NOVER:把 R1-Zero 的"激励训练"从数学题搬到任意文本任务,靠的不是更大的 verifier,而是一个 perplexity
核心摘要
DeepSeek-R1-Zero 火了之后,激励训练(incentive training)这条路被验证过:只在最终答案上算 reward,模型自己就会学会写中间推理。但它有个硬门槛——必须有一个能判对错的外部 verifier。数学和代码可以靠规则匹配,社会智能、创意写作、翻译这些"答案怎么对都难讲"的任务,verifier 根本写不出来。训 reward model?标注贵、上线开销大,还经常被 policy 反向 hack。
这篇 KCL + 图灵研究院 + 上交的 NOVER 给了一个挺漂亮的思路:直接拿 ground truth 答案在 reasoning trajectory 条件下的 perplexity 当 reward——推理写得好,预测真答案的 perplexity 就低,分数就高。不需要任何外部 verifier,只要一份普通的 SFT 数据。在 7 个跨域任务上,Qwen2.5-7B 用 NOVER 训完平均 47.31%,比同尺寸的 R1-Distill-Qwen-7B(671B 蒸馏来的)还高 7.7 个点。更骚的是,作者发现把"中间过程"和"最终答案"在训练范式里互换位置,就能搞出 inverse incentive training,让模型学着按 rubric 写故事,准确率从 50.79% 飙到 64.37%。
值不值得读?我的看法是值。它不是把 GRPO 又改一遍权重的工作,而是真的把 RLVR 的边界往外拓了一大块。
论文信息
- 标题:NOVER: Incentive Training for Language Models via Verifier-Free Reinforcement Learning
- 作者:Wei Liu, Siya Qi, Xinyu Wang, Chen Qian, Yali Du, Yulan He
- 机构:King's College London、The Alan Turing Institute、Shanghai Jiao Tong University
- arXiv:2505.16022v2
- 会议:EMNLP 2025 Main
一个让人头疼的现实问题
R1-Zero 出来之后,圈里有一阵子聊得很多的话题是:激励训练这条路到底能不能推广。
它的玩法你应该已经熟了——给模型一道数学题,让它在 <think>...</think> 里写推理、在 <answer>...</answer> 里写答案,外部用一个简单的 rule-based verifier 看答案对不对,对了 reward 给 1,错了给 0。GRPO 一抡,模型自己就学会写越来越像样的 CoT,aha moment、自我反思、试错回滚这些"高级"行为也跟着冒出来。整个过程不需要 step-level 标注、不需要训 reward model,朴素得让人感动。
问题是这套范式有个不能打破的前提:得有一个能稳定打分的 verifier。
数学有 sympy 帮你判等价,代码有单测帮你跑 case,这俩天然友好。但你换个场景看看:
- 用户问"为什么明朝会灭亡",怎么 verify?
- 帮我写一篇关于自闭症儿童的社交故事(Social Story),怎么 verify?
- 把一段英文翻成西班牙语,词序、用词都有多种合理选项,怎么 verify?
- 多人对话里推断"B 觉得 A 怎么想这件事"(theory-of-mind),怎么 verify?
之前的工作有两条路:要么写一堆 domain-specific 的规则(脆、不通用),要么硬训一个大 verifier model 来兜底(Ma et al. 2025 的 General Verifier、字节 Seed 的 verifier 都是这条路)。
两条路都不好走。第一条路,你写得越细,泛化越差;第二条路,verifier model 本身要训、要部署、要在 RL loop 里反复推理,算力成本可能比 policy model 还高。我自己之前在做长尾任务的 RL 时也尝试过 model-as-judge 这套,说实话,那个稳定性问题是真的让人头大——judge 模型一不小心就被 policy 反向 hack,要么放水,要么严过头训不动。
