上下文永远不够用:SLIDERS 把长文档问答从"读完所有 token"换成"查数据库"
核心摘要
长文档问答有个让人头大的现象——你给模型 1M token 的上下文窗口,看似很大,但真到场景里就发现根本不够用:100 份 10-Q 财报塞进去就是 36M token,上下文直接溢出。常用的 chunking 方法表面上绕开了这个问题,把文档切成块分别处理,但所有 chunk 输出最后还得拼回来给模型做聚合——这一拼,长上下文问题原封不动地回来了。论文管这个叫 Aggregation Bottleneck(聚合瓶颈)。
斯坦福 OVAL 这篇 SLIDERS 给出了一个让我觉得"对,就该这么做"的方案:别再让 LLM 去硬啃拼接的文本了,把信息抽成关系数据库,用 SQL 来推理。LLM 只负责把文本翻译成结构化记录、再翻译成 SQL 查询,所有需要"聚合、对比、计数"的事情都交给数据库去做——这些恰恰是 LLM 在长上下文下做得最差的。
效果挺能打:在 3 个能塞进 GPT-4.1 上下文窗口的"长上下文"基准上,平均比 GPT-4.1 高出 6.6 个点;在两个新构造的、3.9M 和 36M token 的"超长"基准上,分别比次优方法高 19 点和 32 点。FinQ100 上 RLM 跑 10 个文档要 2000 美元、5% 准确率;SLIDERS 跑完 100 个文档花 34 美元、55% 准确率。这个差距已经不是"提升"能形容的了,是数量级的差距。
论文信息
- 标题: Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
- 作者: Harshit Joshi, Priyank Shethia, Jadelynn Dao, Monica S. Lam
- 机构: Stanford University, Computer Science Department
- 时间: 2026 年 4 月 24 日
- 论文链接: https://arxiv.org/abs/2604.22294
- 项目主页: https://sliders.genie.stanford.edu/
- 代码仓库: https://github.com/stanford-oval/sliders
为什么"上下文越来越长"反而救不了长文档问答
先说说我的直觉。这两年大家都在卷上下文窗口——从 4K 到 32K,到 128K,再到现在 GPT-4.1 的 1M token。听上去很美好:以前塞不下的现在塞得下了,那长文档问答应该就解决了对吧?
不是这么回事。
第一个反直觉的现象是,模型的上下文窗口是写在 spec 里的,但模型在长上下文下的实际可用能力远低于这个数。Liu 等人那篇 "Lost in the Middle" 早就告诉过我们:超过一定长度,模型对中间部分的关注度会断崖式下降。RULER、HELMET 这些后续 benchmark 也都在反复确认:标称的上下文长度和模型能可靠利用的"有效上下文"完全不是一回事。
第二个问题更现实——真实工作场景的文档量随时可以击穿任何上下文窗口。论文的 FinQ100 数据集就一个例子:100 家上市公司最近的 10-Q 财报塞在一起就是 36M token。哪怕是 GPT-4.1 的 1M 窗口,也只够装 3% 不到。这不是模型造得不够大的问题,是真实数据规模本身就不会停下来等模型扩窗口。
