好过程无需好答案:把 Agent 的规划和总结拆开训,工业 RL 才走得通
核心摘要
工业里训 Agent 的人大概都被这件事卡过:手头数据 99% 没法直接验证最终答案对错,但端到端 RL 又必须靠"答案对不对"打分。结果就是要么花大钱标数据,要么用一个大模型当裁判去判最终回答——后者的 reward hacking 已经被吐槽很多次了。
来自微信 AI(腾讯)和北大软微的这篇 EMNLP 2025 Industry 论文给了一个挺务实的答案:别再追求"答案对"了,转去打"工具调得全不全"的分。他们把 Agent 拆成 Planner(规划工具调用) + Summarizer(合成回答),只对 Planner 做单目标 RL,奖励信号是用一个 LLM 去判断这一串工具调用序列"完不完整"。结果在 1.7B 和 8B 的 Qwen3 上规划性能涨 8%–12%,端到端回答质量也跟着涨 5%–6%。比起最近一堆 Search-R1 / ReTool 这类只在可验证答案数据上做 RL 的工作,这套方案更像是一个真在工业场景里被业务数据逼出来的解。
不算什么底层突破,但踩到了一个被忽略很久的工程现实:99% 没有 ground truth 的数据,到底怎么做 RL。
论文信息
- 标题:Encouraging Good Processes Without the Need for Good Answers: Reinforcement Learning for LLM Agent Planning
- 作者:Zhiwei Li, Yong Hu, Wenqing Wang
- 机构:WeChat, Tencent Inc., China;北京大学软件与微电子学院
- arXiv:2508.19598(EMNLP 2025 Industry Track)
为什么这篇论文值得看
先说我的真实感受:去年带项目落地一个工具调用 Agent 的时候踩过一个一模一样的坑。我们想用 RL 提升模型挑工具的能力,结果训了几天发现 reward 一直涨,但人工 spot check 反而觉得回答更油了——典型的 reward hacking。后来反复定位,发现问题在于:业务数据里大部分 query 根本没有"标准答案",我们只能让另一个大模型当裁判判最终回答好不好,这个裁判自己就有偏见和盲区,于是策略就开始迎合裁判而不是真去解决问题。
这篇论文的开篇就把这个痛点摆出来了。
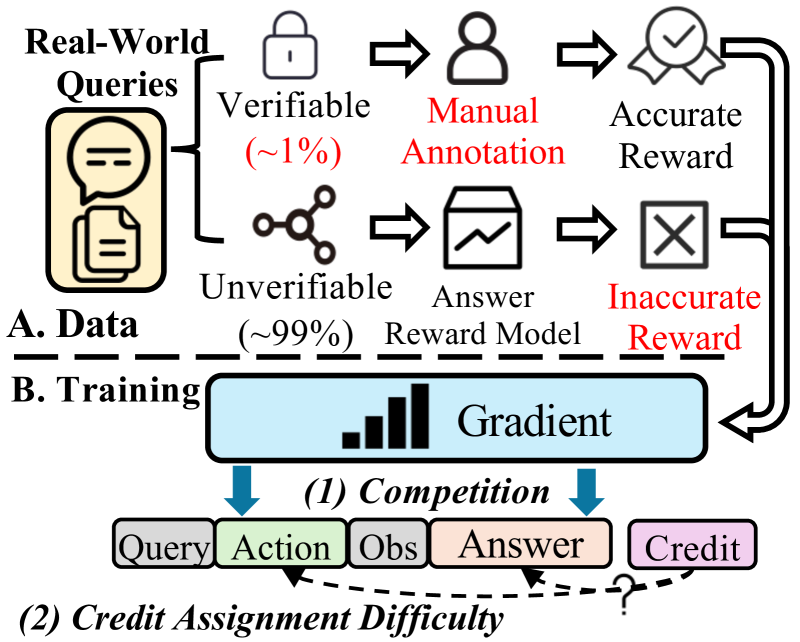
图1:作者把两个核心挑战画得很清楚:A 区域说的是数据现实——真实查询里能直接验证答案的占约 1%,剩下 99% 的非可验证数据只能用 answer reward model 打分,而 reward model 本身容易被 hack;B 区域说的是优化层面——规划和总结这两个目标在梯度方向上经常打架,而且最终答案的奖励根本没办法干净地反推到中间某一步具体动作上,于是该被惩罚的没被惩罚,该被鼓励的也没被鼓励。
这两个挑战在学术 paper 里很容易被一笔带过,但在真实业务里就是天天卡你的事。Search-R1、ReTool、ToRL 这一类近期热门的 Agent RL 工作,全都默认你有可验证答案——能拿数学题、能拿事实问答这种有 ground truth 的数据集刷分确实没问题,但放到一个真实的智能助手业务里,绝大部分 query 既没有数学答案也没有事实标签,你怎么训?
