把 RL Agent 直接扔进真实互联网:DeepResearcher 撕开了 RAG 训练的舒适区
去年下半年开始,"Deep Research"几乎是 Agent 圈最热的词。OpenAI 的 Deep Research、Gemini 的 Deep Research、xAI 的 DeeperSearch,三家闭源都吃到了产品红利,但训练细节一概不公开。开源社区跟着上车,弄出了 Search-R1、R1-Searcher、ReSearch 这一票工作——清一色都在做"RAG 环境里的 RL"。
意思是,给模型挂一个本地 Wikipedia 语料库,模型学着去检索,跑 RL 信号。
听起来挺合理。但有一个问题谁都不愿意正面回答:你训出来的这套东西,扔到真实互联网上还 work 吗?真实的 Google 返回结果是带广告的、是噪声大的、是同一个 query 今天返回明天就变了的,是要面对反爬虫的。本地 BM25 给你召回 Top-K Wikipedia chunk 的世界,跟真实 Web 中间的差距,到底是"工程实现细节",还是"训练根本就不是同一件事"?
这就是 DeepResearcher 这篇论文想撕开的口子。他们直接把 RL 训练扔进真实 Web 环境跑,第一次系统地证明了:在真实网页 + 真实搜索 API 上 scale RL,跟在 RAG 沙盒里 scale RL,根本不是一个东西。
核心摘要
DeepResearcher 是第一个端到端在真实 Web 搜索环境里、用 RL 训练 Deep Research Agent 的开源框架。痛点很直接——所有现有的开源 RAG-RL 方法(Search-R1、R1-Searcher、ReSearch)都基于一个隐藏假设:所有要找的信息都已经在本地语料里了。这个假设在真实研究场景里站不住脚,导致这些方法在跨域场景上的泛化能力被严重高估。
核心方案有四块:(1) 直接用 GRPO + 仅 outcome reward 做端到端 RL,不依赖 SFT 蒸馏人工先验;(2) 多智能体架构:主 reasoner 负责 think + search/browse 决策,独立的 browsing agent 负责从长网页里增量抽信息;(3) 50 节点分布式爬虫集群 + 7 天搜索缓存 + 重试 + masking observation 等一整套真实环境工程方案;(4) 用 pass@10 检测训练数据是否被记忆污染,强制让模型靠搜索而不是参数记忆解题。
效果:相比 prompt-engineered baseline 最多 +28.9 点 MBE,相比 RAG-RL baseline(如 R1-Searcher)最多 +7.2 点。在 OOD 测试集 Bamboogle 上达到 72.8 MBE,对比 R1-Searcher 的 65.6——这个差距才是这篇论文真正值钱的地方:因为 Bamboogle 里的问题刻意超出 Wikipedia 覆盖范围,本地 RAG 类方法的天花板暴露得特别清楚。
我的判断:这篇论文的方法部分没有开宗立派的算法创新——GRPO 是 DeepSeek 的、F1 reward 是常规配置。真正硬核的是工程:怎么在 4096 并发 rollout 的同时把真实 Web 当成稳定的 RL 环境用起来,这套东西做出来才是真本事。可以认为这是开源 Deep Research RL 训练的"baseline first principle paper"——后面所有人想做真实 Web 上的 Agent RL,多半都得回头读它。
论文信息
- 标题:DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
- 作者:Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, Pengfei Liu(其中 Dayuan Fu 与 Xiangkun Hu 为共同一作,Pengfei Liu 通讯)
- 机构:上海交通大学(SJTU)、SII、GAIR
- arXiv:2504.03160(v4)
- 代码:github.com/GAIR-NLP/DeepResearcher
一、为什么 RAG 沙盒训出来的 Agent 经不起真实世界?