那现在常见的解法是什么?切 chunk + RAG 或者 chunk + 聚合。听上去解决了问题:把文档切成 16K 一块,每块独立处理,最后再聚合。问题在于——
聚合那一步本身就是个长上下文问题。
假设你切了 1000 个 chunk,每个 chunk 抽出 500 字的关键信息,1000 个 chunk 就是 50 万字的中间结果。你要拿这些去回答"哪家公司长期借款最低",怎么办?还得把这 50 万字塞回模型让它聚合。这就是论文称的 Aggregation Bottleneck——chunking 试图绕开长上下文,最后又把长上下文的问题原封不动地造了出来。
你想想看,如果聚合那一步还要靠 LLM 在长文本里做计数、排序、跨记录对比,那 LLM 长上下文那些已知的弱点(中间遗漏、计数不准、聚合错位)一个都跑不掉。
这就是 SLIDERS 切入的地方。
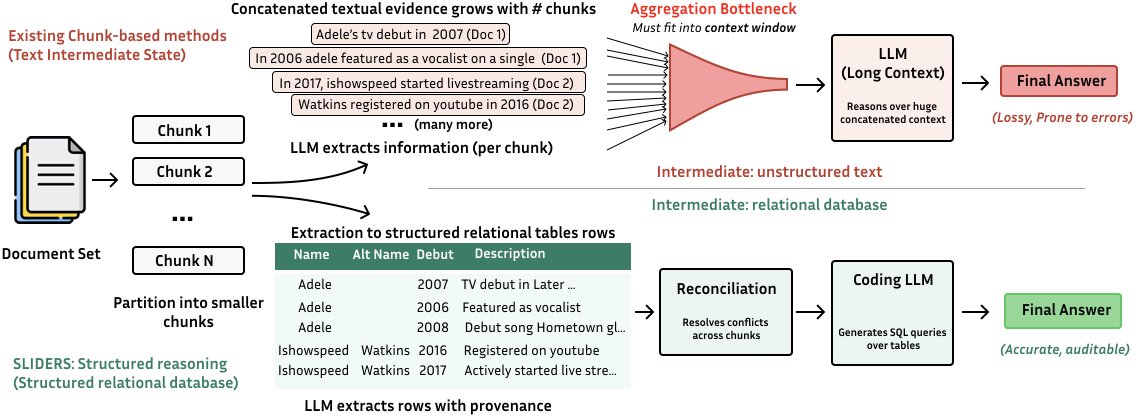
图 1:Chunking 方法的聚合瓶颈 vs SLIDERS 的结构化推理。上半部分是传统 chunking——LLM 抽出每个 chunk 的信息后,所有信息以非结构化文本形式拼回去再喂给 LLM,文本量随 chunk 数增长,再次撞上长上下文。下半部分是 SLIDERS——抽取结果直接进关系数据库,配套 provenance(出处证据),用 SQL 而非 LLM 去做聚合
SLIDERS 的核心 Idea:信息表示和推理彻底分开
一句话说清这个 idea:把"读懂文档"和"做推理"切成两件事,第一件交给 LLM,第二件交给数据库。
具体来说,SLIDERS 做的事情是把长文档集合转成一个关系数据库——每个有用的事实变成数据库里的一行,每行带着它的出处(哪个文档、哪段文字)和抽取理由(为什么从这段文字抽出这个值)。一旦信息进了数据库,回答问题就变成了一件标准的事情:写 SQL。
这里的关键洞察是:LLM 写 SQL 是一项已经被工业界打磨得很成熟的能力,但 LLM 在长上下文里直接做"找出 100 家公司中借款最低的那家"这种聚合任务,是它最薄弱的环节。把这两件事分开,让每个组件做自己擅长的事——这就是论文整个框架的指导思想。
SLIDERS 这个名字是 Scalable Long-document Integration through Decomposed Extraction and Reconciliation System 的缩写。完整流程拆成 5 步:
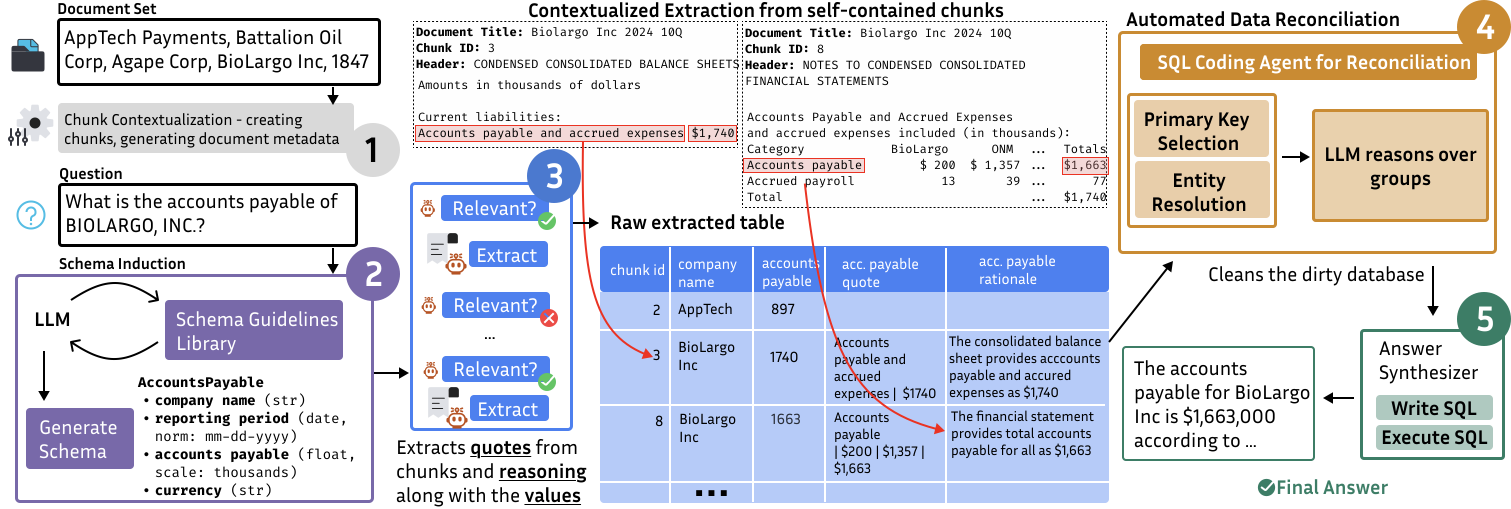
图 2:SLIDERS 完整 pipeline 概览,从文档输入到最终答案的 5 个阶段:(1) Chunk 上下文化,(2) Schema 归纳,(3) 结构化抽取,(4) 数据对账,(5) 基于数据库的问答。例子用的是 Loong benchmark 中的"BIOLARGO 公司应付账款是多少"查询
我把这 5 步对应的关键设计逐个聊一下。
Step 1: Chunk 上下文化——别让 chunk 成为"断头垃圾"
切 chunk 这件事有个老问题:信息一旦被切,上下文就丢了。比如表头在 chunk 1,表内容在 chunk 2,单看任何一块都没法解读。
SLIDERS 的做法是给每个 chunk 同时附上全局元数据(document title、document description)和局部结构标签(section header、表格、图片说明)。chunk 边界尽量沿着自然结构走(不切段落、不切表格、不切代码块),保证每个 chunk 出来都是"自洽"的。
