决策和执行拆开训:一篇把 Agentic RAG 写成 MDP、再用剪枝把数据造快 6 倍的工业界论文
核心摘要
Agentic RAG 流行起来之后,很多人跟风上 outcome RL——整条推理链跑完才看见一个对错题,credit 分配糊成一团,探索又贵又慢。DecEx-RAG 的路子是:把一次问答里的「要不要停、要不要搜、子问题怎么写」明确拆成 Decision 和 Execution 两层,用搜索树 + rollout 过程奖励做细粒度监督;顶层再用剪枝把扩展复杂度压住,造数据时间大概降到原来的 1/6,质量却不掉。作者在六个开放域 QA 上报告相对基线约 6.2% 的平均绝对提升(摘要口径),正文里相对 Search-R1 还给出约 6.3% 的对比叙述。整体更像「把 PRM/树搜索思想塞进工业 RAG 管线」的扎实拼盘,而不是某一层的数学突破——但对要落地训练管线的人,可读性和可复制性都不错。
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | DecEx-RAG: Boosting Agentic Retrieval-Augmented Generation with Decision and Execution Optimization via Process Supervision |
| arXiv | 2510.05691(v1,2025-10-07) |
| 会议 | EMNLP 2025 Industry Track(Anthology:2025.emnlp-industry.99) |
| 作者 | Yongqi Leng, Yikun Lei, Xikai Liu, Meizhi Zhong, Bojian Xiong, Yurong Zhang, Yan Gao, Yi Wu, Yao Hu, Deyi Xiong(通讯作者 Deyi Xiong) |
| 机构 | \(^{1}\) TJUNLP Lab, College of Intelligence and Computing, Tianjin University, Tianjin, China;\(^{2}\) Xiaohongshu Inc. |
| 代码 | github.com/sdsxdxl/DecEx-RAG |
官方摘要里的标题写的是 Agentic Retrieval-Augmented Generation,与口语里的「Agentic RAG」同指一类设定,下文沿用论文缩写。
动机: outcome RL 训检索智能体,哪里让人难受?
做过类似系统的人多半遇到过三件事:模型要把整条轨迹生成完才能拿稀疏奖励,样本效率难看;全局对错信号难以告诉模型「到底是检索决策错了,还是子问题写坏了」;搜索空间一大,树搜或多次 rollout 直接把造数据成本打爆。
Search-R1 这类 outcome-supervised RL 把「会搜」证明了一遍,但中间步骤仍然缺少细粒度、可回传的监督信号。DecEx-RAG 的回应很工程化:显式 MDP、过程奖励、剪枝控复杂度,再用 SFT + DPO 两阶段把模仿学习和偏好对齐接起来。
方法骨架:RAG 当 MDP,Decision / Execution 拆开
作者把状态、动作、转移、奖励放到标准 MDP 记号里(正文小节 2.1)。Decision 这一侧管的是「怎么走」:这一轮该不该结束迭代;若继续,是相信参数记忆就够,还是必须走检索分支。Execution 这一侧管的是「这一步写得好不好」:子问题拆得是否到位、子查询拿去搜是否值得。论文刻意把 sub-question 和 sub-query 分开——语义相近的两个检索词,返回文档往往差一截,混在一个动作空间里不容易学稳。
奖励用 rollout 一致性聚合:对状态-动作对 \((s_t, a_t)\) 做多次模拟完成,用最终答案的正确性得分(如 F1)平均:
其中 \(v(\cdot) \in [0,1]\)。这条式子其实就是把「过程好不好」量化成可比较标量,后面剪枝和选枝都靠它。
搜索树扩展与剪枝:Figure 1 在画什么
下图来自 arXiv HTML 版图 1,展示搜索树如何一层层展开,并在决策层、执行层两侧做剪枝;节点类型(子问题、子查询、知识回答、最终答案)和奖励数值都画在树上,便于对照正文叙述。
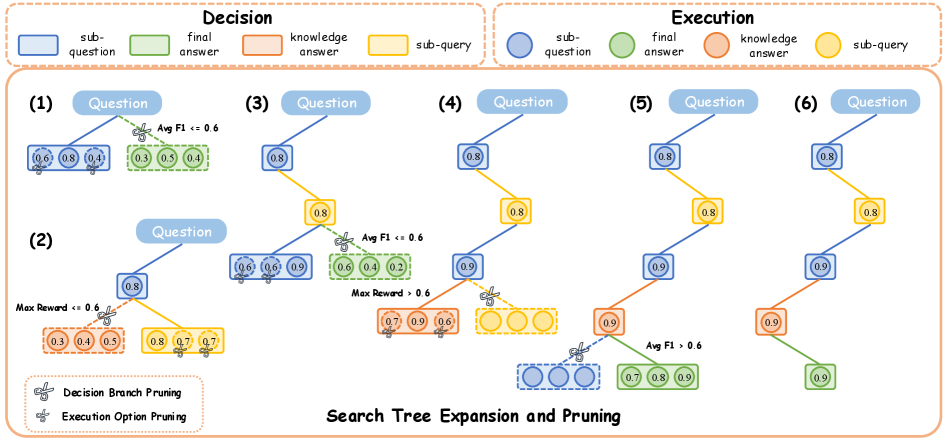
图1:DecEx-RAG 框架示意——搜索树扩展与剪枝过程(来源:论文 Figure 1,arXiv HTML)。
结合正文,终止决策 \(\sigma_t\) 先用非零温度多次采样;若超过一半样本倾向终止,则直接结束。否则采样多个子问题,去重后对每个分支做 rollout,用平均奖励选最优枝继续。检索决策 \(\delta_t\) 上,先尝试用内部知识回答子问题;若最高分超过阈值,说明不必检索,省掉外部调用;否则生成多条 sub-query,同样 rollout 选最优。剪枝策略用聚合奖励砍掉冗余分支,避免深度一层层指数爆炸——后面 Table 2 会给时间数字。
训练:最优链做 SFT,剪枝前生成的偏好做 DPO
树展开结束后,根到叶的最优推理链拿去 SFT,模仿整条多步格式;剪枝前其实产生过大量候选分支,这些分支天然构成 决策偏好 与 执行偏好 两类数据,再喂给 DPO(目标函数细节在附录 A.2)。这也是为什么后面消融里会单独去掉某一类偏好——用来检验「只训决策」或「只训执行」够不够。
实现细节上,作者从 HotpotQA、2WikiMultiHopQA 训练子集抽 2000 + 1000 条问题造数据;检索决策侧策略用 Qwen2.5-7B-Instruct,其余决策统一 Qwen3-30B-A3B;检索跟 Search-R1 对齐:2018 英文维基 + E5 检索器;检索文档数 3,多轮方法最大迭代 \(T_{\max}=4\)。这些数字读下来,复现实验的门槛主要在算力和 rollout 次数,而不是神秘超参。
评估划分里有个细节:HotpotQA 与 2WikiMultiHopQA 被作者视作 域内测试;其余四个数据集当作 域外,用来观察套路能不能迁移到别的题型——读完 Table 1 再回看这一条,就不容易把「全榜碾压」误读成单一数据集上的过拟合。
同期工作里它站在哪儿
同一批「让模型学会调用搜索」的路线里,Search-R1、R1-Searcher 走的是 outcome RL;IKEA、DeepRAG、ReasonRAG 等各有各的树搜或强化痕迹。DecEx-RAG 的自我定位不是再找一个稀疏奖励口径,而是把 step-level 反馈写进树扩展:reward 来自 rollout 聚合,偏好来自剪枝前保留的分叉样本。说实话,它和 PRM、MCTS、测试时扩展算力那条线是并列的对话关系——你若熟悉 Let’s Verify Step by Step 那种逐步判别,会把这里的 rollout 得分看成一种「廉价 surrogate」,省去了单独训大判别器的开发周期,代价则是仿真次数一上来就要算账。
主实验:六个数据集上的整体对比
Table 1 覆盖六个公开数据:单跳 PopQA、NQ、AmbigQA,多跳 HotpotQA、2WikiMultiHopQA、Bamboogle。基线分两大类:纯提示(Direct、Standard RAG、Search-o1 等)和 RL(Search-R1、IKEA、ReasonRAG、DeepRAG 等)。下面这张摘抄表只保留最强 outcome RL 之一与 DecEx-RAG 的 Avg EM / Avg F1,完整 14 列见原文 Table 1。
| 方法 | Avg EM | Avg F1 |
|---|---|---|
| Search-R1 (PPO) | 37.4 | 46.7 |
| DecEx-RAG | 43.7 | 52.4 |
