GRPO-LEAD:让推理模型说人话——给 GRPO 加上长度、罚分和难度三味药
EMNLP 2025 Main · Johns Hopkins University · arXiv 2504.09696
写在前面
跑过 R1 复刻的人多半都碰到过这个尴尬:模型确实变聪明了,AIME 上分明显,可你打开它的输出一看——一道题写了 8000 个 token,前 2000 在反复"Let me reconsider...",中间还插了三段"Wait, let me verify this another way",最后才慢吞吞给出 279 这个答案。
正确率涨了,token 也涨了。推理时延和成本一起飞。
GRPO 的二元奖励信号本身就是这种"啰嗦"的根源:你只看最终答对没答对,模型当然就学会了"多说几句保险"。再叠加一个事实——同一组 8 个 rollout 要么全对要么全错的时候 advantage 直接变零,梯度也没了。结果训练过程里简单题被反复刷高分,难题反而越练越差。
这篇 GRPO-LEAD(EMNLP 2025 Main)想做的事情,就是把这三个病一起治了。改动其实不大:在 GRPO 上加一个长度归一化的奖励、一个错误回答的显式负分、再加一个按题目难度动态放大 advantage 的权重。三个东西堆在一起,14B 模型在 AIME24 / AIME25 上拿到当时这个量级的 SOTA,输出长度还比 baseline 短了 1500-1800 token。
我个人觉得这篇论文的真正价值不在 SOTA,而在于它把"reward shaping 怎么设计"这件事讲清楚了——尤其是难度感知那一块,做法简单得不能再简单(一个 logistic 函数),但解决的问题非常真实。
论文信息
- 标题:GRPO-LEAD: A Difficulty-Aware Reinforcement Learning Approach for Concise Mathematical Reasoning in Language Models
- 作者:Jixiao Zhang, Chunsheng Zuo(共同一作)
- 机构:Johns Hopkins University
- arXiv:2504.09696v2(v1 提交于 2025 年 4 月 13 日,v2 修订于 2025 年 9 月 19 日)
- 会议:EMNLP 2025 Main
- 代码:github.com/aeroplanepaper/GRPO-LEAD
GRPO 到底卡在哪儿
先用一句话把 GRPO 的故事讲清楚:DeepSeek 在 R1 那篇里用的策略优化算法,针对每个问题采样 G 个回答(一组 group),用组内 reward 减去组内均值再除标准差当 advantage,跳过价值函数,单纯用规则奖励(数学题就是答案对/错)就能驱动模型学会长链推理。
简单粗暴,效果好,社区跟进的工作一大堆。
但跑过的人都知道有几个老毛病:
第一,奖励太稀疏,梯度时不时就消失了。 二元 0/1 奖励的代价是:一组里如果 8 个 rollout 全对或者全错,组内方差就是 0,advantage 算出来全是零。这一组对训练完全没贡献。难题尤其严重——模型连一个对的都采不出来,这道题就废了。
