别让模型「想太多」:中国联通团队把推理长度做成难度自适应——DAST 论文精读
一道初中代数题,普通对话模型几十 token 就出答案;换成 R1 这类慢思考模型,思维链能滚到上千 token。你在评测脚本里看着账单往上跳,心情大概不会太平静。
这篇 DAST(Difficulty-Adaptive Slow Thinking,难度自适应慢思考) 要做的事很直白:让大推理模型按题目难易自己决定「想多久」——简单题别啰嗦,难题别把链条砍得太狠。作者在 arXiv 版本标注 EMNLP 2025 Industry Track。论文地址:https://arxiv.org/abs/2503.04472v3。
核心摘要
慢思考模型在数学、竞赛题上确实猛,但业界落地时常遇到一个尴尬:同一套冗长 CoT 习惯套在所有难度上,简单题严重浪费算力,复杂题一旦配合「一刀切压长度」的偏方又容易伤精度。DAST 先定义 Token Length Budget(TLB),把「这道题对当前模型有多难」编码成一个可计算的长度参照;再在这个参照下 校准规则奖励(对错之外再加长度偏差),用偏好对学习 SimPO 把模型掰成「会算账」的推理体。实验里平均压 token 三成以上,同时尽量保住难题表现——这套叙事跳出了「全体压缩」的惯性,工业场景里很顺手:算力不是省在嘴上,而是省在不该拖长的题上。
摘要里那句「平均三成」对应原文 over 30% on average——别把它理解成每条任务都刚好 30%,真实曲线分布在分层实验里看得更清楚:简单档砍得多,难题档砍得少。
论文信息
- 标题:DAST: Difficulty-Adaptive Slow Thinking for Large Reasoning Models
- 作者:Yi Shen, Jian Zhang, Jieyun Huang, Shuming Shi, Wenjing Zhang, Jiangze Yan, Ning Wang, Kai Wang, Zhaoxiang Liu, Shiguo Lian
- 单位:Unicom Data Intelligence, China Unicom;Data Science & Artificial Intelligence Research Institute, China Unicom
- 通信作者邮箱(论文署名页):{sheny73, zhangj2791, liansg}@chinaunicom.cn,ssm01@hotmail.com
