训RAG Agent老犯"搜了又搜"和"乱搜一气"两个毛病?LeTS给出了一个不靠人工标注的解法
浙大 × 蚂蚁集团网商银行 EMNLP 2025 工作
最近一年做 RL-for-RAG 的人,多少都被两件小事折磨过。
第一件:模型在第三步、第四步又把第一步检索过的文档拉了一遍。链路看上去很努力,结果就是 token 越烧越多,答案没变好。第二件更难受——模型本来已经检索到正确文档,下一步突然冒出来一个看似相关其实跑偏的 query,把整个推理带歪。最后一个 final answer 错了,outcome reward 一刀切打到 0,前面那几步真正搜对的努力直接被埋了。
如果你也碰过这两个问题,那这篇 LeTS 大概率会戳到你。它没有去重发明一遍 GRPO,也没有训新的 reward model,只是在 GRPO 的 advantage 上面动了一刀——用两条 rule-based 的过程奖励,把 outcome 级 advantage 按步数重新缩放一遍。然后效果就出来了:相比 ReSearch(同backbone)平均 EM 涨 2.61 个点,生成 token 减少 11.15%,搜索次数减少 30.85%。
核心一句话
LeTS 不是底层 RL 算法的革新,是一份在 GRPO 上面做"过程信号工程"的精细化工作:用基于检索文档 Jaccard 相似度的两条规则奖励(rollout 内查重 + 组内对齐),把原本 outcome-only 的轨迹 advantage 按步重缩放。它的价值在于第一次把"think-and-search 过程的评价"用零标注成本的方式塞进了 RL 目标里——不需要训 PRM、也不需要人标 step label,纯靠组内 rollout 的对比和检索结果的 set 运算就能跑通。论文做完七个 RAG benchmark 的扫扫,看下来更像一个"如何在已有 RL-RAG 框架上多吃出 2 个点"的实操指南,而不是范式级别的创新。但作为工程参考,里头几个细节我觉得是真的值得抄走。
论文信息
- 标题:LeTS: Learning to Think-and-Search via Process-and-Outcome Reward Hybridization
- 作者:Qi Zhang, Shouqing Yang, Lirong Gao, Hao Chen, Xiaomeng Hu, Jinglei Chen, Jiexiang Wang, Sheng Guo, Bo Zheng, Haobo Wang†, Junbo Zhao† (*共同一作,†通讯作者)
- 机构:浙江大学(Zhejiang University)、蚂蚁集团网商银行(MYBank, Ant Group)。
- arXiv:2505.17447(v1,2025年5月23日)
- 收录:EMNLP 2025 Main
- 代码:Cheungki/LeTS
从两个真实样例讲起:到底什么叫"搜废了"
论文一上来就用图 1 讲了两个非常具体的失败案例。我建议先盯着这张图看一分钟,比看任何 abstract 都清楚。
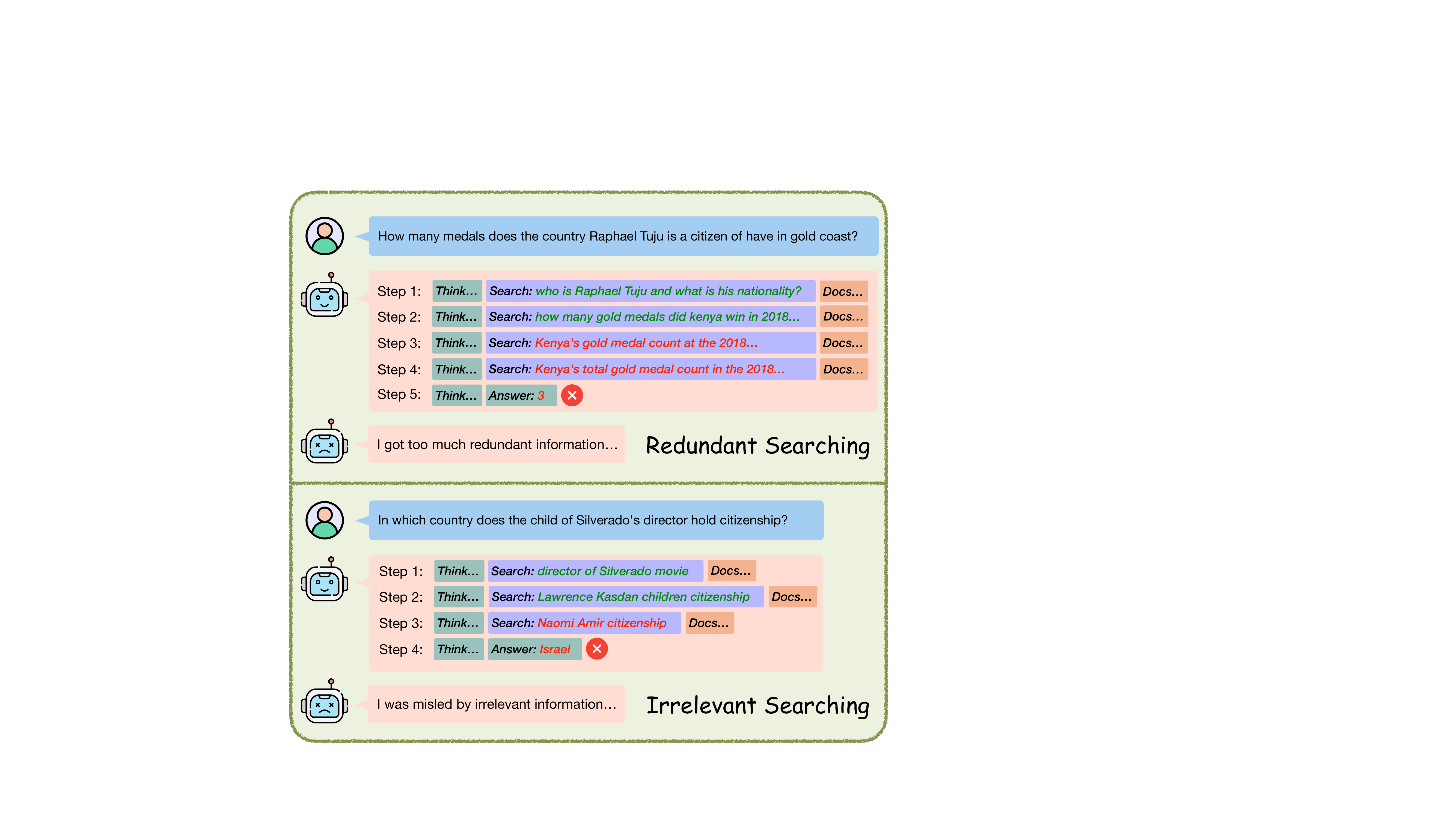
图1:两类典型的"搜废了"模式。Redundant Searching 是同义反复地搜同一件事;Irrelevant Searching 是中间某一步突然跑偏,污染了后续推理。
