三套 Prompt 互相甩锅,怎么调?三星 × GMU 把记忆 Agent 的 APO 做成可落地闭环
调过带记忆模块的对话 Agent 的人,多半都体会过一种「精分」时刻:用户那句回复明显不对劲,但你回看日志——写记忆的 prompt 看起来正常,读记忆的 prompt 也正常,生成那一段拎出来读甚至挺漂亮的。三个模块各自一切正常,合在一起就是不行。你想做 automatic prompt optimization(APO)让 LLM 自己改 prompt,又发现一个更扎心的问题:最终回复差,到底是写错了、读错了、还是生成的时候没用好?没有归因,APO 等于在黑暗里抡锤子。
EMNLP 2025 Industry Track 这篇 Samsung × George Mason 的工作,正面啃的就是这块骨头。
核心摘要
痛点很具体:记忆增强对话 Agent 不是「一次 LLM 调用」,而是 memory-write / memory-read / generation 三套 prompts 串起来的链路;任何一环塌了都体现在最后那句话上,端到端的「好/坏」反馈根本指挥不动 APO。
作者的方案分三层:用 LLM 做带归因的评估器,每条样本不仅给 0–2 的分数,还会指认是写、读、还是生成模块出了问题;用 LLM 同时改三套 prompts,把 error attribution 直接喂进 APO;用凸优化做主动采样,把有限的人类标注预算和 APO 样本预算花在最有信息量、且整体分布均衡的样本上。
效果上,固定 5% 人类预算 + 5% APO 预算的最苛刻设置下,HealthCoaching 的 Personalization 从无 APO 起点 1.58 涨到 1.85,HealthBench 从 1.62 涨到 1.89——0–2 分制下的渐进式改进,但 baseline(Random / Coreset)确实被稳定压住。
我的判断:这篇论文最值钱的不是某个数学定理,而是把 multi-agent prompt 工程当成一个完整的系统问题去拆——评估、归因、采样、优化四个动作必须耦合,缺一块就整体掉链子。如果你正在做带记忆的客服/健康助手/教练 Agent,这套思路比再读十篇单轮 APO 论文有用。局限也很直白:评估器仍是 LLM,医疗场景上线还得另外谈合规与安全。
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | Data-Efficient Automatic Prompt Optimization for Memory-Enhanced Conversational Agents |
| 作者 | Ervine Zheng, Yikuan Li, Geoffrey Jay Tso, Jilong Kuang |
| 机构 | \(^{1}\)Samsung;\(^{2}\)George Mason University |
| 会议 | EMNLP 2025 Industry Track(November 2025, Suzhou) |
| 页码 | 1793–1804 |
| Anthology | 2025.emnlp-industry.126 |
| PDF 链接 |
提一句检索小坑:标题里是 Automatic Prompt Optimization,不是 Active——「主动」体现在方法内部的 active sampling(人类标注 + APO 样本的选择性抽取)。如果你按 "Active Prompt Optimization" 搜,会和这篇擦肩。
为什么单轮 APO 套不到记忆 Agent 上?
