CODI:让模型把思维链"塞"进连续空间,6 个隐向量顶 20 个 token
核心摘要
显式 CoT 让大模型推理能力起飞,但代价是一堆"用来沟通而不是用来计算"的废话 token。把 CoT 完全搬到连续空间里推理这件事,业界尝试过——CommonsenseQA、Coconut 这一路下来效果一直追不上 CoT-SFT,差距动辄十几个点。CODI 这篇论文给出了一个挺漂亮的方案:让同一个模型同时扮演老师(显式 CoT)和学生(隐式 CoT),通过对齐"答案前那个冒号 token"的隐藏状态,把推理能力从语言空间蒸馏到连续空间里。GPT-2 上做 GSM8k,CODI 拿到 43.7%,CoT-SFT 是 44.1%——基本打平,3.1 倍压缩、2.7 倍加速;比之前的 SOTA Coconut 相对涨了 28.2%。这是第一个在小模型尺度上真正追平显式 CoT 的隐式 CoT 方法,思路简洁,工程上也是可复现的尺度。值不值得读?如果你在做推理加速、Latent Reasoning 或者 LRM 后训练,这篇必看。
论文信息
- 标题:CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
- 作者:Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, Yulan He
- 机构:King's College London、The Alan Turing Institute
- 会议:EMNLP 2025
- arXiv:2502.21074v3
- 代码:github.com/zhenyi4/codi
一个一直没解决好的问题:CoT 太啰嗦
你有没有这种感觉——让模型解一道四则运算题,它会先把题面复述一遍,再像小学生一样"我先算这个、再算那个、所以答案是……",最后才吐出真正的数字。
这套 CoT 范式好用,是因为它给了模型一个外化的草稿纸。Wei 那篇 CoT 论文之后,几乎所有推理 benchmark 都靠这个吃饭。但代价是真的不小:解一道 GSM8k 的题平均要生成几十个 token,而真正承载"计算"的 token 可能只有那几个等式右边的数字。剩下的全是"verbal padding"——用来凑句子语法、用来让人类看着舒服的衔接词。
Li 等人 2024 的论文里讲过一个观察:CoT 里大量 token 是用来 communicate 而不是用来 compute 的。你想想看,如果模型在隐藏空间里就能完成推理,何必非要把每一步翻译成"so we have... therefore..."这种外化语言?
这个朴素的直觉,催生了一整条 implicit CoT 的研究路线。
之前的工作走到哪一步了
我整理了一下时间线:
| 方法 | 核心思路 | 致命问题 |
|---|---|---|
| Pause Token (Goyal et al. 2024) | 在生成答案前加几个空白 token,让模型多算一会儿 | 提升幅度小,需从头预训练 |
| iCoT (Deng et al. 2024) | 课程学习——逐步从 CoT 里抠掉 token,让模型把推理"内化"到激活里 | 训完后基本退化为 No-CoT,扛不住放大模型 |
| Coconut (Hao et al. 2024) | 同样课程学习,但改成自回归地传递隐状态作为"continuous thought" | 比显式 CoT 还是差十几个点,作者归因于课程学习的灾难性遗忘 |
到 Coconut 这一步,思路其实已经很清楚了——把 CoT 压缩到连续空间里,跑 6 个隐向量代替 20 多个 token。但就是有个性能 gap 关不上:Coconut 在 GPT-2 上做 GSM8k 拿了 34.1%,CoT-SFT 拿了 44.1%。差了整整 10 个点。
说实话,看到这个 gap 我是有点皱眉的。理论上隐藏空间的表达能力应该更强(每个连续向量是 \( \mathbb{R}^d \) 而非词表的一个 one-hot),怎么会反而打不过显式 CoT?