我自己的第一反应是:这俩问题其实是同一个根因——outcome-only 的 reward 没有给模型"哪一步搜得好、哪一步搜得废"的信号。GRPO 默认拿 final answer 的 F1 作为 reward,整个 rollout 内每个 token 拿到的是一样的 advantage。模型在训练里能学到的只是"这条链整体好不好",学不到"第几步该改"。
如果你做过 trace 级别的 reward shaping,这个困境会很熟悉。CoT 数学场景里有 process reward model(PRM),可以给每一步打分;但 PRM 要么贵(人工标注 PRM800K 那种),要么不靠谱(用 LLM 当 judge)。RAG 场景甚至没有现成的 PRM,因为"一步检索好不好"很难用单 step 的标签精确定义——它依赖于上下文。
LeTS 想做的事就是:不训 PRM,不靠人标,只靠 rollout group 内部的对比和检索文档集合的运算,就能把过程信号挤出来。
一段话讲清楚 think-and-search 的训练范式
为了让后面公式更顺,先把背景过一遍。这是 ReSearch / Search-R1 / R1-Searcher 那一套通用框架:
模型在 <think>...</think> 标签里推理,在 <search>...</search> 里发起检索请求,环境返回 <result>...</result>。多轮交替直到 <answer>...</answer>。形式化地,对一个问题 \(q\) 走 \(n\) 个 think-and-search 步:
最后给出 \(a\)。RL 的目标是让模型学到"什么时候该搜、搜什么"的策略。outcome reward 的定义跟 ReSearch 一致,格式对就给 F1 分(和一个 0.1 的格式分),格式错就 0:
这套是有效的——R1-Searcher 和 ReSearch 都已经在 multi-hop QA 上干掉了 SFT-RAG 路线。但天花板就卡在 outcome 那一刀切。
LeTS 的两条规则奖励:核心其实只有一个想法
LeTS 把 GRPO 一组 \(G\) 个 rollout 按 outcome reward 分成三类:
- Invalid:格式错误的,不参与过程奖励计算
- Outperforming:格式对 + 答案 EM 命中
- Underperforming:格式对但答案错
这就是它整个 design 的起点:好的 rollout 和差的 rollout,能不能互相当老师?
第一条:Rollout-Level Knowledge Redundancy Reward(KR)
这条只对 outperforming rollout 生效。问题是:就算我答对了,链条里有没有"白搜"的步骤?方法很直接——拿 step \(j\) 检索到的文档集合 \(d_{i,j}\) 跟前面所有步 \(d_{i,t}\)(\(t \lt j\))做 Jaccard 相似度,取最大值。重复度越高,奖励越低:
工程直觉:每一步都应该带新信息。如果你这一步搜出来的 5 篇文档跟上一步重了 4 篇,那这步基本是浪费。Jaccard 是 set 运算,没有任何模型推理在里面,0 标注成本。
第二条:Group-Level Knowledge Match Reward(KM)
这条只对 underperforming rollout 生效,思路更巧。一个错的 rollout 里也可能有几步是搜对了的,只是后面被某一步带歪了。怎么挑出"哪几步是好的"?
