ReAct:让大模型学会"边想边干"的智能体范式
一句话总结:ReAct 把人类"想一想再动手"的思维习惯教给了大语言模型,让模型在每一步行动前先说清楚为什么这么做,行动后再根据反馈调整下一步——这个看似朴素的思路,却成了后来整个 AI Agent 领域的奠基范式。
📖 论文信息
- 标题:ReAct: Synergizing Reasoning and Acting in Language Models
- 作者:Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao
- 机构:普林斯顿大学、Google Research
- 发表:ICLR 2023
- 论文链接:arxiv.org/abs/2210.03629
- 项目主页:react-lm.github.io
🎯 这篇论文到底在解决什么问题?
2022 年底,大语言模型(LLM)已经展现出惊人的文本生成能力,但有两个痛点一直卡在那里:
痛点一:只会想,不会干。 像思维链(Chain-of-Thought, CoT)这类方法,让模型把推理过程一步一步写出来,逻辑看上去很漂亮,但模型推理的全部"原料"只有它训练时见过的东西。一旦碰到需要查实时信息、调用计算器、翻数据库的场景,CoT就只能硬编——编出来的东西叫"幻觉"。
痛点二:只会干,不会想。 另一批研究让模型直接输出行动指令去操作外部环境(比如控制机器人、在网页上点击),但模型不解释自己在想什么,碰到稍微复杂一点的任务就抓瞎——它不知道为什么要做这一步,也不知道做完之后下一步该怎么调整。
这就好比一个实习生:光让他坐在那想方案,他可能写出一份逻辑自洽但数据全是编的PPT;光让他执行指令干活,碰到计划外的情况他就卡住了。
ReAct 的核心思路其实特别直觉——让模型边想边干,干完看反馈,再接着想。
🧠 核心方法:Thought → Action → Observation 的闭环
ReAct 这个名字是 Reasoning + Acting 的缩写,核心机制是一个不断循环的三步流程:

图1:上半部分展示了知识问答任务中四种方法的对比(Standard、CoT、Act-only、ReAct),下半部分展示了文本游戏 ALFWorld 中 Act-only 与 ReAct 的对比。可以看到,ReAct 在每一步行动前都有一段绿色的"Thought"推理,这让它能持续修正方向。
Thought(推理):模型的"内心独白"
模型先分析当前状况:我现在知道了什么?还缺什么信息?下一步该做什么?为什么要做这一步?
这不是摆设——推理轨迹是 ReAct 可解释性的关键。传统方法就像一个沉默的员工,做完活交结果,你不知道他怎么想的;ReAct 则是每一步都在"自言自语",你可以随时检查他的逻辑是否合理。
Action(行动):调用外部工具
推理完之后,模型输出一个标准化的行动指令,比如 Search[爱因斯坦 诺贝尔奖] 或 Lookup[获奖原因]。这些行动会被解析器识别并路由到对应的外部工具去执行。
Observation(观察):环境的客观反馈
工具执行完毕后,把结果原样返回给模型。比如搜索引擎返回了一段维基百科的内容,或者游戏环境返回了"你在厨房里,看到一个柜台"。这些客观信息会被追加到模型的上下文里,成为下一轮推理的"新证据"。
然后循环继续:模型拿着新拿到的信息重新推理,决定下一步行动……直到任务完成(输出 Finish[答案]),或者达到最大步数限制。
用一个生活场景打比方:你想订一张今晚从深圳飞海口最便宜的机票。
- Thought:"我需要查今晚从深圳到海口的航班,先看看有哪些可选"
- Action:打开机票 App 搜索
- Observation:App 返回了三个航班及票价
- Thought:"三个航班里最便宜的是 HU7089,480 块,下一步直接订票"
- Action:点击预订 HU7089
- Observation:预订成功