- arXiv:2503.04472v3(初次提交 2025-03-06;版本记录以摘要页为准)
- 备注:EMNLP 2025 Industry Track
动机:overthinking 不是「想得多」,而是「不该想也想」
论文用一张对比图把现象钉死:同一道 \(3x+7=22\),DeepSeek V3 几十 token 结束;DeepSeek-R1 侧思维链体量冲到四位数 token 量级——题并没有变难,贵的是「慢思考的习惯」被滥用。

图1:同一道题上,推理模型相对基座对话模型的 token 规模差异——直观展示「overthinking」带来的无效开销。
现有缓解思路里,提示词压缩、统一剪枝、全局偏好「越短越好」……常常陷入另一个坑:所有题一起变短。难题往往需要足够长的探索与自我纠错;你把链条统统砍短,排行榜上简单集可能更好看,一碰到 AIME 这种高压场景就露怯。
综述类文章会把手段分成三块:改提示、改解码、改训练。提示侧写一句「Be concise」成本低,但对 backbone 与题型极度敏感,这篇里的 CoD、CCoT 就是典型——短期见效,长期不稳。解码侧做动态裁剪、早停、潜空间压缩,能把延迟压下去,有时要以可解释性为代价。训练侧做最短样本 SFT、或拿长度当 reward 做偏好学习,最容易掉进「全体变短」的陷阱——这篇论文盯的就是第三类里最常见的副作用。
所以作者抛出的核心提问其实挺工程:能不能像人一样——一眼简单的就少想两步,一眼棘手的就允许多想一会儿? 难点在于「难度」不好直接喂给模型,而且难度是对「当前模型」而言的,不是教科书章节号。纯用外部教师模型打分也要花钱;只看单次对错又区分不开「刚好卡住」与「完全不会的题」。TLB 这条线有意思的地方在于:难度信号来自骨干模型自己的多次采样,跟线上部署用的是同一套判定规则(数学对错、代码执行结果),工程上少了跨模型对齐的扯皮。
三条主线:TLB、校准奖励、预算偏好数据
Token Length Budget:用采样正确率把「该写多长」钉住
对每道题,用骨干 LRM 先采样 \(N\) 条回答(文中主实验取 \(N=20\),最大生成长度 4096)。记 \(c\) 为其中正确条数,\(p=c/N\) 为采样正确率。\(L_{\overline{r}}\) 为正确样本的平均 token 长,\(L_{\max}\) 为最大生成长度。TLB 定义为:
