代码生成里 Process Reward 第一次被认真验证:PRLCoder 把"行级别"奖励喂给 PPO,难题 Pass@80 涨了 9.6 个点
论文:Process-Supervised Reinforcement Learning for Code Generation 作者:Yufan Ye(北京理工大学),Ting Zhang、Wenbin Jiang、Hua Huang(北京师范大学) arXiv:2502.01715 接收:EMNLP 2025
这篇论文的核心摘要
代码生成领域的 RL 一直是个怪现象——大家都在用"全段代码跑测试用例"作为奖励信号,PPOCoder、CodeRL、RLTF 都是这个套路。问题是这个 reward 太稀疏了:模型生成 30 行代码,最后一个 token 才拿到一个 0/1 的反馈,前面 29 行哪一行写错了?模型自己也不知道。
数学推理那边早就把 PRM(Process Reward Model)玩明白了,OpenAI 的 Let's Verify Step by Step 已经把过程监督的优势写得很清楚。但代码这边迟迟没动静——主要卡在步级别标注成本:让人逐行打分,成本压根扛不住。
PRLCoder 的解法挺漂亮:用 DeepSeek-Coder-V2 当 teacher 模型逐行做"变异/重构",再扔进编译器跑测试用例自动打 Positive/Negative 标签。这套自动化流水线生出 6000 多条步级别样本,训出一个准确率 76% 的 PRM,再用它作为 PPO 的密集奖励源。
效果:MBPP+ 上 Pass@80 从基线的 60.3 涨到 63.8,对长度 \gt 100 行的 HRD 难题 Pass@80 从 50.0 涨到 59.6——9.6 个点,这才是 PRM 真正的价值所在。
一句话评价:这是代码生成领域首篇真正把过程监督 RL 跑通并在多难度梯度上做出区分实验的工作,方法整合性强于颠覆性,但"自动构造步级别奖励数据"这套流水线是真能用的——给后续做代码 PRM 的工作扫清了一个最大的工程障碍。
你有没有觉得,代码 RL 一直差点意思?
我之前在做代码生成的 RL 训练,碰到过一个特别尴尬的场景:模型生成的一个函数,前面 20 行写得挺好,最后一行返回值类型搞错了,编译器报 TypeError。然后呢?整段代码 reward = 0,模型挨了一顿打,但它根本不知道到底是哪里错了。
这就是 outcome supervision 的死穴——稀疏奖励。OpenAI 那边搞数学推理早就发现这个问题,搞出了 PRM800K 数据集,让人逐步标注每一步推理对不对。结果在 MATH 数据集上,过程监督直接把结果监督按在地上摩擦。
但代码这边一直没人认真做。原因不复杂:数学一步就是一行公式,代码一步是什么?一行?一个语句块?标注怎么搞?人工成本是不是要爆炸?
这篇论文就是来回答这个问题的。作者来自北京理工大学和北京师范大学(北师大占了 3 个作者),论文挂在 arXiv 是 2025 年 2 月,最近被 EMNLP 2025 接收。
