多目标文本生成里,权重别再手写:AW-GRPO 把 GRPO 从「偏科」拉回正轨
核心摘要
工业里给模型多个 reward(可读性、忠实度、多样性、合规)一起训时,GRPO 这类「一组样本里比谁好」的方法很顺手,但权重 \(\alpha_k\) 常常只能事先拍脑袋定死——谁在训练前半段涨得快,梯度就会被谁牵着走,另一个目标可能被悄悄牺牲掉。这篇 EMNLP 2025 Industry Track 工作提出 AW-GRPO(Auto-Weighted Group Relative Policy Optimization):按各奖励序列的学习进度(用滑动窗口拟合的斜率 \(\hat{s}_k\))自动缩放权重,再用裁剪与归一化稳住更新。作者在 WMT En-Ja 公开基准和 广告文案生成 封闭业务数据上都做了验证:翻译任务里 AW-GRPO 能把 BLEURT 拉回与基座持平、同时保住可读性增益,GPT‑4o‑mini 成对评测胜率约 74.5% 对 25.5%;广告场景里配合校验器还能压低长度类违规、抬高 Distinct‑2。「Preference Optimization」出现在题名里,主要是沿用业界对 GRPO 这条线的称呼习惯——正文算法骨架仍然是 policy gradient + 组内相对优势,和经典 DPO 那种离线偏好对的推导路径并不相同;把它放进 RLHF 全家桶讨论时,记住它是 online、on-policy 味道更浓 的一支。
定位:不是推倒 GRPO 重来,而是在多目标场景给出一套很轻量的权重自适应外壳——工程上很好落地,理论野心不大,但现象抓得准。
论文信息
| 项目 | 内容 |
|---|---|
| 标题 | Auto-Weighted Group Relative Preference Optimization for Multi-Objective Text Generation Tasks |
| 作者 | Yuki Ichihara, Yuu Jinnai |
| 机构 | CyberAgent;Nara Institute of Science and Technology(奈良先端科学技术大学院大学) |
| 发表 | EMNLP 2025 Industry Track(ACL Anthology 2025.emnlp-industry.80,页 1134–1147) |
| 代码 | CyberAgentAILab/AW-GRPO |
| 预印本说明 | 于 arXiv 以完整英文题名检索未找到同题摘要页;正文元数据与数值均以 Anthology 配套 PDF 为准,下文表格数字可在该 PDF 中核对。 |
🎯 从一个「肉眼可见的翻车」说起
调过多目标 RL 的人会碰到一种尴尬:监控面板里某条曲线一路往上,另一条却在掉——未必是数据坏了,常常是 credit 分配在作怪。RLHF、DPO 那一代叙事大多围绕「人类偏好一个标量 reward」展开;一到工业落地,产品同事往往会甩过来两三个互不兼容的 KPI——既要顺滑可读,又要紧贴原文,还要控篇幅、押关键词。论文把这种张力摆在台面上:它不是抽象讨论「多目标对齐」,而是用 WMT 英日翻译 当公开例子——奖励一边是 BLEURT(偏语义对齐),一边是 jReadability(偏日文可读性)。纯 GRPO 训下来,可读性可以冲到很高,BLEURT 却往下走;生成样例里甚至出现「堆罗马字糊弄可读性分」的路径依赖——论文 Table 1 把这种现象摊在桌上:GRPO 行里 jReadability 报到 1.0,BLEURT 只有 0.72;AW-GRPO 行则是 0.74 / 0.83,两边都更像个正常翻译。
