TurboQuant:用 3-bit 把 KV Cache 压 6 倍,Google 给内存芯片上了一课
核心摘要
大模型推理的瓶颈早就不在算力了——是内存带宽。当你的 LLM 在 128K 上下文下跑不动,不是 GPU 不够快,是显存装不下那么长的 KV Cache。Google Research 提出的 TurboQuant 给出了一个近乎暴力的解法:把 KV Cache 量化到 3-bit,压缩 6 倍,推理加速 8 倍,精度几乎零损失。这不是工程 trick,而是有信息论下界证明的算法突破——在 3.5 bits 时达到"质量中性",意味着再往下压也不会更差了,因为已经接近理论最优。
🎯 问题背景:内存才是 LLM 推理的真正瓶颈
你可能觉得大模型推理慢是因为计算量大。但在实际部署中,内存带宽才是真正的瓶颈。
KV Cache 为什么这么大?
Transformer 模型在推理时需要缓存每一层的 Key 和 Value 矩阵,这就是 KV Cache。问题来了:
假设 Llama-3.1-70B,128K 上下文:
- 每个 token 需要 2 × num_layers × hidden_dim × 2 bytes (FP16)
- 大约 70GB 显存,光是 KV Cache 就吃掉一大半
这就是为什么 128K 上下文的模型在消费级显卡上根本跑不起来——不是算不过来,是装不下。
现有压缩方案的局限
| 方法 | 问题 |
|---|---|
| INT8 量化 | 只能压 2 倍,不够激进 |
| 乘积量化 (PQ) | 需要离线训练码本,索引时间长(几百秒) |
| KIVI / SnapKV | 压缩率有限,长上下文还是会 OOM |
| 传统量化 | 需要存储量化参数(零点、缩放因子),有额外开销 |
核心矛盾:想要高压缩率,就得接受精度损失;想要保持精度,就压不下去。有没有办法打破这个魔咒?
💡 TurboQuant 的核心洞察
TurboQuant 的关键发现是:高维向量在随机旋转后,坐标会变得近似独立且服从已知分布。
这听起来像数学废话,但它的实际意义是:
两个关键数学特性
1. 随机旋转后的坐标分布
对向量 \(\bm{x}\) 乘以随机旋转矩阵 \(\bm{\Pi}\) 后,每个坐标 \(y_j\) 服从 Beta 分布,在高维时收敛于正态分布 \(\mathcal{N}(0, 1/d)\):
2. 坐标之间的近似独立性
高维空间中,旋转后不同坐标之间近似独立。这意味着:
两阶段架构:MSE + 无偏内积
TurboQuant 实际上提供了两种算法:
| 算法 | 目标 | 特点 |
|---|---|---|
| TurboQuant_mse | 最小化 MSE | 单阶段,有偏内积估计 |
| TurboQuant_prod | 无偏内积估计 | 两阶段,用于注意力计算 |
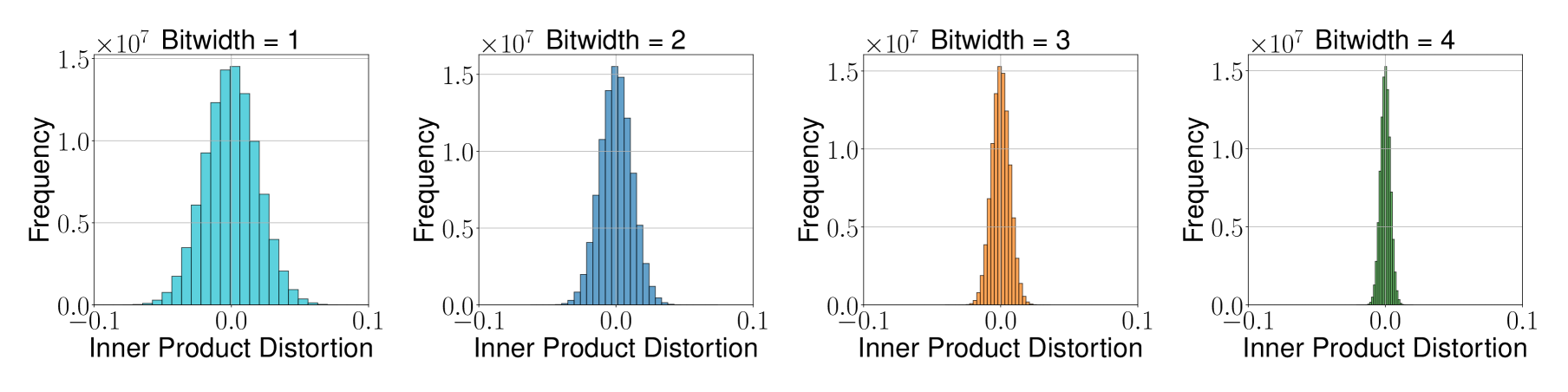
图1:TurboQuant_mse 在 1~4 bit 下的内积失真直方图。可以看到 3-bit 时分布已非常集中于零附近,4-bit 时几乎完全集中,验证了算法的量化误差控制能力。
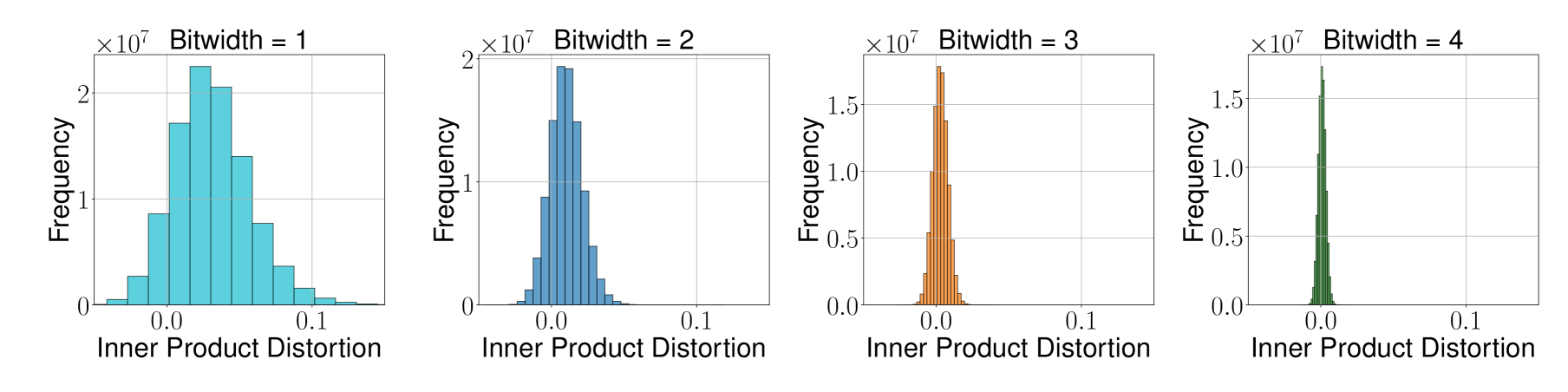
图2:TurboQuant_prod 对比 TurboQuant_mse,分布更加对称且均值更接近零,体现了第二阶段 QJL 量化消除偏差的效果。
为什么需要两阶段?