直觉上:越容易(\(p\) 高),预算越贴近「做对题实际需要的长度」;越难(\(p\) 低),预算贴近上限,鼓励模型别过早自我掐断。极端地,\(p=0\) 时 \(L_{budget}=L_{\max}\),对应「这题对你太难了,先允许你想满」。这跟只靠「采样多少次做对」来贴难度标签相比,多吸收了长度分布——作者在前言里也点名:纯准确率度量有时需要更多样本还不一定能拉开极端难题。
作者在 MATH 训练集上画出不同难度等级下的平均 TLB,整体随等级升高而抬升——这说明 TLB 不是拍脑袋常数,而是跟分层难度统计一致的量。
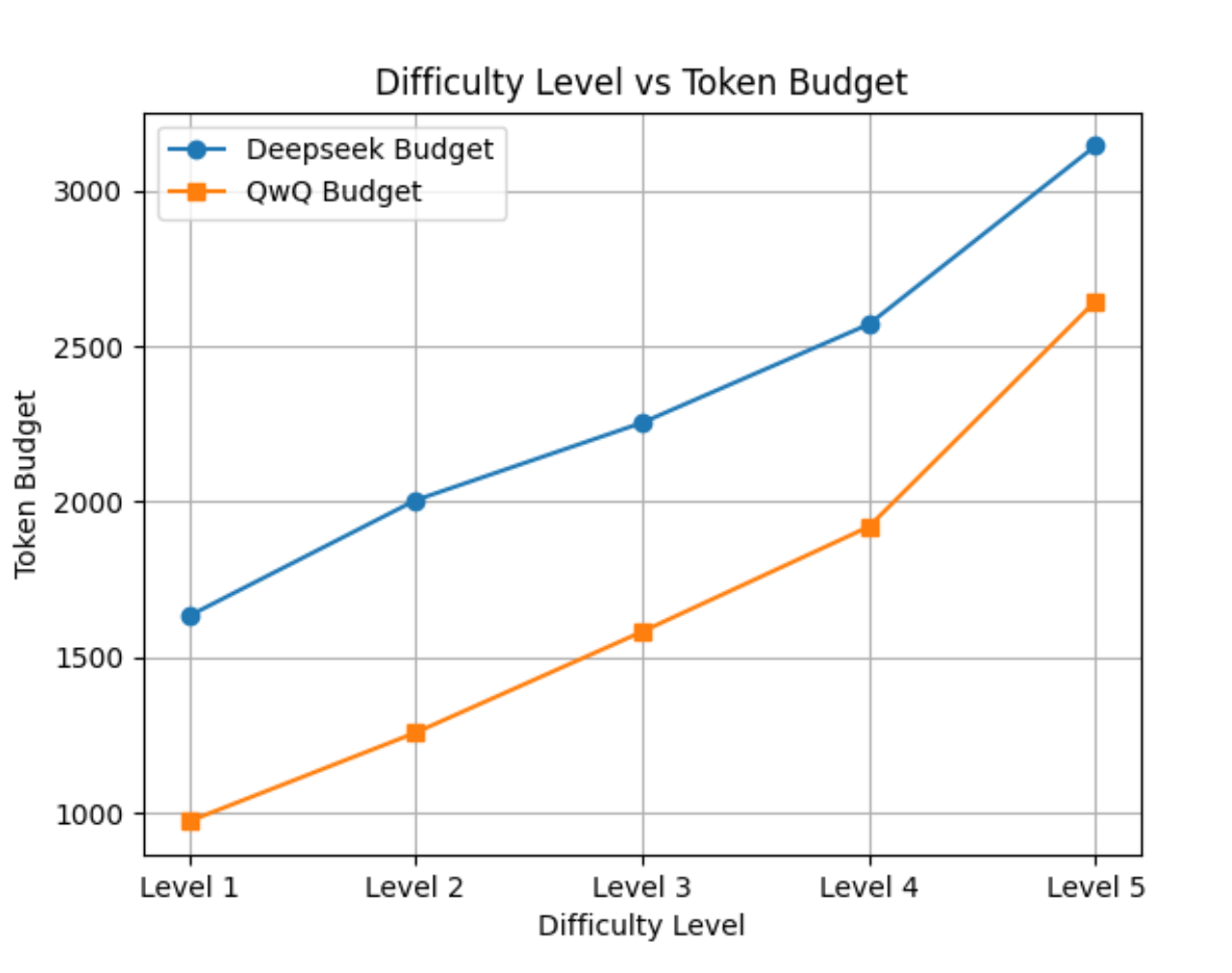
图3:QwQ-32B-preview 与 DS-32B 在 MATH 训练集上,TLB 随难度等级上升;DS-32B 因输出格式含推理链与答案分区,TLB 整体更高。
奖励校准:同对同错,也要看「相对预算」长了还是短了
设第 \(i\) 条回答的实际长度为 \(L_i\),定义相对偏离:
校准后的奖励(论文式 (2))把「规则对错」与「相对预算」拧在一起:
下图把分段形状画得很清楚:做对时,明显长于预算会被扣分;短于预算则抬高奖励,鼓励在「够用」处停笔。做错时,若长度仍显著低于预算,常被视作「还没想够」,奖励沿 \(\lambda\) 往上抬;长度到达预算附近后负面饱和,避免「越长越胡扯还能骗分」。
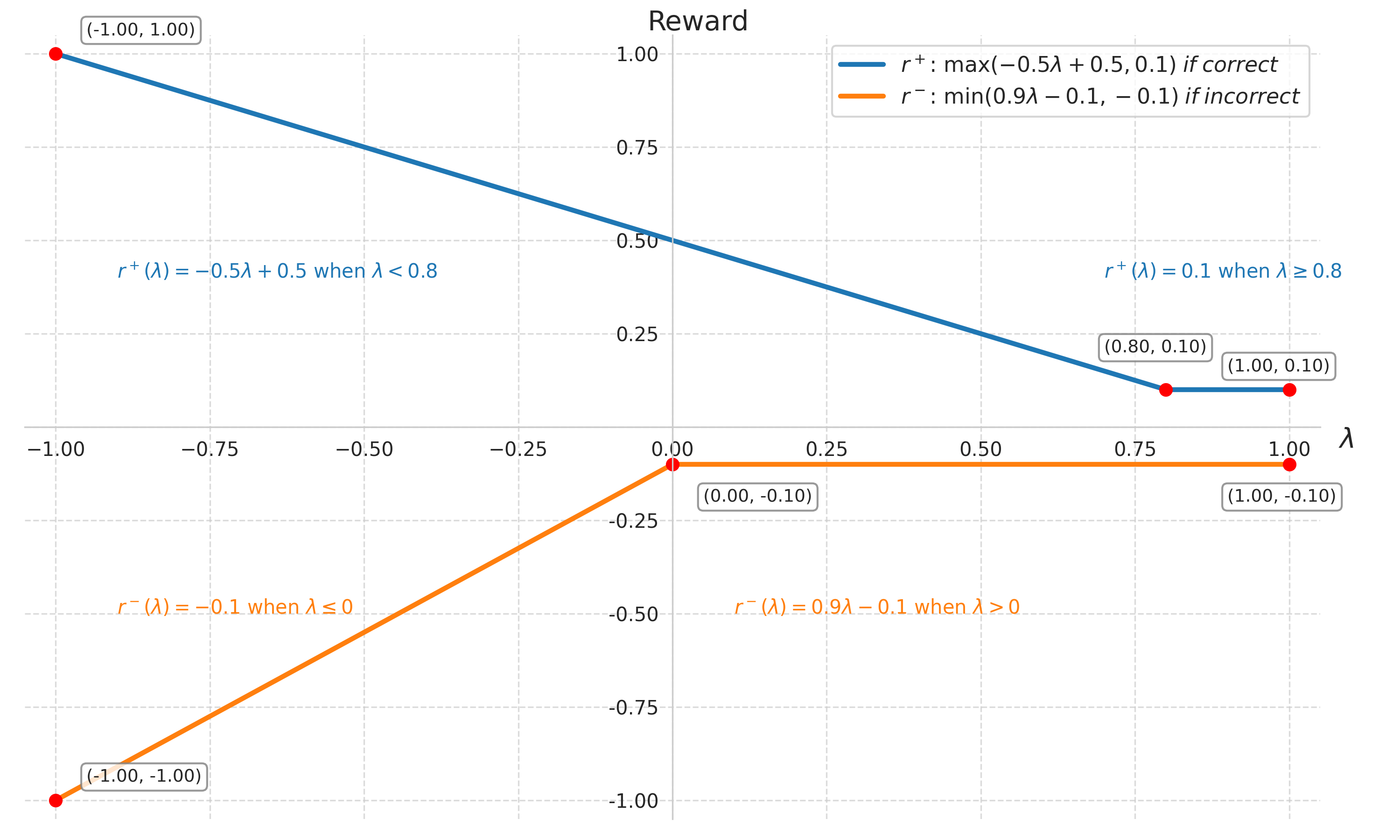
图4:正确(蓝色)与错误(橙色)两类回答下,奖励随 \(\lambda\) 的分段行为——长度与难度参照挂钩后再做偏好排序。
偏好对与 SimPO:不只「短胜长」,还区分「双错」时的取向
采样后对每条回答算校准分,排序构造偏好对 \((x,y_w,y_l)\)。作者强调两类对比:
- DCP(Dual-Correct Pair):两条都对,偏好更短的那条——鼓励 在预算语境下的精简。
- DICP(Dual-InCorrect Pair):两条都错,偏好更长的那条——在预算允许范围内鼓励 多想一想。
另有 CICP(一对正一对误),消融里显示收益不明显,正文解释训练集中弱化这类对。
每题先取 DCP / DICP 中 奖励差 \(\Delta R\) 最大 的对,再做两步过滤:截断阈值 \(\delta\) 丢掉一部分 \(\Delta R\) 太小的对(噪声大);每题最多保留 一对 DCP + 一对 DICP。DS-7B 取 \(\delta=0.18\),DS-32B 取 \(\delta=0.15\)(阈值敏感性后面单独聊)。
