AWS 这篇论文让 LLM Agent 的记忆"自己长出索引",RAG Recall 暴涨 34%
EMNLP 2025 · MemInsight:LLM 智能体的自主记忆增强
核心摘要
做过 long-term agent 的人多少都被这个问题搞过:用户跟 Agent 聊一两个月之后,历史 session 越堆越多,retrieve 出来的"相关上下文"越来越像在抽奖。RAG 把所有 turn 切块塞进向量库,对面问一句"上次我跟你说我对那个事的态度是啥来着",top-5 召回的全是字面相似但语义无关的片段。
这篇 EMNLP 2025 来自 AWS AI 的 MemInsight 给了一个挺干净的方案:让 LLM 自己给历史对话生成结构化属性标签(intent/emotion/entity/event 等),把"扁平的 raw 对话流"变成"带语义索引的记忆片段",retrieve 时既可以按属性过滤,也可以拿属性向量化做 dense search。
效果是真打:在 LoCoMo 长程对话 benchmark 上,RAG(DPR)召回率 26.5%,MemInsight 直接干到 60.5%,相对提升 128%(论文写的是 +34 个点 / +35% overall recall)。在电影对话推荐 LLM-REDIAL 上,"高度有说服力"的推荐占比从 13% 提到 25%,同时只用 1/14 的记忆片段。
我读完最大的感受是:这套思路并不"炸",但它把 Agent Memory 这个领域里大家含糊其辞的"记忆增强",第一次给出了一个清晰可工程化的拆解维度——perspective × granularity × prioritization。值不值得读?如果你正在做对话型 Agent 的长期记忆模块,这篇是必读,至少能省你三周的实验时间。
论文信息
- 标题:MemInsight: Autonomous Memory Augmentation for LLM Agents
- 作者:Rana Salama, Jason Cai, Michelle Yuan, Anna Currey, Monica Sunkara, Yi Zhang, Yassine Benajiba
- 机构:AWS AI(Amazon)
- 会议:EMNLP 2025
- arXiv:2503.21760v2
为什么 Agent 的"长期记忆"是个真问题
先聊点工程上的痛。
去年我跟着团队做了一个面向 To-C 的对话型 Agent,定位是"长期陪伴 + 记住用户偏好"。第一周的体验是真的惊艳——你跟它说"我家猫叫小球,最近肠胃不太好",第二天问"小球今天怎么样"它能接住。