这步本身没有特别 fancy 的算法,但是非常关键的工程基础——后面所有抽取的质量都依赖这一步给的上下文够不够好。论文用的 chunk 大小是 16K 字符。
Step 2: Schema 归纳——不能让 LLM 自由发挥
到了第二步就有意思了。关系数据库需要 schema,每一列得有名字、类型、单位、规范。问题是,schema 不能写死——不同问题需要的 schema 完全不一样。问"长期借款最低的公司"和问"哪个艺人最早出道",要抽的字段差太远了。
SLIDERS 的做法是让 LLM 自己根据问题和文档元数据生成 schema。但他们没有让 LLM 自由发挥,而是提供了一个 schema guideline 库——按问题类型(Ordering、Multiple Choice、Others)和文档类型(Narration、Policy、Dataset、Others)分类,每类有具体的指导原则。
举个例子,对于"Ordering"类问题,guideline 明确告诉 LLM:schema 里不要包含 item 的 index 字段——因为抽取是按 chunk 进行的,chunk 内部的 index 跟全局 index 不一致,存进去就是错的。这种细节的工程经验很重要。
每个字段的定义包含 6 个维度——字段名、语义描述、数据类型、单位、scale、归一化规则。最后这个归一化规则就是为了解决"75°F vs 24°C"、"以千为单位 vs 以百万为单位"这种工程上的脏活。
我觉得这步设计的精明之处在于,他们没有强求 LLM 一次生成一个完美的 schema——后面有专门的对账阶段去修各种问题。Schema 只要"够用"就行。论文的实验也验证了这个判断:用 GPT-4.1-mini 生成的 schema 平均 1 张表 3.3 个字段,用 GPT-5 生成的平均 1.54 张表 13.3 个字段——4 倍的复杂度差距,但下游准确率只差 2.1 个点。
Step 3: 结构化抽取——加个 Relevance Gate 防幻觉
第三步是实际的抽取:拿着 schema 去每个 chunk 里抽数据,写成 JSON。
但这里碰到一个特别讨厌的问题——当一个 chunk 里完全没有 schema 相关内容时,LLM 会幻觉。论文里给的解释挺有意思:因为 schema 有严格的类型要求,模型为了"结构合规"会硬填一些东西。这个观察我觉得很真实——大语言模型在结构化输出场景下,"不肯输出 None"的偏置确实存在,是训练数据的产物。
他们的解法很朴素:加一个 Relevance Gate 在抽取前面——先让模型判断这个 chunk 跟 schema 有没有相关证据,没有就跳过,不进入抽取阶段。
数据上看,这个 gate 在 516 个 chunk 上拒绝了 282 个,false negative 只有 1 个(0.4% 错误率)。说明这个 gate 很 conservative,错放掉的极少,但能把大量噪音 chunk 拦在外面。
抽取的形式化定义是:
其中 \(R\) 就是 relevance gate,\(q^e\) 是为抽取阶段改写过的问题(不是原始问题——这里有个 trick,待会儿讲)。