- Finish:搞定
这就是 ReAct 的全部核心——没有什么复杂的数学公式,没有需要训练的新模块,就是用 Prompt 告诉模型"你要按这个套路来"。
🏗️ 技术架构:三层模块化设计
虽然 ReAct 的思想很朴素,但要让它稳定跑起来,架构设计上还是有讲究的。整体可以拆成三层:
第一层:核心逻辑层——LLM + Prompt
这一层就是大模型本身加上精心设计的提示词。Prompt 里包含几个要素:
- 角色定义:告诉模型"你是一个 ReAct 智能体,需要交替生成 Thought 和 Action"
- Few-shot 示例:给 1-5 个完整的"任务 → Thought → Action → Observation → ... → Finish"示例,让模型学会格式和逻辑模式
- 工具描述:列出所有可用的工具及其参数格式
- 格式约束:明确要求输出必须严格遵循 Thought/Action 的交替格式
一个有意思的点是:ReAct 不需要对模型做任何微调。它完全靠 in-context learning——就是在 prompt 里放几个示例,模型就能学会这个范式。这大幅降低了落地成本。
第二层:执行循环层——调度中枢
这一层负责把推理、行动、观察三个环节串起来,核心是三个组件:
- 上下文管理器:存储历史 TAO 轨迹。当轨迹太长快要撑爆上下文窗口时,采用"保留最近 3 轮完整轨迹 + 早期轨迹摘要"的策略裁剪。
- 行动解析器:解析模型输出的 Action 文本,校验格式是否合规、参数是否完整,然后路由到对应工具。如果解析失败,生成错误提示作为 Observation 返回给模型。
- 循环调度器:控制迭代节奏,判断终止条件(正常完成、超时、连续失败熔断)。
第三层:外部交互层——工具集 + 环境
这一层是 ReAct 与外部世界的接口。工具的设计遵循统一接口:每个工具实现一个 run(params) 方法,接收标准化参数,返回字符串结果。
论文中根据不同任务配置了不同的工具: - HotpotQA / Fever:Search[query](搜索维基百科)、Lookup[keyword](在搜索结果中定位关键词)、Finish[answer] - ALFWorld:go to [location]、take [object]、put [object] in/on [location] 等游戏操作 - WebShop:search[query]、click[element] 等网页交互操作
模块化是这里最大的优势:想从问答任务切换到机器人控制?核心逻辑层和执行循环层不用动,只需要替换工具集就行。
🧪 实验结果:数据说话
论文在四个差异很大的任务上做了实验,覆盖了"知识推理"和"交互决策"两大场景。
知识密集型任务:HotpotQA & Fever
这两个是经典的 NLP benchmark:HotpotQA 做多跳问答(需要综合多条信息才能回答的问题),Fever 做事实核查(判断一个陈述是"支持"、"反驳"还是"信息不足")。
模型统一使用 PaLM-540B,工具是简单的维基百科 API。结果如下:
| 方法 | HotpotQA (EM) | Fever (Acc) |
|---|---|---|
| Standard(直接回答) | 28.7 | 57.1 |
| CoT(思维链) | 29.4 | 56.3 |
| CoT-SC(思维链+自洽性) | 33.4 | 60.4 |
| Act(只行动不推理) | 25.7 | 58.9 |
| ReAct | 27.4 | 60.9 |
| CoT-SC → ReAct(先CoT再ReAct兜底) | 34.2 | 64.6 |
| ReAct → CoT-SC(先ReAct再CoT兜底) | 35.1 | 62.0 |
| 有监督 SOTA | 67.5 | 89.5 |
几个值得注意的发现:
ReAct 单独用并不总是最强的。 在 HotpotQA 上,ReAct(27.4)甚至不如 CoT-SC(33.4)。这是因为 ReAct 对搜索结果质量很敏感——如果搜出来的内容没啥用,模型容易卡住或者走偏。但 ReAct 的强项在 Fever 上体现得更明显:它的 60.9% 打败了 CoT 的 56.3%,因为事实核查特别需要外部证据锚定。
ReAct + CoT-SC 组合才是最优解。 论文提出了一个巧妙的协同策略:先用 CoT-SC 跑,如果多次采样的答案不一致(说明模型没把握),就切换到 ReAct 去查外部信息;或者反过来,ReAct 跑不出结果时用 CoT 兜底。这种组合在两个数据集上都拿到了最高分。
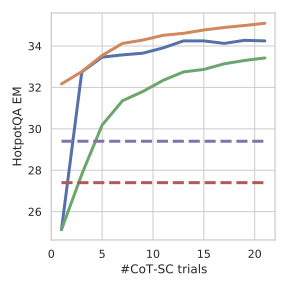
图2(左):HotpotQA 上随着 CoT-SC 采样次数增加的表现。橙色线(CoT-SC → ReAct)和蓝色线(ReAct → CoT-SC)始终在纯 CoT-SC(绿色线)之上,说明两种能力互补。
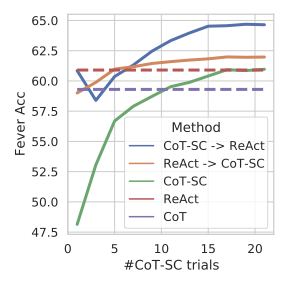
图3:Fever 上的类似趋势——ReAct 提供了一个稳定的"下限保障"(红色虚线),CoT-SC 随采样增加逐渐追上来,两者组合效果最佳。
错误分析:幻觉 vs 搜索失败
论文做了很扎实的人工错误分析,随机抽取样本逐条检查成功和失败的原因:
| 类别 | ReAct | CoT |
|---|---|---|
| 成功案例中 | ||
| 推理和事实都正确 | 94% | 86% |
| 推理或事实有幻觉 | 6% | 14% |
| 失败案例中 | ||
| 推理错误 | 47% | 16% |
| 搜索结果无用 | 23% | - |
| 幻觉 | 0% | 56% |
| 标签歧义 | 29% | 28% |
这张表有两个数字特别亮眼:
-
ReAct 失败案例中的幻觉率是 0%,CoT 是 56%。 这就是外部工具锚定的威力——ReAct 要么拿到正确信息做出正确判断,要么因为搜索不到信息而失败,但它不会"编"。CoT 则相反,超过一半的错误都是在编造事实。
-
ReAct 的主要失败原因是推理错误(47%)和搜索质量差(23%)。 这说明 ReAct 的瓶颈不在"会不会编",而在"搜不搜得到"和"推理链条会不会断"。后者在长链路任务中尤其明显——模型容易陷入重复搜索的死循环。
交互式决策任务:ALFWorld & WebShop
这两个任务更接近真实世界的 Agent 场景:
ALFWorld 是一个文本版的家庭机器人模拟环境——你需要在房间里找到某个物品,执行加热、清洁等操作,然后放到指定位置。包含 6 类子任务:Pick、Clean、Heat、Cool、Look、Pick 2。
WebShop 是一个模拟电商环境——给你一个购物需求描述,你需要在网页上搜索、筛选、点击来买到符合要求的商品。
| 方法 | ALFWorld(成功率) | WebShop(成功率) |
|---|---|---|
| Act(只行动不推理) | 45% | 30.1% |
| ReAct(最优 prompt) | 71% | 40.0% |
| BUTLER(强化学习) | 37% | - |
| IL + RL(模仿学习+强化学习) | - | 28.7% |
| 人类专家 | - | 59.6% |
在 ALFWorld 上,ReAct 71% 的成功率比强化学习方法 BUTLER 的 37% 高了整整 34 个百分点。 而且 BUTLER 是用 \(10^3\) 到 \(10^5\) 量级的训练数据训练出来的,ReAct 只用了 1-2 个 few-shot 示例。
为什么差距这么大?看下面这个对比就明白了:
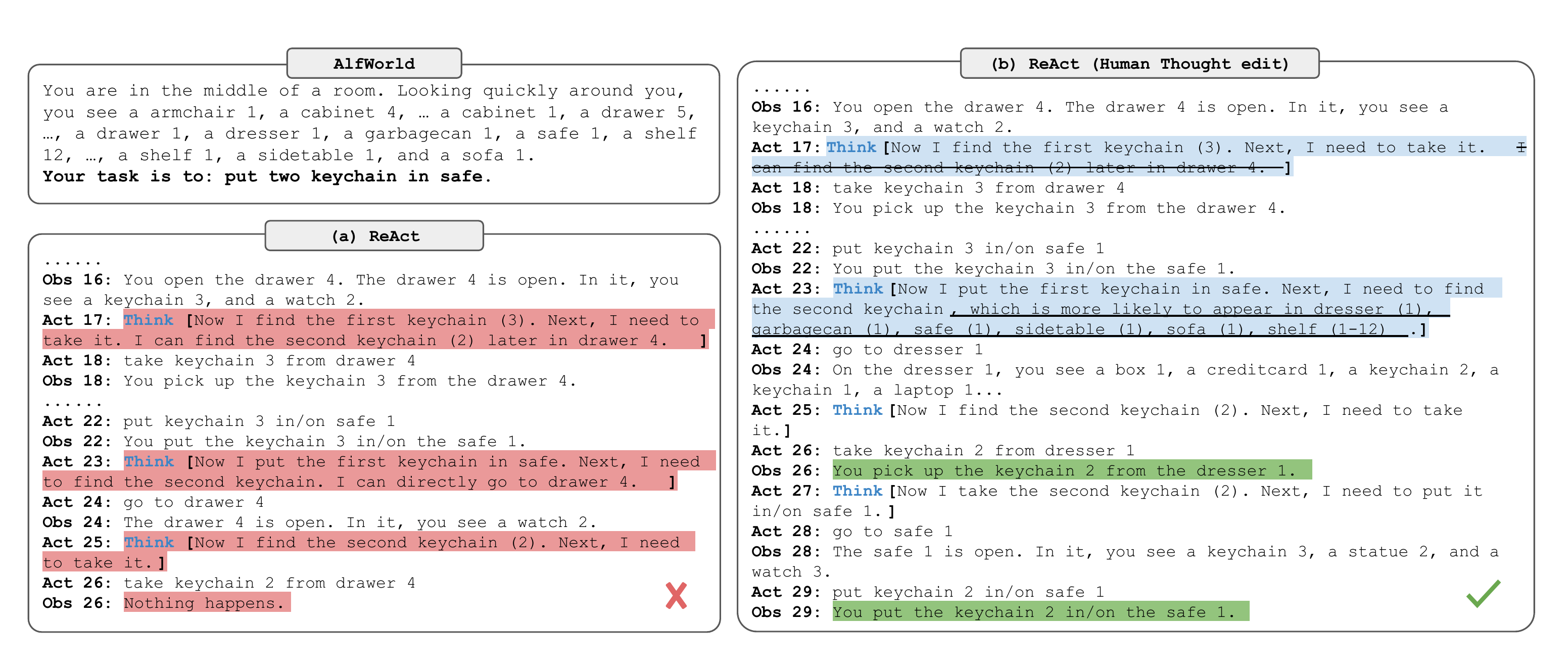