纯 MSE 量化器在内积估计中存在偏差。在注意力机制中,Query 和 Key 的内积直接决定注意力权重——偏差会导致注意力分数偏移,影响生成质量。
TurboQuant_prod 的两阶段流程:
第一阶段:MSE 量化 (b-1 bits)
├── 捕获向量的主要信息和强度
└── 得到粗略估计 + 残差
第二阶段:QJL 量化 (1 bit)
├── 对残差应用 Johnson-Lindenstrauss 变换
├── 只保留符号位 (+1/-1)
└── 消除偏差,实现无偏内积估计
🔧 算法详解
TurboQuant_mse 工作流程
[初始化阶段]
1. 生成随机旋转矩阵 Π ∈ ℝ^(d×d)
2. 通过 Lloyd-Max 算法计算最优质心 c_1, ..., c_{2^b}
[量化过程]
输入:向量 x
1. y ← Π · x # 随机旋转
2. idx_j ← argmin_k |y_j - c_k| # 找最近质心
输出:索引向量 idx
[反量化过程]
输入:索引向量 idx
1. ̃y_j ← c_{idx_j} # 查表重构
2. ̃x ← Π^⊤ · ̃y # 反向旋转
输出:重构向量 ̃x
失真上界: $\(D_{\text{mse}} \leq \frac{\sqrt{3}\pi}{2} \cdot \frac{1}{4^b}\)$
| 位宽 | 理论失真 |
|---|---|
| 1-bit | 0.36 |
| 2-bit | 0.117 |
| 3-bit | 0.03 |
| 4-bit | 0.009 |
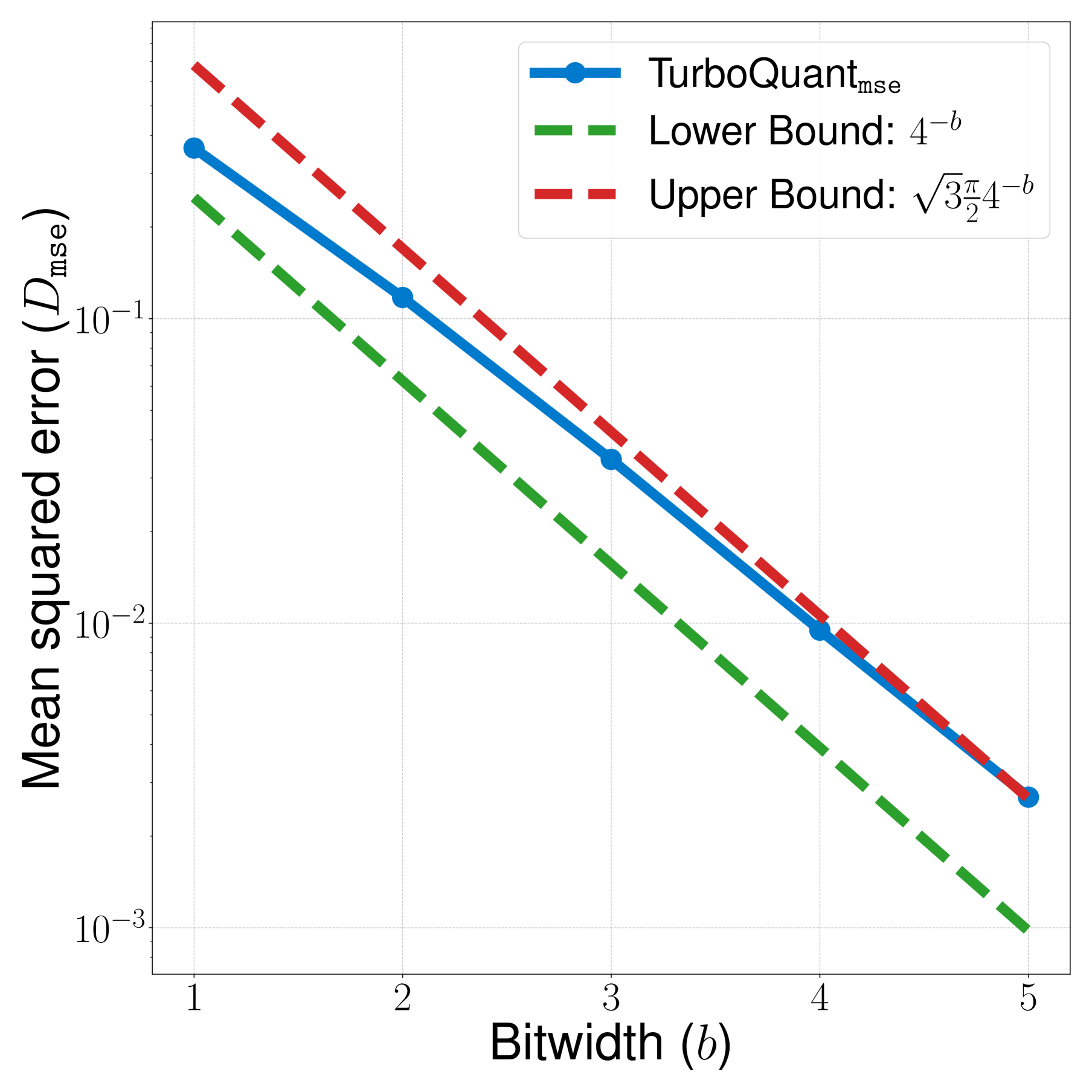
图3:TurboQuant_mse 的 MSE 失真(蓝色实线)随位宽指数衰减,始终介于信息论下界(绿色虚线 \(4^{-b}\))和理论上界(红色虚线 \(\sqrt{3}\frac{\pi}{2} \cdot 4^{-b}\))之间,差距仅约常数倍。
TurboQuant_prod 工作流程
[量化过程]
输入:向量 x
1. idx ← Quant_mse(x) # 第一阶段 MSE 量化 (b-1 bits)
2. r ← x - DeQuant_mse(idx) # 计算残差
3. qjl ← sign(S · r) # QJL 符号 (1 bit)
4. γ ← ||r||_2 # 残差模长
输出:(idx, qjl, γ)
[反量化过程]
输入:(idx, qjl, γ)
