当知识图谱变成"黑箱":BubbleRAG 用气泡膨胀算法让 Graph RAG 的召回率和精准率同时起飞
论文标题:BubbleRAG: Evidence-Driven Retrieval-Augmented Generation for Black-Box Knowledge Graphs
作者:Duyi Pan, Tianao Lou, Xin Li, Haoze Song, Yiwen Wu, Mengyi Deng, Mingyu Yang, Wei Wang
机构:香港科技大学(广州)、香港科技大学
论文链接:https://arxiv.org/abs/2603.20309
发布日期:2026 年 3 月
Graph RAG 近一年异常火热——GraphRAG、LightRAG、HippoRAG2 等方案层出不穷。但它们都有个隐含假设:你多少知道知识图谱长什么样(有哪些实体类型、关系类型)。现实中,LLM 从文档里抽取出来的知识图谱根本没有统一 schema,检索器面对的是一个彻底的黑箱。港科大团队将这个检索问题形式化为 OISR(最优信息子图检索),证明它是 NP-hard 且无法常数因子近似,然后提出 BubbleRAG:用"气泡膨胀"启发式搜索同时优化召回和精准。在三个多跳 QA 基准上,BubbleRAG 平均 F1 达到 63.02%,超越 HippoRAG2 的 60.50%,且无需任何训练。
🎯 问题:Graph RAG 的三重不确定性
当你用 LLM 从一堆文档里抽取三元组构建知识图谱,再用这个图谱辅助问答时,检索环节会遇到三个核心难题:
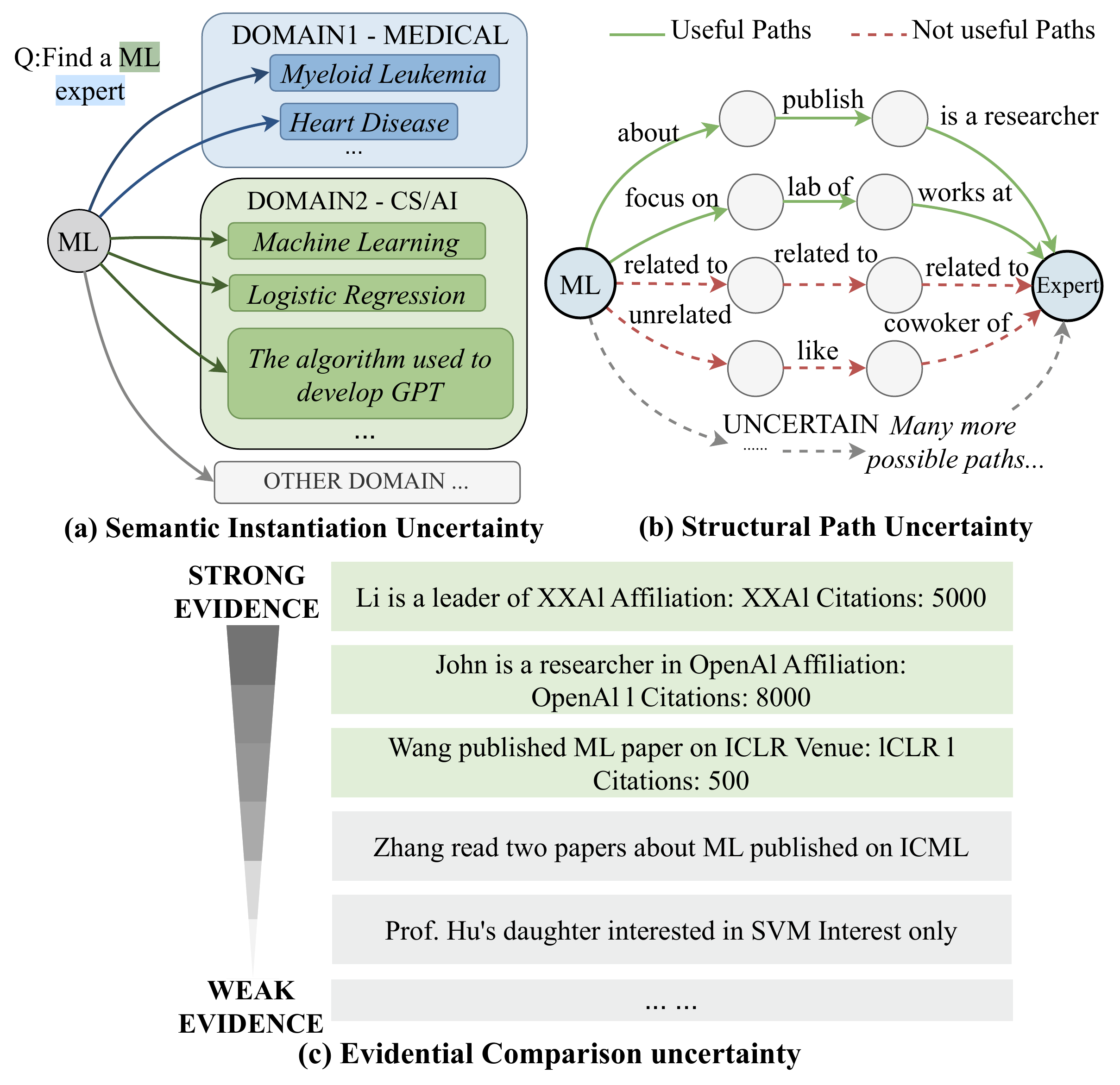 图1:黑箱知识图谱检索的三大挑战。(a) 语义实例化不确定性——"ML"可能映射到医学的"骨髓性白血病"或 AI 的"机器学习";(b) 结构路径不确定性——从 ML 到 Expert 之间存在大量可能路径,有用路径(绿实线)和无用路径(红虚线)交织;(c) 证据对比不确定性——检索到的多条证据强弱不同,如何排序?