优化器选 SimPO:作者的理由很务实——SimPO 对答案长度控制相对敏感,适合这类「既要偏好又要留意长度」的对齐任务。SimPO 相对 DPO 一类带参考模型的写法更省事(参考 Meng et al. 原文),目标函数沿用论文式 (3):对每条偏好对,比较优胜序列与落败序列在策略 \(\pi_\theta\) 下的对数似然,并用序列长度做归一化,再配上 margin \(\gamma\)。附录给出 \(\beta=200\),\(\gamma=1\),训练集规模 DS-7B 约 10295 对、DS-32B 约 9813 对;其中 DCP 约占九成上下(DS-7B 91.26%,DS-32B 87.73%),DICP 占剩余——说明大多数对比信号仍来自「都对但要更短」,「都错但要更长」是配角但不可删。
整体管线用一张总览图串起来:采样 → 算 TLB → 校准奖励 → 组偏好数据 → SimPO 微调。
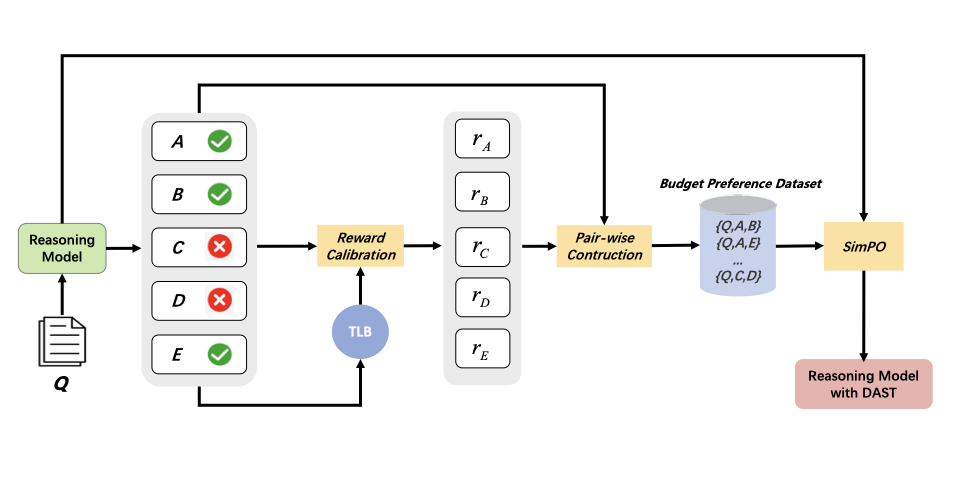
图2:从问题采样多条候选回答,引入 TLB 做奖励校准,再构造偏好数据并用 SimPO 更新——得到带 DAST 的推理模型。
实验:不是只看平均压缩率
设定速览
- 骨干模型:DeepSeek-R1-Distill-Qwen-7B(DS-7B)、同系列 32B(DS-32B)。
- 训练数据:用 MATH 训练集 上的问题构造偏好对——先在每题上采样,再算 TLB、校准分、组对;评测则换到 MATH-500 / AIME / GPQA,避免混谈「训练见过」与「泛化」。
- 基准:MATH-500(按 Level 1–5 分层)、AIME 2024(30 题)、GPQA(198 题)。
- 对照:提示侧 Concise Thoughts(CCoT)、Chain of Draft(CoD);最短样本 SFT(SFTshortest);最短偏好 SimPO(SimPOshortest);余弦奖励版 SimPOcosine;长度惩罚版 SimPOLenPenalty 等。
- 解码:评测最大长度 32768,贪心解码,与引用工作对齐。训练 1 epoch,AdamW,lr = 5e-6,8×H100。
补充一组中间对照,方便定位 DAST 夹在「纯压缩」与「几乎不压」之间:SimPOLenPenalty(DS-32B) 在 MATH-500 上 ACC 90.6、平均长度 1190,压缩极狠,但 AIME ACC 掉到 43.3;SimPOcosine 在 MATH-500 上 ACC 94.2,乍看不弱,可 AIME 只有 63.3,仍低于 DAST 的 76.7。三条基准横着比一圈,预算感知奖励带来的不只是某一栏的长度数字变小,而是整条 ACC–长度权衡曲线的挪动。
