AI能自主做临床科研了吗?港中文&斯坦福联手造出第一个医学AI科学家
核心摘要
2024年 Lu et al. 提出的 The AI Scientist 让人眼前一亮——一个通用 LLM 系统能自主跑完从选题到写论文的全流程。但它有个硬伤:完全不懂医学。临床研究不只是代码问题,还涉及多模态医疗数据(MRI、病理切片、内窥镜视频)、医学证据可追溯性、数据使用伦理政策。香港中文大学、里海大学、斯坦福大学联合提出的 Medical AI Scientist 是第一个专门针对临床自主科研的框架,核心创新在于引入"临床医生-工程师协同推理机制",让 AI 在提出假设时不只会查文献,还能把医学先验(比如"糖尿病视网膜病变有局部血管病变和弥漫性神经退行性变两种模式")直接转化为模型设计(双路径扩散架构)。在 171 个评估案例上,生成的研究想法全面优于 GPT-5 和 Gemini-2.5-Pro;生成的论文质量接近 MICCAI,已有一篇被 ICAIS 2025 接收。
🎯 通用 AI Scientist 为什么进不了临床?
The AI Scientist(Lu et al., 2024)的野心很大:给定一个研究方向,自动完成文献调研 → 提出假设 → 写代码 → 跑实验 → 写论文。但它在医学场景下几乎开箱即挂:
- 数据模态不对:MRI、病理切片、内窥镜视频这些医疗数据,通用 Agent 根本不知道怎么加载和预处理
- 证据不可追溯:提出的假设来自哪篇文献哪个结论,临床研究要求有出处
