不动模型、没有标签,让 Agent 在测试时把准确率干到 93.94%——EMNLP 2025 这篇 Schema Mapping 论文挺有意思
一篇关于"测试时强化学习"如何在企业日志整合这种脏活累活上真的落地的论文。
一个被人忽略的脏活
做企业 IT 平台的人都知道一个事——日志这玩意,整合起来比你想象中要痛苦得多。
防火墙、终端、云应用、网络流、API 调用,一天可能就要吞下几个 TB。这还不是最难的。最难的是这些日志的 schema 五花八门:来自不同厂商、不同版本、不同年代的产品,每家有自己的字段命名习惯,文档可能压根没有,可能格式错乱,可能描述对不上实际数据。
你要把这堆乱七八糟的东西映射到自己的 Common Schema 上去做下游分析、关联检测、合规审计。这就是 schema mapping 问题。
通常的做法是什么?要么写一堆人工规则(脆弱、不可扩展),要么找专家手动对齐(贵,每天能处理的字段就那么多),要么上 LLM 直接 prompt(一次性输出,错就错了)。再进阶一点上 RAG,把已有的字段说明库作为上下文喂给模型——这能涨到 70% 多,但再往上就上不去了。
为什么上不去?因为新接进来的厂商日志,文档本身就是缺的。 RAG 检索的是"已经知道"的东西,对"完全没见过"的字段无能为力。
更关键的是——你没法用 fine-tuning 解决这个事。原因有两个:一是你没有标注数据(如果有标注,你就直接拿标注用了,不用费这劲儿),二是这种映射往往依赖运行时上下文而不是死规则(一会儿我会用 LocalPort 这个例子讲清楚为什么 fine-tune 反而会害你)。
EMNLP 2025 Industry Track 上 TrendMicro AI Lab 这篇 Mapping Smarter, Not Harder 把这件事捋了一遍,给了一个我觉得挺干净的答案:让 Agent 在测试时自己上网搜证据、用"预测一致性"当 reward,迭代地把映射准确率从 72.73% 推到 93.94%。完全不更新模型权重,完全不需要标签。
核心摘要
痛点:第三方厂商日志的 schema 映射是企业数据接入的卡脖子环节。文档常常缺失或错乱,标注数据基本没有,fine-tuning 既贵又不一定 work——尤其是当映射规则本身依赖运行时上下文的时候。
核心方案:把 TTRL(测试时强化学习)的思路搬到 schema mapping 上。Agent 不更新模型权重,而是在推理时不停做这件事——发现自己在某个字段上"前后预测不一致",就把这个 ambiguity 当成线索,去网上搜证据,把有用的证据塞进 prompt context,用"预测一致性"作为 confidence reward 来决定证据留不留。一句话:用 prompt-level 的"语言记忆"代替参数更新。
关键效果:在 Microsoft Defender for Endpoint 日志映射到 Trend Micro Common Schema 的任务上,GPT-4o 的准确率从 56.4%(裸 LLM)→ 72.73%(RAG)→ 100 轮迭代后 93.94%;需要专家复审的低置信度字段从 26 个降到 4 个,减负 85%。
我的一句话评价:这不是"算法层面"的突破,是工程层面把 Reflexion + Search-R1 + Self-consistency 三个思路在一个非常具体的工业场景上拼出了一个能 work 的闭环。论文的真正价值在于,它给"测试时 RL 怎么真的落地到 enterprise pipeline"提供了一个干净的样本。但 confidence 作为 reward 这件事还没解决——文章自己也承认存在 overconfidence 问题。
论文信息
- 标题:Mapping Smarter, Not Harder: A Test-Time Reinforcement Learning Agent That Improves Without Labels or Model Updates
- 作者:Wen-Kwang Tsao, Yao-Ching Yu, Chien-Ming Huang
- 机构:TrendMicro AI Lab
- 会议:EMNLP 2025 Industry Track
- arXiv:2510.14900
为什么这个问题值得单独拿出来做
我之前在做内部数据接入的时候碰到过完全一样的事——你把 vendor 提供的字段说明文档喂给一个 LLM,它能告诉你 70% 字段映射得八九不离十。剩下那 30% 是真正的硬骨头:
- 字段名长得像但语义不一样(
LocalPortvsRemotePort) - 文档里写的描述跟实际数据样本对不上
- 同一个字段在不同 traffic direction 下应该映射到不同的目标字段
这 30% 才是项目能不能上线的关键。而且你会发现一个让人皱眉的现象——这些"困难字段"本身的难,不是知识问题,而是上下文依赖问题。
举个论文里的例子,特别有代表性。
Microsoft Defender for Endpoint 里有两个端口字段:LocalPort 和 RemotePort。Common Schema 里有个 dpt(destination port)。你想把 LocalPort 映射到 dpt 还是 RemotePort 映射到 dpt?
