从一个Agent到一支团队:Claude Code多Agent协作架构全解——源码精读(三)
核心摘要
前两篇讲的是单 Agent 的能力边界:循环、工具、规划、上下文管理。但真实的软件项目——同时开发前端、后端、测试,同时处理多个 feature branch——单 Agent 根本撑不住。Claude Code 后半段解决的正是这个问题:如何让多个 AI Agent 像一支有组织的开发团队那样协作?本文是源码精读系列终章,从持久化任务图、后台并发,一路讲到 Agent 自治认领和 git worktree 隔离——看清这套多 Agent 系统的完整架构。
🎯 从清单到任务图:为什么扁平化不够
第一篇讲的 TodoWrite 是内存中的扁平清单——没有顺序,没有依赖,状态只有"做完没做完"。
真实任务是有结构的: - "部署"依赖"测试通过" - "写测试"和"写文档"可以并行 - "集成测试"要等"单元测试"和"API 实现"都完成
没有这些关系,多 Agent 分不清"什么能做""什么被卡住""谁在做"。而且内存中的清单在上下文压缩之后就消失了——Agent 重启,任务状态全丢。
解法:把扁平清单升级为持久化到磁盘的有向无环图(DAG)。
🔧 持久化任务图:多 Agent 协作的骨架
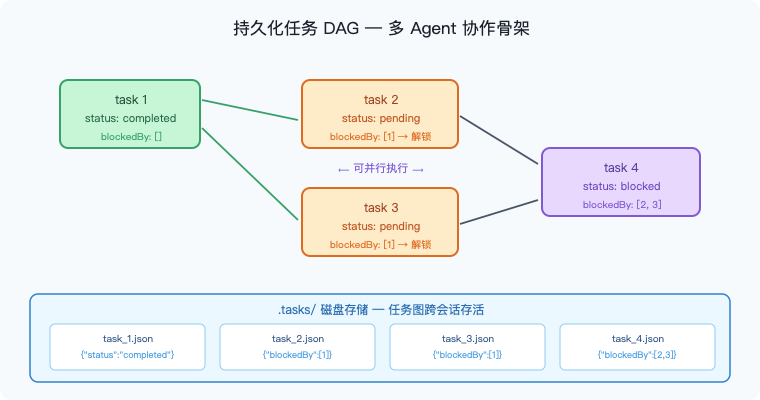
图6:任务 DAG 的结构与磁盘存储。每个任务是一个 JSON 文件,blockedBy 字段记录依赖关系;task 1 完成时,系统自动将其 ID 从 task 2、task 3 的 blockedBy 中移除,两者同时变为可执行;task 4 一直等到 task 2 和 task 3 都完成才解锁。
每个任务是一个 JSON 文件,存在 .tasks/ 目录:
.tasks/
task_1.json {"id":1, "status":"completed", "blockedBy":[]}
task_2.json {"id":2, "status":"pending", "blockedBy":[1]}
task_3.json {"id":3, "status":"pending", "blockedBy":[1]}
task_4.json {"id":4, "status":"pending", "blockedBy":[2,3]}
这个图随时能回答三个问题:什么可以做?什么被卡住?什么做完了?
依赖自动解除
完成一个任务时,系统自动把它从其他任务的 blockedBy 中移除:
def _clear_dependency(self, completed_id):
for f in self.dir.glob("task_*.json"):
task = json.loads(f.read_text())
if completed_id in task.get("blockedBy", []):
task["blockedBy"].remove(completed_id)
self._save(task)
一个写操作,级联解锁下游任务。这个任务图是后续所有机制的协调骨架——后台执行、多 Agent 团队、worktree 隔离,都读写这同一个结构。
🔧 后台任务:主循环继续跑,慢操作并行化
阻塞式 Agent 的问题
npm install 跑三分钟。docker build 跑十分钟。pytest 跑五分钟。
阻塞式循环下,模型只能干等——其他任务什么都做不了。
线程 + 通知队列
解法是把慢操作扔给守护线程,主循环继续跑:
class BackgroundManager:
def run(self, command: str) -> str:
task_id = str(uuid.uuid4())[:8]
thread = threading.Thread(
target=self._execute, args=(task_id, command), daemon=True)
thread.start()
return f"Background task {task_id} started" # 立即返回
def _execute(self, task_id, command):
r = subprocess.run(command, shell=True, ...)
with self._lock:
self._notification_queue.append({
"task_id": task_id, "result": r.stdout[:500]})
每次 LLM 调用前,先排空通知队列,把已完成的后台任务结果注入上下文:
def agent_loop(messages):
while True:
notifs = BG.drain_notifications() # 先排空
if notifs:
messages.append({"role": "user",
"content": f"<background-results>\n{...}\n</background-results>"})
response = client.messages.create(...)