CODI 的作者把这个问题归结为课程学习的遗忘——你一开始让模型学完整 CoT,然后慢慢把 CoT 的前几个 token 替换成连续向量,每替换一次就要重新适应一次。这种 stage-by-stage 的训练范式,跨阶段的 forgetting 是出了名的难解决。
那能不能不要课程学习?一步到位?这就是 CODI 想回答的问题。
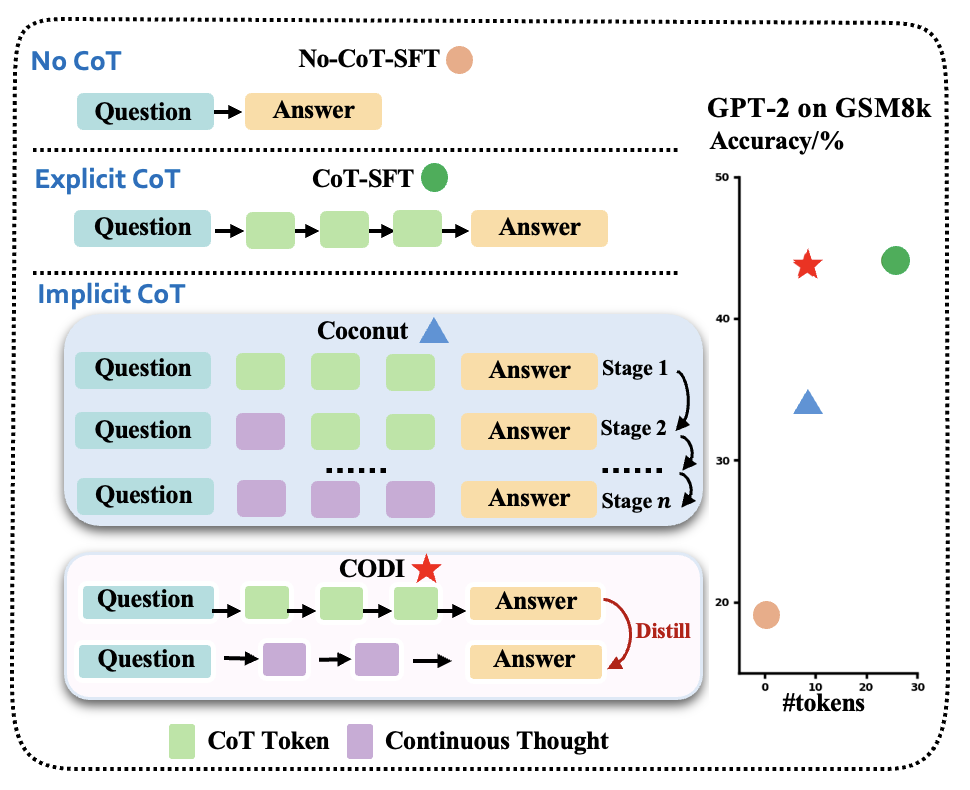
图1:四种推理范式的对比图。右边是 GPT-2 在 GSM8k 上的准确率,CODI(红色五角星)几乎贴着 CoT-SFT(绿色圆),而 Coconut(蓝色三角)落在中间——这一图就讲完了 CODI 的定位
CODI 的核心想法:让模型自己当自己的老师
我看到 CODI 的方法图时,第一反应是——"这不就是知识蒸馏?" 但仔细看下来,它有几个细节挺巧妙的,值得拆开聊聊。
一句话讲清楚 CODI 在做什么
同一个 LLM,同时跑两条 forward path:
- 老师路径:吃
[Question, CoT, "The answer is:", Answer],标准 CoT-SFT,cross-entropy loss - 学生路径:吃
[Question, <bot>, z₁, z₂, ..., z₆, <eot>, "The answer is:", Answer]——把 CoT 文字段替换成 6 个 learnable 的连续向量z_i,每个z_i都是上一步隐藏状态自回归生成出来的
然后,把老师在"冒号"那个位置的隐藏状态,蒸馏给学生在同样位置的隐藏状态。
就这么简单。没有课程学习,没有逐步替换,单阶段端到端训练。
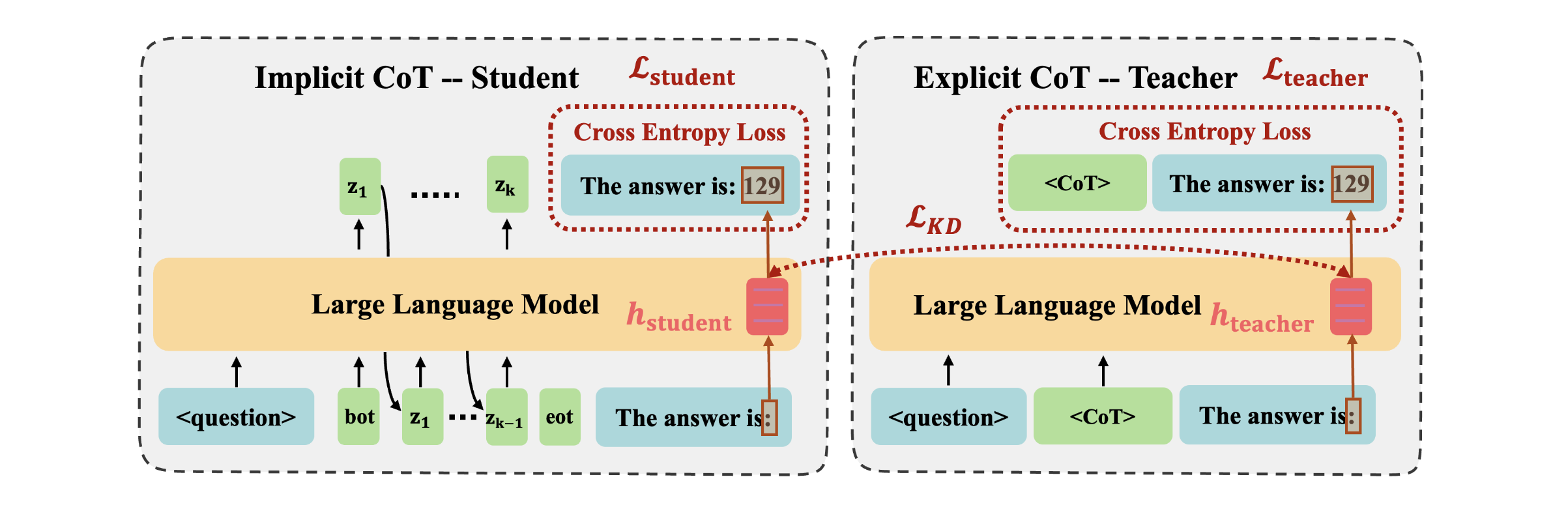
图2:方法架构图。注意 L_KD(中间那条红线)只对齐冒号那一个 token 的隐藏状态,不对齐 CoT 部分——这个设计其实挺关键的
三个 Loss 的组合
整体训练目标是个加权和:
其中: - \(\mathcal{L}_{\text{student}}\):学生路径上对最终答案 token 的 cross-entropy - \(\mathcal{L}_{\text{teacher}}\):老师路径上对 CoT + 答案的标准 cross-entropy - \(\mathcal{L}_{\text{KD}}\):核心创新——L1 loss 对齐两条路径在某个特定 token 位置上所有层的隐藏激活
GPT-2 上三个权重都设为 1;LLaMA-1b 上 \(\beta\) 调到 20,因为它的蒸馏 loss 数量级要小一个数量级。
为什么是冒号?这才是真正有意思的地方
最让我觉得这篇论文有想法的地方,是它对蒸馏哪个 token 的选择。
直觉上你会想:要么对齐所有 token 的激活(信息量最大),要么对齐 CoT token 的激活(最能代表推理过程)。