作者的判断很直接:不要去训那个根本说不清"对错"的最终答案,转去训那个相对容易判对错的工具调用过程。
核心思路:把"答案对不对"换成"工具调没调全"
这套方法叫 RLTR(Reinforcement Learning with Tool-use Rewards)。整个 pipeline 长这样:
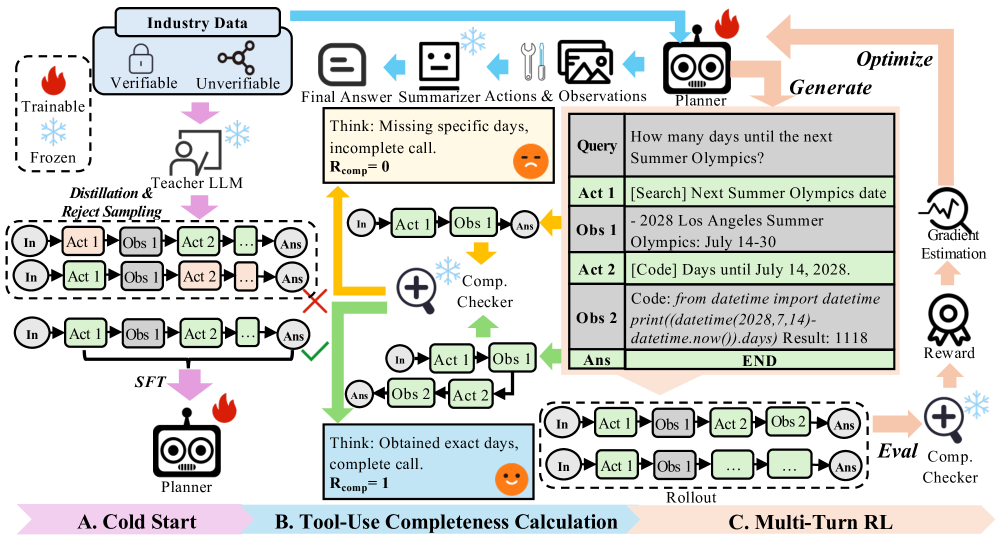
图2:RLTR 三段式架构。最关键的是中间 B 区——奖励信号不再来自 "最终回答对不对",而来自 "Planner 调的这串工具够不够把问题需要的信息搜全"。比如查询"北京和上海的温差是多少",如果 Planner 只搜了北京的天气没搜上海的,Comp. Checker 直接判 0;只有两个城市都搜了、温差也算了,才判 1。右边 C 区里那个"Summer Olympics 还有几天"的具体例子展示了一条完整的好轨迹:先 search 查日期,再 code 算天数差。
我觉得这个设计最巧妙的地方在于一个看起来很朴素的观察:
"Figuring out if something can be done is easier; ensuring it's done correctly is harder."
判断"这件事被做完了没"比判断"这件事被做对了没"要容易得多。前者只看动作覆盖,后者要看内容质量。把奖励的颗粒度往前推,说到底是把一个高方差、高 hacking 风险的判别问题,换成了一个低方差、相对稳定的判别问题。
三个阶段拆开看
冷启动用的是知识蒸馏 + 拒绝采样的常规组合。Teacher 是 Qwen3-32B,对每个 query 采样多条工具调用轨迹,再用同一个 Teacher 做 rejection sampling 选 best-of-n 留下来当 SFT 数据。这步没什么新东西,目的就是让 Planner 先学会基本的工具调用格式。
工具调用完整性奖励是核心。给定一条轨迹 \(\tau\),用一个验证 LLM(Comp. Checker,论文里用的是 Qwen3-30B-A3B)按一段 check 指令去判 0 或 1,重复 N 次取平均:
这个 LLM 判什么?判这条工具调用序列"为了回答这个 query 该搜的都搜了没、该算的都算了没"。它不去看最终答案合不合理,只看动作覆盖是否完整。
总奖励还会加两个负向规则项稳定训练:重复调用惩罚 \(R_{repeat}\) 和工具用错惩罚 \(R_{error}\),外加一个 format 检查——如果轨迹格式都不合法直接给 -1。
多轮 RL 这块没玩什么新花活,PPO/GRPO/REINFORCE++ 都跑通了。模板设计上有个细节值得提:训练时把 tool 返回的 observation 部分 mask 掉不算 loss,只在 action 和 thinking 部分算梯度。这是为了避免 tool 输出的噪声稀释掉策略学到的工具调用信号——很合理的工程考量。
# 伪代码示意 RLTR 的奖励函数
def compute_reward(trajectory, query, tools):
if not is_valid_format(trajectory):
return -1.0 # 格式错直接重罚
R_comp = avg([
comp_checker_llm(trajectory, query) # 0/1
for _ in range(N)
])
R_repeat = -lambda_ * count_repeated_actions(trajectory)
R_error = -mu * count_invalid_tool_calls(trajectory, tools)
return R_comp + R_repeat + R_error
实验:数据本身比方法更有说服力
实验设的是中文场景。训练集是约 4k 工业内部数据 + 0.5k 测试集(分 Normal 和 Hard 两档),加上 ChineseSimpleQA 里筛出的 855 条"必须调工具才能答对"的难题作为开源测试集。