先把场景对齐一下。
你想让一个 LLM 帮你回答"在 Congo 河入海口、非洲第七大国家的那个城市,每天产油多少桶?"这种问题。这是 Bamboogle 里的真实题目。要拆成几步:先查"非洲第七大国",再查"Congo 河入海口的城市",把两个交叉验证一下,再查那个城市的产油数据。
如果你有一个挂着 Wikipedia 的 RAG 系统,每一步都能召回 Top-10 chunk,整个流程相对干净——召回的内容是结构化的、是被精心策划过的、是无广告的。Search-R1 之类方法就是在这种环境里 scale 起来的。
但真实 Google 不长这样。
真实 Google 返回给你 10 条结果,第一条可能是个 SEO 内容农场,第二条是 Yahoo Answers 的过时信息,第三条是被 paywall 挡住的 NYT 文章,第四条才是 Wikipedia。你点进 Wikipedia 那一页,是 50KB 的长文档,前面三屏都是不相关的章节,要拉到中间才看到关键数据。
这两种环境,让模型学到的策略根本不一样。 RAG 模型学到的是"怎么 query 让 BM25 召回好",真实 Web 模型学到的是"怎么 query 让 Google rank 好 + 怎么判断哪个域名能信 + 怎么跳过广告 + 怎么在长文档里找到关键段落 + 信息冲突时怎么交叉验证"。
后者才是 Deep Research 在真实场景里需要的能力。
这件事情其实之前内部我们做 Agent 项目的时候就有体感——你在沙盒里训得再好,部署到真实环境照样翻车。但能把这个直觉系统地论证清楚、还把工程做出来的,DeepResearcher 是第一篇。

图 1:DeepResearcher 在 7 个数据集(4 个 in-domain + 3 个 OOD)上的 MBE 准确率全部第一。值得盯着看的是 Bamboogle——这个数据集刻意涉及 Wikipedia 之外的知识,DeepResearcher 比同样能上 Web 的 R1-Searcher 还高 7.2 点。
二、方法层面:架构其实不复杂,复杂的是真实环境怎么 hold 住
把 DeepResearcher 的算法和工程拆开看。
2.1 算法侧:GRPO + 只用 outcome reward
算法没有花活,用的是 DeepSeek-R1 那套 GRPO(Group Relative Policy Optimization)。给定一个 question \(x\),从旧策略采样 \(G\) 条 trajectory,用同组 trajectory 的 reward 互相做基线(不需要单独训 critic),然后优化下面这个目标:
reward 设计也极简:
格式不对(缺 tag、tool call 解析失败之类)直接给 -1 重罚;格式对,就用预测答案和 ground truth 之间的 word-level F1 作为 reward。
这里有个细节我得吐槽一下——用 F1 而不是 binary correctness 当 reward,存在隐性 reward hacking 的风险。模型可能学会"宁可答得啰嗦点,把可能的答案都涵盖进去,赌 F1 高一些"。论文自己也承认了这点,说未来对长答案场景需要更复杂的 reward 机制。这是个值得在工程落地时盯着的口子。
还有一个关键的工程细节:masking observation。tool 返回的搜索结果、网页内容这些 token 是"环境观察",不是模型自己生成的。如果把这些 token 也算进 RL loss,模型就会被自己看到的搜索噪声反向训练。所以 DeepResearcher 把这部分 mask 掉,只在模型自己生成的 think/search/browse/answer 部分回传梯度。
这个细节看着不起眼,但漏了就训不动。
2.2 架构:主 Agent + Browsing Agent 的分工
整体架构是个双 Agent 设计:
- 主 Agent(DeepResearcher 本体):负责 think → 决定调用 search 还是 browse → 看到信息后继续 think → 最终 answer
- Browsing Agent:单独负责把长网页啃成有用信息
