让奖励模型先"想清楚"再打分:R-PRM 把 PRM 从打分器升级成推理者
EMNLP 2025 | R-PRM: Reasoning-Driven Process Reward Modeling
作者:Shuaijie She, Junxiao Liu, Yifeng Liu, Jiajun Chen, Xin Huang, Shujian Huang
机构:南京大学新型软件技术国家重点实验室 · 中国移动通信有限公司研究院
arXiv:2503.21295 | 代码:NJUNLP/R-PRM
一个让我皱眉很久的现象
如果你跑过 PRM(Process Reward Model),大概率碰到过这种事情:模型把一道题做错了,但每一步的过程分都给得挺高,置信度还都在 0.9 以上。你看着 PRM 的输出会有点恍惚——它到底是在评分,还是在猜?
ProcessBench MATH 数据集里有这么一个例子。题目是找最小的两位数质数且其反转数不是质数(emirp 的反例)。模型的解题过程在 Step 7 跳过了对 19 的检查,直接到 Step 8 检查 23。这是一个明显错误,因为 19 反过来是 91(91 = 7×13,不是质数)——23 根本不是答案,19 才是。
主流 PRM 的反应?Qwen2.5-Math-PRM-7B 给 Step 8 打了 0.99,Qwen2.5-Math-7B-PRM800K 给了 0.86。两个最强的开源 PRM,都在为一个错误的步骤背书。
这不是这一个 case 的问题。这是当前一代 PRM 的结构性问题——直接输出标量分数的判别式模型,没有"思考"的空间,错了也说不清错在哪。
R-PRM 这篇 EMNLP 2025 的工作,就是冲着这个结构问题去的。它的核心动作只有一个:让 PRM 先生成一段结构化的分析推理,再给出 Yes/No 判断。听起来朴素,但效果是真的能打。
核心摘要
PRM 训练数据极度稀缺(PRM800K 一共就那么多人工标注),而当前 PRM 又普遍采用判别式打分,学习信号窄、可解释性几乎为零。R-PRM 用一套巧得很的 bootstrap 方案绕开了数据瓶颈:拿 LLaMA3.3-70B-Instruct 当种子模型,在 PRM800K 已有的标签上反向"补"出 5 维度的分析过程,得到约 28.9 万条 SFT 样本和 26.9 万条偏好对。在 Qwen2.5-Math-7B-Instruct 上 SFT + DPO 训出 R-PRM-DPO,ProcessBench 上 F1=70.4(比同等数据量的 PRM800K 基线高 11.9 个点)、PRMBench 上 F1=66.8(高 8.5 个点);用它来做 Best-of-8 引导推理,6 个数学评测集上比 Qwen2.5-7B-Instruct 的 pass@1 平均涨 8.6 个点。更妙的是,因为是生成式 PRM,推理时还能 sample K 条评估轨迹做平均——K 从 1 到 32 单调上涨。
我对这篇论文的评价偏正面:思路算不上原创(用大模型生成 critique 这条路 LLM-as-Judge 早就在走),但把"PRM = 推理者"这个想法做扎实了,工程上 SFT→DPO→inference scaling 三段式很顺,关键是数据效率确实漂亮——6.4 万样本就追平了 Qwen 在 26.5 万样本上训出来的 PRM。值得花时间细读,特别是如果你正在做 PRM/Reward Model 相关的工程。
为什么需要这篇论文:判别式 PRM 的三个内伤
PRM 的故事最早是 OpenAI 那篇 Let's Verify Step by Step(Lightman et al., 2023)讲清楚的。相比只看最终答案的 ORM(Outcome Reward Model),PRM 给每一步打分,理论上能定位错误更精确、信用分配更合理。但落到工程上,PRM 一直有三个老大难:
第一,数据极度稀缺。PRM800K 是人工标注,800k 步骤标签听起来不少,问题数量其实只有 12k 道。后来 Math-Shepherd 走 Monte Carlo 估计、Qwen2.5-Math-PRM 上 LLM-as-Judge 加滤噪——前者贵得离谱(每个题要 rollout 几十次),后者降噪不彻底。真正的瓶颈是高质量的 step 级评估数据,到 2025 年还没解决。
第二,判别式打分把学习信号压扁了。一个 step 对不对,判断难度其实非常高——需要看上下文、追溯前置假设、复算关键公式。让模型直接吐一个标量,等于把所有这些复杂判断压缩进 logit。模型学得吃力,效果还有上限。这是我自己跑 PRM 训练时最直观的感受——loss 收敛得慢,到头来效果还是不太稳。
第三,没有可解释性。判别式 PRM 给个 0.87 是什么意思?这步对一半?这步在数据来源上有问题?还是计算错了?拿到下游做 RL 训练或者 BoN 选择时,这个分数缺乏诊断价值。如果 PRM 误判了一个错误步骤,你连诊断 PRM 自己的能力都没有。
R-PRM 的破题思路其实很直接:既然 step 评估本身就是个推理任务,那就让 PRM 像做题一样推理。模型先写一段结构化的分析("先看前面几步在干嘛、再看当前步的目标和数据来源、检查一致性、复算结果"),然后基于这段分析给 Yes/No。这个范式有几个好处:
- 学习信号变密了——SFT loss 是整段 critique 的 token-level 交叉熵,比单个标量有信息得多
- 天然带可解释性——critique 就是诊断报告
- 可以做推理时 scaling——sample 多条 critique 取平均,K 越大越准
听起来朴素,但要把它做 work,得解决"哪来这么多带 critique 的训练数据"。这就是 R-PRM 真正的工程价值所在。
方法核心:从 PRM800K 标签反推 critique
R-PRM 的整体框架可以用一句话概括:用强 LLM 反向生成 critique,SFT 让小模型学会推理评估,DPO 优化推理过程,推理时再多采样取平均。
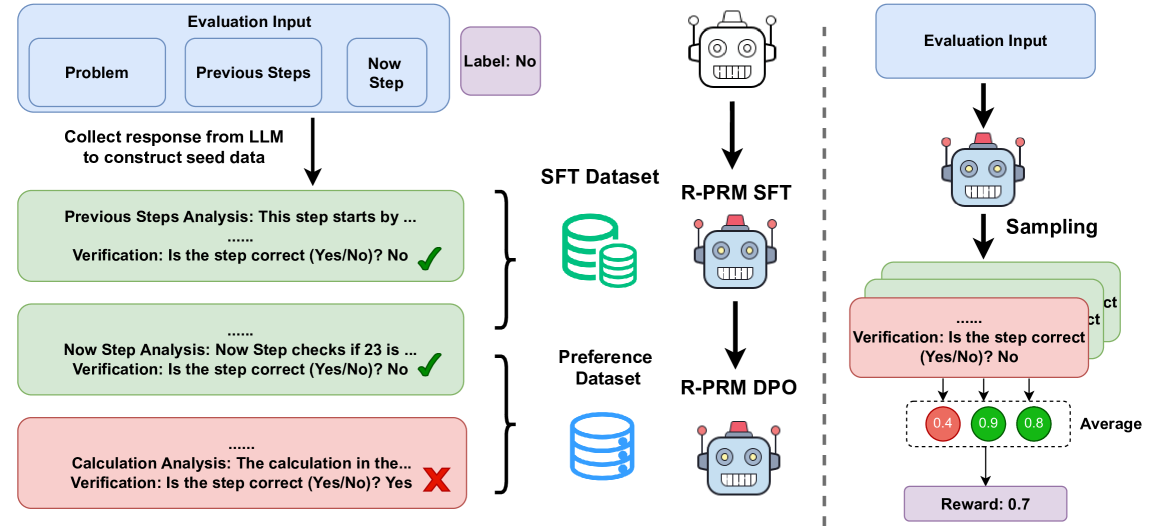
图1:R-PRM 框架总览。绿色机器人代表训练后的模型,白色代表初始模型。左边的关键设计是"Collect response from LLM to construct seed data"——让强模型生成多条候选 critique,按 Yes/No 判断与人工标签是否一致筛选成正负样本。
Step 1: 用 LLaMA3.3-70B 给 PRM800K"补 critique"
PRM800K 原本只有"step 是否正确"的二值标签。R-PRM 的做法是:拿 LLaMA3.3-70B-Instruct 作为 teacher,针对每个 step 生成 4 条候选评估轨迹。每条轨迹包含五个维度的分析:
- Previous Steps Analysis:前面的步骤每一步在干什么、是否有错
- Now Step Analysis:当前步骤在做什么、试图解决问题的哪一部分
- Data Source Analysis:当前步骤用了哪些数据、来源是否合理一致
- Consistency Analysis:当前步骤与前面是否逻辑自洽,内部是否一致
- Calculation Analysis:涉及计算时反向验算
最终输出 "Verification: Is the step correct (Yes/No)? X" 的判断。只有 teacher 的判断与 PRM800K 人工标签一致的轨迹才被保留——这一步至关重要,等于用人工标签做了过滤器,把强模型的 critique 中靠谱的那部分蒸馏出来。
