CodeRAG:把"检索什么"和"重排什么"都想清楚——仓库级代码补全的一次系统性重做
核心摘要
仓库级代码补全这件事,过去几年大家都在卷各种 RAG 方案,但坐下来仔细看,会发现整条链路几乎每个环节都有人偷懒:检索 query 直接拿光标前 k 行凑数,retriever 只用一种路径,reranker 跟下游 code LLM 训练目标完全脱节。CodeRAG 这篇 EMNLP 2025 的工作,把这三个问题一起拎出来,系统地补一遍——用 log probability 引导的 query 构造、稀疏/稠密/数据流三路并行检索、加上一个为 code LLM 偏好做对齐的 BestFit 重排器(再蒸馏成 0.6B 的小模型)。在 ReccEval 上用 Qwen2.5-Coder-7B 跑出来的 EM 是 47.48%,比 DraCo 的 39.99% 提了将近 8 个绝对点,在更难的 CCEval 跨文件场景上同样稳。这不是哪一个组件的小创新,而是把整条 pipeline 拧紧了——值不值得读,看你做不做仓库级补全这个方向,做的话基本是一篇"必读、且能直接抄作业"的论文。
论文信息
- 标题:CodeRAG: Finding Relevant and Necessary Knowledge for Retrieval-Augmented Repository-Level Code Completion
- 作者:Sheng Zhang¹†, Yifan Ding¹†, Shuquan Lian¹, Shun Song², Hui Li¹§
- ¹ 厦门大学(Key Laboratory of Multimedia Trusted Perception and Efficient Computing, Ministry of Education of China)
- ² 蚂蚁集团 Ant Group
- † 共同一作;§ Hui Li 是通讯作者
- arXiv:2509.16112v1(2025 年 9 月 19 日)
- 会议:EMNLP 2025 (Main)
- 代码:https://github.com/KDEGroup/CodeRAG
一、从"代码补全到底卡在哪"说起
如果你用过 Copilot、Cursor 或者任何接进 IDE 的 code LLM,肯定有过这种体验:
写一个独立的小函数,比如让它实现快排——基本上没什么悬念,模型能秒。HumanEval 上 GPT-4o 这种模型 Pass@1 已经飙到 92.7%,DeepSeek-V3 也有 91.5%,看上去问题已经解决了。
但是一旦把场景搬回真实仓库——代码不是独立的,而是要 import 隔壁文件的工具函数,要继承某个基类,要遵守这个项目特有的命名约定和数据结构——模型立刻就抓瞎。它根本不知道你这个项目里 ModelProvider 长什么样、retriever 接受哪些参数、config 应该怎么初始化。
这个鸿沟,就是仓库级代码补全(repository-level code completion)的根本痛点。
社区给出的主流解法是 RAG:检索仓库内的相关代码片段,拼到 prompt 里喂给 code LLM 当上下文。逻辑没毛病,但 CodeRAG 这篇论文坐下来一条一条审视,发现现有方案几乎每个环节都有问题:
P1 — 检索 query 构造太粗暴:直接拿光标前 k 行当 query。问题是文件开头定义的关键变量、import、类签名根本进不来;如果光标前正好是几行无关代码(比如打个 log),那 retriever 拉回来的就全是噪声。
P2 — 单一检索路径:要么纯 sparse(BM25/TF-IDF),要么纯 dense(embedding 相似度),要么纯 dataflow。每种都有自己擅长的场景,但没有一种能 cover 所有 case。
P3 — retriever 和 code LLM 各练各的:retriever 训练时优化的是召回相关性,code LLM 训练时优化的是下一个 token 预测。两边的"相关"不是同一个东西。retriever 觉得相关的代码,未必是 code LLM 真正用得上的。