CODI 的选择都不是。它只对齐答案前那个冒号——The answer is: 末尾那个 :。
为什么是它?作者用了个挺漂亮的理论推导(附录 B)。简化一下核心结论:
考虑 transformer 在最后那个冒号位置 q 的注意力激活。如果输入里有 CoT rationale R,那么这个位置的激活可以分解为:
第一项是没有 CoT 时的"基线激活";第二项是 CoT 给这个位置带来的激活漂移(hidden activation shift)。
这个分解告诉你一件事:CoT 对最终答案的所有贡献,都浓缩在了答案前一个 token 的激活漂移里。Orgad 等人 2025 那篇 ICLR 关于 LLM 内部表示的论文也指向同一个观察——"模型其实知道得比它说出来的多",而这些隐式知识就编码在答案前一两个 token 的激活里。
CODI 利用了这个性质:与其让学生在每个位置都模仿老师(计算开销大、信号噪声大),不如只在最关键的那个 token 上做对齐。学生不需要 CoT 文字,但只要它的"冒号"激活和老师的"冒号"激活足够接近,那么后续生成答案的能力就是等价的。
这个想法的优雅之处在于,它把 CoT 的本质定义为"对答案 token 的激活漂移"——一个非常清晰、可优化的代理目标。
一些训练上的"工程细节"
我看代码时注意到几个挺细的东西:
1. 训练时排除最后一步 CoT
GSM8k-Aug 的 CoT 长这样:<<10÷5=2>><<2×2=4>><<6×4=24>>,最后一步往往直接给出答案。如果蒸馏时把这一步留给老师看,老师就会学会一个 shortcut——直接从最后一个 CoT token 抄答案到冒号位置。这样老师的激活就不再编码"完整推理过程",而是退化成"答案的副本"。
消融实验里,保留最后一步 CoT 会让准确率从 43.7% 掉到 31.7%——掉了 12 个点。这个细节真的挺要命的。
2. 跨层归一化
不同层的隐藏激活范数差异极大。CODI 的做法是用老师当前 batch 内每层激活的标准差对 L1 loss 做归一化。这个 trick 在 Deng 2023 的 implicit CoT 论文里也用过,是个比较稳的工程实践。
3. Stop-gradient
蒸馏 loss 上对老师那一侧加 stop-gradient:
这是为了保证知识单向流动——只让老师影响学生,不让学生反过来"污染"老师。这是个基础操作,但在自蒸馏里很容易忘。
4. Projection MLP
学生路径的连续向量 z_i 在送到下一步之前,会过一个两层 MLP + LayerNorm 做投影。论文说这是为了"区分潜在空间和 token 空间"。消融里去掉投影只掉了 1.2 个点(43.7% → 42.5%),这个组件不算关键,但能稳定训练。
实验结果:第一个真正追平显式 CoT 的隐式 CoT 方法
好,现在到了见真章的时候。CODI 到底打出了什么样的数?