- 伦理合规缺失:医学论文发表有严格的数据使用政策,自动生成系统必须主动声明数据来源和伦理批准
- 评估基准缺失:没有针对自动化医学研究的标准化评估框架
Medical AI Scientist 的出发点就是解决这四个问题。
🏗️ 系统架构:三大核心模块

图1:系统整体架构。左侧是三种工作模式(论文复现、文献启发创新、任务驱动探索);中间是 Idea Proposer(创意提出者)、Experimental Executor(实验执行者)、Manuscript Composer(手稿撰写者)三大核心模块;底层基础设施包括 Docker 化沙箱、MONAI/SimpleITK 医学工具箱、PubMed/IEEExplore 知识库。
整个框架的运作分为三个串联模块:
1. Idea Proposer(创意提出者)
这是最核心的创新点。医学研究假设的生成不能靠通用 LLM 随便联想——它需要把文献里的医学知识和工程实现方案真正对接起来。
临床医生-工程师协同推理机制的工作流:
| 子模块 | 职责 |
|---|---|
| Analyzer | 解析临床任务的核心挑战(如"糖尿病视网膜病变多类别不平衡") |
| Explorer | 搜索匹配的计算范式(如"扩散模型 + 双路径架构") |
| Surveyor | 从文献中构建结构化证据库(医学证据 + 工程证据分开存储) |
| Generator | 把医学先验和工程方案组合生成可验证的假设 |