LeTS 的做法:拿同 group 里某条 outperforming rollout 当锚,做步骤级双向匹配。具体地,对错的 rollout \(y_u\) 和对的 \(y_o\),构造匹配矩阵 \(\mathbf{m}^{u,o} \in \mathbb{R}^{n_u \times n_o}\),每个元素是两边某两步检索文档集的 Jaccard 相似度:
然后用 Kuhn-Munkres 算法(也叫匈牙利算法,一种最优二分匹配)对两组步骤做最优分配,每个错链的步骤拿到的 KM 奖励 = 它跟对链里被分到的那一步的 Jaccard 相似度。如果某一步在对链里能找到强匹配,说明它"思路是对的",惩罚就该轻一点。
我看到这块的时候愣了一下——用匈牙利做 step alignment 在论文里其实不算第一次出现,但在 RL-for-RAG 这个组合下,对应到 optimal transport 视角的解释("underperforming 的步骤被最优运输到 outperforming 上")我觉得是真的漂亮。它把"组内自我对比"这个 self-consistency 的思路,从 inference time(最后投票)平移到了 training time(每一步打分)。
如果一个 group 里没有任何 outperforming rollout(即没人答对),KM 就跳过这个 group。
第三步:怎么把过程信号塞回 advantage
光有 process reward 还不够,关键是怎么和 outcome advantage 融合。LeTS 没用加权求和、也没改 critic,而是用了一个步级 advantage rescaling:
其中 \(A_i^{o}\) 是 GRPO 里组内归一化的 outcome advantage,\(\hat{r}_{i,j}^{p}\) 是 rollout 内归一化的 process reward,\(\lambda\) 是缩放因子(实验固定 0.1)。\(\mathrm{sgn}(A_i^o)\) 这个细节挺关键——它保证 rescaling 永远是"放大"或"减弱"原 advantage 的绝对值,不会翻号。
直觉上:
- \(A_i^o > 0\)(这条链好):步好的(高 \(\hat{r}^p\))advantage 进一步放大,步差的削弱
- \(A_i^o \lt 0\)(这条链差):步好的削弱惩罚(因为它本身是对的),步差的加重惩罚
实现上还有一个小细节:最后一个推理步不参与 rescaling——这是为了避免最终回答的梯度被扰动,跟 final answer 直接相关的那一步必须保持原 advantage。
整个流程图就长这样:
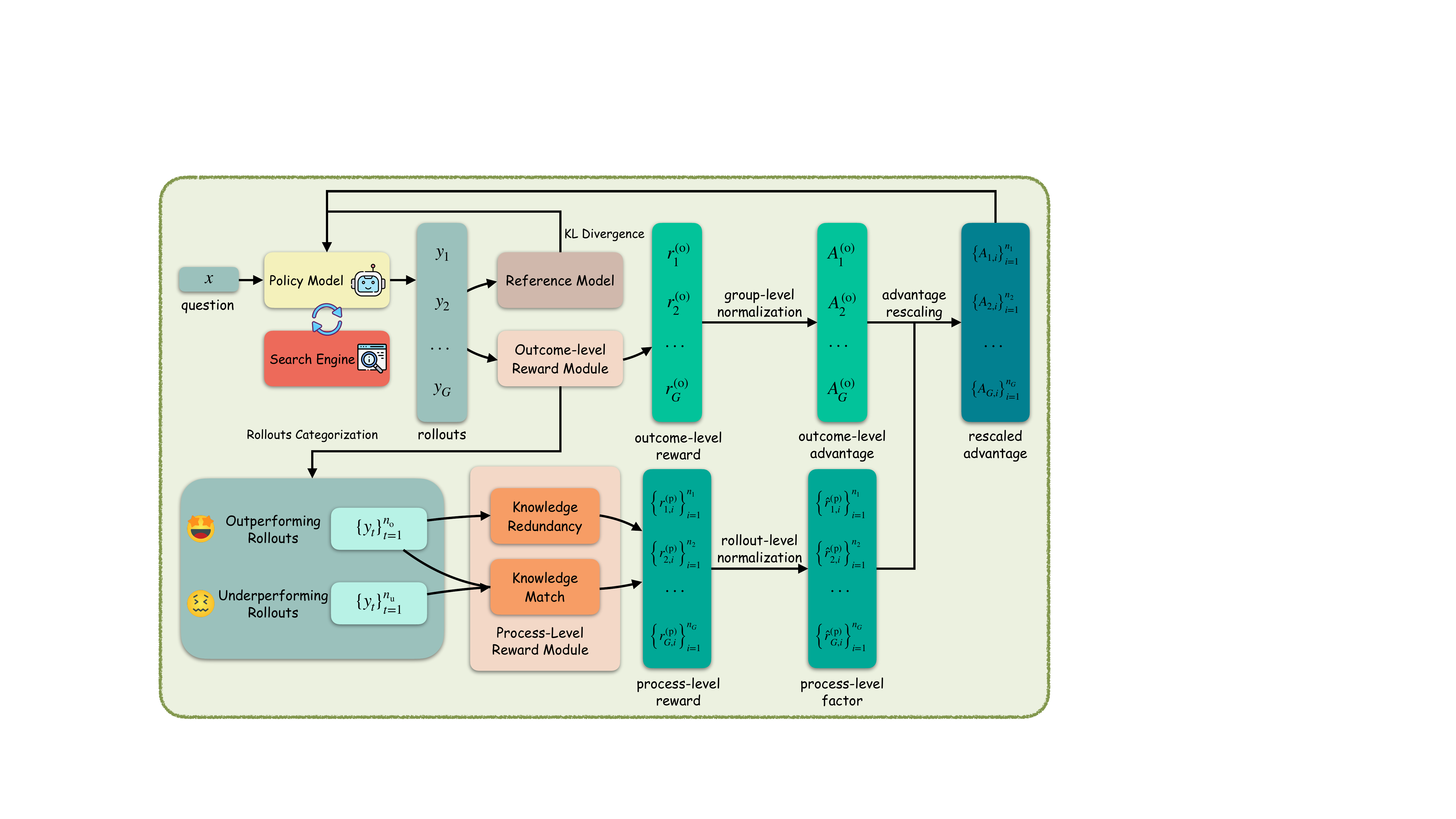
图2:LeTS 总体框架。和原版 GRPO 比,多了"按 outcome 分桶 → 两路 process reward → 步级 advantage rescaling"这条线。注意 reference model 和 KL 散度部分跟标准 GRPO 没差别。
实验:跑了七个 benchmark,看几个关键数据