1. ̃x_mse ← DeQuant_mse(idx) # 第一阶段重构
2. ̃x_qjl ← (√(π/2) / d) · γ · S^⊤ · qjl # QJL 重构
3. ̃x ← ̃x_mse + ̃x_qjl # 合并
输出:最终重构向量
关键性质——无偏性: $\(\mathbb{E}[\langle \bm{y}, \tilde{\bm{x}} \rangle] = \langle \bm{y}, \bm{x} \rangle\)$
这意味着内积估计的期望等于真实内积,没有系统性偏差。
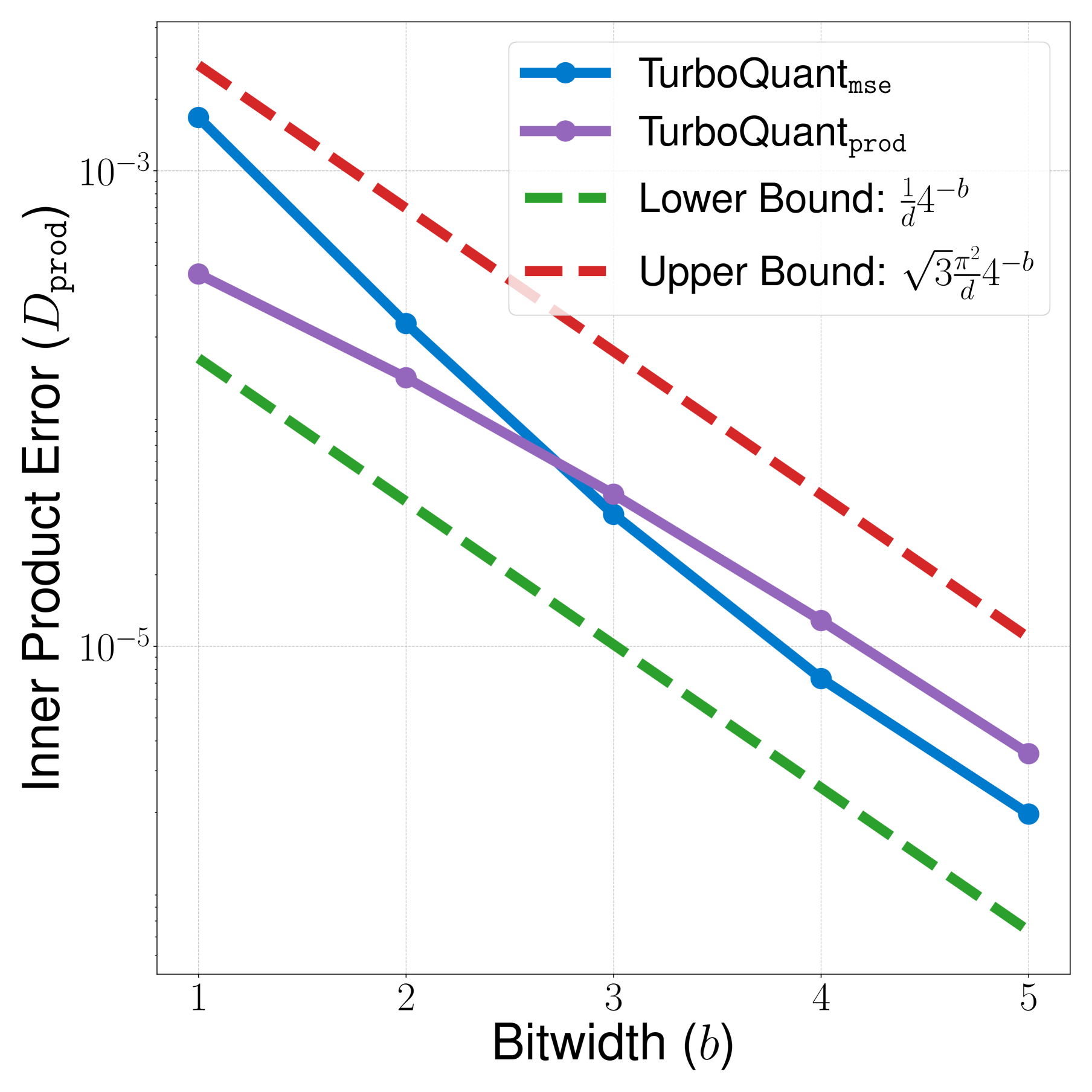
图4:TurboQuant_mse(蓝线)和 TurboQuant_prod(紫线)的内积误差随位宽指数下降,均介于理论下界(绿虚线)和上界(红虚线)之间,且 prod 版本在高位宽时更接近下界。
📊 实验结果
1. Needle-In-A-Haystack:大海捞针测试
在 4x 压缩(内存压缩比 0.25)下测试 Llama-3.1-8B-Instruct:
| 方法 | 得分 |
|---|---|
| Full-Precision (无压缩) | 0.997 |
| SnapKV | 0.858 |
