让模型"故意答错",反而把验证器训得更准——逻辑推理上的 ORM + Test-Time Scaling 实验
一篇 EMNLP 2025 的小切口工作,思路很有意思:与其费劲收集"模型容易犯的错",不如直接诱导它犯错。
核心摘要
测试时扩展(Test-Time Scaling)+ 奖励模型这一路打法,过去一年在数学和代码上几乎已经被卷穿了,但演绎逻辑推理这块一直没人认真做。这篇 EMNLP 2025 的论文把 Outcome Reward Model(ORM)拉进 FOLIO、JustLogic、ProverQA 三个逻辑数据集,做了一件挺反常识的事——他们发现,让 LLM 沿着用户故意提供的错误答案"硬掰"出来的推理链,比模型自然采样出来的错误链对训练 ORM 更值钱。基于这个观察,他们提出了 Echo Chain-of-Thought(EcCoT) 数据增强,把诱导出来的伪推理混进 ORM 训练集。在 ProverQA 上 Gemma3-1B 的 reasoner 配 EcCoT-ORM,准确率比 Majority Vote 提升约 30 个点;在 4 个不同 reasoner 上 EcCoT 都稳定优于纯 CoT。
我的判断是:方法新颖度中等,但选题精准,把"LLM 习惯顺着用户给的错误答案胡说"这个老问题用得很巧——一个本来是"幻觉"的副作用,反过来变成训练 verifier 的金矿。值得 RL/test-time scaling 这一线的同学读一读。
论文信息
- 标题:Logical Reasoning with Outcome Reward Models for Test-Time Scaling
- 作者:Ramya Keerthy Thatikonda, Wray Buntine, Ehsan Shareghi
- 机构:Monash University(Department of Data Science & AI),Wray Buntine 同时挂 VinUniversity College of Engineering and Computer Science
- 会议:EMNLP 2025
- arXiv:2508.19903
- 代码:github.com/RamyaKeerthy/LogicORM
为什么这篇值得看
先说背景。Test-time scaling 现在的主流套路其实就两步:reasoner 跑 N 个样本,verifier(PRM 或 ORM)打分,Best-of-N 或 weighted vote 选答案。这套打法在数学上有 Math-Shepherd、PRM800K,在代码上有各种 unit-test-based reward——但演绎逻辑推理这条线一直比较冷门。
为什么冷门?我自己之前调过类似的事,体感是这样:逻辑推理任务的"答案空间"太窄了——FOLIO 这种就 True/False/Uncertain 三个标签,模型瞎猜 33% 都能蒙到。这种格式下,process reward 想标注每一步对错都很难("中间步骤错不错"很多时候连人都难判),所以大家习惯性地觉得"逻辑推理要么靠符号求解器要么靠 fine-tune,verifier 这条路意义不大"。