三套 prompt 把搜索空间「乘起来」了
经典 APO 的设定(论文式 (4))非常干净:
输入是一个 prompt \(z_{\mathrm{old}}\)、一批「用户消息 → 回复 → 评分」三元组,让 LLM 改出一个更好的 \(z_{\mathrm{new}}\)。这套范式在单轮任务上跑得很顺。
记忆增强 Agent 不是这个长相。论文 Figure 1 把流水线画得很清楚:
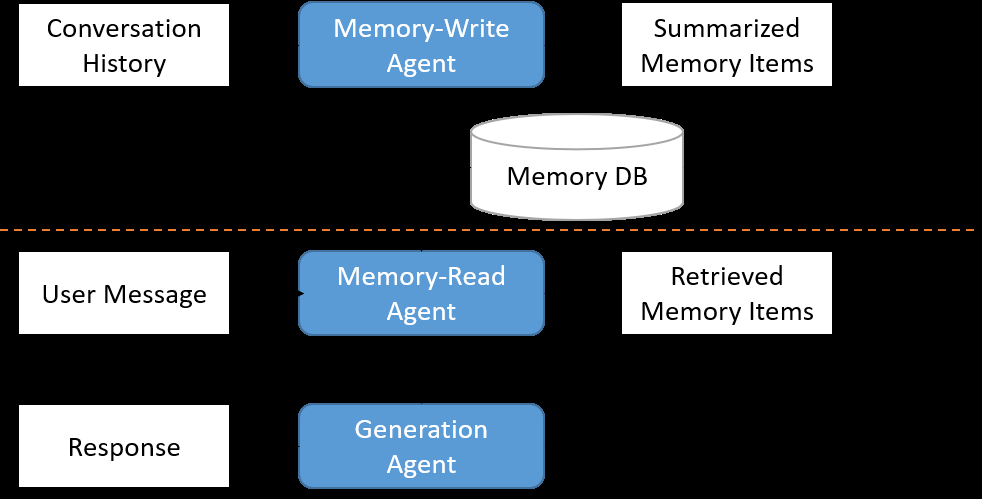
图1:左侧 Memory Writing 把对话历史压成结构化记忆条目入库;右侧 Memory Reading 在新一轮对话里按用户话语去捞相关记忆,再交给 Response Generation 揉进最终回复。三套 prompts 共用一个 Memory DB——这就是后面所有麻烦的根源。
形式化来讲(论文式 (5)),APO 的对象从一个 prompt 变成了 \(Z = \{z_{\mathrm{read}}, z_{\mathrm{write}}, z_{\mathrm{generation}}\}\) 三套 prompts,喂给 APO 的样本里也得多塞两个变量:写到了什么、读到了什么。
这里多出来的 \(a\) 是 error attribution——告诉 APO 这条样本失败时,矛盾出在 write / read / generation 的哪一层。
没有归因,APO 大概率优化错地方
我在做带工具调用的 Agent 时踩过类似的坑:reward 一直在涨,generation 的回复看起来越来越流畅,但用户场景化体验反而下滑。后来 trace 发现是上游 retrieval 把错误的上下文塞进了 prompt——下游 LLM 越优化越熟练地「合理化」错误证据。这种事在记忆 Agent 里只会更严重:write 阶段把不该入库的细节写进去了,read 阶段在污染过的索引里精准命中了「错的」记忆,generation 拿着错误证据写出一段顺畅但偏离用户偏好的回复——三层各自都有理由说自己没问题。
只看最终一句话的 score,APO 通常会把所有压力堆到 generation prompt 上去 polish——你确实能看到分数微涨,但写/读两层的脏数据继续在底下烂。
这就是为什么这篇论文要把归因写进 APO 的反馈信号里。先归因,再让 LLM 改 prompts。
同期工作站位
Related Work 里作者把同期方向梳得很克制:APO 家族从 Prasad et al. (2022) 的离散编辑搜索 GrIPS、Zhou et al. (2022) 的「LLM 自己生成 prompt 候选」,到 Yang et al. (2023) 把过往 prompt 性能当 optimizer 信号,再到 PROMST(Chen et al., 2024)专门处理多步任务的人类反馈整合,路线很多。