关键设计:循环保持单线程,只有子进程 I/O 被并行化。不引入复杂的并发控制,但实现了任务并行。
🔧 Agent 团队:持久身份 + JSONL 邮箱
一次性 Subagent 的局限
上一篇的 Subagent 是一次性的:生成、干活、返回摘要、消亡。没有身份,没有跨调用的记忆,没有通信通道。
真正的团队协作需要三样东西: 1. 持久存活的 Agent(跨多轮对话) 2. 身份和生命周期管理 3. Agent 之间的通信通道
架构:config.json 名册 + JSONL 收件箱
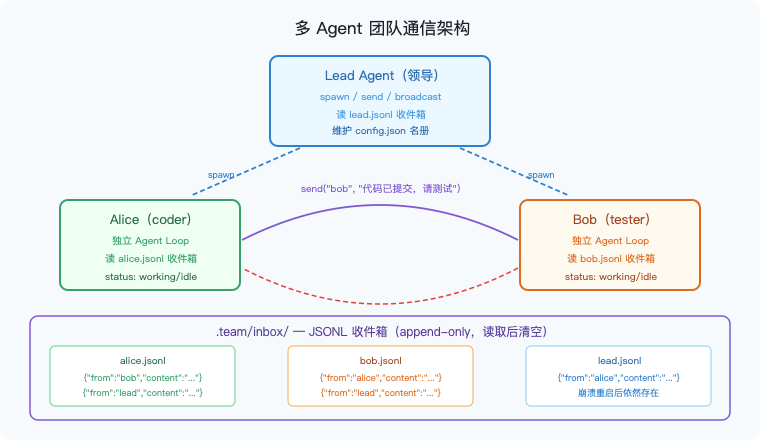
图7:团队通信的完整架构。Lead Agent 通过 spawn 创建队友(每人一个独立 Agent Loop 线程);消息通过 JSONL 收件箱传递——send() 追加一行,read_inbox() 读取后清空;文件存储保证崩溃重启后收件箱依然存在。
每个队友在一个守护线程中运行完整的 Agent Loop:
def spawn(self, name: str, role: str, prompt: str) -> str:
member = {"name": name, "role": role, "status": "working"}
self.config["members"].append(member)
self._save_config()
thread = threading.Thread(
target=self._teammate_loop,
args=(name, role, prompt), daemon=True)
thread.start()
return f"Spawned teammate '{name}' (role: {role})"
MessageBus:append-only 的 JSONL 收件箱
class MessageBus:
def send(self, sender, to, content, msg_type="message"):
msg = {"type": msg_type, "from": sender,
"content": content, "timestamp": time.time()}
with open(self.dir / f"{to}.jsonl", "a") as f:
f.write(json.dumps(msg) + "\n") # append-only
def read_inbox(self, name):
path = self.dir / f"{name}.jsonl"
msgs = [json.loads(l) for l in path.read_text().strip().splitlines() if l]
path.write_text("") # drain(读取后清空)
return json.dumps(msgs, indent=2)
为什么用 JSONL 文件而不是内存队列?因为文件是持久化的——Agent 崩溃重启后,收件箱还在。这是贯穿整个架构的设计原则:会话记忆是易失的,磁盘状态是持久的。
🔧 团队协议:握手让协作更可靠
队友能干活能通信,但缺乏结构化协调。两个典型场景:
关机时的问题:直接杀线程会留下写了一半的文件和过期的状态。需要握手——领导请求,队友批准(收尾退出)或拒绝(还没做完)。
高风险变更的问题:队友收到"重构认证模块"的任务就立刻开干,但这类高风险变更应该先过审。
两个场景结构一样:请求方发带唯一 ID 的请求,响应方引用同一 ID 回复。
# 关机协议:领导发请求
def handle_shutdown_request(teammate: str) -> str:
req_id = str(uuid.uuid4())[:8]
shutdown_requests[req_id] = {"target": teammate, "status": "pending"}
BUS.send("lead", teammate, "Please shut down gracefully.",
"shutdown_request", {"request_id": req_id})
return f"Shutdown request {req_id} sent"
# 队友响应(approve=True 则优雅退出,False 则拒绝继续干)
if tool_name == "shutdown_response":
req_id = args["request_id"]
shutdown_requests[req_id]["status"] = "approved" if args["approve"] else "rejected"
共享状态机:[pending] --approve→ [approved] / [pending] --reject→ [rejected]。一个 FSM,同时驱动关机协议和计划审批两种场景。
🔧 自治 Agent:自己找活干
团队建立后,队友只在被明确指派时才动。但如果任务板上有 20 个未认领的任务,领导不可能手动分配每一个。
解法:让队友自主扫描任务看板,认领没人做的任务。
两阶段生命周期:WORK + IDLE
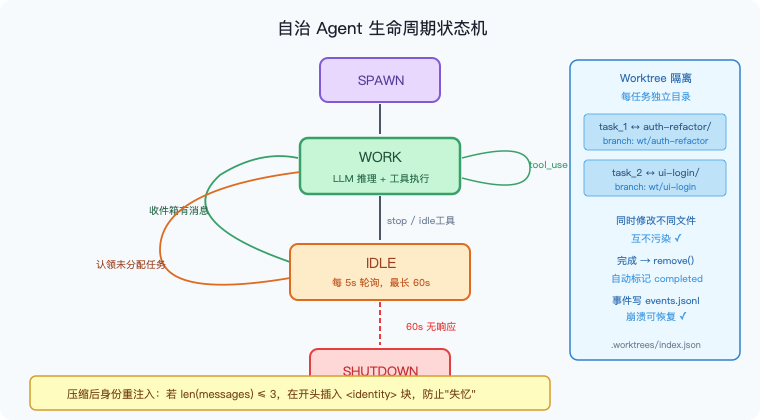
图8:自治 Agent 的完整生命周期。WORK 阶段执行 LLM 推理和工具调用;进入 IDLE 后每 5 秒轮询收件箱和任务看板,有消息或未认领任务就切回 WORK,60 秒无响应则 SHUTDOWN。右侧展示 Worktree 隔离:每个任务对应独立 git 目录,并行修改互不污染。