作者在文中归纳三条读表心得(小节 3.3):纯 prompt 天花板明显;同样 约 3K 训练样本下,过程监督相对 outcome RL 能拉出 约 6%–8% 量级的优势区间(这是他们正文段落给出的区间表述,与摘要里 6.2% 全局平均口径并存,写作时不宜混成一个数字);DecEx-RAG 在多个过程监督类方法里也排在前面。
值得一提的判断:他们认为 Search-o1 在 小模型 上未必复现论文里的巨大优势,因为长链路指令跟随能力差一截——这点对工业选型很实在:prompt 堆栈不是免费午餐。
消融:Figure 2 三张小子图在说什么
Figure 2 拆成三块子图(arXiv HTML 版文件名为 x2–x4),分别对应正文里的 SFT 数据选取、DPO 偏好构成、训练阶段组合。
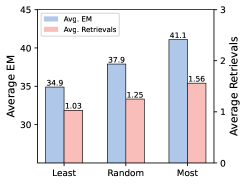
图2(a):SFT 阶段 Least / Random / Most 三种检索代价策略下,平均 EM 与平均检索次数(论文 Figure 2a)。
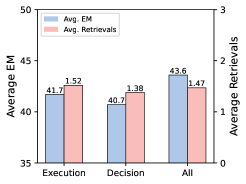
图2(b):仅用 Execution 偏好、仅用 Decision 偏好、二者全用上(All)的对比(论文 Figure 2b)。
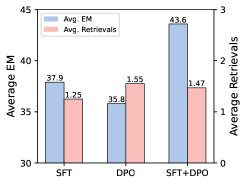
图2(c):不同训练阶段组合的 EM 与检索次数(论文 Figure 2c)。
读图时可以和文字互相印证:Most 检索策略 EM 最高,检索也更频繁,模型更像在用多轮检索「复查」答案;只训决策或只训执行都不如两边一起上;单走 DPO 会出现 EM 掉下去但检索次数反而升高的情况——说明没有好的模仿基底,偏好对齐会把习惯带偏。SFT+DPO 在图上回到最高的 43.6 平均 EM 档位(与子图标注一致),对应全文强调的阶段性训练。
剪枝到底省了多少:Table 2
三种扩展:Pruning Search、No Pruning Search、Full Node Search。在 \(k=3, n=4, T_{\max}=4\) 设定下,平均单次扩展时间:134.9 s vs 743.2 s,大约 5.5 倍加速,与摘要「近 6×」同量级;Full Node 慢到不可比(正文写单题可超 1 小时)。更关键的是:从 Pruning 与 No Pruning 各采样等量数据训练 Qwen2.5-7B-Instruct,SFT 与 SFT+DPO 下的平均 EM/F1 几乎同一档——例如 Pruning 路径 SFT+DPO 为 36.6 / 45.3,No Pruning 为 36.3 / 44.8。也就是说:剪枝主要省算力,不太像在用搜索精度换质量。
坦率的读后感
亮点:问题陈述贴近当前工业界训「会检索的智能体」时的痛点;MDP 分解 + 树扩展 + 过程奖励 + 剪枝 + SFT/DPO,整条链路一环扣一环,附录还给大量 prompt 模板,工程可复制性强。奖励用 rollout 正确率平均,实现简单,不依赖单独训一个庞大的 PRM。
需要心里有数的地方:复杂度和延迟仍由 rollout 次数、分支宽度 \(k\)、深度 \(l\) 共同决定,剪枝是缓解而不是魔法;与 Search-R1 的比较建立在团队复现与对齐设定之上,读者如果自己复现基线,数字仍可能浮动;过程奖励仍是基于答案正确性的间接信号,并不是逐步人工标注的 PRM。
如果你在做「检索调用贵、但要可控训 Agent」的产品或研究,这篇论文的价值在于:把决策质量和生成质量拆开优化,并用剪枝把数据管线跑得动——比单纯喊「我们上了 RL」更可执行。落地时我会优先对齐三件事:rollout 次数与分支宽度能不能压得住;检索器和维基版本是否与基线一致;小模型上要不要砍掉 Search-o1 那种超长 prompt 流水线,把注意力放回树扩展本身。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我