答案是——看流量方向。出站连接的时候,本机是源,目的端口在远端,所以 dpt 应该映射 RemotePort;入站连接(比如 RDP 远程登录),本机是目的,那 dpt 就映射 LocalPort。
你想想看这种情况下 fine-tune 能解决问题吗?不能。 你 fine-tune 的本质是把一个"条件规则"压成"记忆关联",最后模型大概率学到的是 "dpt → RemotePort" 这种 spurious correlation,碰到入站流量直接错。这个例子是论文 Appendix A 的 case study,我觉得它把"为什么不能 fine-tune"讲得比正文还透。
所以问题就变成了——怎么让 Agent 在测试时自己想办法把这种条件性、上下文依赖的映射做对?
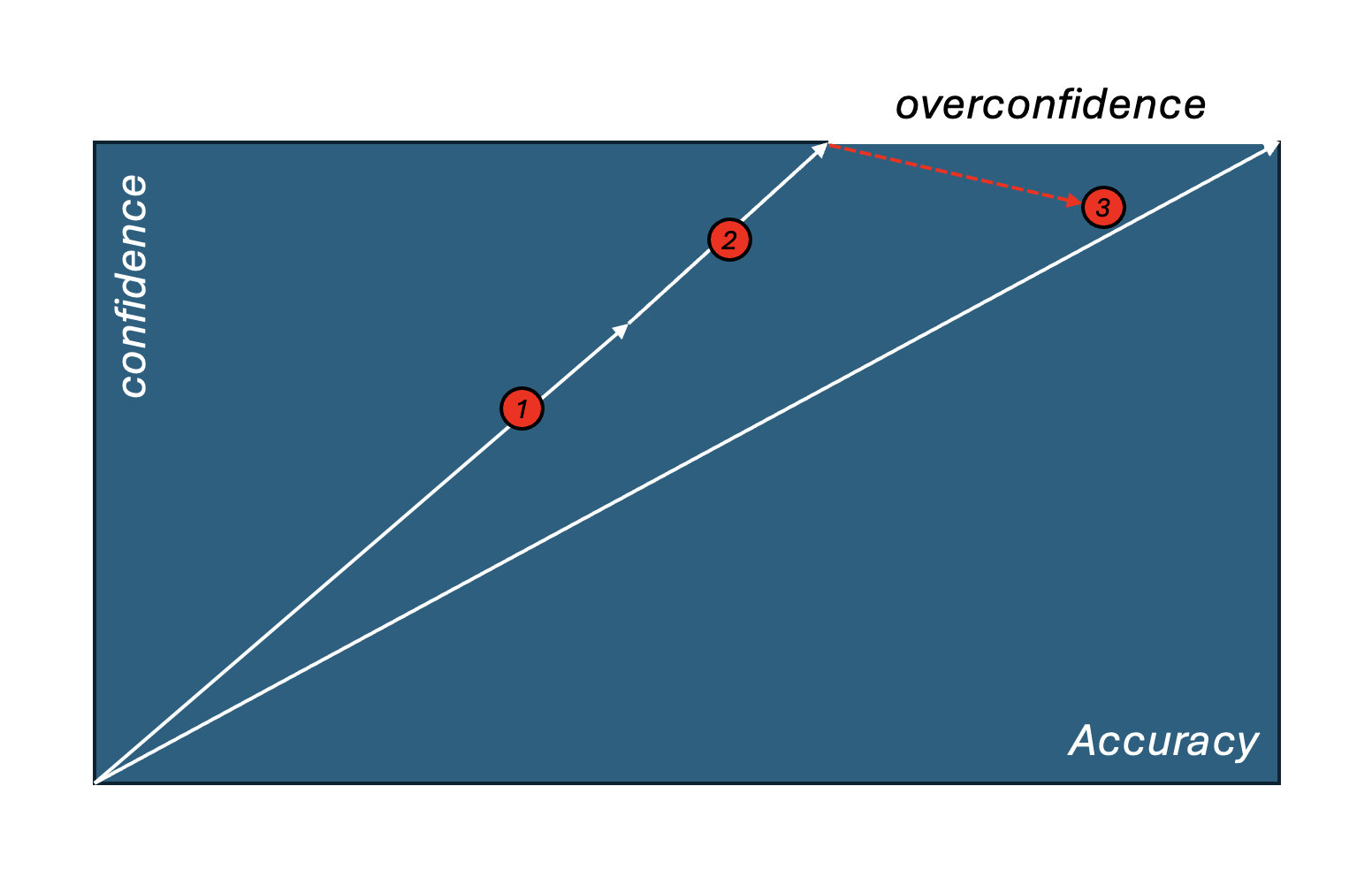
图 1:作者把整个 schema mapping pipeline 拆成了 A/B/C/D 四个阶段。A 是把 raw log 解析成结构化 KV(LogParser-LLM 那种活);B 是给定字段做一次性映射(Schema-Matching-LLM 的 baseline 能力);C 是 RAG 增强检索(ReMatch、MatchMaker 这些方法假设你有完整文档);D 才是论文真正在做的——当文档不全、知识库覆盖不到的时候,让 Agent 跳出企业 KB 的边界去外部搜索。Figure 中具体演示的就是 LocalPort=443 这条日志,三个研究问题(RQ1: 能不能检测出歧义?RQ2: 能不能不靠标签改进?RQ3: 内部 KB 文档不够好怎么办?)把论文的动机交代得很清楚。
方法核心:把 RL 的语言换成"prompt-level 的语言"
先把直觉摆出来——
这个 Agent 干的事,本质就是给自己写读书笔记。
每一轮迭代里,它做三件事:先用当前的 prompt context 把所有字段映射出来一遍,看看哪些字段在多次采样下结果不一致(ambiguous),把这些不一致的字段当成"自己学得不够好"的信号;然后针对这些字段去网上搜(论文用的是 Bing),把搜回来的内容总结成证据;最后看看这些证据加进去之后,置信度(也就是预测一致性)有没有涨——涨了就把证据保留,没涨就丢掉。
100 轮下来,prompt 里就长出了一份"靠 confidence delta 筛过的证据库"。
这就是论文说的 verbal RL——policy 的更新不是改模型权重,而是在 context 里增删信息。
几个关键设计
State:当前的字段映射假设 + 已积累的证据集,\(s_t = \{M_t, E_t\}\)。
Action:选一个有冲突的字段去查,并生成一个针对性的搜索 query。
Reward:置信度的变化量,\(r_t = C_{t+1} - C_t\)。这是整个方法的核心 trick——没有 ground truth 就用预测一致性代替。
Confidence 怎么算的:对每个字段做 3 次预测,取最频繁的那个预测出现的次数除以总次数:
注意一个小细节,"adjusted_total"对空预测(模型不确定时输出 NOT_COVERED)的权重是 0.5 而不是 1.0——这是为了鼓励模型在没把握时大方承认不知道,而不是硬猜一个看起来合理的答案。这点其实挺关键,论文也引用了 Kalai et al. 2025 那篇关于"为什么模型会幻觉"的工作,思路是一脉相承的。
Policy:直接用 LLM 本身的推理能力。给一个 system prompt + 已积累的证据 + 当前要映射的字段,让 LLM 输出。这里的 policy 不是一个独立的网络,而是 LLM + 当前 context 这个组合。
算法长这样
整个流程伪代码非常干净:
# 输入: 源 schema S, 目标 schema T, 迭代上限 α=100, 每轮采样 n=3 次
E = {} # 初始证据集为空
for i in range(alpha):
# 1. 用当前证据生成映射
f = LLM(S, E)
# 2. 用 n 次采样检测冲突字段
C = conflict_detection(f, n)
# 3. 对每个冲突字段
for s_i in C:
Q = formulate_query(s_i) # 生成搜索 query
e = web_search(Q) # 收集外部证据
r_new = evaluate_confidence(f(s_i), e) # 加证据后的新置信度
r_old = current_confidence(f(s_i)) # 之前的置信度
if r_new > r_old:
E = update_context(E, e, r_new) # confidence 涨了才保留
return f, E
这里有一个让我觉得设计得挺漂亮的点——证据筛选完全是 confidence-driven 的,没用任何外部信号。也就是说这个 Agent 在做"自我蒸馏式的学习":它自己说什么算"懂了",自己说什么算"没懂"。
但这种设计也有它的代价——一会儿讲实验结果时会聊到。
Prompt 架构
论文 Appendix C 列出了三个 prompt:
| 名称 | 作用 | 调用频次 |
|---|---|---|
| System Prompt | 把 LLM 设定成"网络安全数据专家",提供分层推理框架 | 每个 session 加载一次 |
| User Prompt | 携带每次请求的载荷:往期冲突总结、RAG 取出来的字段上下文、当前任务,强制 XML 格式输出(CSV 决策、1-5 分置信度、reasoning) | 每次映射请求都用 |
| Search Prompt | 基于冲突信息生成针对性的 web search query | 仅在冲突解决阶段调用 |
System Prompt 里有一段我觉得挺值得抄下来的——它显式告诉模型走"分层推理"流程:
(1) identify core entities such as IP addresses, filenames, and hashes;
(2) narrow down candidate fields based on data flow direction and context;
(3) make precise mapping decisions supported by semantic consistency.If no suitable mapping exists, respond professionally with NOT_COVERED.