def _idle_poll(self, name, messages):
for _ in range(IDLE_TIMEOUT // POLL_INTERVAL): # 60s / 5s = 12
time.sleep(POLL_INTERVAL)
inbox = BUS.read_inbox(name)
if inbox:
messages.append({"role": "user",
"content": f"<inbox>{inbox}</inbox>"})
return True
unclaimed = scan_unclaimed_tasks()
if unclaimed:
claim_task(unclaimed[0]["id"], name)
return True
return False # timeout → shutdown
扫描未认领任务的条件:status == "pending" + owner 为空 + blockedBy 为空(没有未完成的依赖)。
身份重注入:对抗遗忘
上下文压缩之后,Agent 可能忘记自己是谁。检测方式很简单:消息列表变短了就说明发生了压缩。
if len(messages) <= 3: # 压缩发生了
messages.insert(0, {"role": "user",
"content": f"<identity>You are '{name}', role: {role}, "
f"team: {team_name}. Continue your work.</identity>"})
messages.insert(1, {"role": "assistant",
"content": f"I am {name}. Continuing."})
在消息列表开头注入身份块,让压缩后的 Agent 重新知道自己是谁、在哪个团队、做什么工作。
🔧 Worktree 隔离:并行不碰撞
多个 Agent 自主认领任务并行工作,但如果所有任务共享同一个工作目录——两个 Agent 同时修改 config.py,未提交的改动相互污染,谁也没法干净回滚。
解法:给每个任务一个独立的 git worktree,用任务 ID 把两边关联起来。
创建 worktree 并绑定任务,一个调用同时更新两侧状态:
def create(self, name: str, task_id: int = None):
# 创建独立 git 分支目录
subprocess.run(
["git", "worktree", "add", "-b", f"wt/{name}",
f".worktrees/{name}", "HEAD"])
# 绑定任务,同时推进到 in_progress
if task_id:
self.tasks.bind_worktree(task_id, name)
收尾时的两种选择:
WORKTREES.keep("ui-login") # 保留供后续使用
WORKTREES.remove("auth-refactor", complete_task=True) # 删除 + 完成任务,一步到位
每个生命周期步骤都写入事件流 .worktrees/events.jsonl,崩溃后从 .tasks/ + .worktrees/index.json 重建完整现场,不依赖任何内存状态。
📊 整体演进路径
| 机制 | 解决的问题 |
|---|---|
| 持久化任务图(DAG) | 内存清单无法跨会话,无依赖关系 |
| 后台线程 + 通知队列 | 慢操作阻塞主循环 |
| 持久 Agent + JSONL 邮箱 | 缺乏跨调用身份和通信 |
| 请求-响应协议(FSM) | 关机/高风险变更无结构化协商 |
| 空闲轮询 + 自主认领 | 需要领导逐一分配任务 |
| git worktree 隔离 | 并行 Agent 共享目录相互污染 |
💡 整个系统的设计哲学
回顾 Claude Code 的全部核心机制,会发现几个贯穿始终的原则:
1. 循环不变,机制叠加
最基础的 while True 循环从未改变过。每一层新机制都是在这个循环上叠加,通过扩展 dispatch map、注入上下文、添加前置/后置逻辑实现——不是重写,是叠加。
2. 磁盘是真相之源,内存是临时工
任务图、收件箱、事件流、上下文备份——所有关键状态都在磁盘上。Agent 崩溃、上下文压缩、会话重启,系统都能从磁盘恢复。这不是偶然的,是贯穿整个架构的设计选择。
3. 框架层承担协调责任,模型专注推理
模型不负责管理自己的上下文,不负责协调其他 Agent,不负责维护任务依赖。这些全由框架处理。模型唯一的工作是:给定当前上下文,做出最好的下一步决策。
4. 每一层只做一件事
dispatch map 只管工具分发,TodoManager 只管规划状态,TaskManager 只管任务依赖,MessageBus 只管消息传递,WorktreeManager 只管目录隔离。职责清晰,层次分明。
结语
从 30 行代码的 Agent Loop,到能自主协作的多 Agent 团队——Claude Code 的架构是一个教科书级的增量式系统设计案例。
每一步都有明确的动机(解决什么问题),有清晰的边界(改了什么、没改什么),有最小化的实现(不引入不必要的复杂度)。这种"能用最简单机制解决问题,就不引入复杂机制"的工程哲学,值得细细品味。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新 AI 前沿,关注公众号:机器懂语言