但这些工作几乎都默认有大量标注——单轮分类有 ground truth,多步任务也假设你有人力批量打分。一旦走到记忆 Agent 这种垂直场景(论文用的是健康教练),人类标注既贵又慢,你必须挑得准。
另一条线是 Active Prompt(Diao et al., 2023)的 chain-of-thought 示例选择,以及 Zhen et al. (2025) 把主动采样用在 LLM-as-a-Judge 校准上——这篇论文作者就是其中一位,思路上是延续。区别在于这次的采样目标同时要服务两件事:让人类校准 evaluator,以及给 APO 喂代表性足够、标签可靠的案例。单一目标的 active learning 公式套不进来,所以才有了后面的凸优化重写。
方法骨架:评估带归因,采样靠凸优化
整体闭环看 Figure 2:
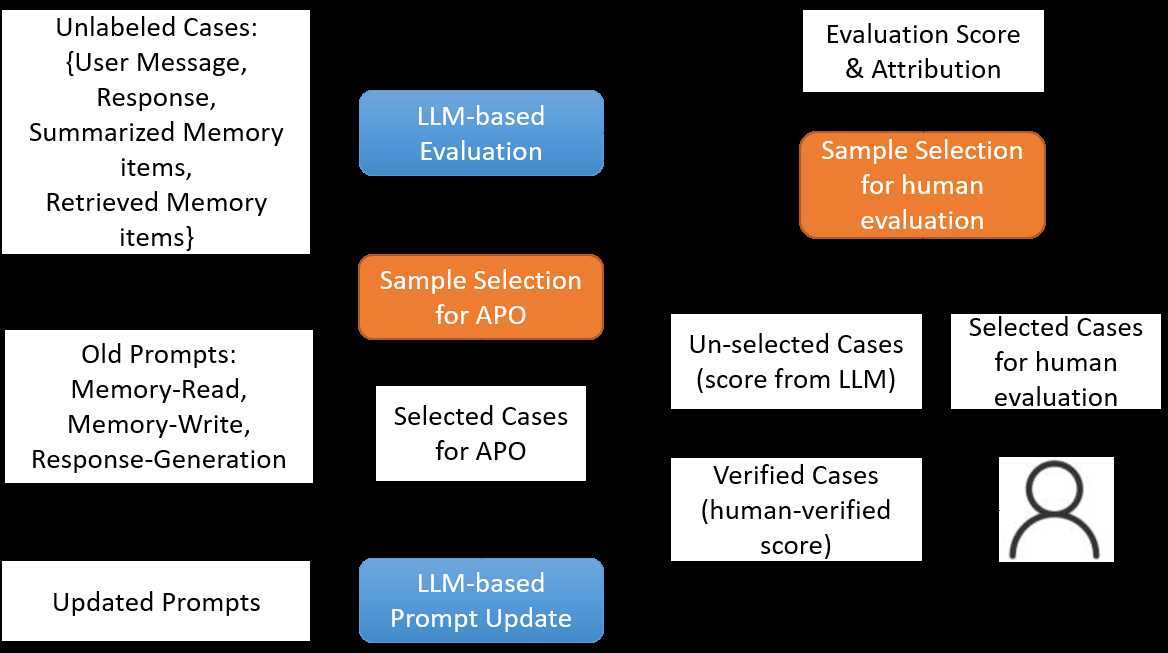
图2:左侧未标注样本进入 LLM 评估器,得到分数和归因;中间 Subset Selection 同时做两件事——选一批送人类校准 evaluator,选另一批送 APO 更新 prompts;右侧 LLM-Based Update 同时刷新三套 prompts。橙色块强调采样不是随机抠几条。
评估器:先打分,再指认是哪层塌了
LLM 评估器的输出是一个二元组 \((s, a)\):分数 \(s\) 加归因 \(a\)(论文式 (6)):
注意输入里把 \(m_{\mathrm{write}}, m_{\mathrm{read}}\) 都摆了出来——这是关键。评估器看到的不仅是「用户说了啥 → Agent 回了啥」,还有「这一轮往库里写了啥、又捞回了啥」。归因 \(a\) 取值就是 memory-write / memory-read / generation 三选一,分数完美时 \(a\) 为空。
这一步其实暗藏一个工程要求:你的日志必须能完整回放出 \(m_{\mathrm{write}}, m_{\mathrm{read}}\)。如果你的系统只记最终回复不记中间状态,这套方法根本起不来。这点论文没特别强调,但落地团队肯定知道这是第一道门槛。
归因怎么帮 APO?两件事:改 prompt 时,让 LLM 看到「这条样本之所以差,因为 read 模块没捞对相关历史」这种解释,而不是只看到 score=0.8;选样本时,让采样算法保证 write/read/generation 三类失败案例都有露面,不让某一类背锅。
主动采样(人类校准侧):不确定 + 代表性
evaluator 自己也会出错,所以要请人类校准一部分样本。但人类标注预算 \(k\) 是死的,怎么挑?
