Attention Residuals:让深层网络学会按需回看历史层,而不是把所有层一股脑叠上去
- 论文标题:Attention Residuals
- arXiv:
https://arxiv.org/abs/2603.15031 - 代码仓库:
https://github.com/MoonshotAI/Attention-Residuals - 作者:Kimi Team,Guangyu Chen,Yu Zhang,Jianlin Su
- 提交时间:2026 年 3 月
🎯 一句话看懂
这篇论文做的事,其实可以用一句很朴素的话概括:别再让每一层都被迫平等地背着全部历史往前走了,应该让当前层自己决定,究竟要更信最近几层,还是该回头找更早的表示。
传统 PreNorm 残差连接像一个只会“累加”的记账员:前面每层的输出,不管有用没用,都以权重 1 加进来。层数一深,隐藏状态幅值一路涨,后面新层的声音反而被稀释掉。Attention Residuals 的做法很直接——把“深度上的残差累加”改成“深度上的注意力选择”。
如果你愿意把 Transformer 的时间维注意力想成“当前 token 去翻前文”,那这篇论文的核心类比就是:当前层也该能翻前面的层。
📖 这篇论文到底在打什么靶子
现代大模型几乎都爱用 PreNorm。原因很现实:训练稳、扩展方便、工程上成熟。可 PreNorm 有个长期潜伏的问题,论文里把它说得很清楚:所有残差分支都按固定单位权重累加,会带来 hidden state 随深度失控增长,进而稀释单层贡献。
把这个过程想成开会就很好懂。一个会议室里,每个发言人说完都不关麦,后面的人还得继续叠在前面人的声音上。层数少时还凑合,层数一多,房间里的背景噪音会越来越大。后面那位想让别人听到自己,只能把嗓门越提越高。于是你会看到两件事一起发生:
- 输出幅值越往深层越大:因为新层得用更大的输出去盖过前面积累下来的“旧账”。
- 梯度分布失衡:早层会拿到异常重的梯度负担,整条深度路径不好调。
这也是论文里反复强调的 PreNorm dilution。我觉得这个问题以前不是没人意识到,而是大家更多把精力放在 token 维注意力、MoE、KV cache、长上下文这些更显眼的地方。残差连接因为太“基础设施化”,反而长期被默认成一个不值得再动的组件。
这篇论文最漂亮的地方就在这:它没有再去发明一个更复杂的 block,而是回过头去重做“层与层之间怎么连接”这件老问题。
🧠 从“时间注意力”类比到“深度注意力”
作者提出的核心直觉叫 Time-Depth Duality。RNN 在时间维上把所有历史压进一个状态里,Transformer 用注意力替代它,让当前位置能按需访问过去 token。那在网络深度上,残差连接不也在做类似的压缩吗?
传统残差是:
它等价于一种很粗暴的历史聚合:前面所有层的影响都被塞进一个不断膨胀的单一状态里。
AttnRes 改成:
这里最关键的变化就两个:
- 不再固定权重为 1,而是学一个深度方向的 softmax 权重。
- 当前层可以从更早层直接取信息,不必只能吃上一层的混合结果。