这篇论文就把这个空缺填上了——不光把 ORM 在三个逻辑 benchmark 上跑了一遍,还顺便挖了一个让 LLM 主动犯错来增广训练数据的取巧办法。
顺带一提,这里讲的 ORM 是 Outcome Reward Model,只对最终答案打分,不像 PRM(Process Reward Model)需要标注每一步推理。Math-Shepherd 那一系列工作里 PRM 一般效果更好,但代价是数据标注成本高得多。
ORM 训练数据的两条路:CoT vs EcCoT
整篇论文最值得讲清楚的就是这张方法图。
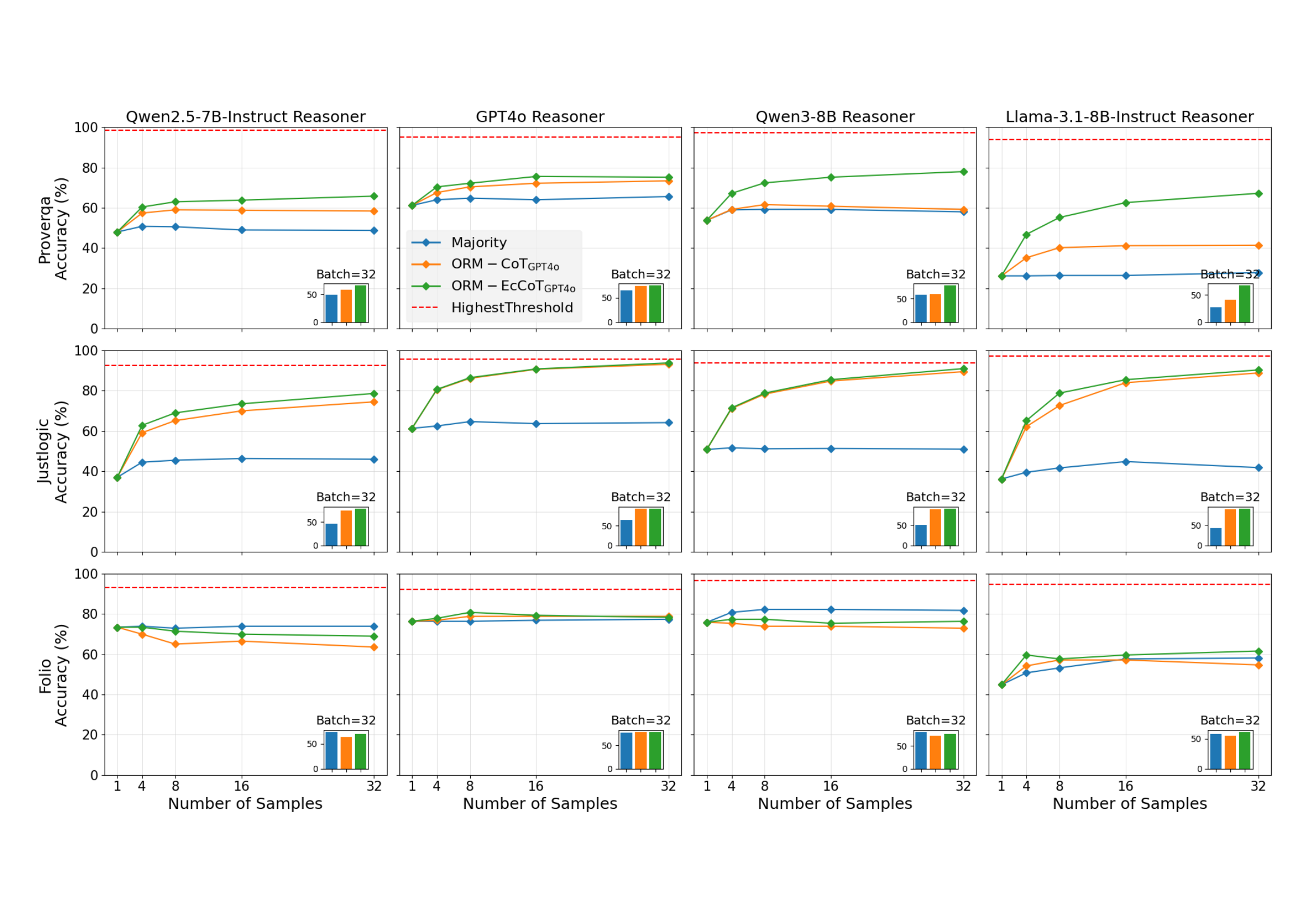
图1:CoT-ORM 与 EcCoT-ORM 的训练数据构造流程。A 部分是标准做法——给 LLM 题目、做 K 步推理、按最终答案是否对打 ±1 标签;B 部分是 Echo 增强——故意把错误答案塞进 prompt 里诱导 LLM 顺着错的"硬掰",然后用 LLM-as-a-Judge 过滤掉那些一眼能看出来是胡扯的,剩下"看起来挺合理但实际上错"的进训练集。
A 路径:标准 CoT 采样(baseline)
这部分没啥惊喜,就是 Math-Shepherd 那一套搬过来:
- 用 prompt
"Please reason step by step, and put your final answer within \boxed{}"让 LLM 对同一道题采样 K 个推理链 - 对照 gold label 给每条链打标签:答案对就是正样本,错就是负样本
- 把这些 (推理链, 标签) 对喂给一个 7B Qwen2.5 做分类训练,拿到 ORM
作者把 K 设成 8(ProverQA、JustLogic)或 10(FOLIO),对应得到 ORM-CoT。
B 路径:Echo Chain-of-Thought(EcCoT)
这才是论文的真正贡献。先看 prompt 怎么改的:
原 CoT prompt: "Please reason step by step, and put your final answer within \boxed{}"
Echo prompt: "Given the answer is True, please reason step by step, and put your final answer within \boxed{}"
就加了 Given the answer is X 前面这一截。但这一截在 LLM 身上的效果非常魔幻——LLM 倾向于顺着用户给的答案去构造"看起来自洽"的推理链,哪怕这个答案是错的。这个现象其实 sycophancy 文献里早就讨论过了,作者把它工具化了。
具体做法:
- 对 ProverQA 训练集每道题,轮流用三个错误答案(True / False / Uncertain)去 prompt 模型。如果题目正确答案是 True,那 Echo prompt 里就用 False 和 Uncertain 各做一遍,逼模型为这两个错答案生成"理由"。