主实验
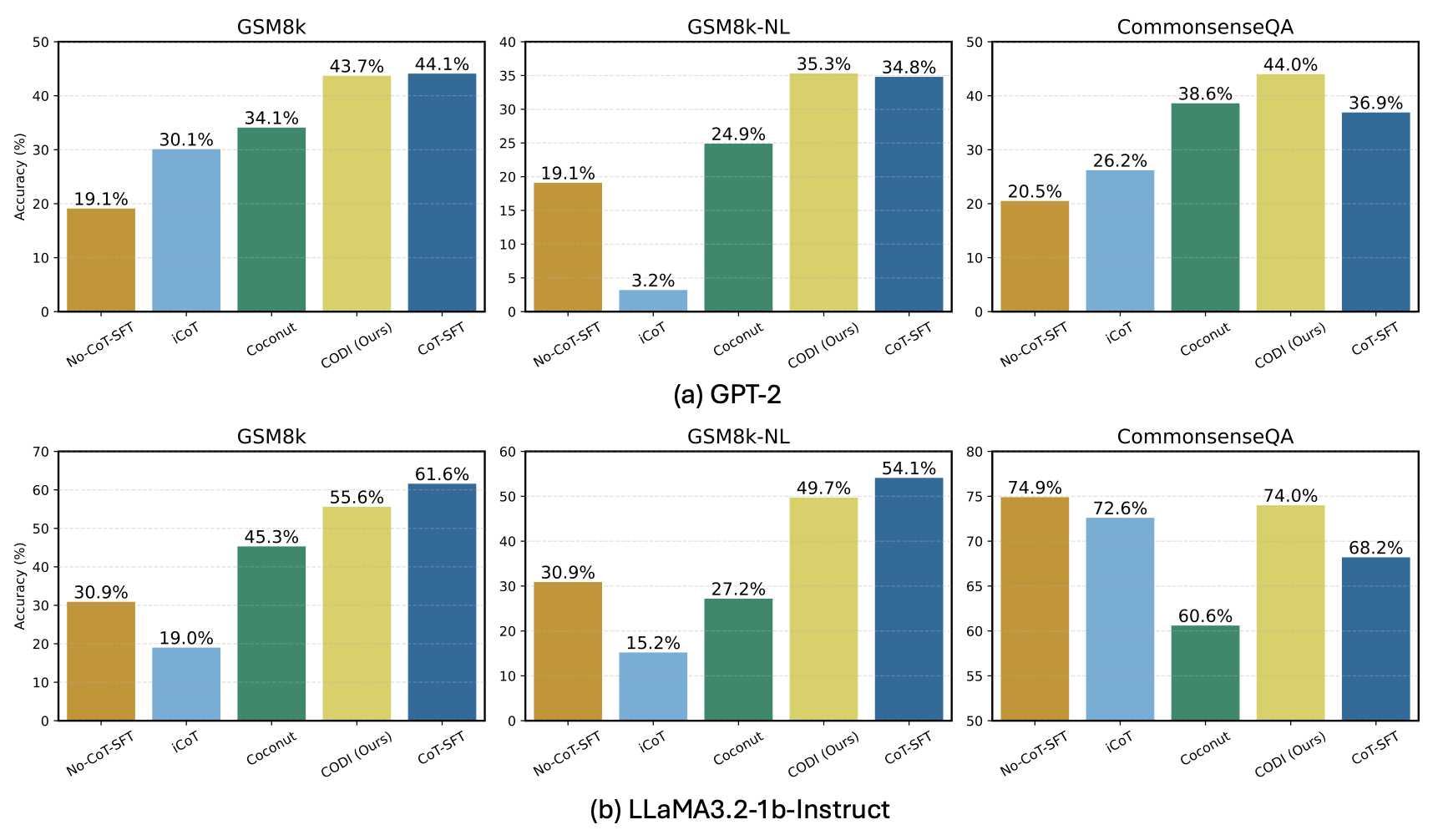
图3:CODI(黄色)在所有数据集上都把之前的 implicit CoT 方法(iCoT 浅蓝、Coconut 绿)拉下一大截。在 GPT-2 + GSM8k 上,CODI 拿到 43.7%,几乎追平 CoT-SFT 的 44.1%;在 GSM8k-NL(带自然语言的 CoT)上甚至反超了 CoT-SFT
我把关键数字整理成表,方便看:
| 数据集 / 模型 | No-CoT-SFT | iCoT | Coconut | CODI | CoT-SFT |
|---|---|---|---|---|---|
| GSM8k / GPT-2 | 19.1 | 30.1 | 34.1 | 43.7 | 44.1 |
| GSM8k / LLaMA-1b | 30.9 | 19.0 | 45.3 | 55.6 | 61.6 |
| GSM8k-NL / GPT-2 | 19.1 | 3.2 | 24.9 | 35.3 | 34.8 |
| GSM8k-NL / LLaMA-1b | 30.9 | 15.2 | 27.2 | 49.7 | 54.1 |
| CommonsenseQA / GPT-2 | 20.5 | 26.2 | 38.6 | 44.0 | 36.9 |
| CommonsenseQA / LLaMA-1b | 74.9 | 72.6 | 60.6 | 74.0 | 68.2 |
几个值得停下来想想的发现:
第一,GPT-2 上 CODI 几乎贴着 CoT-SFT。43.7% vs 44.1%,差 0.4 个点——在 GSM8k 这种波动可能 1 个点的数据集上,这就是打平。Coconut 那 10 个点的 gap 被填上了。
第二,GSM8k-NL 上 CODI 反超 CoT-SFT(GPT-2: 35.3% vs 34.8%)。这其实有点反直觉。我的理解是:自然语言版的 CoT 噪声更大,GPT-2 这种小模型学不动这种 verbose 的语言模式,反而会被带偏;而 CODI 不模仿语言,只对齐激活,避开了这个陷阱。
第三,iCoT 在 GSM8k-NL 上崩了(GPT-2 3.2%,LLaMA-1b 15.2%)。这个数据其实挺打脸的——课程学习路线在长 CoT 上根本撑不住,作者的"遗忘问题"假设有了实证。
第四,CommonsenseQA 上 LLaMA-1b 用 CoT 反而掉点(CoT-SFT 68.2% < No-CoT-SFT 74.9%)。这是个有意思的现象:当训练 CoT 是用 GPT-4o-mini 生成的,就强行让 LLaMA 学一种它不熟悉的推理模式,反而会破坏原有的语言知识。CODI 既受益于 CoT 监督,又不用模仿具体的语言模式,所以能保持 74.0%。
28.2% 的相对提升从哪来
abstract 里写"outperforming the previous state-of-the-art by 28.2% in accuracy"。我刚开始没看懂,算了一下:CODI 43.7% vs Coconut 34.1%,相对提升 (43.7-34.1)/34.1 = 28.2%。对,就是 GPT-2 上 GSM8k 这个数。