这就像把“只有一根接力棒”的比赛,改成了“当前跑者可以回头从多个补给站拿水”。你不必盲信刚刚那一棒,也不用把一路上所有东西都背在身上。
更具体一点,Full AttnRes 里每一层有一个可学习的伪 query 向量 \(w_l\),键和值来自更早层的表示。作者用 RMSNorm 处理 key,再做 softmax。这个小设计很关键,因为如果不做归一化,幅值大的层会天然在注意力里占便宜,等于把“谁声音大谁赢”又偷偷带回来了。
我很喜欢这个设计里的克制感。它没有把 query 做成输入相关的复杂投影,而是先用每层一个可学习向量。这样做看上去“弱”,但带来两个现实好处:
- 推理时不需要额外的 \(d \times d\) 投影开销;
- 同一 block 内多个层的 query 可以提前并行批处理,后面基础设施优化全靠这个性质撑起来。
这不是为了论文好看,而是明显考虑过大模型训练和推理里的真账单。
🏗️ Full AttnRes 很优雅,但工程上会卡在哪
如果完全照理想方案来,当前层要看所有更早层,那就是 Full AttnRes。它在概念上最纯粹,也的确给出了最好 loss。
问题也很直接:
- 需要保存所有层输出,带来 \(O(Ld)\) 的存储与通信负担;
- 深度上全连接后,虽然计算量 \(O(L^2d)\) 对 \(L \lt 1000\) 的网络还不算离谱,但在大规模训练里,真正难受的往往不是算力,而是跨 stage 通信和激活保活。
论文这部分说得很坦白。小规模训练时,AttnRes 几乎不额外占内存,因为反向传播本来就要留激活。可一旦上到分布式训练、激活重计算、pipeline parallel,这些原本能释放再重算的中间状态,现在得一直带着,还得跨 stage 传。账就变了。
所以作者没有停留在“理论最优”,而是继续往下做了个更能落地的版本:Block AttnRes。
🔧 Block AttnRes:把“全层回看”压缩成“按块回看”
Block AttnRes 的思路很像做摘要:
- 把 \(L\) 层切成 \(N\) 个 block;
- block 内部的层输出先累加成一个 block 表示;
- 当前层主要对历史 block 表示做注意力;
- 对当前 block 内部,还保留一个逐层更新的 partial sum,避免块内信息彻底糊掉。
于是,Full AttnRes 里“看所有历史层”的问题,被替换成“看历史 block + 当前 block 的局部累积”。
效果是什么?
- 存储和通信从 \(O(Ld)\) 降到 \(O(Nd)\);
- 计算从 \(O(L^2)\) 降到 \(O(N^2)\);
- 当 \(N \approx 8\) 时,已经能吃到大部分收益。
这点非常重要。很多架构论文的坏毛病是:理论方案很好,压缩版一做性能就塌。AttnRes 没塌。Block 版本和 Full 版本在大尺度下只差一点点,这就有工程价值了。
官方仓库给了一张很直观的总览图:
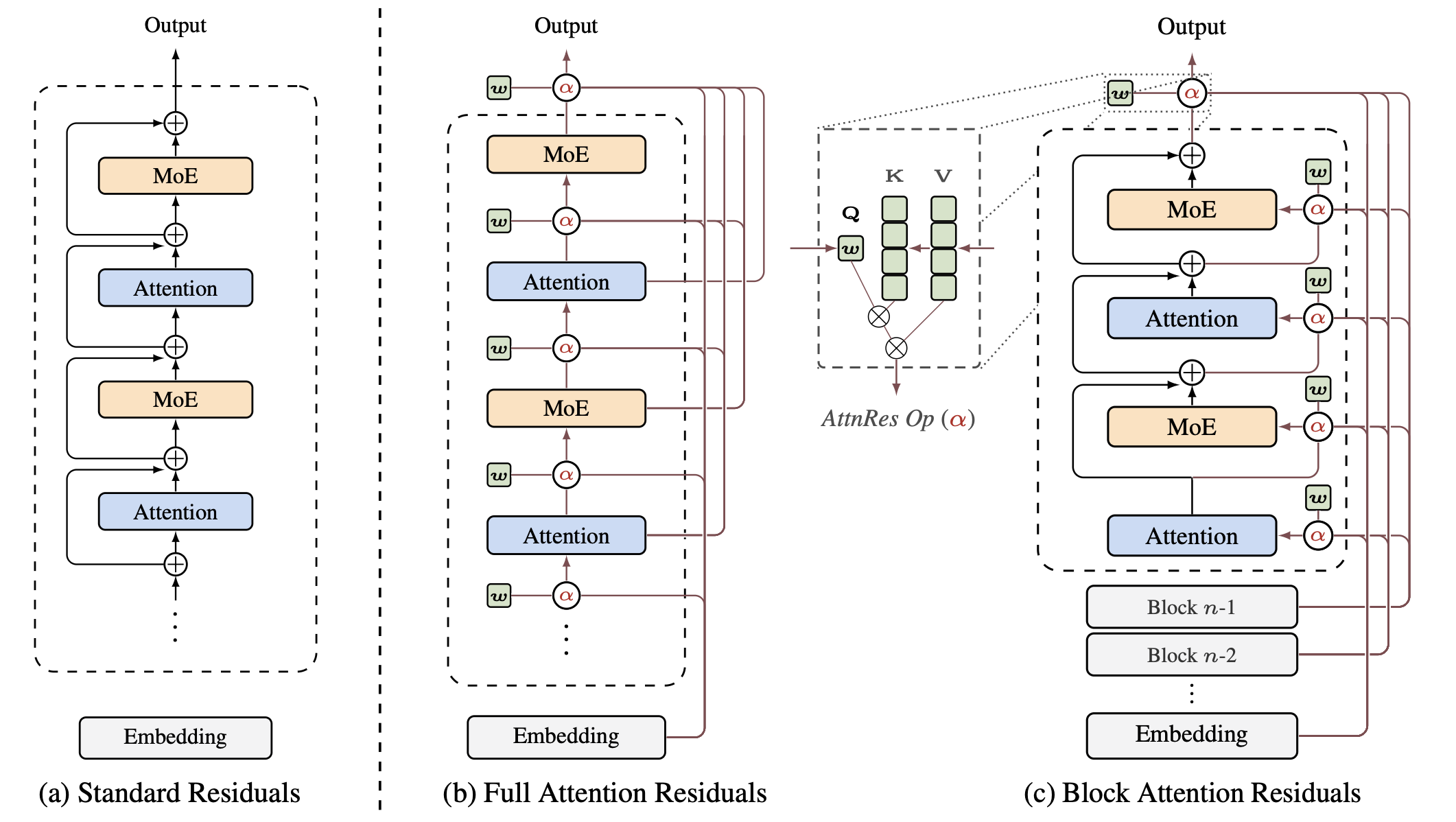