NOVER 这篇就是冲着这个问题来的。
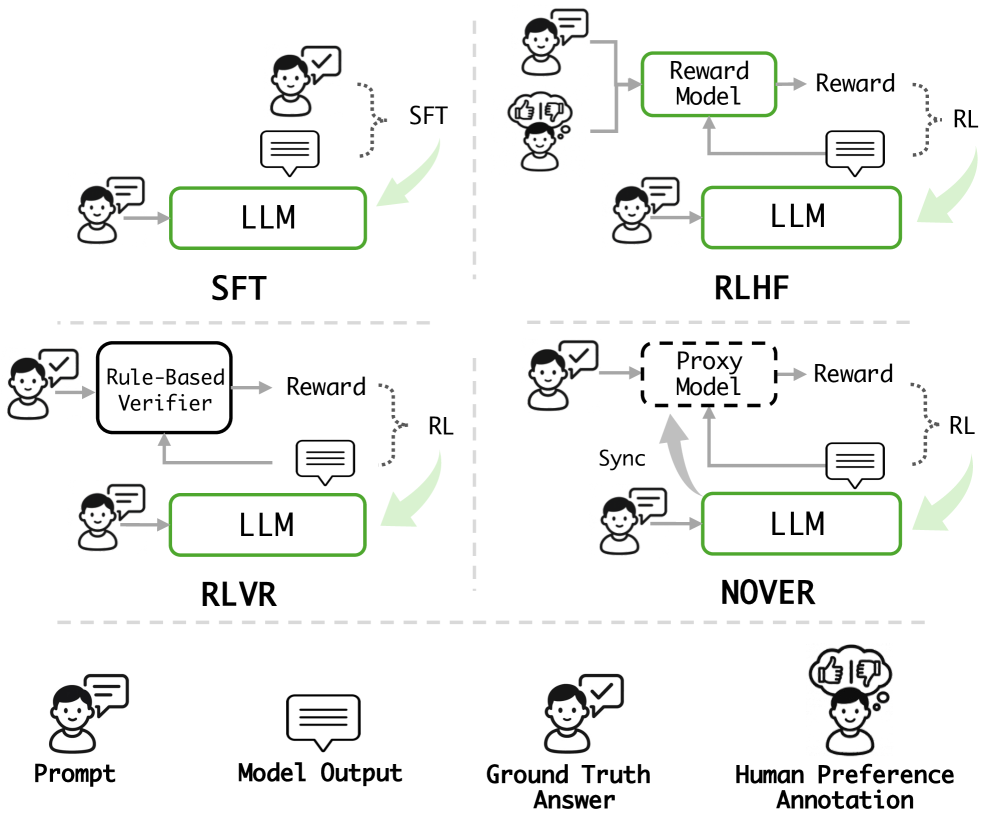
图 1:NOVER 跟 SFT、RLHF、RLVR 三种主流后训练范式的对比。SFT 直接拿 ground truth 监督;RLHF 要训一个 reward model;RLVR 靠规则验证器。NOVER 既不要 verifier 也不要 reward model,靠一个跟 policy 同步的 proxy model 来打分。
核心 idea:把"reasoning perplexity"当 reward
我看到这个方法的第一反应是——"等等,这个 loss 真的会收敛吗?"
但顺着想了一会儿,会觉得它其实挺自然的。
一个简单的直觉
假设你给模型一道题 \(p\),它先生成一段推理 \(t\),再生成答案 \(a\)。你手上还有一份 ground truth 答案 \(g\)(来自普通的 SFT 数据集)。
现在问个问题:给定推理 \(t\),模型生成 \(g\) 这条标准答案的概率是多少?
如果推理写得好,那预测 \(g\) 应该不难——perplexity 应该低;如果推理在胡扯,预测 \(g\) 就会卡壳——perplexity 会高。
把这个量当 reward signal,是不是比硬训一个 verifier 干净多了?
NOVER 给的具体公式是这样:
分子是 ground truth 在 reasoning 条件下的对数概率之和(teacher-forcing 算的,没解码开销);分母里 \(|g|\) 是答案长度做归一化,\(N(|t|) = \max(1, 1 + \log(|t|))\) 是给推理长度留了一个缓冲,防止 perplexity 跟着推理长度被压低(这种 length bias 是老问题了)。
然后这玩意儿替代了 RLVR 里的 \(R_{\mathrm{rule}}\),整个 GRPO pipeline 几乎不变。
作者还专门做了 profiling:因为 perplexity 是 teacher-forcing 算的,只占总训练时间的 ~5%。比起跑一遍 verifier model 推理,这开销可以忽略。
为什么是 policy 自己当 proxy?
这里有个我一开始没看明白的设计。
公式里那个 \(\pi_p\)(proxy model)算 perplexity 的"打分模型"——直觉上你会觉得它得是个独立的、冻住的模型,不然"既当运动员又当裁判"会出问题。
VR-CLI(Gurung & Lapata 2025)就是这么做的——拿一个外挂的冻住模型当 proxy。但 NOVER 反其道而行之,直接用 policy model \(\pi_\theta\) 自己来当 proxy,并且每隔 \(T_{\mathrm{sync}}\) 步做一次 EMA 同步:
作者的论证是:proxy 跟 policy 的目标是一致的——都是"在好的推理条件下,让正确答案的 perplexity 尽量低"。如果用一个冻住的 proxy,它会跟不断进化的 policy 逐渐脱节,导致 reward 信号跟实际能力错位。
这里其实有一个"运动员/裁判"的反驳——但作者把它挡掉了:proxy 不直接判好坏,它判的是"给定 ground truth,在你这条推理路径下出现的概率"。ground truth 是客观的,proxy 不是在自由发挥,它是在用客观锚做相对评分。
工程上更香的一点:因为用了 LoRA(占满模型参数 ~0.4%),policy 和 proxy 共享 base model,切换只需要换 adapter,几乎零额外显存。
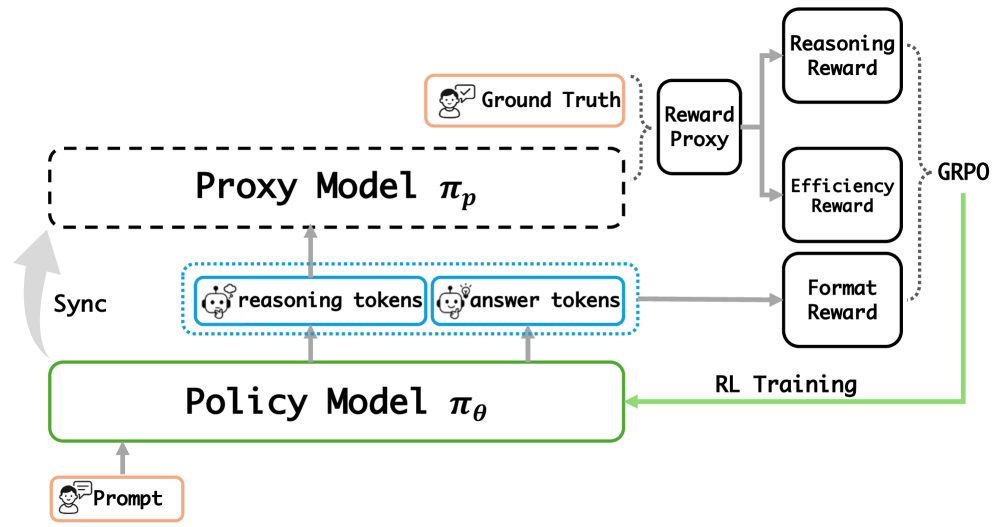
图 3:NOVER 的整体训练流程。Policy 跑 rollout 出 <think> 和 <answer>,Proxy 拿 <think> 之后的位置算 ground truth answer 的 perplexity 当 reasoning reward;同时还有 efficiency reward(鼓励"短而准")和 format reward(标签格式校验)。三个 reward 按一种条件组合方式合在一起,喂给 GRPO。