第二,模型越练越啰嗦。 这个其实是 reward hacking 的一种典型变体。你给的 max budget 是 16k token,模型发现"我多想几步,多 self-verify 一遍,正确率确实会涨"——于是它就拼命凑长度。Pass@1 在涨,但每一个 token 的边际收益都低得可怜。Kimi、L1、Yeo et al. 这些工作都试图用各种长度奖励压一下,但要么是预先定一个"理想长度",要么是 cosine 衰减,都很死。
第三,对错的边界太模糊。 没有显式负分的话,模型对一道难题宁可瞎猜一个不写"我不会"——猜对了拿 1 分,猜错了 0 分,从期望上看猜永远不亏。但这种行为对真实精度没好处,只会让 pass@1 看起来好看一点。
第四,简单题刷分,难题摆烂。 这点最隐蔽。你训练数据里 80% 的题模型本来就能 80% 答对,剩下 20% 的难题它从来都答不对。GRPO 不区分难度,每道题给一样的 advantage 量级,结果就是模型在简单题上反复练同一种套路,难题永远没机会真正进步。
这四个病,前三个都有人单独修过,但少有把它们当成一个系统问题去解的。LEAD 就是冲着这一块来的。
方法:LEAD 三件套
LEAD = Length-dependent reward + Explicit penalty + Advantage reweighting for Difficulty。整个框架一张图就能讲清楚。
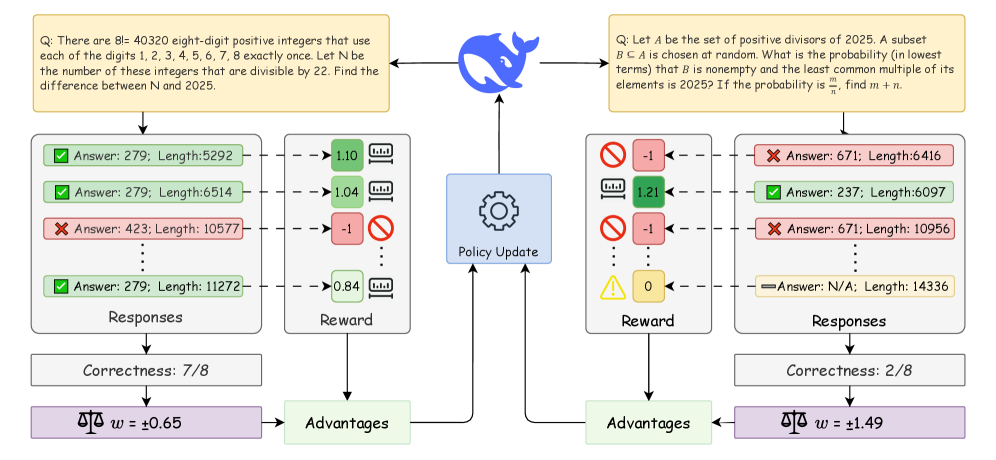
图1:左右两道题分别展示了简单题(8 个 rollout 中 7 个对)和难题(8 个 rollout 中 2 个对)下,LEAD 是怎么做奖励和 advantage 调整的。简单题每个正确回答按相对长度给一个 0.84-1.10 的奖励,最长那个不算正样本;难题里错回答统统拿 -1,对的回答按长度给正分,最后整组 advantage 还要乘上一个难度权重 w——简单题 w=±0.65,难题 w=±1.49,难题被显式放大。
下面把三个组件一个个拆开。
长度依赖奖励:让短答案更值钱
核心思路一句话:正确回答之间也要分高低,越短越值钱。
具体做法是先对一组里所有正确回答的 token 长度做 z-score 归一化:
其中 \(\mu, \sigma\) 是这一组正确回答长度的均值和标准差。然后用一个指数衰减把 z 映射成 reward:
论文里 \(\alpha = 0.05\),温和一点的衰减。
这个设计精明在哪?
它没用绝对长度。Kimi 用 min-max 归一化,L1 用一个固定的 golden length,Yeo 用 cosine——这些都假设你能预先知道每道题"应该"多长。但这是个错觉。简单题 1500 token 就够了,难题可能需要 6000 token。给所有题硬上一个固定阈值,要么逼着模型在难题上糊弄事,要么让简单题写得过细。
z-score 归一化的好处是它本身是相对的——同一组里你比别人短,你就拿高分,跟绝对长度无关。模型自然会在每一道题上都学着"在保证答对的前提下尽量精简"。
实测上这个东西涨点很扎实:AIME25 的 Pass@1 从 0.292 涨到 0.308(+5.4%),Cons@32 从 0.467 涨到 0.533(+14.1%),平均长度反而从 7113 token 砍到 5210 token(-26.8%)。
正确率往上走,长度往下走,这种数据很难骗到。
显式负分:把"瞎猜"的成本明码标价
第二个组件最简单:错的回答不再给 0,给 \(-1\)。