图1:左边是标准残差,所有历史只能被均匀加和;中间是 Full AttnRes,每层对所有历史层做深度注意力;右边是 Block AttnRes,把层分组后在块级别做选择,把内存从 \(O(Ld)\) 压到 \(O(Nd)\)。这张图基本把整篇论文的骨架讲完了。
如果只看这张图,我会把这篇工作的贡献归纳成一句话:把“深度维度的跳连”从手工写死,升级成了可学习的稀疏回看。
⚙️ 真正让我高看一眼的,是它把基础设施也补齐了
很多论文做到这里就停了:提出 Block 版本,然后说“我们工程上也能跑”。这篇没有糊弄,它把通信、prefill、解码延迟这些麻烦账都摊开了。
1. 训练阶段:跨 stage 缓存
如果 pipeline parallel 里每次都把完整 block 历史重新发一遍,通信会非常浪费。作者做了一个 cross-stage caching:前一轮虚拟 stage 收到的 block,本地先缓存,下一轮只传增量块。
论文给出的结论很明确:
- 峰值单次传输代价从 \(O(C)\) 降到 \(O(P)\);
- 在 steady-state 1F1B 下,这个改动可以把额外通信尽量盖到计算下面;
- 端到端训练开销在 pipeline 并行场景下 低于 4%。
2. 推理阶段:两阶段计算
Block AttnRes 还有一个麻烦:每一层都回看历史 block,会带来反复读取 KV 风格缓存的开销。作者把它拆成两段:
- Phase 1:同一 block 内所有层的 query 一次性并行打到历史 block 表示上;
- Phase 2:块内再顺序处理 partial sum,并用 online softmax 把两路结果合并。
这个设计本质上是在做“把随机小读合并成一次批量大读”。论文给出的每层 I/O 也很亮眼:
- 标准残差:
3d - Full AttnRes:
24d - Block AttnRes:
5.5d - mHC:
34d
这组数字挺有说服力。Block AttnRes 的代价确实比标准残差高,但远没高到不能接受,而且明显比同类复杂残差方案省得多。
3. 长上下文 prefill:分片缓存
长上下文时,缓存 block 表示也会涨。论文举了一个例子:128K 上下文、8 个 block 时,如果直接存,要到 15 GB。作者进一步做了 sequence sharding:
- 按序列维切到 \(P\) 个 TP 设备上;
- 每卡内存可降到 约 1.9 GB;
- 再叠加 chunked prefill,比如 16K chunk,单卡额外开销能压到 0.3 GB 以下。
这部分让我觉得作者不是只在做“paper architecture”,而是真把它当一个要进大规模训练栈的组件在设计。
📊 扩展规律实验:它不是只在一个点上赢,而是一路都赢
论文先做了五个不同规模的 scaling law,对比基线、Full AttnRes、Block AttnRes,以及 mHC-lite。
主表里的关键数字如下:
| 激活参数 | Tokens | Baseline | Block AttnRes | Full AttnRes | mHC-lite |