不是把 perplexity 直接当 reward 就完事了
这块是我觉得论文最有价值的工程细节。
如果你天真地把 perplexity 直接拿来排序、再 group-normalize 一下塞进 GRPO,会出事。作者实测出三种 fail mode:
Fail mode 1:reasoning explosion(推理爆炸)
模型发现一个 hack:在 reasoning 里直接写一段类似 + <answer> + <common_question> = ... 的"伪代码",把答案的字面前缀塞进去,于是预测 ground truth 的 perplexity 变得贼低。结果是 completion 长度从 ~400 token 直接飙到 1000+,输出乱码但 reward 很高。
Fail mode 2:reasoning collapse(推理坍缩)
反过来一个极端:模型发现写极少的 reasoning tokens 也能拿到 reward(因为 perplexity 的 length bias 没完全消除,短 reasoning 反而更稳),于是直接学会"啥也不想",<think>Physics.</think> 草草交差。
Fail mode 3:proxy drift(代理漂移)
policy 在变,proxy 不变,几千步之后两者 distribution gap 越来越大,reward 信号开始抽风。
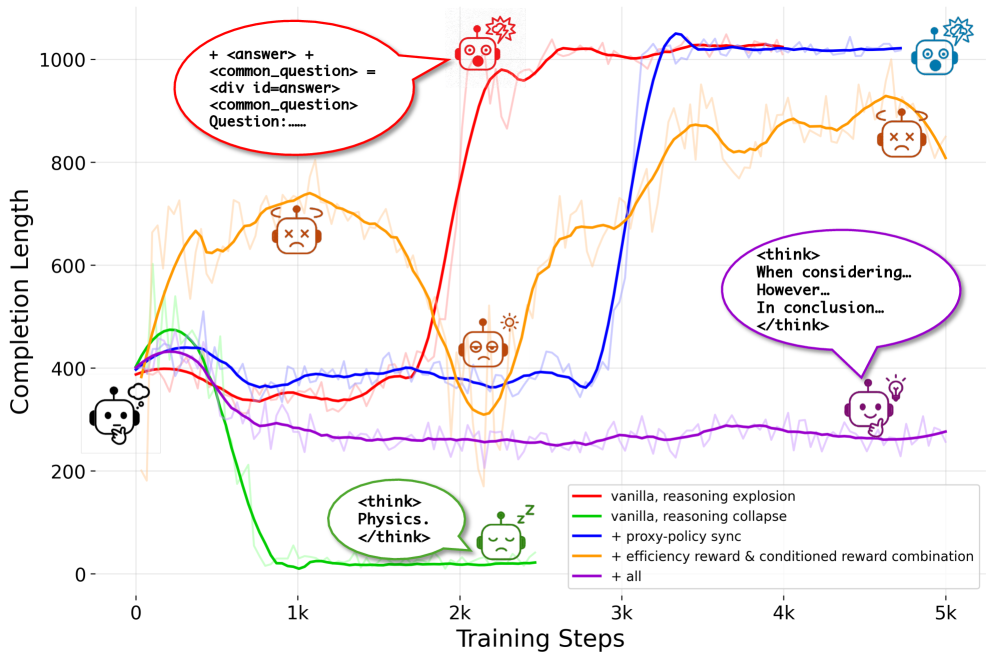
图 5:作者称之为 "curse of proxy"——proxy reward 不准,模型就会找漏洞 hack。红色是 reasoning explosion(直接把答案前缀塞进 think 里),绿色是 reasoning collapse(什么都不想),蓝色是只加 sync 的版本,橙色加了 efficiency 和 conditioned reward,紫色是 NOVER 全套。紫色那条几乎是直线,挺漂亮的。
三剂猛药
为了堵住这些洞,NOVER 一共加了三个组件:
1. Reasoning Reward 离散化:不用连续的 perplexity 当 reward(方差太大、clip ratio 不稳定),而是按 group 内 perplexity 排名给离散分数:
\(k=1\) 时只奖励最优那条(适合客观任务),\(k=n_{\mathrm{valid}}\) 时按 quantile rank 全员排名(适合开放式任务)。
2. Efficiency Reward:奖励"用更少 reasoning tokens 拿到更低 perplexity"的样本:
群组内对每个 sample \(i\) 数一下:"有多少其他样本既比我 perplexity 高又比我 reasoning 长?" 数得越多,说明你"短且准",reward 就越高。这一招把 reasoning explosion 干掉了——啰嗦没好处。
注意这里有个细节:作者并不用 \(R_e\) 替代 \(R_r\),因为训练前期大部分 completion 都还没学会"短而准",光有 efficiency reward 会全 0、训不动。\(R_r\) 是基本盘,\(R_e\) 是加分项。
3. Conditioned Reward Combination:这个设计我特别喜欢。
只有 format 正确(\(R_f=1\),标签合法)时,reasoning reward 和 efficiency reward 才会被加进去;否则直接归零。
这一招挺关键的——模型如果用乱码格式去 hack reward,它先在 format 这关被拒,整组 reward 直接掉到地板,相对优势变成大负数,policy 立刻被推开这条路。这就避免了 reasoning explosion 那种"输出乱码但 perplexity 低"的死循环。
加 sync 是为了对付 proxy drift,加 efficiency 是为了对付 explosion,加 conditioned combination 是为了把 explosion 进一步堵死。三剂药下去,紫色那条曲线才能走得那么稳。
实验:从数学题到翻译,全场景拉通
主实验:7 个数据集横扫
实验设置覆盖 4 大类任务:
| 类别 | 数据集 | 性质 |