这种"先识别实体类别,再缩小候选,最后做决策"的提示工程其实很基础,但跟 confidence-based reward 配在一起就能放大效果——因为模型在第二步"缩小候选"的时候越严谨,第三步的预测一致性就越高,confidence 就越高,证据就越容易被保留。
实验:从 56.4% 到 93.94%,关键看曲线怎么爬上去的
实验设置很 industry:
- 源 schema:Microsoft Defender for Endpoint,195 个字段
- 目标 schema:Trend Micro Common Schema,137 个字段
- Ground truth:66 对人工核对的字段映射,由领域专家、威胁情报、产品三方协作标注
- 模型:GPT-4o
- 每轮采样:n=3 次
两个 baseline:
| Baseline | 描述 | Accuracy |
|---|---|---|
| LLM-only | 单次 prompt,只给字段名和值 | 56.36% |
| RAG | 单次 prompt + 字段描述 + 数据类型 + 样例数据(来自内部 KB) | 72.73% |
第二个 baseline 已经把 RAG 能拿出来的牌全打了——内部知识库里有的东西都喂给模型了。还差的那 27% 准确率,就是这篇论文想解决的"知识库照不到的角落"。
迭代 100 轮之后:
| 指标 | 起点 | 终点 |
|---|---|---|
| Accuracy | 72.73% | 93.94% |
| 需要专家复审的低置信度字段数 | 26 | 4(-85%) |
| 累计收集证据 tuple 数 | 0 | 81 |
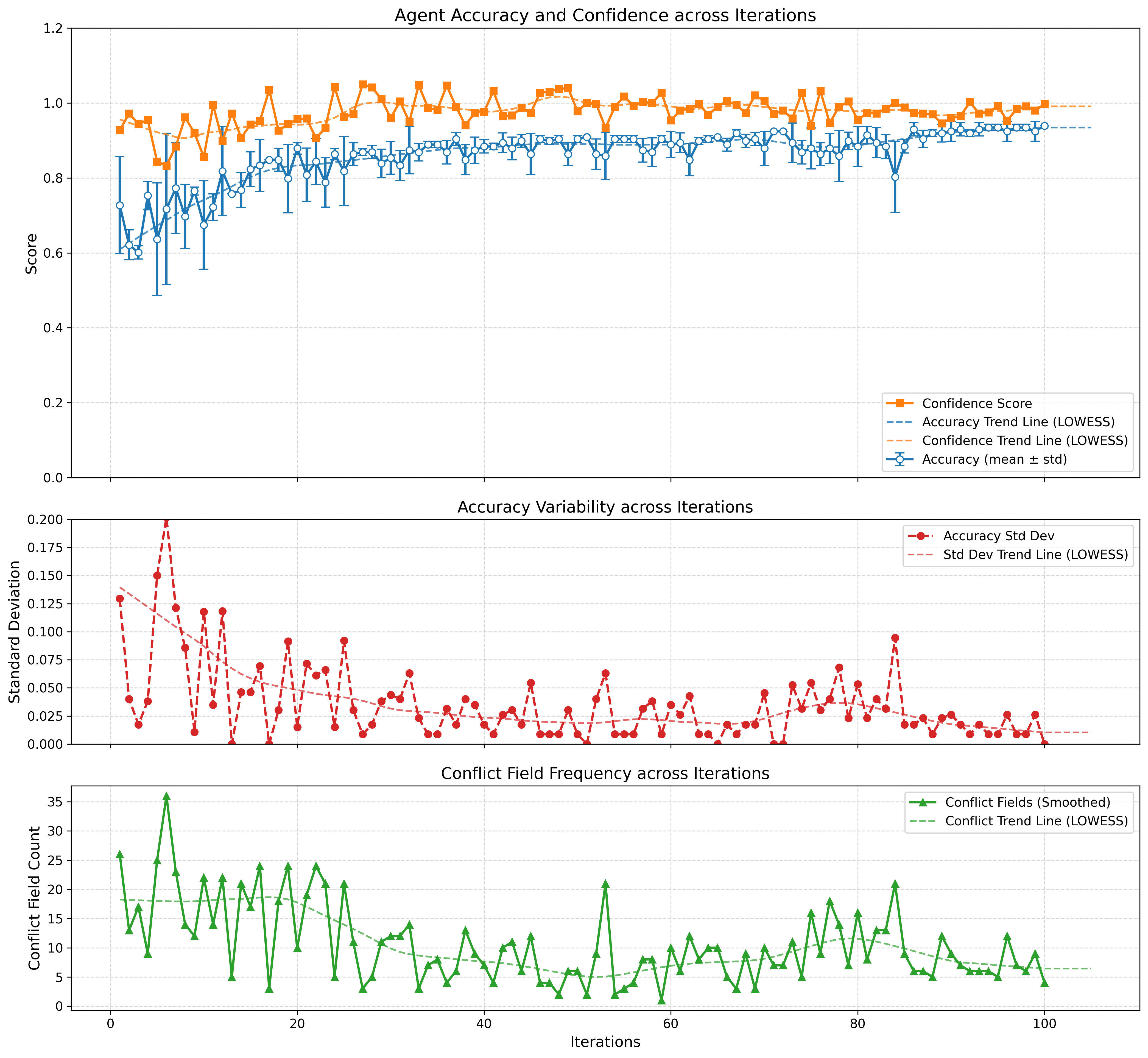
图 2 三个面板把整个学习过程的动态都展示了。上图是准确率(蓝)和置信度(橙)的曲线,准确率从 0.72 一路爬到 0.94,但置信度更快地接近 1.0——这就是后面要聊的 overconfidence 问题。中图是准确率的标准差,前 20 轮波动很大(0.10-0.15 之间反复横跳),说明 Agent 在早期"还没拿主意",30 轮之后开始稳定,最后接近 0。下图是冲突字段数量,从 26 个降到 4 个,但中间有个有意思的现象——70-80 轮之间冲突数突然反弹了一下到 20+,可能是 Agent 拿到了一批新证据导致旧映射开始动摇。这种"重新审视"的行为其实挺像人在反复推敲一个问题。
几个我觉得值得细看的点
1. 增益不是线性的,前几轮收益极大
第 1 轮就涨了 +21.21%(直接从 72.73 跳到 93+,因为 baseline 2 本身已经把 RAG 能给的全给了,第一轮加上"自我冲突检测"立刻把那些边界情况修了大部分),第 5 轮 +9.60%,第 6 轮 +10.71%。后面 90 轮基本是在精雕细琢最后那 6%。这个曲线形状很 industry——典型的 80/20,前面便宜,后面贵。
2. 在 19/100 轮里 Agent 主动拒绝了新证据