为什么要拆?因为一个真实网页很可能 50KB+,全部塞进主 Agent 的 context 里,10 轮 tool call 后 context 就爆炸了。Browsing Agent 拿到一个 URL 后,按段落顺序读(模拟人浏览的方式),维护一个短期 memory,每读完一段判断"还要不要继续读下一段"。如果前几段都是 SEO 垃圾内容,直接早停,不浪费 token。
这套设计其实很像人在搜资料:先看摘要,不行就深入第一段,再不行就放弃这个 URL 换下一个。
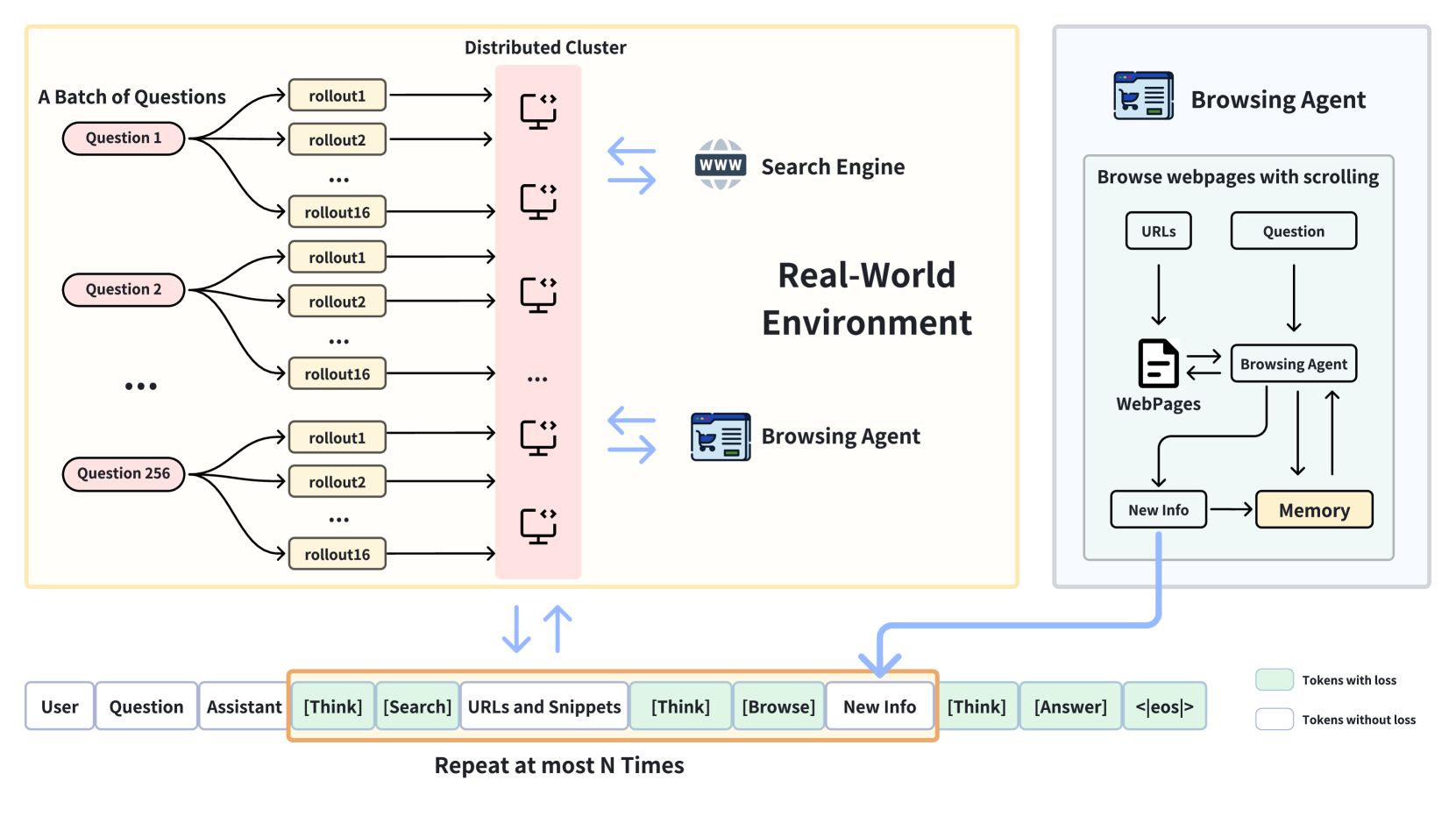
图 3:核心架构图。绿色 token 是参与 loss 计算的(模型自己生成的 think/search/browse/answer),白色 token 是 mask 掉的(环境返回的搜索结果、网页内容)。一次 rollout 可以最多 N 轮 tool call,期间 Browsing Agent 作为子模块独立工作。
注意右下角的图例——绿色 token with loss、白色 token without loss——这就是前面提到的 observation masking 的可视化。
2.3 工程:撑住真实 Web 环境是真功夫
这里才是 DeepResearcher 比较扎实的部分。任何一个做过爬虫的人都懂,真实 Web 是个充满妖魔鬼怪的世界。
挑战 I:高并发。一次 GRPO step 要 256 个 question × 16 个 rollout = 4096 个并发的 trajectory,每个 trajectory 又会发起多次 search + 多次 browse。瞬时打到搜索 API 和爬虫上的请求量是巨大的。
解法是搭了 50 节点的分布式 CPU 服务器集群,专门 handle tool 请求。每个 node 分担一部分搜索 + 爬虫 + 内容处理任务。
挑战 II:反爬 + API 限流。Google Search API 本身有 200 QPS 之类的限制,目标网页有反爬机制(返回 403、返回乱码、超时不响应)。解法是两条:
- 健壮的重试机制 + 异常处理
- 7 天的搜索缓存:相同 query 在 7 天内直接走 cache。这一招既降成本又稳定 reward 信号——同一个 query 短时间内 Google 返回结果不会差太多。
挑战 III 就是上面说的 Browsing Agent 分页读取策略,避免长网页吃掉 context。
这套东西做下来,真实 Web 才能被当成 RL 环境稳定地用。如果换成是我自己做这个事,光这个工程量就够喝一壶——这部分论文里写得比较白描,但每一条都是真实踩过的坑。
三、训练数据:怎么保证模型不是在背答案
这是论文里我个人觉得思路特别对的地方。
3.1 选数据集
DeepResearcher 没有自己造训练集,而是直接用四个开源开放域 QA 数据集:
| 数据集 | 类型 | 用途 |
|---|---|---|
| NaturalQuestions (NQ) | 单跳 | 单文档可答 |
| TriviaQA (TQ) | 单跳 | 单文档可答 |
| HotpotQA | 多跳 | 跨文档推理 |
| 2WikiMultiHopQA | 多跳 | 跨文档推理 |
最终训练集 80,000 条,按 NQ:TQ:HotpotQA:2Wiki = 1:1:3:3 配比。75% 是多跳问题——因为 Deep Research 的本质就是多步信息整合,单跳问题练不出来这个能力。
3.2 关键的污染过滤:pass@10
这个步骤如果不做,整个 RL 训练就是个笑话。
为什么?这些 QA 数据集都是公开的,在大模型预训练语料里多多少少会出现过。如果你直接用这些数据训 RL,模型很可能根本不需要 search,靠参数记忆就能答对——你以为模型在学搜索,其实它只是在学怎么把背过的答案输出来。
DeepResearcher 的过滤策略很简单粗暴:对每一条候选 question,从基础模型采样 10 个回答,如果其中任何一个包含正确答案,就把这条 question 从训练集里踢掉。这就是 pass@10 污染检测。
剩下来的题目,是基础模型自己答不出来的题目。这才能保证 RL 信号真的在驱动模型学"怎么用搜索找答案",而不是"怎么把背过的答案吐出来"。