我的第一反应是——这个 idea 不算特别新,Dai 等人在 2024 年 10 月发的 arXiv:2410.17621("Process supervision-guided policy optimization for code generation")也是同期工作,思路类似都是用代码前缀+自动测试评估。论文也很坦诚地在 Related Work 里点名了这一工作,但因为 Dai 用的是闭源模型,没法直接对比。所以严格说 PRLCoder 不是"首次提出",但是是首个把整套自动构造数据 + PRM + PPO 完整开放细节并做出难度分层实验的工作。这点要分清楚。
整体框架:三段式,没什么花活
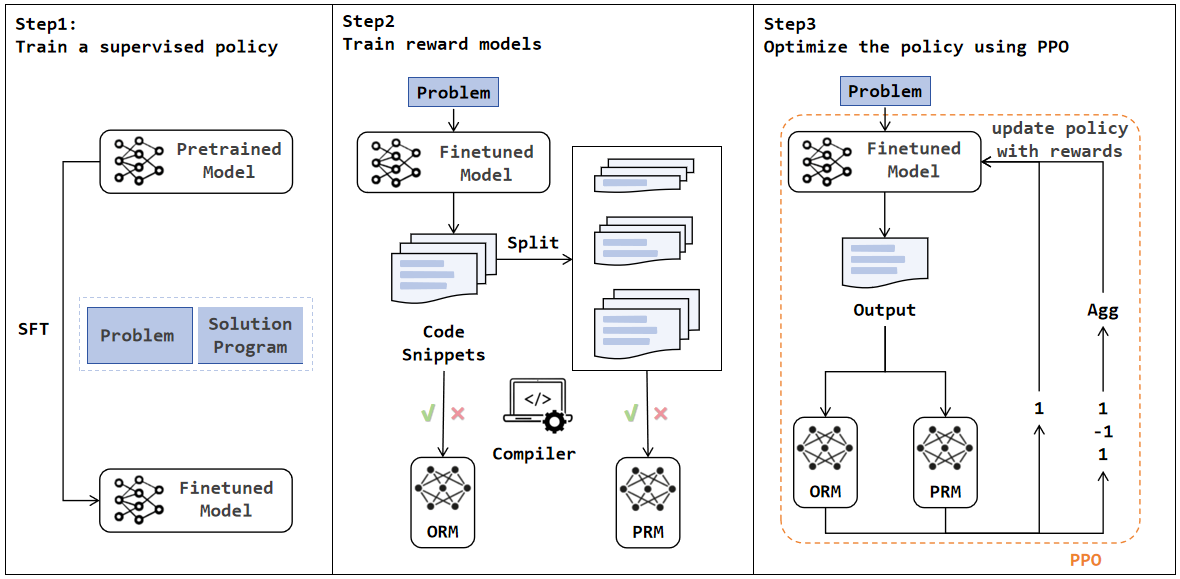
图1:PRLCoder 整体框架。Step1 用 MBPP 训练集对 CodeT5+ 做监督微调(SFT);Step2 训练奖励模型(同时训 ORM 作为对照,PRM 用自动构造的步级别数据);Step3 用训好的 PRM/ORM 给 PPO 提供奖励信号,迭代优化 policy。
整套流程没什么颠覆性设计,跟主流 RLHF 几乎是 1:1 对齐——SFT → RM → PPO。真正的关键创新只有一个地方:奖励模型从哪儿来?怎么造它的训练数据?
PRLCoder 的回答是:让 teacher 模型逐行变异/重构代码,让编译器自动打标签。这套自动化流水线是论文最值钱的部分。
自动构造步级别奖励数据:这套流水线值得抄
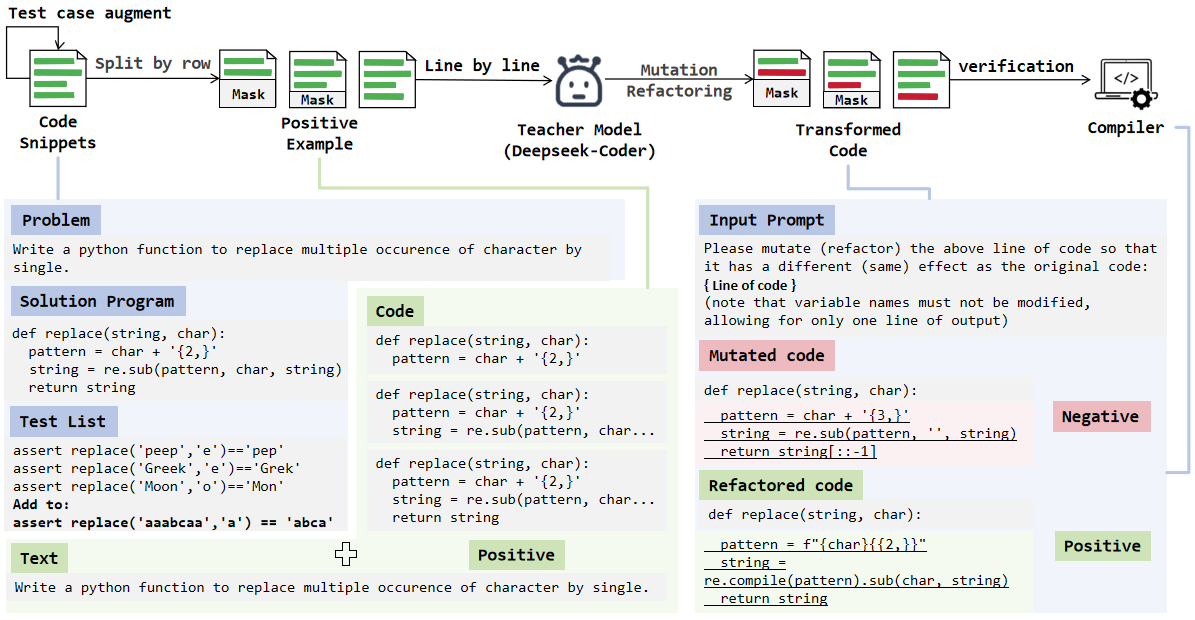
图2:自动化数据构造流程。原始代码按行切分,对每一行用 DeepSeek-Coder-V2 做两种操作——Mutation(让这行的功能变得不一样)或 Refactoring(保留功能改写代码)。改完后把这行后面的内容 mask 掉,剩下的代码扔进编译器跑测试用例。Mutated code 通常应该 Negative(功能变了所以测试挂了),Refactored code 应该 Positive(功能没变所以测试通过)。如果实际跑出来跟预期一致就保留,否则丢弃。
这套思路挺漂亮的,仔细拆一下:
正样本怎么来? 原始 reference code 本身就是正样本——把它按行切开,对每一行 \(s_{ij}\),把后续行 mask 掉,标签直接打 Positive。这样一份 reference code 能产出 \(L_i\) 个正样本(\(L_i\) 是行数)。
负样本怎么来? 这是关键。对每一行,用 prompt 让 DeepSeek-Coder-V2 做两种操作:
- Mutation:让这行的功能跟原代码不一样(比如把
pattern = char + '{2,}'改成pattern = char + '{3,}') - Refactoring:保留功能但改写代码(比如改成 f-string 写法)
改完后跑编译器+测试用例,根据结果打标签。Mutation 改出来的通常是负样本,Refactoring 改出来的通常是正样本。这套自动流水线最终生出:
| Split | Positive | Negative |
|---|---|---|