这个数字本身没什么水分——Coconut 和 CODI 用的训练数据、基础模型、连续 token 数都一样,能比的就是训练框架本身。
OOD 鲁棒性
CODI 在 GSM8k-Aug 上训练,然后直接放到 SVAMP、GSM-Hard、MultiArith 上裸测:
| GPT-2 | SVAMP | GSM-Hard | MultiArith |
|---|---|---|---|
| No-CoT-SFT | 16.4 | 4.3 | 41.1 |
| CoT-SFT | 41.8 | 9.8 | 90.7 |
| Coconut | 36.4 | 7.9 | 82.2 |
| CODI | 42.9 | 9.9 | 92.8 |
GPT-2 上,CODI 在三个 OOD 数据集上全部超过了 CoT-SFT。SVAMP 涨 1 个点、GSM-Hard 涨 0.1 个点、MultiArith 涨 2 个点。LLaMA-1b 上则没全面反超 CoT-SFT,但还是把 Coconut 拉下来一大截。
作者把这个归因为"软先验"——连续向量没有显式的模仿目标,所以不容易过拟合到训练 CoT 的 surface pattern 上。这个解释我觉得是站得住脚的。同样的机制在 prompt tuning(Lester 2021)那边也观察到过——continuous prompt 比 discrete prompt 更鲁棒。
效率:3.1 倍压缩、2.7 倍加速
CODI 用 6 个连续 token + 2 个特殊 token = 8 个"思考 token"。GSM8k-Aug 平均 CoT 长度是 20.3 个 token,所以压缩比是 20.3/(8) ≈ 3.1×;推理时间上是 2.7× 加速。
GSM8k-Aug-NL 平均 CoT 是 65.5 个 token,同样 8 个思考 token,压缩比飙到 8.2×,推理加速 5.9×。
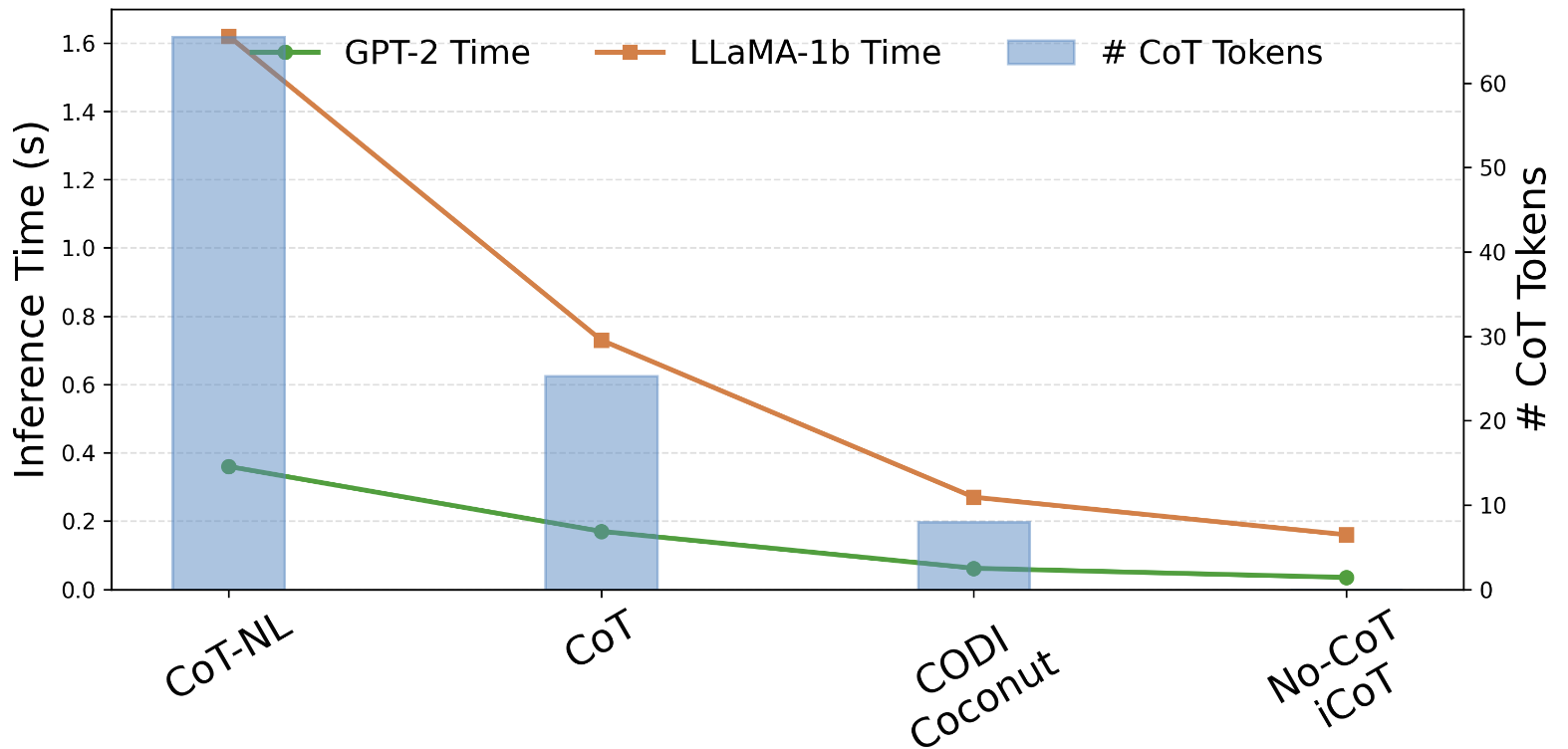
图4:效率对比。在 GSM8k-Aug-NL 上长 CoT 越长,CODI 加速比越大——这是显然的,因为 CODI 的"思考 token"数固定为 8,分母不变
这里有个值得注意的点——最优的连续 token 数是 6,不是越多越好。多于 6 反而掉点。作者认为 6 大致对应 GSM8k 的平均推理步数,多了就是冗余的优化负担。这个观察其实挺工程化的——你不需要一个 universal 的 latent token 数,需要根据数据集 CoT 平均长度来定。
消融实验
消融表(GPT-2 上):
| 配置 | 准确率 |
|---|---|
| No-CoT-SFT | 19.1% |
| CODI | 43.7% |
| separate static teacher(独立预训练老师) | 27.1% |
| w/ multitask student(学生也学显式 CoT) | 42.2% |
| w/o L1 loss(去掉蒸馏 loss) | 24.5% |
| w/ CoT last step(保留最后一步 CoT) | 31.7% |