这三个问题听起来都不算"惊世骇俗",但把它们一起认真处理,效果是非常显著的。
我看到这三个 P 的列法时,第一反应是——做检索的人应该都懂,这三个坑前两年都在 QA RAG 里被反复 debug 过,但放到代码这个场景,确实没人做得这么彻底。
二、三种检索路径,各擅其场——为什么必须多路并发
先看 P2 那个最直观的——单一检索为什么不够用。
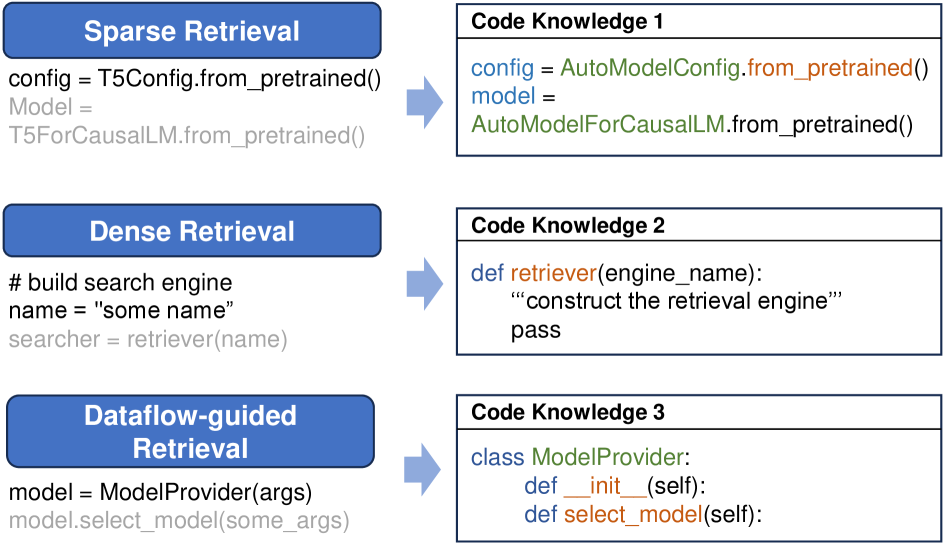
图1:三种代码补全场景对应三种不同的检索路径。灰色文字是待生成的代码。Sparse Retrieval 适合 query 和被检索代码有大量字面重叠的场景(比如同一种 model 加载模板);Dense Retrieval 适合 query 和被检索代码语义相关但词面不同的场景;Dataflow-Guided Retrieval 适合需要追溯变量定义的场景(model = ModelProvider(args) 之后要补 model.select_model(...),那就得知道 ModelProvider 类长什么样)。
这张图看完应该就明白了:
- 第一种场景,光标前两行是
config = T5Config.from_pretrained(),下一行要补Model = T5ForCausalLM.from_pretrained()。这种"换个类名套同样模板"的场景,sparse retrieval 一查就能找到AutoModelConfig + AutoModelForCausalLM那块的样板代码。 - 第二种场景,注释是
# build search engine,下一行要补searcher = retriever(name)。这里 query 跟def retriever(engine_name)这个函数定义没有词面重叠,但语义上是匹配的——只有 dense retrieval 能把这个函数翻出来。 - 第三种场景更典型,前面写了
model = ModelProvider(args),下一行要补model.select_model(some_args)。要正确补全,必须知道ModelProvider这个类有select_model方法。这就是 dataflow 派上用场的地方——顺着变量的定义关系往上追。
每种检索方式都有它的甜区,但任何一种单独用都会漏掉另外两种场景。CodeRAG 的回答很朴素:那就并行跑三路,不要赌。
三、整体架构:五步走
把三个 P 的解法串起来,CodeRAG 的整体流程是这样的:
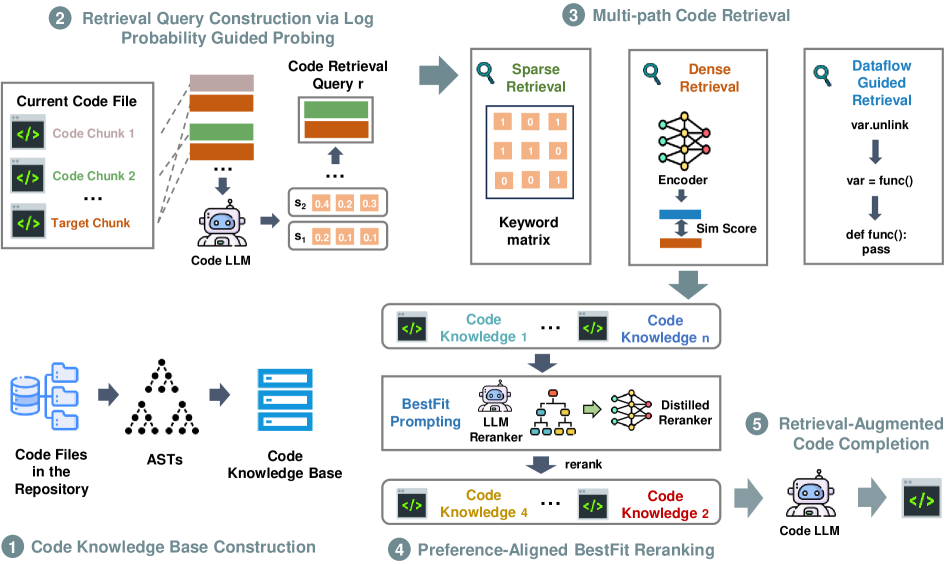
图2:CodeRAG 五步流程概览。① 离线把仓库代码解析成 AST、抽出函数/全局变量/类成员/类方法四种结构化"知识单元",构建代码知识库;② 在线用 log probability guided probing 构造 retrieval query;③ 三路并行检索(sparse + dense + dataflow),合并结果得到 n 个候选;④ 用 BestFit 重排(LLM reranker 或蒸馏后的小模型)筛出 top-u;⑤ 把 u 个代码片段拼到光标前的代码上下文里,喂给 code LLM 完成补全。
下面顺着这五步逐个聊。
3.1 代码知识库:四种结构化单元
通用 RAG 处理文本时,常见做法是按长度切块或者按分隔符切——简单粗暴但放到代码上就出问题。一个类被中间硬切开,重要的方法签名和成员变量就分家了,retriever 就再也理不清这个类到底在干嘛。
CodeRAG 选了一个非常符合工程直觉的切法——按 AST 抽语义单元。
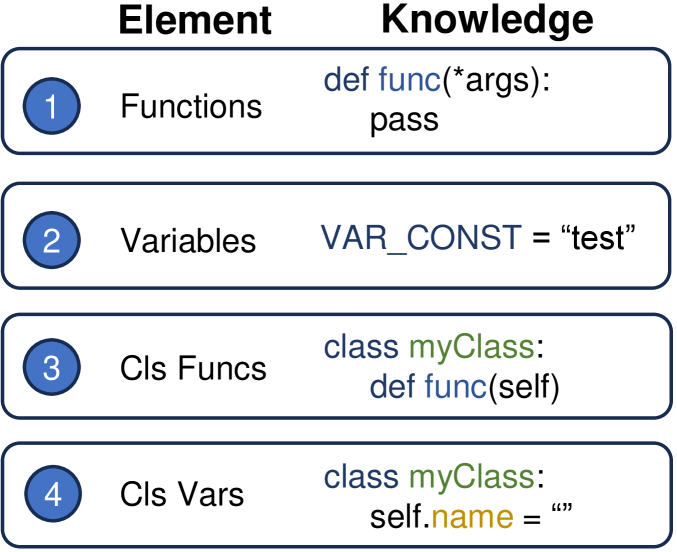
图3:CodeRAG 知识库里只有四种 element:① 普通函数 functions,② 全局变量 variables,③ 类的方法 cls funcs,④ 类的成员变量 cls vars。每一种都是 AST 上的一个完整子树,不会被切碎。