| Train | 3,469 | 2,674 |
| Val | 632 | 507 |
| Test | 631 | 488 |
总共 8,401 条步级别样本,纯自动化,零人工标注成本。
但这里其实有个隐患——MBPP 原始测试用例的覆盖率是不够的。论文里讲:变异之后的代码明明是错的,但测试用例没覆盖到那个分支,照样能 pass。这种假阳性会污染整个奖励数据集。
作者的应对是用 LLM 生成额外的测试用例做路径覆盖增强,搞出了一个升级版的 MBPP+ 数据集。这个细节挺工程的,但对最终效果应该贡献不小——你要是 PRM 一开始就在错误标签上训练,后面 RL 阶段全是垃圾。
说实话这一招在工业界已经是默认操作了,但论文把它显式做成 pipeline 的一环讲清楚,这一点我挺欣赏的。很多论文会忽略"测试用例覆盖率"这个隐藏 bug,导致结论根本站不住脚。
三种 ORM 对照:把"对手"做强了再打,结论才有说服力
为了证明 PRM 真的好,作者没图省事只跟一个最弱的 ORM 比。他们做了三种 ORM,每种都用各自最优的策略训练:
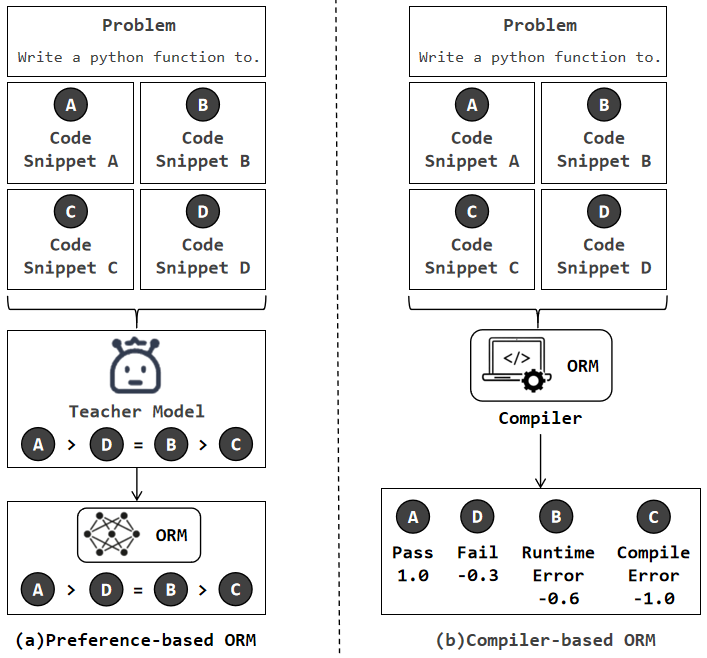
图3:(a) Preference-based ORM——参照 RLHF,让 teacher 模型对多个生成结果做排序,用偏好数据训 RM;(b) Compiler-based ORM——直接用编译器的四种状态(Pass=1.0、Fail=-0.3、Runtime Error=-0.6、Compile Error=-1.0)作为 reward,跟 CodeRL、PPOCoder 是同一思路。
这三种 ORM 对应三个等级的对手:
- O-ORM(Original ORM):直接用 PRM 那个数据集训出来的 ORM,最弱的对照
- P-ORM(Preference-based ORM):模仿 RLHF,用 teacher 模型生成偏好排序数据训 RM
- C-ORM(Compiler-based ORM):编译器反馈直接当 reward,对应 CodeRL 和 PPOCoder 两种实现
我比较喜欢这个设计的地方在于——作者承认 PRM 数据集和 C-ORM 的训练数据并不直接相交,所以严格说 PRM 和 C-ORM 不是"完全公平的对照"。但他们的论点是:每种方法都用自己路径下的最优数据训练,比较的是两条路线的天花板,而不是"完全等价的输入下哪个赢"。这个表达方式比那些假装"完全公平"的论文老实多了。
核心公式:从结果奖励到过程奖励,就这一行差别
ORM 的奖励分配方式很简单:
只在最后一个 token 给 reward,前面全是 0。这就是稀疏奖励的来源。
PRM 是这样的:
把代码切成 \(k\) 段(按 \n 切,所以基本是按行切),每段结束的位置都给一个 reward。这样 30 行的代码,模型能拿到 30 个 reward 信号,PPO 的优势函数估计就稳得多。
PPO 那块加了一个标准的 KL 散度惩罚项,跟主流 RLHF 实现一致:
工程上这个 PRM reward 的实现细节得提一下:每行结束位置才给 reward,所以行内的 token 仍然是稀疏的。理论上还能更细——比如 token 级别都给——但行级别已经比 outcome supervision 密集得多了,工程上是个 sweet spot。
实验结果:PRM 在难题上才真正发力
先看 MBPP+ 主表。这里把测试集按代码长度分成三档:EZY(\lt 50 行)、MED(50-100 行)、HRD(\gt 100 行),分别跑 Pass@1、Pass@10、Pass@80。
| 模型 | Size | Pass@1 (all) | Pass@10 (all) | Pass@80 EZY | Pass@80 MED | Pass@80 HRD | Pass@80 (all) |
|---|---|---|---|---|---|---|---|
| GPT 137B | 137B | - | - | - | - | - | 61.4 |
| LLaMA | 7B | 17.7 | 40.3 | 68.4 | 54.8 | 48.9 | 59.3 |
| CodeT5+ (基线) | 770M | 18.0 | 41.6 | 67.9 | 56.4 | 50.0 | 60.3 |
| O-ORM | 770M | 20.1 | 39.7 | 65.7 | 52.5 | 51.2 | 57.9 |
| P-ORM | 770M | 18.2 | 41.9 | 67.4 | 56.9 | 52.8 | 62.0 |
| C-ORM (CodeRL) | 770M | 18.1 | 42.0 | 66.1 | 56.9 | 52.6 | 61.0 |
| C-ORM (PPOCoder) | 770M | 18.5 | 42.4 | 66.7 | 57.3 | 53.4 | 61.9 |
| RSFT | 770M | 18.3 | 42.6 | 68.4 | 58.4 | 57.2 | 62.2 |
| PRLCoder | 770M | 18.7 | 43.0 | 69.0 | 60.0 | 59.6 | 63.8 |
几个点挺有意思:
HRD 列(\gt 100 行的复杂代码)涨幅最大——基线 50.0,PRLCoder 59.6,+9.6 个点。在 EZY 列(简单代码)反而只涨了 1.1 个点。这跟作者的 hypothesis 一致:过程监督的优势在长代码、复杂逻辑上才显著。原因不难理解——简单代码本来就 3-5 行,outcome reward 也够用;越长的代码,前面几行的小错误对最终结果的影响越大,过程监督的"早期发现"价值才能放出来。
O-ORM 在 Pass@10 / Pass@80 上反而比基线还差。作者的解释是 O-ORM 训练数据里负样本对错误代码有强偏置,导致它在 RL 时把一些正确代码也判错了。这个发现挺反直觉的——你以为加了 reward model 总不会更差吧?结果就是更差了。这也是为什么作者后面又加了 P-ORM 和 C-ORM 两个更强的对照。