最终拿到大约 28.9 万条 SFT 样本,平均每个 step 不止一条 critique。重点是没有引入任何新的人工标注,全是在现有 PRM800K 上做的扩展。
Step 2: SFT 训练 R-PRM-7B-SFT
用 Qwen2.5-Math-7B-Instruct 作为 base model,把上面的 (Q, \(s_{1:i}\), \(A_i\), \(J_i\)) 拼成目标序列做指令微调:
其中 \(Y_i = A_i \oplus J_i\) 是 critique 加判断的完整序列。和普通的 instruction tuning 一模一样,没有任何特殊 trick。这点其实让我挺意外的——按我之前做 reward model 的经验,往往要在 loss 上加各种约束(比如对最终判断 token 加权),R-PRM 直接整段 token-level CE 就 work 了。
训完之后就是 R-PRM-7B-SFT。在 ProcessBench 上拿到 F1=65.2,已经超过了主流的 PRM baselines。
Step 3: 用 DPO 优化推理过程,零额外标注
这一步是我觉得最巧的。生成式 PRM 有个判别式 PRM 没有的属性——你可以对同一个 step 让模型 sample 多条 critique,然后看哪些导出了正确判断。
具体做法:对训练集里每个 step,让 R-PRM-7B-SFT 采样多条评估轨迹。
- 最终判断与人工标签一致的 → 作为偏好的 winner \(Y^w\)
- 判断不一致的 → 作为 loser \(Y^l\)
用标准 DPO loss 优化:
注意整个过程没有引入新的标注数据,偏好对完全来自 SFT 模型自己 sample 的轨迹 + 已有的 PRM800K 标签做监督信号。这是利用了"生成式"这个范式自带的优势——同样的 input 可以采样出无数条不同的 critique,而最终判断对不对又有 ground truth 可对比。
这一步得到约 26.9 万条偏好对,DPO 训完得到 R-PRM-7B-DPO。在 ProcessBench 上 F1 从 65.2 涨到 70.4,5.2 个点的提升靠的是已有数据的二次榨取——这个数据效率,挺漂亮的。
Step 4: 推理时多采样 + 平均聚合
判别式 PRM 给一个 step 一个分数就完了。R-PRM 因为是生成式的,可以在推理时采样 K 条评估轨迹:
然后聚合方式是取 K 条轨迹中"yes"概率的均值:
默认配置 K=10。这个设计借鉴了 self-consistency / majority voting 那一套思路,但因为每条轨迹是完整 critique,所以信息融合发生在 reward 层而不是 token 层。说到底就是用更多 inference 算力换更稳定的奖励信号。
实验结果:数据效率是真亮点
ProcessBench:F1 从 58.5 涨到 70.4
ProcessBench 是 Zheng et al. 2024 提出的,覆盖 GSM8K / MATH / OlympiadBench / OmniMATH 四个难度递增的子集,共 3400 条测试样本。任务是识别推理过程中的第一个错误步骤(或者确认全部正确)。
| 模型 | GSM8K | MATH | OlympiadBench | OmniMATH | Avg. F1 |
|---|---|---|---|---|---|
| GPT-4o | 79.2 | 63.6 | 51.4 | 53.5 | 61.9 |
| o1-mini | 93.2 | 88.9 | 87.2 | 82.4 | 87.9 |