每条抽取出的字段值都是一个三元组 \(\langle v, p, r \rangle\):\(v\) 是规范化后的值,\(p\) 是 provenance(最小支持文本片段),\(r\) 是 rationale(为什么这段话能映射到这个值)。后面对账的时候,这些 provenance 和 rationale 就是 agent 判断的依据。
为什么这个抽取阶段能 scale?两个原因:(i) 单 chunk 大小可控,永远不会爆任何模型的上下文;(ii) chunk 之间完全独立,可以并行。
Step 4: 数据对账——SLIDERS 真正最值钱的部分
我个人觉得,对账这步才是 SLIDERS 区别于其他 chunk-based 方法的真正分水岭。
为什么?因为前面那些步骤,DocETL 等方法多少也都在做。但是把"局部抽取出的脏数据"清理成"全局一致的数据库"——这件事一旦做不好,前面所有努力都白费。
来看一下问题有多脏。在 FinQ100(100 家公司财报)上,SLIDERS 抽出来 685 行,但 ground truth 只有 105 行。也就是说有 580 行是冗余、冲突或部分重复的——直接拿这 685 行去算"借款最低",结果一定是错的。
对账要解决三类问题: 1. 去重 (Deduplication):同一条信息在多处用不同表达出现 2. 冲突解决 (Conflict Resolution):同一属性在不同 chunk 给了不同值 3. 整合 (Consolidation):多条记录各自包含同一实体的部分属性
这三种操作的具体含义可以看下表:
| 操作 | 触发条件 | 决策依据 | 执行动作 |
|---|---|---|---|
| 去重 | 不同表达的同义行 | 看 provenance,选最精确/最显式的版本 | 保留一条规范表示,合并冗余行 |
| 冲突解决 | 同属性多个不同值 | 看 provenance 和 rationale,判断哪个值在原文里更有支撑 | 保留最佳支持的值,删除其他 |
| 整合 | 同一实体的互补属性散在多行 | 判断属性是否能无矛盾合并 | 合并成更完整的一条,传播共享值 |
朴素的做法是对所有行做两两比较,复杂度 \(O(n^2)\),几百行还行,几万行就挂了。SLIDERS 的关键观察是:关系结构本身提供了天然的分解——同一实体或同一claim 通常会被某些公共属性"锚定",这些属性就是 primary key。按 primary key 分组之后,每组里只剩很少的行,对账就在小分区内做。
Phase 1: Partition
第一阶段先选 primary key——LLM 看着 schema 和样本行选出主键,跑 3 次投票确定。然后做 entity resolution——同一个人可能写成 "J. Smith"、"John Smith"、"Smith, John",必须统一。SLIDERS 先在文档内做 ER(作为"分块"步骤),再跨文档做 ER(用 LLM 写 SQL 迭代地对齐 key 值)。最后按 primary key 做 SQL group by,每组成为独立的对账单元。
Phase 2: 对账 Agent
对每个分区,agent 先用 SQL 查询去看分区里的内容、值分布、provenance、rationale,然后判断该用哪种对账操作(去重/冲突/整合),生成 SQL 程序去执行。
这里我特别欣赏的一点:所有对账动作都用 SQL 表达,整个过程是可审计的。出了问题,你能看到 agent 写了什么 SQL、用了什么证据、修改了哪些行。这在金融、法律这类高风险场景里几乎是刚需。