| PyramidKV | 0.895 |
| KIVI | 0.981 |
| PolarQuant | 0.995 |
| TurboQuant | 0.997 |
结论:TurboQuant 在 4x 压缩下实现了与全精度模型完全相同的性能。
下面的热力图更直观地展示了各方法在不同上下文长度和深度位置上的得分分布:
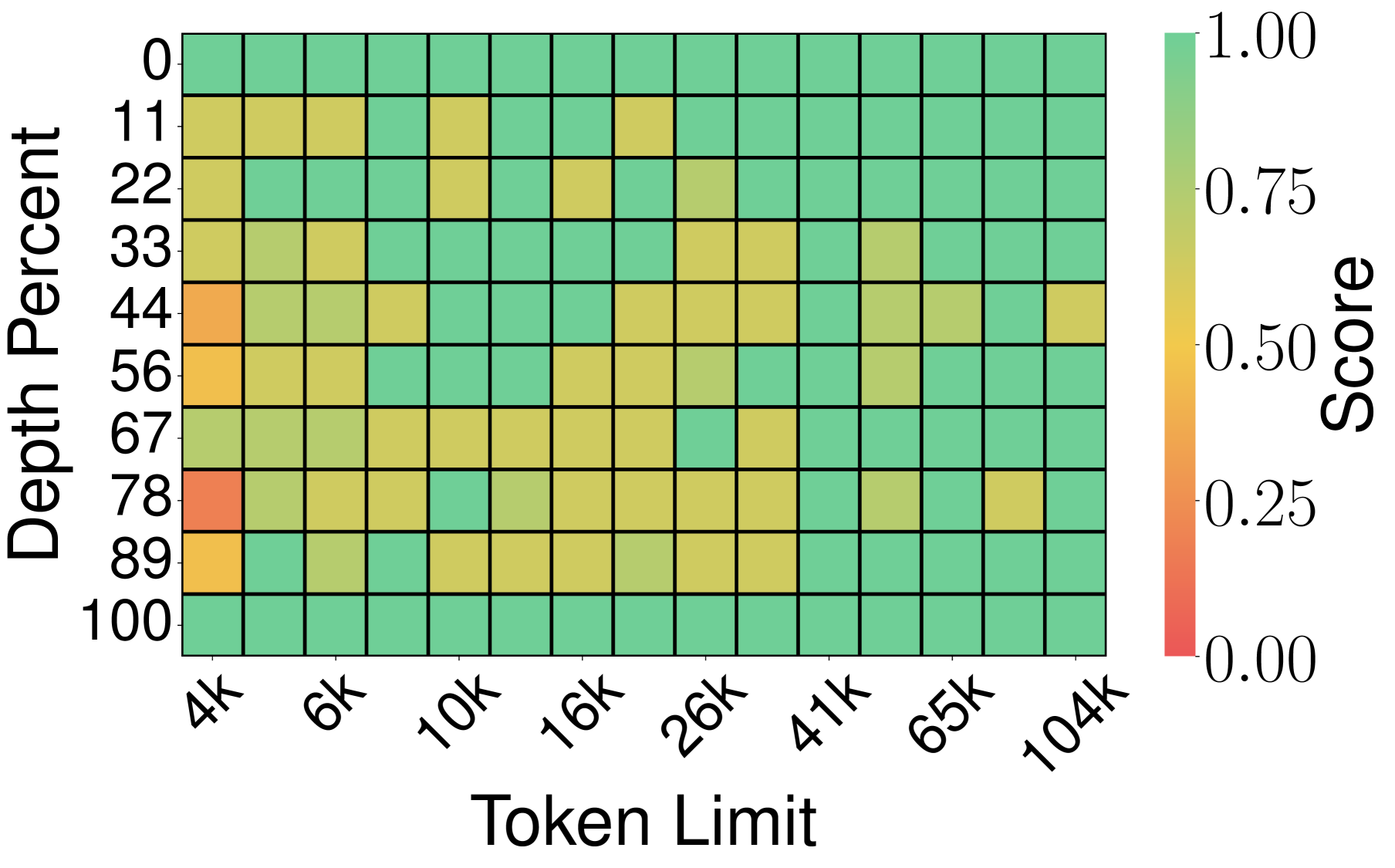
图5:SnapKV(压缩比 0.25)在多个深度位置和 token 长度上出现大量失分(黄色/红色),说明 token 选择策略的局限性。
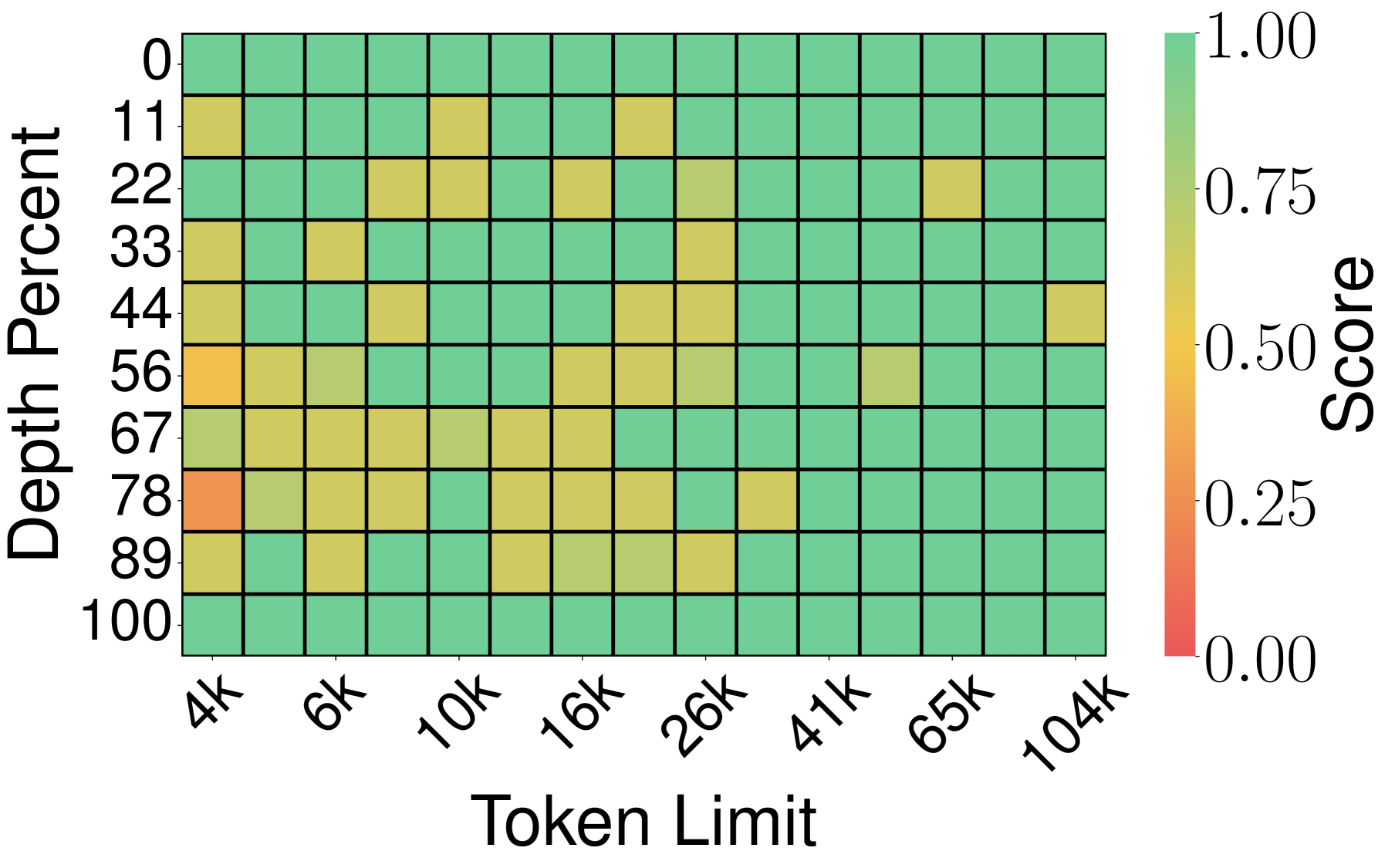
图6:PyramidKV 同样在相近区域出现失分,说明金字塔式分层的预算分配仍有盲区。
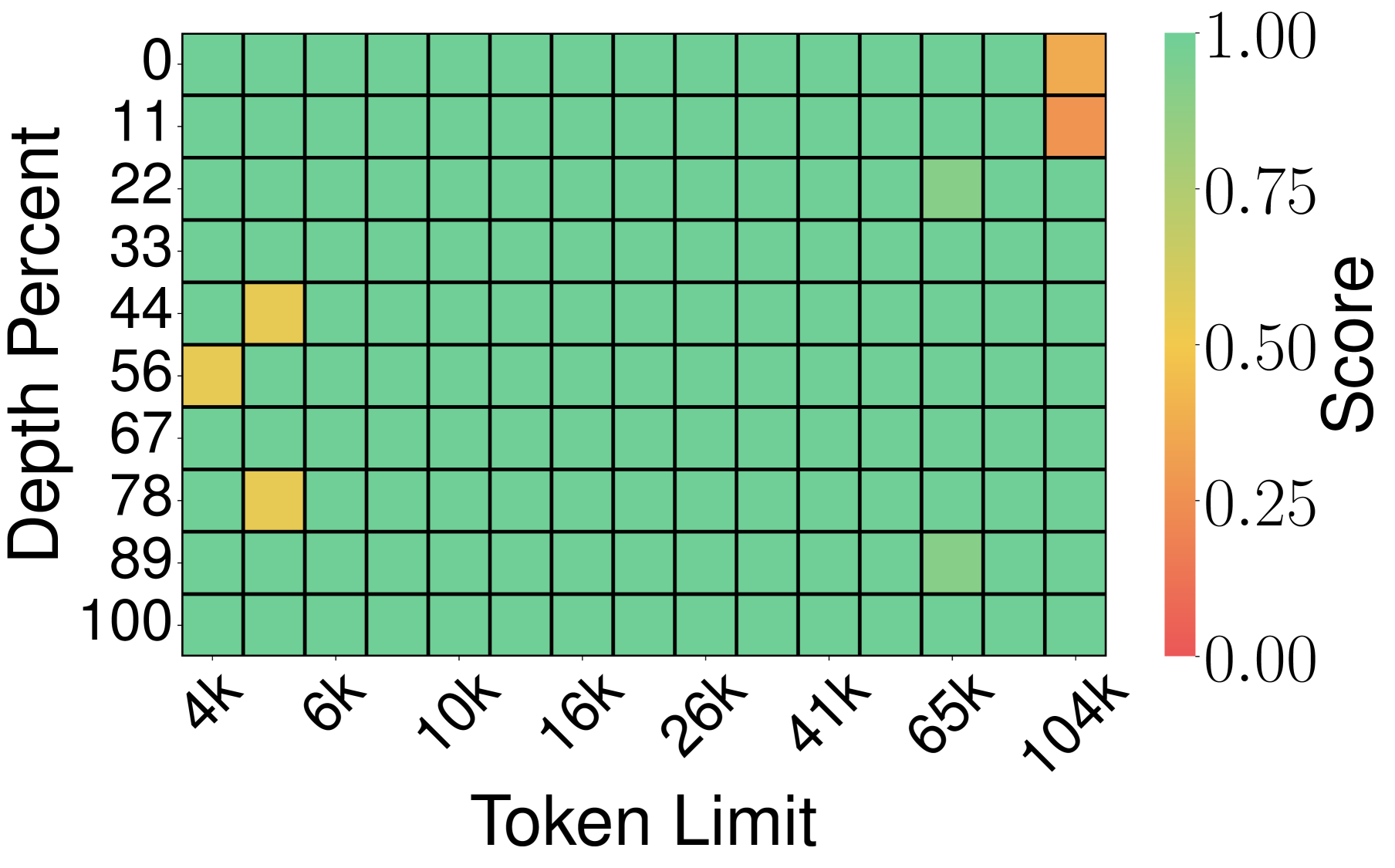
图7:KIVI 整体表现较好,仅少量边缘位置出现失分,但并未达到全精度水平。
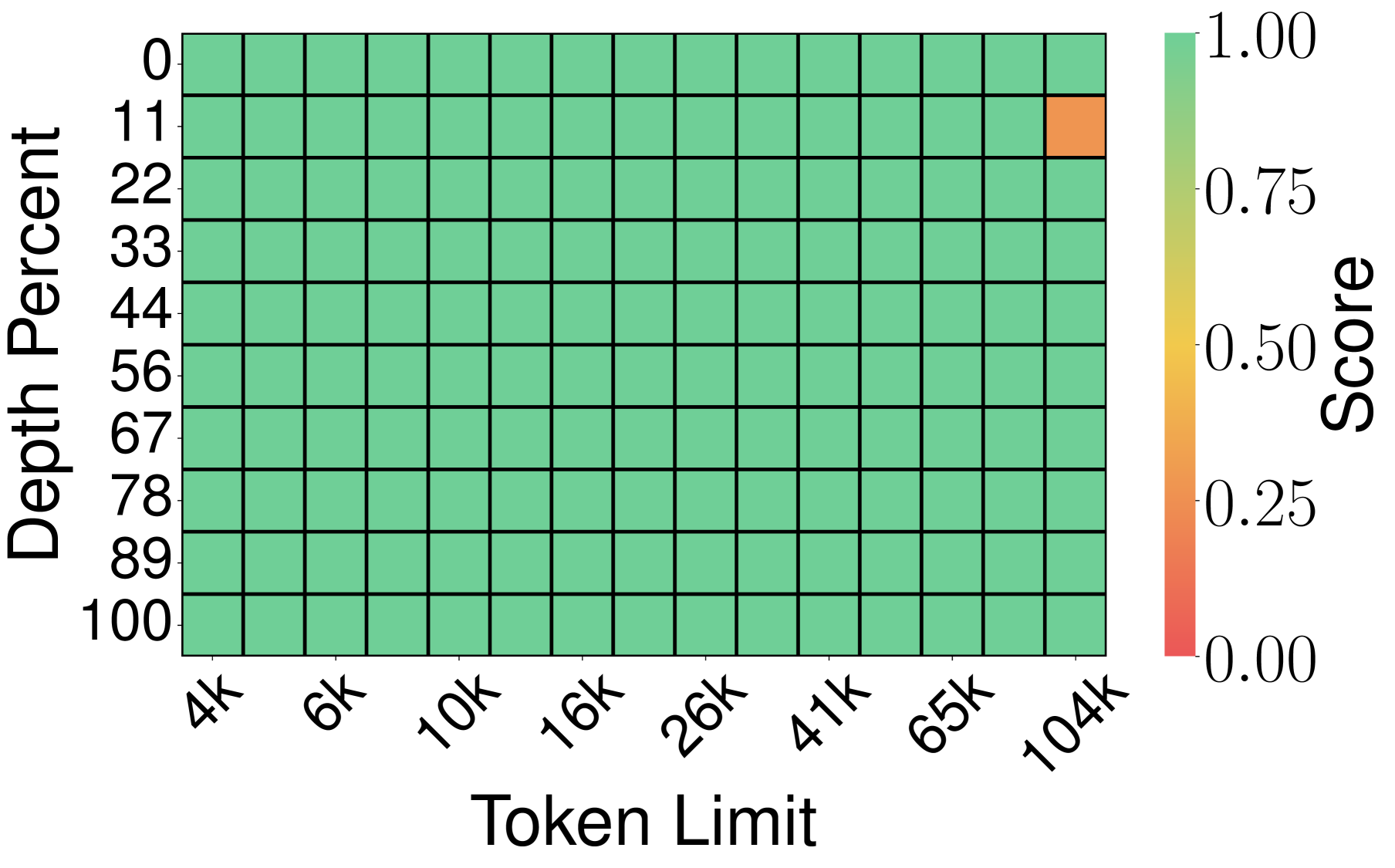
图8:PolarQuant 热力图接近全绿,仅极少位置有轻微失分,是 TurboQuant 之前最强的对比方法。