- 这些"被诱导出来的错链"很多都是似是而非的——你单看推理过程会觉得"哦好像是这么回事",但结论错了。这正是 verifier 最需要学会识别的难样本。
- 然后过 LLM Judge(用同一个 LLM)做二次过滤:
"Judge if the reasoning logically follows from the input; respond only with Correct or Incorrect."把那些"模型自己都觉得不对"的链丢掉——这些太明显了,verifier 不需要它们。剩下的"模型自己也分辨不出来错"的链才是金子。
聪明的地方在这里:留下来的样本 = 那些 LLM 在不知道答案的情况下也容易掉进去的陷阱。这正是 inference 时 reasoner 真实会犯的错的分布。
我看到这一步的时候第一反应是——这不就把 reward hacking 的因头反着用了么?sycophancy 平时是个 bug,到这里变成 feature。
对照一下 STaR(Zelikman et al.):STaR 也用过类似 trick 但目的相反——它给模型一个正确答案当 hint 让模型反向构造推理链,目的是扩充正样本。这里作者明确强调"我们和 STaR 不一样,我们是给错答案,目的是扩充难负样本"。
数据规模长什么样
放一组 ProverQA 用 GPT-4o 当 generator 的统计(Appendix Table 5),看看 Echo 真的能拉出多少错样本:
| 模式 | Echo 标签 | Total | Correct | Incorrect |
|---|---|---|---|---|
| CoT 0-shot | -- | 39998 | 34486 (86%) | 5512 (14%) |
| Echo 0-shot | True | 40000 | 32865 (82%) | 7135 (18%) |
| Echo 0-shot | False | 39996 | 25725 (64%) | 14271 (36%) |
| Echo 0-shot | Uncertain | 39968 | 19385 (49%) | 20583 (51%) |
| Echo-CoT 合并 | -- | 63278 | 34486(54%) | 28792(46%) |
读这张表的时候我停了一下。看几个数:
- GPT-4o 自然采样 CoT 错误率才 14%——这模型在 ProverQA 上其实已经挺强了,单纯靠 sample 不容易刷出难负样本。
- 诱导成 Uncertain 时错误率 51%——模型一听到"答案是 Uncertain"就懵了一半。Uncertain 在演绎推理里语义最微妙(前提既不蕴含也不否定结论),最容易被 sycophancy 拐跑。
- 合并 Echo + CoT 后正负比从 86:14 直接拉到 54:46。对训练分类器来说,正负样本差不多是 1:1 几乎是教科书理想分布。
