PPO 不是 RLHF 的最优解:Google 跑了 3500 次实验、烧了 30000 TPU 小时给出最终排名
EMNLP 2025 Industry Track | RLHF Algorithms Ranked: An Extensive Evaluation Across Diverse Tasks, Rewards, and Hyperparameters
核心摘要
做 RLHF 的同学应该都被这个问题折磨过:现在 RLHF 算法满天飞——PPO、DPO、IPO、KTO、GRPO、RSO……每篇论文都说自己 SOTA,但对比实验只跟两三个 baseline 比,超参也基本是各说各话。到底哪个算法在你的任务上能 work?没人真的回答过。
Google Research 这篇论文是我最近看到的少数"硬核做对比"的工作。他们一口气评测了 17 个 RLHF 算法,跑了 3500 多次训练、烧了 30000 多 TPU 小时,在两个经典任务(TL;DR 摘要、Anthropic H/H)和两个奖励模型(Gemma 2B RM、规则奖励)上做了完整的超参搜索。结论可能会让一些人不太舒服——PPO 只是中游水平(胜率 54-59%),真正稳定打榜的是 REINFORCE with Baseline、IPO、DPO、GRPO 和 Best-of-N,最差的是 DQN(胜率最低跌到 32%)。
更值得一看的是它的工程结论:最好的超参往往是小学习率、低 KL 系数、低温度采样——也就是说"两层正则同时加"会过约束模型。这个观察跟 Ahmadian 那篇 "Back to Basics" 的判断对上了。
不算底层突破,但绝对是工程上一份值得放进实验室手册的横评,省下你自己跑超参的钱。
论文信息
- 标题:RLHF Algorithms Ranked: An Extensive Evaluation Across Diverse Tasks, Rewards, and Hyperparameters
- 作者:Lucas Spangher, Rama Kumar Pasumarthi, Nick Masiewicki, William F. Arnold, Aditi Kaushal, Dale Johnson, Peter Grabowski, Eugene Ie
- 机构:Google Research(William F. Arnold 隶属 KAIST)
- 发表:EMNLP 2025 Industry Track,2025 年 11 月
- 链接:ACL Anthology
为什么这篇横评值得读
先聊一下我自己的真实感受。过去两年做 RLHF 选型的时候我一直有个困惑:每个新 RLHF 方法都说自己比 PPO 好,但你要把它们放在同一套数据、同一个 reward model、同一个超参预算下做公平对比,会发现榜单经常翻盘。
这不是哪个作者的问题,而是 RLHF 这个领域本身的实验复现门槛太高——光是 PPO 一个算法,actor、critic、reward model、reference model 四个模型同时挂在显存里,再叠加 KL 系数、clip ratio、value loss 系数、GAE λ、policy lr 这些超参,一次完整的网格搜索就能烧穿你一个季度的算力预算。所以大部分论文写实验时只能选定几组超参做对比,对手算法的最优配置经常没找到。