论文给每个样本 \(x\) 一个权重 \(w_x \in [0,1]\),连续松弛后用 \(\ell_1\) 促稀疏。目标函数(论文式 (8))写得很干净:
约束:\(\sum w_x \leq k\),\(0 \leq w_x \leq 1\)。
三项分别对应三个直觉:
- 不确定性 \(u_x\):让 evaluator 在高温度下对同一条样本反复打分,看分数方差。方差大说明 evaluator 自己对这条拿不准,人类介入边际收益最高。论文给的具体设置是 evaluator 温度 1、top-p 0.5——多次采样获取分数方差。
- 代表性(KL 项):选出的子集分布 \(P\) 应该尽量接近全局分布 \(Q\)。论文示例用 topic 分布(运动/睡眠/饮食等)作为分层维度,并明确说「error attribution」也可以作为另一条分层维度——逼着批次里 write/read/generation 三类失败都有覆盖。
- 稀疏性(\(\ell_1\) 项):把权重压向 0/1,方便最后取 top-\(k\)。
这个目标函数是线性项 + KL + \(\ell_1\) + box 约束,完美的凸问题——作者直接点名用 cvxpy 求解,全局最优可保证。论文 Appendix 7.3 给了完整伪代码。
我读这一段时直接想:「为什么之前我没这么写?」很多团队挑 active learning 样本就是拍脑袋写一堆 heuristic(pick top-uncertain,再从里面去重取 diverse),代码里到处是 if-else。把它统一成可解的凸问题,工程上的好处是立刻可审计——\(\lambda_1, \lambda_2\) 调多少、KL 项算的是哪个维度,都能写进单测。
主动采样(APO 样本侧):方向反过来
第二份采样选的是真正喂给 APO 去改 prompts 的样本(论文式 (9)),目标变成最小化:
注意符号反了——这次要的是低不确定性的样本。直觉很顺:APO 用的样本必须分数靠谱,否则「LLM 改 prompt」会被噪声标签带偏。同时仍然要保持分布代表性、覆盖三类归因。
人类已经标过的样本不确定性直接置 0,等于优先选这些「金标」案例进 APO。
一个细节:B1 不应大于 B2
论文明确说 \(B_1\)(人类预算)不应该大于 \(B_2\)(APO 预算)。这个约束乍看奇怪——人类标得多不是更好吗?