第三周开始翻车。同一个用户问"上次推荐的那个咖啡店地址再发我一下",Agent 检索回来的是三天前一段完全无关的关于"猫粮品牌"的对话片段——只因为那段里出现了"地址"这个词。
这就是 raw memory + naive RAG 的典型死法:对话历史作为非结构化文本被 chunk 之后,向量化保留的全是字面信息,而真正决定相关性的是语义角色(user intent / emotion / entity / event 等)。
学术界对这个问题有几种处理思路:
| 路线 | 代表工作 | 短板 |
|---|---|---|
| 把对话压缩成 summary | MemoryBank、LoCoMo Baseline | 压缩损失细节,多轮检索失真 |
| 把对话切成 event sequence | Maharana et al. 2024 | event 边界靠 LLM 切,质量不稳 |
| 把记忆建成知识图谱 | AriGraph | 节点/边的 schema 需要预定义 |
| 操作系统式分页 | MemGPT | 仍然是 raw text,没有语义结构 |
| 手工 schema 标注 | A-Mem | task-specific 笔记需要人定义模板 |
| 工业级 pipeline | Mem0 | 偏工程,语义结构化不深 |
MemInsight 想解决的核心矛盾是:既要结构化(保证检索精度),又要自动化(不依赖人工 schema)。
它给出的答案就一句话——让 LLM 自己看着对话生成标签,标签自己当索引。
方法核心:把记忆增强拆成三个正交维度
整个方案的架构图长这样:
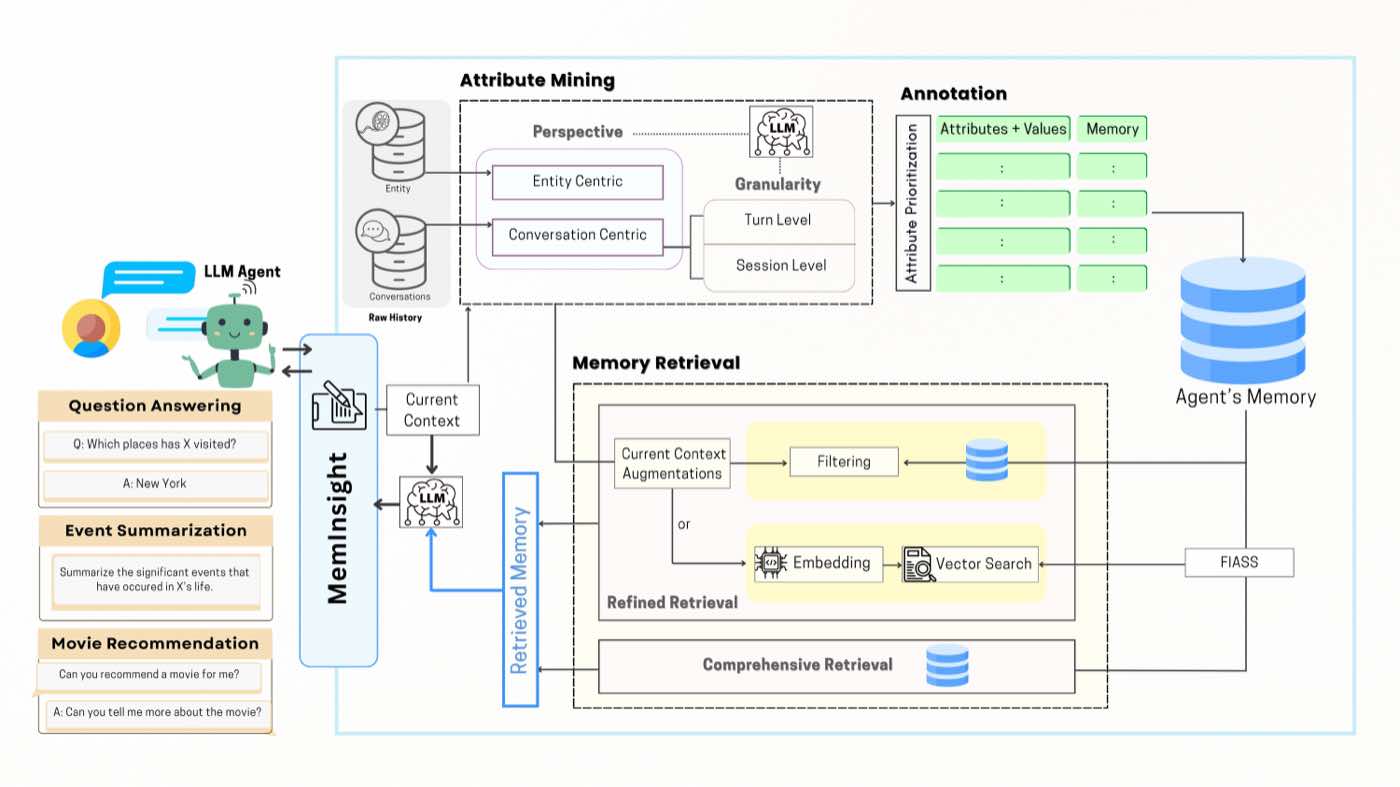
图1:MemInsight 框架的三个核心模块。Attribute Mining 负责从原始对话中挖掘语义属性(区分 perspective 和 granularity 两个维度);Annotation 把属性绑定到对应的记忆实例上(包含 prioritization 排序);Memory Retrieval 提供 refined retrieval(属性过滤 + 向量召回)和 comprehensive retrieval(全量带回)两种模式。下游可对接 QA、事件总结、对话推荐等任务。
我个人觉得这张图最有价值的不是模块切分,而是把"记忆增强"拆成了三个正交维度:
- Perspective(视角):你是站在"实体"(entity-centric)的角度打标签,还是站在"对话"(conversation-centric)的角度?