为什么这一改动会有用?作者给了一个我觉得挺漂亮的推导。假设长度惩罚可以忽略(\(\exp(-\alpha z) \approx 1\)),那一个回答的期望奖励就是:
只有当 \(P(\text{correct}) > 0.5\) 的时候,模型才能从这个回答里拿到正期望。
换成 GRPO 原版的 \(0/1\) 奖励,\(P(\text{correct}) > 0\) 就有正期望——也就是说哪怕你只有 10% 的把握,写一个答案也好过空着。这就是模型学会"瞎猜"的根源。
加了 \(-1\) 之后,模型必须对自己的答案有 50% 以上的把握才划算。这个阈值不是拍脑袋定的,是数学上推出来的——一个非常干净的设计。
实测上加上这个负分后,AIME24 上 Cons@32 从 0.767 涨到 0.800,Pass@1 从 0.458 涨到 0.470。涨幅不算特别夸张,但意义在于它系统性地降低了"无脑猜测"的概率。
难度感知 advantage:把学习预算往难题倾斜
这是我觉得 LEAD 最值钱的设计。
先定义一个题目的"经验正确率":一组 8 个 rollout 里答对了几个,比如 \(\rho_q = 7/8 = 0.875\)(简单题)或 \(\rho_q = 2/8 = 0.25\)(难题)。
然后用一个 logistic 函数把它映射成权重:
论文里 \(A = 0.4, B = 1.5, \rho_0 = 0.75, k = 10\)。这组超参的含义是:当 \(\rho_q\) 远高于 0.75(简单题),权重接近 0.4;当 \(\rho_q\) 远低于 0.75(难题),权重接近 1.5;过渡发生在 0.75 附近,斜率 \(k = 10\) 让过渡相当陡峭。
最后的 advantage 公式分两种情况:
这个 case 拆得很有意思。当 advantage 为正,也就是这是个"超过组内均值"的好回答,用 \(w(\rho_q)\) 加权——难题里的好回答稀有又珍贵,权重大;简单题里的好回答到处都是,权重小。当 advantage 为负,也就是差回答,用 \(w(1 - \rho_q)\) 加权——这就把规则反过来了:简单题上的差回答得重罚,因为本来就该答对;难题上的差回答轻罚,因为本来就难。
我读到这里愣了一下,因为这个设计其实在做两件事:
- 把训练梯度往"信息密度高"的样本倾斜——难题的对+简单题的错;
- 又不至于完全放弃简单题的梯度,因为 \(w\) 最低还是 0.4。
如果你做过 curriculum learning 或者 Hard Example Mining 的工作,会觉得这个思路很熟悉,但 LEAD 把它放在 GRPO 的 advantage 那一层来做,工程上特别轻——只需要在算 advantage 的时候多乘一个 logistic 项,没有任何额外采样、模型或数据处理。
还有一个"半个组件":训练课程
论文 §3.4 还讲了一个数据层面的 trick:先用 13k 道高质量数学题做 SFT(解答用 QwQ-32B 生成),然后做两阶段 RL——
- Stage 1:在 9k 道 DeepScaler 难题上跑 100 步,所有 LEAD 组件都开。