Step 5: 问答——LLM 写 SQL 答题
到这一步问题简单了:基于干净的数据库,LLM 拿着 schema 和原始问题写 SQL,执行,看结果,必要时再迭代。这就是经典的 text-to-SQL,有非常成熟的实现路径。
值得提一句,论文用了 SUQL(一种带 LLM 调用的 SQL 扩展)作为查询执行层,这样一些需要语义理解的过滤可以直接嵌进 SQL 里。
一个特别值得一提的细节:Question Decomposition
附录里有一段我觉得特别能体现工程功力的设计——问题分解。
考虑一个查询:"Return the second poem about the Great Wall of China."(返回关于长城的第二首诗。)
朴素做法是把这个原始问题直接喂给抽取阶段。结果会很离谱:假设 chunk 1 有一首相关诗 P1,chunk 2 有两首 P2、P3。抽取器看到"second",会在 chunk 1 里找不到(因为本地只有一首),然后从 chunk 2 抽出 P3(chunk 内的第二首)。最后全局答案是 P3,但正确答案是 P2。
问题出在哪?抽取阶段不应该做"回答问题"这件事——它应该穷举所有候选证据,把"找出第二首"的工作留给后续阶段。
SLIDERS 的解法是把原始问题 \(q\) 拆成两个:抽取专用的 \(q_e\)("识别所有关于长城的诗歌")和对账专用的 \(q_r\)("如何把诗歌候选合并去重")。Schema 归纳和最终问答仍然用原始 \(q\)。
这种"按阶段重写问题"的设计在 RAG 和 agent 系统里很少见到有人做这么细,但其实非常关键——它从语义层面隔离了不同阶段的职责。
实验:让人最印象深刻的不是榜单分数,是 cost
长上下文基准(≤360K tokens)
先看能塞进 GPT-4.1 上下文的三个基准:FinanceBench(金融单文档 QA)、Loong(多文档跨语言 QA)、Oolong(聚合密集型)。
| 方法 | LLM | FinanceBench | Loong | Oolong | 平均 |
|---|---|---|---|---|---|
| RAG | Qwen3-4B + GPT-4.1 | 62.67 | 54.35 | 11.32 | 42.77 |
| LongRAG | Qwen3-4B + GPT-4.1 | 72.00 | 59.10 | 22.00 | 51.03 |
| GraphRAG | Qwen3-4B + GPT-4.1 | 75.33 | 61.28 | 22.00 | 52.87 |
| 直接喂 LLM | GPT-4.1 | 82.00 | 76.74 | 45.56 | 68.69 |
| 直接喂 LLM | Qwen3.5 122B | 84.67 | 74.78 | 24.89 | 61.44 |
| DocETL | GPT-4.1 | 63.33 | 75.03 | 49.00 | 62.44 |
| Chain of Agents | GPT-5 + GPT-5-mini | 71.30 | 54.46 | 17.11 | 47.62 |
| RLM | GPT-5 + GPT-5-mini | 75.33 | 72.64 | 51.42 | 66.46 |