- Granularity(粒度):你是 turn-level 一句一句标,还是 session-level 整段总结?
- Prioritization(优先级):标签按相关性排序,还是无序堆?
这三个维度独立,组合出多种增强策略。看起来不复杂,但之前的工作要么只做其中一个维度(比如 MemoryBank 只做 session 总结),要么把维度混在一起没拆清楚。
Perspective:实体视角 vs 对话视角
Entity-centric 关注的是"对话里提到的那个东西本身的属性"——比如用户说"我喜欢《盗梦空间》",标签会是 {title: 盗梦空间, director: Christopher Nolan, genre: Sci-Fi, release_year: 2010, ...},重点是把实体"立体化"。
Conversation-centric 关注的是"用户为什么这么说"——同一句话,标签会是 {intent: 推荐, emotion: 好奇, motivation: 想找烧脑的电影, perception: 经典, ...}。
举个论文里的例子,看一眼就明白这俩视角的区别:

图2:左边是 entity-centric 的例子,对图书 "Already Taken" 生成 title/author/genre/publisher/themes 等结构化属性;右边是 conversation-centric 的例子,从一段用户对电影《The Screaming Skull》表达失望的对话里提取 intent / emotion / perception / memory / format 等对话维度的属性。同一段文本,两套视角拿到的是完全不同的语义切片。
实战的启发是:做推荐场景偏 entity-centric,做闲聊/陪伴偏 conversation-centric。论文里的实验也是这么分的——电影推荐用 entity-centric,对话 QA 用 conversation-centric。
Granularity:turn 级 vs session 级
这个维度更直观——你想要"颗粒度细到每一句"还是"颗粒度粗到整个 session"。
论文里有张图特别直观:

图3:左边是一段 Melanie 和 Caroline 关于"参加心理健康慈善跑"的多轮对话;右上是 turn-level 标注(每一轮各自标注 event/time/emotion/topic),右下是 session-level 标注(整段对话归纳出每个说话人的 event/emotion/intent)。turn 级保留了"上周六" "rewarding" 等具体细节,session 级则总结成 "ran charity race for mental health" + "thinking about self-care" 这种更高层的语义。
工程上的 trade-off 也很经典:
- turn-level 信息密度高,对细颗粒检索(比如"用户上次提到 X 时是什么情绪")友好,但标签数量爆炸
- session-level 标签少、聚合度高,对整体把控(比如"这个用户最近一周的关注点是什么")友好,但丢细节
实验里 turn-level 在事件总结任务上整体优于 session-level——这个我自己也踩过坑,当年做 session 总结发现 LLM 会把不该揉到一起的事件揉到一起。
Prioritization:把最重要的属性放第一位
这里是个特别工程化的小细节:基础版(Basic)就是把属性无序拼起来,Priority 版是让 LLM 在生成时按相关性从高到低排。
为什么这事儿有意义?因为后续做 embedding-based retrieval 的时候,会把所有属性 concat 起来过 encoder。如果属性顺序不固定,embedding 会受到位置偏置干扰;按重要性排序之后,第一个属性总是"最锚"的语义信号。
实验数据很能打——Priority 版本在 LoCoMo 上的 recall 比 Basic 版高了 12 个点(48.8 → 60.5),多出来的 12 个点全是排序带来的,没动模型也没动数据。
我看到这个的第一反应是:这个 trick 其实在 dense retrieval 圈里早被证明过——做 BM25 + reranker 时大家都知道把核心 term 放前面收益巨大。论文把它平移到了 LLM 自动标签场景,简单但有效。
Attribute Prioritization 的 Prompt 是怎么写的
附录里有完整 prompt,核心一段是:
1- Identify the key attributes in the dialogue turn and their corresponding values.
2- Arrange attributes descendingly with respect to relevance from left to right.
3- Generate the sorted annotations list in the format: [attribute] where attribute is the attribute name
and value is its corresponding value from the text.
4- Skip all attributes with none values
Important: YOU MUST put attribute name is between [ ] and value between <>.
Only return a list of [attribute] nothing else.