|---|---|---|
| General Reasoning | Natural Reasoning(NR)、General Thoughts-430k(GT)、WebInstruct(WI) | 多步推理、事实导向 |
| Creative Writing | SS-GEN(SGN) | 自闭症儿童社交故事生成 |
| Social Intelligence | EmoBench(EB)、ToMBench(TB) | 情绪识别、心智理论 |
| Multilingual | OPUS-BOOK-TRANSLATION(OP) | 16 种语言、64 个语言对 |
模型用 Qwen2.5-3B / 7B 的 base checkpoint(不是 instruct),训练用 LoRA + GRPO。Qwen2.5-7B 在 2 张 H100 上训 1000 步、max length 1024,大概 2 小时。
主表数据(数据严格对照原文 Table 1):
| 方法 | NR | GT | WI | SGN | EB | TB | OP | 平均 |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-3B Base | 21.80% | 43.10% | 18.40% | 18.70% | 32.03% | 46.79% | 16.70% | 28.22% |
| 3B + CoT | 24.40% | 48.90% | 24.20% | 14.76% | 28.12% | 51.23% | 1.40% | 27.57% |
| 3B + SFT | 27.00% | 36.20% | 27.30% | 20.08% | 36.72% | 48.66% | 17.30% | 30.47% |
| 3B + NOVER | 28.60% | 60.30% | 28.10% | 41.64% | 38.28% | 57.88% | 20.70% | 39.36% |
| Qwen2.5-7B Base | 31.80% | 48.50% | 20.70% | 24.21% | 28.91% | 44.22% | 19.30% | 31.09% |
| 7B + CoT | 31.20% | 57.60% | 29.20% | 33.46% | 38.28% | 50.99% | 1.60% | 34.62% |
| 7B + SFT | 27.50% | 45.20% | 33.50% | 37.85% | 47.66% | 57.06% | 23.30% | 38.87% |
| 7B + NOVER | 38.20% | 61.80% | 36.60% | 50.79% | 49.22% | 67.79% | 26.80% | 47.31% |
| Qwen2.5-7B-Instruct | 29.90% | 56.20% | 35.60% | 67.72% | 46.88% | 65.23% | 23.50% | 46.43% |
| R1-Distill-Qwen-7B | 41.00% | 60.20% | 38.00% | 40.16% | 35.16% | 54.61% | 8.20% | 39.62% |
几个让我感觉"嗯,能打"的点:
第一个点是 7B-NOVER 的平均分 47.31%,比 R1-Distill-Qwen-7B 的 39.62% 高了 7.7 个点——这就是论文摘要里反复说的那个 7.7%。R1-Distill-Qwen-7B 是 DeepSeek 用 671B 老师蒸馏出来的,训练数据量、reasoning 质量都不是一个量级的资源;NOVER 只用了一份普通 SFT 数据 + LoRA + 2 张 H100 + 1000 步训练,能反超还是挺意外的。
第二个点是 OPUS(翻译)这一列。R1-Distill-Qwen-7B 在翻译上只有 8.20%,7B + CoT 直接掉到 1.60%——这其实是个挺典型的"reasoning 反而拖累 task"的案例:模型一边想一边写翻译,越想越偏,自由发挥型 CoT 在翻译这种"对照型任务"上是反作用。NOVER 把它拉回 26.80%,这是因为 perplexity proxy 对"翻译要忠于原文"这件事有天然的抓力——你乱发挥,ground truth 的 perplexity 就上去了。