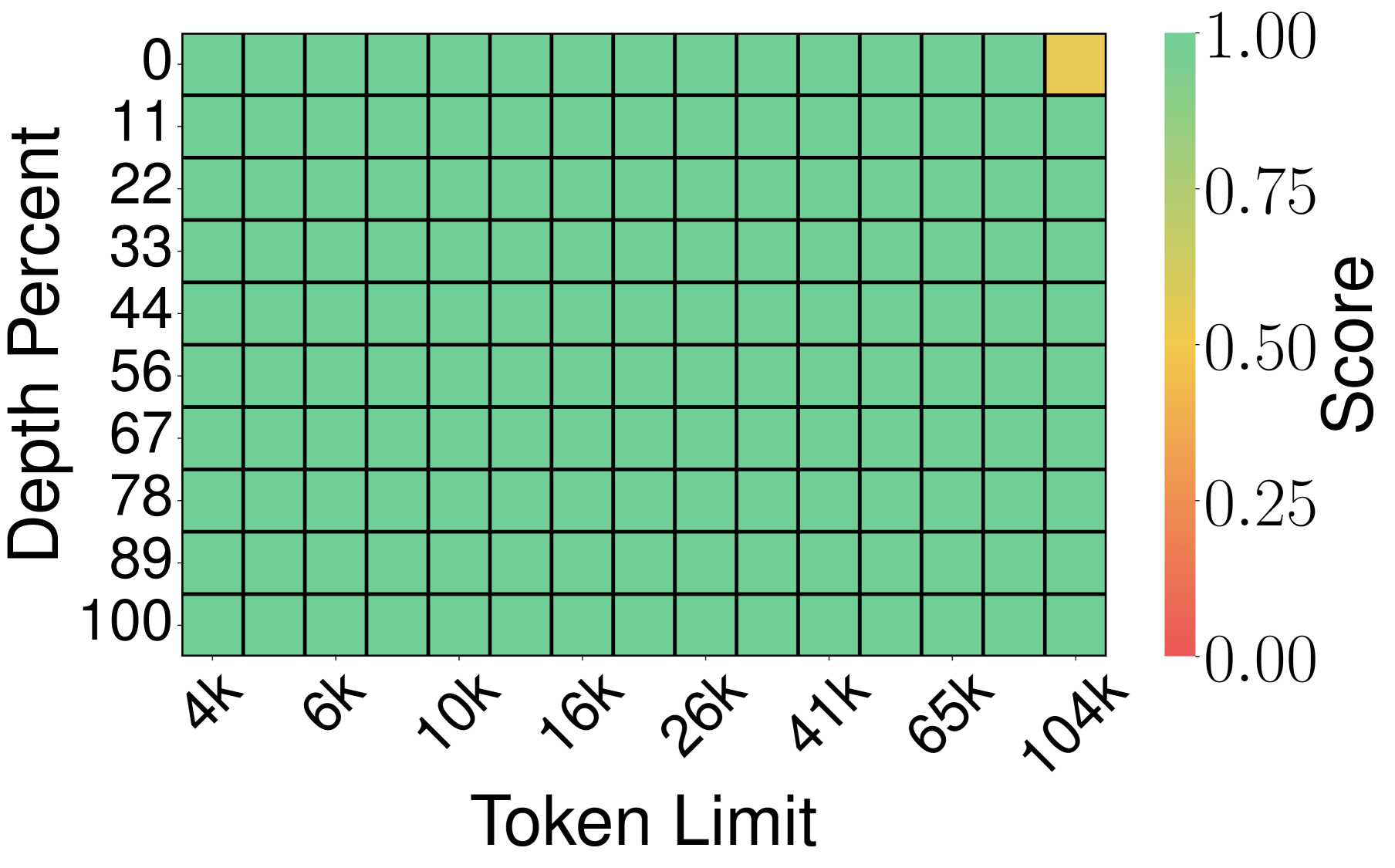
图9:TurboQuant_mse 在所有位置几乎满分,仅右上角极远处有极小失分。
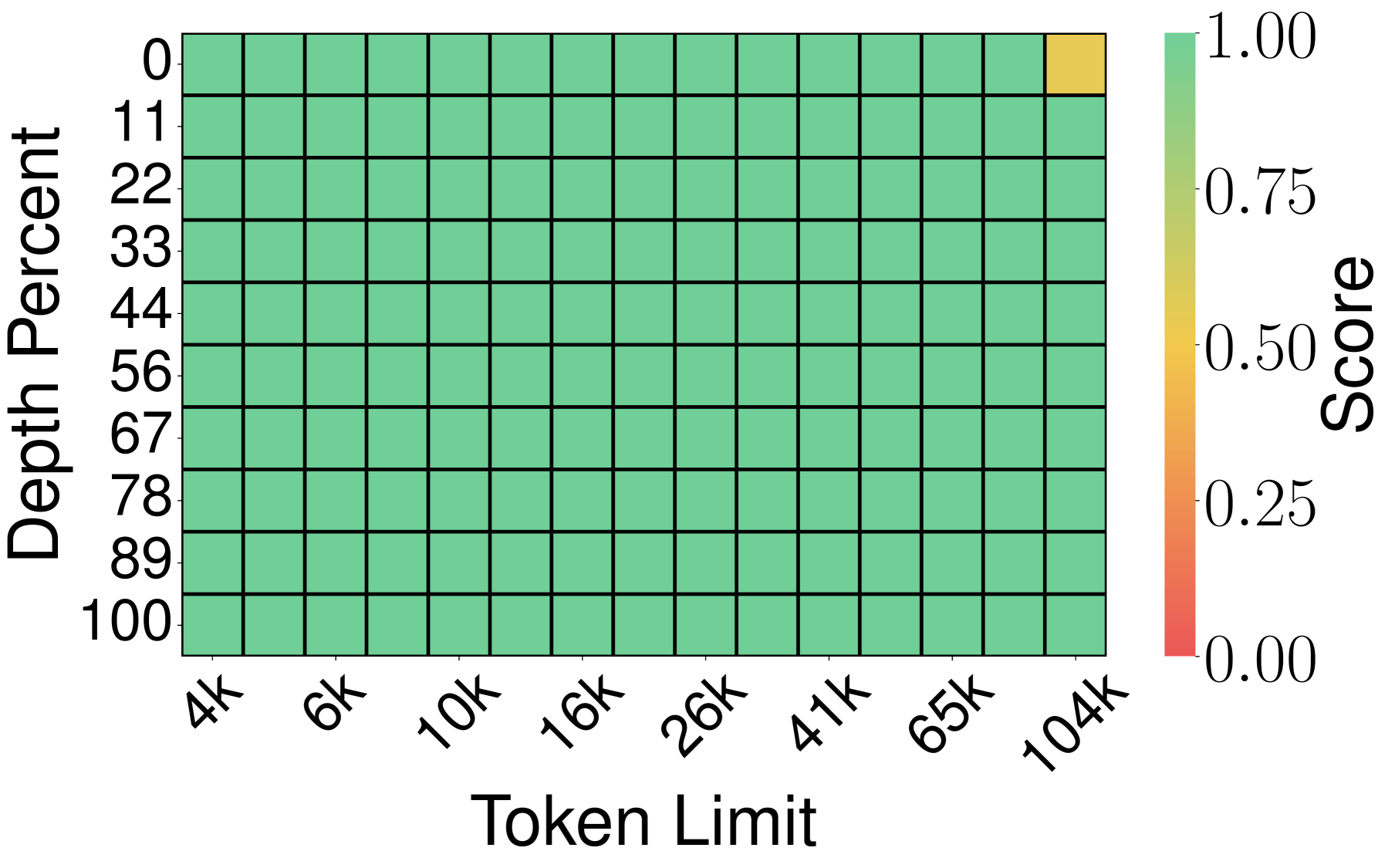
图10:TurboQuant_prod 热力图与 TurboQuant_mse 类似,整体覆盖全面,两者均与全精度模型(0.997)持平。
2. LongBench:端到端生成质量
| 模型 | 方法 | 位宽 | 平均分 |
|---|---|---|---|
| Llama-3.1-8B | Full Cache | 16 bits | 50.06 |
| KIVI | 5 bits | 50.16 | |
| PolarQuant | 3.9 bits | 49.78 | |
| TurboQuant | 3.5 bits | 50.06 | |
| TurboQuant | 2.5 bits | 49.44 | |
| Ministral-7B | Full Cache | 16 bits | 49.89 |
| TurboQuant | 2.5 bits | 49.62 |
关键发现:3.5 bits 实现"质量中性"——与全精度模型得分完全相同(50.06)。