这个细节我看到的时候眼前一亮。之前我们做类似事情,这块的污染检测一直没做得这么彻底——结果就是训完发现榜上分数涨了,但部署到真实场景上一塌糊涂。pass@10 这个简单的 trick,应该成为所有 RAG/Search RL 训练的标配。
另外还有一层 low-quality question 过滤:用 DeepSeek-R1 自动判断,剔除时效性问题("现在 Apple 的 CEO 是谁"——答案会变)、主观题("哪个手机最好")、有害内容。
四、实验结果:数据漂亮,但要会看
4.1 Backbone 和 setup
底座模型是 Qwen2.5-7B-Instruct,用 verl 框架训。一个 step:
- 256 个 prompt
- 每个 prompt 16 个 rollout(用于 GRPO 组内基线估计)
- 每个 rollout 最多 10 轮 tool call
- mini-batch 4096
7B 这个尺寸其实挺克制的。证明这套训练范式不是只能在大模型上跑得通。
4.2 主实验:In-domain(表 1)
| Method | Env | NQ F1 / MBE | TQ F1 / MBE | HotpotQA F1 / MBE | 2Wiki F1 / MBE |
|---|---|---|---|---|---|
| Prompt-Based | |||||
| CoT | Local RAG | 19.8 / 32.0 | 45.6 / 48.2 | 24.4 / 27.9 | 26.4 / 27.3 |
| CoT + RAG | Local RAG | 42.0 / 59.6 | 68.9 / 75.8 | 37.1 / 43.8 | 24.4 / 24.8 |
| Search-o1* | Local RAG | 34.5 / 57.4 | 52.6 / 61.1 | 31.6 / 40.8 | 28.6 / 32.8 |
| Search-o1 | Web Search | 32.4 / 55.1 | 58.9 / 69.5 | 33.0 / 42.4 | 30.9 / 37.7 |
| Training-Based | |||||
| Search-r1-base | Local RAG | 45.4 / 60.0 | 71.9 / 76.2 | 55.9 / 63.0 | 44.6 / 47.9 |
| Search-r1-instruct | Local RAG | 33.1 / 49.6 | 44.7 / 49.2 | 45.7 / 52.5 | 43.4 / 48.8 |
| R1-Searcher | Web Search | 35.4 / 52.3 | 73.1 / 79.1 | 44.8 / 53.1 | 59.4 / 65.8 |
| DeepResearcher | Web Search | 39.6 / 61.9 | 78.4 / 85.0 | 52.8 / 64.3 | 59.7 / 66.6 |
几个值得停下来想一想的点:
MBE(GPT-4o-mini 当 judge)维度 DeepResearcher 全场第一。注意 MBE 是更靠谱的指标——因为短答案的 F1 经常受表述形式影响(同样的意思换个说法 F1 就掉),LLM-as-Judge 对语义等价更敏感。
但 F1 维度上 NQ 和 HotpotQA 输给了 Search-r1-base(39.6 vs 45.4,52.8 vs 55.9)。论文的解释是 Search-r1-base 跑在本地 Wikipedia RAG 环境,而 NQ/HotpotQA 的答案恰好都在 Wikipedia 里——这对 RAG 是个完美匹配的场景。DeepResearcher 要在整个互联网里找答案,本身就是 harder mode。
这个解释我觉得是站得住脚的。但作为读者要意识到:如果你的应用场景是一个边界很清楚的封闭知识库(比如公司内部文档库),那 Search-R1 这类方法可能反而比 DeepResearcher 更高效——杀鸡用牛刀的事情没必要。
4.3 OOD 实验:才是真正的看点(表 2)