图1:黑箱知识图谱检索的三大挑战。(a) 语义实例化不确定性——"ML"可能映射到医学的"骨髓性白血病"或 AI 的"机器学习";(b) 结构路径不确定性——从 ML 到 Expert 之间存在大量可能路径,有用路径(绿实线)和无用路径(红虚线)交织;(c) 证据对比不确定性——检索到的多条证据强弱不同,如何排序?
挑战一:语义实例化不确定性(损害召回率)
查询中的"ML"在知识图谱里可能对应"骨髓性白血病"也可能对应"机器学习"——在没有 schema 的黑箱图谱中,这种歧义无处不在。HippoRAG2 等方法从单个种子节点出发做 PageRank,一旦种子选错,整个检索链条就偏了。
挑战二:结构路径不确定性(损害召回率)
即使正确定位了"ML"节点,从 ML 到目标答案(比如某位专家)之间可能存在成百上千条路径。哪些路径承载了有用信息?迭代多跳方法(如 ToG)在每一步都要做选择,任何一步的错误都会级联放大。
挑战三:证据对比不确定性(损害精准率)
检索到的子图片段各有一些证据,但强弱差异很大。"Li 是 XXAI 的领导者,引用 5000"和"张 读过两篇 ML 论文"都跟查询相关,但信息密度天差地别。缺乏有效的排序机制,就会把低质量证据混进最终上下文。
已有方法通常只解决其中一两个问题。BubbleRAG 的关键突破在于:将问题形式化后,同时从召回和精准两个方向系统优化。
🏗️ 方法:从形式化到气泡膨胀
OISR:给直觉找到数学根基
BubbleRAG 将黑箱图谱检索形式化为 OISR(Optimal Informative Subgraph Retrieval)问题:
给定知识图谱 \(G = (V, E)\)、节点/边的价值函数 \(\text{val}(\cdot)\)、以及一组语义锚点集合 \(S = \{S_1, S_2, \ldots, S_k\}\)(每个 \(S_i\) 对应查询中一个关键概念的候选节点),找到一个连通子图 \(G'\) 使得: - 覆盖所有锚点组(每组至少包含一个节点) - 最大化子图内节点和边的平均价值
这个问题是 Group Steiner Tree 的变体,论文证明它是 NP-hard 且 APX-hard(不存在常数因子近似算法)。换句话说:不可能有完美解,只能靠启发式做到尽可能好。
BubbleRAG 五步流水线