格式 [attribute_name]<value> 这种带分隔符的写法,方便后续 parse;显式要求"按相关性降序"是核心;"跳过 none 值"避免 LLM 凑数。
这套 prompt 工程上挺值得复用的,不要小看格式约束的威力——之前做属性抽取的同行应该都知道,把 LLM 的输出格式锁死之后,下游 pipeline 的稳定性会上一个台阶。
检索:属性可以当 filter,也可以当 embedding 输入
有了带属性的记忆之后,retrieve 有两种玩法。
Refined Retrieval(精修式):先把当前 query 也跑一遍属性增强,拿到 query 侧的属性集合 \(A_Q\),然后两条路径任选:
-
Attribute-based:用 \(A_Q\) 跟记忆库的属性集合做 match,类似 SQL 的 WHERE 子句 $\(\mathcal{R}_{\text{attr}}(A_Q, \mathbb{M}) = \text{Top-}k \{(A_k, M_k) \mid \text{match}(A_Q, A_k)\}\)$
-
Embedding-based:把属性集合送进 encoder 拿到 dense vector,做余弦相似度 $\(\text{sim}(A_Q, A_k) = \frac{\phi(A_Q) \cdot \phi(A_k)}{\|\phi(A_Q)\| \cdot \|\phi(A_k)\|}\)$
Comprehensive Retrieval(全量式):直接把所有相关记忆 + 它们的所有属性都带回上下文,靠模型自己挑——这个是兜底方案,适合上下文窗口够长的场景。
embedding 这块还有个有意思的细节,论文比较了两种向量化方式:

图4:以三部电影为例(《无间行者》《禁闭岛》《霍比特人》),左边是"对每个属性独立 embed 然后取平均"的方法(averaging over independent embeddings),右边是"把所有属性拼成一段文本一次性 embed"的方法(all augmentations embedding)。三者两两对比的余弦相似度差异很有意思:左侧《无间行者》vs《禁闭岛》是 90.23%(导演同为 Scorsese,类型相近),vs《霍比特人》是 75%;右侧 vs《禁闭岛》拉到 91.5%,vs《霍比特人》却跌到 37.97%——拼接式 embed 把"差异"放大得更明显。论文最终选了 averaging 方法,因为它更稳定。
这个对比挺有教育意义。我自己之前一直觉得"反正都是 embedding,怎么聚合差不多吧"——看完这个例子才意识到,当属性数量不均、字段长短不一时,"先 embed 再 pool"比"拼起来一次 embed"对长尾属性更友好。
实验:三个任务,一边能打一边有疑点
任务 1:LoCoMo 长程对话问答
LoCoMo 是 30 个多 session 对话,每个对话覆盖几周到几个月的时间跨度,问题分五类:single-hop、multi-hop、temporal、open-domain、adversarial。
主表(Table 1,F1 score):
| Model | Single-hop | Multi-hop | Temporal | Open-domain | Adversarial | Overall |
|---|---|---|---|---|---|---|
| Baseline (Claude-3-Sonnet, 全量历史) | 15.0 | 10.0 | 3.3 | 26.0 | 45.3 | 26.1 |
| LoCoMo (Mistral v1) | 10.2 | 12.8 | 16.1 | 19.5 | 17.0 | 13.9 |
| ReadAgent (GPT-4o) | 9.1 | 12.6 | 5.3 | 9.6 | 9.81 | 8.5 |
| MemoryBank (GPT-4o) | 5.0 | 9.6 | 5.5 | 6.6 | 7.3 | 6.2 |
| MemInsight (Claude, attr-based) | 18.0 | 10.3 | 7.5 | 27.0 | 58.3 | 29.1 |
| RAG Baseline (DPR) | 11.9 | 9.0 | 6.3 | 12.0 | 89.9 | 28.7 |
| MemInsight (Mistral v1, Priority) | 16.1 | 14.1 | 6.1 | 16.7 | 81.2 | 30.0 |