这就是为什么 Ahmadian 那篇 Back to Basics(ICML 2024)当时让我挺触动的——他们论证"PPO 在 RLHF 场景里其实是过度设计",REINFORCE 和它的变体反而更好。Ahmadian 的核心观点是:PPO 当年是为机器人控制这种"长序列、连续动作、稀疏奖励"场景设计的,trust region 那套约束在那种场景下确实必要;但 LLM 的 RLHF 是"单步轨迹(一次生成一段文本就结束)+ 离散动作(token 选择)+ 稠密奖励(每个序列都有 reward)",根本用不着那么重的约束。但 Ahmadian 只比了 4 个算法(PPO、DPO、REINFORCE、RLOO),覆盖面有限。
Spangher 这篇的定位很清楚:把 Ahmadian 的论点放到一个真正大规模的 benchmark 上,看它能不能被验证。算法从 4 个扩到 17 个,超参从单点对比变成完整网格搜索,任务从 1 个扩到 2 个,奖励模型从 1 个扩到 2 个。
值得一提的还有更早一些的 Tulu 2.5(Ivison et al., 2024)——他们在开源数据集上做过 PPO vs DPO 的细致对比,结论是 PPO 在某些 benchmark 上能略胜 DPO。但 Tulu 系列的对比仅限于这两个算法,对 IPO/GRPO/KTO 这些新势力没有覆盖。
所以这篇 EMNLP 2025 的横评,其实是站在 Ahmadian 和 Tulu 这两个工作的肩膀上:算法集合最广、超参搜索最深、报告最透明。这种"花算力把别人花不起的钱花掉、得出一个所有人都能查的结论"的工作,在工业界其实更稀缺。
17 个算法到底是谁
作者把这 17 个算法按"怎么用偏好数据"分成三类,我给你画个对照表(这张表论文里没有,是我看完总结的):
| 类别 | 算法 | 核心思路 | 是否需要 Reward Model |
|---|---|---|---|
| 经典 RL + RM | AC(Actor-Critic) | actor 选动作,critic 估值 | ✅ |
| DQN | Bellman 更新估 Q 函数 | ✅ | |
| GRPO | 用一组采样的均值做 baseline | ✅ | |
| IQLearn | 逆 Q 学习,模仿学习路线 | ✅ | |
| PCL | 路径一致性约束 | ✅ | |
| PI(Policy Iteration) | 经典策略迭代 | ✅ | |
| PPO | clipped objective 限制策略变化 | ✅ | |
| REINFORCE | Monte Carlo 策略梯度 | ✅ | |
| REINFORCE w/Baseline | 减 baseline 降方差 | ✅ | |
| 直接偏好优化 | DPO | 偏好三元组 + Bradley-Terry | ❌ |
| IPO | DPO 推广到非成对偏好 | ❌ | |
| GPO | DPO/IPO 的统一抽象 | ❌ | |
| EXO | 用 anchor 分布做约束 | ❌ | |
| DRO | 单条 reward 信号优化 | ⚠️(标量 reward) | |
| KTO | Kahneman-Tversky 心理学启发,只要赞踩 | ❌ | |
| SLiC | 似然校准 | ❌ | |
| 采样筛选 | BON | 从 N 个候选里选最好的去 clone | ✅ |
| RSO | 拒绝采样优化 | ✅ |