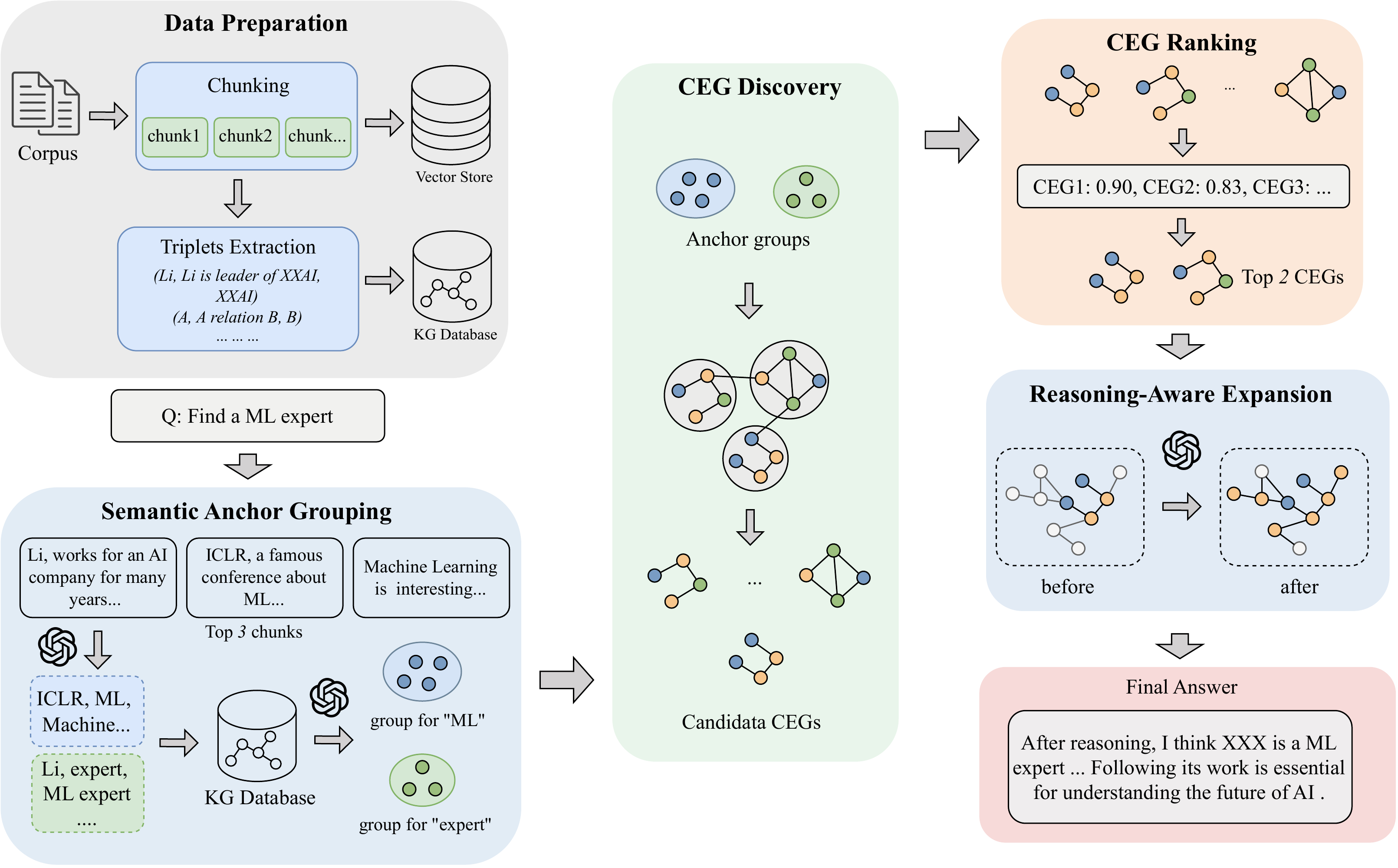 图2:BubbleRAG 流水线。数据准备(Chunking→三元组抽取→KG)→ 语义锚点分组 → 候选证据图发现(气泡膨胀)→ CEG 排序 → 推理感知扩展 → 最终答案。
图2:BubbleRAG 流水线。数据准备(Chunking→三元组抽取→KG)→ 语义锚点分组 → 候选证据图发现(气泡膨胀)→ CEG 排序 → 推理感知扩展 → 最终答案。
Step 1:数据准备——从文档中抽取三元组构建知识图谱,关键区别是 BubbleRAG 在边上存储了完整的三元组文本(不只是关系名),为后续语义匹配提供更丰富的信号。
Step 2:语义锚点分组——这是 BubbleRAG 最核心的预处理步骤:
- LLM 从查询中抽取显式和隐式关键词
- 对模糊关键词做锚点特化——把"mother"这种全局匹配上千节点的泛化词改写为"Lothair II's mother"
- Schema 松弛——如果某个概念在图谱中找不到精确匹配,用文本块作为本地社区的"预览窗口"来放松约束
- LLM 将候选锚点聚类并加权——核心主体实体权重高,修饰性概念权重低
Step 3:候选证据图发现(气泡膨胀)
这是算法的精华所在。从每个锚点组发起多源 Dijkstra 搜索,代价函数为 \(\text{cost}(v) = 1 - \cos(z_q, z_v)\)——与查询越相关的节点,穿越代价越低。
搜索过程形如一组"气泡"从各个锚点组向外膨胀: - 各向异性:气泡沿着与查询语义相关的方向优先扩展 - 碰撞检测:当来自不同锚点组的气泡在某个节点"碰撞"(bitmask 显示多组覆盖),该节点成为 Steiner 连接点 - 路径回溯:从碰撞点回溯到各组的源锚点,融合成一个连通的候选证据图(CEG)
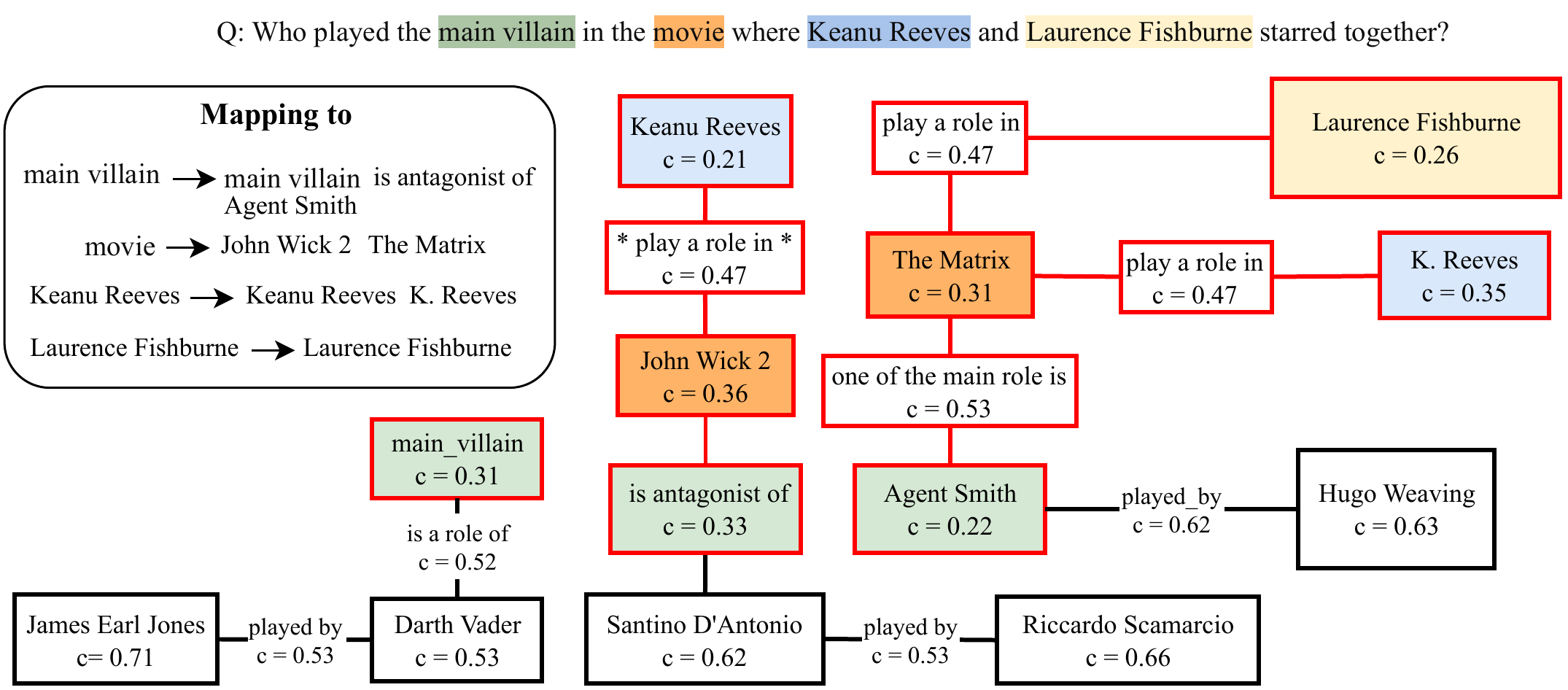 图3:气泡膨胀实例。查询"谁演了 Keanu Reeves 和 Laurence Fishburne 合演电影中的主要反派?"——不同颜色对应不同语义锚点组。红框标记的节点和边已被纳入 CEG。代价值(c)越低表示与查询越相关。最终正确定位到 Hugo Weaving → Agent Smith → The Matrix 这条证据链。