PRLCoder 在 Pass@1 上的优势其实很小(18.7 vs 18.5 PPOCoder)。真正的差距在 Pass@10/80 上拉开——这说明 PRM 训出来的模型生成代码的多样性更好,不是只 cherry-pick 单条最优解。Pass@k 越大优势越显著,这点对实际部署(n-best rerank、多次采样选最优)特别有价值。
再看 HumanEval 的迁移性能:
| 模型 | Size | Pass@1 | Pass@100 |
|---|---|---|---|
| CodeT5+ | 770M | 12.5 | 38.0 |
| O-ORM | 770M | 13.2 | 40.1 |
| P-ORM | 770M | 12.9 | 40.6 |
| C-ORM (CodeRL) | 770M | 12.6 | 39.7 |
| PPOCoder | 770M | 13.0 | 40.0 |
| PRLCoder | 770M | 13.6 | 41.8 |
跨数据集仍然稳。论文坦诚交代了一句——他们的 CodeT5+ 在 HumanEval 上比原始论文报的低,是因为只在 MBPP+ 上微调,训练数据少得多。这点透明度还行。
PRM 自身的质量:accuracy 0.76,正样本好识别负样本难
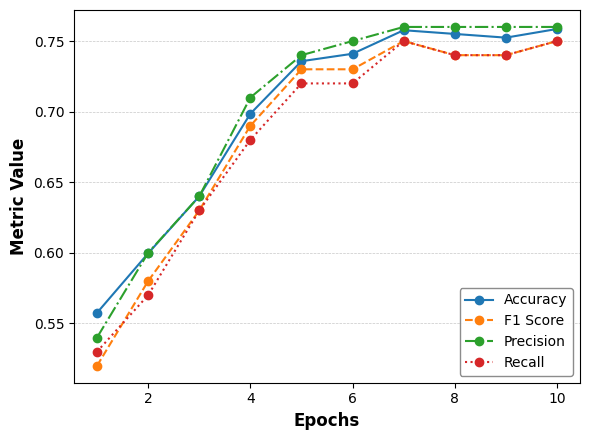
图4:训好的 PRM 在测试集上的整体表现——10 个 epoch 后整体准确率收敛到约 0.76,F1 与 Recall 略低于 Precision。这个数据自查很重要,如果 PRM 本身就是个 50% 准确率的模型,下游 RL 拿它当 reward 等于在喂噪声。
整体准确率 0.76,但正负类的 accuracy 差异很大——Positive 样本 0.84,Negative 样本只有 0.65。也就是说 PRM 容易把对的代码判对,但不太容易把错的代码判错。这种偏差会让 RL 阶段产生一定比例的"假阳性"奖励,但作者实测下游效果还是涨了——说明这个噪声水平在可接受范围内。
说实话看到 Negative 类 0.65 的时候我有点皱眉。这个数对工业级部署其实是不够的——你想想看,PRM 当 reward 用,假阳性会让 PPO 把模型推向一些看起来没错但实际有 bug 的代码风格上去。论文的 RL 涨点掩盖了这个问题,但如果换个更难的数据集或者更长的 horizon,PRM 噪声的累积可能会显现出来。这是个值得后续工作改进的点。
训练稳定性:PRM 的最大隐性收益

图5:Compiler Loss(蓝)、Preference Loss(橙)、PRLCoder Loss(绿)的对比。PRLCoder 收敛最快、最平稳——前 25 步几乎单调下降到 0.025 附近就收敛了;Compiler Loss 中间还出现了一个明显的反弹峰;Preference Loss 末段也开始抬头。
我个人觉得这张图比主表更能说明问题。
代码生成 RL 训练最大的痛点不是涨点幅度,而是稳定性。我之前调过 PPOCoder 的开源实现,最大的感受是 reward 经常震荡到怀疑人生——一会儿 0.9 一会儿 0.3,还分不清是 baseline 没估好还是 reward 信号本身就抖。这张图说明 PRM 不光涨点,训练曲线本身就更平滑、更可预测——这对真正想把代码 RL 部署到生产环境的团队来说,意义甚至比涨点更大。