图4:ALFWorld 中 Act-only(左)vs ReAct+人类编辑推理(右)的对比。Act-only 模型在执行过程中遇到错误后无法恢复(一路标红),而加入推理后模型能及时发现问题并调整策略(绿色 Thought 标注的推理步骤指引了正确方向)。
Act-only 模型在 ALFWorld 里的典型失败模式是"死磕"——打开了错误的抽屉之后,它不会想"这个抽屉没有,换个地方找",而是一直重复操作。ReAct 加入 Thought 后,模型可以在每一步反思"上一步没找到,下一步应该去别的地方看看"。
在 WebShop 上,ReAct 40% 的成功率也大幅领先模仿学习+强化学习的 28.7%,但距离人类专家的 59.6% 还有不小差距——这说明 ReAct 虽然是一个好范式,但在需要深度理解产品属性和用户意图的场景下,纯 prompt 方法还不够。
微调实验:小模型也能行
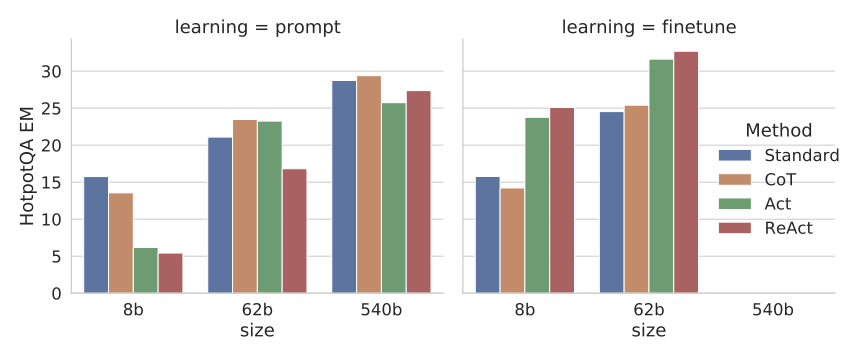
图5:HotpotQA 上不同模型规模(8B / 62B / 540B)在 Prompt(左)和 Finetune(右)设置下的表现。右图显示:在微调场景下,ReAct 格式让 62B 的小模型超越了 540B 大模型的 Prompt 表现。
这张图传达了一个很重要的信号:ReAct 不只是大模型的专利。当你对小模型做微调时,用 ReAct 格式的数据训练效果最好——62B 模型微调后在 HotpotQA 上跑到了 ~33 分,超过了 540B 模型 prompt 的 ~29 分。这意味着 ReAct 可以作为一种数据格式来蒸馏大模型的推理能力到小模型中。
🔬 深入分析:ReAct 做对了什么,没做好什么
做对的事情
1. 把"可解释性"从口号变成了工程手段。
在 ReAct 之前,大模型的决策就是个黑箱——你给它一个问题,它给你一个答案,中间发生了什么完全不知道。ReAct 强制模型在每一步行动前"自言自语",这不仅方便调试,还让人类可以在关键节点介入修正。论文的人工研究证实了这一点:在 ReAct 的成功案例中,94% 的推理轨迹和事实都是正确的,而 CoT 只有 86%。
2. 用最低的成本实现了推理和行动的统一。
不需要训练新模型、不需要设计新架构、不需要标注大量数据——只需要在 prompt 里放几个精心设计的示例。这种"四两拨千斤"的方法论让 ReAct 的落地门槛极低,也是它后来被 LangChain、AutoGPT 等框架广泛采用的重要原因。
3. 模块化设计让场景迁移成本极低。
从问答切到游戏控制,只需要换工具集和 few-shot 示例。核心的 TAO 循环逻辑完全复用。
没做好的地方
1. 上下文窗口是硬瓶颈。
每一轮 TAO 循环都在往上下文里追加内容。论文中的任务基本上 3-6 步就能搞定,但如果任务需要 10 步以上呢?上下文裁剪虽然能缓解,但"保留近期 + 早期摘要"的策略必然会丢失信息。2023-2024 年长上下文模型(Gemini 1.5 Pro 的 100 万 token 窗口)在一定程度上缓解了这个问题,但信息在长上下文中的"迷失"(lost in the middle)又是另一个挑战。
2. 没有行动效果的量化反馈机制。
模型选择调用哪个工具、用什么参数,完全靠自己"想"——没有一个 reward 信号告诉它"这次搜索质量很高"或者"你已经搜了三次同样的东西了"。错误分析也印证了这一点:ReAct 47% 的失败来自推理错误,其中相当一部分是重复无效行动。
3. 搜索质量严重依赖外部工具。
论文在 HotpotQA 上 ReAct 跑不过 CoT-SC,核心原因就是维基百科 API 经常返回不相关的结果。模型本身缺少"这个搜索结果有没有用"的判断能力——或者说,它在 prompt 中没有被充分引导去做这种判断。
💡 ReAct 在 Agent 技术栈中的位置
从 2023 年到 2026 年,ReAct 已经成了 AI Agent 领域绕不开的基础范式。但它不是终点,而是起点。看看 ReAct 启发了什么:
| 方向 | 代表工作 | 核心改进 |