| Qwen2.5-72B-Instruct (judge) | 76.2 | 61.8 | 54.6 | 52.2 | 61.2 |
| Math-Shepherd-7B | 47.9 | 29.5 | 24.8 | 23.8 | 31.5 |
| RLHFlow-DeepSeek-8B | 38.8 | 33.8 | 16.9 | 16.9 | 26.6 |
| Skywork-PRM-7B | 70.8 | 53.6 | 22.9 | 21.0 | 42.1 |
| Qwen2.5-Math-7B-PRM800K | 68.2 | 62.6 | 50.7 | 44.3 | 58.5 |
| Qwen2.5-Math-PRM-7B (1.8M data) | 82.4 | 77.6 | 67.5 | 66.3 | 73.5 |
| R-PRM-7B-SFT | 77.2 | 71.6 | 59.6 | 52.3 | 65.2 |
| R-PRM-7B-DPO | 80.7 | 76.9 | 63.8 | 60.1 | 70.4 |
几个值得说道的点:
第一,11.9 个点从哪来。论文摘要里那个 "surpasses strong baselines by 11.9 points" 指的是和 Qwen2.5-Math-7B-PRM800K(58.5)的对比——同样基于 PRM800K 训练的判别式 baseline。R-PRM-DPO 70.4 - 58.5 = 11.9。这个对比是公平的,因为两个模型用的是同一份原始标注数据,差异完全在范式(生成式 vs 判别式)和训练流程(SFT+DPO vs 单阶段判别)上。
第二,输给 Qwen2.5-Math-PRM-7B 但输得不算难看。Qwen2.5-Math-PRM-7B 用了 180 万条样本(PRM800K + Math-Shepherd 合成数据 + LLM-as-Judge 滤噪),F1=73.5。R-PRM-DPO 用了 28.9 万样本(其实就是 PRM800K 自己反推出来的),F1=70.4。用 1/6 的数据拿到了 95.8% 的性能,这个数据效率是真的能打。
第三,OoD 上的鲁棒性。OlympiadBench 和 OmniMATH 是训练集(PRM800K 主要是 MATH/GSM8K 难度)以外的高难度题。R-PRM-DPO 在这俩上分别拿了 63.8 和 60.1,超过除 Qwen2.5-Math-PRM-7B 外的所有 PRM。这暗示生成式推理范式学到的可能是数据集无关的"评估模式",泛化性比直接拟合分数好。
PRMBench:在敏感性维度反超 GPT-4o
PRMBench 是更细粒度的 benchmark,把 PRM 的能力拆成 Simplicity / Soundness / Sensitivity 三个维度、9 个子项。
| 模型 | Simplicity Avg | Soundness Avg | Sensitivity Avg | Overall |
|---|---|---|---|---|
| GPT-4o | 59.7 | 70.9 | 75.8 | 66.8 |
| o1-mini | 64.6 | 72.1 | 75.5 | 68.8 |
| Qwen2.5-Math-7B-PRM800K | 48.2 | 62.2 | 72.2 | 58.3 |
| Qwen2.5-Math-PRM-7B | 52.1 | 71.0 | 75.5 | 65.5 |
| R-PRM-7B-SFT | 58.7 | 66.4 | 75.7 | 64.9 |
| R-PRM-7B-DPO | 55.2 | 71.2 | 76.6 | 66.8 |