这个数据收集方式还有一个隐藏好处:多样性。论文用 Self-BLEU 评估了一下:
| 数据集 | 样本数 | CoT Self-BLEU | EcCoT Self-BLEU |
|---|---|---|---|
| ProverQA | 8 | 0.92 | 0.77 |
| FOLIO | 10 | 0.92 | 0.83 |
| FOLIO | 40 | 0.92 | 0.93 |
Self-BLEU 越低代表生成越多样。CoT 的 Self-BLEU 死活在 0.92 不动——LLM 对同一道题的多次采样长得太像,说到底是在重复同一个"推理路径模板"。Echo 因为换了答案就被迫切换论证路径,多样性显著更高。这点我觉得挺关键的——增 sample 数从 10 提到 40,CoT 多样性几乎没变(看最后一行),所以单纯加大 N 不能替代 Echo 的作用。
训练配置(顺手记一下)
- ORM backbone:Qwen2.5-7B-Instruct,LoRA 微调
- 训练:单卡 A100,3 epoch,batch size 64,learning rate 5×10⁻⁴
- 步标记:
<extra_0>token 上接+/-表示正负样本,沿用 zhang2025lessons 的做法 - 三个数据集:ProverQA(5000 训练)、JustLogic(4900 训练)、FOLIO(约 1000 训练)
- Generator(生成训练数据的 LLM):Qwen2.5-7B 和 GPT-4o 各试了一遍
- Reasoner(推理时跑 Best-of-N 的 LLM):Qwen2.5-7B、GPT-4o、Qwen3-8B、LLaMA-3.1-8B
最关键的对比维度:Generator 和 Reasoner 不一定是同一个模型——这是 ORM 设计里很重要的解耦,因为你训 verifier 的时候用啥模型生成数据,跟 verifier 上线后给谁打分,是两件事。
实验结果
预实验:先证明几件小事
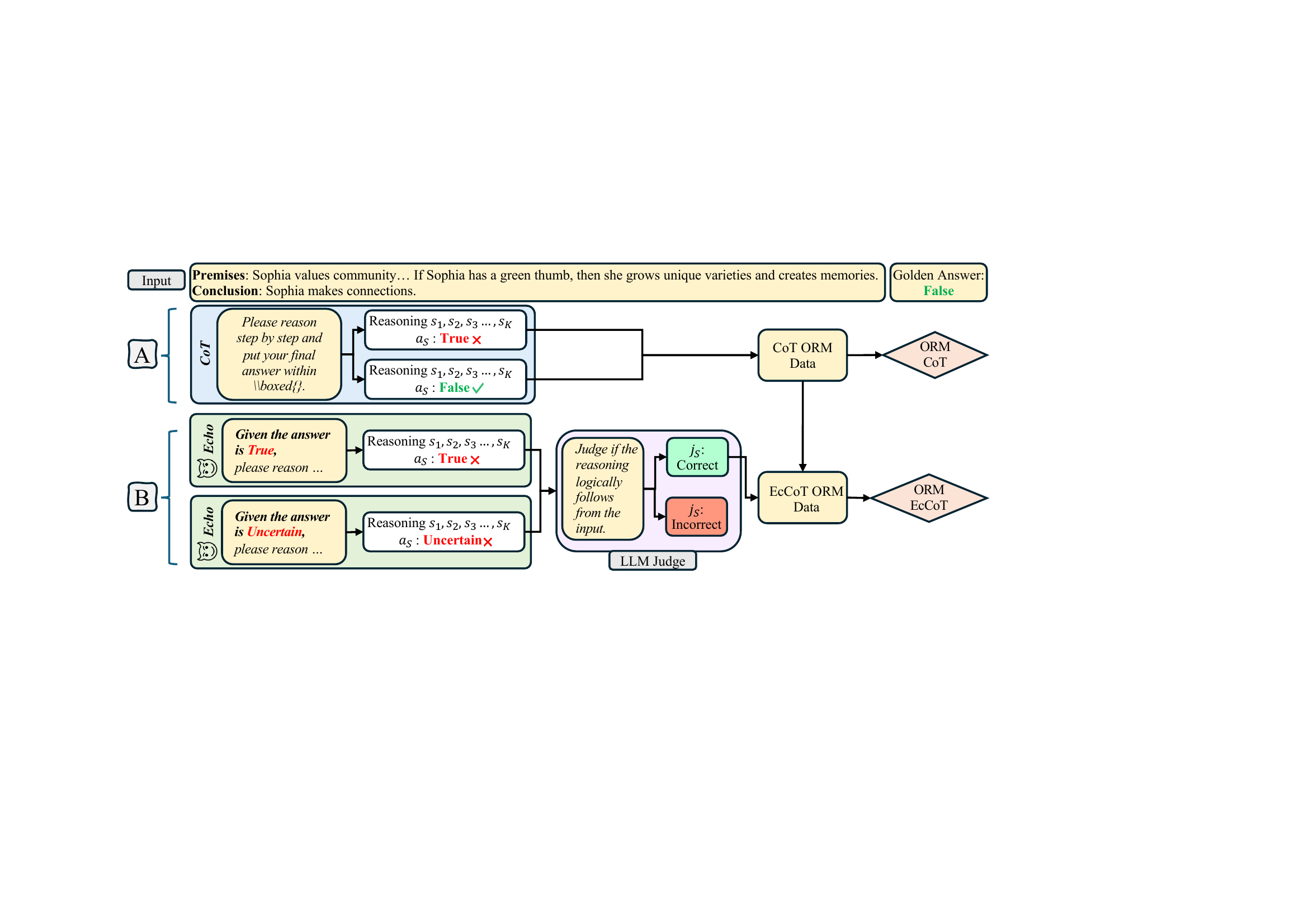
图2:在 ProverQA 上的预实验。左图 Qwen2.5-7B 当 reasoner,右图 GPT-4o 当 reasoner。橙色虚线和绿色实线分别是用 8 样本 CoT 和 8 样本 EcCoT 训练出来的 ORM,红色虚线是只用 1 样本 CoT 训练的 ORM("small")。蓝色是 Majority Vote baseline。
这张图其实回答了三个问题:
问题 1:训练时每题采几个样本?1 个 vs 8 个差多少?
看那条红色虚线(ORM-CoT^small_Qwen,每题只采 1 个 CoT)——它在两个 reasoner 上都低于 Majority Vote。也就是说,只采 1 个样本训出来的 ORM 比不投票还差。这个结果其实挺直观——单样本 CoT 几乎没有反例,分类器学不到什么真正的"错误模式"。