图3:气泡膨胀实例。查询"谁演了 Keanu Reeves 和 Laurence Fishburne 合演电影中的主要反派?"——不同颜色对应不同语义锚点组。红框标记的节点和边已被纳入 CEG。代价值(c)越低表示与查询越相关。最终正确定位到 Hugo Weaving → Agent Smith → The Matrix 这条证据链。
Step 4:CEG 排序——复合打分,平衡语义相关性和结构完整性:
其中语义代价 \(\text{Cost}_{\text{sem}}\) 用平均值而非总和(保证大小无关),结构惩罚 \(\text{Penalty}_{\text{miss}}(T) = e^{\alpha \cdot r_{\text{miss}}}\) 中的 \(\alpha\) 控制对缺失概念组的惩罚力度。\(\alpha\) 大则逼近 AND 语义,\(\alpha\) 小则逼近 OR 语义。
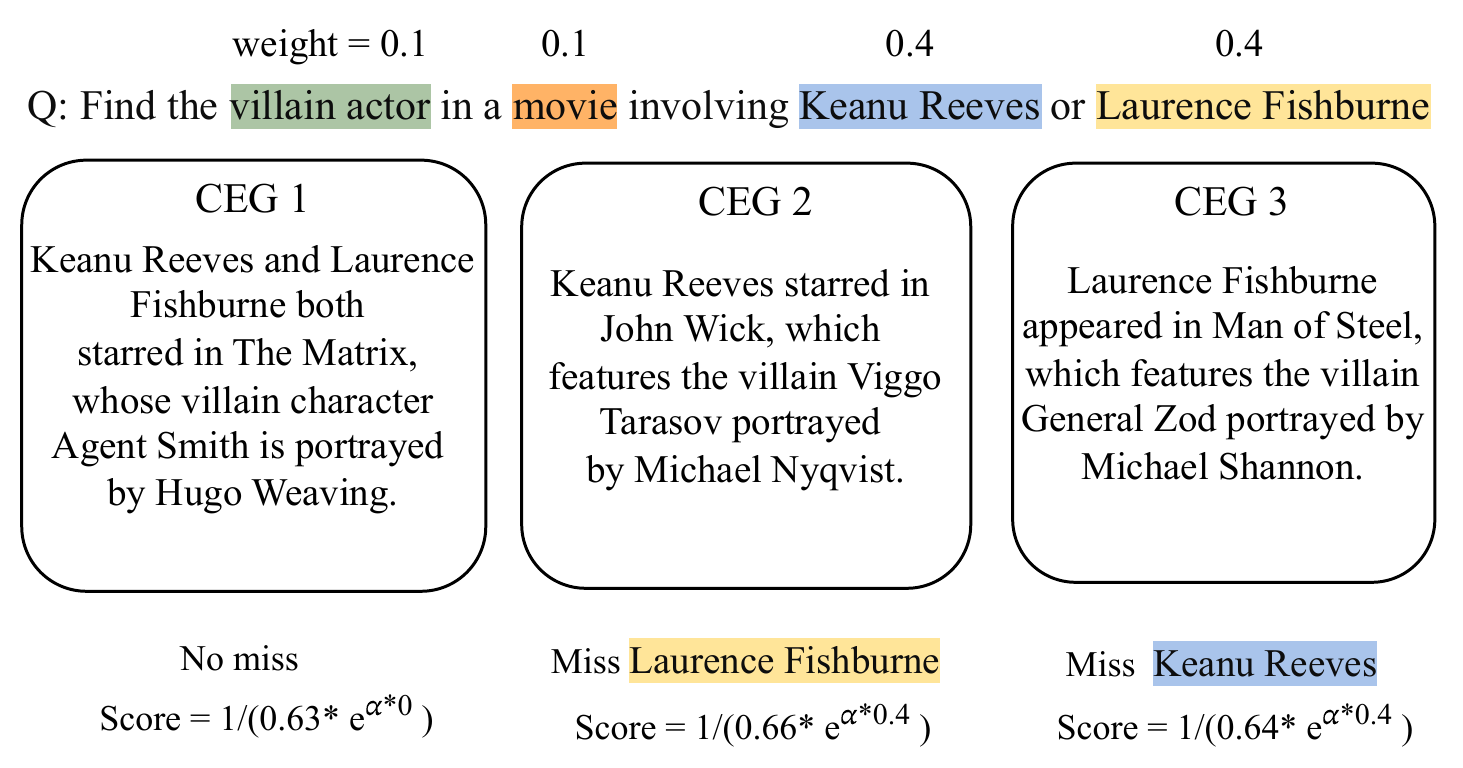 图4:CEG 排序示例。三个候选证据图——CEG1 覆盖所有锚点组(Score 最高),CEG2 缺失 Laurence Fishburne,CEG3 缺失 Keanu Reeves。通过调整 α 可以灵活支持 AND/OR/比较类查询。
图4:CEG 排序示例。三个候选证据图——CEG1 覆盖所有锚点组(Score 最高),CEG2 缺失 Laurence Fishburne,CEG3 缺失 Keanu Reeves。通过调整 α 可以灵活支持 AND/OR/比较类查询。
Step 5:推理感知扩展——答案实体可能不在 CEG 内部,而在其邻域。LLM 引导的多跳扩展从 top-n CEG 出发,逐步吸纳相关邻居节点,直到达到深度上限或 LLM 判断无需继续。
🧪 实验结果
主实验:三个多跳 QA 基准
对比 10 个方法,分别在 30B 和 8B 两种规模的 LLM 上测试(每个数据集 1000 题):
| 方法 | HotpotQA F1 | MuSiQue F1 | 2Wiki F1 | 平均 F1 | 平均 ACC |
|---|---|---|---|---|---|