R-PRM-DPO 在 Soundness 上略超 Qwen2.5-Math-PRM(71.2 vs 71.0),在 Sensitivity 上同样略超(76.6 vs 75.5),整体 66.8 已经追平 GPT-4o。这里我比较关心的是 Soundness——它考察的是模型识别"看起来对但实际有错"步骤的能力,包含 Empirical Soundness、Step Consistency、Domain Consistency、Confidence Invariance 四个子项。R-PRM 的强项就在这种需要溯源、复算的判断,因为它的 critique 模板本身就强制覆盖了这些维度。
数据效率:6.4 万样本干翻 26.5 万样本
这张图是我觉得这篇论文最值得放出来的:
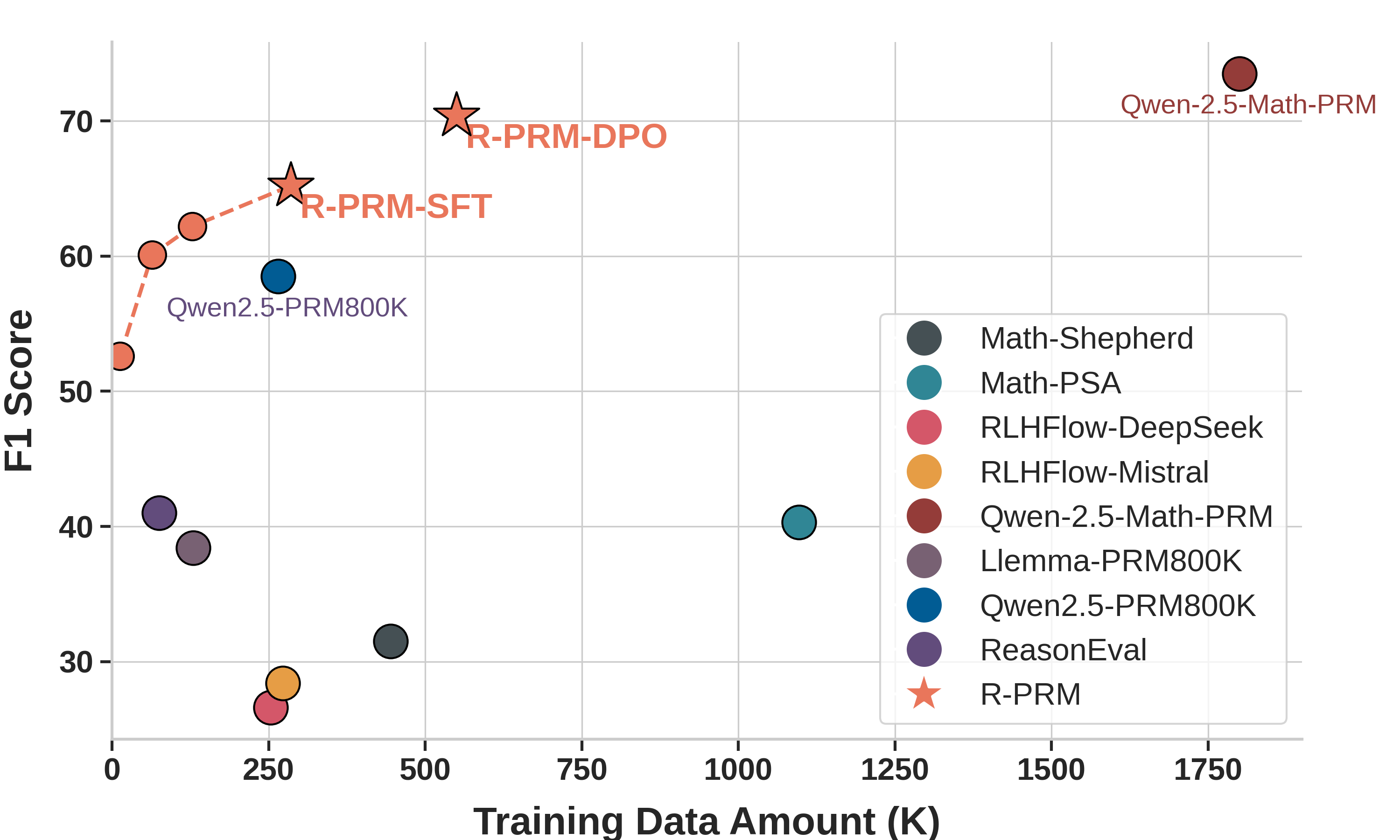
图2:数据效率对比。R-PRM-SFT 在 12.8k 样本时就已经超过大部分 baseline,64k 样本超过用 265k 样本训的 Qwen2.5-Math-7B-PRM800K,285k 样本拿到 65.2。再叠加 DPO(不引入新标注)能继续涨到 70.4。右上角的 Qwen2.5-Math-PRM 用了 1.8M 样本。
具体数字: - 12.8k 样本 → F1=52.6(已经超过大部分开源 PRM) - 64k 样本 → F1 已经超过 Qwen2.5-Math-7B-PRM800K(265k 样本,58.5)1.6 个点 - 285k 样本 → F1=65.2 (SFT) - + 269k 偏好对(无新标注) → F1=70.4 (DPO)
我想说一句——这个数据效率背后是有"代价"的:每条 SFT 样本的 token 长度比判别式 PRM 长得多(多了一段五维度 critique),训练算力其实没有省。但人工标注成本是省下了,而对 PRM 这种数据极其稀缺的任务,标注成本才是真瓶颈。
引导推理:BoN/Guide Search 都涨了 8 个点
把 R-PRM 接到 Qwen2.5-7B-Instruct 上做 Best-of-8 和 Greedy Guide Search,跑 6 个数学评测:
Best-of-8(每题采 8 个候选解,PRM 选最高分):
| 设置 | AIME24 | AMC23 | MATH | OlympiadBench | College Math | Minerva MATH | Avg |
|---|---|---|---|---|---|---|---|
| pass@1 | 11.2 | 47.8 | 73.0 | 38.0 | 38.6 | 37.2 | 41.0 |
| maj@8 | 20.0 | 57.5 | 79.6 | 47.0 | 41.5 | 42.7 | 48.0 |
| pass@8 (上界) | 33.3 | 82.5 | 88.8 | 58.5 | 47.5 | 57.7 | 61.4 |
| Qwen2.5-Math-PRM-7B | 16.7 | 55.0 | 82.0 | 48.0 | 43.5 | 43.0 | 48.0 |
| R-PRM-7B-DPO | 20.0 | 62.5 | 82.2 | 48.0 | 41.0 | 44.1 | 49.6 |
Greedy Guide Search(每步选最高分继续生成):
| 设置 | AIME24 | AMC23 | MATH | OlympiadBench | College Math | Minerva MATH | Avg |
|---|---|---|---|---|---|---|---|
| pass@1 | 11.2 | 47.8 | 73.0 | 38.0 | 38.6 | 37.2 | 41.0 |
| Qwen2.5-Math-PRM-7B | 16.7 | 60.0 | 81.0 | 43.5 | 39.0 | 40.4 | 46.8 |