3. 最近邻搜索:索引时间对比
| 维度 | PQ | RabitQ | TurboQuant |
|---|---|---|---|
| 200 | 37.04s | 597.25s | 0.0007s |
| 1536 | 239.75s | 2267.59s | 0.0013s |
| 3072 | 494.42s | 3957.19s | 0.0021s |
TurboQuant 的索引时间几乎为零——因为它不需要训练码本,可以直接在线量化。
除了速度,TurboQuant 的召回率也不输有离线训练优势的 PQ 和 RabitQ:
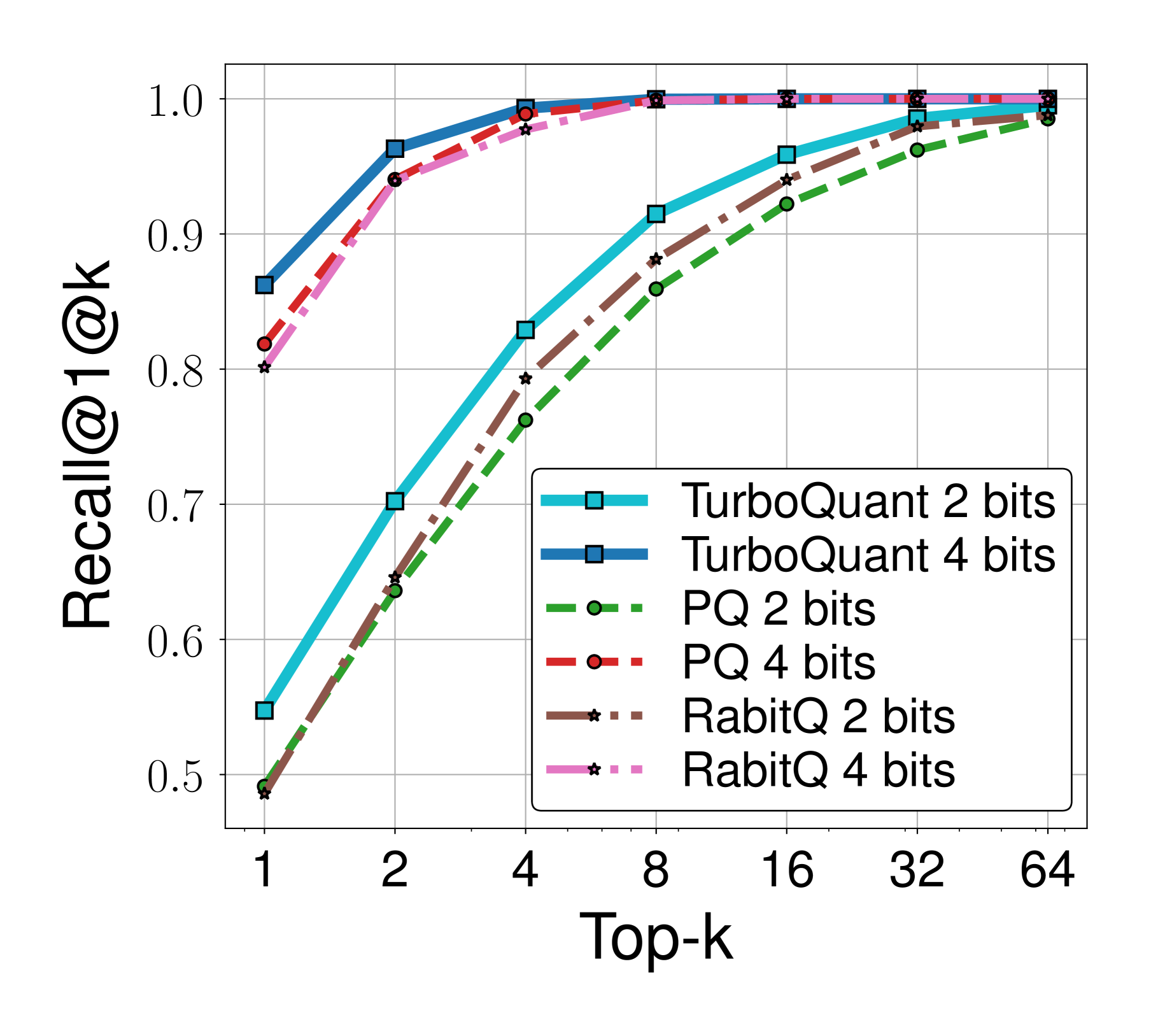
图11:在近似最近邻搜索中,TurboQuant 4-bit(深蓝实线)的召回率与 PQ 4-bit(红色虚线)接近,且 TurboQuant 2-bit(青色线)虽然稍低,但索引构建完全在线、毫秒级完成,而 PQ 需要离线训练数百秒。
4. 推理加速
在 H100 GPU 上,4-bit TurboQuant 相比 32-bit 原始表示: - 注意力 logits 计算加速 8 倍 - 运行时开销可忽略
🧠 为什么 TurboQuant 能这么强?