| Assessor | 多维评估(新颖性 + 伦理性 + 可行性) |
这个机制的关键:医学先验不是作为软提示混进 prompt 里,而是以结构化证据的形式存储,生成的研究想法中每个核心设计都能追溯到具体文献。
2. Experimental Executor(实验执行者)
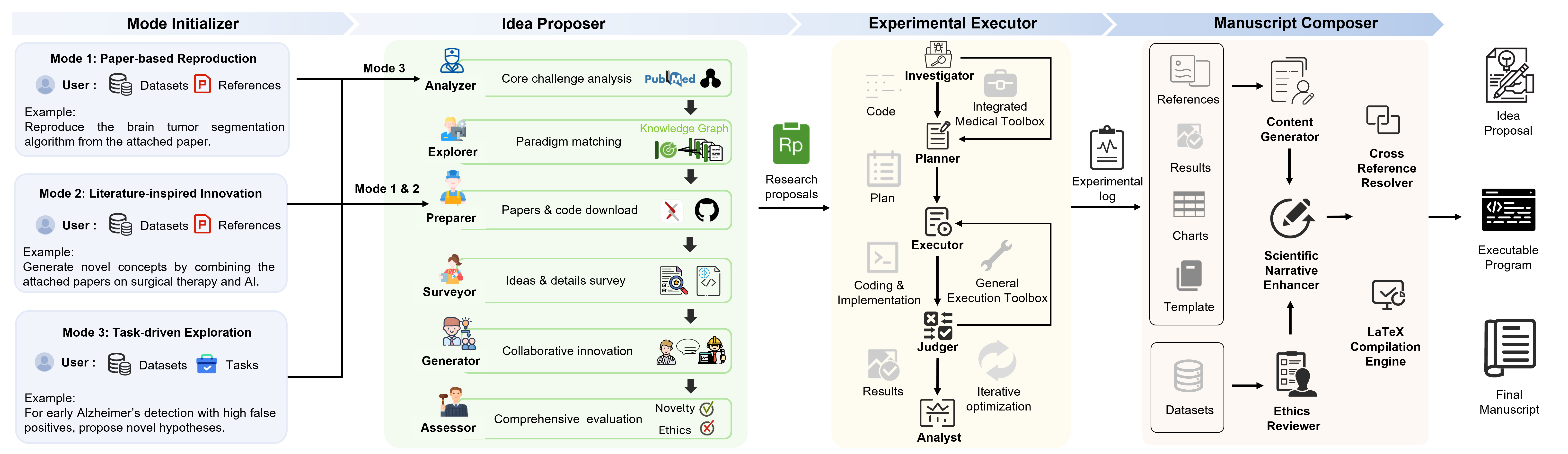
图2:详细架构图,展示了 Idea Proposer 各子模块(Explorer/Surveyor/Generator/Assessor)在三种模式下的工作流程,以及 Experimental Executor 如何通过 Investigator→Planner→Executor→Judger 完成实验的迭代验证。
实验执行在 Docker 化沙箱中进行(保证安全隔离),内置了专用医学工具箱:
- MONAI / SimpleITK:医学图像处理(NIfTI加载、CT重采样、病理切片预处理)
- 迭代自修正循环:代码运行失败 → Judger 分析报错 → Executor 修复 → 重新运行,最多迭代 N 轮
- 通用执行工具链 + 医学专用工具箱并存,同一实验管道能处理 2D 图像分类、视频恢复、生存分析等 19 种任务
3. Manuscript Composer(手稿撰写者)
生成论文不只是把实验结果填进模板,还要满足医学期刊的特殊要求:
- Cross-Reference Resolver:确保方法、结果、讨论之间的引用一致