| Vanilla LLM | 17.84 | 5.80 | 20.14 | 12.97 | 23.88 |
| NaiveRAG | 73.07 | 43.68 | 52.15 | 53.51 | 56.71 |
| ToG | 40.07 | 16.76 | 35.88 | 24.15 | 30.16 |
| LightRAG(hybrid) | 54.87 | 39.57 | 55.67 | 47.74 | 49.92 |
| HippoRAG2 | 71.72 | 45.04 | 67.65 | 60.50 | 64.40 |
| BubbleRAG | 74.35 | 53.03 | 72.54 | 63.02 | 66.63 |
上表为 30B 模型结果。8B 模型上 BubbleRAG 同样在 MuSiQue 和 2Wiki 上领先。
几个关键数据值得关注:
MuSiQue 上拉开最大差距:BubbleRAG 53.03% vs HippoRAG2 45.04%,领先近 8 个点。MuSiQue 需要 3-4 跳推理,正是"结构路径不确定性"最严重的场景——气泡膨胀的多源搜索在此发挥了最大优势。
2Wiki 上的压倒性优势:72.54% vs HippoRAG2 的 67.65%,领先约 5 个点。
NaiveRAG 意外能打:在 HotpotQA 上,NaiveRAG(73.07%)居然和 HippoRAG2(71.72%)打平。这暗示在某些 2 跳场景下,简单的向量检索可能比复杂的图遍历更稳健——Graph RAG 的价值主要体现在 3+ 跳的复杂推理上。
ToG 表现最差:迭代式多跳探索(40.07%)甚至不如 NaiveRAG,印证了论文指出的"单锚点级联失败"问题。
消融实验
| 变体 | 2Wiki F1 | HotpotQA F1 |
|---|---|---|
| BubbleRAG(完整) | 64.97 | 71.82 |
| 去掉锚点特化 | 60.45(↓4.52) | 69.28(↓2.54) |
| 去掉 Schema 松弛 | 53.62(↓11.35) | 66.65(↓5.17) |
| 去掉 CEG 排序 | 58.76(↓6.21) | 70.20(↓1.62) |