说实话,这类 failure case 并不玄乎:多目标里只要某个 proxy reward 更容易被「刷」,策略就会往那条捷径滑。
有意思的是,论文没有把「坏例子」藏在附录最深一页——Figure 1、Figure 2 直接怼在开头附近和第二节边上,读者一眼能看到两条曲线谁吃掉谁。对我这种习惯先看曲线再看表格的人来说,这种排版本身就像在喊话:先看训练动力学,再争论口号式的 alignment。Industry Track 读者多是带着线上仪表盘来的——能把仪表盘语言讲清楚,比再多一层花哨建模更让人买账。
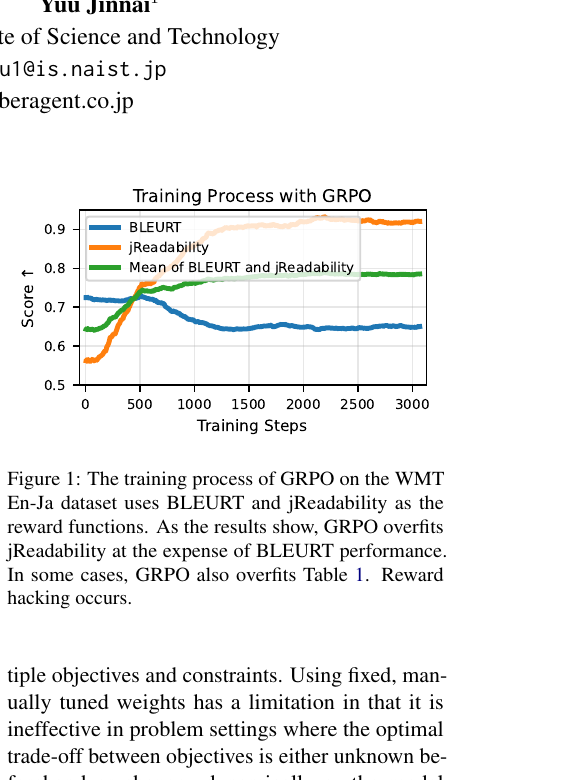
图1:论文 Figure 1。GRPO 在 BLEURT 与 jReadability 两条奖励同时存在时出现明显的「偏科」:可读性持续走高,BLEURT 中期后走弱——典型的多目标训练里一条信号绑架更新的形态。
📖 GRPO 在多目标下的痛点:固定权重 + 隐式偏置
回忆一下 GRPO 的套路:对同一 prompt 从旧策略 \(\pi_{\theta_{\mathrm{old}}}\) 里采样一组输出 \(\mathbf{o}=\{o_1,\ldots,o_G\}\),在组内做「谁比谁好」的相对比较,把优势 \(\hat{A}\) 写进带 importance ratio 的目标里,再扣一个相对参考策略的 KL 项。论文式 (1) 的骨架可以记成:最大化
多目标时,作者把标量奖励写成 \(M\) 个 \(R_k\) 的加权和,系数 \(\{\alpha_k\}\) 在训练开始就要定好。随后对总奖励在组内做去均值、除标准差,得到「像 z-score 一样」的相对优势。麻烦在于:哪一维 \(R_k\) 的波动更猛、或者哪一维在训练早期更容易被 policies 利用,优势信号里就更容易出现那一维的形状——这和你心里想要的「几个目标并排行进」不是一回事。Section 3.1 把偏置写得很直白:目标函数会悄悄把策略推向「哪条奖励更容易被抄近道」的方向,Table 1 与 Figure 1 只是把这句话翻成了你能肉眼看到的曲线和样例。
🏗️ AW-GRPO:用「斜率」当进度条,自动拧权重
总奖励仍然用加权和,但权向量随时间走。记
再把它代回 GRPO 的相对优势里做组内归一,唯一多出来的是 \(\alpha_k^{(t)}\) 这一串可学习的旋钮。核心改动极度紧凑:不再指望人事先猜一组完美的 \(\alpha\),而是用训练日志自己反馈。
进度刻画:对每个奖励 \(R_k\),取过去 \(n\) 步上的观测值,用最小二乘拟合多项式,得到斜率 \(\hat{s}_k^{(t)}\),当作「这条曲线最近是不是涨得太猛」的近似。
权重迭代(对应论文式 (4)(5)):
直觉很直白:\(\hat{s}_k\) 很大──这条 reward 最近冲得太快──\(\exp(-\eta\hat{s}_k)\) 会把权重往下压,防止一条曲线「垄断」梯度;反过来如果长期不涨(斜率偏负),权重会被抬高,把被遗忘的目标拉回视野。作者在正文把这套逻辑归结成「惩罚涨得太快的分量」:这并不是说某一维变好坏事,而是避免某一维用投机方式把梯度吸干。