| SLIDERS | GPT-4.1 + GPT-4.1-mini | 89.33 | 78.57 | 64.67 | 75.56 |
| SLIDERS | Qwen3.5 122B | 82.10 | 75.70 | 68.00 | 75.26 |
几个观察:
第一,SLIDERS 用 GPT-4.1 比直接喂 GPT-4.1 高 6.6 个点。这点很关键——基线已经能把全部内容塞进 context 了,按理说应该是最强配置。但 SLIDERS 还是赢了。最大的赢面在 Oolong:64.67% vs 45.56%,差 19 个点。Oolong 的设计就是聚合密集型——这种任务恰好就是 LLM 在长上下文下的最弱项。
第二,用开源模型 Qwen3.5 122B 替换 GPT-4.1,SLIDERS 平均分 75.26,仍然显著高于 GPT-4.1 直接喂的 68.69。这说明 SLIDERS 的提升不是靠某个特定模型的特殊能力,框架本身就值钱。
第三,DocETL 这个对比很有意思——它也是 schema-driven extraction,但是没有对账阶段。结果在 FinanceBench 上只有 63.33%,比直接喂 GPT-4.1 的 82% 还差。这其实印证了对账的价值:抽取出脏数据不做清理,比直接看原文还差。
第四点要批判性看一下。SLIDERS 在 Loong 中文法律子集表现是 59.9%(论文承认),是各域中最低的。论文给的解释是"法律文档本身就 16K 不到,chunking 和 reconciliation 的开销没收益"。我觉得这个解释合理但也意味着——SLIDERS 不是万能的,对短文档反而有 overhead,适用边界要划清楚。
超长基准(≥3.9M tokens)
这才是 SLIDERS 真正秀肌肉的地方。
| 方法 | WikiCeleb100 (3.9M) | FinQ100 (36M) |
|---|---|---|
| RAG | 31.41 | 5.00 |
| LongRAG | 43.20 | 28.87 |
| GraphRAG | 48.59 | 跑不动(成本爆炸) |
| GPT-4.1 直接喂 | N/A(爆窗口) | N/A |
| DocETL | 54.26 | 跑不动 |
| RLM | 59.80 | 7.4%(只跑 10 文档,估算全跑 $2000) |
| SLIDERS (GPT-4.1) | 78.91 | 55.22 |
| SLIDERS (Qwen3.5 122B) | 76.92 | 60.18 |
WikiCeleb100 上 SLIDERS 78.91% vs RLM 59.80%,领先 19 个点。FinQ100 上对比更夸张——RLM 跑 10 个文档 7.4%,SLIDERS 跑全部 100 个文档 55.22%。
更狠的是 cost 的对比: - WikiCeleb100:GPT-4.1(如果有无限上下文)需要 $171.60,SLIDERS 只要 $13.10 - FinQ100:估算 $1800 vs SLIDERS 实际 $34.63
为什么差这么多?因为 SLIDERS 一旦构建了数据库,多个问题可以共享同一个数据库——抽取和对账只做一次,问答可以反复做。这就把成本从"每问一次重算一遍"变成了"一次性投入 + 每问只算 SQL"的模式,跟数据仓库的逻辑一样。
Ablation:到底哪个组件最重要?