|---|---|---|---|---|---|
| 194M | 38.7B | 1.931 | 1.909 | 1.899 | 1.906 |
| 241M | 45.4B | 1.895 | 1.875 | 1.874 | 1.869 |
| 296M | 62.1B | 1.829 | 1.809 | 1.804 | 1.807 |
| 436M | 87.9B | 1.766 | 1.746 | 1.737 | 1.747 |
| 528M | 119.0B | 1.719 | 1.693 | 1.692 | 1.694 |
从趋势看有三件事:
- Full AttnRes 基本一直最好;
- Block AttnRes 跟得很紧,到最大尺度只差
0.001; - 优势不是偶然点状提升,而是整条 scaling curve 下移。
对应的拟合曲线也很漂亮:
- Baseline:\(\mathcal{L} = 1.891 \times C^{-0.057}\)
- Full AttnRes:\(\mathcal{L} = 1.865 \times C^{-0.057}\)
- Block AttnRes:\(\mathcal{L} = 1.870 \times C^{-0.058}\)
图放在这里最直观:
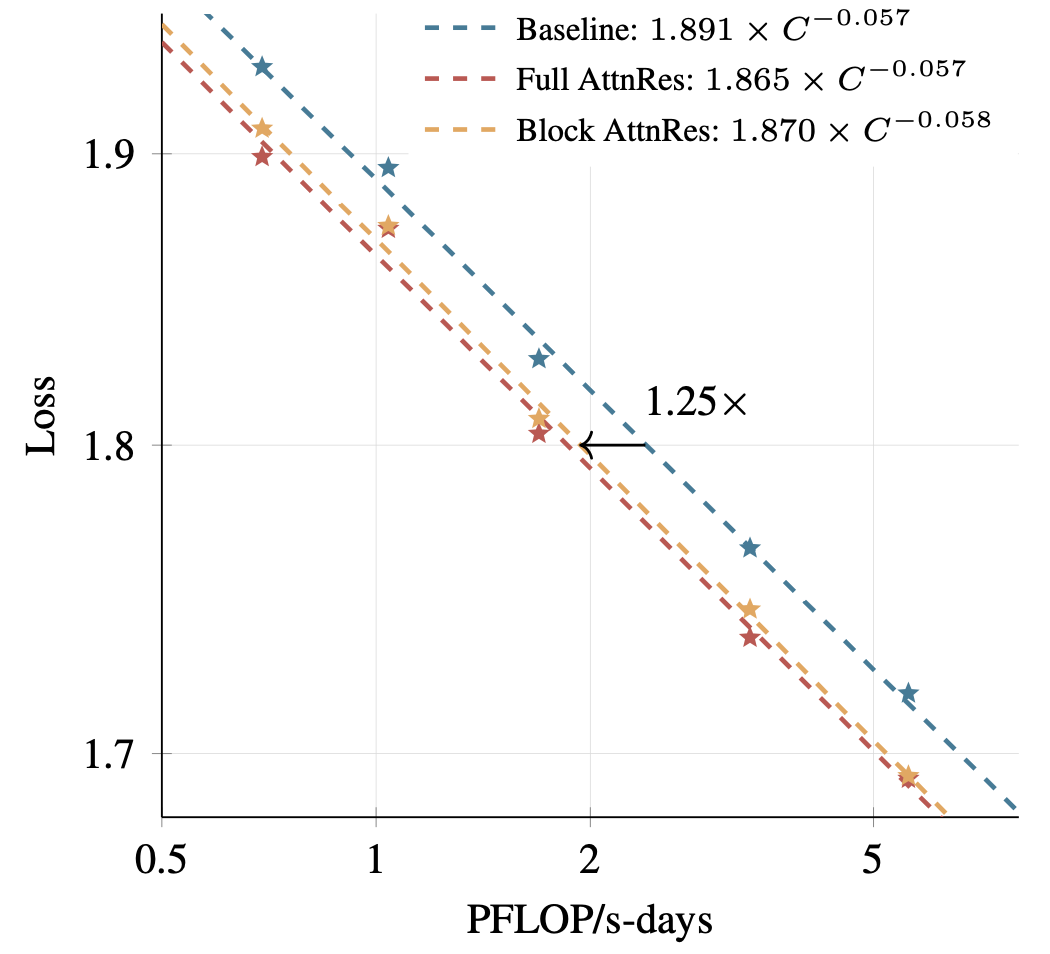
图2:三条曲线斜率差不多,但 AttnRes 整体更低,说明它不是改变了“怎么随算力增长”,而是把同等算力下的损失整体往下拉。作者据此估算,在 5.6 PFLOP/s-days 时,Block AttnRes 相当于给了基线大约 1.25 倍的训练算力优势。
我对这组结果的判断是:这篇论文最硬的证据,不是某个 benchmark 上多几点,而是它让 scaling 曲线整条平移。
这是架构工作里非常稀缺的信号。因为很多局部 trick 只在某个尺寸、某个训练 recipe、某个验证集上灵光,规模一变就不稳。AttnRes 看起来没这个毛病。
🧪 放到 Kimi Linear 48B 上,真实下游也有肉眼可见的涨幅
作者没有满足于小模型 loss,还把它接到 Kimi Linear 这套 MoE 架构上跑了完整 recipe。
模型配置是:
- 27 个 Transformer blocks,也就是 54 层
- 256 个专家里每 token 路由 8 个,再加 1 个共享专家
- 总参数 48B,激活参数 3B
- Block AttnRes 采用每块 6 层,也就是 9 个 block,再加 token embedding,一共 10 个深度源
- 训练 recipe 与 Kimi Linear 1.4T token 方案保持一致
更具体一点:
- 先在 1T tokens 上做 WSD 预训练;
- 再接约 400B 高质量 token 的中训;
- 后面继续把上下文长度拉到 32K;
- 全局 batch size 是 8M tokens。
最终下游成绩如下:
| 评测 | Baseline | AttnRes | 提升 |
|---|---|---|---|
| MMLU | 73.5 | 74.6 | +1.1 |
| MMLU-Pro | 52.2 | 52.2 | 0 |
| GPQA-Diamond | 36.9 | 44.4 | +7.5 |
| BBH | 76.3 | 78.0 | +1.7 |
| ARC-Challenge | 64.6 | 65.7 | +1.1 |
| HellaSwag | 83.2 | 83.4 | +0.2 |
| TriviaQA | 69.9 | 71.8 | +1.9 |
| GSM8K | 81.7 | 82.4 | +0.7 |
| MGSM | 64.9 | 66.1 | +1.2 |
| Math | 53.5 | 57.1 | +3.6 |
| CMath | 84.7 | 85.1 | +0.4 |
| HumanEval | 59.1 | 62.2 | +3.1 |
| MBPP | 72.0 | 73.9 | +1.9 |
| CMMLU | 82.0 | 82.9 | +0.9 |
| C-Eval | 79.6 | 82.5 | +2.9 |
这里最抓眼球的是两类任务:
- 多步科学推理:GPQA-Diamond 直接涨了
+7.5 - 代码与数学:Math
+3.6,HumanEval+3.1
这很符合 AttnRes 的机制直觉。知识型任务有涨,但最猛的地方出现在需要后层反复调用早层中间表示的复合推理任务上。你可以把它理解成:模型不是只有更大记忆,而是更会在深度方向上检索自己。
我会把这部分看成论文最有产品味道的结果。因为如果一个残差改造只能让 validation loss 好看一点,但下游不动,那价值会打折。现在这些 benchmark 的提升说明,深度信息流这件事真的会传导到实际能力上。
📈 训练动态:这篇论文最“显眼”的证据图
官方仓库里另一张很关键的图,是训练动态:
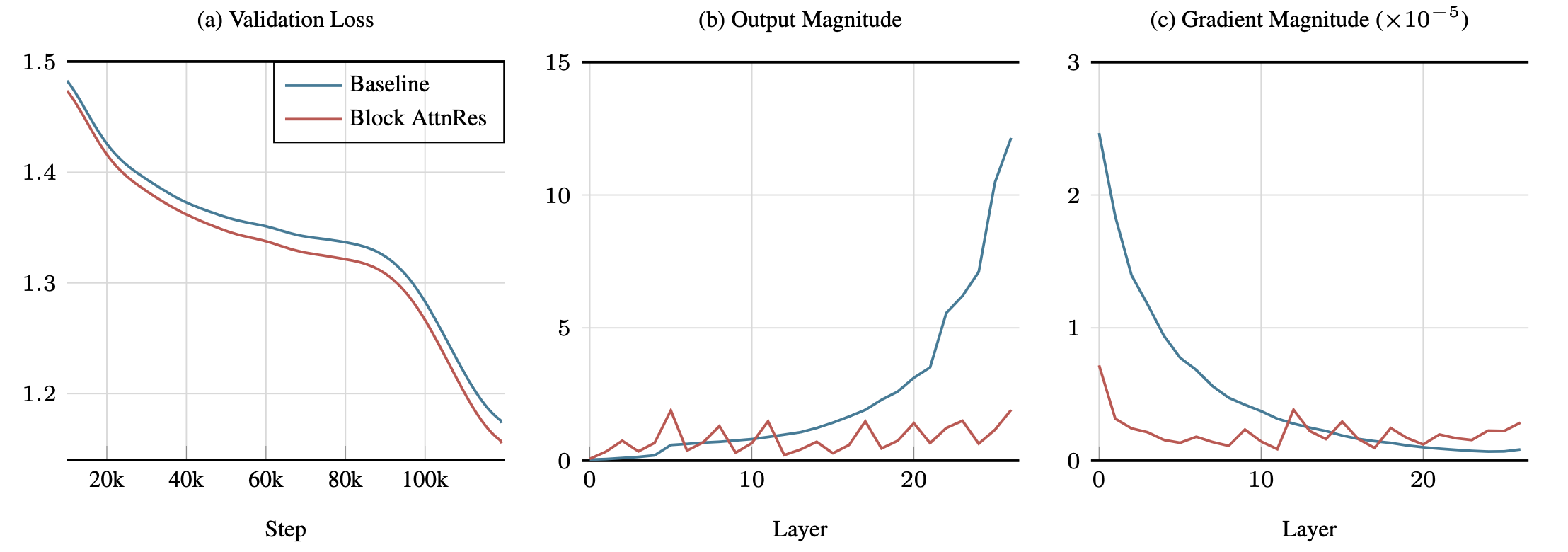
图3:左图是验证损失,中图是各层输出幅值,右图是各层梯度幅值。基线模型里,输出幅值随着深度一路涨,梯度更多压在浅层;Block AttnRes 把这种失衡压平了。
这张图的价值在于,它不是只告诉你“结果更好”,还告诉你为什么会更好。
输出幅值
基线模型里,越往后层,输出 magnitude 越夸张,到了末尾 block 几乎像冲天而起。这就是典型的 residual accumulation 失控。
Block AttnRes 则呈现出一种周期性、有界的模式。每到 block 边界,选择性聚合就像把残差流“清一次缓存”,不会再让幅值无止境堆高。
梯度幅值
基线里浅层梯度特别大,深层越来越弱,很像一条失衡的水管。AttnRes 的 softmax 权重让不同深度源之间出现竞争,梯度更平均,训练也更舒服。
这里我有个主观看法:比起把它理解成“更强 skip connection”,我更愿意把它理解成“给深度方向加了一套流量调度器”。