等等,这里有个矛盾——论文摘要说"17 个算法",但 Section 4 列表只列了 16 个。我数了几遍:列表里有 PI(Policy Iteration),但 4.1.2 节里又额外提了 SLiC 但 4.1.1 节漏了 PI 的描述。所以严格说应该是 17 个,论文行文有点小不严谨。这种细节多少能看出 Industry Track 论文的赶进度感,但不影响核心结论。
值得多说两句的是 GRPO——这个算法这两年特别火(DeepSeek-Math 用它做 LLM 数学推理),它和 PPO 最大的区别是不要 critic 模型。具体做法:对同一个 prompt 采样 G 条回答,把这 G 条回答的奖励均值当 baseline 来算 advantage。少一个模型意味着显存少一份,工程上很香。这篇论文跑下来 GRPO 也确实在第一梯队。
还有 DPO 这条线值得展开聊。DPO 的核心 trick 是用一个数学等价变换,把"训 reward model + 用 reward model 跑 RL"两步直接合成一步,不再需要显式的 reward model。从工程角度看,DPO 把原本"四模型同台竞技"(actor、critic、reward、reference)简化成"两模型对抗"(policy 和 reference),显存压力直接腰斩。但代价是它本质是个离线算法——你只能在已有的偏好数据上训,没法像 PPO 那样在训练过程中持续采样新数据来更新 policy。这就引出了 IPO、KTO、GPO 这一长串变种,每个都在尝试补 DPO 的不同短板。
这篇论文的有趣之处在于:你能从同一张表里看出这些"DPO 全家桶"哪些真的在解决问题、哪些只是在 paper 之间互相模仿。比如 EXO 和 SLiC 在所有四列都是中下游(48% 上下),跟 DPO 67% 的差距明显——说明它们提出的"改进"在这个 benchmark 上没立住。这种"打脸"在 RLHF 圈是很罕见的,作者敢这么报数据,是这篇论文最有勇气的地方。
实验设置:怎么算"公平"
公平对比这种事情,魔鬼全在细节里。我把作者的设置拆开看:
起点模型:所有算法都从同一个 Gemma 2B SFT 模型起步,避免"baseline 跑得不够好"这种锅甩给起跑线。
两个奖励模型: 1. Gemma 2B Reward Model——标准做法,用偏好数据训出来的 RM。 2. Rules-based reward——这是个有意思的设计。把 ROUGE-LSum 加上长度惩罚做成一个"宪法 AI 风格"的规则奖励。这种 reward 不会被 model gaming,因为它是封闭的数学函数。作者用它做对照,看哪些算法是真在优化语义、哪些是在 reward hacking。
两个任务: 1. OpenAI TL;DR Summarization(11.6 万条人写指令 + 9.6 万对偏好对)——经典 Reddit 摘要任务。 2. Anthropic Helpfulness/Harmlessness(11.2 万对偏好对)——经典对齐任务。
评测方式:用一个更大的 Gemma 7B 模型当裁判,让 RLHF 后的模型和 SFT 基线做两两对决,每对跑 200 个 prompt(按 80% 统计功效算出来的样本量)。再加上 ROUGE-LSum 做辅助指标,并报告 reward 曲线。
超参搜索:每个算法搜 3 个超参,每个超参 3 个值(27 种组合)。前两个超参对所有算法都一样: - Policy 学习率:\(1\mathrm{e}{-7}\)、\(1\mathrm{e}{-6}\)、\(1\mathrm{e}{-5}\) - KL 系数 α:0.3、0.1、0.05 - 第三个是算法各自的特征参数(详见原文 Appendix Table 3)。