| 配置 | F.Bench | Loong | Oolong | 平均 |
|---|---|---|---|---|
| SLIDERS 完整 | 80.00 | 84.37 | 64.67 | 74.79 |
| 去掉 Chunking(直接全文抽取) | 70.00 | 79.72 | 40.00 | 60.34 |
| 去掉 Reconciliation | 76.70 | 82.84 | 62.42 | 72.71 |
| 去掉 Reconciliation + SQL(直接 LLM 回答) | 70.00 | 84.45 | 58.62 | 70.74 |
几个有意思的发现:
Chunking 在 Oolong 上的影响最大——去掉就掉 24 个点。这点其实反直觉:你以为 chunking 是为了上下文限制不得不做的妥协,但实验显示,即使内容能塞下,chunking 抽取还是显著优于全文抽取。原因可能是聚焦——一次只看一小段,模型不容易遗漏。
去掉 Reconciliation 在 FinanceBench 上掉得最狠——3.3 个点。FinanceBench 主要是单文档的金融抽取,看上去对账影响不该这么大。但仔细想想,单一报告里也有"应付账款在某条目里说是 $1740,在汇总表里又是 $1663"这种内部不一致——对账正是用来处理这种问题的。
直接用 LLM 回答而不写 SQL,平均掉 4 个点——说明 SQL 这一层是实打实有用的。LLM 在已经结构化的数据上做"统计"也比直接回答更准。
对账 Agent 行为分析
这部分论文做了非常细的分析。几个关键数字: - 平均每个 primary key 组只需要 1.28 次迭代就能收敛 - FinQ100 上行数从平均 5+ 行/key 降到接近 1 行/key - 不同数据集的对账操作分布差异很大:FinQ100 主要是冲突解决,WikiCeleb100 主要是去重和整合,Loong Legal 几乎不需要对账
这种 dataset-dependent 的行为说明对账 agent 的判断是有针对性的,而不是机械套模板。
Schema 的鲁棒性、成本、延迟
Schema 不挑模型
| 数据集 | GPT-4.1 | GPT-4.1-mini | GPT-5 | 极差 |
|---|---|---|---|---|
| Loong Papers | 91.30 | 89.96 | 88.00 | 3.30 |
| Loong Legal | 64.12 | 68.34 | 61.26 | 7.08 |
| Loong Finance EN | 74.50 | 68.10 | 73.10 | 6.40 |
| Loong Finance ZH | 93.96 | 90.46 | 93.20 | 3.50 |
| Loong 平均 | 80.97 | 79.22 | 78.89 | 2.08 |
| FinanceBench | 76.71 | 80.00 | 80.00 | 3.33 |
Schema 复杂度差 4 倍,下游准确率只差 2.1 个点(Loong 平均)。这个鲁棒性意味着——你不用纠结于用最强的模型去生成 schema,便宜模型就够用。
成本:每问 $0.76
平均每个问题 $0.76,其中 ~40% 花在 entity resolution 上(要扫全表找潜在匹配)。对比 RLM agent scaffolding,SLIDERS 在更高准确率下成本相当或更低。
延迟:端到端 vs Amortized
- 端到端:从零开始为单个查询构建结构化表示,Loong 平均 2.6 分钟,FinanceBench 3 分钟
- Amortized:离线一次性构建,在线问答只需 ~25 秒/问
WikiCeleb100 完整离线 pipeline 只要 16 分钟(schema 20s + 抽取 6 分钟并行 + 对账 9.7 分钟)。同一份数据 GraphRAG 要 2.3 小时 + $182,准确率还更低。
我的判断:这篇论文哪些值钱、哪些有局限
值钱的地方
第一,"Aggregation Bottleneck"这个 framing 立得住。它精准击中了 chunk-based 方法的核心痛点——很多人下意识以为长上下文窗口扩大就解决了问题,但忽略了"聚合"本身也需要长上下文能力。这个 framing 之后,"为什么需要结构化推理"就变得自然且有说服力。