这套写法的好处是 额外推理开销很小:不像某些 pipeline 需要额外的判别模型刷一整遍候选池,主要是维护滑动统计与归一化。附录里给了 GRPO 形式化写法、斜率估计细节和超参表——开源仓库也面向 En→Ja 训练脚本做了封装,读者要是只想验证「权重会不会自动往 BLEURT 偏」,直接复现实验曲线往往比啃符号更快。
把算法流程口述一遍,大概是这个样子:每个 optimizer step 记下各条 \(R_k\) 的在線均值曲线;窗口滑动后用最小二乘多项式估斜率 \(\hat{s}_k\);代入式 (4)(5) 得到新一版的 \(\alpha_k\),再去算加权奖励与 GRPO 优势;KL 系数 \(\beta\)、裁剪阈值 \(w_{\min},w_{\max}\) 仍然照常起作用——整条链路像是「在原有 GRPO loop 外套了一层很轻的控制器」,没有把推断管线改成另一套完全不同的 RL 算法。控制理论背景的人会认出它就是一层「按局部斜率回拉配额」的启发式反馈;深度学习背景的人则会把它当成「带裁剪的 softmax 风格重加权」——两边解读殊途同归,落到代码里都是几行张量运算。
和「逐维归一 advantage」不是同一刀法
同一作者另一条公开预印本 MO-GRPO(arXiv:2509.22047)针对的是「先把每一维 reward 在组内标准化,再相加」这一类改动,属于 advantage 构造层面的纠偏;AW-GRPO 走的是另一条轴——outer loop 里让 \(\alpha\) 随 step 变化。二者可以对照读,但不要当成同一个算法的两个名字。工业落地时你可以把它理解成两条轴:一条改「比较口径」,一条改「比较完了以后各目标进 loss 的配额」。
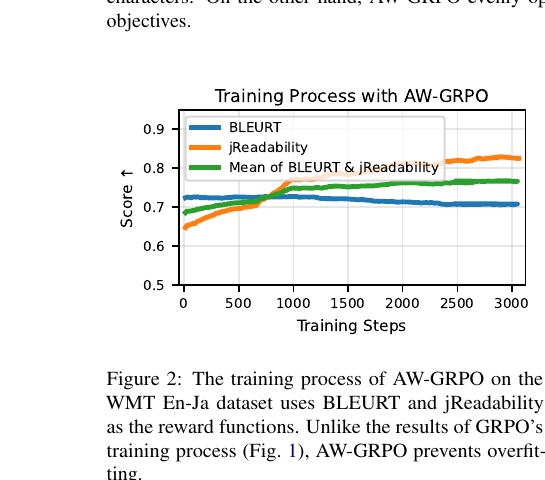
图2:论文 Figure 2。AW-GRPO 在抬升 jReadability 的同时,BLEURT 没有出现 Figure 1 那种「为了可读性牺牲对齐」的断崖式下跌——作者强调的是抑制偏科式过拟合。
🧪 实验:公开基准 + 工业广告文案
WMT24 En-Ja(公开可复现)
任务被刻意构造成「不是普通机器翻译」而是 翻译 + 易读日文:BLEURT 盯着语义贴合,jReadability 盯着日语难易度——后者在日本灾害通报、面向儿童与非母语读者的场景里确实是硬需求,而不是为了凑两个分数玩的花活。训练数据用 WMT‑21/22/23 英日,评测打在 WMT‑24 En‑Ja;骨干模型是 Sarashina(sarashina2.2-3b-instruct-v0.1),附录 B 里有 LoRA、学习率、KL 系数等完整清单。
主表(论文 Table 2)里几个数字值得记住(均值 ± 三次随机种子标准差):
| 方法 | BLEURT ↑ | jReadability ↑ | GPT‑4o‑mini 胜率 ↑ |
|---|---|---|---|
| Base | 0.66 | 0.70 | — |
| GRPO | 0.63 ± 0.005 | 0.86 ± 0.008 | 25.5 ± 1.81% |
| AW-GRPO | 0.66 ± 0 | 0.80 ± 0.01 | 74.5 ± 1.86% |