这个粒度选得挺讲究——比"按行切"保留了语义完整性,比"整个文件存"又能精确定位。同时对仓库内可被 import/调用的"接口"覆盖得很完整:你能用到的东西,要么是函数,要么是类的成员,要么是模块级常量,正好这四类。
3.2 用 log probability 替代"光标前 k 行"
这一步是 CodeRAG 第一个比较 nice 的设计。
之前的 RepoCoder、ProCC 这些方法,构造检索 query 的方式都是"取光标前 k 行",或者"光标前 k 行 + 模型先生成一段代码"。问题是:k 行未必是相关的 k 行。
举个例子:你在写一个文件,光标前 10 行可能正好是一段 print 调试代码,但真正决定下面要写啥的,是文件开头的 import 和类定义。这种情况下"取光标前 10 行"会引入噪声,"重要但远的"反而被忽略。
CodeRAG 的思路:让 code LLM 自己投票。
伪代码写得很直白,我用文字翻译一下:
- 把整个待补全文件切成若干个 f 行的小 chunk;
- 对每一个非 target 的 chunk \(c_i\),把它拼到 target chunk 前面,喂给一个轻量 code LLM(论文用的是 CodeT5p-220m)让它预测后续 m 个 token;
- 把 m 个 token 的最大 log probability 加起来,得到 \(c_i\) 的"置信度分数" \(s_i\)——这个分数越高,说明加了 \(c_i\) 之后模型对续写的把握越大,那么 \(c_i\) 跟 target 的相关性就越强;
- 选 top-g 个分最高的 chunk,跟 target chunk 拼起来作为最终 retrieval query。
我看到这个设计的时候第一反应是——这不就是 probing 那一套思路嘛?让模型自己告诉你"看到什么之后我心里更有底",说到底是在用 LLM 的 perplexity 作为相关性的代理指标。这种"用模型自己当裁判"的玩法在 RAG 领域很常见(比如 LLM-as-a-reranker),但用在 query 构造这一步是比较少见的。
成本上也可以接受——CodeT5p-220m 才 2.2 亿参数,一次 query 构造平均 0.14 秒,比下游 code LLM 的生成开销小多了。
3.3 多路并行检索的细节
三路检索的实现都很标准:
- Sparse Retrieval:用 TF-IDF 算 query 和知识库里每个代码单元的相似度。
- Dense Retrieval:用 CodeT5p-220m 的预训练 encoder 编码,cosine 相似度匹配。
- Dataflow-Guided Retrieval:跟 DraCo 一样的做法——把当前文件构造成 dataflow graph,从光标处的最后一个变量出发,沿数据依赖关系往上追。
每一路都取 top-j 个结果(j 设成 15),sparse 和 dense 各贡献 j 个,加上 dataflow 至多 1 个,总共拿到 \(n = 2j + 1\) 个候选。
这一步的设计简洁到没有什么可吐槽的。三种检索都是已有方法,作者没有发明新的检索算法——但把它们并联起来这件事本身就有价值。
3.4 BestFit 重排:为什么不用 listwise
到这里其实还有一个问题没解决——n=31 个候选 chunk 全塞进 prompt 太长,code LLM 上下文吃不下,而且无关代码反而是干扰。所以要 rerank 出 top-u(论文 u=10),只把最关键的留下。
最直接的做法是把 LLM 当 reranker,用 listwise prompting——一次性给 LLM 看 n 个候选,让它输出一个排序列表 [Index 1][Index 2]...[Index u]。RankGPT、RankVicuna 这些工作都是这种思路。
但 CodeRAG 经验性地发现两个坑:
- 几 B 参数级别的开源 LLM 经常不严格 follow listwise 的格式。要让它老老实实按格式输出排序,得调更大的模型——但调云端大模型 API 又贵又慢。
- Listwise 本身就慢。要生成一个完整的排序列表,得逐 token 往外吐,每一步都是一次 forward;如果列表里有 10 个 index,那就要十几次 forward。