| MemInsight (Claude, Priority) | 15.8 | 15.8 | 6.7 | 19.7 | 75.3 | 30.1 |
Recall@5(Table 2):
| Model | Single | Multi | Temporal | Open | Adv. | Overall |
|---|---|---|---|---|---|---|
| RAG (DPR) | 15.7 | 31.4 | 15.4 | 15.4 | 34.9 | 26.5 |
| MemInsight (Llama, Priority) | 31.3 | 63.6 | 23.8 | 53.4 | 28.7 | 44.9 |
| MemInsight (Mistral, Priority) | 31.4 | 63.9 | 26.9 | 58.1 | 36.7 | 48.9 |
| MemInsight (Claude, Priority) | 39.7 | 75.1 | 32.6 | 70.9 | 49.7 | 60.5 |
Recall 这块是真的能打——overall 从 26.5 拉到 60.5,相对涨了 128%。multi-hop 从 31.4 直接干到 75.1,单跳到双跳推理的提升尤其明显。
但 F1 score 这边我得吐槽两句。
第一:adversarial 类问题上,DPR 的 89.9% 远高于 MemInsight 的 75.3%。论文一笔带过说"DPR 略高",但这其实暴露了一个问题——对抗类问题往往是要识别"对话里其实没说过这件事",而 MemInsight 的属性增强会主动补全语义,反而容易被诱导。这是个不能忽略的 trade-off。
第二:multi-hop 和 temporal 在 attribute-based 检索下不如 baseline(Claude-3-Sonnet 全量历史)。论文的解释是"LoCoMo 用的是 partial-match F1 metric"——这个解释不太能服人,partial-match 应该对所有方法都一视同仁。我倾向于认为属性化之后的 turn-level 检索丢失了对话间的时序连接,做 multi-hop 时缺少"桥梁信息"。
不过 Recall 拉得这么开,整体方向肯定是对的。Priority 版本一致优于 Basic,验证了排序的价值。
任务 2:LLM-REDIAL 电影对话推荐
LLM-REDIAL 是 10K 段对话 + 11K 部电影提及。评估时把 ground-truth 电影 mask 掉,让模型基于历史推荐。
直接看 LLM-based 评估(Persuasiveness 和 Relatedness):
| Model | 检索条数 | Unpers ↓ | Partial Pers | Highly Pers | Not Comp ↓ | Comp | Match |
|---|---|---|---|---|---|---|---|
| Baseline (Sonnet, 全量) | 144 | 16.0 | 64.0 | 13.0 | 57.0 | 41.0 | 2.0 |
| MemInsight (Sonnet, attr-based) | 15 | 2.0 | 75.0 | 17.0 | 40.5 | 54.0 | 2.0 |
| MemInsight (Haiku, embed) | 10 | 1.6 | 53.0 | 25.0 | 23.3 | 74.4 | 2.2 |
| MemInsight (Sonnet, comprehensive) | 144 | 2.0 | 74.0 | 12.0 | 42.5 | 56.0 | 1.0 |
亮点很清晰:
- 检索量从 144 降到 15(减 89.5%),还把 Unpersuasive 比例从 16% 压到 2%——这个数据是真的硬。说明属性化检索精准度高很多。
- Highly Persuasive 从 13% 升到 25%,这个幅度在推荐任务上算大新闻。
- Relatedness 维度上,"Comparable" 占比从 41% 提到 74.4%。
但传统的 Recall@K 和 NDCG@K 几乎没动——R@10 从 0.015 提到 0.025,绝对值都低得像噪声。
论文自己也承认这个矛盾:"These improvements were not reflected in recall and NDCG metrics."