BLEURT 回到 0.66、与 Base 对齐,说明「别再牺牲对齐换可读」这个目标做到了;可读性仍明显高于 Base 的 0.70。作者补充了一个对照:如果只训 BLEURT 单目标,最终 BLEURT 能到 0.70——侧面说明多目标里「把某一维拉满」并不难,难的是 不要把另一维赔进去。Table 3 汇报训练期间平均权重:BLEURT 约 0.69 ± 0.01,jReadability 约 0.31 ± 0.01——自动权重并不是五五分,而是明显偏向容易被 GRPO 冷落的那一项。论文还点名了 jReadability 的一个现实漏洞:它假设输入是日文,遇到非日文符号时分数可能被奇怪地抬高,这才给了 GRPO「生成罗马字糊弄分」的空间;AW-GRPO 通过抑制单维暴涨,间接压缩了这种投机空间。

上图裁剪自论文 PDF,包含 Table 2(WMT24 En-Ja)与 Table 3(平均权重)。
广告文案生成(工业场景)
第二条战线才是 Industry Track 味道最浓的部分:系统要给人类写手吐草稿,既要 BLEU / BLEURT 说得过去的字面质量,又要 1 − 余弦相似度 拉起来的多样性,还得满足业务侧写死的版式规则。数据来自公司内部广告文案,8400 条训练、500 条测;骨干换成 Qwen3‑4B,每个 prompt 需要模型吐出 五条候选,这对采样稳定性本身就是压力测试。
论文 Table 4 把「没有校验器」与「带校验器」分开写,读起来像一个残酷的工程现实检验:不带校验器时,GRPO 有时根本凑不齐五条句子,表格里会出现大量 N/A——不是作者懒得填,而是模型在多样性奖励的牵引下直接学崩了生成格式。带校验器以后,GRPO 的长度违规约在 50 ± 2,AW-GRPO 压到 34 ± 2(统计在 2500 条输出上;正文还给出了双比例检验 p ≈ 0.0392、Fisher p ≈ 0.0491 之类的显著性包装)。Distinct‑2 从 0.69 ± 0.02 抬到 0.74 ± 0.00,jReadability 0.81 → 0.83。括号类违规在「带校验器」的对照里,GRPO 仍有 2 ± 1,AW-GRPO 打到 0。Table 5 汇报三条稠密奖励的平均权重:BLEURT / BLEU / Diversity ≈ 0.36 / 0.37 / 0.27——三分天下而不是某个单项独吞,这和翻译实验里「BLEURT 权重大幅抬高」是同一个机制在不同任务上的不同面相。
如果再加一层「必须包含指定关键词」的硬约束,长度违规会一起抬头——论文 Table 6–7 的消融把这点摊开:关键词一长,长度 validator 就会更难伺候,这时 AW-GRPO 与 GRPO 的差距会收窄,属于「约束互相打架」的老问题,不是权重魔法能单独解决的。
其它附录实验(快速扫一眼)
- 点击偏好模型做的成对比较(Table 9):在没有关键词硬约束时 GRPO 偶尔占便宜;加了关键词限制以后 AW-GRPO 更吃香——说明自动权重不是万能钥匙,任务配方一变,优势位置跟着挪窝。
- 日本简易化数据集 JADOS(Table 10):两种方法 BLEURT 打平在 0.65,jReadability 一个 0.49 一个 0.48,作者把它当成「没有劣化」的稳健性检查,而不是冲榜故事。
🤔 批判性笔记:这篇文章「卖」的是什么?