第三个点是 SFT 在 NR 这列上居然不如 base model(27.50% vs 31.80%)。这是个挺反直觉的数据,作者的解释是:SFT 让模型学会"直接给答案",反而压制了它本来就有的 CoT 能力。这跟 Chu et al. 2025(SFT memorizes, RL generalizes)的结论吻合——拿来当辅助论据用挺到位。
不过我也得说一句话:Qwen2.5-7B-Instruct 在 SGN 上 67.72%、TB 上 65.23%,依然比 NOVER 强。Instruct 版本有海量 instruction-following 数据训过,在某些任务上的天花板是 NOVER 在 SFT 数据上做 RL 够不到的。NOVER 不是万能解,它的位置是"在我没有 reward model 也没有海量 instruct 数据时,用一份基础 SFT 数据就能把模型提到一个挺高的水平"。
跨模型骨干:Mistral / LLaMA 也有效
Table 2 给了 Mistral-7B-Instruct 和 LLaMA-3.1-8B 上的实验。结论很简单:NOVER 在不同模型上都有提升,但需要 base 模型本身有 instruction-following 和基础 CoT 能力——LLaMA-3.1-8B 的 base checkpoint 表现一般,但 Instruct 版本就能跟上。
这其实也是 RLVR 的老生常谈了:base 模型得先有"会想"的能力,激励训练才能把这个能力激发出来。如果 base 连 instruction-following 都做不到,RL 喂进去也是浪费。
数据维度切片分析
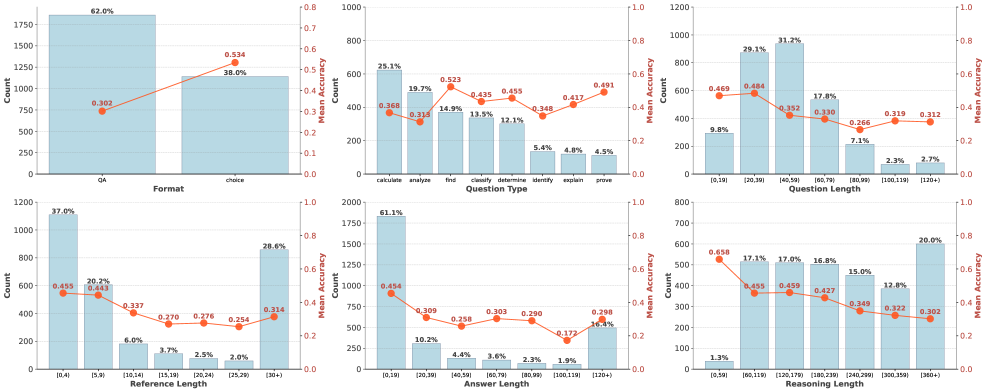
图 4:NOVER 在 NR/GT/WI 上按 6 个维度切片的准确率。蓝柱是样本数量,红线是平均准确率。Choice 类型 53.4% 显著高于 QA 30.2%,因为选项缩小了搜索空间;reasoning length 0-59 token 段准确率 65.8%,越长反而越低——印证了"长 reasoning 不一定更好"。
这张图我觉得挺有意思的有两点:
第一,reasoning length 跟准确率是负相关的——0-59 token 段 65.8%,120+ 段降到 30.2%。这跟 Sui et al. 2025 那篇"effective reasoning length matters"的结论完全一致。所以 efficiency reward 不是凭空加的,是有数据支撑的。
第二,question type 那张图:在 calculate、analyze、find 这些"主动操作型"任务上,准确率从 36.8% 到 52.3% 不等,但 identify、explain、prove 这些"判断型"任务反而准确率更低(34.8%、41.7%、49.1%)。我猜是因为后者的答案空间更开放,perplexity proxy 的判别力会下降——这其实是 NOVER 本身的一个边界。
为什么 NOVER 比"模型当 verifier"更稳?
这一节是论文的另一块亮点。作者直接做了实验对比 verifier-free vs model-as-verifier。
Table 4:NOVER vs LLM-as-Judge vs General Verifier(WebInstruct 数据集)
| 类别 | 方法 | Qwen2.5-3B | Qwen2.5-7B |
|---|---|---|---|
| Baselines | Base | 18.40% | 20.70% |
| + CoT | 24.20% | 29.20% | |
| + SFT | 27.30% | 33.50% | |
| Model as Verifier | + GV(General Verifier) | 18.30% | 30.00% |
| + LJ(LLM Judge,宽松版) | 21.40% | 3.80% | |
| + LJ_S(LLM Judge,严格版) | – | 21.60% | |