| R-PRM-7B-DPO | 16.7 | 70.0 | 80.0 | 46.5 | 39.5 | 43.4 | 49.4 |
R-PRM 在两种引导策略下平均都比 Qwen2.5-Math-PRM-7B 高出 1.6 ~ 2.6 个点,比 pass@1 涨 8.4 ~ 8.6 个点,都超过了 majority voting。我看到 AMC23 上 BoN 拿到 62.5、Guide Search 拿到 70.0,比 pass@1 (47.8) 涨了 14.7 ~ 22.2 个点——这种小数据集上的方差比较大,但绝对收益很可观。
需要泼一盆冷水:pass@8 的上界是 61.4,maj@8 是 48.0,PRM 引导拿到 49.4 ~ 49.6,距离上界还有 11~12 个点的空间。PRM 的 reward 信号还远没有把 sampling 的潜力榨干。这一点论文自己也承认了——他们认为接 MCTS 或 Beam Search 可能有更大空间。
推理时 Scaling:K=2 到 K=4 是个跃升
R-PRM 因为是生成式 PRM,可以在推理时采样多条评估轨迹取平均。K 从 1 加到 32 的曲线是这样:
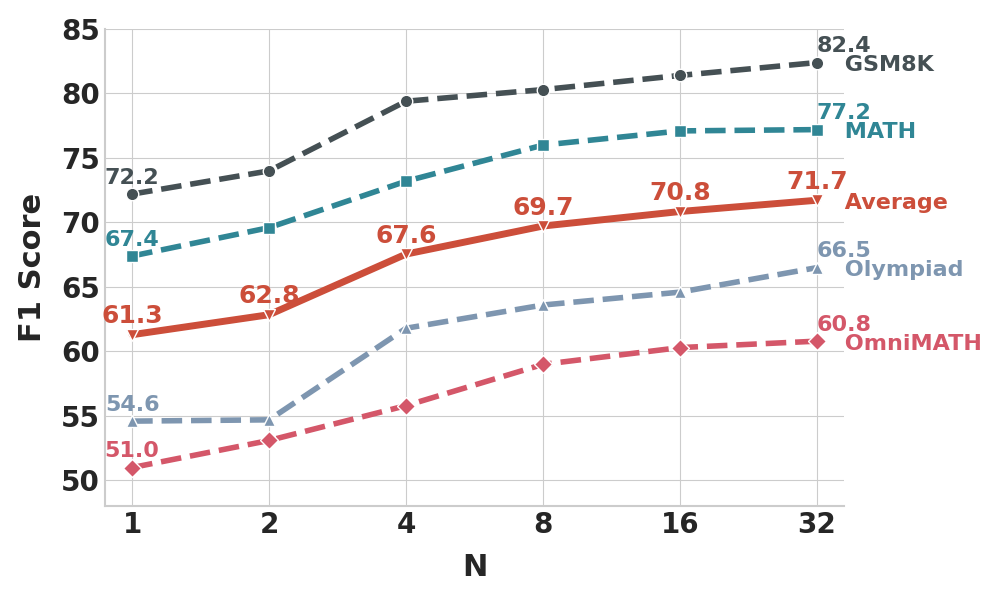
图3:推理时多轨迹采样的 scaling 曲线。横轴是采样轨迹数 K,纵轴是 F1。GSM8K(最容易)、MATH、Olympiad、OmniMATH(最难)四条线和 Average 都在 K 增大时单调上升,OoD 的 OlympiadBench 和 OmniMATH 收益最大(OlympiadBench 从 54.6 涨到 66.5,OmniMATH 从 51.0 涨到 60.8)。
K 从 2 到 4 是个明显的跃升点(Average 从 62.8 到 67.6),之后 K=4 到 K=32 还是缓慢爬升。OoD 数据集(Olympiad/OmniMATH)的收益最大——这个观察其实挺合理的:在简单任务上一条 critique 可能就够稳了,但在难任务上单条 critique 容易跑偏,多采样平均能显著降低噪声。
工程上看,K=10 是性价比挺高的设置。如果你在用 R-PRM 做线上服务,可以根据题目难度自适应调 K——简单题 K=2,难题 K=10 起。
阈值鲁棒性:判别式 PRM 的隐性偏差
论文里有一个细节我觉得挺值得说的——判别式 PRM 在不同 threshold 下的 F1 分数会剧烈波动,而生成式的 R-PRM 几乎不受 threshold 影响。
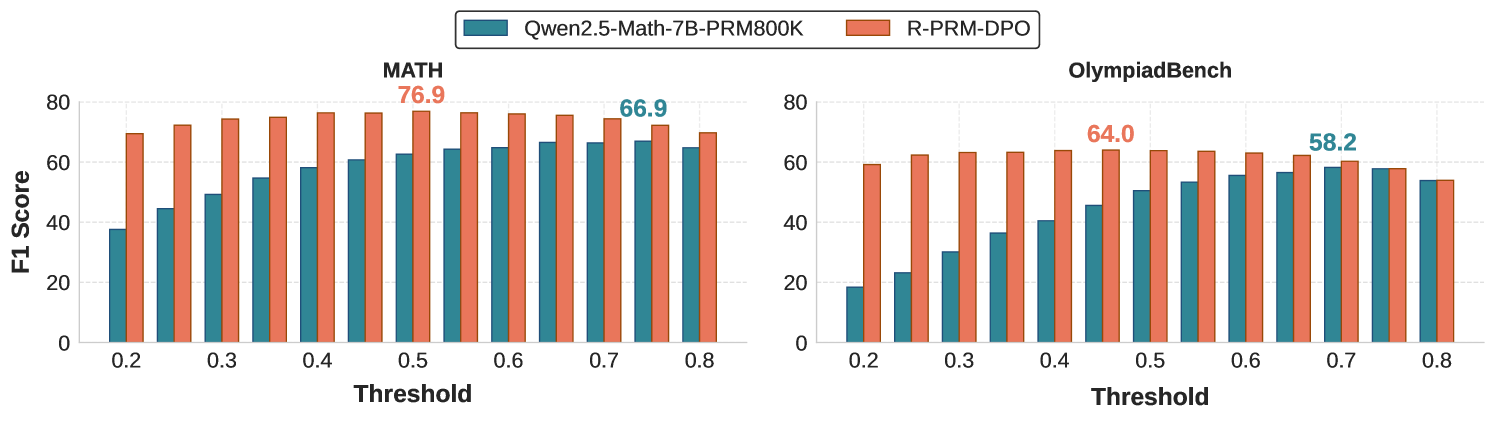
图4:固定 threshold=0.5 做二分类时,R-PRM-DPO 在 MATH 上 F1=76.9,在 OlympiadBench 上 F1=64.0,几乎是两个数据集上的最优表现。Qwen2.5-Math-7B-PRM800K 则需要更高的 threshold 才能达到最优,且 OoD 数据上的偏差更大。
PRMBench 上的整体趋势更夸张——Qwen2.5-Math-7B-PRM800K 在 0.5 阈值下只有 58.3,要到 0.8 阈值才达到 66.5 的最优。判别式 PRM 的分数分布不是 well-calibrated 的,意味着如果你想用它做绝对阈值判断(比如训练时用 PRM 过滤数据),需要先针对每个评测集调一遍阈值。R-PRM 这种鲁棒性背后的直觉是:生成式范式输出的不是一个标量,而是 K 条 critique 的"yes"概率均值,本身已经做了一次平滑。
我自己工程上的经验,这个特性挺重要——如果 PRM 能在固定 threshold 下稳定工作,下游 pipeline 就不用为每个新场景重新调参,省的不仅是时间,还有 calibration 数据。