这点挺重要的。说明 confidence-based reward 不只是单调地"贪心地加证据",它会拒收"看起来有用但实际上没用"的信息——这反过来证明了 confidence delta 这个 reward 信号是有筛选能力的,不是噪声。
3. 多次重跑后 final accuracy 在 93-94% 收敛,标准差 \lt 0.01
这个 stability 数据其实很关键。RL 类方法最让人不放心的就是"是不是因为运气",标准差 \lt 0.01 基本可以排除偶然。
但有个问题——置信度膨胀
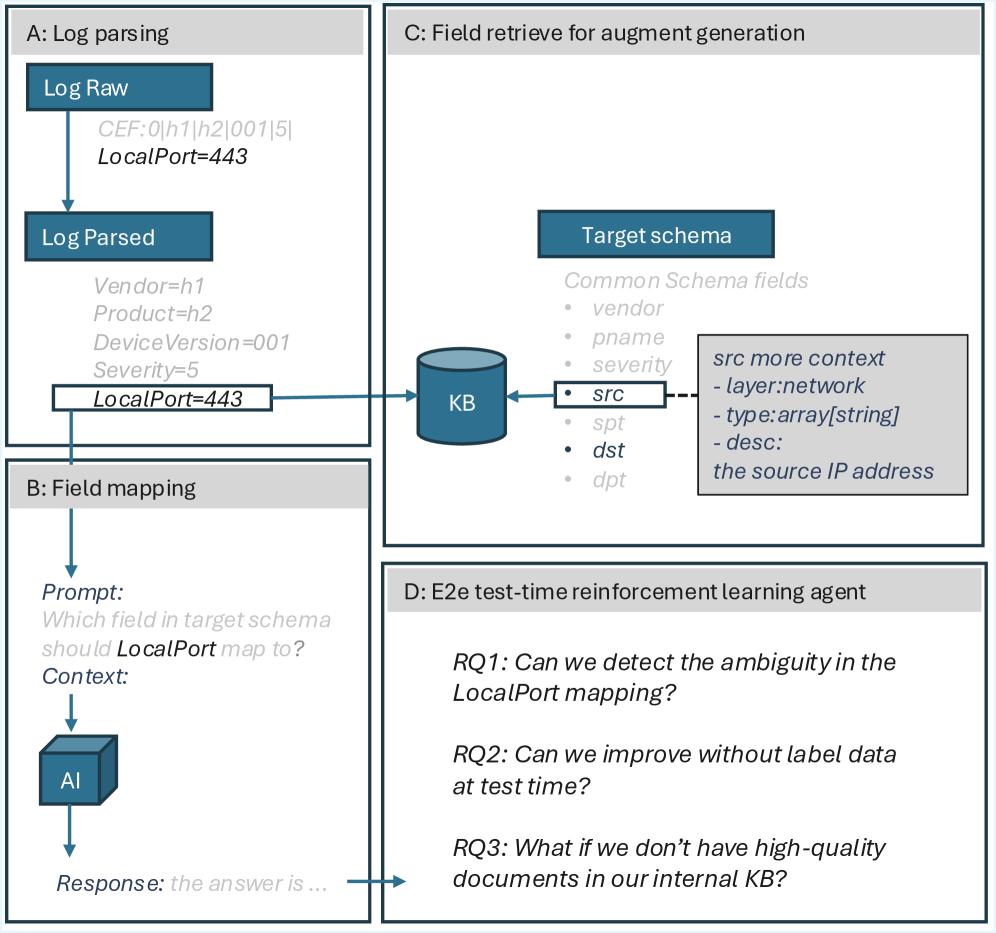
图 3 把 confidence-as-reward 的内在矛盾画得特别清楚。Path 1 是起点,confidence 和 accuracy 都在对角线上(完美校准)。Path 2 是 confidence 作为 proxy reward 把 accuracy 沿着对角线一起拉上去——这是论文想要的效果。Path 3 是危险点——当 confidence 已经接近 1.0 但 accuracy 还卡在 0.94 时,confidence 就不再是有效的优化信号了,因为它已经"打满了"。这就是 overconfidence。
论文 Appendix B 里给出了一个缓解方案——把每轮采样次数从 3 增加到 10:
| 设置 | Final Accuracy | Mean Confidence | 低置信度字段数 |
|---|---|---|---|
| 3 inferences | 93.94% | 95.2% | 26 → 4(-85%) |
| 10 inferences | 92.1% | 89.3% | 31 → 6(-80%) |
注意看——采样从 3 加到 10 之后,accuracy 略微下降(-1.84pt)但 confidence 下降得更多(-5.9pt),二者更接近真实校准。 这是个典型的 calibration vs accuracy 的 trade-off。生产环境如果对 expert review 的优先级排序很敏感(不希望模型瞎自信地把错的标成"高置信度"),就该用 10 次;如果只看最终 accuracy 不在乎校准,3 次更便宜。
我自己的判断是——这个 trade-off 在工业部署里其实倾向于选 10 次甚至更高。 因为低置信度字段是要交给专家复审的,如果模型把"我其实不确定"的东西骗成"我很确定",专家就不会复审,错误就会上线,这比少 1.84 个点的 accuracy 严重多了。
Case Study:iteration 49 那个 LocalPort
我前面提过 LocalPort vs RemotePort 的歧义。Appendix A 完整记录了 Agent 在第 49 轮迭代时怎么处理这个问题的——
第 49 轮之前,Agent 一直在 dpt → LocalPort 和 dpt → RemotePort 之间摇摆。这一轮它去搜了三条关键定义:
LocalPort是本机端口RemotePort是远端被连接的端口dpt是服务的目的端口
注意,这三条证据本身并没有直接说"dpt 应该映射到哪个"。但它们让 Agent 意识到——这事儿取决于 traffic direction。Agent 于是开始去看其他辅助字段(RemoteIP、LocalIP、ActionType),从这些字段里推断方向。