- Scientific Narrative Enhancer:增强科学叙事逻辑,避免单纯罗列数据
- Ethics Reviewer:自动生成伦理声明,标注数据集来源和使用许可
- LaTeX 自动编译 + 自修复:编译失败自动修复语法错误
🔧 三种工作模式
模式一:论文复现
输入:任务指令 + 数据集 + 目标论文
行为:忠实复现方法,验证可复现性
模式二:文献启发创新
输入:任务指令 + 数据集 + 参考文献列表
行为:识别研究空白 → 提出改进假设 → 实现并验证
模式三:任务驱动探索(自治程度最高)
输入:任务指令 + 数据集
行为:自主挖掘文献 → 选择范式 → 提出假设 → 实验 → 成稿
三种模式覆盖了从"验证已有工作"到"从零开始研究"的不同自主程度需求。
📊 实验结果
评估基准:Med-AI Bench
作者构建了 Med-AI Bench,包含: - 171 个高质量评估案例 - 19 种临床任务(分类、分割、检测、恢复……) - 6 种数据模态(医学图像、视频、文本、生理信号、电子病历、多模态)
创意生成质量
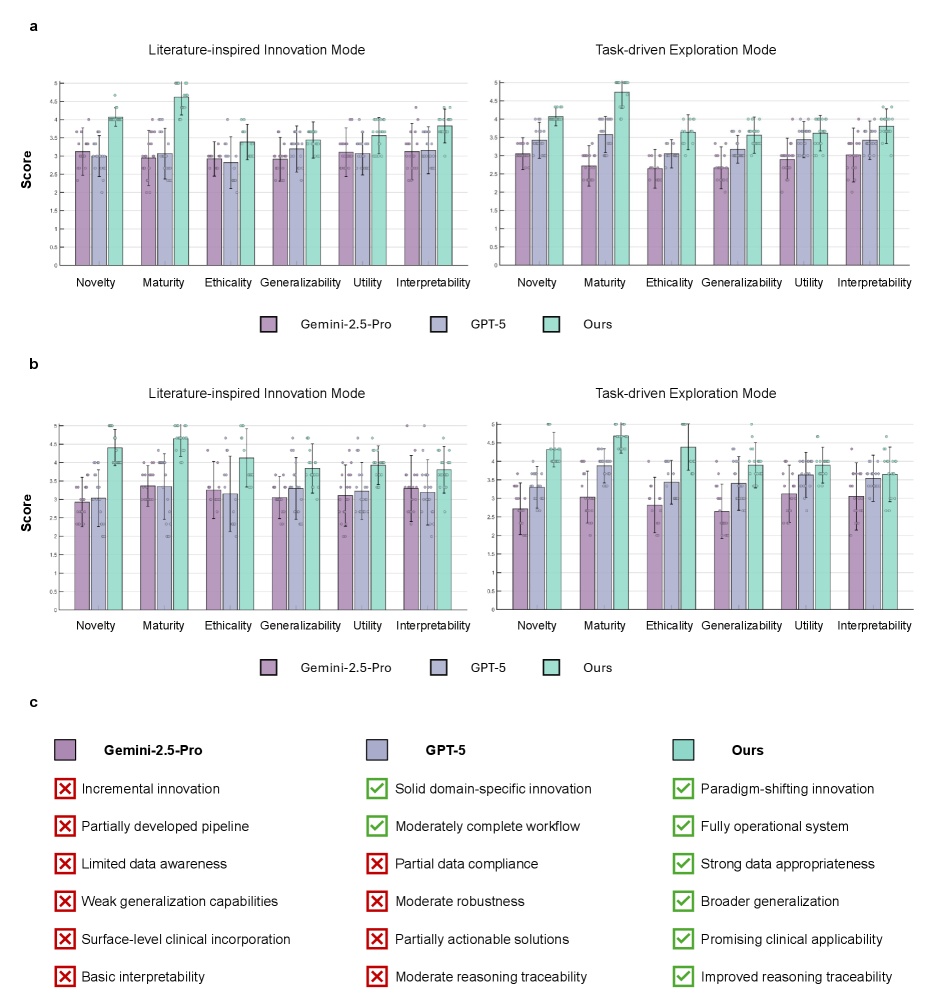
图3:Medical AI Scientist(绿色)在新颖性、成熟度、伦理性、可泛化性、实用性、可解释性六个维度上,在文献创新模式和任务探索模式下均明显优于 Gemini-2.5-Pro(紫色)和 GPT-5(蓝色)。定性评估(c)显示,GPT-5 能做到"领域内扎实创新",但只有 Medical AI Scientist 达到"范式转变级别创新"并全面绿检。