| w/o Projection(去掉投影 MLP) | 42.5% |
挑几个有信息量的:
自蒸馏 vs 独立老师:用单独训练的老师模型,效果反而掉到 27.1%。这有点反常识——按理说一个训得更好的老师应该带来更强监督。但作者解释说,学生需要先具备做显式 CoT 的能力,再压缩到连续空间才有意义;如果老师学生权重不共享,学生根本没机会"先学走再学跑"。"w/ multitask student"(让独立学生也学一份显式 CoT)能把性能拉回 42.2%,验证了这一点。
去掉 L1 loss 掉了 19 个点(43.7→24.5)。这个数字是核心创新的"价值证明"——没有蒸馏 loss,自蒸馏框架就退化成普通的多任务学习,连续 token 没人监督,跟瞎转没区别。
保留最后一步 CoT 掉 12 个点——前面分析过,这是 shortcut 问题。
可解释性:连续向量真的在"算"东西
我承认看到 implicit CoT 这种方法时,第一反应总是"模型在隐藏空间到底在做什么?"——很难验证它是真的在做推理还是在做某种 pattern matching。
CODI 在这一块给出了相当扎实的实证。
把 z_i 投影回词表空间
每个连续向量 z_i 本质是 \( \mathbb{R}^d \) 里的一个点。如果用模型的 LM head(也就是 word embedding)把它投影回词表,找最相近的 token,会看到什么?

图6:每个 z_i 的 attended tokens(注意力权重最高的 10 个 token)和 decoded tokens(投影回词表后 top-5)。可以看到 z_2 attends 到 "4"、"
这个可视化很有说服力。连续向量虽然没有显式的语言形式,但它的注意力模式和投影结果都暗示了:模型在用连续 token 存储中间计算结果。
更进一步,作者统计了一个量化指标:在 CODI 答对的题目里,能从连续向量 decode 出的中间结果与 ground-truth CoT 的中间结果的匹配率:
| 题目步数 | 1 | 2 | 3 |
|---|---|---|---|
| 解码匹配率 | 97.1% | 83.9% | 75.0% |
单步题里 97% 的中间结果能被解码出来。即使是 3 步题,也有 75%。这不是"模型记住了答案"——是"模型在连续空间里真的算了一遍"。
一个有意思的发现
附录 D 里有个挺打脸的实验。作者把 CODI 解码出来的中间结果当作合成 CoT,重新训一个 GPT-2("Res"),看它能不能达到 CODI 的水平:
| GPT-2 训练数据 | 准确率 |
|---|---|
| No-CoT-SFT | 19.1% |
| 用 CODI 解码的中间结果当 CoT | 34.0% |
| 加上运算符当 CoT | 35.7% |
| CODI 自己 | 43.7% |
合成版 CoT 训练的 GPT-2 也就 35% 左右——比 No-CoT 强,但差 CODI 整整 8 个点。说明 CODI 的连续向量编码的信息比"中间结果 + 运算符"还多——可能是某种我们用语言无法表达的中间状态。