| Verifier-Free | + NOVER | 28.10% | 36.60% |
+ LJ 在 7B 上掉到 3.80%——这不是数错了,是真的训崩了。
作者的解释是:宽松版的 LLM judge prompt 鼓励 reward hacking——policy 学会输出"看起来合理但实际模糊"的答案(比如给个粗略的方向、不写具体步骤),judge 一看"嗯,跟 reference 大方向对得上"就给正分。policy 越训越油滑,最后准确率从 base 的 20.70% 掉到 3.80%,这就是 reward hacking 把模型训歪了的真实案例。
严格版 prompt(LJ_S)改善了一些,到 21.60%,但 3B 直接训不起来——严格 prompt 给的奖励太稀疏,正样本不够多,整个 RL loop 转不动。
General Verifier(Ma et al. 2025 训出来的专用 verifier model)在 7B 上做到 30.00%,比 LLM Judge 稳一些,但还是被 NOVER 的 36.60% 干翻了。作者发现 verifier 模型经常被 policy "套路"——比如 policy 故意只写一半步骤、把 verifier 引导成"自己解题",verifier 一不小心就放水。
NOVER 的优势在哪?它判的不是"答案对不对",而是"在你这条推理路径下,标准答案的 perplexity 是不是低"。这个量没法被 policy 用文本技巧 hack——你要降低 ground truth 的 perplexity,唯一的办法就是把推理写得真的能引导出 ground truth。
我觉得这一段是 NOVER 论文里 critical thinking 最值得吸收的部分:verifier 越聪明,hack 它的方式就越多;perplexity 看似简单粗暴,但它的攻击面非常窄。
推理模式的演化:从 Decomposition 到 Direct
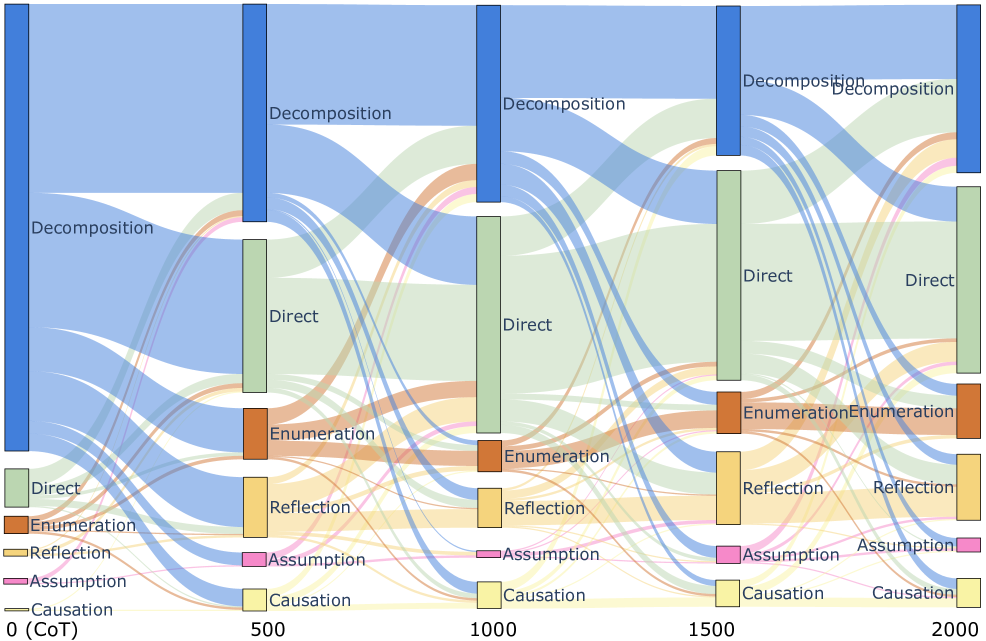
图 6:训练过程中推理模式的演化。横轴是训练步数(0、500、1000、1500、2000),纵轴是各类模式的占比。0 步时(CoT prompting)几乎全是 Decomposition——典型的"我先把问题拆成几步"的 CoT 模板。训练到 2000 步时,Direct(直接给中间结论,不啰嗦)占比大幅上升,同时 Enumeration、Reflection 等模式也开始稳定出现。
这张 Sankey 图我看了挺久。
它讲的是一件挺微妙的事:CoT prompting 出来的推理大部分是"任务分解"模式("我要先 ... 然后 ... 最后 ..."),但 efficiency reward 一加上去,模型很快学会跳过冗余的分解步骤、直接给中间结论。
这跟我们工程里观察到的现象很一致:让模型 "think step by step",它会把每一步都写得啰里啰嗦的,但实际上很多步骤本身没贡献——模型只是在执行"我应该写 step 1 / step 2 / step 3"这个模板。NOVER 通过 efficiency reward 把模板的部分压掉,让模型只在真正需要的地方思考。
至于 Reflection 和 Enumeration 的占比上升,作者的观点是:随着训练进行,模型学会在确实需要枚举或反思的地方使用相应的模式,而不是一刀切地用任务分解。这就是 RLVR 类方法常说的"emergent reasoning behaviors"——只是这里没有 verifier 也跑出来了。
Inverse Incentive Training:把"过程"当"结果"训
到这里如果论文就结束,已经是一篇扎实的工作了。但作者又抛出来一个挺巧的玩法。
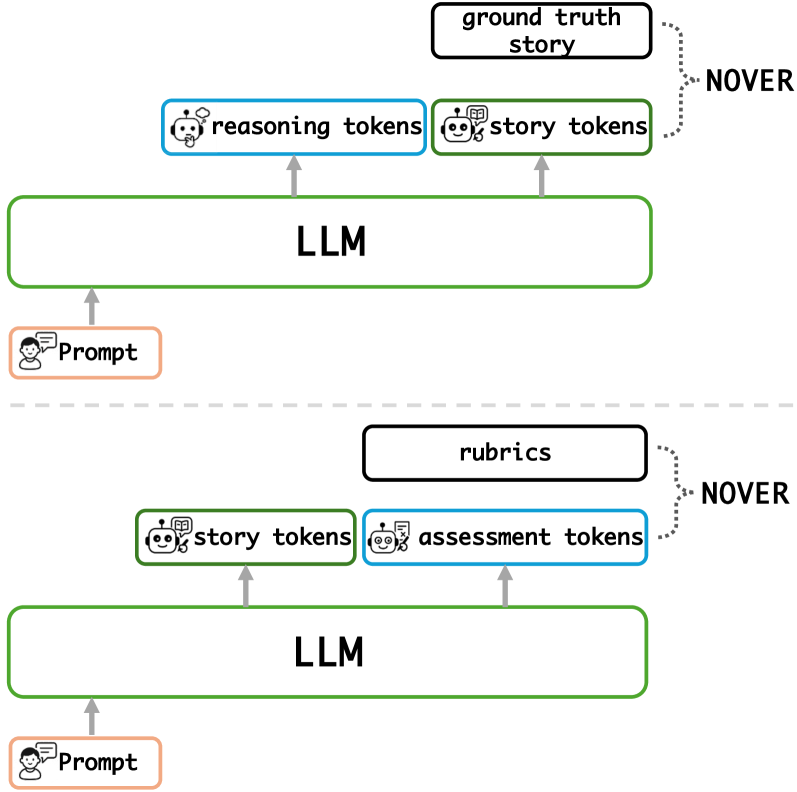
图 7:上半部分是标准 NOVER——把 reasoning 当中间过程、把 story 当最终答案、用 ground truth story 当 perplexity 的对照。下半部分是 NOVER_RUBRIC——把 story 当中间过程、把 assessment 当最终答案、用 ground truth rubric 当对照。两种范式互换了"过程"和"结果"的位置。
它要解决什么问题?