作者特别提了一句——超参的取值是跟原算法作者讨论后定的。我觉得这是一个挺关键的细节,避免了"baseline 跑不好是因为超参没调"的指责。
算力:30000+ TPU 小时,3500+ 训练 run。这个量级在学术界很少见,工业界倒是常态。
核心结果:谁赢了,谁输了
直接上数据。这是论文 Table 2 的胜率(每个 RLHF 模型 vs SFT 基线,由更大的奖励模型做裁判):
| 算法 | TL;DR (2B RM) | H/H (2B RM) | TL;DR (7B RM) | H/H (7B RM) |
|---|---|---|---|---|
| R w/Baseline | 66% | 64% | 69% | 69% |
| GRPO | 65% | 63% | 75% | 68% |
| DPO | 62% | 67% | 69% | 69% |
| IPO | 66% | 48% | 69% | 51% |
| BON | 64% | 52% | 68% | 58% |
| REINFORCE | 60% | 62% | 64% | 67% |
| RSO | 58% | 61% | 61% | 66% |
| GPO | 61% | 46% | 64% | 49% |
| DRO | 58% | 52% | 61% | 58% |
| PPO | 54% | 57% | 58% | 59% |
| AC | 53% | 55% | 56% | 59% |
| KTO | 52% | 56% | 57% | 59% |
| IQLearn | 49% | 51% | 52% | 54% |
| EXO | 48% | 43% | 51% | 48% |
| SLiC | 48% | 49% | 48% | 52% |
| PI | 45% | 46% | 48% | 49% |
| PCL | 41% | 42% | 45% | 45% |
| DQN | 32% | 36% | 35% | 42% |
粗体是各列前三名(论文标注),最下方加粗的 DQN 是垫底。
几个我看完最有感觉的判断:
第一,REINFORCE with Baseline 是真稳。四列里三列前三、一列也是 64%。这跟 Ahmadian 当年的论点几乎是完美贴合——一个最古早、最简单的策略梯度方法,加个减 baseline 的小手术,就能稳赢一众"高级"方法。
第二,PPO 不是 RLHF 的"金标准"。54-59%。说实话看到这个数字我愣了一下——业界一直把 PPO 当 RLHF 的事实标准,OpenAI/Anthropic 早期那波 alignment 工作也是 PPO,但在这个 benchmark 上它甚至打不过 REINFORCE。作者的解释是:PPO 的 trust region 思路在 LLM 这种单步轨迹 + 大动作空间的场景下其实是过度约束。这个解释跟 Ahmadian 一致。
第三,DQN 和 PCL 是真的不行。DQN 32-42%,比 SFT 还差。这其实挺反直觉的——DQN 在游戏 RL 里是元老级算法。但 LLM 的状态空间是 token 序列,动作空间是整个词表,让一个 Q 网络去估 \(Q(s, a)\) 几乎是 mission impossible。