我的解读是:LLM-REDIAL 的 ground truth 是"电影标题精确匹配",而 LLM 推荐的电影可能是 ground truth 的"同类替代"——这种情况下传统指标全失效,只有 LLM-as-judge 能识别"虽然不是同一部但是是好推荐"。所以这块的评估方法学比绝对数字本身更值得关注。
任务 3:LoCoMo 事件总结
用 G-Eval 评 Relevance / Coherence / Consistency:
| Model | Sonnet Rel. | Sonnet Coh. | Sonnet Con. | Mistral Rel. | Mistral Coh. | Mistral Con. |
|---|---|---|---|---|---|---|
| Baseline | 3.27 | 3.52 | 2.86 | 3.39 | 3.71 | 4.10 |
| MemInsight (TL only) | 3.08 | 3.33 | 2.76 | 2.54 | 2.53 | 2.49 |
| MemInsight (SL only) | 3.08 | 3.39 | 2.68 | 4.13 | 4.41 | 4.29 |
| MemInsight + Dialogues (TL) | 3.29 | 3.46 | 2.92 | 4.30 | 4.53 | 4.60 |
这个表的关键发现是:只用属性不够,属性 + 原始对话才是最优组合。Mistral v1 上从 baseline 的 3.39/3.71/4.10 提到 4.30/4.53/4.60,提升幅度很可观。
但 Sonnet 上几乎没提升(3.29 vs 3.27)——这暴露了一个事实:强模型本身已经能从 raw dialogue 里抽取事件,属性增强的边际收益不大;弱模型才更需要这种结构化辅助。
这个发现挺重要的:MemInsight 对小模型的增益更大。如果你正在用 7B 级别的模型做 Agent,这套方法的 ROI 会比用 70B 模型高很多。
那些容易被忽略的细节
99.14% 的标注是"无幻觉"的
附录里有个挺有意思的数据——用 DeepEval 跑幻觉检测,Claude-Sonnet 生成的属性 99.14% 是 grounded in dialogue 的,剩下 0.86% 主要是"过于抽象"而不是"事实错误"。
但 Llama 和 Mistral 就没这么稳。论文给了个具体例子:

图5:同一段 Jon 和 Gina 的对话("Lost my job as a banker yesterday, so I'm gonna take a shot at starting my own business.")三个模型给出的标注对比。Claude(左)给出最简洁准确的标签:person/job_status/former_job/intent;Llama(中)出现了大段幻觉(红色),凭空补全了 Gina 的反应、Jon 想开烘焙店、有商业计划等原文里完全没说的内容;Mistral(右)虽然没幻觉但用了 happy 这种不准确的 emotion 标签(Jon 刚失业不太可能 happy)。
这张图其实是论文里最值钱的几张之一——它直接告诉你这套方法对 backbone LLM 的依赖有多重。如果你用开源弱模型来跑属性挖掘,幻觉会污染整个记忆库,retrieve 出来的"准确属性"其实是模型脑补的。
LLM-REDIAL 上的属性分布
附录里给了 9687 部电影上提取属性的统计:平均每部 7.39 个属性,Top-5 是 Genre / Release year / Director / Setting / Characters,覆盖了 99.7% 的电影(Failed 0.10%)。
这个数据有两层意义:
- 99.9% 的成功率说明 attribute mining 在结构良好的领域(电影/书籍)几乎是"开箱即用"
- 属性分布存在长尾——Genre 出现 9662 次(几乎全覆盖),Characters 只有 3603 次。Priority 排序就是为了让头部属性主导 embedding 信号。
几点批判性思考
痛点是真的,但解法是不是最优?