- Stage 2:把 stage 1 里 rollout 准确率不超过 75% 的题(约 2283 道)单独挑出来,再加上 Light-R1 的难题数据集(合计 3524 道),继续跑。后期还观察到模型有 n-gram 重复输出的毛病——这可能跟 SFT 里 EOS 信号不强有关——于是临时把长度奖励关掉,把重复 n-gram 的负分调到 -1.5,又跑了 140 步。
这一节其实把"高质量 SFT + 难题 curriculum + 针对性 reward 修补"讲得很坦诚,没遮掩,是这种工程论文里我比较欣赏的部分。
实验:数据怎么说话
设置
7B 实验从 DeepSeek-R1-Distill-Qwen-7B-Math 起步,14B 实验从 DeepSeek-R1-Distill-Qwen-14B 起步。所有训练用 VERL,KL penalty 直接砍掉(验证下来反而抑制探索)。
学习率 \(1 \times 10^{-6}\),batch size 32,group size 8。7B 测试时长度限制 8k,14B 测试时长度限制 14k。验证集是 27 道题,从 AIMO2、CMU-MATH-AIMO 和 AIME24 里抽出来的。
评估指标三个:
- Pass@1:单次采样答对的概率(温度 0.6 采样 32 次平均)
- Cons@32:32 次采样多数投票的准确率
- Len_avg:平均输出长度
数据集 AIME24 / AIME25——美国邀请赛级别的难题,每年 30 道,是当下衡量数学推理模型最硬的两个 benchmark。
训练动态:长度奖励让收敛更快
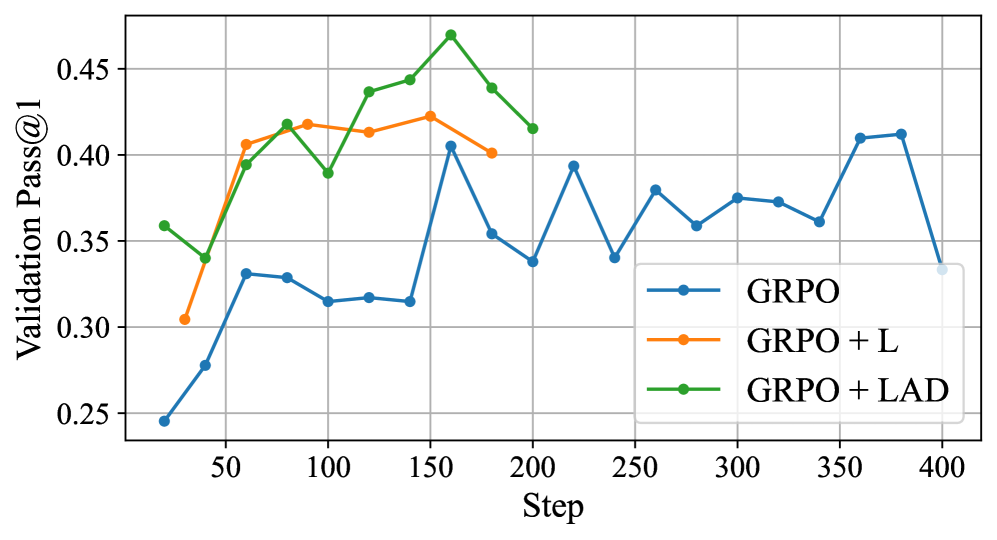
图2:蓝色是原版 GRPO,橙色是 GRPO+L(加长度奖励),绿色是 GRPO+LAD(再加难度感知)。曲线讲了两件事:长度奖励让前 100 步的收敛速度肉眼可见地快了一截,而加上难度权重后整条曲线又抬高了一档,到 step 150 附近能上 0.47 的 Pass@1。
这个图让我比较意外。直觉上你会觉得"加约束"应该让收敛变慢——长度奖励等于多了一个约束,怎么反而更快?
我后来想通了。原版 GRPO 在一组全对或全错的时候 advantage 是 0,等于没梯度。加了相对长度奖励之后,就算一组 8 个全对,它们的长度也几乎不可能都一样——长度差异本身就构成了 reward 差异,advantage 不再是零。长度奖励其实是把稀疏的二元 reward 变成了连续 reward,等于把梯度稠密化了。
这个观察我觉得比 SOTA 更值钱。后续做 RL fine-tuning 的同学完全可以借鉴。
7B 消融:每个组件都有贡献,但贡献点不一样
| 配置 | AIME24 Cons@32 | AIME24 Pass@1 | AIME24 Len | AIME25 Cons@32 | AIME25 Pass@1 | AIME25 Len |
|---|---|---|---|---|---|---|
| Deepseek-7B(baseline) | 0.767 | 0.431 | 6,990 | 0.467 | 0.292 | 7,113 |
| GRPO + 长度奖励 | 0.767 | 0.438 | 5,275 | 0.533 | 0.308 | 5,210 |
| + 难度权重 | 0.767 | 0.458 | 5,323 | 0.567 | 0.325 | 5,437 |
| + 显式负分(完整 LEAD) | 0.800 | 0.470 | 6,104 | 0.567 | 0.345 | 6,308 |