训练只用 MusiQue 训练集,2 个 epoch;评估在 4 个 multi-hop benchmark + 3 个 single-hop benchmark 上。基础模型 Qwen2.5-7B / 7B-Instruct / 3B-Instruct。
主实验:multi-hop
| Model | HotpotQA EM | 2Wiki EM | MusiQue EM | Bamboogle EM | 平均 EM | 平均 LJ |
|---|---|---|---|---|---|---|
| Direct | 19.18 | 25.76 | 3.76 | 10.40 | 14.78 | 22.82 |
| Naïve RAG | 31.90 | 25.78 | 6.21 | 20.80 | 21.17 | 30.97 |
| Iter-RetGen | 34.36 | 27.92 | 8.69 | 21.60 | 23.14 | 33.86 |
| IR-CoT | 30.33 | 21.57 | 6.99 | 24.80 | 20.92 | 33.43 |
| ReSearch-Qwen-7B | 40.57 | 44.67 | 21.68 | 43.20 | 37.53 | 49.23 |
| ReSearch-Qwen-7B-Instruct | 43.52 | 47.59 | 22.30 | 42.40 | 38.95 | 51.42 |
| LeTS-Qwen-7B | 40.62 | 46.79 | 22.18 | 47.20 | 39.20 | 51.22 |
| LeTS-Qwen-7B-Instruct | 43.16 | 48.66 | 23.21 | 51.20 | 41.56 | 53.75 |
EM=Exact Match,LJ=LLM-as-a-Judge(GPT-4o-mini判别语义等价)。LeTS-Qwen-7B-Instruct 在 4 个 multi-hop benchmark 平均拿到 41.56% EM 和 53.75% LJ,比同 backbone 的 ReSearch 涨 2.61% 和 2.33%。
3B-Instruct 上也是一样的趋势,LeTS 平均比 ReSearch 涨 1.05% EM。
单跳泛化
虽然只在 MusiQue 这种 multi-hop 数据集上训,但单跳上也涨了:
| Method | NQ | PopQA | TriviaQA | 平均 |
|---|---|---|---|---|
| Naïve RAG | 36.26 | 39.93 | 61.24 | 45.81 |
| ReSearch | 40.86 | 44.58 | 63.71 | 49.72 |
| LeTS | 42.58 | 43.91 | 64.63 | 50.37 |
值得说一下:单跳数据集本来不需要多步思考,能涨 0.65% 我倾向于解读为"过程奖励让模型对 retrieve-or-not 的判断更准了,少走冤枉路"。
推理效率:这个数我觉得最有说服力