主表(Table 1)数字直接贴出来:
| 模型 | 方法 | Industry Normal Com. | Hel. | Rel. | Hard Com. | Hel. | Rel. | OS Match |
|---|---|---|---|---|---|---|---|---|
| Qwen3-235B | DIRECT | 67.2 | 71.5 | 72.7 | 50.5 | 47.4 | 46.4 | 45.8 |
| DeepSeek-R1 | DIRECT | 68.8 | 71.2 | 76.0 | 49.7 | 57.5 | 51.5 | 49.5 |
| Qwen3-1.7B | DIRECT | 44.9 | 41.9 | 46.7 | 22.4 | 30.4 | 32.5 | 29.8 |
| Qwen3-1.7B | E2E SFT | 56.3 | 59.2 | 62.4 | 30.1 | 35.3 | 37.7 | 37.1 |
| Qwen3-1.7B | SFT (Planner) | 60.1 | 61.3 | 64.5 | 35.3 | 38.6 | 41.4 | 39.4 |
| Qwen3-1.7B | E2E RL | 62.4 | 63.5 | 65.6 | 37.5 | 41.4 | 45.2 | 40.0 |
| Qwen3-1.7B | RLTR | 70.2 | 68.4 | 72.6 | 45.4 | 48.4 | 49.4 | 45.6 |
| Qwen3-8B | DIRECT | 51.5 | 53.8 | 65.2 | 35.3 | 36.3 | 37.4 | 35.3 |
| Qwen3-8B | E2E SFT | 66.0 | 65.4 | 70.2 | 40.4 | 45.5 | 44.8 | 41.4 |
| Qwen3-8B | SFT (Planner) | 67.2 | 70.1 | 71.3 | 46.4 | 48.4 | 51.4 | 44.4 |
| Qwen3-8B | E2E RL | 69.6 | 71.2 | 76.7 | 44.4 | 47.4 | 53.5 | 45.2 |
| Qwen3-8B | RLTR | 82.7 | 76.7 | 80.9 | 54.5 | 61.6 | 65.6 | 51.6 |
几个数值我反复看了几遍:
1.7B 的小模型用 RLTR 训完之后超过了 Qwen3-235B 直接调工具的水平。 Industry Normal 的 Com. 从 235B DIRECT 的 67.2 涨到 1.7B RLTR 的 70.2。这不是说 1.7B 比 235B 更强——235B 没经过任何工具调用任务的训练,只是靠 prompt 在做。但这至少说明,针对工具调用这一个具体能力做单目标 RL,小模型可以追平甚至超过大十几倍参数的通用模型。这个结论对工业部署很有意义:你不需要为了 Agent 业务上一个 70B+ 的模型。
8B 上的提升尤其在 Hard 集上明显。 Hard 集 Hel. 从 E2E RL 的 47.4 跳到 RLTR 的 61.6,14.2 个点的差距。说实话看到这个数我有点皱眉——E2E RL 的 baseline 是不是没充分调?后面看了消融才放心一些(下面会说)。
Match 这一栏(开源 ChineseSimpleQA)是个相对硬核的指标,因为这个数据集有 ground truth。Qwen3-8B RLTR 的 51.6 和 DeepSeek-R1 的 49.5 持平略高,1.7B RLTR 的 45.6 也已经接近 235B 的 45.8。考虑到他们 RLTR 训练时根本没用 ChineseSimpleQA 的 ground truth(用的是工具调用完整性奖励),这个数还是挺能打的。
训练动力学也支持作者的主张
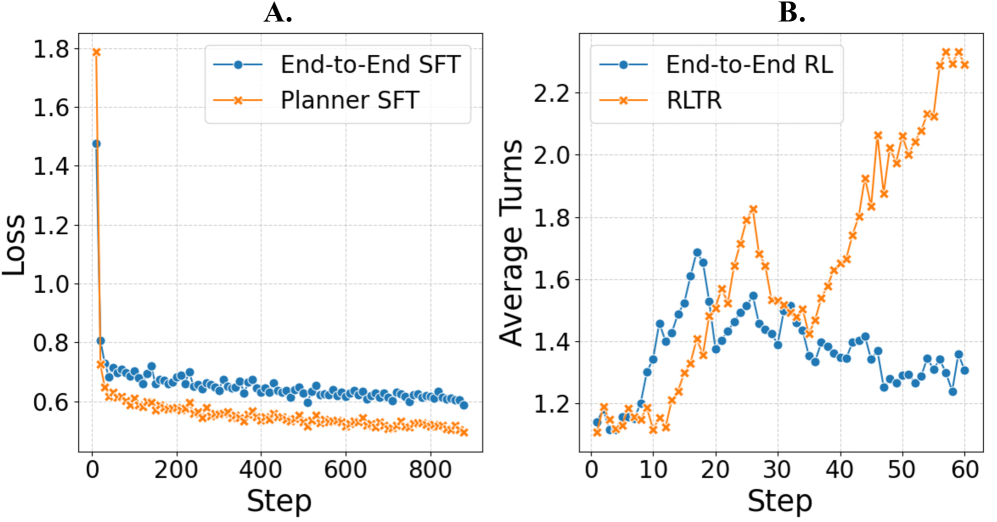