arXiv 摘要页仍挂着匿名仓库链接(Industry 版本常见做法),读完正文若要复现,盯紧两件事就够:偏好对构造里的 \(\delta\),以及 SimPO 的超参数 \(\beta\)、\(\gamma\)——二者一动,长度人格跟着飘。公开权重若后续更新,以作者正式放出的 checkpoint 说明为准;此处解读仅针对当前 arXiv v3 全文表格与附录版本。
主表:谁在「压长度」和「保精度」之间更像成年人
下面这张表把三条基准上的 ACC、平均长度 LEN、正确样本平均长度 C-LEN、压缩率 CR / C-CR 一并列出——读的时候别只盯 CR:AIME 上猛砍长度的方法常常伴随 ACC 断崖。
表1:主实验结果汇总(摘自论文 Table 1)
| MODEL | METHOD | MATH-500 ACC↑ | MATH-500 LEN↓ | AIME ACC↑ | AIME LEN↓ | GPQA ACC↑ | GPQA LEN↓ |
|---|---|---|---|---|---|---|---|
| DS-7B | Origin | 93.2 | 4039 | 60.0 | 10603 | 47.98 | 8021 |
| DS-7B | CoD | 75.8 | 1596 | 43.3 | 9399 | 49.49 | 7178 |
| DS-7B | SimPOshortest | 89.8 | 1891 | 53.3 | 8291 | 50.51 | 6068 |
| DS-7B | DAST | 93.6 | 3309 | 70.0 | 10804 | 51.51 | 7684 |
| DS-32B | Origin | 94.4 | 3782 | 73.3 | 10955 | 65.15 | 6410 |
| DS-32B | SimPOshortest | 89.0 | 1107 | 36.7 | 2580 | 63.13 | 2455 |
| DS-32B | DAST | 95.8 | 2044 | 76.7 | 7023 | 65.15 | 5535 |
几个读表时值得停一秒的点:
- 提示词捷径不稳:CoD 在 DS-7B 上把 MATH-500 ACC 拉到 75.8,AIME 掉到 43.3——「写得短」不等于「想得对」。