理论保证:接近信息论下界
论文证明了任何向量量化器的失真下界: - MSE 下界:\(\geq \frac{1}{4^b}\) - 内积失真下界:\(\geq \frac{1}{d} \cdot \frac{1}{4^b}\)
TurboQuant 的失真仅比理论下界差约 2.7 倍的常数因子。
这意味着什么?在信息论意义上,TurboQuant 已经接近最优。再往下压,任何算法都不可能做得更好。
下图展示了 TurboQuant_prod 在不同向量夹角(avg IP)场景下的内积失真分布,验证了其在各种数据分布下的稳定性:
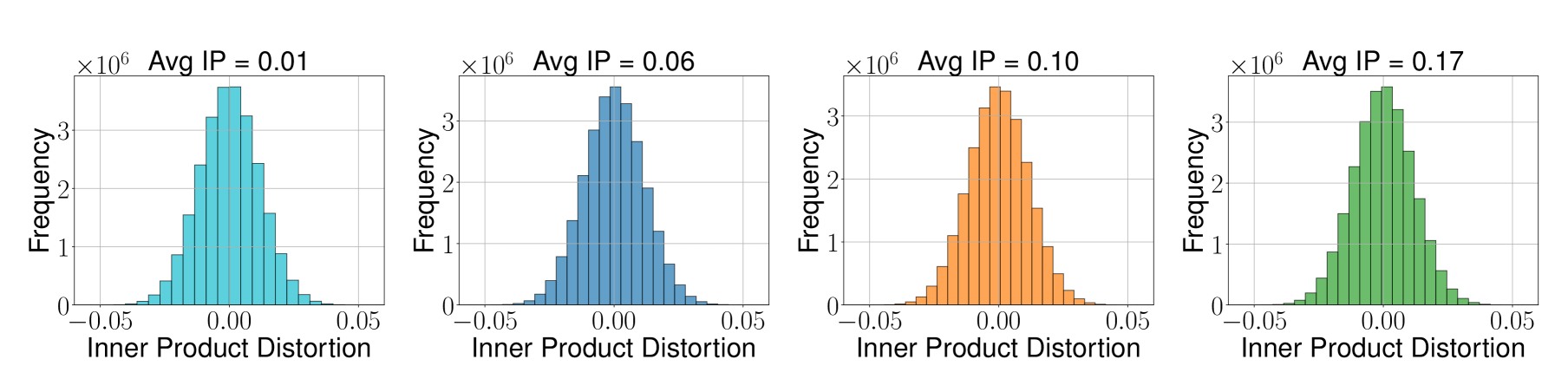
图12:在 avg IP 从 0.01(几乎正交)到 0.17(有一定相关性)的场景下,TurboQuant_prod 的内积失真分布始终以零为中心,说明无偏性在不同数据分布下均成立。
数据无关:零调参成本
传统量化方法(如 PQ)需要: 1. 收集校准数据 2. 训练码本(几百秒) 3. 数据分布变化时重新训练
TurboQuant: 1. 随机旋转矩阵——不用学 2. 最优标量量化器——有闭式解 3. 完全数据无关,即插即用
无额外存储开销
传统量化需要为每个数据块存储: - 零点(zero-point):全精度 - 缩放因子(scale):全精度
这些"量化参数"本身就要占 1-2 bits,部分抵消了压缩收益。
TurboQuant 利用随机旋转后的坐标分布已知(Beta 分布),不需要存储任何量化参数。
🔬 与其他工作的关系
TurboQuant 并非凭空出现,它整合了多项前置工作的思想:
PolarQuant(AISTATS 2026)
PolarQuant 将向量转换为极坐标(半径 + 角度),发现角度分布紧密有界,无需显式归一化。
TurboQuant 在第一阶段使用了 PolarQuant 的思想:通过坐标变换使数据落入已知分布。
QJL:Quantized Johnson-Lindenstrauss
QJL 是一种 1-bit 量化方法,将向量投影到随机方向后只保留符号。它的关键性质是提供无偏的内积估计。
TurboQuant 在第二阶段使用 QJL 来消除 MSE 量化器的偏差。
与工业界方案的对比
| 方案 | 压缩率 | 精度损失 | 训练成本 | 部署复杂度 |
|---|---|---|---|---|
| KIVI | ~3x | 小 | 无 | 低 |
| SnapKV | ~3x | 中 | 无 | 中 |
| TurboQuant | 6x+ | 几乎为零 | 无 | 低 |
TurboQuant 在压缩率和精度上都优于现有方案,同时保持了零训练成本和低部署复杂度。
⚠️ 局限性与思考
1. 旋转矩阵的计算开销
虽然旋转本身是 \(O(d^2)\) 的矩阵乘法,但对于高维向量(如 1536 维)仍有计算开销。论文提到可以使用 Hadamard 变换或 FFT 加速,将复杂度降到 \(O(d \log d)\)。
2. 残差模长的存储
TurboQuant_prod 需要额外存储残差模长 \(\gamma\),这增加了少量开销。不过模长是标量,存储成本可以忽略。
3. 实际部署的工程挑战
TurboQuant+ 开源项目发现了一些论文未提及的工程细节: - K/V 非对称压缩:Key 对精度更敏感,建议 Key 用 8-bit,Value 可以用更低位宽 - 边界层保护:模型的首尾层对量化更敏感,需要特殊处理
4. 绝对性能 vs 相对性能
虽然 TurboQuant 在相对指标上表现优异,但 3-bit 量化的绝对性能仍有提升空间。在极端压缩场景(如边缘设备),可能需要结合其他技术(如稀疏化)进一步提升。
💭 更深层的启示:LLM 的参数冗余
TurboQuant 再次印证了一个观点:LLM 的表示空间存在大量冗余。
冗余在哪里?
| 位置 | 冗余类型 | 压缩极限 |
|---|---|---|
| 模型权重 | 参数冗余 | INT4 (~4x) |
| KV Cache | 状态冗余 | 3-bit (~6x) |
这暗示了一个更深层的问题:LLM 学到的表示中,有多少是真正"有用"的信息,又有多少是可以被压缩掉的"噪声"?
冗余是好是坏?
好的方面: - 提供鲁棒性,对抗噪声和分布外样本 - 支持多任务泛化 - 可能隐含"隐式集成"效果
坏的方面: - 推理时内存/计算浪费 - 部署成本高 - 可能过度记忆训练数据
TurboQuant 证明了:至少 6 倍的 KV Cache 信息是可以被"安全压缩"的。这些冗余对模型性能几乎无害。
📌 总结
TurboQuant 是"理论优雅 + 工程实用"的典范:
| 维度 | TurboQuant 的表现 |
|---|---|
| 压缩率 | 6x+(3.5 bits 实现"质量中性") |
| 精度损失 | 几乎为零 |
| 训练成本 | 零(数据无关) |
| 部署复杂度 | 低(即插即用) |
| 理论保证 | 接近信息论下界(常数因子 2.7) |
| 推理加速 | 8x(H100 上注意力计算) |
它不仅是一个压缩算法,更是对 LLM 表示空间的一次深入探索。当我们可以把 KV Cache 压到 3-bit 而几乎无损时,不禁要问:模型里还有多少"水分"可以被挤掉?
参考文献
- Amir Zandieh, Majid Daliri, Majid Hadian, Vahab Mirrokni. "TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate." ICLR 2026.
- Insu Han et al. "PolarQuant: Quantizing KV Caches with Polar Transformation." AISTATS 2026.
- Google Research Blog. "TurboQuant: Redefining AI efficiency with extreme compression." 2026.
- TurboQuant+ 开源项目:https://github.com/TheTom/turboquant_plus
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注公众号:机器懂语言