanEval
论文设了两组backbone(GPT-3.5-turbo / GPT-4o-mini),对比了8种baseline,最大rollout=16。我把核心数据整理成下面这张表:
| Backbone | 方法 | APPS Intro. PR | APPS Inter. PR | APPS Comp. PR | Avg PR | HumanEval pass@1 |
|---|---|---|---|---|---|---|
| GPT-3.5-turbo | Base(1) | 50.43 | 40.57 | 23.67 | 38.22 | 70.12 |
| Base(16) | 66.77 | 62.65 | 25.50 | 51.64 | 81.71 | |
| LATS(反思流) | 54.06 | 45.86 | 21.83 | 40.58 | 79.88 | |
| LDB(block分析debug) | 56.68 | 46.78 | 21.00 | 41.49 | 81.09 | |
| Reflexion | 53.20 | 45.58 | 17.50 | 38.76 | 71.95 | |
| ToT | 62.56 | 57.97 | 28.00 | 49.51 | 76.22 | |
| RethinkMCTS | 67.09 | 68.65 | 29.50 | 55.08 | 89.02 | |
| GPT-4o-mini | Base(1) | 56.56 | 52.40 | 35.00 | 47.98 | 87.20 |
| Base(16) | 67.79 | 66.25 | 38.50 | 57.51 | 93.29 | |
| LATS | 69.46 | 67.65 | 35.83 | 57.65 | 93.29 | |
| LDB | 60.64 | 60.78 | 40.33 | 53.91 | 90.85 | |
| ToT | 71.03 | 67.84 | 37.17 | 58.08 | 92.68 | |
| RethinkMCTS | 76.60 | 74.35 | 42.50 | 64.48 | 94.51 |
(PR = Pass Rate)
几个观察:
第一,最显著的提升出现在GPT-3.5-turbo上。HumanEval从81.71(Base 16次采样)涨到89.02,差了7.3个点。论文给的解释是:弱模型更受益于thought过程的纠错。这个解释我基本认同——强模型本身reasoning能力强,提升空间小;弱模型的瓶颈往往就在"想不清楚",rethink正好补这块。
第二,APPS Inter.(中等难度)的pass rate直接从LATS的45.86拉到68.65,差了22.8个点。这个数其实有点惊人——传统search方法在中等难度上提升有限,rethink反倒在这里发力。我猜原因是:Inter.难度的题目通常"思路对了一半就能过部分test",正好给block-level分析留出了精确归因的空间,rethink能修对那一半错的reasoning。
第三,Reflexion在GPT-3.5上APPS Comp.只有17.5,还不如Base(1)。这其实暴露了反思流的一个隐患——错误日志堆久了,模型反而被带偏。这个现象自己跑Reflexion的时候我也观察到过,论文这里数据更直接。
3.2 消融实验:哪个组件最关键
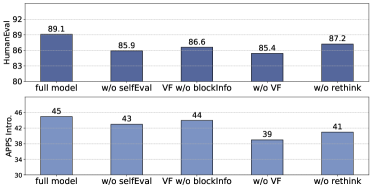
图3:消融实验。full model是完整RethinkMCTS。w/o selfEval去掉LLM自评(Reward只用public test pass rate),VF w/o blockInfo是verbal feedback只保留代码错误信息不做block-level分析,w/o VF是完全去掉verbal feedback,w/o rethink是去掉rethink机制只保留搜索。HumanEval上full=89.1,w/o rethink=87.2,w/o VF=85.4,w/o blockInfo=86.6。APPS Intro.上full=45,w/o VF=39,差6个点。
这张图的key takeaway:
- w/o VF掉得最多(HumanEval 89.1→85.4,APPS 45→39)。verbal feedback是整个rethink机制的"信息源",没了它rethink也无米下炊
- w/o rethink掉了2个点(HumanEval 89.1→87.2)。这其实印证了"光有反馈不够,得有动作"
- w/o blockInfo(只去掉block-level细节,保留普通错误信息):HumanEval掉得明显(86.6),APPS掉得不明显(44)。论文解释这是因为HumanEval的test case少(平均2.8个),test case本身信息量不足,必须靠block分析挖深
- w/o selfEval:HumanEval下降3.2个点。public test cases覆盖不全的时候,LLM自评提供了关键的区分度
3.3 Rethink vs Reflection的直接对决
这个对比是论文最有说服力的实验——把RethinkMCTS的rethink换成reflection,其他全保持不变。
| Dataset | Reflection pass@1 | Rethink pass@1 | Reflection token | Rethink token |
|---|---|---|---|---|
| APPS-Intro. | 54 | 59 (+9.2%) | 177353 | 143048 (-19.3%) |
| APPS-Inter. | 45 | 49 (+8.9%) | 163494 | 126648 (-22.5%) |
| APPS-Comp. | 24 | 28 (+16.6%) | 189215 | 182193 (-3.7%) |
| HumanEval | 93.29 | 94.51 (+1.3%) | 57027 | 36678 (-35.7%) |
效果更好(+1.3% ~ +16.6%),token还更省(最多省35.7%)。这个数据真挺能打的。
为什么省token?因为reflection要不断把过往错误堆进prompt,prompt长度随着搜索轮次线性增长;rethink只是局部修改一个节点,不需要在后续prompt中维护错误历史。
3.4 Test Time Scaling:rethink vs more rollouts
这是我觉得很有工程味的一个实验。同样的总rollout预算,是花在rethink上更值,还是花在多跑几次MCTS更值?