读这张表有几个有意思的点。
长度奖励主管"砍 token"。AIME25 上从 7113 直接干到 5210,砍了 27%,而 Pass@1 还小涨 5.4%。这是最干净的"双赢"。
难度权重主管"挑战难题"。注意从 GRPO+L 到 GRPO+LAD,AIME25 Pass@1 涨了 5.5%,但长度几乎没变。这印证了它真的是把学习信号往难题倾斜,让模型学会更难的解法。
显式负分主管"提精度"。最后一行 AIME24 Cons@32 从 0.767 提到 0.800(+4.3%),AIME25 Pass@1 从 0.325 提到 0.345(+6.2%)。但有个 trade-off:长度从 5300 多反弹到 6100 多。负分让模型不敢瞎猜,所以会自动多想几步——这其实是合理的行为。
我有点遗憾的是论文没给出"完整 LEAD" 在更激进的负分(比如 -2、-3)下的曲线。从期望奖励的推导看,负分大小直接控制 \(P(\text{correct})\) 的阈值。-1 对应 0.5,-2 对应 0.67——后者会让模型更保守。这个 trade-off 没探索完。
推理预算下的表现:低预算才是真考验
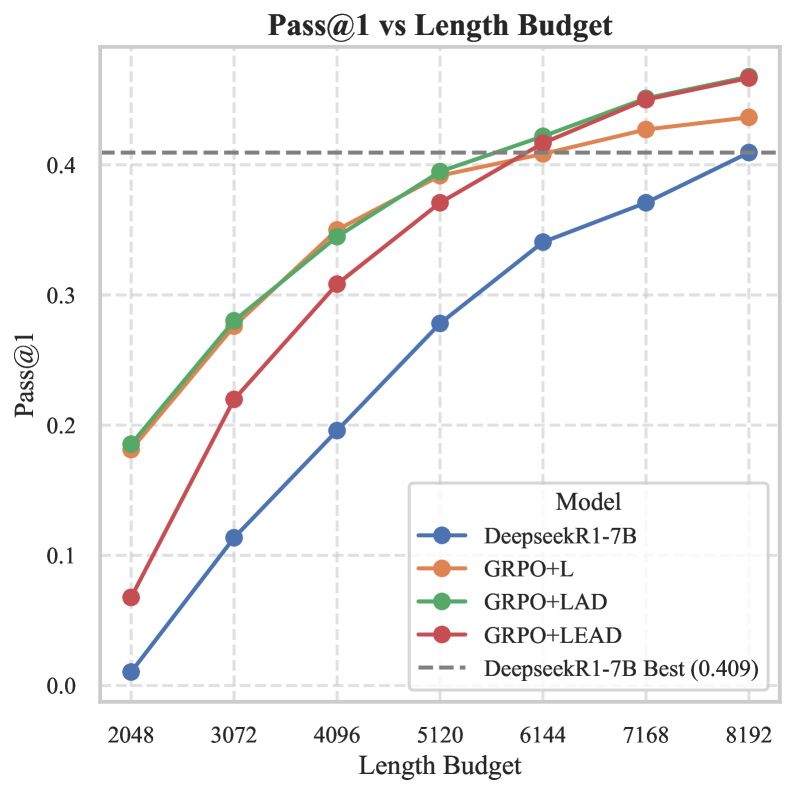
图3a:横轴是允许的最大 token 数,从 2048 到 8192。蓝线是没训练过的 DeepseekR1-7B(原始 distill),橙绿红三条是 LEAD 各阶段的模型。注意一个关键事实:在 2048-4096 这种低预算下,所有训过的模型都比 baseline 高出至少 10 个百分点;而到 6144 之后,原始模型才追到 0.4 附近——也就是说 LEAD 训练的模型用 5/8 的 token 就能匹配 baseline 的最高分。
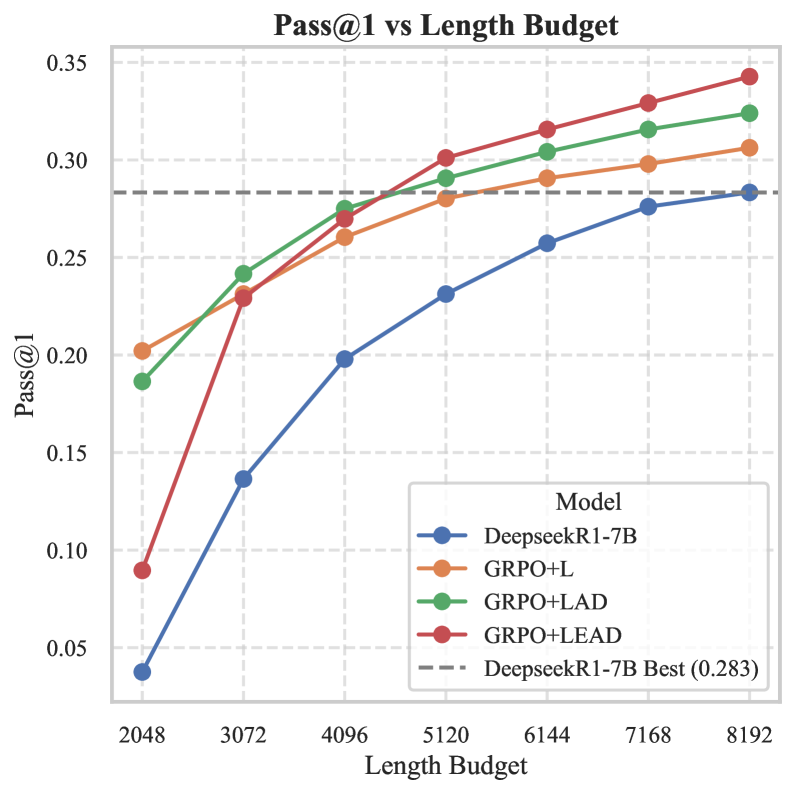
图3b:AIME25 比 AIME24 难得多。同样的趋势:LEAD 模型在低预算下大幅超越基线,但在高预算下完整版 GRPO+LEAD(红色)反而最强,到 8192 token 能上 0.34。这跟训练动态吻合——显式负分让模型多想几步,所以它需要更多预算来发挥。
这两张图让我对 LEAD 的实际工程价值评分更高了。在生产环境里,inference token 数直接关联成本和延迟。如果你能在 4096 token 内拿到原始模型 8192 token 的精度,等于成本砍半。这种 deployment-friendly 的特性,比 pure SOTA 更值得关注。
14B 上 SOTA:跟 Light-R1 正面 PK
| 模型 | AIME24 Cons@32 | AIME24 Pass@1 | AIME24 Len | AIME25 Cons@32 | AIME25 Pass@1 | AIME25 Len |
|---|---|---|---|---|---|---|
| DeepSeek-14B | 0.800 | 0.614 | 9,182 | 0.633 | 0.429 | 10,046 |
| Light-R1-14B-DS | 0.833 | 0.641 | 9,571 | 0.767 | 0.505 | 10,194 |
| LEAD-stage1 | 0.833 | 0.629 | 8,790 | 0.767 | 0.523 | 9,371 |