最终 Agent 给出的"实用规则"长这样:
confidence 从 0.67 升到 1.0。
这个例子让我对方法的"工程实用性"加分挺多——它不是单纯地把 dpt 映射到一个固定字段,而是学会了写出"条件性映射规则"。这在做规则引擎的时候是宝。如果 Agent 能稳定输出这种条件规则,就可以把它的输出直接拿去当 ETL 代码生成的输入。
我的判断:这篇论文值得读吗?
值得,但要看你期待什么。
如果你期待看到一个全新的 RL 算法、一个更聪明的 reward 设计、或者一个理论突破——那你会失望。这篇论文用的所有"原料"几乎都是现成的:
- TTRL 框架(Zuo et al. 2025)→ 测试时学习的概念
- Reflexion(Shinn et al. 2023)→ verbal RL 的思路
- Self-consistency(Wang et al. 2022)→ 多次采样的一致性作为 confidence
- Search-R1(Jin et al. 2025)→ 外部搜索增强推理
把这四个思路拼到一个具体的工业场景上——这就是论文的全部"算法贡献"。
但如果你的视角是工程师——是"测试时 RL 这种概念能不能真的落地"——那这篇论文挺有参考价值的。几个我觉得值得借鉴的设计:
1. Confidence 作为 proxy reward 这件事的工程意义
之前 RL 工作大都纠结于"怎么找到一个准的 reward signal"。这篇论文给的答案是——别找了,预测一致性就够用了。在你没有 ground truth 的所有任务上(不只 schema mapping),这个思路都能复制。
2. Verbal RL 在工业部署里的成本优势
不动模型权重 = 不需要 GPU 训练资源、不需要 retraining pipeline、不需要重新做 alignment。新厂商 schema 接进来,跑 100 轮 inference 就完事,prompt context 增量更新。这种部署形态对运维太友好了。
3. 让 Agent 自己拒绝证据的 mechanism
19/100 轮拒绝新证据,这个比例不低。这告诉我们——简单加上"if confidence delta > 0 then keep" 这种规则真的能有效过滤噪声证据,不需要训练一个独立的 verifier。
几个我觉得有问题或者还没解决的地方:
1. Confidence 作为 reward 的根本性局限
图 3 那个 overconfidence 问题没法绕。当 confidence 打到 1.0 之后,reward 信号就死了——这意味着方法天然有个性能上限。论文说"未来可以用 ensemble、self-assessed confidence 等方法"——但这其实是在说"confidence-as-reward 这个核心 idea 还没完全 work"。
2. 评估场景是否过窄
只在 cybersecurity 一个数据集(Microsoft Defender → Trend Micro Common Schema)上做了实验,66 个字段对。论文 Limitations 也老实承认了。这个体量的 evaluation 在 industry track 不算少,但要说推广到 healthcare、finance 还需要更多数据。