针对这两个问题,作者提出了 BestFit prompting——不让 LLM 输出排序列表,只让它从一组候选里挑出"最有用的那一个"。

图4:BestFit prompting 的 prompt 模板——给 LLM 一段待补全代码(query)和若干个候选代码片段(code snippets),让它在 <answer> 标签里输出最有帮助的那一个的字母编号(比如 <answer>[C]</answer>)。一个 forward 就出结果。
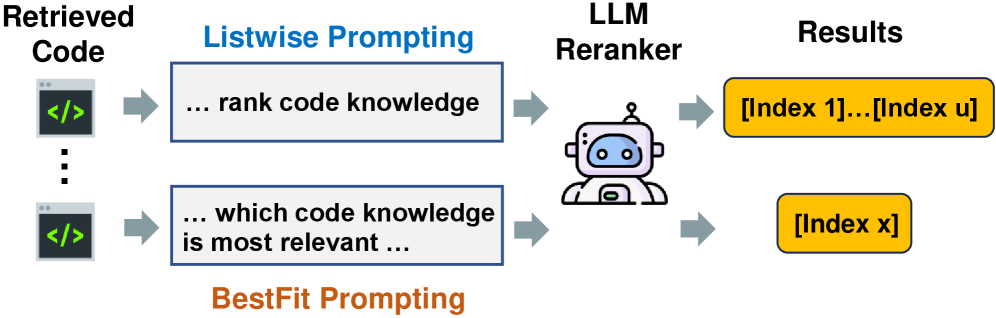
图5:左边 listwise prompting 让 LLM 一次性输出 u 个 index 的有序列表,右边 BestFit 一次只输出 1 个 index。BestFit 的输出更短,几 B 参数的开源模型能稳定 follow,单次 forward 就出结果。
听起来跟 listwise 比有点笨——一次只能选一个,那要选出 top-u 是不是要重复 u 次?没错,但作者用了一个挺优雅的工程 trick:
滑动窗口 + 堆排序
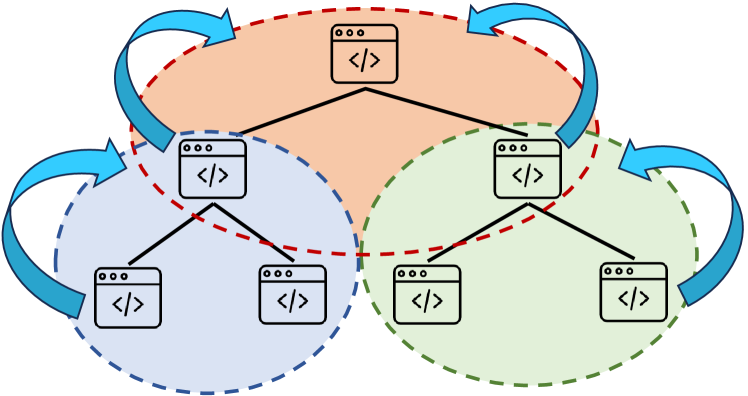
图6:把 n 个候选切成若干个 size=3 的滑动窗口(相邻窗口共享 1 个元素),每个窗口里用 BestFit 选出"最有用的一个",然后这些 winner 进入上一层的窗口继续比较——结构上是一棵堆树。一次堆排序就能找出 top-u 个最相关的代码片段,整体复杂度 \(O(N \log N)\)。
这个组合设计我觉得是论文里最有工程美感的一处——把"LLM 当 pair-wise comparator"的思路用堆排序加速,复杂度从 listwise 的"一次大 forward 一个长输出"降到"\(N \log N\) 次小 forward 各一个短输出"。在实际推理中,short output 比 long output 快得不止一个数量级。
3.5 蒸馏到 0.6B 的小 reranker
即使 BestFit 已经够省了,每次都跑 8B 的 Qwen3-8B 当 reranker 还是有点重。论文进一步把 LLM reranker 蒸馏成一个小模型——backbone 用 Qwen3-0.6B,LoRA 微调。
蒸馏数据怎么造?用 Algorithm 2:
- 对每条 retrieval query,准备好初始的检索列表 L;
- 从 L 里随机采样不同数量的代码片段,构造 N 种变体(N = {2,3,4,5,6,7});
- 让 Qwen3-8B reranker 用 BestFit prompt 在每个变体上选一次"最有帮助的",重复 5 次;
- 只保留至少 4/5 次都选同一个的 query-list-answer 三元组作为蒸馏样本——这一步是为了过滤 LLM reranker 自己都不太自信的 case,只蒸馏它"高置信度"的偏好。
token-level cross-entropy loss + LoRA,一套很标准的 distillation pipeline。
四、实验:数据全面碾压,但要看清楚比的是谁
先放主表。论文在 ReccEval(6,461 条 Python 测试样本,2023 年新发的 PyPI 项目)上的全量评测:
4.1 ReccEval 主结果(100% 数据)
| Method | CodeGen-350M EM/ES | SantaCoder-1.1B EM/ES | StarCoder2-3B EM/ES | Qwen2.5-Coder-7B EM/ES |
|---|---|---|---|---|
| Zero-Shot | 4.04 / 38.36 | 6.27 / 42.22 | 7.86 / 45.04 | 11.48 / 47.72 |
| CCFinder | 16.50 / 47.71 | 19.08 / 50.99 | 28.12 / 58.93 | 28.43 / 58.95 |