这是我觉得这篇论文最有想象空间的发现。CoT 的"语言瓶颈"假设一直存在——某些推理过程是没法用人类语言完整描述的。CODI 给出了一个具体的实例:连续向量装得下比 token 更丰富的信息。
我的判断:这篇论文好在哪、还差什么
读完整篇我的感受是——这是一篇在小尺度上把一个老问题做透了的论文。亮点和局限都比较明显。
亮点
第一,思路简洁得让人怀疑"这么简单为啥之前没人做"。自蒸馏不是新东西,多任务学习也不是,激活对齐也不是。但是把"冒号 token 的激活漂移就是 CoT 的本质"这个观察跟自蒸馏框架结合起来——这个组合是真的没人做过。CoT shift 的理论分析(附录 B)虽然有点 hand-wavy,但给了核心设计一个理论支撑。
第二,实验做得扎实。不是只在 GSM8k 上刷了一个数就完事,而是覆盖了: - 两种基础模型(GPT-2、LLaMA-1b) - 三种训练数据(数学符号 CoT、自然语言 CoT、常识推理 CoT) - 三个 OOD 数据集(SVAMP、GSM-Hard、MultiArith) - 完整的消融(蒸馏 loss、最后一步 CoT、自蒸馏 vs 独立老师、投影层) - 可解释性的量化指标
这是个相当完整的实验矩阵。
第三,把 implicit CoT 的"性能 gap"问题第一次合上了。之前从 Pause Token 到 iCoT 到 Coconut,每一篇都说"我比上一篇强",但都没追平显式 CoT。CODI 在 GPT-2 上拿到 99% 的 CoT-SFT 性能,这是质变。LLaMA-1b 上还没完全合上(90% 左右),但已经是这条路线最好的结果。
局限和我有点皱眉的地方
第一,规模问题。GPT-2 (124M) 和 LLaMA-1b 都是小模型。Geiping 等人 2025 那篇 latent reasoning 论文做到了 3.5B、800B token,但他们是预训练。CODI 是后训练框架,没在更大模型上验证过。说实话我不太确定 8B / 70B 这种尺度上自蒸馏还能不能撑住——更大的模型可能本身就具备了更好的内部表示,蒸馏的边际收益可能下降。这是一个值得看 follow-up 的点。
第二,OOD 上 LLaMA-1b 还是输给 CoT-SFT。SVAMP 上 61.1 vs 66.7、GSM-Hard 上 12.8 vs 15.6——差距虽然不大但确实存在。CODI 在 GPT-2 上反超是因为 GPT-2 本身做语言 CoT 就很差,CODI 反而避开了这个短板。LLaMA-1b 自带的语言能力够强,CoT-SFT 在 OOD 上还是有优势。
第三,对蒸馏 token 的选择有点 ad-hoc。作者选了答案前的冒号,附录 G 也证明换成其他 prompt 设计(比如 "Answer:"、"the answer is:")效果差不多。但这个鲁棒性其实只测了非常相似的 prompt 模板,换到完全不同的任务结构(比如多轮对话、代码生成)能不能找到合适的"漂移 token",论文没说。
第四,一个我自己也没完全想通的地方——既然 self-distillation 把 explicit CoT 的能力压到了"冒号"那一个 token 的激活上,那为什么还需要 6 个连续 thought token?理论上 1 个就够了?作者解释说 6 大致对应 CoT 步数,但这个解释和"激活漂移"框架有点张力——按激活漂移理论,单点对齐就够了;按多步推理理论,需要展开成链。两者怎么协调,论文没讲清楚。