残差连接原来像不限流的总线,谁都往上写。AttnRes 给它装了个带竞争的路由规则,结果是信息流和梯度流都没那么拥堵了。
🔬 消融实验:真正起作用的到底是什么
这部分是论文里我最关心的,因为很多架构论文到收尾时会暴露“真正有效的其实是别的因素”。AttnRes 的消融比较干净。
1. 和旧方案比,赢点不在“多连几层”,而在“按内容选层”
16-layer 模型上:
- Baseline:
1.766 - DenseFormer:
1.767 - mHC:
1.747 - Full AttnRes:
1.737 - Block AttnRes:
1.746
DenseFormer 本质上也是让层看更多历史,但权重是静态的、输入无关的,结果几乎没赢。这说明一个要害:光让历史连接变稠密没用,关键是选择机制必须是内容相关的。
这很像搜索系统。把更多文档都塞进候选集,不代表答案就更好;有用的是排序器,而不是候选池本身。
2. softmax 比 sigmoid 更合适
把 softmax 换成 sigmoid,loss 从 1.737 变成 1.741。数字不算巨大,但方向很稳定。
作者的解释我认同:softmax 有竞争关系,能迫使模型在深度来源之间做更尖锐的选择;sigmoid 更像“都给一点票”,会把注意力重新搞成“人人有份”的旧残差味道。
3. 输入相关 query 虽然更强,但作者没贪这个便宜
把 query 做成从当前 hidden state 投出来,loss 可以到 1.731,比默认 Full AttnRes 的 1.737 更好。
可作者没把这个版本当默认方案,因为它会:
- 增加每层一个 \(d \times d\) 投影;
- 破坏 query 与前向解耦的性质;
- 让推理时块内并行失效,内存访问也更难看。
我很认同这个取舍。论文没有为了多刷 0.006 loss,硬把工程代价翻上去。 这类克制,往往比单纯追 SOTA 更说明作者清楚自己在做什么。
4. Block size 不必太细
Block size 的扫描结果也有意思:
- Full AttnRes,也就是 \(S=1\):
1.737 - Block size 2:
1.746 - Block size 4:
1.746 - Block size 8:
1.748 - 再变大就逐步回到基线附近
这说明一个很务实的点:你没必要为了一点点理论完整性,把块切得非常细。大约 8 个 block 就够用了。
🧭 架构扫描透露了一个更深的信号:AttnRes 更吃深度
论文还做了一组我觉得相当有味道的分析:固定算力和参数预算,扫不同的深度、宽度、头数配比。
结果显示:
- 基线最优点在 \(d_{model}/L_b \approx 60\),validation loss 为
1.847 - AttnRes 最优点移到了 \(d_{model}/L_b \approx 45\),validation loss 为
1.802
在固定参数预算下,更低的 \(d_{model}/L_b\) 意味着更深、更窄。换句话说,AttnRes 让模型更会利用深度了。