| RG-1 | 20.04 / 50.30 | 24.07 / 54.72 | 29.35 / 59.43 | 33.01 / 61.55 |
| RepoCoder | 23.96 / 53.27 | 26.78 / 56.59 | 34.27 / 63.09 | 34.99 / 62.71 |
| DraCo | 21.85 / 51.44 | 30.27 / 59.38 | 36.57 / 64.31 | 39.99 / 66.26 |
| RepoFuse | 21.20 / 51.18 | 28.73 / 57.89 | 33.88 / 61.96 | 38.24 / 65.11 |
| CodeRAG-LLMR | 26.81 / 55.54 | 36.17 / 63.00 | 42.69 / 68.07 | 47.48 / 70.82 |
注:EM = Exact Match,ES = Edit Similarity。
几个观察:
第一,CodeRAG 在所有四个 code LLM 上都拿了 EM 和 ES 的双第一,没有任何一个 setting 是别人赢的。
第二,模型越大,CodeRAG 的优势越明显——Qwen2.5-Coder-7B 上 EM 47.48 比 DraCo 的 39.99 高了 7.49 个绝对点(相对 +18.7%),比次优的 RepoFuse 高了 9.24 个绝对点。这说明检索质量和 base model 能力是相互强化的关系,retriever 给的 context 越对症,强模型越能用上。
第三——这点很重要——所有 baseline 在 CodeGen-350M 这种小模型上效果都很糟。Zero-Shot 才 4.04 EM,CCFinder 也只有 16.50。CodeRAG 在 350M 上能跑到 26.81,说明它的 context 工程做得是真的细。但反过来想,350M 这种规模的 code LLM 现在基本没人在生产里用了,主流场景是 7B+,所以更值得看右边那一栏。
4.2 CCEval 跨文件场景的稳定性
ReccEval 主要是文件内补全,CCEval 是另一个故事——它要求待补全的语句至少包含一次跨文件 API 调用,是更严酷的仓库级场景。
| Method | CodeGen-350M EM/ES | SantaCoder-1.1B EM/ES | StarCoder2-3B EM/ES | Qwen2.5-Coder-7B EM/ES |
|---|---|---|---|---|
| Zero-Shot | 2.70 / 43.02 | 4.35 / 46.52 | 6.53 / 48.56 | 11.11 / 52.19 |
| CCFinder | 10.58 / 48.65 | 14.63 / 53.44 | 21.08 / 58.11 | 24.80 / 59.52 |
| RG-1 | 8.78 / 49.54 | 12.83 / 53.78 | 17.78 / 57.74 | 22.51 / 61.84 |
| RepoCoder | 10.58 / 51.07 | 15.12 / 55.66 | 21.24 / 60.90 | 25.89 / 63.65 |
| DraCo | 12.83 / 50.71 | 19.70 / 57.17 | 26.68 / 62.11 | 30.69 / 65.46 |
| RepoFuse | 11.22 / 50.78 | 17.64 / 56.52 | 23.34 / 61.28 | 27.73 / 64.76 |
| CodeRAG-LLMR | 14.11 / 52.44 | 22.89 / 59.92 | 30.66 / 65.46 | 35.20 / 68.93 |
跨文件场景下 CodeRAG 依然稳——Qwen2.5-Coder-7B 上 35.20 vs DraCo 的 30.69,差距是 4.51 个绝对点(相对 +14.7%)。比 ReccEval 的优势小一些,但跨文件本来就是更难的任务,所有 baseline 的绝对值都掉下来了。
4.3 消融:到底是哪一部分在拉分
这是我最想看的表——三个 P 的解法,到底哪个最关键?