| Method | Env | Musique F1 / MBE | Bamboogle F1 / MBE | PopQA F1 / MBE |
|---|---|---|---|---|
| CoT | Local RAG | 8.5 / 7.4 | 22.1 / 21.6 | 17.0 / 15.0 |
| CoT + RAG | Local RAG | 10.0 / 10.0 | 25.4 / 27.2 | 46.9 / 48.8 |
| Search-o1* | Local RAG | 16.8 / 21.3 | 35.8 / 38.4 | 36.9 / 42.4 |
| Search-o1 | Web Search | 14.7 / 19.7 | 46.6 / 53.6 | 38.3 / 43.4 |
| Search-r1-base | Local RAG | 26.7 / 27.5 | 56.5 / 57.6 | 43.2 / 47.0 |
| Search-r1-instruct | Local RAG | 26.5 / 28.3 | 45.0 / 47.2 | 43.0 / 44.5 |
| R1-Searcher | Web Search | 22.8 / 25.6 | 64.8 / 65.6 | 42.7 / 43.4 |
| DeepResearcher | Web Search | 27.1 / 29.3 | 71.0 / 72.8 | 48.5 / 52.7 |
Bamboogle 是这张表的灵魂。Bamboogle 的设计就是故意涉及 Wikipedia 之外的知识——比如某个产品的最新功能、某个非主流领域的细节。
看数字:
- Search-r1-base(本地 RAG):57.6 MBE
- R1-Searcher(虽然支持 Web 但训练时用的是 site:en.wikipedia.org 的 Wikipedia 子集):65.6 MBE
- DeepResearcher(真实 Web 训练):72.8 MBE
这 7.2 个点的差距,才是"在真实环境训"和"在 RAG 环境训"的真实 gap。
R1-Searcher 是个特别好的对照:它推理时也能上 Web,但训练时被框死在 Wikipedia 里。意思就是模型从来没在训练阶段见过"Web 上长什么样",部署到真实 Web 上就是水土不服。
这是这篇论文最值钱的实验数据,没有之一。 论文 Abstract 里那个"+28.9 vs prompt-based"看着唬人,但跟最弱的 baseline 比涨 28 个点没那么有信息量;真正能说明问题的就是这个 +7.2 vs R1-Searcher——同样能上 Web,差别就在训练环境真不真实。
4.4 训练动力学:还在涨,但代价是什么
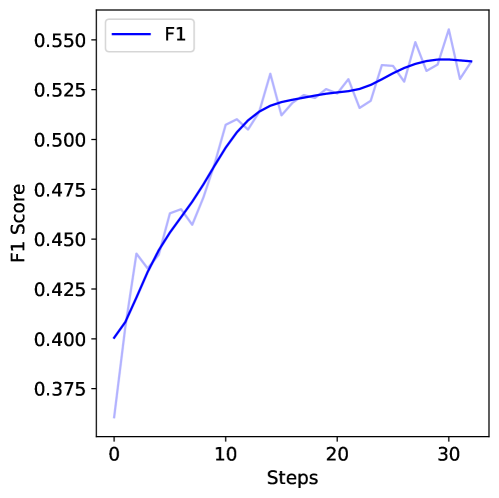
图 4(a):训练 F1 score 从 0.40 涨到约 0.55。30 步基本收敛——RL 阶段只用了 ~30 个训练 step(每个 step 4096 rollout),数据效率其实很高。
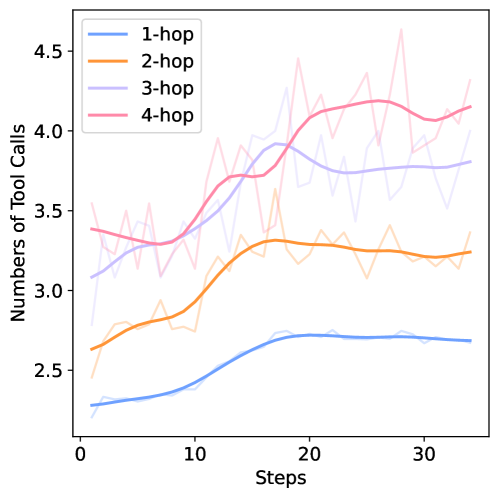
图 4(b):按 hop 数拆解的 tool call 次数。最有意思的是 4-hop 那条粉色线,到 step 34 还在持续上升——这说明对最难的问题,模型还在学着调用更多工具。论文也直接承认了这一点。但反过来想:训练是不是停得太早了?多训几个 step,难题上的表现会不会还有 headroom?
简单几条观察:
- F1 大概 30 step 收敛,RL 阶段非常便宜——这是真实环境训练成本能控制住的关键
- 难题上的工具调用次数还没饱和——4-hop 问题继续训应该还有红利
- response length 也在持续增长,模型在生成更长的 think、更细致的双重检查
五、四种 emergent 行为:论文里最讨人喜欢的部分
抛开数字看定性的部分。RL 训完之后,模型自发表现出四种行为,没有任何人工规则强制:
行为 I:Planning(多跳问题先做规划)
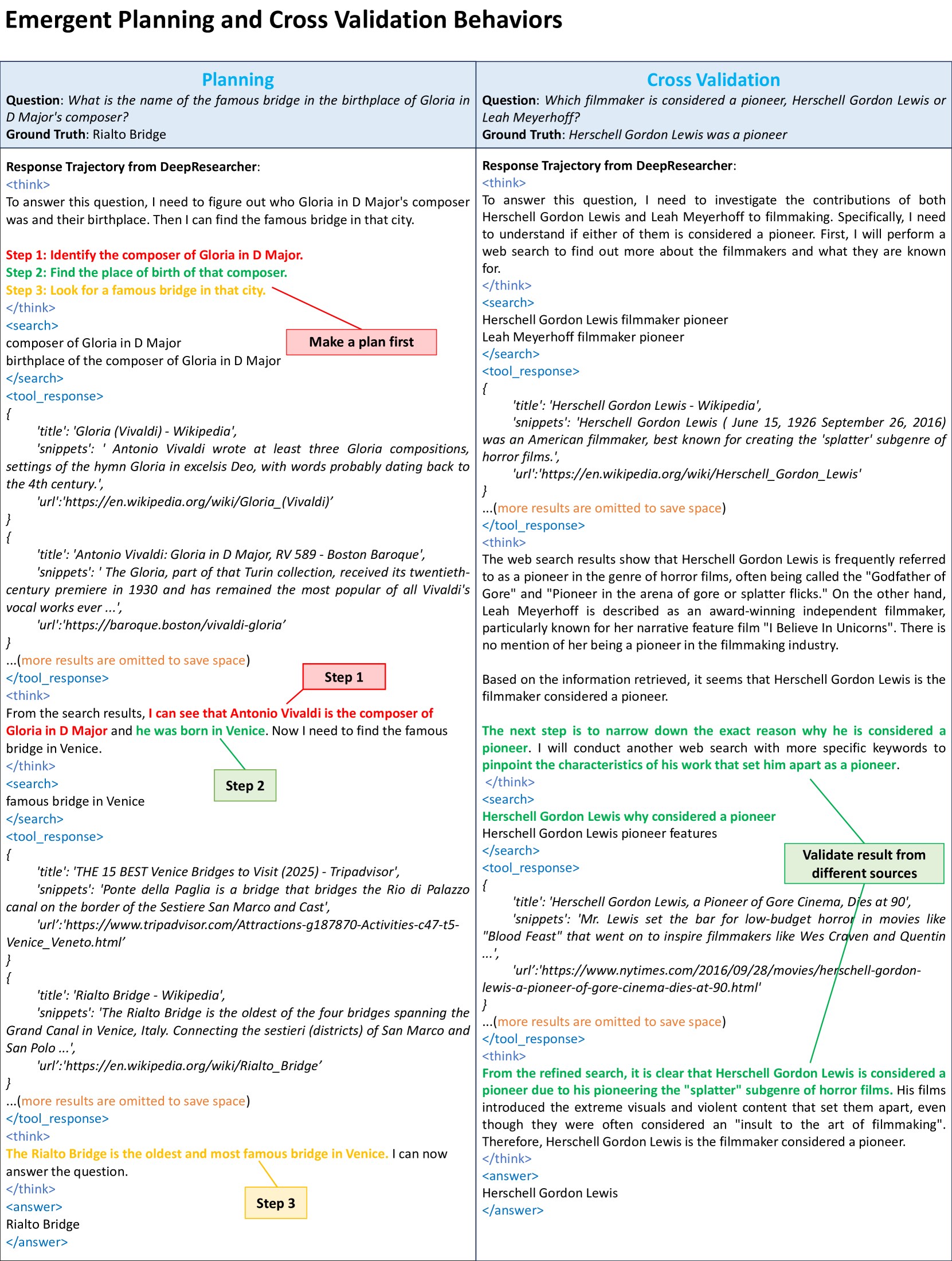