第四,DPO/IPO 在 H/H 上的差距很有意思。DPO 67%,IPO 48%——同一类直接偏好优化方法,差了将近 20 个点。仔细看 Table 1 的最优超参:DPO 在 H/H 上选了 \(\beta_{\text{DPO}}=0.5\),IPO 选了 \(\beta_{\text{IPO}}=0\)。也就是说 IPO 在这个任务上几乎"放弃了正则化",可能就是这个原因导致它跑飞。这是一个挺典型的"算法对超参敏感导致排名翻盘"的例子。
第五,GRPO 是最大的黑马。在 7B 裁判 + TL;DR 上拿到 75% 的最高分。作为一个 critic-free 的方法,工程上的便利性又非常好——这就是为什么 DeepSeek 那条线推 GRPO 推得那么用力。
训练曲线:reward 涨不一定真的好
胜率表只能告诉你最终的强弱,但 RLHF 真正的麻烦在训练过程。论文 Figure 1 给了三个任务的 reward / KL / ROUGE 曲线,我把它放在这里——这张图特别能说明问题:
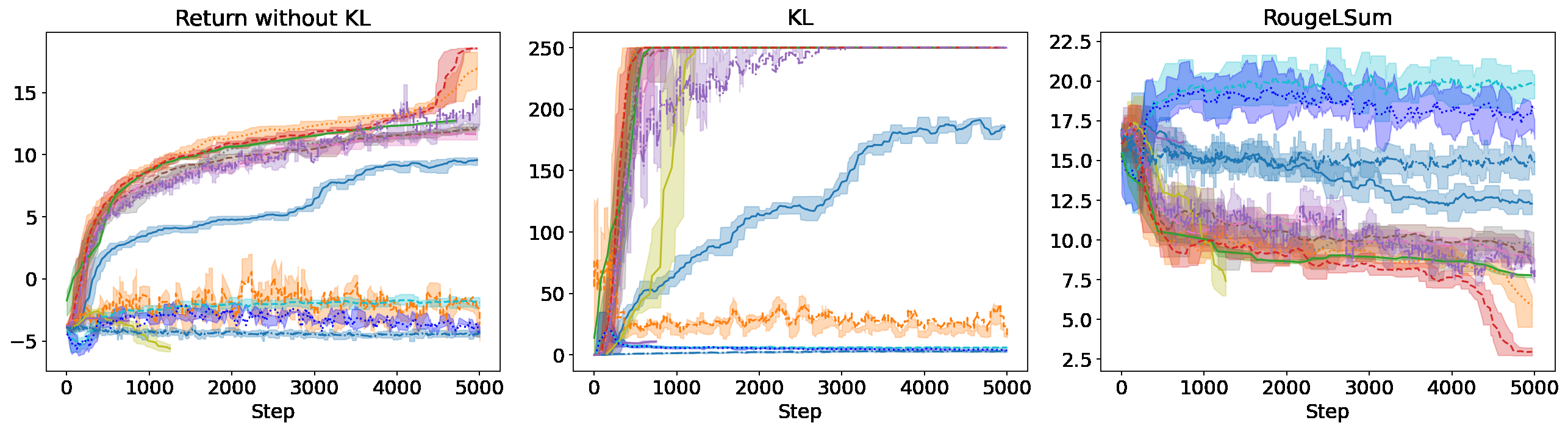
(a) TL;DR 任务 + Gemma 2B 奖励模型。左图 Return 在涨,但有一组算法(红/橙/紫色那几条)的 reward 飙到 15+ 的时候 ROUGE 反而在掉——典型的 reward hacking。中图 KL 散度也在飙到 200+,意味着模型已经偏离 SFT 起点很远。
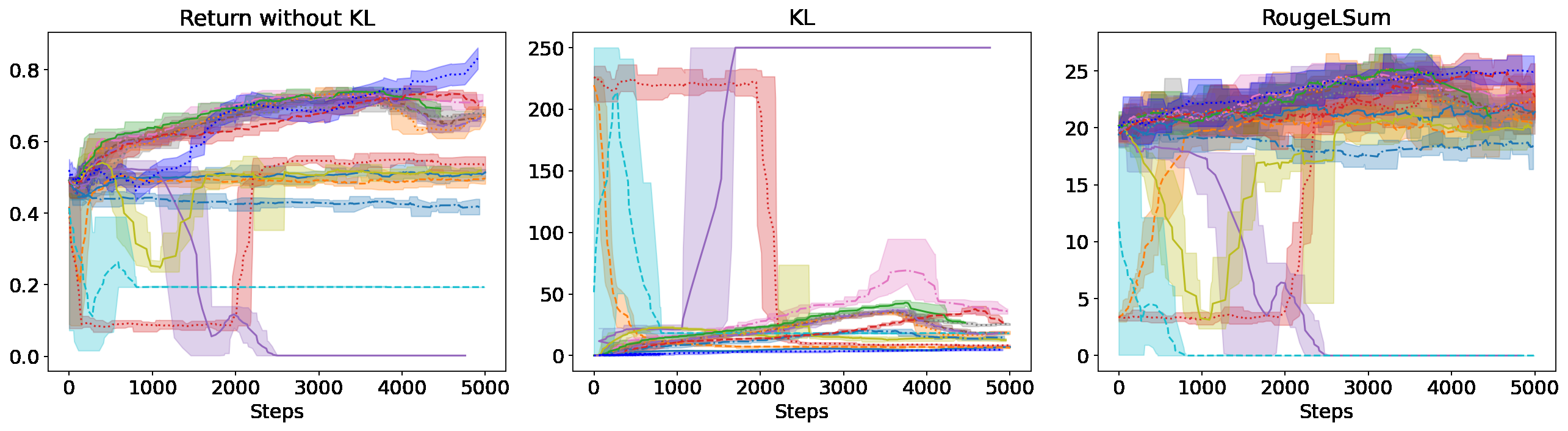
(b) TL;DR + 规则奖励(ROUGE + 长度惩罚)。换了一个无法被 hack 的奖励之后,reward 涨幅明显收敛得多(0-0.8 区间)。但仍然能看到几条曲线(青绿色和淡黄色那两条)的 ROUGE 在某些步数突然崩盘到接近 0——这是 mode collapse 在生效,模型生成了完全无意义的输出。
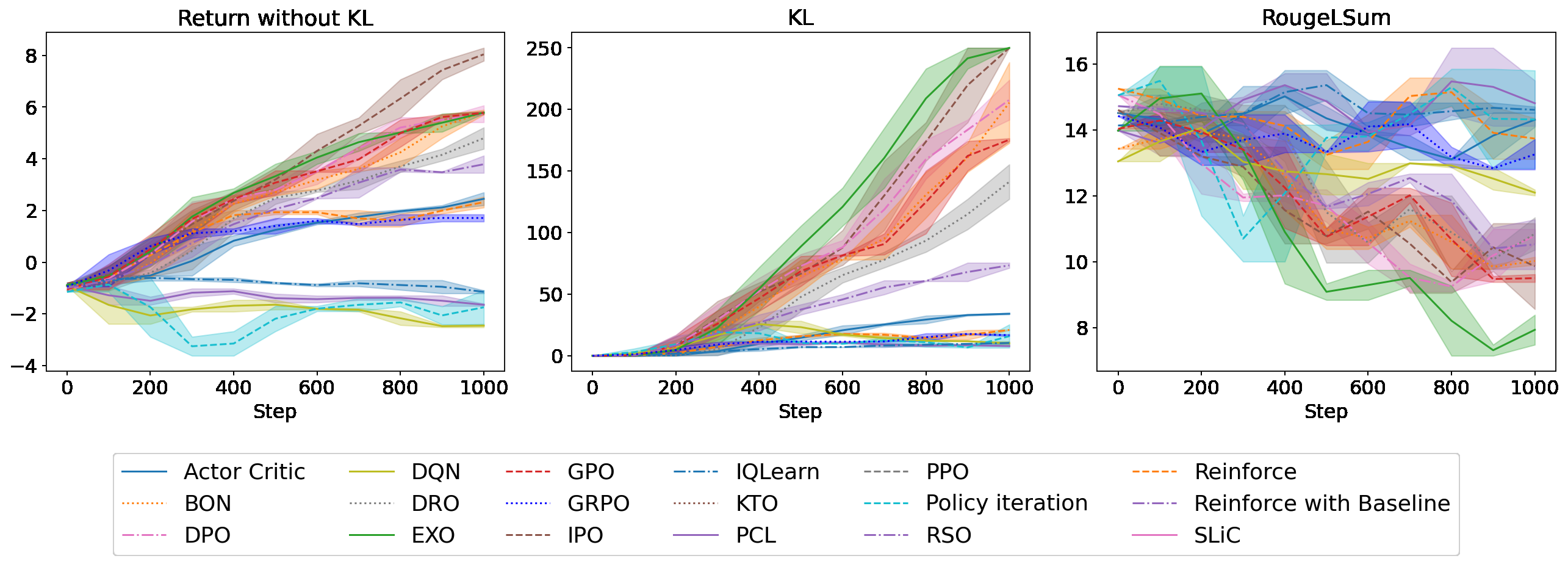
(c) Helpfulness/Harmlessness + Gemma 2B 奖励模型。这个任务上 reward 范围更小(-2 到 8),KL 涨势比前两个温和,但 ROUGE 掉得比较厉害——说明 H/H 任务上 reward 优化和文本质量的相关性最弱,最容易 reward hacking。
我觉得看这三张图最重要的一个 takeaway:reward 涨 ≠ 模型变好。论文附录里给了一个非常生动的反面例子,模型生成的东西长这样:
Model Response: increa increa increa increa increa increa
increa increa increa increa increa increa increa increa
increa increa increa increa increa increa increa increa
increa increa increa ...(持续重复几百遍)
这个就是 mode collapse 的典型形态——奖励模型在训练数据上没见过这种"垃圾",给它打了高分;模型发现这条路 reward 高,就拼命走这条路,最后退化成无意义重复。这种现象在你只看 reward 曲线时是发现不了的,必须看 ROUGE 或者人工评审才能暴露。
工程意义上,这意味着训 RLHF 的时候永远不能只盯一个指标。reward + ROUGE + 人工抽样,三件套缺一不可。