| 变体 | CodeGen-350M EM/ES | Qwen2.5-Coder-7B EM/ES |
|---|---|---|
| CodeRAGs(仅 sparse) | 22.07 / 51.31 | 39.89 / 59.46 |
| CodeRAGd(仅 dense) | 20.49 / 50.36 | 39.66 / 58.47 |
| CodeRAGd+s(sparse+dense) | 22.88 / 51.95 | 41.95 / 59.59 |
| CodeRAGdf(仅 dataflow) | 21.28 / 50.94 | 41.86 / 59.06 |
| CodeRAGdf+s(dataflow+sparse) | 24.21 / 53.01 | 44.21 / 62.36 |
| CodeRAGdf+s+d(三路全开,无重排) | 23.89 / 52.86 | 44.61 / 68.81 |
| CodeRAGdf+s+d+lr(三路+LLM reranker) | 26.81 / 55.54 | 47.48 / 70.82 |
几个关键发现:
多路检索带来的提升在中等规模模型上更明显。Qwen-7B 上从单 sparse 的 39.89 EM 到三路 + reranker 的 47.48 EM,提了 7.59 个绝对点。
Reranker 单独贡献了 2-3 个 EM 点。对比 df+s+d 的 44.61 和 df+s+d+lr 的 47.48,纯靠加 reranker 涨了 2.87 个点,这个增量比从单路升级到多路的增量还要大一些。说明 P3(retriever 和 LLM 错位)这个问题在工程上是真的存在,而且解决它的 ROI 很高。
我个人对这个消融比较 buy in 的一点是——它没有把所有提升都归给一个环节。如果 reranker 一上去就拉了 5 个 EM,反过来说"前面三路检索是不是有点冗余"。但实际数据是,三路检索本身就贡献了大头,reranker 是锦上添花。设计上看是合理且互补的。
4.4 蒸馏小 reranker 的代价
| Method (StarCoder2-3B) | EM | ES | EM (Identifier) | F1 |
|---|---|---|---|---|
| CodeRAG-LLMR (Qwen3-8B) | 43.31 | 68.54 | 51.10 | 65.78 |
| CodeRAG-DisR (Qwen3-0.6B) | 39.88 | 66.21 | 47.62 | 62.89 |
| 次优 baseline (DraCo) | 36.60 | 64.78 | 45.41 | 61.76 |
蒸馏到 0.6B 后掉了 3.43 个 EM 点(43.31 → 39.88),但还是比所有 baseline 高(DraCo 36.60)。这个 trade-off 在工程上很有用——0.6B 的模型可以本地跑,延迟小、成本低,3-4 个 EM 点的损失换来部署友好性,对生产场景是划算的。
4.5 检索 query 构造方法的对比
这是 P1 的消融——log probability 引导真的比"取最后 k 行"好吗?