图 2:左侧 Planning 案例。问题是"D 大调《光荣颂》(Gloria in D Major)作曲家出生地最有名的桥是什么?"。DeepResearcher 在第一段 think 里就明确列出 3 步计划:(1) 找作曲家身份 → (2) 找出生地 → (3) 在出生地找著名桥。然后按这个计划逐步执行,最后给出 Rialto Bridge。右侧 Cross Validation 案例展示了模型对答案的"二次确认"。
划重点:这个 plan 不是 prompt 强制要求的,也不是 SFT 数据里教的,是 outcome reward 训出来的副产物。这跟 DeepSeek-R1 训出来的"aha moment"是同一类现象——简单 reward 信号 × 足够多的 trajectory,会自动浮现高级行为。
行为 II:Cross-validation(交叉验证)
图 2 右侧的例子。问题是"Herschell Gordon Lewis 和 Leah Meyerhoff 哪个是先驱?"。模型第一次搜索就发现答案是 Herschell Gordon Lewis,但它没有马上回答,而是又发起一次更聚焦的搜索"Herschell Gordon Lewis why considered a pioneer",确认其先驱身份的具体原因(splatter 恐怖电影流派的开创者),才给出最终答案。
这种"我已经有可能的答案了,但我再 double-check 一下"的行为,对 hallucination 的抑制是非常关键的。
行为 III:Reflection(反思 + 调整搜索方向)
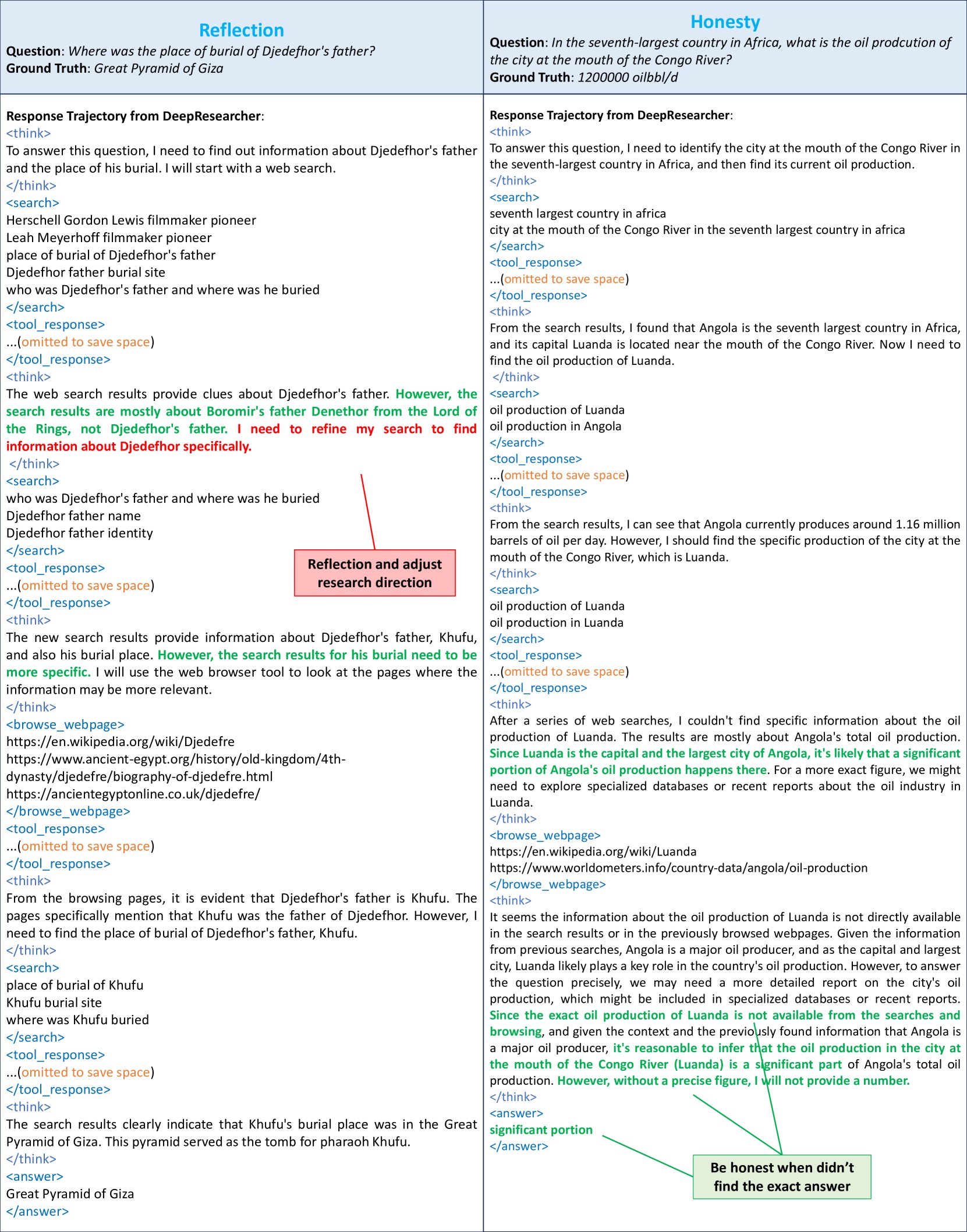
图 6:左侧 Reflection 案例展示了"搜索 → 发现召回不对 → 重新设计 query"的循环。问题是关于古埃及法老 Djedefhor 父亲的安葬地,第一次搜索召回了《指环王》里的 Denethor(名字相近导致语义混淆),模型识别出"This is Denethor from Lord of the Rings, not Djedefhor's father",主动调整 query 继续追查,最终找到 Khufu → Great Pyramid of Giza。右侧 Honesty 案例则更难得——找不到精确数字时模型说"significant portion"而不是瞎编一个数字。
这个行为的工程价值很高。真实场景里,搜索质量的不稳定性是常态——同样的 query 不同时间、不同搜索引擎返回结果差异很大。一个能在搜索结果偏离预期时主动调整 query 的 Agent,比一个"搜什么用什么"的 Agent 健壮得多。
行为 IV:Honesty(诚实承认局限)
图 6 右侧。问题是 Luanda(Congo 河入海口、非洲第七大国家安哥拉的首都)每天产油多少桶。多轮搜索后,DeepResearcher 找到了安哥拉全国 116 万桶/天的数据,但找不到 Luanda 单独城市的产量。换成普通 LLM,大概率会直接编一个数字。但 DeepResearcher 的输出是 "significant portion"——一个可以被人类理解的诚实答案。
论文自己也吐槽了一句:现在的 QA 评估指标其实不奖励这种 honest abstention 行为——你说 "significant portion" 在 F1 metric 下肯定不如瞎编一个看起来对的数字得分高。所以这种行为能在 outcome reward RL 里浮现出来,反而有点出乎意料。
我的猜测是:F1 reward 在"完全错"和"部分模糊但不错"之间,模糊的回答其实能拿到一些 partial credit(比如 "significant" 这个词在 ground truth 里也可能出现),而"瞎编一个具体数字"反而很容易完全 mismatch。所以模型学到了"宁可模糊,不可乱编"的策略。
这是 reward shaping 无心插柳的好结果。
六、批判性思考:这篇论文哪些地方需要打问号?
我尽量客观地列几条。
1. "首个"的定位需要小心