| Dataset | HotpotQA | 2Wiki | MusiQue | Bamboogle | 平均 |
|---|---|---|---|---|---|
| ReSearch tokens | 278.25 | 328.53 | 328.14 | 232.87 | 291.95 |
| LeTS tokens | 244.29 | 275.82 | 335.87 | 189.30 | 261.32 |
| Δ% | ↓12.20 | ↓16.04 | ↑2.36 | ↓18.71 | ↓11.15 |
| ReSearch 搜索次数 | 2.78 | 3.48 | 3.21 | 2.58 | 3.01 |
| LeTS 搜索次数 | 1.84 | 2.31 | 2.21 | 1.94 | 2.08 |
| Δ% | ↓33.81 | ↓33.62 | ↓31.15 | ↓24.81 | ↓30.85 |
生成 token 平均少 11%,搜索次数平均少 30%——推理成本和检索 API 调用成本同步往下走。在工业部署里这个比涨 2 个点 EM 更值钱。我做过类似的 multi-hop agent,一次 query 平均 3 次检索压到 2 次,整个 P99 latency 立刻就好看了。
消融:两条奖励缺一不可
| Method | w/. KR | w/. KM | AST↓ | EM↑ |
|---|---|---|---|---|
| vanilla GRPO | ✗ | ✗ | 3.21 | 22.18 |
| w/. KR | ✓ | ✗ | 2.71 | 22.22 |
| w/. KM | ✗ | ✓ | 2.59 | 22.67 |
| LeTS | ✓ | ✓ | 2.21 | 23.21 |
AST=Average Search Time。两条规则单独上各自能拉低 0.5+ 次平均搜索次数,组合起来拉到 2.21。EM 也是只用其中一条收益有限,组合才把分数顶上去。这个数说明两条 reward 的目标是互补的——KR 负责"少搜重的",KM 负责"对的步骤别冤枉"。
训练动力学
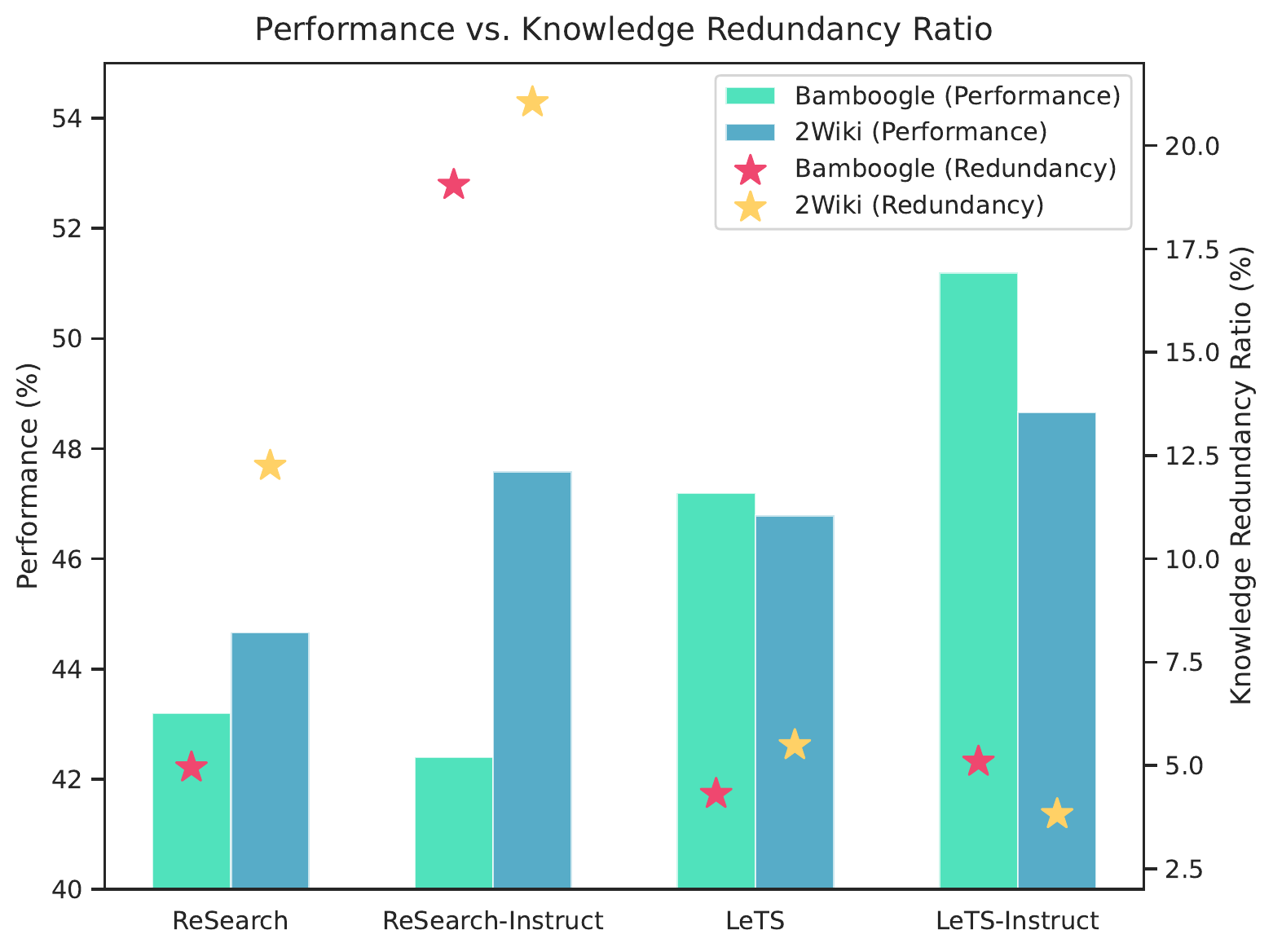
图3:在 Bamboogle 和 2Wiki 上,LeTS 把性能往上推的同时把检索冗余打下去。注意 ReSearch-Instruct 的冗余比反而比 ReSearch-Base 高,这是个反直觉但有道理的现象。
ReSearch-Instruct 冗余反而更高这个细节我多想了一下。Instruct 模型在 RL 里更倾向于"反复确认"——它被训练得更小心,不确定就再搜一次。但这种"小心"在没有过程惩罚的时候会被 outcome reward 默许(因为搜多次确实有时候能保命),LeTS 加上 KR 之后这个"假勤奋"就被卡住了。
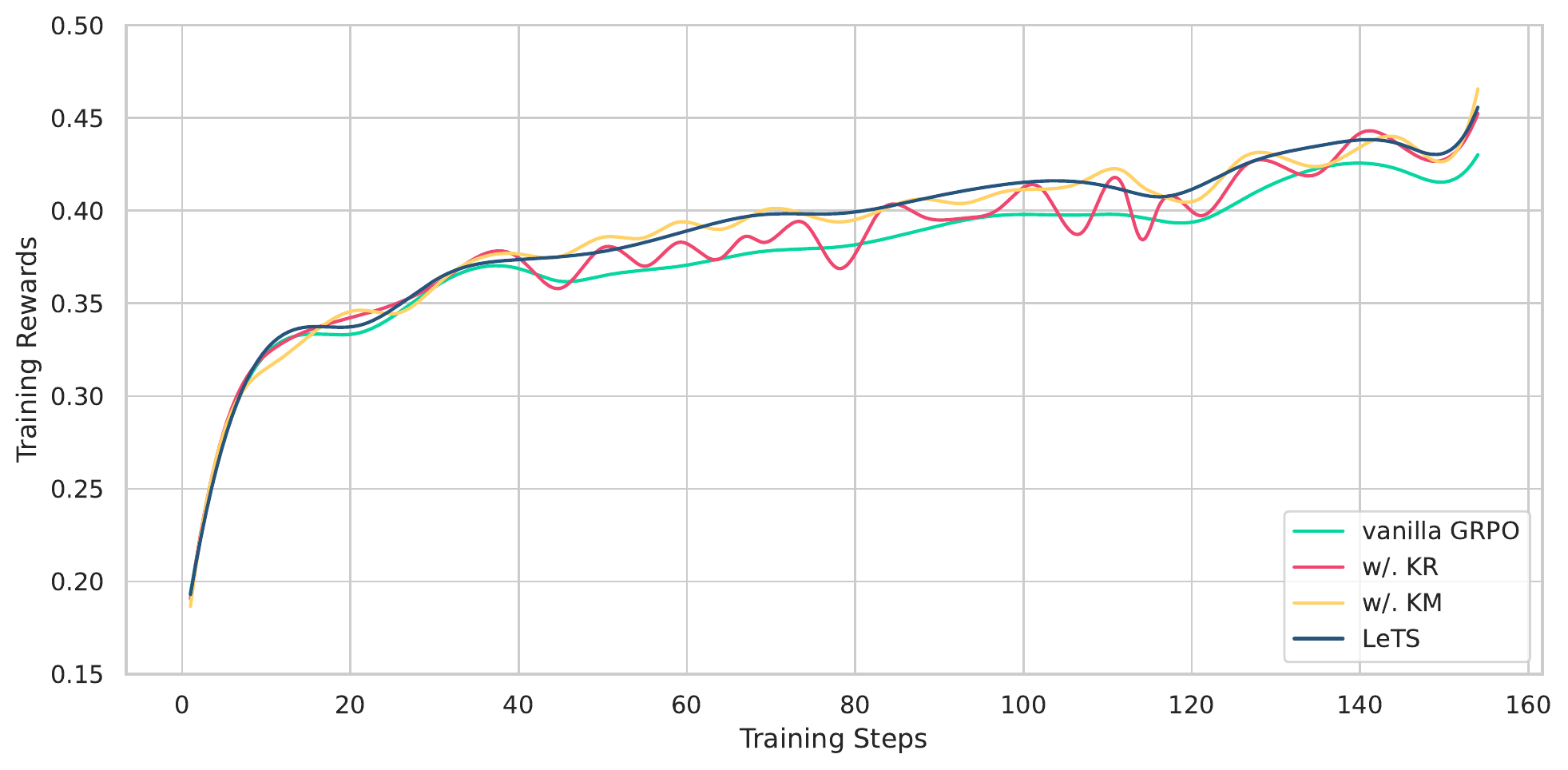
图4:训练 reward 曲线。LeTS 不是涨得最猛的那条,但稳定性明显比 vanilla GRPO 好。
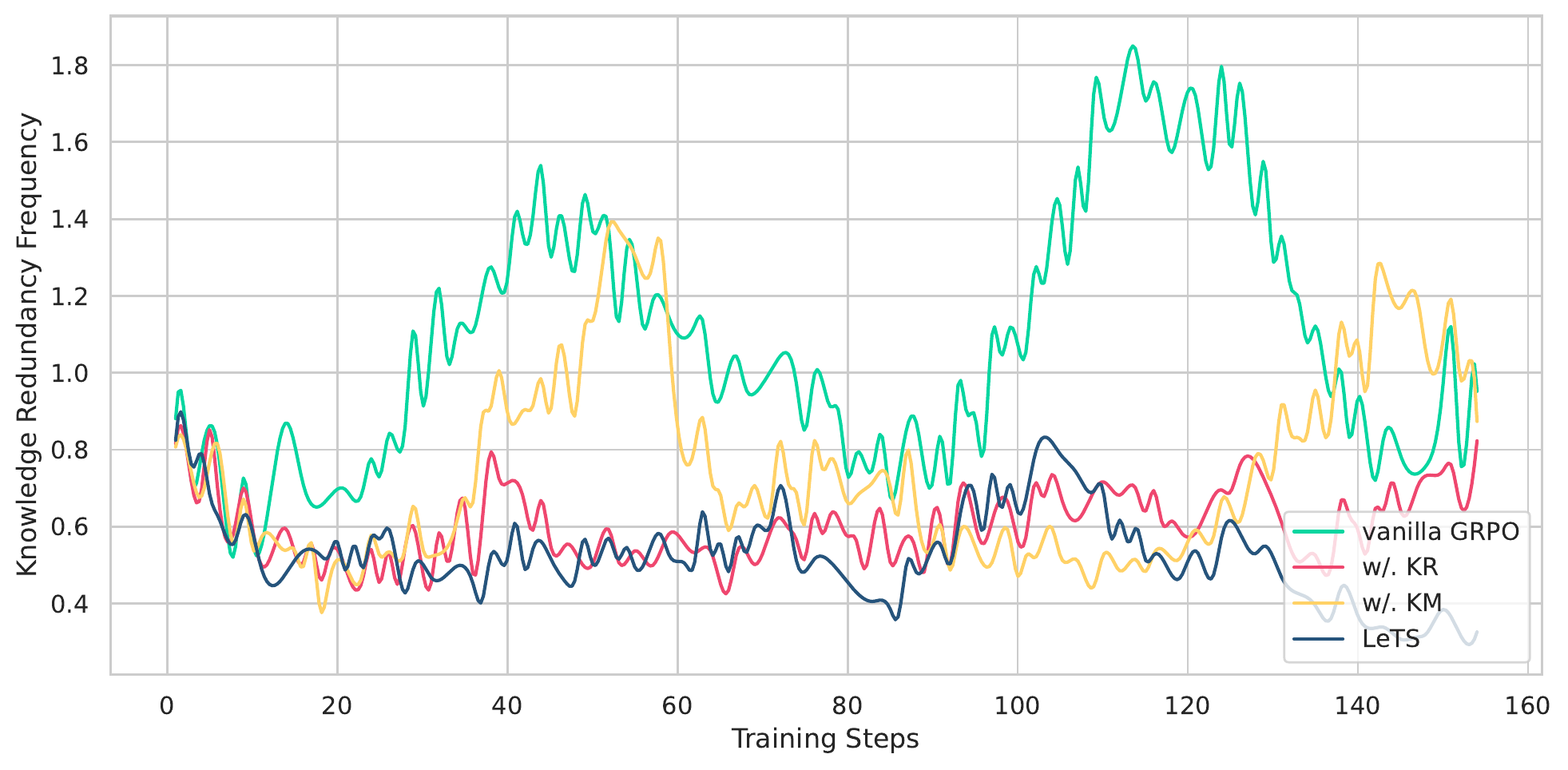