| Query 构造方法 (Qwen2.5-Coder-7B) | EM | ES | EM (Identifier) | F1 |
|---|---|---|---|---|
| Jaccard 相似度选 chunk | 33.54 | 61.89 | 40.99 | 55.33 |
| 取最后 1 行 | 32.08 | 61.04 | 39.58 | 54.91 |
| 取最后 3 行 | 34.84 | 62.85 | 42.39 | 56.97 |
| 取最后 5 行 | 34.21 | 62.26 | 41.50 | 56.04 |
| 取最后 10 行 | 32.95 | 61.48 | 40.20 | 54.93 |
| CodeRAGs(log prob 引导) | 35.01 | 63.11 | 42.31 | 57.24 |
注意这个表只用了 sparse 检索路径,是为了隔离 query 构造方法本身的效果。
观察:
- 最后 k 行的最优选择是 k=3,再多反而不如;
- log probability 引导比所有 last-k 都好,但优势不算大,比 last_3 只高 0.17 个 EM 点;
- 跟 Jaccard(一种基于 query-chunk 相似度的 chunk 选择方法)比,log prob 引导有 1.47 个 EM 点的优势。
说实话,这一项的 gain 是这篇论文里我觉得最不显眼的——0.17 EM 的 gap 不算"显著领先"。如果只看 sparse 这一路,"取最后 3 行"几乎是同样好的方案,而且实现成本更低(不用跑一遍 CodeT5p-220m)。这个发现至少对工程同学是有用的:如果你只想做 sparse 检索的快速版本,"光标前 3 行"是个性价比很高的 baseline。
4.6 计算开销
| Method | 平均耗时(秒/query) |
|---|---|
| RepoCoder | 0.21 |
| DraCo | 0.04 |
| RepoFuse | 0.15 |
| CodeRAG | 0.23 |
CodeRAG 比 DraCo 慢了 6 倍——这是因为 DraCo 只有 dataflow 一路,不需要做相似度检索。和 RepoCoder 比基本持平。
CodeRAG 各步骤的细分:
| 步骤 | 耗时(秒) |
|---|---|
| Query 构造(log prob probing) | 0.14 |
| Sparse 检索 | 0.002 |
| Dense 检索 | 0.015 |
| Dataflow 检索 | 0.03 |
| Distilled Reranker | 0.06 |
最大开销在 query 构造阶段,因为要跑 220M 模型做 m 步生成。如果接受用 last_3 替代 log prob(看上面 4.5),这一步可以砍到几乎 0。这是一个纯工程上的选择:精度还是速度。
4.7 retain 多少个 reranked 片段
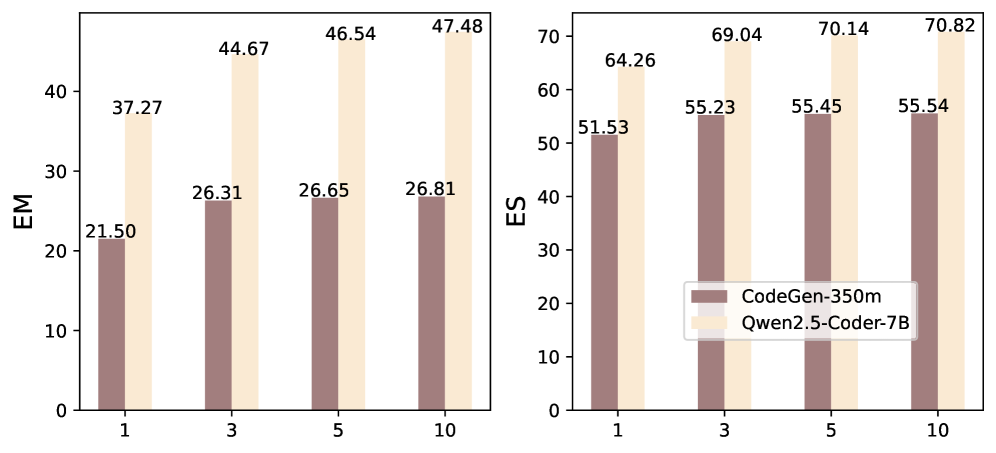
图7:u 从 1 增加到 10 的过程中 EM 和 ES 的变化。CodeGen-350M(深色)从 1→3 时增益最大(EM 21.50→26.31),3→5 已经放缓,5→10 几乎没动。Qwen2.5-Coder-7B(浅色)也是同样的曲线形状——u=3 是性价比拐点。
这个图我觉得对工程实践很有指导意义——如果你想压缩 prompt 长度,u=3 已经能拿到接近 90% 的最终性能,u=10 的边际收益很小。在大模型上下文成本不便宜的今天,这个发现可以直接转化成 token 预算。
五、人工评估:reranker 的排序到底好不好
仅看 EM/ES 没法直接验证 reranker 排出来的列表"质量"如何(有可能 reranker 排序不准但下游 LLM 把它救回来了)。所以作者请了 3 位 CS 硕士独立打分,1-5 分制,5 分最好。
三位评委的平均分:3.69 / 3.76 / 4.03
3.8 左右——不算特别高。这意味着 LLM reranker 的排序能力是"明显好于随机"但远未到完美。这个数对论文整体观点没有伤害,反而很诚实地告诉读者——reranker 还有提升空间,未来工作的方向是 retriever-LLM 联合训练。
我挺欣赏作者把这个真实数据放出来的——很多论文这一步要么不做要么粉饰,3.8 这个数据是论文 limitation section 提到的"misalignment 没有完全解决"的实证。
六、说说我的几个判断
6.1 这篇论文最值钱的地方
不是哪个单点创新——CodeRAG 的所有组件单独拿出来看都不算"震惊体": - log probability 当相关性指标,QA RAG 里早就有人玩过; - 多路检索的并联,Hybrid Retrieval 是 IR 领域的老套路; - BestFit prompting + 堆排序,骨子里是 pairwise reranking 的工程优化版; - LLM reranker 蒸馏到小模型,Cross-Encoder 蒸馏的玩法在 retrieval 领域很常见。
它的价值在于"系统性地把这套方法体系搬进 code 这个领域"。在这之前的 RepoCoder、DraCo、RepoFuse 都只 hit 了 P1/P2/P3 中的一两个,CodeRAG 是第一个把三个问题一起拎出来打包解决的。