论文反复强调 "first comprehensive framework for end-to-end training of LLM-based deep research agents through scaling RL in real-world environments"。这个表述在学术上没问题——R1-Searcher 虽然推理时上 Web,但训练用的是 Wikipedia;Search-R1 是纯 RAG。但读者要明白,DeepResearcher 的方法本身(GRPO + outcome reward + multi-agent browsing)每一块都不是新的,新的是把这些组件 + 真实 Web 环境工程一整套打通。
这是工程整合层面的"首个",不是算法层面的"首个"。两者都很有价值,但价值类型不同。
2. F1 reward 的 reward hacking 风险
前面提过。F1 是 set-overlap 度量,模型可以通过"列出多个可能答案"来稳定提分。论文里没有看到对这种行为的检查。我建议如果有人复现这个工作,额外用一个二分类的 LLM-as-Judge reward 做对照,看看 F1 reward 训出来的模型答案是不是有变啰嗦的趋势。
3. 训练数据全是短答案 QA
NQ、TQ、HotpotQA、2Wiki 全部是短答案的事实型 QA。这种训练分布下,模型可能学到的是"快速找到一个 entity / number / phrase",而不是真正意义上的"深度研究"——后者通常需要长篇综合性的回答。
OpenAI 的 Deep Research 产品其实主要是面向长报告生成的,跟 DeepResearcher 的训练目标差异很大。DeepResearcher 这套方法能不能 generalize 到"写一份关于 XXX 的研究报告"这种任务,论文里没有验证。论文也提到说,长答案场景需要更复杂的 reward 机制,是 future work。
4. 50 节点分布式集群的复现门槛
这点论文不算问题,但对想 follow 这个工作的人是个现实门槛。4096 并发的真实 Web 请求 + 7 天 cache + 反爬重试机制,对大部分学术实验室来说不是想搭就能搭的。如果你要做类似工作,可能需要先想清楚怎么用更小的并发跑——比如降到 16/32 个 rollout per prompt,但训练成本会被拉高。
5. base model 的选择
用了 Qwen2.5-7B-Instruct 作为底座。换成 base model(不带 instruct)会怎么样?论文里没有 ablation。Search-R1 同时报告了 base 和 instruct 两个版本(Search-r1-base 和 Search-r1-instruct),结果差异巨大——base 版本反而更强。DeepResearcher 没有做这个对比有点遗憾。
七、跟同期工业界 / 闭源工作的对比
简单梳理一下相关工作的位置,方便你校准 DeepResearcher 在整个赛道里的坐标。
| 方法 | 训练算法 | 训练环境 | 推理环境 | 端到端? | 开源? |
|---|---|---|---|---|---|
| OpenAI Deep Research | RL(细节闭源) | 估计真实 Web | 真实 Web | 是 | 否 |
| Gemini Deep Research | 未公开 | 未公开 | 真实 Web | 未公开 | 否 |
| Search-o1 | 纯 prompt | / | RAG/Web 都行 | 否 | 是 |
| Search-R1 | PPO/GRPO | 本地 Wikipedia RAG | 本地 Wikipedia RAG | 是 | 是 |
| R1-Searcher | RL | site:wikipedia 限定的 Web | Web | 是 | 是 |
| DeepResearcher | GRPO | 真实 Web | 真实 Web | 是 | 是 |
DeepResearcher 在开源阵营里,是第一个真正把"训练环境 = 推理环境 = 真实 Web"做闭环的。这个定位非常清晰。
跟 OpenAI Deep Research 比,肯定还有差距——OpenAI 用的可能是更大的 base model(o-series),数据规模更大,可能还有 long-form reward 设计。但作为开源社区可复现的 baseline,DeepResearcher 的价值不可替代。