图5:训练中的知识冗余频率。vanilla GRPO 那条绿色线在中段那个鼓包真的很说明问题——模型在没有过程惩罚的时候,会主动学会"多搜几次反正能命中"的偷懒策略。
图 5 这条曲线我觉得是论文最有信息量的一张图。vanilla GRPO 不是不收敛,是收敛到了一个错的局部解:最优策略变成"反正不要钱,那我多搜几次"。这跟之前 reward hacking 的研究是对的上的——任何没有显式约束的 reward 设计都会被 RL 钻空子。LeTS 做的事情就是把这个"成本"显式化进 reward。
一个有意思的负面发现:3B-Base 上 reward hacking 直接崩
论文附录里讲了一个值得提的细节:他们试图在 Qwen2.5-3B-Base 上跑 ReSearch,结果 reward 涨到 0.3 左右的时候,模型平均搜索次数直接降到 0——也就是说模型学会了完全不搜直接答,靠记住的 F1 分数糊弄过去。
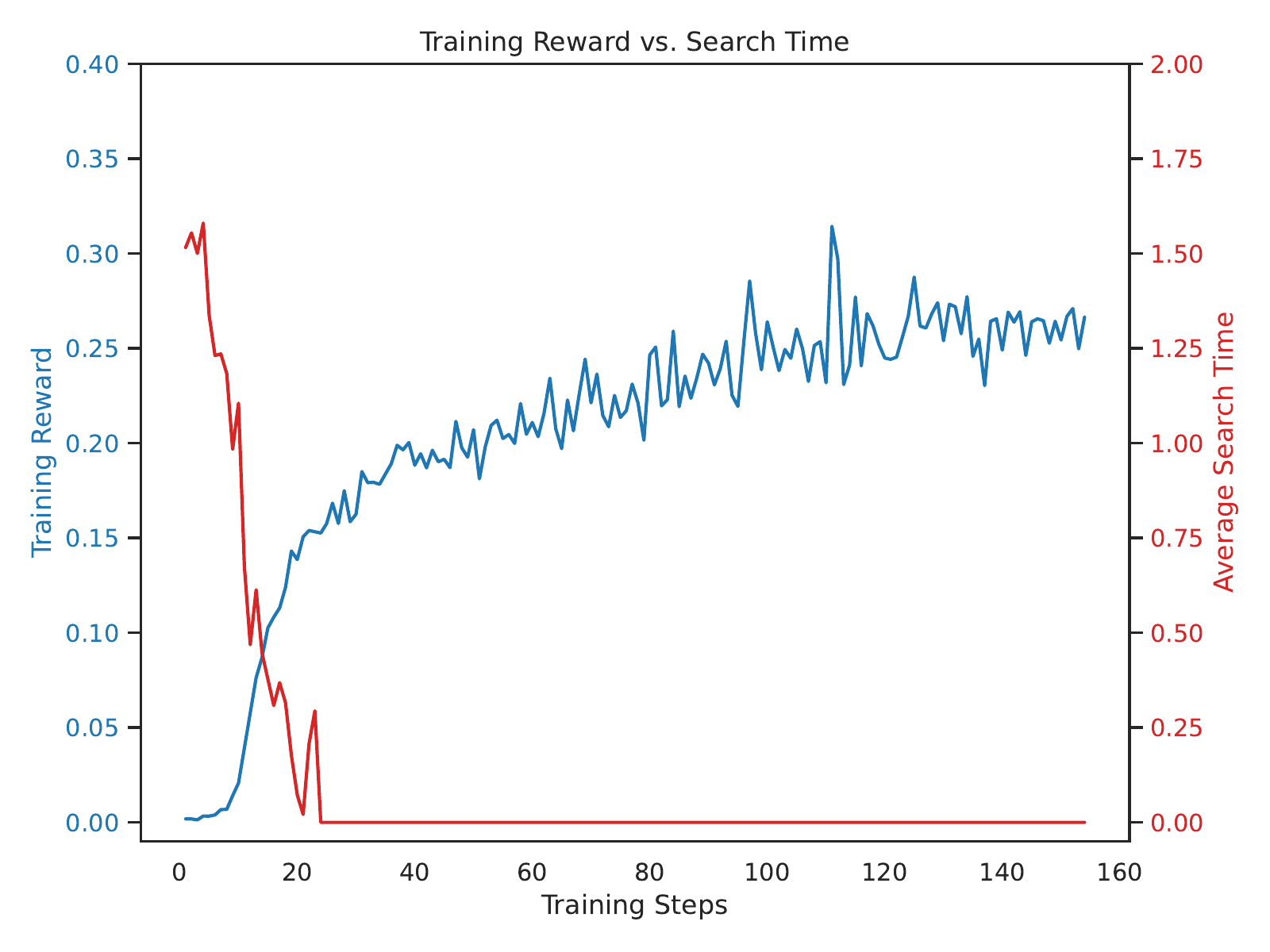
图6:3B-Base 的 reward hacking 现象。这是论文里非常诚实的一段描述,提醒我们 outcome-only RL 在小模型上的脆弱性。
这个发现不是 LeTS 的功劳(LeTS 也没解决),但它给后续工作提了一个悬而未决的问题:对于 base model 尤其是小 base model,单靠 F1 outcome reward 是不足以激发 think-and-search 行为的。这块论文坦白没解,留给后续。
训练配置(给想复现的同行)
| Parameter | Value |
|---|---|
| Learning Rate | 1e-6 |
| Train Batch Size | 256 |
| Number of Training Epochs | 2 |
| Number of Rollouts | 5 |
| Rollout Temperature | 1.0 |
| KL Loss Coefficient | 0.001 |
| Clip Ratio | 0.2 |
| Num. Document Retrieval | 5 |
| Rescale Factor \(\lambda\) | 0.1 |
硬件:8×A100,全参 + gradient checkpointing。框架:VeRL 做 RL,FlashRAG 做评估。
\(\lambda\) 是在 {0.05, 0.1, 0.2} 里调出来的,后续所有实验固定 0.1——也就是 process reward 对 advantage 的扰动幅度其实不大,就是个温和的"调味剂"。
我的判断
三个我觉得真值得抄的细节
第一,Jaccard + Kuhn-Munkres 这个组合的零成本特性。检索文档是 doc id set,做 set 交并和最优匹配本来就是个低开销的操作。整个 process reward 不需要多走一遍模型,不需要 PRM,不需要标注。这种"零额外计算 + 零额外标注"的设计在 RL 里非常稀缺——大部分 process reward 方案要么贵要么噪。如果你做的是工具调用 agent,把 Jaccard 换成"工具返回结果的特征 hash 集合 + Kuhn-Munkres 对齐",这套范式照搬基本能跑。