- SimPOshortest 在 DS-32B 上把长度砍到极致(AIME LEN 2580),但 AIME ACC 36.7——典型「压缩过头」。
- DAST(DS-7B)在 AIME 上 LEN 相对 Origin 甚至略升(10804 vs 10603),ACC 从 60.0 提到 70.0——作者特意强调:方法不是无脑缩短,而是在难题上允许更长推理。
- DAST(DS-32B) 在三条基准上 ACC 至少持平或上涨,同时拿到可观的 CR——这篇工业稿想要的「省算力但不砸招牌」在这里更像闭环。
- GPQA 一眼看去有点「平淡」:DS-32B 一行里 DAST 与 Origin 的 ACC 都是 65.15,压缩主要来自长度侧(6410 → 5535 token)。这说明跨学科问答里,「难度自适应」不一定总能翻译成 ACC 大涨——但至少没有把分数砸穿,算是个务实的底线。
若把 SimPOcosine(论文里的余弦长度奖励替代)拉进来对比,作者写道它与 DAST 在 ACC–CR 曲线上走势相近,但 DAST 在多条基准上仍占优——直白讲:不是「反正别一刀切」这句口号赢了,而是把预算写进奖励形状之后,偏好数据真的变了。
分层:难题上压缩得更克制
Figure 5 把 MATH-500 按 Level 拆开:DAST 在 Level 5 上相对其它压缩方案更守住准确率;长度压缩主要集中在简单档。
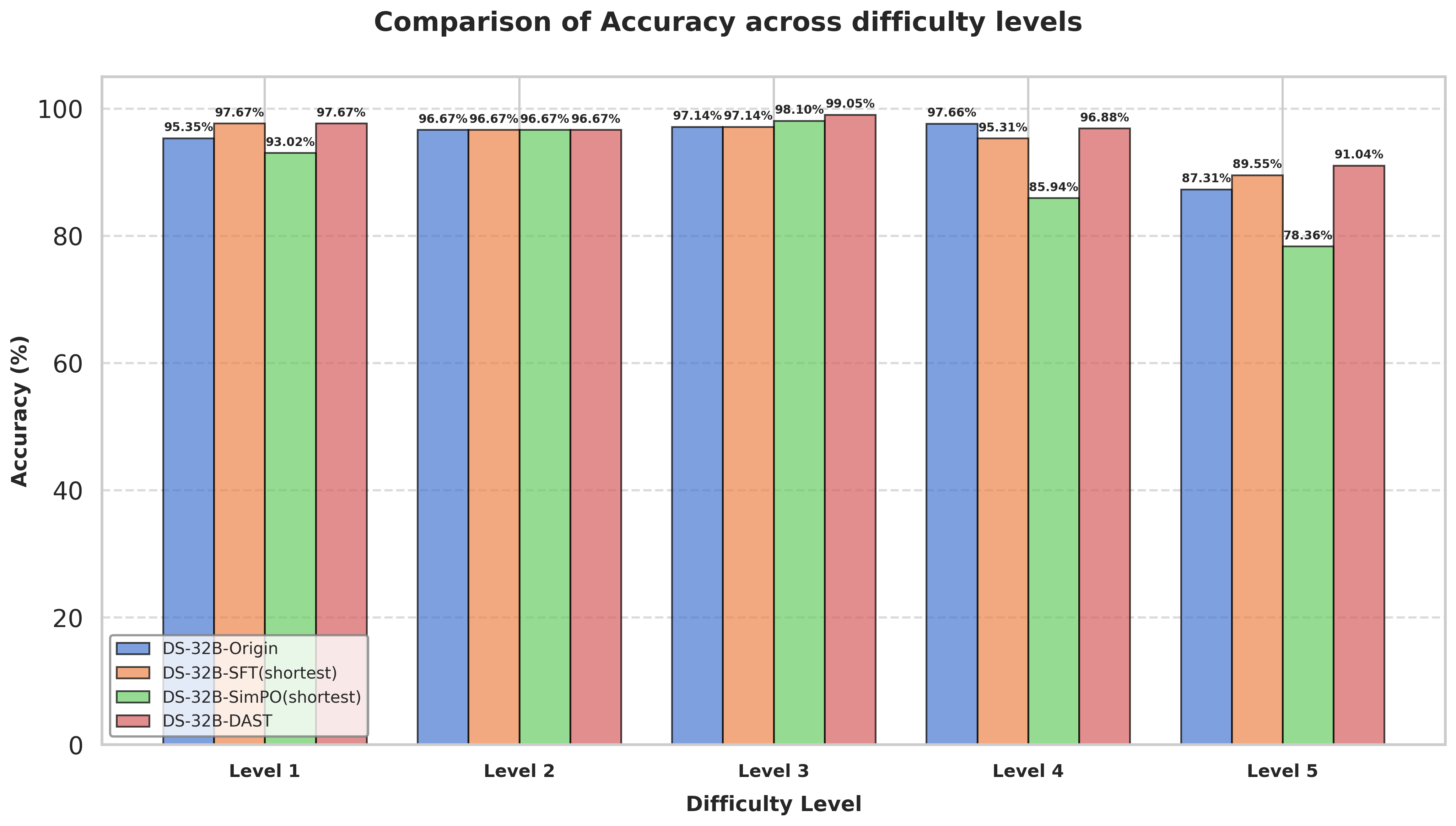
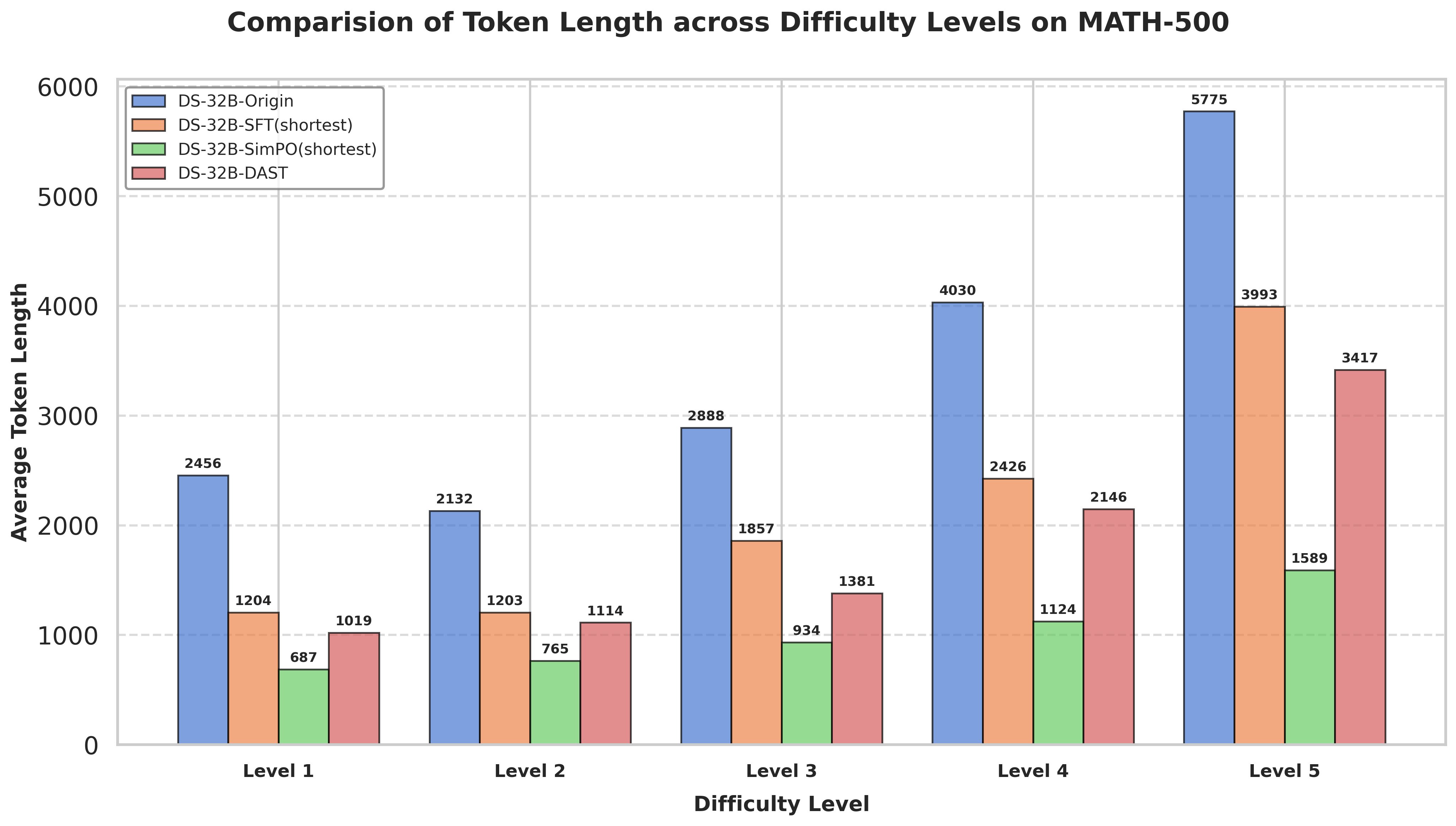
图5:DS-32B 上各方法在 MATH-500 各难度级的 ACC(上)与平均 token(下)。SimPOshortest 长度最激进,但在高难度档 ACC 下滑更明显。
Table 2 把「分层压缩率」量化(DS-32B,MATH-500):SimPOshortest 各 Level 的 CR 分别为 72.0%、64.1%、67.6%、72.1%、72.5%,起伏不大;DAST 对应为 58.5%、47.7%、51.9%、46.7%、40.8%——越难的档,压缩越克制。压缩强度随难度变浅,这条曲线本身就是「难度自适应」的直接证据。
消融:双组件缺一就像偏科
| Model | ACC | LEN | CR |
|---|---|---|---|
| DS-7B | 93.2 | 4039.13 | - |