一个具体的 case:发现"跳过 19"的错误
回到开头那个 emirp 的例子。Step 7 模型跳过了对 19 的检查,直接到 Step 8 检查 23。Qwen2.5-Math-PRM-7B 给 0.99,Qwen2.5-Math-7B-PRM800K 给 0.86,都没看出来。
R-PRM 的 critique 是这么写的(节选):
Previous Steps Analysis: …… Calculation Analysis: ……Upon reviewing, the mistake in the analysis is assuming 23 is the answer without properly checking if there are smaller primes that are not emirps. ……Given the oversight in the analysis regarding the thorough checking of primes and their reversals, the conclusion that 23 is the smallest such prime without properly validating against all primes in sequence is premature. Conclusion: The Now Step incorrectly concludes that 23 is the smallest two-digit prime number …… Verification: Is the step correct (Yes/No)? No
R-PRM (Majority Voting) score: 0.0547
注意 R-PRM 的判断逻辑——它先识别出"任务要求按升序检查所有候选",然后自己回去验算 19 是不是质数(19 是质数)+ 19 反过来是不是质数(91=7×13 不是质数),从而发现 19 才是答案,Step 8 跳过 19 直接到 23 是错的。
这个 case 说明的事情是:R-PRM 的能力不止是"判断",是"重做"。它能够基于 critique 模板里的"Previous Steps Analysis"主动回溯前面的步骤,发现遗漏。判别式 PRM 没有这个能力——它只能基于当前 step 的特征做模式匹配,匹配到"23 是质数 + 32 不是质数"就给高分。
我的判断:是工程整合,但整合得很扎实
这篇论文要我说亮点和槽点都得说。
亮点上:
第一,数据效率的故事讲得很清楚。同等数据量下 11.9 个点的提升,少 6 倍数据情况下 95.8% 的性能,这两个数据是真有说服力的。生成式范式 + 自蒸馏 + DPO 这套组合拳,把 PRM 的标注瓶颈大幅缓解了。
第二,Inference-time scaling 这条路打开了。判别式 PRM 在测试时只能 forward 一次,没法 scale。R-PRM 的 K 条采样让 reward 模型也加入了"test-time compute"的游戏,这个范式 shift 对未来 PRM 设计影响应该不小。
第三,鲁棒性和泛化性的实验做得扎实。threshold 鲁棒性、OoD 泛化、不同数据规模的 scaling、不同 K 的 scaling,每条曲线都做了——这种实验密度对一篇 7B 模型的 PRM 论文来说,已经超出预期了。
槽点上:
第一,"生成式 PRM" 不是新概念。LLM-as-Judge 走的就是这条路,Self-Reward Models(Yuan et al., 2024)等工作也在做。R-PRM 真正的贡献是把这套范式专门为 PRM 任务做了优化(5 维度 critique 模板 + DPO 过程优化 + inference scaling),但论文写法上有点把这条路当成完全新颖的方向,措辞可以更克制一些。