第二,把 reasoning 拆成"信息表示 + SQL 执行"是个根本性的架构选择。这跟数据仓库的"ETL + SQL"是同构的,工程上几十年的实践早就证明这条路走得通。LLM 不擅长聚合,但 LLM 擅长把自然语言翻译成 SQL;DB 不会写自然语言,但 DB 做聚合既准又便宜。把每个工具放在它最擅长的位置,就是好工程。
第三,对账阶段是真正的硬核创新。把 provenance 和 extraction rationale 当作 first-class 信号去做对账,配合 LLM 写 SQL 完成清理——这个设计在我看来是这篇论文最值钱的部分。它不只是"加一步去重",而是整套基于证据的清理框架。
第四,可审计性是杀手级特性。所有对账动作都是 SQL,所有抽取都带 provenance——这意味着金融、法律、医疗这种高风险场景里,人类审核员可以追到每一条结论的源头。这种属性比单纯的准确率更重要。
我觉得有问题的地方
第一,对短文档反而有 overhead。Loong 中文法律子集就是反例。论文承认了这点但没给出"什么场景下不该用 SLIDERS"的明确建议。如果你做的是单文档抽取且文档不长,老老实实直接喂模型可能更好。
第二,schema 归纳质量有上限。论文说 schema 不是 fragile bottleneck,但它也提到"过度复杂的 schema 反而增加对账难度"——这意味着 schema 必须卡在一个 sweet spot。对于"开放性问题"(用户问得很模糊),怎么生成 schema 还是个开放问题。
第三,依赖 LLM 写正确 SQL。整个 pipeline 假设 LLM 能可靠地把意图翻译成 SQL。在简单查询上这是没问题的,但碰到复杂的多表 join、嵌套子查询,LLM 写错的概率不低。论文没专门讨论这块的 failure mode。
第四,benchmark 的"新颖度"。WikiCeleb100 和 FinQ100 是论文作者新构造的——只有 22 和 25 个问题。虽然问题有挑战性,但样本量这么小,置信区间会比较大。FinQ100 上 SLIDERS 55%,看起来比 baseline 高很多,但这个绝对数值距离"可用"还差得远。论文自己也承认"对自动化来说还不够可靠"。
给工程实践的启发
如果你在做以下场景,SLIDERS 这套思路值得借鉴:
- 多文档分析、需要做跨文档聚合(金融分析、医疗记录、法律文献综述)
- 同一份文档库需要回答多个问题(amortized 模式收益最大)
- 需要可审计、可追溯的回答(合规、风险评估)
- 数据规模超过任何单 LLM 的可靠上下文(百万到亿级 token)
不太适用的场景:
- 单文档、短文本的直接问答(直接喂模型更省事)
- 需要"开放式""创造性"输出的任务(结构化反而会丢信息)
- 实时响应要求强(端到端 2-3 分钟肯定不够)
跟同期工作的对比
跟 DocETL(Berkeley)相比,SLIDERS 的关键差异是有显式的对账阶段。DocETL 的优化器更侧重于"如何选择最好的 ETL pipeline",而 SLIDERS 更侧重于"如何把抽取结果清洗成全局一致的数据库"。
跟 RLM(Recursive Language Model)相比,SLIDERS 用关系数据库作为持久化中间状态,RLM 用 Python 程序递归调用。SLIDERS 在准确率和成本上都领先,主要是因为 SQL 的执行确定性比"让 LLM 写 Python 程序"更高。
跟 GraphRAG(微软)相比,两者都试图用结构化中间表示。GraphRAG 用知识图谱,SLIDERS 用关系数据库。从实验看 SLIDERS 在长文档场景全面胜出,原因可能是关系数据库的"聚合"操作(COUNT、SUM、AVG、GROUP BY)天然适合财务、统计这类查询,而知识图谱的"路径查询"在这类场景反而绕。
写在最后
这篇论文给我最大的感受是——长上下文不是终点,结构化才是。我们一直在追求"模型能读多长的输入",但真实世界的工作流早就证明:人类做长文档分析也不是把所有页面都摊开同时读,而是抽出表格、做笔记、整理成结构化的数据,然后再分析。
SLIDERS 把这个工作流固化成了一个可执行的 pipeline。它没有发明新的注意力机制,没有训练新的模型,但靠把"抽取"和"推理"分开这一个架构决策,就在 36M token 的真实数据上把准确率从 5% 拉到 55%——这个跃迁是任何"再扩 10 倍上下文窗口"都做不到的。
如果你也在做企业级长文档分析、做 agent 多轮调用工具、做知识库问答——这套"结构化推理"的思路值得仔细琢磨一下。把对的事情交给对的工具,永远比"用一个工具解决所有问题"要走得远。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我