| DAST | 93.6 | 3309.16 | 18.0% |
| w/o DCP | 94.6 | 4759.07 | -17.8% |
| w/o DICP | 90.0 | 1624.60 | 59.8% |
| + CICP | 93.2 | 3295.96 | 18.3% |
去掉 DCP,精度上去但长度暴涨;去掉 DICP,压缩率最好但 ACC 跌 3.2 个点。两者互补才能把「短得合适」与「难时多想」同时留住。加 CICP 基本不占便宜——这条负面结果写进正文,态度上加分。
\(\delta\) 与 reward hacking
Figure 6 展示 DS-32B 在验证子集上 ACC、CR 随 \(\delta\) 的变化:\(\delta=0.15\) 时 ACC 峰值与 CR 约 47% 的长度压缩并存。作者提醒 \(\delta=0\) 时 CR 可能接近 0 甚至为负,部分因为 低区分度的 DICP 对 会诱导 reward hacking——这类细节在工业落地调参会反复碰到。
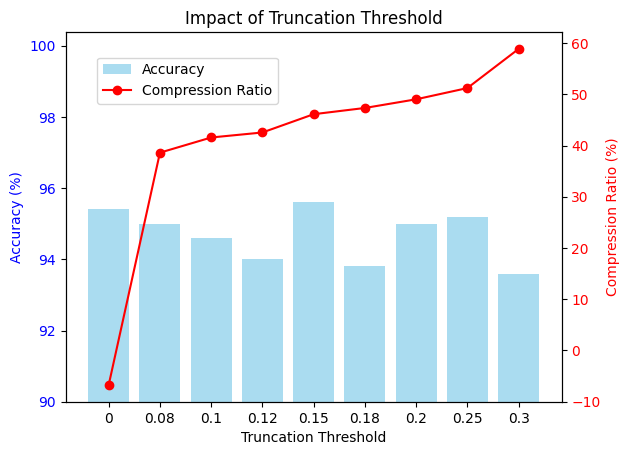
图6:网格搜索展示 \(\delta\) 与 ACC、压缩率的折中;DS-32B 最终取 \(\delta=0.15\),DS-7B 取 \(0.18\)。
案例:同一简单题,原模型啰嗦 vs DAST 收敛
附录给出 DeepSeek-R1-Distill-Qwen-32B 在某简单题上的并排输出:原版堆叠大量冗余自我对话,DAST 后输出更干净。案例展示的其实是用户侧体验:思维链不是越长越有说服力,尤其在移动端或小窗口里,啰嗦的自我纠错段落会直接消耗注意力预算——这类产品在采纳推理模型时,往往同时在优化「延迟」与「可读性」,DAST 正好踩在两条线的交汇处。
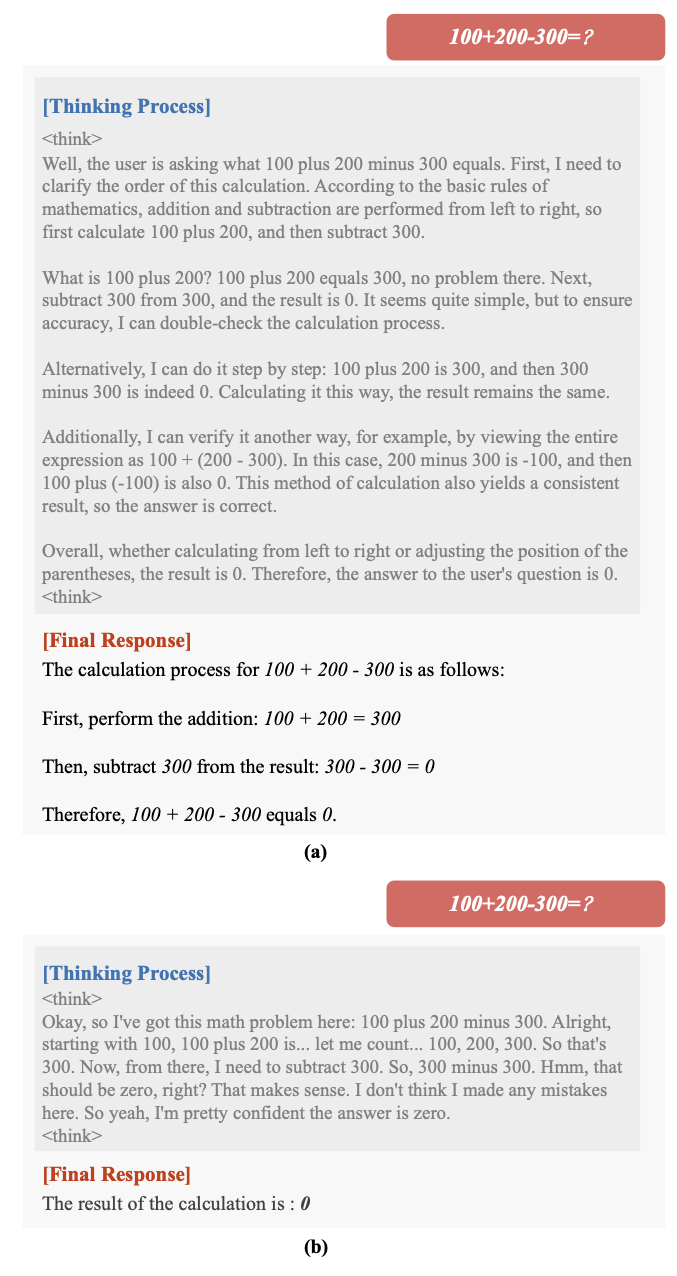
图9:案例对比——DAST 在保持正确性的前提下缩短无效自我重复。
我的判断:这类工作的位置与边界
亮点
- TLB 把「难度」摊平成可批量估计的长度参照,跟采样统计绑定,比手工拍 token 上限更像自动调参。
- 奖励校准 + DCP/DICP 把偏好数据从「谁短谁赢」扩展成「该短时短、该长时长」,主表与分层图相互印证。
- 工业论文气质:流程(采样→校准→SimPO)清晰,超参与附录表格齐全,适合工程团队复刻。
需要心里有数的限制(论文 Limitations 已写,我同意其中几条):