第二,没和强 baseline 比 inference-time 算力。R-PRM K=10 等于一次评估要 sample 10 条 critique,token 量级是判别式 PRM 的几十倍。如果把判别式 PRM 也给 10 倍算力(比如 ensemble 10 个不同种子的 PRM),公平对比之下 R-PRM 还能领先多少?论文没回答这个问题。
第三,Qwen2.5-Math-PRM-7B 在 ProcessBench 上还是赢的(73.5 vs 70.4)。R-PRM 的优势完全建立在"用同等数据量"的对比上。如果让 R-PRM 也用 1.8M 样本训,能不能反超?论文没做这个实验——可能是算力受限,但作为读者难免会想问一句。
第四,没在 70B 上验证。论文 Limitations 自己也承认了。7B 的 base model 推理能力本身就有限,70B 上 critique 的质量可能更高、scaling 收益更大,但也可能进入边际收益递减区。这个实验的缺失让结论的天花板有点不明朗。
工程启发:你能从中拿走什么
如果你正在做 PRM、Reward Model 或者更广泛的 evaluation model,R-PRM 这套方法论里至少有三个东西可以直接用:
第一,把判别式评估改成生成式 critique。哪怕你不做完整的 SFT+DPO,光是把 prompt 从 "给这一步打分 0-1" 改成 "先分析五个维度再给 Yes/No 判断",就能拿到不少提升。LLM-as-Judge 圈子里这个 trick 已经在用,R-PRM 把它做成了 PRM 的标准范式。
第二,用强模型 + 已有标签反向蒸馏 critique。你不需要任何新的人工标注,只要有一份带 ground truth 的小数据集,就可以用 70B 模型扩充出 critique 训练数据。注意一定要用人工标签做过滤,把 teacher 跑偏的 critique 筛掉。
第三,用 DPO 对生成过程做精修。生成式 PRM 的偏好对完全可以从模型自己采样的轨迹中构造——和 ground truth 一致的是 winner,不一致的是 loser,零额外标注成本。这个思路在其他 generation task 上同样适用。
至于 inference-time scaling 那块,工程上要注意算力账:K=10 意味着推理成本是判别式 PRM 的 10 倍以上(critique 还更长)。线上服务建议根据题目难度做自适应——简单题低 K,难题高 K。
收尾:PRM 进入"会思考的评分员"时代
回到一开始那个让人皱眉的现象:判别式 PRM 给错误步骤打 0.99 这种事,根子上是因为它没"思考"的空间。R-PRM 给出了一个朴素但 work 的解决方案——把评分变成推理。
这条路径已经被 R-PRM 证明了:能跑通,数据效率漂亮,鲁棒性强。下一步我比较期待看到:
- 70B 甚至更大规模上 critique 质量和 scaling 收益的曲线
- 接 MCTS 或 Beam Search 做更精细的搜索
- Critique 本身能不能被 RL 优化得更短、更准(现在每条 critique 几百 token,工程上还是偏重)
- 跨领域迁移——数学之外的 reasoning 任务(代码、科学推理)能不能用同样的 5 维度模板
如果你在做 PRM 相关工作,这篇论文值得你好好读一遍源码。仓库在 NJUNLP/R-PRM,prompt 模板和数据构造脚本都开源了,复现门槛不高。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我