实验执行成功率
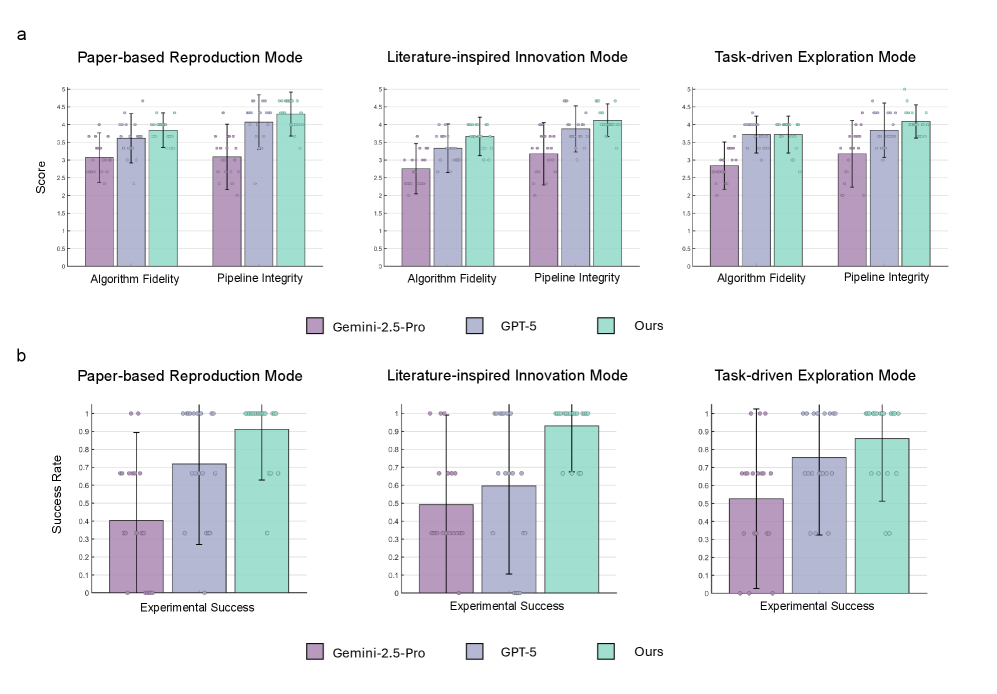
图4:Medical AI Scientist 在三种模式下的代码执行成功率分别为 0.91(复现)、0.93(文献创新)、0.86(任务探索),均大幅高于 GPT-5 和 Gemini-2.5-Pro。算法保真度和管道完整性得分同样领先。
关键数字汇总:
| 模式 | Medical AI Scientist | GPT-5 | Gemini-2.5-Pro |
|---|---|---|---|
| 论文复现成功率 | 0.91 | ~0.70 | ~0.40 |
| 文献创新成功率 | 0.93 | ~0.60 | ~0.50 |
| 任务探索成功率 | 0.86 | ~0.80 | ~0.55 |
生成论文质量
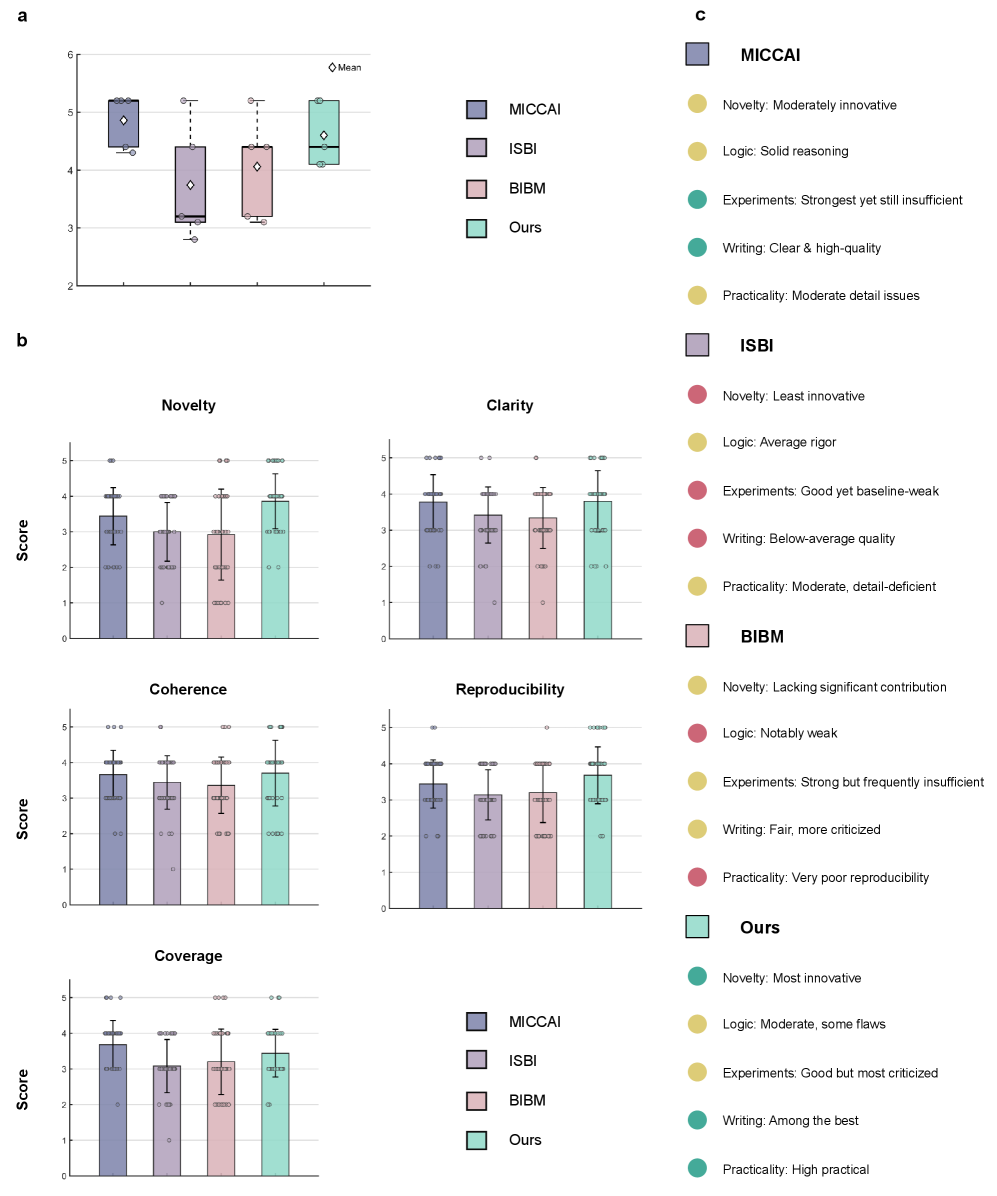
图5:双盲评估(10位医学专家 + Stanford Agentic Reviewer)结果。生成论文在整体评分上接近 MICCAI 水平,明显优于 ISBI 和 BIBM;在新颖性和写作维度上最强,但在实验严谨性上仍是被批评最多的维度(这也是所有自动化系统的共同短板)。
🔬 案例解析:系统实际产出是什么水平?