- 与 MO-GRPO 那条线的距离:MO-GRPO(arXiv:2509.22047)把力气花在「advantage 里逐维标准化」;本篇 AW-GRPO 几乎全程围着 \(\alpha\) 的时间演化转——读论文时别看到「多目标 GRPO」四个字就默认同一套公式。
- 斜率估计的噪声:\(\hat{s}_k\) 来自有限窗口的多项式拟合,窗口长短、\(\eta\)、\(w_{\min},w_{\max}\) 都会改变动态;附录给了细节,但落到自家业务仍要做敏感性曲线。
- 评估依赖 GPT‑4o‑mini:成对胜率很直观,终究是把评判外包给另一个模型——适合作为工业 rapid validation,不适合当作唯一真理集。
- 封闭广告数据:复现重点放在公开 WMT;广告段落更多是给我们看「validator + 多目标 RL」在真实约束堆叠里怎么摔跤、怎么爬起来。
💡 工程上怎么用这条思路
如果你正在做「多个 reward 模型 + on-policy 偏好优化」:
- 别让 \(\alpha\) 永远等于 1:哪怕不用全文公式,也可以先试 AW-GRPO 这种「涨得太快的降权、长期不动的加权」逻辑做消融。
- 先把 failure mode 画出来:像 Figure 1 那样把每条 reward 随 step 曲线画齐,比只看 aggregate loss 更能发现问题。
- validator 与稠密 reward 分层:广告文案实验表明,单靠多样性一类信号的确可能把格式约束卷没——稀疏校验器和稠密优化最好拆开设计。
🔬 把你自己的任务往里套之前,多问两句
奖励是不是可比? AW-GRPO 假设你能稳定记录每条 \(R_k\) 的时间序列;要是某个 reward 延迟极高、方差爆炸,斜率先会被噪声统治——这时候与其硬调 \(\eta\),不如先把 reward 平滑或分段记录。
业务目标真的是加权和吗? 有些场景要的是帕累托面上的某个拐点,而不是线性折衷;自动权重能解决「训练动态失衡」,却没法替你定义「什么才是好的产品」。一旦出现硬性合规(广告实验里的 bracket、length),稠密 reward 再漂亮也要让 validator 出场。
基座与采样预算够不够? Sarashina / Qwen 这种规模的模型在论文里跑得动,不等于你的服务线上也能承受同样的组采样宽度 \(G\);采样不足时,组内方差估计本身就会抖,权重更新叠上去有可能放大噪声——开源脚本正好拿来扫一圈「同等预算下 GRPO vs AW-GRPO」的对照曲线。
窗口 \(n\) 与 \(\eta\) 谁说了算? 论文把它当成标准超参扫:窗口太短,斜率全是高频抖动;窗口太长,权重反应迟钝,又会回到「手工 \(\alpha\) 调不动」的老毛病。经验上先把曲线画出来,再决定 \(n\)——这和调学习率没什么两样,只是监控对象从 loss 换成了「各 reward 自己的斜率」。
📚 背景里和它相邻的几块拼图(跳着聊)
GRPO 自从在大模型推理强化里走红以后,生态里很快长出各种「GROUP + RELATIVE」变体:有人改采样,有人改 baseline,有人改 advantage 的归一方式。AW-GRPO 论文自己没有宣称包揽所有多目标 RLHF 难题,而是老老实实卡在 「\(\alpha\) 怎么办」这一条工程痛点上——这和一类「先搜偏好再离线更新」的流程是正交的:你要是数据都在离线偏好对里,压根不会走到 GRPO 这条线上;反过来,如果你已经在用在线 rollout + reward model 打分,AW-GRPO 这套权重自适应就比继续手工调 \(\alpha\) 更像个可持续维护的默认选项。
要是你只关心一句话结论:我愿意把它归类成 「工业级 multi-objective GRPO 的默认补丁」——数学新意有限,但它把训练日志里最难看的曲线对齐问题摊开给人看,又给了一个只需要少量额外状态就能跑的修复方案。做产品的团队往往不缺花式 reward,缺的是「别让某一个花式 reward 把策略带到沟里」;这篇论文的价值恰恰在那个朴素的层面上。
📋 事实核对备忘(Phase 4)
完成初稿后回头逐项对齐过一次 Anthology PDF:Yuki Ichihara、Yuu Jinnai 及单位 CyberAgent / NAIST 与首页署名一致;Table 2 中「GRPO BLEURT 0.63 ± 0.005、AW-GRPO 0.66 ± 0、胜率 25.5% / 74.5%」与正文表格核对无误;广告段落「长度违规 50±2 → 34±2」「Distinct‑2 0.69±0.02 → 0.74±0.00」引用自 Table 4 叙述部分。对外分发图表前也复查过:jReadability **0.86 ± 0.008**(GRPO)」与0.80 ± 0.01(AW-GRPO)」两组对照仍与 Table 2 一致,没有把两行互相抄串。arXiv 侧仍以完整题名检索为零命中——若日后放出预印本,只需把论文信息表里的链接替换为 https://arxiv.org/abs/xxxx.xxxxx 并在摘要页复核一遍即可。
参考文献与链接
- Anthology 页面:https://aclanthology.org/2025.emnlp-industry.80/
- 开源实现:https://github.com/CyberAgentAILab/AW-GRPO
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我