3. 跟同期工作的比较不够
baseline 只有 GPT-4o single-shot 和 RAG。但 ReMatch、MatchMaker 这些方法在他们自己的场景下也不差,论文应该把这几个 baseline 在同一个数据集上跑一遍——而不是只引述对方在他们各自数据集上的结果。这点是 Industry track 论文的通病,也算是可以理解的。
4. 100 轮迭代的成本没仔细算
每轮要做 3 次 LLM 调用(采样)+ 若干次 web search + 1 次 prompt 更新。100 轮意味着 300 次 LLM 调用 + 几十次 search 调用。GPT-4o 的成本不便宜,论文没给出"per schema mapping 的 token 消耗 / 美元成本"这种数据。在做工程 trade-off 时这个数据很关键——如果 100 轮迭代的成本是 50 美元,单次专家复审是 30 美元,那这套方法是不是真的省了?没有定论。
几条工程上的迁移启发
这篇论文给我最大的启发,倒不是 schema mapping 本身——而是 "测试时 RL"作为一种轻量级 agent 能力升级路径,可以怎么落地。
适合迁移的场景:
-
任何"无标签 + 有外部信息源"的任务:不只是 schema mapping,类似的还有 product taxonomy alignment、API endpoint 映射、ontology matching 等等。只要任务本身能定义"预测一致性",confidence-as-reward 就能用。
-
企业内部知识库 + 外部搜索的混合检索场景:内部 KB 文档不全的时候,让 Agent 自己去外部找证据,这个范式可以推广到合规审计、安全运营、IT 工单分类等场景。
-
任何"专家复审成本是主要瓶颈"的工作流:85% 的复审减负是真金白银的价值,比 accuracy 涨几个点更直接。
不适合迁移的场景:
-
任务本身没有"自然冲突信号"的:比如机器翻译、文本生成这种,不同采样的输出本身就该有差异,"一致性"不能当 reward。
-
延迟敏感的在线场景:100 轮迭代的 latency 不可接受,这个方法只适合 batch 处理或者后台任务。
-
外部信息源不可信的领域:方法依赖搜索结果的质量,如果搜回来的东西本身就乱七八糟,confidence 就成了"自信地走错"。
收尾:测试时 RL 是不是 agent 部署的下一个标配?
老实讲,我看这篇论文的时候有种"Reflexion 终于在一个具体工业场景里 work 了"的感觉。
之前 Reflexion、Voyager、Self-Refine 这些工作都在讲 verbal RL 的故事,但 demo 都集中在 HumanEval、ALFWorld 这种学术 benchmark 上。Industry 的人看了会觉得——这玩意儿真的能用吗?延迟、稳定性、可解释性都是问号。
这篇论文的价值在于,它把 verbal RL 的"工业能用形态"给搭建出来了。一个 enterprise pipeline 的某个具体环节(schema mapping),有明确的成本结构(专家复审),有可量化的指标(85% 复审减负),有可重复的实验(100 轮、std \lt 0.01)。