而且效果数据是真的能打——Qwen2.5-Coder-7B 上 EM 提升 7-9 个绝对点,这个幅度在 code completion 这个已经被卷过几轮的方向上,是实打实的进步。
6.2 我有几点想吐槽
第一,P1 的解法 ROI 不高。从 4.5 的对比表看,log probability 引导比 last_3 只高 0.17 EM 点,但延迟从近乎 0 涨到了 0.14 秒(占总开销的 60%)。这个 trade-off 是不是值得,需要打个问号。
如果让我做工程落地,我会先用 last_3 做 baseline,多路检索 + reranker 才是收益最大的两个升级点。
第二,消融表少了一个关键 setting——"只用 LLM reranker,不做多路检索"。也就是说,光拿 sparse + reranker 跟 sparse + dense + dataflow + reranker 比,看看 reranker 是不是已经能把单路检索的不足补回来。这个对比对工程师选型很有价值,但论文没给。
第三,3 位评委 3.8 分的人工评估说明 reranker 还远谈不上"对齐"了 code LLM 偏好。论文 limitation 里也承认了这一点。后面如果有人能把 retriever 和 code LLM 做联合训练(比如类似 RAFT、KAR-RAG 那一套),可能还有 3-5 个点的空间。
第四——这是我个人的喜好——TF-IDF 在 2025 年还是 sparse retrieval 的默认选项有点保守。BM25 在很多场景上比 TF-IDF 稳,论文 baseline 里 RG-1 用的是 BoW,CodeRAG 自己用的是 TF-IDF,没看到 BM25 的对比。这个细节不影响结论,但作为读者会有点好奇。
6.3 对工程的启发
如果你团队正在做仓库级 code completion 或者类似 Cursor/Copilot 这种 IDE 内补全,下面几点可以直接拿走:
- 三路并行检索是值得搭的——不需要发明新检索算法,把现有的 sparse + dense + dataflow 接成 hybrid 就行。这一步 ROI 最高。
- 加一个 reranker,BestFit + 堆排序的设计很值得抄——比 listwise 稳、比 pointwise 准。Qwen3-8B 是个好用的开源 reranker。
- 如果延迟敏感,蒸馏到 0.6B——CodeRAG 报告掉 3-4 个 EM 点,但还是高于所有 baseline。
- u=3 已经够用——如果你 prompt 预算紧,retain 3 个最相关的代码片段,性价比拐点。
- query 构造可以从 last_3 起步——log probability 引导带的提升不大,工程上可以放到 P2。
6.4 跟同期工作的位置
同期还有像 GraphCoder(liu2024graphcoder)和 GraphCodeAgent(同名的另一篇 arXiv 论文)也在做类似方向,但思路不同——前者重在用 control-flow / data-dependency 图建模代码上下文,后者重在用 LLM agent + 双图引导的多跳推理。
CodeRAG 跟它们的区别在于——它没有发明新的图结构或者新的 agent loop,而是认认真真在 RAG 三个传统环节上各做一件正确的事。在我看来这是更"工程化"也更"易复现"的路线,对没有大量算力做 agent 多轮交互的团队更友好。
七、收尾
代码补全这个领域有一种"看起来已经被卷烂了"的错觉——HumanEval 都 92% 了还有什么好做的?但 CodeRAG 这种工作提醒我们,真实仓库级的场景跟函数级 benchmark 完全是两码事。把视角从"模型本身"挪到"模型周围的 context 工程",还有大把可以挖的空间。
这篇论文如果让我打分,结构上 9 分(三个 P 的对应解法很对位),技术深度 7.5 分(每个组件都不算颠覆性创新但组合得当),实验充分度 8.5 分(两个 benchmark + 4 个 code LLM + 完整消融,还是少了一点 setting),工程可用性 9 分(代码已开源、蒸馏模型 0.6B 可以本地跑)。
总体上是这种"读完想动手抄一抄"的论文——而不是"读完只能写个公众号文章"的那种。如果你做仓库级补全相关的方向,强烈建议把 CodeRAG 的代码 clone 下来跑一遍。
参考资料
- 论文:CodeRAG: Finding Relevant and Necessary Knowledge for Retrieval-Augmented Repository-Level Code Completion (arXiv:2509.16112)
- 代码:github.com/KDEGroup/CodeRAG
- 同期相关工作:DraCo (Cheng et al., ACL 2024)、RepoFuse (Liang et al., 2024)、RepoCoder (Zhang et al., EMNLP 2023)、GraphCoder (Liu et al., 2024)
- benchmark:ReccEval(DraCo 提出)、CCEval (Ding et al., NeurIPS 2023)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我