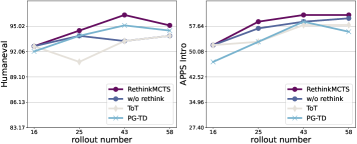
图5:左HumanEval,右APPS Intro。横轴是总rollout数(16/25/43/58),紫色是RethinkMCTS(部分预算用于rethink),灰色是w/o rethink但增加rollout数。从40+ rollouts开始,紫色明显甩开灰色。
结论很清晰:同等预算下,把budget花在rethink上比单纯增加搜索次数更划算。
这个finding对实际系统部署有意义。如果你在做code agent,预算紧张的时候,与其增加beam_size或者跑更多rollout,不如把预算花在"修正搜出来的错误路径"上。
另一个佐证数据来自Table 4——w/o rethink时整个搜索树里能通过public test的代码占比是10.04%(APPS Intro.),加上rethink后涨到15.60%。也就是说,rethink让搜索树整体的"健康度"提高了。
四、几个我觉得值得讨论的问题
4.1 这是真创新还是工程整合?
坦率讲,单看每个组件,都不是新东西:
- 思路级搜索 ≈ ToT + MCTS的拼接
- block-level分析直接来自LDB
- LLM self-evaluation是常规操作
- P-UCB公式是AlphaZero那套
那RethinkMCTS的核心贡献在哪?我觉得是rethink这个动作本身——把"积累错误"换成"修正错误",并且只修当前节点不动祖先。这个设计简单但很对。
很多论文的"创新"是堆组件,RethinkMCTS反过来——它没堆,它把reflection这一个组件改了,效果直接上来了。
4.2 token开销真的能接受吗
主实验数据看着漂亮,但代价是token狂烧。Table 5里RethinkMCTS在APPS Intro.的input token = 123207,对比PG-TD的27827,4.4倍。
作者的态度是"我们不优化token",但实际部署里这就是现实问题。HumanEval一题烧0.009美元、APPS一题烧0.029美元(GPT-4o-mini价位),跑1000题就是几十美元。如果换成GPT-4或更强的模型,价格会显著上去。
工程落地层面,我觉得有两个方向值得探索:
- block-level分析能不能做缓存/简化?很多简单错误其实不需要全套CFG分析
- rethink能不能选择性触发?不是每次失败都rethink,可以根据错误类型筛
4.3 generalization的边界在哪
论文Limitations部分自己也承认了——RethinkMCTS依赖"详细的执行反馈",代码生成正好有这个条件(编译器、调试器、CFG分析)。换到数学题、写作、对话生成这些领域,没有那么细粒度的反馈,整个rethink机制就跑不起来。
不过反过来想,任何能拿到"分步骤可验证反馈"的任务,都有可能套用这个框架。我能想到的几个候选:
- 工具调用:每次API call成功/失败可以提供block级反馈
- SQL生成:执行结果对/错可以做语句级归因
- 数学题中的可验证步骤:比如某些代数变换可以独立验证
但需要的反馈基础设施都不便宜。这块之后哪个团队能做出"通用反馈分析模块",可能会成为下一个增长点。
4.4 一个隐藏的问题:rethink的target怎么选
论文里rethink的target永远是"当前出错的节点"。但作者自己在Limitations里也提到:错误的根因可能在更早的祖先节点。当前实现是"信MCTS的增量增长——错误祖先终归会被它的子节点rethink波及"。
这其实是个偷懒的设计。如果加一个verifier专门判断"错误根因在哪一层",效果应该会更好。但这又会引入新的复杂度。论文留作future work,挺合理的。
五、给做代码Agent的工程启发
如果你也在做code agent,这篇论文有几个直接可以借鉴的点:
1. 把搜索动作从代码层提到思路层。这个改动改动不大,但收益挺直接。哪怕你不用MCTS,单纯在prompt里"先生成多个thought,每个thought独立做code generation+evaluation",再选最好的,也能立竿见影。
2. 失败时不要光"反思",要"重写"。这是这篇论文最值得带走的一句话。memory累积错误是一个看起来合理但实际有副作用的设计——它让agent的注意力被错误版本污染。当你发现一个推理步骤走错时,就地改它,比贴一张"曾经错过"的便签有效得多。
3. block-level归因比"代码错了"信息量大得多。无论你用不用MCTS,给failure case提供细粒度的归因信息,都会大幅提升模型的修复能力。这个不是论文新发现,但RethinkMCTS给了一个干净的工程实现可以参考。
4. dual evaluation的设计哲学。当你的primary metric(如pass rate)有覆盖盲区时,加一个secondary metric(如LLM self-eval)做扰动。注意reward上限不要直接覆盖primary,否则探索性会丢。\((0.8, 0.2)\) 这种anti-saturation的设计值得借鉴。
收尾
这篇论文不是底层突破。它没改训练,没改模型,没引入新模态。它做的事是把现有组件用一个更对的姿势组合起来——把"积累错误"换成"修正错误",把"在代码空间瞎搜"换成"在思路空间搜+按需修"。
但也正是这种"姿势"上的精巧,让它在同等设置下比一众baseline高出可观幅度,且token还省了。这种工作我蛮喜欢的——不假装自己是革命,只是把一件事做得更对。
最后留一个问题给读者:rethink的核心是"refine current erroneous thought",但怎么定义"erroneous"?现在的实现依赖public test的pass rate。如果连public test本身都覆盖得不全(论文里HumanEval平均2.8个),rethink的触发条件其实是有偏的。这是个值得挖的方向——更好的"错误检测器"+rethink,可能才是这套范式的最终形态。
如果你也在做code agent,这篇论文的代码开源了,跑通APPS的成本不算高,值得自己实测一下。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我