把每题采样数从 1 提到 8(橙色虚线),ORM 的表现立刻翻盘,远超 Majority Vote。N=32 时 Qwen reasoner 上 ORM-CoT^large 把 ProverQA 准确率从 49%(Majority)拉到 71%。
问题 2:Echo 增强值不值?
绿色实线(EcCoT^large)在 Qwen reasoner 上略低于 CoT,在 GPT-4o reasoner 上略高于 CoT。对,预实验里 Echo 的优势并没有特别明显——这个细节作者很坦诚地写出来了,没藏。但作者的判断是:Qwen 自己当 generator 时,Echo 拉出来的样本对 GPT-4o 这种更强的 reasoner 才帮得上忙;如果换 GPT-4o 当 generator,效果应该更好。
问题 3:用谁当 generator 好?
紫色虚线(ORM-CoT^small_GPT4o)虽然只用 1 个样本,但比红色(Qwen 单样本)明显高一截。这说明 generator 模型质量对 ORM 训练数据的影响其实挺大——GPT-4o 单样本就能压过 Qwen 单样本不少。所以后面正式实验作者直接换成 GPT-4o 当 generator。
这里我有点小疑问:他们没做 GPT-4o 单样本 vs GPT-4o 8 样本的对比,所以 "8 sample > 1 sample" 这个结论严格说只在 Qwen-as-generator 上验证过。不过从直觉上这不应该是 generator-specific 的现象。
主实验:4 个 reasoner × 3 个数据集
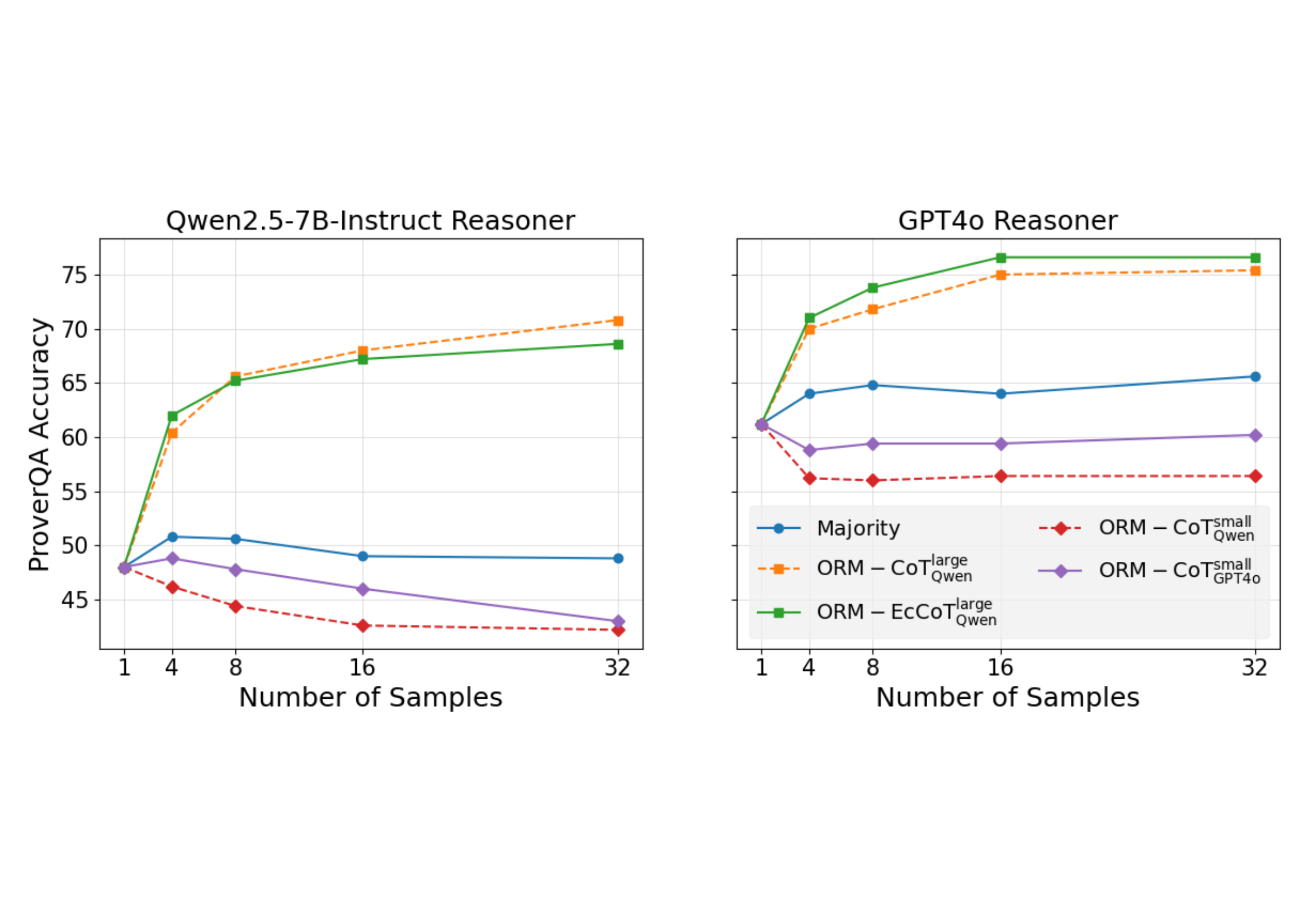
图3:主实验结果。横轴是 Best-of-N 的 N,纵轴是测试准确率。蓝色是 Majority Vote,橙色是 ORM-CoT,绿色是 ORM-EcCoT,红色虚线是 Highest Threshold(HT)——假设 N 个样本里至少有一个对,理论上能达到的上限。每个小图右下角的柱状图是 N=32 时 Majority/CoT/EcCoT 三者的对比。
这张图信息密度最高,分两条线看:
横看(同一 reasoner,三个数据集表现差异): - 在 ProverQA 上,所有 reasoner 都吃 EcCoT 的优势,绿线明显在橙线上面 - 在 JustLogic 上,CoT 和 EcCoT 几乎重合——都接近 HT 上限了,没空间再涨 - 在 FOLIO 上,效果最弱——尤其在 GPT-4o 和 Qwen3 上 ORM 几乎没起到作用,跟 Majority 差不多
纵看(同一数据集,不同 reasoner 表现差异): - LLaMA-3.1-8B 是最弱的 reasoner,但也是 ORM 提升最猛的——ProverQA 上从 ~25%(Majority N=32)拉到 ~68%,43 个点的提升。这个数我看到的时候停了一秒。 - GPT-4o 起点最高,所以 ORM 提升空间也小 - Qwen2.5 和 Qwen3 中间,提升幅度也中间
为什么 FOLIO 上 ORM 没用?