第二,stepwise advantage rescaling 是个比加权求和更优雅的融合方式。我之前在做 multi-source reward 融合的时候习惯用 \(r = r_o + \alpha r_p\) 那种线性叠加,问题是 \(\alpha\) 不好调,process reward 的 scale 一变整个训练就不稳了。LeTS 这个 \((1 + \mathrm{sgn}(A^o) \cdot \lambda \hat{r}^p) \cdot A^o\) 的形式有个隐藏好处:process reward 永远是相对地调节 outcome advantage 的幅度,不会单独主导梯度方向。\(\lambda\) 在 {0.05, 0.1, 0.2} 里都能 work 这个事就说明这个公式 robust 得多。
第三,"组内对比"的思路完全可以推广。LeTS 做的是 RAG 场景下"对的 rollout 教错的 rollout"。这个范式其实很像 self-consistency 在 training time 的版本。我能想到的近期推广: - 工具调用 agent 里"对的链"教"错的链"哪一步该调用哪个工具 - 代码生成里"对的链"教"错的链"哪一步该改测试还是改实现 - 数学推理里 outperforming 的解题路径教 underperforming 的某一步推导
只要你能定义出"步级 representation 的相似度",这套就能套。
三个让我皱眉的地方
第一,所谓的 process reward 本质是 lexical overlap,不是 semantic。Jaccard 算的是 doc id 的集合重合度,但实际工程里两篇内容相似的文档可能根本不重合(不同来源的相同事实)。我做过类似的 dedup,Jaccard 的 false positive/false negative 都不低。论文用 doc id 当 set 元素其实是个比较粗糙的度量——你可以反过来想,如果 retriever 本身就不太稳定(每次返回的 top-k 都有抖动),那 Jaccard 信号会很噪。论文没讨论这块的鲁棒性。
第二,训练数据只有 MusiQue,泛化结论需要打折扣。所有的训练都只在 MusiQue 一个数据集上跑了 2 个 epoch,然后报泛化数据。在 multi-hop 场景里 MusiQue 是相对最难的(多跳更深),用它训出来的模型在 HotpotQA / 2Wiki 上涨分有合理性。但单跳数据集(NQ/PopQA)上的提升我觉得还没充分论证——0.65% 的平均提升在单跳本来 noise floor 就高的场景下,能不能当结论需要保留态度。