Schema 松弛贡献最大:在 2Wiki 上去掉后 F1 暴跌 11.35 个点。这说明黑箱图谱中概念-实体的匹配鸿沟极其严重,松弛机制是维持召回率的关键。
锚点特化和 CEG 排序分别对召回和精准做出贡献,三个组件各司其职。
效率分析
| 方法 | 延迟(s) | 查询 token | 索引 token |
|---|---|---|---|
| NaiveRAG | 0.67 | 249K | — |
| HippoRAG2 | 4.26 | 419K | 4,576K |
| ToG | 45.93 | 766K | — |
| BubbleRAG | 20.99 | 1,064K | 3,840K |
BubbleRAG 的 20.99 秒延迟是 HippoRAG2 的约 5 倍,主要开销在锚点分组和推理扩展两个 LLM 交互步骤。相比 ToG 的 45.93 秒倒是快了一半。对于离线知识库问答场景可以接受,但实时对话场景可能需要进一步优化。
🤔 批判性分析
亮点
-
问题形式化的严谨性:将黑箱图谱检索形式化为 OISR 并证明其 NP-hard,为启发式设计提供了理论依据——不是"凑巧能用",而是"在不可能最优的前提下做到尽可能好"。
-
气泡膨胀的工程优雅性:多源 Dijkstra + 碰撞检测 + 路径回溯,用经典算法思想解决新问题。代价函数直接用余弦相似度,简洁且有效。
-
即插即用:不需要训练检索器,不需要修改知识图谱结构,换个 LLM 就能跑。
局限与疑问
-
LLM 依赖偏重:锚点分组、特化、Schema 松弛、推理扩展四个步骤都需要 LLM 调用。查询阶段消耗了超过 100 万 token——这个成本在大规模部署中不可忽视。论文应该给出每步的 LLM 调用次数和 token 消耗的拆分。
-
"黑箱"假设是否过于极端? 实际场景中,LLM 抽取的知识图谱虽然没有严格 schema,但抽取 prompt 通常会约束关系类型。完全零 schema 信息的"纯黑箱"可能更多是理论假设而非工程现实。
-
8B 模型上的表现不一致:在 HotpotQA 8B 上,HippoRAG2(73.33%)反而超过了 BubbleRAG(71.82%)。论文对此没有深入分析。猜测是 8B 模型在锚点分组等需要推理的步骤上能力不足,导致上游误差放大。