|---|---|---|
| 工具使用标准化 | Toolformer, Gorilla | 自动发现和调用 API |
| 多智能体协作 | AutoGen, CrewAI | 多个 ReAct Agent 协同完成复杂任务 |
| 长程记忆 | MemGPT, Generative Agents | 引入外部记忆模块突破上下文限制 |
| 强化学习融合 | WebAgent, AgentTuning | 用 RL 优化行动选择策略 |
| 规划增强 | Plan-and-Solve, Tree of Thoughts | 在 ReAct 之上增加全局规划能力 |
当下主流的 Agent 框架——LangChain 的 AgentExecutor、OpenAI 的 Function Calling、Anthropic 的 Tool Use——本质上都是 ReAct 的工程化实现。区别只在于:
- 格式标准化:从 ReAct 的自由文本
Action: Search[query]演化到了结构化的 JSON 函数调用 - 工具发现:从手动指定工具列表到模型自动根据任务选择工具
- 错误恢复:从简单重试到复杂的 fallback 策略
可以说,ReAct 定义了"推理型 Agent"这个品类。
🤔 我的一些思考
ReAct 为什么能成为范式?
不是因为它的实验数据多么碾压——实际上在 HotpotQA 上它单独还打不过 CoT-SC。真正让它成为范式的是简洁性和可组合性:TAO 循环是一个足够简单的抽象,简单到任何团队都能在一天之内把它跑起来,又足够灵活到可以不断往上叠加新能力。
ReAct 最需要补的短板是什么?
我觉得是行动质量的反馈闭环。当前 ReAct 的行动选择完全依赖 LLM 的"直觉",缺乏量化的好坏判断。如果能引入一个轻量级的 reward model——不需要多复杂,哪怕只是"这次搜索结果的相关性打几分"——就能大幅减少无效行动,降低执行成本。2024-2025 年 Agent Tuning 方向的工作已经在尝试用 RL 优化 Agent 的行动策略,效果很明显。
对工程落地的启示
如果你正在构建一个 AI Agent 系统,ReAct 教给我们的最重要的一课不是"要用 TAO 循环",而是显式推理轨迹的价值远大于你的想象。它不仅让系统可调试、可解释,还能作为数据飞轮的起点——你可以从推理轨迹中发现模型的短板,定向优化 prompt 或微调数据。
📚 参考文献
- Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., & Cao, Y. (2023). ReAct: Synergizing Reasoning and Acting in Language Models. ICLR 2023. arxiv.org/abs/2210.03629
- Wei, J., et al. (2022). Chain-of-thought prompting elicits reasoning in large language models. NeurIPS 2022.
- Wang, X., et al. (2022). Self-consistency improves chain of thought reasoning in language models.
- Shridhar, M., et al. (2020). ALFWorld: Aligning Text and Embodied Environments for Interactive Learning.
- Yao, S., et al. (2022). WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents.
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言