跟同期工作放一起看
这一阵 latent reasoning 这条赛道挺热闹的。除了 CODI,还有几个值得对比的工作:
- Coconut(Hao et al. 2024):直接对手,CODI 主要打它
- SoftCoT(Xu et al. 2025):也用 soft token,但还是依赖显式 CoT 生成
- Token Assorted(Su et al. 2025):混合 latent token 和 text token
- Geiping et al. 2025:纯预训练路线,循环深度 transformer,3.5B 规模
CODI 和这些工作的差异在于:它是纯隐式 + 后训练,可以挂在已有的预训练模型上,不需要改架构、不需要预训练。从工程落地的角度,门槛是最低的。
工程上的启发
如果你在做 LRM (Latent Reasoning Model) 后训练,CODI 的几个 trick 是可以拿来用的:
- 自蒸馏框架:同一个模型当老师和学生,避免维护两份权重,省一半显存
- 单 token 蒸馏:不要试图对齐所有激活,找到"瓶颈 token"对齐就够了
- 去掉最后一步 CoT:避免 shortcut,是个隐藏的工程坑
- 跨层激活归一化:不同层范数差异巨大,做 L1/L2 距离前一定要归一化
如果你在做推理加速:3.1× 压缩、2.7× 推理加速这个数字虽然在 GPT-2 上得出,但思路是模型无关的——核心是让模型在更少的"思考预算"里完成等量的推理。这个范式跟最近一些 "dynamic compute" 工作(比如 sparse mixture-of-depths)也能配合。
收尾
CODI 这篇论文我觉得在 implicit CoT 这条线上是个里程碑——第一次把性能 gap 真正合上了,而且方法本身简单到一看就懂、一跑就 work。它的核心洞察"CoT 的本质是答案前一个 token 的激活漂移",可能比方法本身更有价值——这是一个对 CoT 工作机制的全新理解角度。
往后看,我觉得有两个值得期待的方向:
一是规模。当前 1B 内验证完成,下一步显然是 7B / 13B 甚至更大。Geiping 那篇预训练路线已经证明了大规模 latent reasoning 是 work 的,CODI 这种后训练范式能不能跟上是关键。
二是和 RL 结合。当前 CODI 是纯监督学习的蒸馏,但 implicit CoT 天然适合做 RL 的"思考预算优化"——同一个问题用更少的连续 token 解出来,本身就是个可以优化的目标。这块如果能跟 GRPO/PPO 这类 RL 方法结合,可能能榨出更多性能。
如果你在做推理加速、Latent Reasoning、或者后训练框架设计,这篇值得花一两个小时认真读一遍。代码也开源在 github.com/zhenyi4/codi,复现门槛不算高(GPT-2 单卡 A100 36 小时就能跑完)。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我