超参分析:小学习率、低 KL、低温度
这部分是论文最有工程价值的发现,我列一下作者从 Table 1 总结出来的几个规律:
规律 1:最好的超参往往是最小的学习率。在 17 个算法里,绝大多数在 TL;DR 任务上选了 \(1\mathrm{e}{-7}\) 作为 policy lr。这个值真的很小——很多 RLHF 教程会推荐 \(1\mathrm{e}{-5}\) 到 \(5\mathrm{e}{-6}\)。作者的解释是:RLHF 阶段你只是在 SFT 模型上做"微调里的微调",太大的学习率很容易把已经学好的语言能力破坏掉。
规律 2:KL 系数 α 倾向于小值。绝大多数最优配置选了 0.05 或 0.10,很少选 0.30。这跟规律 1 一起看其实有个共同的故事:你不需要同时用"小学习率"和"强 KL 约束"两层缰绳,两层一起加会过约束模型,让它根本动不了。这跟 PPO trust region 在 LLM 上失效的原因是一样的逻辑。
规律 3:温度倾向于 1.0。REINFORCE 系列、PPO、PCL 这些算法的最优 decoder 温度都是 1.0,不是 1.5 或 2.0。也就是说,RLHF 阶段不要做激进的探索,温和的采样反而效果好。
把这三条放一起看,作者总结出一个挺漂亮的判断:RLHF 的真正定位不是"让模型大幅改变",而是"让模型在已有能力的小邻域里精细微调"。所有让模型"动得太快"的设计——大学习率、激进采样、弱正则——都会把它带到坑里。
我自己之前调 RLHF 的时候也踩过这个坑。一开始按 SFT 的经验直接用 lr=1e-5,结果 reward 还没怎么涨,模型已经胡言乱语了。后来把学习率压到 1e-7,再把 KL 系数从 0.5 降到 0.1,这才稳住。那时候没看到这篇 paper,自己摸黑摸了快两个月才找到合适配置。如果当时这张 Table 1 已经放在面前,估计能省掉一个研究员月。这就是为什么我说"工业界横评"的价值经常被低估——它替你把那些只能靠经验摸索的 trial-and-error 写成了可查证的表格。
我的几个判断
聊完结论,说点我自己看完的想法。
这篇论文最值钱的地方在哪里:不是它的"创新",而是它的工程基建——把所有 RLHF 算法在同一套 codebase 里实现一遍,用同一套训练框架跑出来。这种事情看着简单,但你真做的时候,光"复现 17 个算法"这一项就能耗掉 3-6 个月。Google 干这种事最有动机也最有资源。结果就是:你拿这张表当选型 checklist 用,能省掉好几个研究员月。
它的局限性也很明显:
-
起点模型只有 2B——作者自己也承认了,2B 模型上的结论能不能 transfer 到 70B 甚至更大的模型上,是个开放问题。我个人猜测:RLHF 算法的相对排名在大小模型上应该比较稳(这是工程经验),但绝对差距会缩小——大模型本身能力就强,RLHF 算法间的差异会被稀释。
-
超参搜索还是不够大。每个算法 27 种组合,听起来不少,但 RLHF 算法的"敏感超参"远不止 3 个。比如 PPO 的 clip ratio、value loss coefficient、GAE λ 都没动;GRPO 的组大小 G 只搜了 10/20/50 三个值。理论上,每个算法的真正最优配置可能还在搜索空间外。
-
任务覆盖偏窄。摘要 + 对齐这两个任务都是"通用对话"性质的,没有覆盖到数学推理、代码、工具调用这些最近 RLHF 的热门战场。比如 GRPO 在数学题上表现极强(DeepSeek-Math),在这篇 benchmark 上排名能不能 transfer,没人知道。