| LEAD-stage2 | 0.867 | 0.650 | 8,267 | 0.767 | 0.539 | 8,668 |
14k token budget 下,LEAD-stage2 在 AIME24 拿到 0.867 / 0.650,AIME25 拿到 0.767 / 0.539——四个数据点里三个最佳,剩下一个并列最佳。最关键的是,输出平均长度比 Light-R1 短了 1300 多 token。
我对这个对比有点疑问要点出来:Light-R1 用的是 cosine 长度奖励,预算上限不同,curriculum 的细节也不一样。把"少 1300 token 还涨点"完全归功于 LEAD 三件套有点武断——SFT 数据集和 stage 1+2 的 curriculum 对最终结果的贡献,论文没单独消融。这是它实验上一个明显的不足。
但即便剔除这个不确定性,LEAD-stage1 只跑了 100 步、24 小时(8 张 H20),就在 AIME25 Pass@1 上超过了 Light-R1(0.523 vs 0.505)——这个数据是真的能打。性价比高。
我的判断
它真正解决了什么
梯度稠密化:这是我读完最大的收获。GRPO 的二元 reward + 一组要么全对要么全错的现实,造成了大量"无效组"。LEAD 通过引入连续的长度奖励,让每一组都有可用的 advantage 信号。这事很多论文不点破,但工程上特别关键。
难度自适应权重:logistic 这种朴素到不能再朴素的设计居然 work,是因为它做对了一件事——把权重的拐点放在 \(\rho_0 = 0.75\) 附近。这个值是经验选的(论文也承认没做超参搜索),但选得很巧:模型本来已经能 75% 答对的题,确实没必要再下重注;剩下那部分才是真正的 learning frontier。
长度的 z-score 归一化:这个用相对而非绝对长度的思路,比 Kimi/L1 的固定阈值优雅很多。你不需要预先知道每道题"应该"多长。
它没解决什么
partial credit:数学题答错就是 -1,但很多时候模型其实做对了 80% 步骤,只是最后一步算错。这种部分正确的信号 LEAD 拿不到。论文的局限性章节自己也承认了这点。
领域泛化:所有实验都在 AIME 上做。难度感知权重在数学这种 0/1 评判很清楚的任务上 work,但换到 QA、coding、open-ended generation 上要不要重新设计 \(\rho_q\) 和 \(w\),论文没回答。附录里给了一点 coding 的实验但篇幅很短。
超参鲁棒性:\(A=0.4, B=1.5, \rho_0=0.75, k=10\) 这一套数到底有多挑选?\(\alpha=0.05\) 的长度衰减系数对不同模型大小是不是要重调?这些都没系统消融——论文自己也坦承没做超参搜索("compute 不够")。
和 Light-R1 的对比不够干净:用了不同的 SFT 数据、不同的 curriculum,最后把全部增益归到 reward 设计上,有点把工程整合的功劳算到 LEAD 头上的嫌疑。
工程启发
如果你也在做 RL fine-tuning,我觉得这篇有几个非常值得借鉴的点:
-
二元 reward 的稀疏性问题,可以用相对长度变成连续 reward 来缓解。这个 trick 几乎零成本,效果立竿见影。