仔细想就明白:如果 \(B_1 = 20\%\) 而 \(B_2 = 5\%\),意味着你雇人类核了一堆样本,最后只送 1/4 进 APO,剩下 3/4 的人工成本浪费了。人类标注的最高 ROI 出现在「标完就用」的链路上。这个约束很实诚,反映出作者真在 ROI 视角上拆过预算。
一个具体场景:健康教练 Agent
论文 Figure 3、Figure 4 把方法落到了健康教练的真实场景,这种插图在 Industry Track 看起来像 demo,但其实是验证「归因」假设最关键的证据——只有在能把对话拆成结构化字段的场景里,模块归因才真有意义。
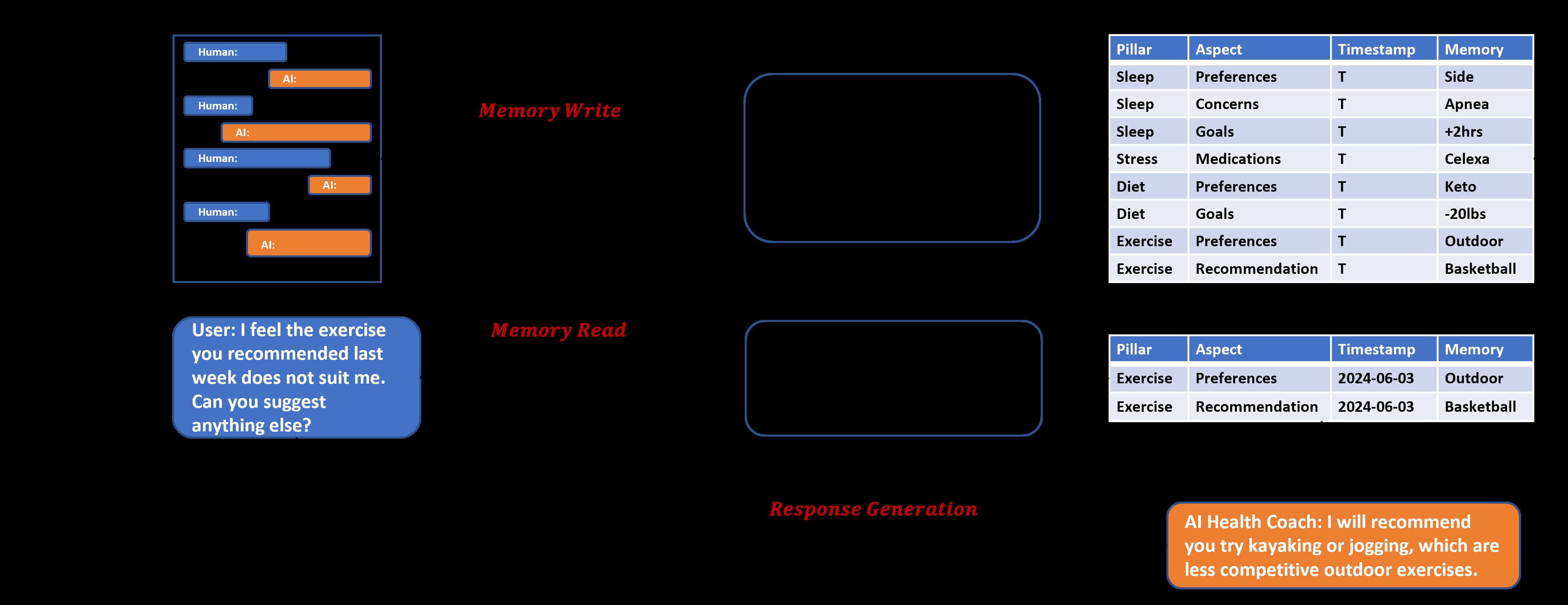
图3:Memory Write 把对话历史拆成 pillar / aspect / time range / summary 表格——比如「diet 偏好北方菜」「sleep 平均 6.2 小时」;Memory Read 接到「上周让我打篮球,但我膝盖不舒服」这种 query 时,去库里捞「diet 偏好」「exercise 偏好」「曾经讨论过的运动」这几条;Response Generation 拿着这些去改写推荐——比如把篮球换成游泳。这是一个相对干净、字段化的写读链路,归因到模块级别不会很模糊。
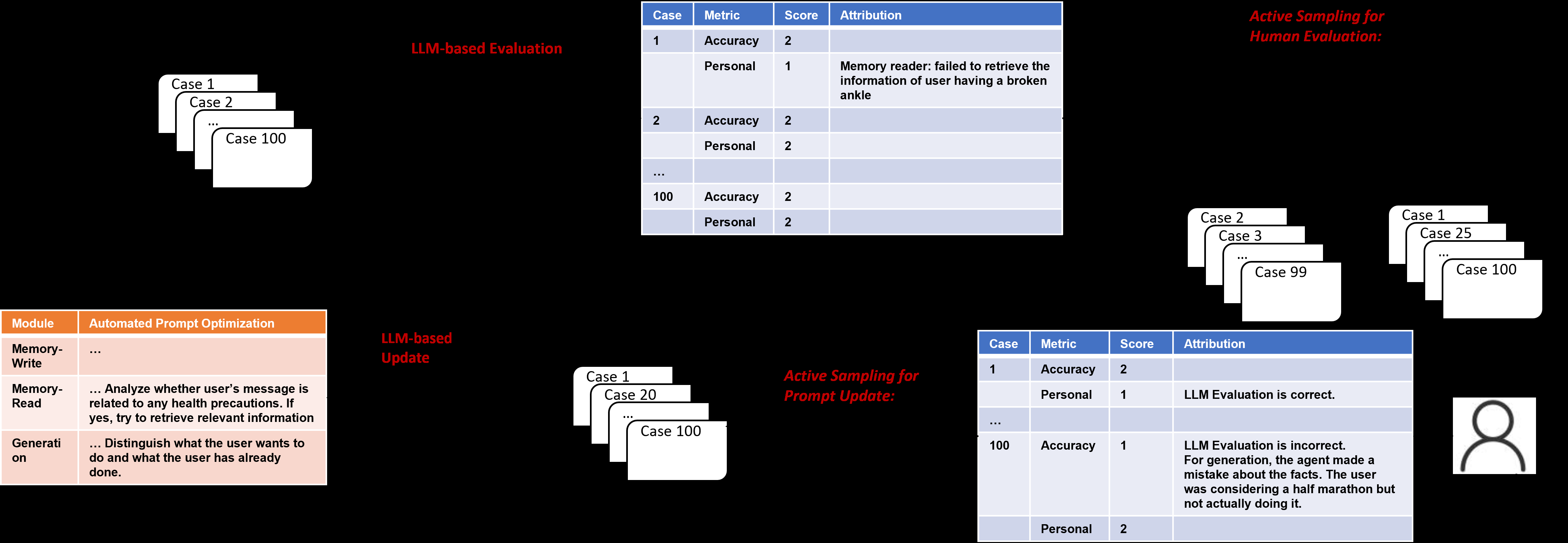
图4:100 条对话案例 → LLM 评估器打分并归因 → 采样选出代表性样本送人类核对 → 再选一批进 APO → LLM 同时改三套 prompts。整张图其实就是论文的方法骨架在真实业务里的一次完整描边。
我读这两张图的最大感受是:它给了一份可复用的字段清单。如果你也在搭类似的 Agent,先按 Figure 3 的字段对齐你的日志(pillar、aspect、memory、retrieval result、generation),再套这套 APO,迁移成本是可控的。如果你的日志里写/读两层的中间产物根本没落地,那这套方法用不上——这是工程前提,不是算法瓶颈。
实验:四张表,归因到底贡献多少?
设定
| 维度 | 取值 |
|---|---|
| 数据集 | HealthBench(公开,简化文中称 HB);HealthCoaching(专有,500 cases,1 个月用户试点) |
| 主模型 | Gemini-2.5-pro(主表);Llama3-70b(附录 7.4) |
| 指标 | Consistency、Personalization,区间 0–2,共 8 名健康教练锚定 rubric(主文重点报告 Personalization) |