-
与 NaiveRAG 的差距在简单场景下收窄:HotpotQA 是 2 跳场景,NaiveRAG(73.07%)和 BubbleRAG(74.35%)差距仅 1.28 个点。Graph RAG 的真正战场在 3+ 跳复杂推理,2 跳场景可能不值得引入这么重的框架。
-
参数敏感性:α=5.0 时 F1 从 60.52 降到 57.35,说明 AND/OR 语义的切换对性能影响不小,实际部署时需要根据查询类型动态调整。
📊 与主流 Graph RAG 方法的定位
| 方法 | 检索范式 | 是否需训练 | 初始化方式 | 核心局限 |
|---|---|---|---|---|
| HippoRAG2 | PPR 随机游走 | ❌ | 单/多种子节点 | 种子选错则全盘皆输 |
| LightRAG | 预构建社区索引 | ❌ | 全局/局部检索 | 静态结构无法适应动态查询 |
| ToG | 迭代式束搜索 | ❌ | 单种子 + 逐跳扩展 | 级联失败,效率极低 |
| GraphRAG | 社区摘要 + 层次索引 | ❌ | 全局社区 | 依赖离线预处理,灵活性差 |
| BubbleRAG | 多源气泡膨胀 | ❌ | 多组锚点并行 | LLM 调用成本高 |
BubbleRAG 的独特性在于:它是目前唯一从多组锚点同时出发做检索的方法,避免了单点初始化的级联失败,同时通过 CEG 排序实现了召回-精准的联合优化。
总结
BubbleRAG 给 Graph RAG 领域带来了两个关键启示:形式化问题比堆工程更重要(OISR 的提出让整个方法有了清晰的优化目标),检索的起点决定了上限(多组锚点初始化比单种子方案更鲁棒)。
在 3-4 跳的复杂推理场景中,BubbleRAG 以 63.02% 的平均 F1 确立了新的 SOTA。但 20 秒的延迟和百万级 token 的查询消耗也提醒我们:好的检索不等于高效的检索,如何在精度和效率之间找到最佳平衡点,是后续工作的核心方向。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言