作者贴了一张挺关键的解释图:
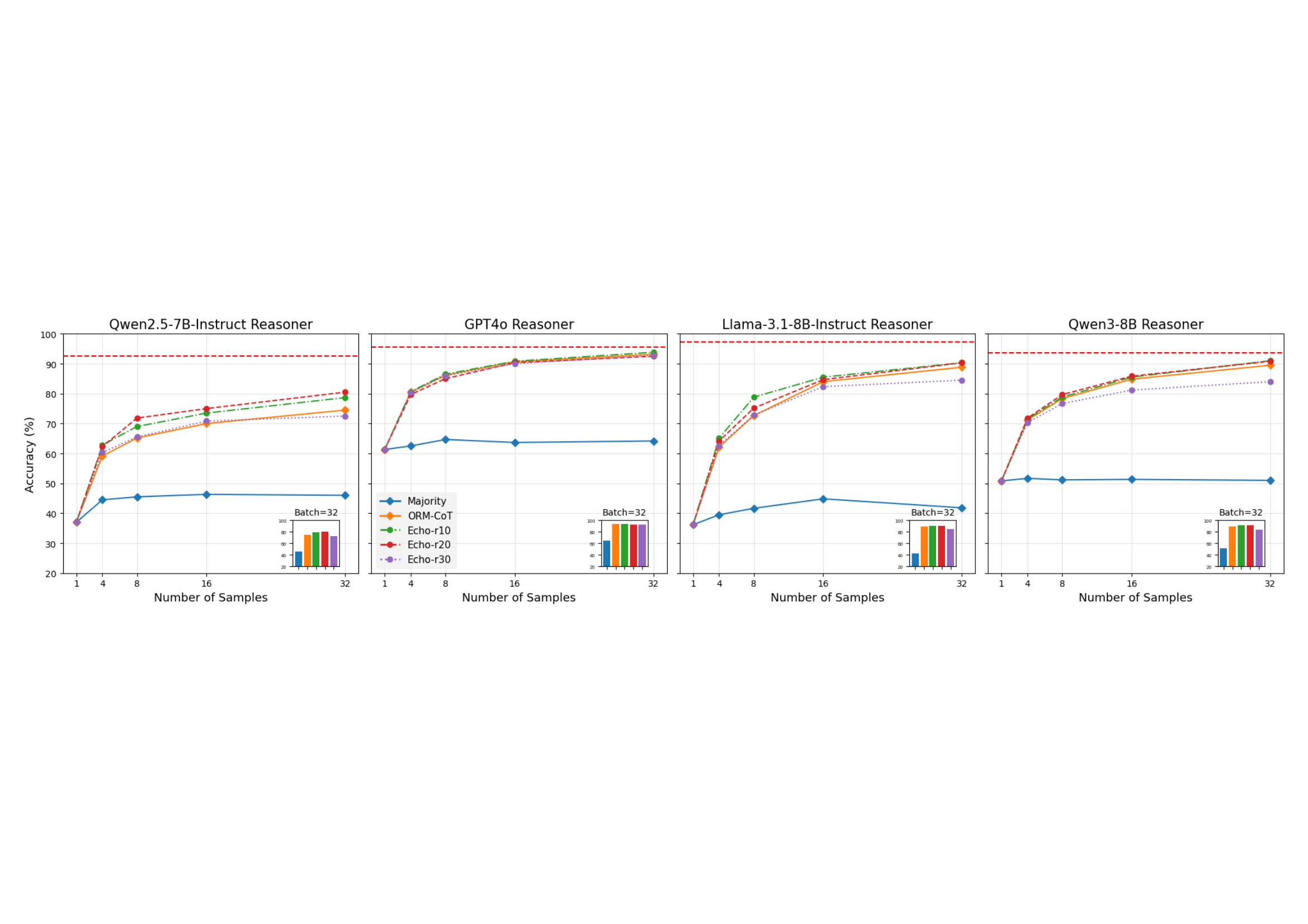
图4:在不同 sample size 下,N 个采样里"答对的比例"。横轴是 N,纵轴是平均答对个数。FOLIO(右)上 N=32 时,所有 reasoner 平均能答对 20+/32,也就是 reasoner 自己已经有 60%-90% 的样本是对的——这种情况下 Majority Vote 基本就是天花板,ORM 再怎么挑也挑不出更好的来。
我觉得这是论文里最诚实的一张图。ORM 不是万能的——它只在 reasoner 自己"对不齐"的时候才有用。在 FOLIO 这种 reasoner 已经基本会做的题上,引入 ORM 不仅没用还可能引入噪声(你看图3 里 GPT-4o 在 FOLIO 上 ORM-CoT 还略低于 Majority)。
这个结论对工程落地很有指导意义——上 ORM 之前先量一下你的 reasoner 在目标任务上的 majority vote frequency,太高了别折腾。
一个我特别 buy 的 ablation:Gemma 越小,Echo 越香
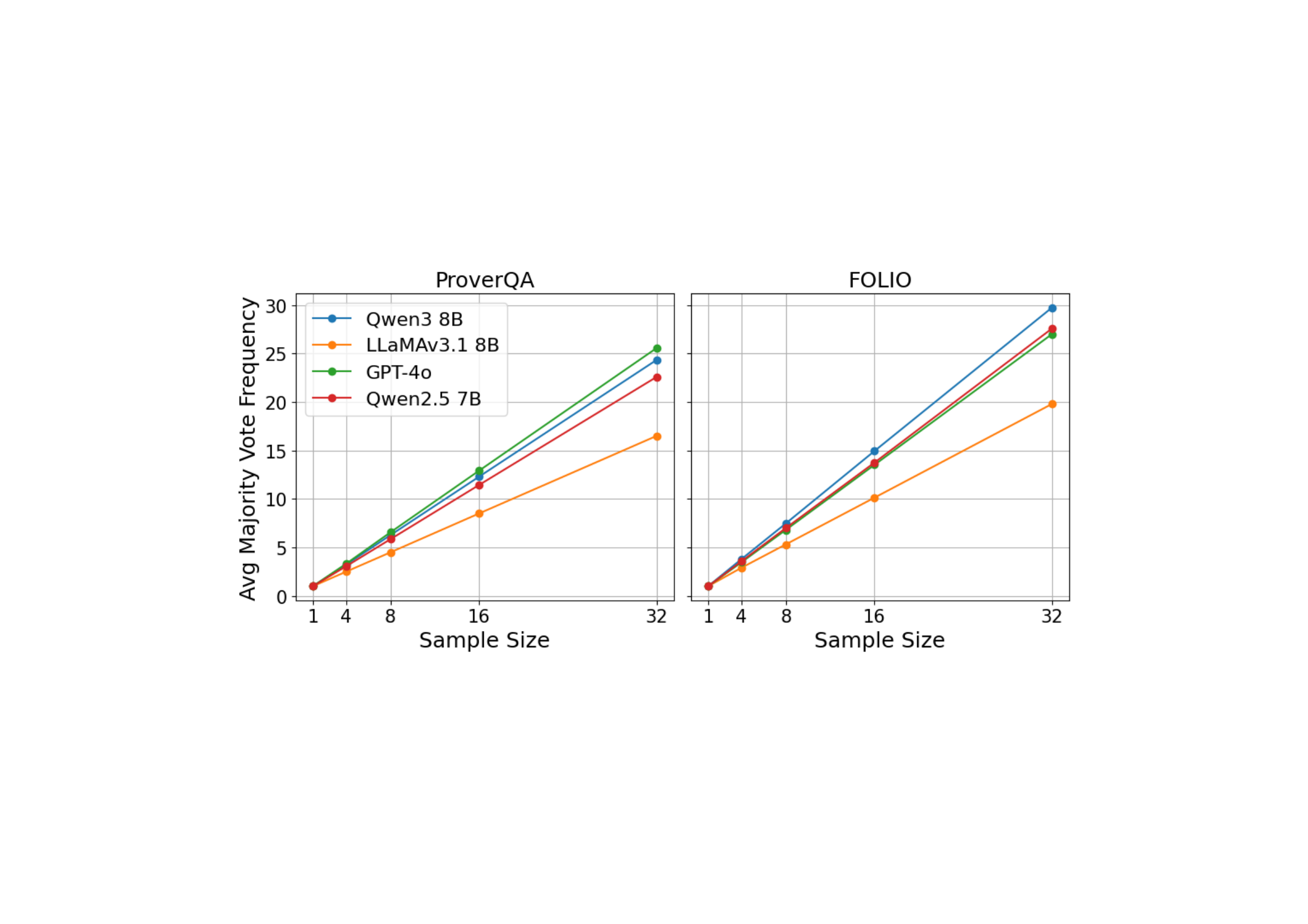
图5:把 reasoner 换成 Gemma3 系列,1B/4B/12B 三档。最左列是 Gemma3-1B——一个 1B 模型直接做逻辑推理基本就是个废物,ProverQA Majority 准确率不到 10%。但配上 ORM-EcCoT 后 N=32 能拉到约 35%,CoT-ORM 拉到约 22%。
这张图我盯了好一会儿。1B 的 Gemma 在 ProverQA 上 Majority 准确率几乎 0——本来都已经废了。但配上 EcCoT 后,居然能从大概 1% 拉到 35%。这个跨度比 4B 和 12B 上看到的提升大得多。