| 预算 | \(B_1 \in \{5\%, 10\%\}\)(人类预算)、\(B_2 \in \{5\%, 10\%\}\)(APO 样本预算),约束 \(B_1 \leq B_2\) |
| baseline | Random(Ghojogh et al., 2020)、密度感知 Coreset(Kim & Shin, 2022) |
| 起点参考 | 无 APO 初始 prompts:HealthCoaching 1.58,HealthBench 1.62 |
研究问题三个:RQ.1 数据效率(同预算下是否压住 baseline);RQ.2 鲁棒性(变 budget 是否仍占优);RQ.3 归因贡献(去掉归因再跑一遍)。
Table 1 — HealthCoaching · 完整归因 · Personalization
| 方法 | \(B_1=5\%, B_2=5\%\) | \(B_1=5\%, B_2=10\%\) | \(B_1=10\%, B_2=10\%\) |
|---|---|---|---|
| Random | 1.67 | 1.71 | 1.73 |
| Coreset | 1.72 | 1.74 | 1.78 |
| Proposed | 1.85 | 1.89 | 1.93 |
Table 2 — HealthCoaching · 去掉归因 · Personalization
| 方法 | \(B_1=5\%, B_2=5\%\) | \(B_1=5\%, B_2=10\%\) | \(B_1=10\%, B_2=10\%\) |
|---|---|---|---|
| Random | 1.61 | 1.63 | 1.68 |
| Coreset | 1.65 | 1.68 | 1.73 |
| Proposed | 1.78 | 1.82 | 1.85 |
Table 3 — HealthBench · 完整归因 · Personalization
| 方法 | \(B_1=5\%, B_2=5\%\) | \(B_1=5\%, B_2=10\%\) | \(B_1=10\%, B_2=10\%\) |
|---|---|---|---|
| Random | 1.70 | 1.74 | 1.76 |
| Coreset | 1.76 | 1.78 | 1.83 |