第三,没跟 S²R 这类 process+outcome 工作做正面对比。论文 related work 里提到 S²R(Sun 等的 process+outcome RL,但那篇是数学场景),然后说"S²R 不是 retrieval-specific"就把它放过去了。但 S²R 的范式(self-verify + self-correct + process reward)其实可以平移到 RAG 上——LeTS 没把这个对比做出来,导致"process+outcome 哪条路线更优"这个问题在 RAG 场景下没有真正回答。
这篇论文的真实定位
不是底层突破,是"基于 GRPO 的精细化信号工程"路线下的一个高质量样本。
跟 ReSearch / Search-R1 / R1-Searcher 比,LeTS 的算法骨架完全一致(都是 GRPO + outcome reward),创新点局限在 reward shaping 这一层。它最大的价值在于演示了"零标注成本的过程信号是可行的",这一点对工业部署有实际意义——当你已经在跑 ReSearch-like 的 pipeline,加一层 KR+KM 几乎是免费的,但能换来 30% 的搜索次数节省。
跟 PRM 路线(OpenAI Math Shepherd、DeepSeek-Math 那种用 PRM 给每步打分)比,LeTS 是一个 trade-off:放弃了"语义级别的步级评估",换来了"零标注 + 零额外计算"。在 RAG 场景下我倾向于这个 trade-off 是值的——毕竟 RAG 的"步级好坏"本来就难以用绝对的语义标签精确定义。
一个开放问题
如果把 LeTS 这套从 multi-hop QA 推广到更复杂的 agent 场景(比如带工具调用、网页操作的 long-horizon agent),KR/KM 这两条规则该怎么改?
- KR 可以改成"工具调用结果的 representation 重合度",理论上能 work
- KM 在 agent 任务里可能更难——成功的 trajectory 和失败的 trajectory 步数差异可能巨大,Kuhn-Munkres 二分匹配的对齐质量会下降
这是我看完之后最想知道的问题。如果 LeTS 团队后续在这块出 follow-up,我会很期待。
写在最后
如果你正好在做 RL-for-RAG,或者更广义的 RL-for-agent,LeTS 提供的不是一个能让你直接抄走的 SOTA 方法,而是一个值得借鉴的 reward design pattern:
在已有的 outcome-RL 框架上,用零标注成本的规则信号(基于 representation 集合运算 + 组内最优匹配)做步级 reward shaping,通过 advantage rescaling 而非加权求和的方式融合进 GRPO,固定一个温和的 \(\lambda\)。
这个 pattern 抄过去几乎没成本,但很可能给你换来 5-10% 的推理效率提升。在工业场景里这种"低风险、稳收益"的方案永远是最受欢迎的。
至于这套方案能不能上更大模型(70B 量级)继续 work,论文坦白没验证,限于成本。但从 7B 上的趋势来看,我个人是相对乐观的——process reward 解决的是"信号粒度"问题,跟模型 scale 关系不大。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我