直觉上为什么会这样?我的理解是:小模型自己分布很乱,N 个样本里可能也就 1-2 个蒙对的。Majority Vote 完全失灵,但只要 N 个里有任何一个对的,强 verifier 就有机会把它捞出来——这正是 ORM 的核心价值所在。模型越弱,verifier 的边际收益越大。
这对端侧/小模型部署其实是个挺有意思的方向:与其堆 reasoner 参数,不如端侧跑个 1B 的 reasoner,云上挂一个 7B 的 verifier,可能比直接上 7B reasoner 还划算。
关键 ablation 之"加 Echo 还是加样本量"
这个 ablation 我觉得对方法党特别重要——很多人会怀疑:"你 Echo 不就是变相增加训练数据么?我直接采更多 CoT 样本不就行了?"
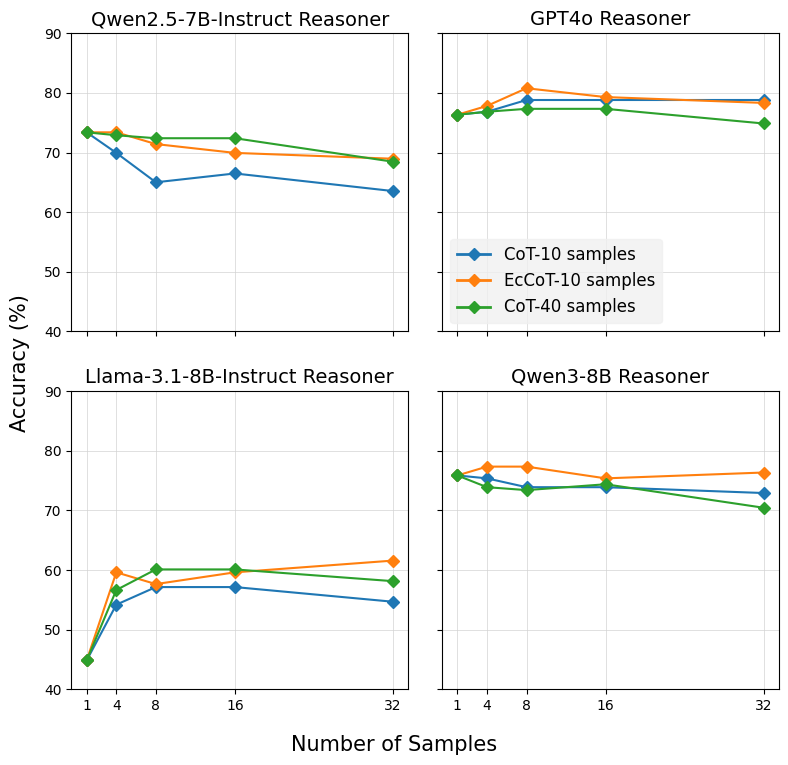
图6:每题用 10 CoT + 10 Echo(橙色 EcCoT-10)vs 每题用 40 CoT(绿色 CoT-40,等价的总样本量)vs 每题 10 CoT(蓝色 CoT-10)。在 4 个 reasoner 上,EcCoT-10 在 Llama 和 Qwen2.5 上都明显更好;GPT-4o 和 Qwen3 上几乎打平。
直接增加 CoT 样本到 40(绿色)并没有打过 EcCoT-10(橙色)。原因前面 Self-BLEU 那张表已经说清楚了——CoT 多样性不会因为采更多就变好,它是被 prompt 锁死的。Echo 则强制切换论证路径,是真的扩展了错误覆盖面。
这条结论我觉得是这篇论文最值钱的一句:训练 verifier 时数据多样性的瓶颈不在样本数量,在 prompt 设计本身。
我的判断:这篇论文到底怎么样?