| Proposed | 1.89 | 1.91 | 1.94 |
Table 4 — HealthBench · 去掉归因 · Personalization
| 方法 | \(B_1=5\%, B_2=5\%\) | \(B_1=5\%, B_2=10\%\) | \(B_1=10\%, B_2=10\%\) |
|---|---|---|---|
| Random | 1.67 | 1.72 | 1.72 |
| Coreset | 1.74 | 1.75 | 1.78 |
| Proposed | 1.82 | 1.84 | 1.89 |
这些数应该怎么读?
第一,同预算下 Proposed 稳定压过 Random / Coreset(RQ.1 + RQ.2)。差距在 0.07–0.13 之间——0–2 制下接近 5–7% 的相对提升。在垂直对话评估里,这种幅度比榜单上常见的「2 个点」更扎实,因为 rubric 是 8 个领域专家锚出来的,不是松弛的多选题。
第二,去掉归因后 Proposed 仍领先,但绝对分整体下沉 0.05–0.07(RQ.3)。这个对比把作者的叙事讲得很干净:归因不是唯一增益来源——主动采样自己就能跑出大头——但归因贡献了一段稳定的、独立的增量。我觉得这个数字其实算是论文最有说服力的部分,因为它把「主动采样」和「归因」两个变量拆开看了,没有混在一起讲故事。
第三,起点 1.58 / 1.62 → 最高 1.93 / 1.94,提升约 0.32–0.35。听起来还好,但你要意识到这是 0–2 制 + 专家 rubric 下的硬涨幅;在生产环境里这个幅度通常对应肉眼可见的体验差异。
第四,论文也提到优化后的 prompts 会增加 few-shot 示例、加上更多条件化指令、对模糊场景给出更明确的处置规则——这是 LLM 在批量 case 反思后自然倾向的产物。我自己手工迭代健康向 prompts 时也会往这个方向收敛,论文的结果其实是把工程师的经验法则交给 LLM 自动化了一遍。
老实说一句:主文只展开了 Gemini-2.5-pro 的 Personalization 一组数字,Consistency 和 Llama3-70b 的曲线在附录 Table 5–12。我对照过附录数字,整体趋势一致——Llama3 上 Proposed 同样压过 baseline,Consistency 也涨。但要做严肃 benchmark 对齐,还是得自己把附录读完。
批判性看待:这篇论文的边界在哪?