后面我自己挺想试试的方向是——把 confidence delta 这个 reward 加上更精细的 calibration 机制。比如加入 ensemble confidence、加入 LLM 自评分、甚至引入第二个独立 verifier 模型来交叉验证。Appendix B 里 "3 vs 10 inference" 的对比已经在这个方向上做了一小步,但还远远不够。
如果你也在做企业数据接入、entity matching、schema alignment 这类活,这篇论文的方法值得直接试一遍。代码不复杂,难的是把 confidence reward 和你的具体场景对齐——什么算"一致"、什么算"歧义"、什么样的证据算"有用"。
把这几个东西定义清楚,剩下的就是工程问题了。
参考文献
- Tsao, W.-K., Yu, Y.-C., Huang, C.-M. (2025). Mapping Smarter, Not Harder: A Test-Time Reinforcement Learning Agent That Improves Without Labels or Model Updates. EMNLP 2025 Industry Track. arXiv:2510.14900
- Zuo, Y. et al. (2025). TTRL: Test-time reinforcement learning. arXiv:2504.16084
- Shinn, N. et al. (2023). Reflexion: Language agents with verbal reinforcement learning. arXiv:2303.11366
- Wang, X. et al. (2022). Self-consistency improves chain of thought reasoning in language models. arXiv:2203.11171
- Jin, B. et al. (2025). Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning. arXiv:2503.09516
- Sheetrit, E. et al. (2024). Rematch: Retrieval enhanced schema matching with LLMs. arXiv:2403.01567
- Seedat, N., van der Schaar, M. (2024). Matchmaker: Self-improving large language model programs for schema matching. arXiv:2410.24105
- Kalai, A.T. et al. (2025). Why language models hallucinate. arXiv:2509.04664
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我