SS-GEN 数据集里有两类东西:参考故事 + rubric(评估标准,比如"用词得当"、"陈述句多于指导句"等 6 个维度)。
如果用标准 NOVER 训:reasoning → story,story 的 perplexity 跟 reference story 对照——这种训法会让模型"模仿参考故事",学的是写作风格。
但 social story 的本质不是"模仿某个参考故事",是"按 rubric 写故事"。参考故事只是 rubric 的一个实例,硬模仿就把方差也学进去了。
NOVER_RUBRIC 的反向操作
作者把整个流程反过来:story → assessment,assessment 的 perplexity 跟 rubric 对照。
读起来有点绕,我重述一下:模型的目标是"先写一个故事,然后写一段对这个故事的评估,让评估在 rubric 条件下 perplexity 低"。模型要写一个能被 rubric 准确评估的故事——而 rubric 是在"过程"位置,故事反而成了"中间产物"。
我说"反直觉"主要是在这儿:传统范式里,中间过程是为最终答案服务的;这里反过来,中间过程(故事)才是真正想要的输出,最终答案(评估)只是个"对照标尺"。
效果
| 方法 | SS-GEN 准确率 |
|---|---|
| Qwen2.5-7B + 标准 NOVER | 50.79% |
| Qwen2.5-7B + NOVER_RUBRIC | 64.37% |
涨了 13.6 个点。
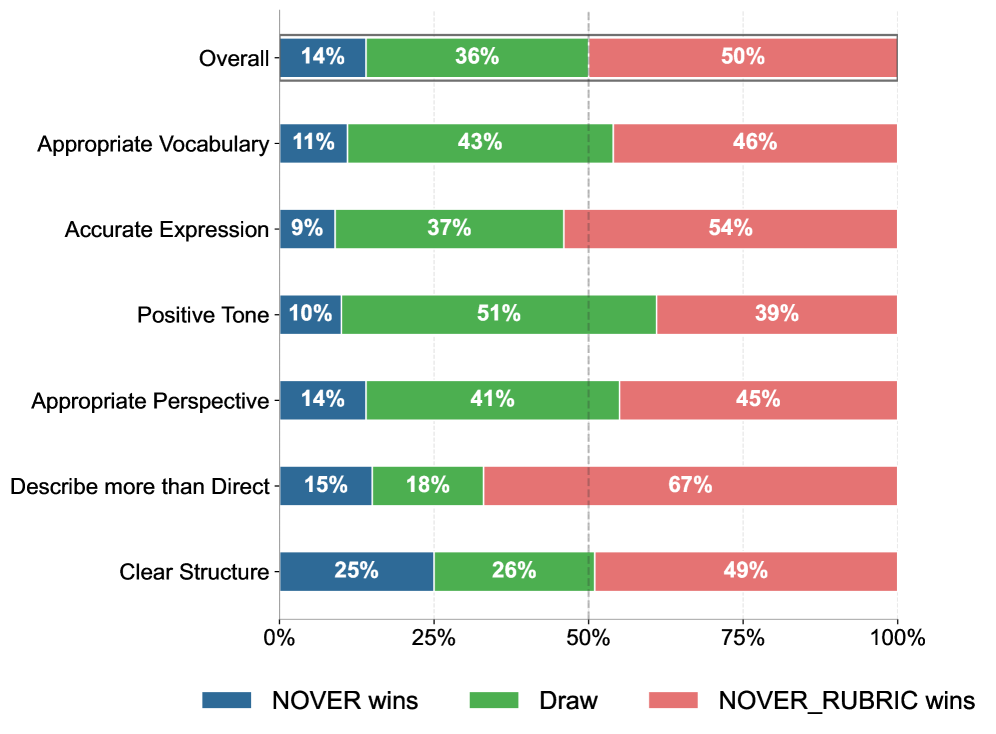
图 8:100 个样本人工评测结果。Overall NOVER_RUBRIC 胜率 50%、平局 36%、NOVER 胜 14%。在 "Describe more than Direct"(陈述多于指导)这个最关键的 social story 准则上,NOVER_RUBRIC 胜率高达 67%。
这块东西我看的时候还挺感慨的。它把 NOVER 框架从"用 RL 训 reasoning 能力"扩展到了"用 RL 训任意需要按 rubric 生成的内容",creative writing、structured generation、按格式生成报告……都可以套这个范式。
唯一的注意点:作者也承认"光有 rubric 类的 outcome reward 没有 process reward,故事会偶尔出现幻觉(比如重复'once upon a time'两次)"。所以未来要把 process reward 和 outcome reward 结合,这是个开放问题。
我的判断:值得读、能落地,但有边界
亮点在哪
1. 真的把 RLVR 的边界往外推了。从数学/代码到任意 text-to-text 任务,这步跨度挺大。之前业界的解法基本都是"训更大的 verifier",NOVER 给了一个完全不同的方向——用模型自己当 perplexity 计算器。
2. 工程上挺务实。LoRA + 共享 base + EMA 同步,整套训练只比 RLVR 多 5% 的算力开销。这个数我看了下 Appendix B 的 profiling,是真实跑出来的。
3. Conditioned reward combination 这个设计挺漂亮。format 不对就把 reasoning reward 直接归零,这一招把 perplexity hack 的攻击面切掉了一大半。我觉得这是论文里最值得借鉴的工程 trick。
4. Inverse incentive training 这个 idea 挺让人兴奋。它意味着 NOVER 不只是 RLVR 的一个 verifier-free 替代,而是一个新的训练范式骨架——只要你有"过程 + 结果"两类数据,无论谁当过程谁当结果,都能套进来训。
边界和问题
1. 需要 base 模型已经有基础的 instruction-following 和 CoT 能力。这是 RLVR 的通病,NOVER 没解决。如果你的 base 模型是 LLaMA 那种纯预训练 checkpoint,得先 SFT 一下再上 NOVER。
2. 在 false premise(前提错误)类任务上会输给 SFT。FANToM 这类需要"识别题目本身有问题"的任务,base 模型本来就答不对,NOVER 又依赖 base 模型先生成正确答案再强化,自然 work 不起来。这块作者也写得挺坦诚——这是 RL 类方法的硬伤,不是 NOVER 一个人的问题。