亮点
- 选题精准:Test-time scaling 大家都在卷数学和代码,逻辑推理是个被忽视的小坑,作者填得正中靶心。三个 benchmark + 4 个 reasoner + 多个 generator 组合,覆盖度足够说明问题。
- Echo trick 很巧:把 sycophancy 这个老问题反向利用,是真有点"魔法"的味道。而且 LLM Judge 二次过滤这一步关键——没这步会过拟合到一些"模型自己都知道错"的浅显错误,反而稀释训练数据。
- 诚实:实验里 EcCoT 不优的地方(如 FOLIO 上的 GPT-4o reasoner、JustLogic 上接近天花板等)都直接讲了,没硬吹。HT(Highest Threshold)这个上限指标加得很到位,让读者一眼看出 ORM 还有多少进步空间。
局限和我觉得没说清楚的地方
- Echo 数据生成成本不低。每题要采 8 次(CoT)+ 3 标签 × 8 次(Echo)= 32 次 LLM 调用,再过 LLM Judge 过滤。在 GPT-4o 上跑 ProverQA 5000 题至少几百美元。论文没讨论 cost-effectiveness。
- JustLogic 的 resampling 处理有点 ad-hoc。GPT-4o 在 JustLogic 上 echo 出 49197 条数据(其中 60% 错),作者用了一套基于 BLEU 多样性 + 频率的 weighted resampling 取 10000 条,α=0.8 β=0.2,10k/20k/30k 各跑一遍取 10k 最优。这套调参逻辑看起来更像炼丹而不是原理性发现,扩展到新数据集需要重调。
- Limitation 自承:只用 outcome supervision,不验证中间步骤的 faithfulness——也就是说模型可能学到"shortcut" 但 verifier 抓不到。作者也提到未来要看 PRM。
- 没和符号求解器路线(如 LogicLM、SatLM)对比。在演绎逻辑这一块,符号求解器+LLM 混合架构是有竞争力的,论文应该至少有一组对比数据,不然读者会怀疑"是不是我直接 LLM+Z3 一把梭就 90+ 了"。
跟同期工作的关系
读这篇时绕不开这几个工作: - Math-Shepherd / Let's Verify Step by Step:经典 PRM/ORM 在数学上的工作,是这篇的方法论母本。 - STaR(Zelikman et al. 2022):同样用了"给 LLM 一个 hint 答案让它反向编 rationale"的 trick,但 STaR 给的是正确答案,目的是扩充 SFT 数据;这篇给错误答案,目的是扩充 ORM 难负样本。两者刚好反着用。 - Sycophancy 系列研究:把 sycophancy 当问题来 mitigate 的论文有不少,但把它当 feature 来利用的目前还少见。这篇某种程度上是在告诉大家:你不一定要消除模型的弱点,可以反过来挖矿。
对工程落地的启发
如果你正在搭一套 reasoning + verifier 的 pipeline:
- 先量 Majority Vote frequency:reasoner 在你目标任务上 N=8 能多数票答对几题?如果 \gt 80%,verifier 收益有限;50%-80% 是 ORM 最甜的区间;\lt 30% 那就上 RL 重训 reasoner,verifier 救不了。
- 训 ORM 时一定要采多样本:单样本训出来的 ORM 大概率比不投票还差。8-10 个样本是经验起点。
- Echo trick 可以试:成本不高(多打几次 prompt),尤其对那些有"反常识"答案的任务(Uncertain、None of the above 这类标签),效果会比较明显。
- Generator 选强模型:GPT-4o 当 generator 训出来的 ORM 比 Qwen 当 generator 强不少,所以前期数据可以舍得花预算。
收个尾
这是一篇典型的"小切口、做扎实"的 EMNLP 论文。没有炫目的架构创新,但把一个被忽视的领域(逻辑推理 + ORM)认认真真做了一遍,顺手发现了一个挺有意思的副产物(Echo 增强)。如果你也在做 verifier-based test-time scaling,或者在小模型推理方向上想找突破口,这篇值得花 30 分钟读一下原文。
更广义地说,Echo 这个思路提示了一种"反向利用模型 bug"的方法论——sycophancy、hallucination、reward hacking 这些过去被当成需要消灭的问题,其实在某些训练数据生成场景下都可能反过来用。这个思维范式值得记一下。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。