-
mode collapse 的处理略草率。作者明确提到"mode collapse 有时会人工拉高 reward",但没有把"是否发生 mode collapse"作为评估维度量化报告。读者只能从 ROUGE 曲线和附录的 decoded output 里去推断。如果作者能给一个 mode collapse 检测指标(比如生成多样性、重复率),这张表的价值会再上一层楼。
对工程实践的启发:
- 如果你在挑算法:闭眼选 REINFORCE with Baseline 起手,简单稳定。如果你的任务有强偏好数据,可以换 DPO 或 GRPO。先别上 PPO,复杂度收益比真的不划算。
- 如果你在调超参:从 lr=1e-7、α=0.1、温度=1.0 起手,先确保模型不崩,再慢慢往激进方向调。
- 如果你在做评估:永远不要只看 reward 曲线,必须配 ROUGE / pass@k / 人工抽样的三件套,不然你会被 mode collapse 阴。
- 如果你在做基础设施:DPO 和 GRPO 是最值得做工程优化的两个算法。DPO 因为是离线的,可以做完整的偏好数据 pipeline 加速;GRPO 因为没有 critic,可以直接复用 SFT 训练框架,工程改造最小。这两个方向在工业界的产出比最高。
一个我觉得作者还可以再深挖的方向:胜率表是用 Gemma 7B 当裁判算出来的——但 Gemma 7B 自己就有偏好倾向。比如它可能更喜欢长回答、更喜欢列表式排版、更喜欢委婉表达。这些"裁判模型自己的偏好"会传染到所有被它评估的 RLHF 算法上。理想情况下应该用人工评审 + 多个不同家族的裁判模型(比如 Claude、GPT、开源模型)做交叉验证。当然这个成本不低,但如果只用一个裁判模型,胜率排名就有可能是裁判模型偏好的"投影",而不是算法本身的强弱。这是我觉得这类 benchmark 工作最容易被忽略的方法论问题。
收尾
这篇论文不能算"理论突破"——它没有提出新算法,没有新理论。但它是一篇我会收藏在书签里、做项目时随手翻的工具书。
更值得说的是它代表的研究风气——花算力把"模糊的工业界共识"变成"可查证的客观数据",这种工作在 AI 圈被严重低估了。每年顶会上一堆"我比 PPO 好 2 个点"的论文,但真把 17 个算法摆一起公平比一次的,全行业一只手能数过来。
如果你也在做 RLHF/对齐相关的事,强烈建议把 Table 1 和 Table 2 打印贴在工位墙上。下次有人来跟你 pitch "我们应该上 PPO/IPO/EXO",你可以直接指着这张表说:兄弟,先看看人家烧 30000 TPU 小时跑出来的结论。
PPO 的神话该破了。这篇横评算是补了最后一颗钉子。
参考链接: - 论文:https://aclanthology.org/2025.emnlp-industry.35/ - Back to Basics(Ahmadian et al., 2024):https://arxiv.org/abs/2402.14740 - DPO 原文:https://arxiv.org/abs/2305.18290 - GRPO(DeepSeek-Math):https://arxiv.org/abs/2402.03300
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我