3. Perplexity 在答案空间过于开放的任务上判别力会下降。比如"写一首诗"、"给我 10 个营销文案 idea",ground truth 的 perplexity 几乎对所有合理输出都差不多,reward 信号就会很模糊。这块需要 inverse incentive training + rubric 配合才能 work。
4. 跟 Qwen 强绑定。论文里基本都是 Qwen 实验,LLaMA 和 Mistral 实验也是只用了 Instruct 版本。在更小或更弱的 base 模型上能不能 work,论文里没给充分证据。
跟同期工作的位置
NOVER 出来的时间点(2025 年 5 月)正好夹在几个相关工作之间:
- VR-CLI(Gurung & Lapata, 2025):用一个冻住的外部 model 算 perplexity,NOVER 把它换成了 policy 自己 + EMA 同步
- General Verifier(Ma et al., 2025):训一个通用 verifier model,被 NOVER 在 WebInstruct 上压了 6.6 个点
- Dr.GRPO / DAPO / SimpleRL:都是 GRPO 的变体优化,但都假设有 verifier
NOVER 跟它们不是同一个层面的工作。前面的工作是在 RLVR 的框架里改进 algorithm,NOVER 是在框架外面动了一下"reward 是从哪来的"这件事。这个差异决定了它的应用面比那几个改 GRPO 权重的工作要宽得多。
工程落地的几个建议
如果你也在做类似的事情,几个直接能用的点:
1. 找不到 verifier 的领域,可以试试这个思路。我们之前在做一个 domain-specific 报告生成的项目,纠结要不要训 reward model,看完这篇之后觉得 perplexity proxy 这条路值得先试。代码量也不大,TRL + LoRA + GRPO 加几行代码就能起来。
2. Conditioned reward combination 那个 trick 通用性很强。任何用 model-based reward 的场景,先上一个 cheap 的 format/legality check,把奖励"按通过率 gate 住"。format 不对就归零,避免 reward hacking 把训练带歪。
3. Inverse incentive training 用在 structured generation 上。如果你的任务是"按规则/模板/rubric 生成内容",没有 ground truth instances 的时候,把 rubric 当 ground truth、把生成内容当中间产物——这个范式值得仔细想想。
4. Efficiency reward 别忘了。但凡用 RL 训 reasoning,加一个"短而准 > 长而准"的 reward 几乎肯定有用。NOVER 这个 \(R_e\) 的写法(pairwise 对比)也很容易照搬到其他场景。
结尾
NOVER 这篇我觉得是 2025 年激励训练这条线上挺有分量的一篇。它不是把 GRPO 又调一遍参数的工作,而是真的把 RLVR 的边界从"有 verifier 的领域"推到了"任意 SFT 数据可以做的领域"。
更重要的是,它给了一个清晰的信号——激励训练的本质不是"verifier",而是"有一个比模型当前能力更稳定、更客观的锚"。这个锚可以是规则、可以是 reward model、也可以是 ground truth 在 perplexity 视角下的一个映射。看清楚这一层,之后这类方法的设计空间就大很多。
我比较期待的后续是:把 perplexity proxy 跟更细粒度的 process reward 结合,把 false premise 这类硬伤补上,再把 inverse incentive training 推到更多 structured generation 任务上去。这条路应该还有不少空间。
参考链接: - 论文:arXiv:2505.16022 - 代码:GitHub: jacquelinejiarunliu/NOVER(论文中引用的项目地址)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我