-
难度感知的权重,logistic 就够了,不用上 PRM 或 process reward。LEAD 的整个 advantage 改动加起来不到 20 行代码,但效果挺顽强。
-
显式负分配合 0.5 阈值的解释,让 reward shaping 不再是黑盒——你能理性推断每个超参的物理含义。这种"reward 设计的可解释性"在工业界 fine-tuning 里特别有用。
-
如果你的训练数据是混合难度的,强烈建议加一个简单的 difficulty-aware 权重。哪怕是一个粗糙的 if-else(\(\rho_q \lt 0.3\) 加权 1.5x,否则 1x),也比不加好。
跟同期工作的位置
这篇跟 DeepSeek-R1(GRPO 原版)、Light-R1(cosine 长度奖励 + SFT curriculum)、Kimi(min-max 长度归一)、L1(控制思考时长)、S-GRPO(早退)这些工作处在同一条主线上——都是在给 GRPO 的 reward 信号做精细化改造。
LEAD 的独特之处是把"reward 信号稠密化"和"难度感知权重"显式分开做。其他论文要么只搞长度,要么只搞 curriculum,要么只搞 RM。LEAD 把三件事拼成一个简洁的方案,而且配 ablation 把每件事的贡献拆得很清楚。这一点的写作完成度比很多同类工作都高。
但要说"底层突破",我不会这么定义。三个组件单看都不算原创——长度奖励、负分、难度权重,文献里都有先例。LEAD 的贡献更像是一个精心调过的工程整合,加上对每一块工作机制的清晰解释。这种论文不给你"我发明了新世界"的震撼,但读完会让你觉得"这套配方可以直接抄进我的项目"。
收尾
如果你正在用 GRPO 或者它的变体训自己的推理模型,又面临"模型越练越啰嗦、难题死活上不去、简单题反复刷分"这几个症状中的至少一个,那这篇的方法可以直接拿来用——三件套每个都是几十行代码的改动,没有额外采样开销,也不需要训练 reward model。
我个人最看好的还是难度感知 advantage reweighting 那一块。它是这篇里最容易迁移到非数学领域的 idea——只要你能定义一个组内的"经验正确率"或者类似的指标,logistic 那一套就能套上去。
唯一要警惕的是不要被那个 SOTA 数字过度吸引。LEAD 的 stage 2 训练里塞了高质量 SFT 数据、两阶段 curriculum、n-gram 重复惩罚一堆东西,从 baseline 到 0.539 AIME25 Pass@1 这条路上,到底是哪一段贡献最大,论文没给你完全干净的答案。
但这并不影响它作为一篇好的工程论文——读完知道为什么 work、怎么 work、能不能套到自己项目上。这就够了。
参考资料
- 论文 PDF:arXiv:2504.09696v2
- 代码:github.com/aeroplanepaper/GRPO-LEAD
- 相关工作 GRPO(DeepSeek-R1):arXiv:2501.12948
- 相关工作 Light-R1:Wen et al., 2025
- 相关工作 L1(控制思考时长):Aggarwal & Welleck, 2025
- 训练框架 VERL:Sheng et al., 2024
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我