亮点
- 第一次系统地把 multi-agent prompt 工程当作一个完整问题处理:评估、归因、采样、优化四件事耦合在一个闭环里。这个叙事结构对工业团队几乎是「可执行规范」——你照着 Figure 2 在自己系统里画一遍架构都成立。
- 采样写成可解的凸问题:cvxpy 直接 plug-and-play,比拍脑袋的 heuristic 更利于审计与复现。
- B1 ≤ B2 这种约束:体现作者真在工业 ROI 视角上拆过预算,不是单纯算法主义。
需要警惕的几条
- Evaluator 仍是 LLM:整套优化链条吃它的偏差。Limitations 里作者自己也点名要用「成熟、被广泛验证的 LLM」做评估器。如果你换个差一点的模型当 judge,整个 APO 可能反而把错误模式 reinforce 进 prompts。
- 健康场景的合规问题:这是 Industry Track 论文最容易被误读的一点——「我也能直接拿这个上线」。不行。论文 Limitations 第二条很明确:上线前要做安全和稳健性测试。这套算法只解决「prompts 怎么改」,不解决「医疗内容是否合规」。
- 对比广度有限:主文 baseline 只对了 Random + Coreset。同期的 Active-Prompt(Diao et al., 2023)、Zhen et al. (2025) 的主动采样校准 LLM-as-a-Judge——这两条线和本文很相关,主文里没直接定量对比,要靠读者自己脑补 delta。
- 专有数据不可复现:HealthCoaching 是 Samsung 内部 1 个月试点的 500 cases,外部读者复现只能跑 HealthBench 那一支。这是 Industry Track 常态,但确实限制了第三方独立核查的强度。
- 三类归因的边界其实模糊:现实中一条样本失败可能同时归因于 write 不全 + read 召回偏(write 写漏了关键 aspect 导致 read 召回不到)。论文走的是「单一最主要原因」的简化路线,对处理 cascade error 的能力没单独评估。
一个真实的工程顾虑
我会盯着 \(\lambda_1, \lambda_2\) 这两个超参——它们决定了「不确定性 vs 代表性」的权衡,论文主文没给消融。话题分层 \(Q\) 的估计也是个隐藏变量:如果你的线上日志主题分布有长尾偏,估错了 \(Q\),整个采样就会朝错误方向倾斜。落地时要把这两块当成可调参数纳入实验设计,别当成黑箱。
落地时我会怎么用?
如果你正在做带记忆的客服 / 教练 / 助手 Agent,我会建议照下面四步走:
- 先把日志字段对齐论文式 (5)——最少能完整回放 \(m_{\mathrm{write}}, m_{\mathrm{read}}\),否则归因没法做。如果你现在只记最终回复不记中间状态,先补这一块再谈 APO。
- 评估器先做归因再做总分——就算暂时不上 active sampling,让 evaluator 在每条 case 上输出一个 attribution 标签,已经能让你的人工巡检效率翻倍。这个改动几乎零成本,先吃现成红利。
- 采样阶段先把话题分布 \(Q\) 估靠谱——可以用线上日志直接估,宁可分箱粗一点也别瞎拍。话题划分错了,「代表性」就会变成另一种偏见。
- APO 迭代温度逼近贪心——论文写的 \(T=0\), top-p \(\approx 0\) 是有讲究的:APO 不需要多样性,要的是稳定收敛。这一点和训练 RL 时偏好高温度采样的直觉相反,别混用。
再补一层 checklist:evaluator 是否与你的产品 rubric 对齐(Consistency vs Personalization 的权重你定了吗?);人类评估是否真的覆盖了争议样本(不是「看起来难」的样本,而是 evaluator 自己拿不准的样本);APO 更新是否做了版本管理与灰度。论文给的是算法闭环,产品闭环还得你自己补。
收尾
记忆 Agent 的难点从来不在「模型够不够大」。真正的麻烦在 模块交错时的信用分配——三套 prompts 互相影响,单纯优化最后一层等于在给错题写评语。这篇论文的贡献不是发明了某个新算法,而是把「评估带归因 + 凸优化采样 + LLM 同时改三套 prompts + 人类预算前置约束」这一整条工业链路拼齐了。它不替你解决合规和产品 sense,但至少让「该改哪条 prompt」从黑箱变成可审计的工程问题。
如果你的系统已经被三路 prompts 的互相拖累折磨过,这套叙事会立刻对上号;如果还没到那一步,至少把日志字段先按 Figure 3 拆好——等你需要这套方法时,门槛会低很多。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注我。