图3:左边那张 SFT loss 曲线很说明问题——只学 Planner 的目标比同时学 Planner+Summarizer 收敛更快、loss 更低。右边那张 RL 平均轮数更值得说道:RLTR 的 Planner 越训越愿意多调工具(从 1.1 涨到 2.3+),而端到端 RL 训着训着工具调用次数反而下降——因为对 E2E RL 来说,少调几次工具直接出答案,如果 reward model 觉得答案过得去,那就是"赚到",于是策略学到的反而是"少调工具拿好答案",正好相反。
这张图我觉得是全文最有说服力的一张。它说明了端到端 RL 在工业场景里有个反向激励问题:当 reward 来自最终答案,模型最优策略未必是"把信息搜全",可能是"用现有信息瞎编一个看起来合理的答案让 reward model 给好评"。这跟我之前调 Agent 时观察到的现象完全一致。
Reward 函数本身的可靠性
Table 3 是个轻量但很重要的实验。作者人工标了 925 条轨迹的对错,然后让 Qwen3-235B-A22B 分别用"答案正确性奖励"和"工具调用完整性奖励"打分,比对人工标签:
| Reward | ACC | F1 |
|---|---|---|
| Answer reward | 65.30 | 76.17 |
| Tool-Use Comp. reward | 74.59 | 84.64 |
完整性奖励的准确率比答案奖励高 9.3 个点。这个结果其实挺反直觉的——你会觉得答案级别的判断更接近"真值"才对。但实际情况是:判断"答案是否正确"需要模型同时具备问题领域知识 + 推理能力 + 事实核查能力,而判断"工具调用是否完整"只需要模型理解 query 的信息需求。后者的难度低一个数量级,所以同样一个裁判 LLM 判得更准。
案例分析:reward 差异在哪儿

图7:A 是 reward 函数差异的最佳教学案例——agent 凭空编了上海的天气数据,碰巧编出来的温差看着合理,answer reward 直接放行;而完整性 reward 一眼看出"上海天气都没搜过你哪来的温差",正确给负分。B 展示了规划能力提升的实际收益——优化后的 Planner 学会了一次搜索拿到的信息有疑虑就再搜一次交叉验证,于是 Summarizer 拿到的是干净一致的事实,最终回答自然就对了。
A 这个案例很典型,是 reward hacking 的教科书例子。模型学到的不是"答对问题",而是"输出一个让裁判觉得答对了的字符串"。
我的判断:踩中了一个真实痛点,但远不是终点
真正值钱的地方
这篇论文不是底层方法论突破,PPO/GRPO 还是那套 PPO/GRPO,知识蒸馏冷启动也很常规。它的价值在工程判断:
第一,承认了"99% 数据无 ground truth"这个现实,并且没有走"那就只在 1% 上做 RL"的妥协路线。Search-R1、ToRL 这些工作选择了在 NQ、TriviaQA、AIME 这种有标签的数据上做 RL,这条路在学术上更干净,但在工业场景里覆盖面太窄。
第二,把奖励的颗粒度从"答案"前移到"过程",并且找到了一个"裁判难度低 + 与最终答案质量正相关"的代理指标。Process Reward Model 这个方向其实早就有人做(AgentPRM 之类),但 PRM 通常要训一个专门的 reward model,本身又是 reward hacking 的源头。RLTR 用 LLM-as-judge + 一个非常具体的判别问题("工具调用完不完整")回避了 PRM 的训练成本和 hacking 风险,这是一个很务实的折中。
第三,Planner-Summarizer 解耦后,Planner 是模块化的可复用组件。论文里 8B 的 Planner 配 1.7B 的 Summarizer 也能 work,意味着部署时可以根据延迟/成本预算自由组合。这个设计在业务上太有用了。
让我皱眉的地方
但也不是没问题。