- 评测集中在 STEM 问答,代码生成、开放域对话未覆盖。
- \(\delta\) 敏感,迁移新骨干或新题库大概率要重扫一遍。
- 离线构造偏好 + SimPO,相对在线 RL 天花板可能更低,但成本也更可控——取舍要看业务预算。
落地时我会多看两眼的地方:TLB 依赖 每条训练题采 20 条、4096 上限 的设定——题库变大时,这一步就是纯算力账;线上推理并不会每条题先跑二十遍,所以训练分布与真实请求分布是否一致,要靠你自己的业务数据验证。另一个现实问题是:规则奖励(数学答案对错)在部分场景不好定义,TLB 与校准奖励都要跟着换判定器。
若把视角再拉近一点:这篇工作的训练管线全程 离线偏好学习,没有在线 rollout;优点是工程上更可控,缺点是遇到「奖励稀疏 + 长链条 credit assignment」时,未必榨干模型容量——作者在 Limitations 里也提了未来走向 on-policy RL + 同一套奖励形状。读者要是已经在做 GRPO / PPO 类在线推理训练,可以把 DAST 的 TLB 与校准函数当成 离线热身,再丢进在线阶段细化,未必非此即彼。
跟「手工 token budget 搜索」类工作比,DAST 把预算做成 数据驱动标量;跟纯最短偏好比,它显式保护 难题链长。如果你正在把 R1 系模型塞进按 token 计费的产品里,这篇论文值得放进 reading list:省下来的不只是账单,还有用户读思维链时的耐心。
和「预设 token 上限」类路线差在哪
Han et al. 的 token-budget-aware 推理要在提示里 反复试探 长度阈值,成本高、路线偏启发式。DAST 这边把预算写成 采样统计量,一次离线算完写进奖励,推理阶段不必再扫一圈候选阈值。Related Work 里也点名:不少工作用手工离散档位控制长度;DAST 试图让「该多长」跟 当前模型对题的把握程度 绑定起来——这不是否认手工预算的价值,而是把调参对象从「几句 prompt」挪到了 数据构造与奖励形状。
读指标时建议同时看 CR 与 C-CR:前者压的是全体输出的平均长度,后者只看答对样本的长度。全体压得很猛但 C-CR 失控,往往意味着模型在「勉强猜对」与「大幅缩短」之间选择了后者;DAST 在 Table 1 里几项 C-CR / C-LEN 的变化,要和 ACC 同一行读,才有说服力。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。