案例一:糖尿病视网膜病变分级(文献创新模式)
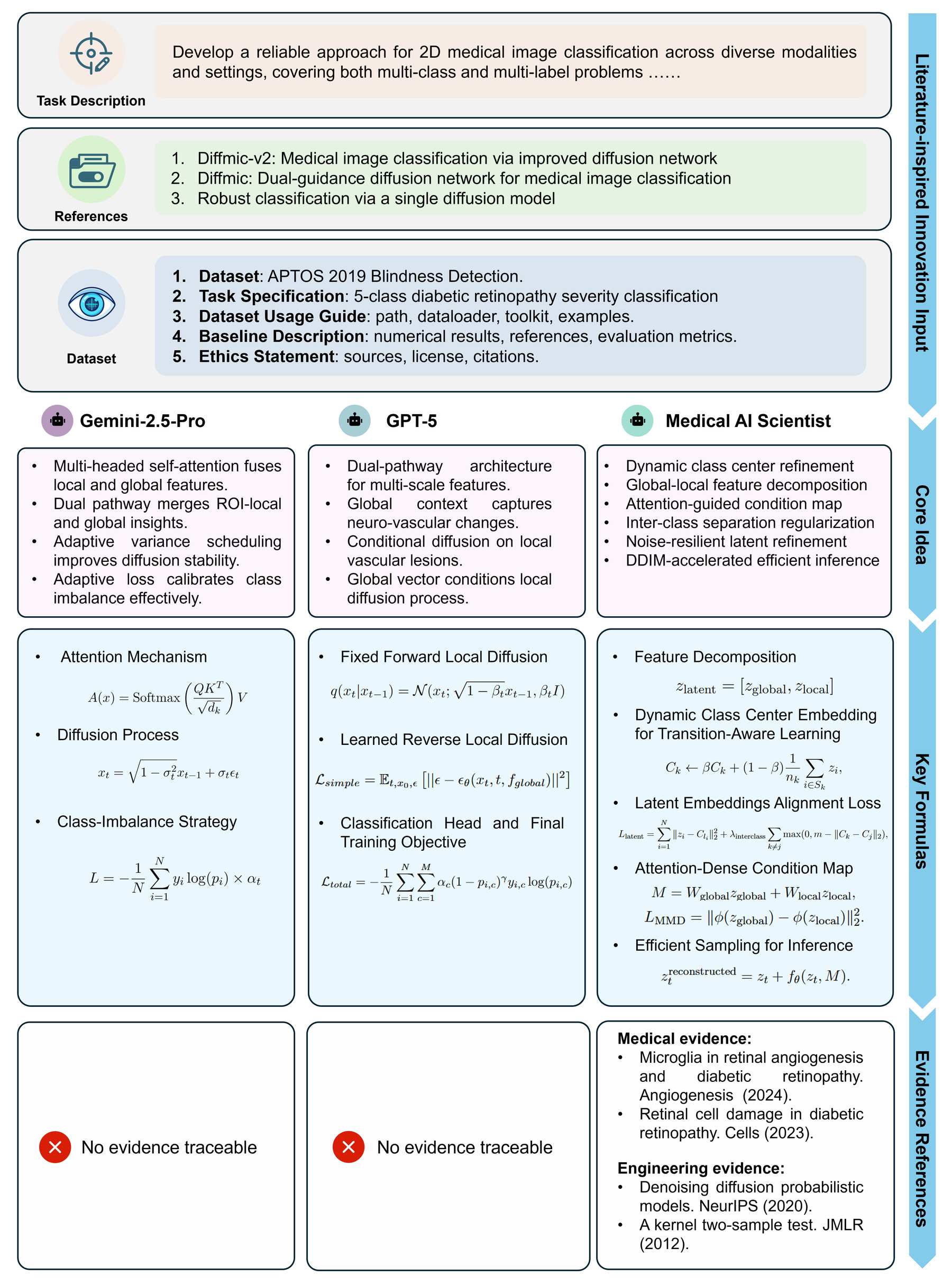
图6:以糖尿病视网膜病变分级为例的完整工作流程。系统识别出数据集(APTOS 2019)的核心挑战(多类别不平衡、局部血管病变与弥漫性神经退行性变的区分),利用医学先验提出双路径扩散架构("Neuro"路径+血管路径),生成含有完整公式推导和实验代码的研究方案,最终由人类评审员评为"强、有充分执行依据"。
系统的核心做法: 1. 医学先验到工程方案:DR 有两类损伤模式(局部血管病理 + 弥漫性神经退行性变)→ 双路径架构,分别处理两种特征 2. 证据可追溯:方案中的每个设计决策都对应具体文献引用(共 5 篇文献) 3. GPT-5 怎么做:只提出通用双路径 + Focal Loss,没有用医学先验驱动架构设计
案例二:内窥镜视频恢复(任务探索模式)

图7:从"恢复低分辨率临床内窥镜视频帧"这一简短描述出发,系统自主识别了 Hamiltonian 流场建模范式,提出用时序运动约束(temporal motion constraint)增强视频恢复的一致性,生成了包含完整架构图、数学推导、消融实验的论文草稿,人类评审员评为"技术上深刻、实践上有意义"。
⚠️ 局限性与值得商榷的地方
这篇论文的亮点是真实的,但有几个值得冷静看待的地方:
1. "接近 MICCAI 水平"的评估方式存在争议
用 Stanford Agentic Reviewer 做评估,而这个 Reviewer 本身也是 LLM,相当于 LLM 给 LLM 打分。虽然有 10 位人类专家的双盲评估作为补充,但人类专家样本量有限(每篇论文平均几位评审),统计置信度需要更多实验验证。
2. 实验执行成功率的定义
论文中的"执行成功率"指代码能运行完并产出结果,不等于实验设计合理、结果有意义。Fig. 4 的图示显示,即使"成功"的运行中,部分结果的实验设计仍被评审指出问题。
3. 数据集和任务难度的代表性
Med-AI Bench 的 171 个案例主要来自 MICCAI/ISBI 等会议的公开数据集,都是"有标准答案"的任务。对于没有公开代码基准的前沿临床问题(如稀有病种、多中心回顾性研究),系统能否胜任尚未验证。
4. 和同期工作的对比不够充分
论文只对比了 GPT-5 和 Gemini-2.5-Pro 作为 baseline,没有对比 The AI Scientist(Lu et al.)、ResearchAgent 等专门的自主科研系统,使得"首个医学 AI Scientist"的对比基线略显单薄。