为什么 PRM 能更稳定?我的理解是:每行都有 reward,PPO 的 advantage 估计能在更细粒度上做平均,方差自然就小了。这是密集奖励相对稀疏奖励的天然优势。
Case Study:看看 PRM 是怎么逐行打分的
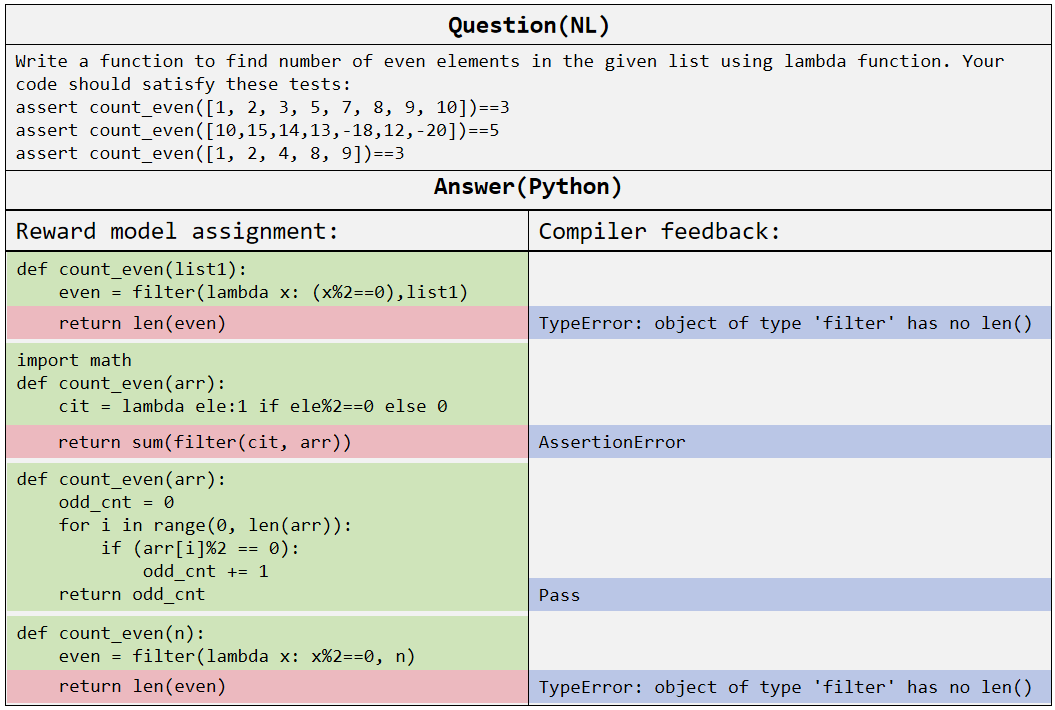
图6:一个 count_even 函数生成的 case study。绿色块是 PRM 判定为 Positive 的代码段,粉色块是判为 Negative 的。右边的"Compiler feedback"是真实的编译器反馈。可以看到 PRM 的判断跟编译器结果对得上——比如 return len(even) 这一行被判 Negative,编译器实测真的报了 TypeError: object of type 'filter' has no len()。
这个 case 挺直观地展示了 PRM 的工作机制——它确实能定位到具体哪一行错了,而不是只告诉你"整段代码挂了"。这就是过程监督的核心价值:定位错误位置,而不是只判定结果对错。
我特别喜欢这个 case 里的第三个解法:用 for i in range(0, len(arr)) 循环统计,PRM 把 4 行全判为 Positive,编译器实测也确实 Pass。这说明 PRM 学到的不只是"哪些写法编译会错",而是对代码生成路径的整体把握——它能识别出"这个写法一开始就走对了路"。
这篇论文到底怎么样?我的判断
亮点(确实做得好的地方):
- 自动构造步级别奖励数据的 pipeline 是真能用的。Mutation/Refactoring + 编译器自动打标签,这套思路在工程上可复制性很强。我自己最近在做类似事情,用这套方法生数据成本能降一个数量级。
- 难度分层实验是个加分项。把 MBPP 按代码长度分 EZY/MED/HRD 三档分别评估,让 PRM 的优势在哪儿暴露得很清楚——它就是在长代码上才显著起飞。
- 训练稳定性的体现。Loss 曲线那张图说服力比主表更强。
- 三种 ORM 对照做得扎实。没图省事拿最弱的对手凑数。
问题(坦诚说必须指出的):
- 基线模型只有 CodeT5+ (770M)。在今天 7B+ 代码模型遍地走的语境下,770M 已经偏小,迁移到 DeepSeek-Coder、Qwen2.5-Coder 这些 7B/14B 模型上效果如何完全是开放问题。论文 Limitations 里也老实承认了。
- PRM 的 Negative 准确率 0.65 偏低。这个数对长 horizon、高难度任务可能会有累积误差。
- 行级别 reward 还不够细。一行代码内部的不同 token 仍然是稀疏的,token 级别的 PRM 是个明显的下一步。
- 跟 Dai 等人的同期工作(arXiv:2410.17621)没法直接对比——因为 Dai 用闭源模型。论文坦诚提到了这点,但确实是对工作影响力的一个客观限制。
它在整个代码 RL 浪潮里处于什么位置?