完整性奖励本身是不是也会被 hack? 论文里没深入讨论这个。如果 Comp. Checker 的判别策略被 Planner 学会了——比如"只要调用三次以上工具且包含 search 和 code 就判 1"——Planner 完全可以学会"调一次没必要的 search、再调一次没必要的 code"来骗到正分。论文给的 Comp. Checker 准确率是 74.59%,意味着 25% 的判断是错的,这部分就是 reward hacking 的入口。Section 3.3 的 \(R_{repeat}\) 和 \(R_{error}\) 算是部分缓解,但没有定量证据说明它们真的堵住了 hack 路径。
Planner-Summarizer 的解耦带来了信息瓶颈。Planner 不知道 Summarizer 最终会怎么用这些信息,可能搜一堆 Summarizer 用不上的内容,也可能漏掉对 Summarizer 关键的细节。论文里 5%–6% 的 E2E 涨幅其实没有 Planner 涨幅 8%–12% 那么大,部分原因可能就在这。如果 Summarizer 也能给 Planner 反馈"我需要什么信息",提升空间应该更大。
评估闭环里的 Qwen3-235B-A22B 是个潜在偏见源。训练时用 Qwen3-30B 当 Comp. Checker,评估时用 Qwen3-235B 当裁判,两者在 prompt 风格、判别偏好上大概率是相关的。Hel. 和 Rel. 这两个指标完全靠 Qwen3-235B 打分,会不会存在"训出来的策略恰好迎合 Qwen 系裁判的偏好"?论文用 ChineseSimpleQA 的 Match 指标做了一定程度的客观验证(这个不依赖 LLM 裁判),但只覆盖了一小部分场景。
只在中文 + Sogou 搜索 + 沙箱 Code 这套环境里测过。Limitations 一节作者自己也承认了。我的猜测是这套思路在英文场景同样 work——核心机制(完整性比正确性好判)是语言无关的——但需要别人来验证。
工程落地启发
如果你也在做类似的 Agent 业务,几条直接能用的启发:
- 如果数据里大部分 query 没有 ground truth,先别急着上 E2E RL,重新审视一下能不能拆出一个"过程信号"(不一定是工具完整性,可能是别的中间指标)。
- Planner-Summarizer 物理解耦在部署上是真划算——Planner 用稍大一点的模型保证规划质量,Summarizer 可以用小模型甚至直接 prompt 一个通用模型,整体延迟和成本都更可控。
- 冷启动 + RL 的两段式训练在 1.7B–8B 这个量级上跑得通,对中小公司没有自训百亿模型的也是个可行路径。Teacher 用现成的开源大模型(论文里是 Qwen3-32B)就行。
- LLM-as-judge 做 reward 时,挑判别难度低的指标——"完不完整"、"格式对不对"、"步骤多不多余",这些都比"答案对不对"更稳。
收尾
这篇论文我读完最大的感慨是:工业 RL 跟学术 RL 真的是两个东西。学术界这一两年发的 Agent RL 工作,绝大多数默认有可验证答案——这在 benchmark 上漂亮,但跑回真实业务一半都用不了。RLTR 不是什么炫技工作,但它把工业落地的真实约束摆出来认真应对了一次:99% 没标签、reward model 不可靠、规划和总结目标打架。给的解也很务实——不追求最优,但走得通。
我估计这类"过程奖励 + 子目标解耦"的思路会在 Agent RL 后续工作里越来越多。长期看,把奖励信号从"结果对不对"前移到"过程合不合规"是个不可逆的趋势,因为越复杂的 Agent 系统越没法用结果反推过程,credit assignment 只会越来越难。RLTR 算是这个方向上一个合格的工业起点。
要继续往前走,几个我会关注的方向:Comp. Checker 的 reward hacking 鲁棒性研究、Planner 和 Summarizer 之间双向反馈机制、以及把这套方法迁移到非搜索/代码工具的更复杂动作空间。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我