八、对工程实践的启发
如果你也在做类似的事情,几条可以借鉴的点:
1. 真实环境训练的 pass@10 污染检测。这个 trick 几乎零成本,但能保证你的 RL 信号确实在训"用工具找答案"而不是"背答案"。强烈推荐做任何 search/RAG RL 训练之前都加这一步。
2. observation masking 不能省。tool 返回的 token 必须 mask 掉,否则梯度方向会被搜索结果污染。这是 Agent RL 的基础设施级别的细节,做对了不一定加分,做错了直接训不动。
3. multi-agent browsing 的分工值得学。把"决策层"和"信息提取层"拆成两个 Agent,让长网页处理不污染主 Agent 的 context。这个模式在很多 long-context Agent 场景都能套用。
4. 7 天搜索缓存的妙用。除了降成本,它还稳定了 RL 训练的 reward 分布——同一个 query 训练期间返回结果不变,避免了"reward 被搜索结果随机性污染"。这个 insight 我之前没特别想过,但确实是真实环境 RL 必须要做的工程取舍。
5. backbone 不必很大。7B 模型 + 80k 数据 + 30 step RL 就训出了对标 R1-Searcher 的性能。真正的 deep research 能力主要来自"环境真实"和"reward 设计对",而不是模型 scale。
九、收尾:到底值不值得读?
我个人的答案是值得,但要带着正确的预期读。
这篇论文不是在算法层面给你一个新公式——它的算法部分(GRPO + outcome reward)几乎完全是 DeepSeek-R1 那套搬过来的。
这篇论文真正的贡献是把"真实 Web 上的 RL 训练"从一个口号变成了一个能跑、能复现、效果能打的开源系统。后面所有想在真实环境里做 Agent RL 训练的人——不管你做的是搜索、写代码、操作浏览器、还是什么其他 tool-use 场景——都需要先回答 DeepResearcher 提出的那些问题:
- 我的训练环境跟推理环境一致吗?还是在沙盒里训、在野外推?
- 我的训练数据有没有被基础模型记忆过?
- 我有没有 mask 掉 observation tokens?
- 我的 reward 设计有没有 reward hacking 的口子?
- 我的工程基础设施 hold 得住高并发的真实环境调用吗?
这五个问题,DeepResearcher 都给出了一个具体的答案。能不能用、好不好用、要不要用,是你自己的事;但绕过这五个问题去做 Agent RL,多半要踩坑。
如果你正在做 Deep Research、做 search-augmented LLM、做 tool-use RL 训练,这篇论文应该列在你的必读 list 里。如果你做的是封闭知识库的 RAG、是不需要联网的内部 Agent,那 Search-R1 那条线可能更适合你。
最后吐槽一句:这篇论文也没解决长篇研究报告生成这个真正困难的 deep research 场景,论文自己也承认了。短答案 QA 上的 7B + GRPO 跑通了,但要 scale 到"写一份 50 页关于某行业的市场分析报告"这种任务,reward 设计、训练数据、长 trajectory 的 credit assignment——每一块都还是开放问题。
OpenAI Deep Research 在做的事情,开源社区到 DeepResearcher 这一步只是吹响了集结号。真正的硬仗在后面。
参考资料
- DeepResearcher 论文:https://arxiv.org/abs/2504.03160
- DeepResearcher 代码:https://github.com/GAIR-NLP/DeepResearcher
- Search-R1(RAG-RL 对照工作):arXiv 2503.09516
- R1-Searcher(Wikipedia 限定 Web):arXiv 2503.05592
- DeepSeek-R1(GRPO 算法源头):arXiv 2501.12948
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我