MemInsight 解决的痛点是真实的——长程 Agent 的 raw memory 检索确实在大规模下崩盘,这个我自己踩过太多次。
但解法层面我有几个疑问:
1. LLM 自动标签 vs 知识图谱:MemInsight 把对话拆成 (attribute, value) 二元组,其实就是一种"扁平化的轻量级 KG"。同期的 AriGraph 直接做了 episodic + semantic 的双层 KG,从结构表达力上看更强。论文跟 AriGraph 没有直接对比,这是个遗憾。
2. 全量增强 vs 增量增强:论文用的是"对话发生时立即标注"的 push 模式,但实际工程里很多场景是"用户问到了再标"的 pull 模式(节省 LLM 调用)。论文没讨论 cost / latency 这块,对工业落地不够友好。
3. 属性 schema 是不是应该跨用户复用:MemInsight 让每段对话独立生成属性集合,导致不同用户的同一类事件可能被打成不同标签。这对单用户检索没问题,但跨用户的 memory 共享/迁移就麻烦了。Mem0 在这块走的是更工程化的统一 schema 路线,思路不一样。
实验配置的几个小水分
Backbone 选择:MemInsight 用 Claude-3-Sonnet 做 backbone,对比的 baseline 用的是 GPT-4o 或 Mistral v1。模型不对齐就比性能,结论的可信度会打折扣。
Adversarial 维度的"高分":DPR 在 adversarial 上拿到 89.9% F1,远高于其他方法。这其实是因为 adversarial 类问题往往要"拒绝回答",而 retrieval 不充分时模型更容易拒答(高 F1 = 拒答正确)。这个分数本身就不能直接当作 retrieval 质量的证明。
Recall 提升 vs F1 提升的不一致:Recall 翻倍但 F1 只涨了 4 个点(26.1 → 30.1),这说明MemInsight 召回了更多相关记忆,但模型没能把召回的内容都用上。retrieve 不是瓶颈,answer generation 才是。这个角度论文没展开。
那哪些点是真的有价值
抛开吐槽,我觉得这篇的核心贡献是这几点:
1. 维度拆分本身:把"记忆增强"清晰拆成 perspective × granularity × prioritization 三个正交维度,这个分类法本身就值得做长期记忆模块的同行借鉴。后续做这块的工作大概率会沿用。
2. Priority Augmentation 的 Trick:12 个 recall 点的提升,纯靠 prompt 工程实现。投入产出比极高,几乎所有做属性抽取的 pipeline 都应该加这一步。
3. Embedding 聚合方式的对比实验:averaging vs all-in-one 的对比给了一个反直觉但靠谱的指引——多属性场景下"先 embed 再 pool"比"拼起来一起 embed"更稳。
4. 弱模型增益 \gt 强模型:Mistral 上的提升远大于 Sonnet 上的提升。这个发现对小模型部署场景特别有意义——你不一定非要换大模型才能做好长期记忆,加一层 attribute mining 可能就够。
工程上能怎么用
如果你正在做对话型 Agent 的长期记忆模块,这套方法可以分三步落地:
第一步:选 perspective。如果是推荐/问答类任务,做 entity-centric;如果是陪伴/情感类,做 conversation-centric;两个都要的话,分两套属性独立索引。
第二步:选 granularity。短对话 turn-level 起步,长对话同时维护 turn 和 session 两套粒度,retrieve 时根据 query 类型动态选择(具体细节问题走 turn,整体把握走 session)。
第三步:把 Priority Augmentation 的 prompt 直接抄过去用。这是最容易落地、收益最稳的一步。
最后顺便提一句,这套方法的最大成本是 LLM 调用 —— 每条对话都要过一次 backbone LLM 做属性增强。线上场景如果调用频次高,需要考虑: - 用更便宜的模型(Haiku/Mistral)做属性挖掘,但要接受质量下降 - 异步增强(先把 raw 存下来,定时 batch 跑) - 增量增强(只对会被检索到的高频对话做)
论文没讨论这块的成本侧,但工程化必然要面对。
收尾
回到开篇那个问题——为什么"记得住"的 Agent 这么难做?
这篇 MemInsight 的回答是:raw memory 不是真正的"记忆",结构化的 semantic representation 才是。这个观点本身不新——人类记忆心理学说了几十年了——但第一次有人在 LLM Agent 这个场景里把它做成了一套清晰可工程化的 framework,并且用 60.5% recall vs 26.5% RAG 给了一个让人没法反驳的数字证明。
我对它的判断:这不是底层突破,但是这个赛道里少有的"拆得清楚 + 数据扎实"的工作。会成为后续做 Agent Memory 的人绕不开的一篇引用。如果你团队正在为长期对话记忆模块发愁,强烈建议照着这个 framework 先跑一版 baseline,再讨论要不要上更复杂的 KG / Graph RAG 方案。
至于"AI Agent 的记忆问题被解决了吗"——还远着呢。MemInsight 解决的是"语义索引",但 Agent Memory 还有更难的问题:how to forget(什么时候该忘),how to consolidate(怎么把短期记忆固化成长期),how to share across users(怎么跨用户做记忆迁移)。这些这篇没碰,但都是接下来值得做的方向。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。