我的判断是:这是代码生成 PRM 落地的早期奠基性工作之一,但不是颠覆性突破。整体框架(SFT→RM→PPO)跟主流 RLHF 完全对齐,PRM 思路也是从 OpenAI 数学推理的经验迁移过来的。真正的工程贡献是把"自动构造步级别数据"的 pipeline 跑通了——这个东西后面的工作肯定会借鉴。
跟数学领域 PRM 比一比,代码 PRM 的特殊性在哪儿
顺着上面的再聊聊——为啥代码 PRM 比数学 PRM 晚出来这么多?
数学推理那边,OpenAI 的 PRM800K 是 800K 条人工标注的步级别数据,Lightman 那篇 Let's Verify Step by Step 直接砸资源做出来的。后续 DeepSeek 的 Math-shepherd 用蒙特卡洛 rollout 自动构造数据替代人工,思路是"看这一步往后能不能 rollout 到正确答案",本质是用结果反推过程。
代码这边的难处是"过程对错"的定义比数学难得多:
- 数学一步:写出
x = 5这一步对不对,最终能否解出原题就是判据 - 代码一行:写出
pattern = char + '{2,}'这一行对不对,没法用单一判据。它可能语法对、运行不挂,但功能错了——这种 bug 编译器看不出来,只有把整套测试用例跑一遍才知道
PRLCoder 用 mutation 的方式硬生生把"功能正确性"压进了行级别标注里——通过反向构造(让 teacher 模型故意改坏一行),把那行的功能贡献暴露给编译器。这个思路跟 Math-shepherd 的 rollout 在哲学上是一致的,但操作上更粗暴更直接。
我自己的判断是,代码 PRM 长期来看不一定要走 line-level 这条路。代码的天然结构是 AST,按 if-else、按函数体、按循环体切分可能更符合代码的语义颗粒度。Ma 等人 2023 年那篇就是按 AST 操作的,理论上比按行更好,但工程上 AST 操作要适配多种语言,远比按 \n 切要复杂。所以 PRLCoder 选行级别是个工程上 cost-effective 的折中,但不是终局。
工程启发
如果你也在做代码生成 RL 训练,几个点值得抄:
- 测试用例覆盖率必须先增强。原始 MBPP 的覆盖率不够,会导致 reward 信号本身就是错的——这个隐藏 bug 会让所有下游对比失效。先补测试用例,再训 RM。
- Mutation/Refactoring 双路构造负样本。光让 teacher 模型胡乱改是不够的——Refactoring 应该出 Positive、Mutation 应该出 Negative,跑完编译器再过滤掉跟预期不一致的,这样数据质量才稳。
- PRM 的 reward 在行边界给信号就够了。token 级别理论上更细,但工程上 cost-benefit 不一定划算,按
\n切是个不错的工程默认值。 - 难度分层评估是必做的。光看整体平均分会掩盖真正有意思的现象——PRM 在难题上才发力,不分层根本看不出来。
一些更本质的追问
回头看这套工作,还有几个问题论文没回答:
- PRM 的 reward 模型本身能不能 scale up? Unixcoder 作为 RM base 在今天看是相当老的模型,换成更强的 base(比如 DeepSeek-Coder-7B)能不能让 PRM 准确率冲上 0.9?
- 能不能从行级别走到 AST 节点级别? Ma 等人 2023 年那篇就是按 AST 操作的,理论上比按行更符合代码的语法结构。
- 如果 reward 信号能闭环到 unit test 自生成怎么办? 当前 pipeline 还需要原始 MBPP 的 reference code,如果 teacher 模型能直接生成 problem + solution + test,整套系统就能 self-bootstrap 起来——这才是真正的代码 RL 终局。
这些问题作者自己在 Limitations 里也或多或少触及到了——这是一篇知道自己边界在哪儿的论文,挺难得。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我