这点我觉得很关键,因为它不只是“给现有架构补点血”,而是可能在更长期里影响架构选型:
- 如果残差连接不再强行把深度压成一个单状态,
- 那么“深一点到底有没有用”这个问题的答案,可能会重新变。
当然,论文也很老实地说了,偏深的网络在部署时通常延迟更高,所以这不是简单的产品推荐。但从研究角度看,这是一条很有后劲的线索:有些时候我们不是缺深度,而是旧残差让深度没法被好好消费。
💡 我对这篇论文的判断:不是花哨小 trick,而是残差连接的一次重估价
如果只用一句评价,我会说:这篇工作很像“把注意力从 token 维再复制一遍到 depth 维”,但落地细节比这个口号扎实得多。
我喜欢它的三个地方:
- 问题抓得准:盯住了 PreNorm 里一个大家默认忍着用、但确实越来越痛的结构性问题。
- 形式很干净:没有发明一堆分支和矩阵,而是把残差统一写进一个“深度注意力”框架里。
- 工程补完度高:训练通信、prefill 内存、解码 I/O 都给了方案和实测开销。
如果非要挑毛病,我觉得也有三处边界:
- 现在的主验证平台还是 Kimi Linear 系列。这当然很有说服力,但还想看它在更广的 dense Transformer、不同 optimizer、不同数据配方上的迁移稳定性。
- Full AttnRes 依旧是更优上界。Block 版本已经很好,可毕竟还是一种压缩近似。未来如果硬件和互联更强,作者自己也承认会更倾向更细粒度 block,甚至回到 full。
- 这个方法更像预训练架构改动,不是便宜的后装插件。 你很难指望把一个已训练好的大模型直接打补丁替换残差,收益大概率要靠从头训练才能出来。
不过这些都不算硬伤。架构论文最怕的是“想法新鲜,但证据链不完整”。AttnRes 的证据链是完整的。
🛠️ 如果把它迁到自己的模型里,哪些经验最值得抄
如果你做的是大模型预训练或架构研究,我觉得这篇论文至少给了 5 个能直接拿走的启发:
- 残差不是铁板一块:注意力、MoE、归一化都在被重构,残差连接本身也值得重新设计。
- 先处理深度信息流,再谈更深网络:很多“深层不如加宽”的经验规律,可能部分只是旧残差的副作用。
- 输入相关选择很重要:静态加权跨层连接,收益可能有限;动态选择才真正改变表达路径。
- 做架构时别回避系统账单:如果一个结构不能讲清通信、缓存、prefill 和延迟,那它离生产很远。
- 用 block 压缩换工程可行性,是很通用的范式:不光能用于残差,很多跨层或跨步记忆结构都能借鉴这个做法。
如果你问我这篇论文最适合谁看,我会给三个答案:
- 做大模型架构的人,尤其是在琢磨残差、归一化、深度扩展的人;
- 做长训练栈和分布式系统的人,因为里面的 pipeline cache 和 prefill 设计很实;
- 做推理与代码能力方向的人,因为它在 GPQA、Math、HumanEval 这些任务上的收益很说明问题。
🧪 一个简化版伪代码:Block AttnRes 到底怎么跑
下面这段不是论文原文代码,而是把它的核心流程压成了一个更容易看懂的伪代码:
# blocks: 历史 block 表示 [b0, b1, ..., b(n-1)]
# partial_block: 当前 block 内已经累加的表示
# w_l: 当前层的 learned pseudo-query
def block_attn_res(w_l, blocks, partial_block=None):
sources = list(blocks)
if partial_block is not None:
sources.append(partial_block)
keys = [rmsnorm(x) for x in sources]
scores = [dot(w_l, k) for k in keys]
alpha = softmax(scores)
h_l = sum(a * v for a, v in zip(alpha, sources))
return h_l
for block in model.blocks:
# Phase 1:对历史 block 并行算
# Phase 2:块内顺序更新 partial_block
partial_block = None
for layer in block:
h = block_attn_res(layer.w, blocks, partial_block)
y = layer.forward(h)
partial_block = y if partial_block is None else partial_block + y
blocks.append(partial_block)
真正在高性能实现里,Phase 1 和 Phase 2 会拆得更细,还会用 online softmax 合并统计量。但从算法直觉上,你抓住一句话就够了:当前层的输入,不再是“上层状态 + 当前层输出”,而是“对历史深度表示做一次选择性重组”。
📝 一个更偏研究者视角的结论
我会把 Attention Residuals 看成这样一篇论文:
它不是在重新发明 Transformer,而是在重新定义 Transformer 里最习以为常的一根线——残差线。过去大家默认这根线越简单越好,最好是常数 1、无脑相加、训练稳定。可当模型深度、专家规模、训练 token、长上下文都一路往上长时,这种“简单”开始变成一种隐形束缚。
AttnRes 的价值,不只是把 loss 压低一点,而是给了一个更一般的观点:深度本身也可以被注意力化。
一旦接受这个观点,后面可以展开的空间就很大:
- 深度维是否能做更稀疏的路由?
- 不同 token 是否该用不同的 depth retrieval 策略?
- 残差、记忆、层间检索,会不会最终长成统一框架?
这篇论文还不是这个方向的终点,但很可能会变成一个明确的起点。
🔗 参考资料
- 论文:
https://arxiv.org/abs/2603.15031 - 官方仓库:
https://github.com/MoonshotAI/Attention-Residuals
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言