💡 工程落地视角
对于想借鉴这套框架的开发者,最有价值的几个设计:
医学工具链抽象:把 MONAI/SimpleITK 封装成 Agent 可调用的工具,解决了通用 LLM 不会处理医疗数据格式的问题。这个思路可以推广到其他专业领域(金融数据处理、物理仿真工具链等)。
双层证据库(医学证据 + 工程证据分开存储):在知识密集型任务中,把不同来源的知识显式区分并分开存储,比混合进 prompt 更利于追溯和检验,可以大幅减少幻觉。
反思-修正循环(Judger 机制):实验执行失败不直接报错返回,而是由 Judger 分析失败原因后反馈给 Executor 修复,这是让执行成功率从 50% 提升到 90%+ 的关键设计。
📌 总结
| 维度 | 表现 |
|---|---|
| 核心创新 | 临床医生-工程师协同推理,医学先验驱动工程设计 |
| 评估规模 | 171 案例、19 任务、6 模态,是目前最系统的医学 AI 科研基准 |
| 创意质量 | 全面优于 GPT-5 和 Gemini-2.5-Pro |
| 执行成功率 | 0.86~0.93,远超 baseline |
| 论文质量 | 接近 MICCAI 水平,优于 ISBI/BIBM |
| 主要局限 | 评估方式存争议;不适用于无公开数据集的前沿问题;缺乏与专用 AI Scientist 系统的对比 |
这篇工作更像一个"垂直领域 AI Scientist"的系统工程范本,而非算法突破——它的价值在于把医学领域知识、工具链、伦理合规整合进一套可用的多 Agent 流水线,并给出了相当扎实的评估体系。后续能否真正进入临床研究流程,取决于它能否处理好"有新数据"和"没有公开基准"的开放式研究场景。
参考文献
- Hongtao Wu, Boyun Zheng, Dingjie Song, Yu Jiang, Jianfeng Gao, Lei Xing, Lichao Sun, Yixuan Yuan. "Towards a Medical AI Scientist." arXiv:2603.28589, 2026.
- Chris Lu et al. "The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery." arXiv:2408.06292, 2024.
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注公众号:机器懂语言