Avey-B:抛弃注意力机制,用"分拣员+处理器"重新定义双向编码器
一句话总结:Avey-B 用"排序器-处理器"流水线取代了 Transformer 中的自注意力机制,实现了 O(N) 线性复杂度,在 NLU 四大任务上与 ModernBERT 打成平手,同时在长文本场景(96K tokens)上取得了 3.38 倍加速和 11.63 倍于 NeoBERT 的吞吐量优势。
论文标题:Avey-B: A Bidirectional Encoder that Don't Pay Attention
作者:Devang Acharya, Mohammad Hammoud
机构:Avey AI
发表时间:2026年2月17日
论文链接:arXiv:2602.15814
一、为什么我们需要"不用注意力"的编码器?
1.1 Transformer 注意力机制的瓶颈
自 2017 年 Vaswani 等人提出 Transformer 以来,自注意力(Self-Attention)机制一直是 NLP 领域的基石。BERT、RoBERTa、ModernBERT、NeoBERT……这些双向编码器模型在文本分类、命名实体识别、问答系统、信息检索等任务上大放异彩,几乎统治了自然语言理解(NLU)的所有基准。
然而,自注意力的代价也很明显:它的计算复杂度是 \(O(N^2)\),其中 \(N\) 是输入序列长度。这意味着当你把文本长度从 2K 扩展到 96K 时,计算量会增长约 2300 倍。对于需要处理长文档的检索系统、法律文本分析、科研论文理解等场景,这个二次复杂度就像一道无形的墙。
打个比方:想象一个教室里有 100 个学生,老师(注意力机制)要让每个学生与其他所有学生交流一遍,才能决定谁的发言最重要。100 个学生需要 \(100 \times 100 = 10000\) 次两两交流。如果学生增加到 1000 人,就需要 100 万次交流——这显然不可行。
1.2 现有的"高效注意力"方案
学界和工业界为解决这个问题提出了大量方案:
- Sparse Attention(如 Longformer、BigBird):只让部分 token 互相关注,降低到 \(O(N\sqrt{N})\) 或 \(O(N \log N)\)
- Linear Attention(如 Performer、Katharopoulos et al.):通过核函数近似 softmax attention,达到 \(O(N)\)
- State Space Models(如 Mamba、S4):用状态空间方程替代注意力,在因果(单向)场景下表现出色
但这些方案面临一个共同的尴尬:要么牺牲了表达能力,要么主要针对因果语言模型设计,在双向编码器场景下表现不佳。事实上,截至 2026 年初,NLU 领域的主流 SOTA 模型——ModernBERT 和 NeoBERT——仍然使用标准的自注意力机制。
1.3 Avey-B 的切入点
Avey-B 的作者提出了一个大胆的问题:我们真的需要注意力机制来做双向语言理解吗?
他们的答案是:不需要。与其修修补补地优化注意力,不如彻底换一套机制。Avey-B 提出了一种全新的"排序器/排名器(Sorter/Ranker)+ 神经处理器(Neural Processor)"架构,用余弦相似度匹配和学习型线性变换来替代自注意力,从根本上实现了 \(O(N)\) 的线性复杂度。
二、方法概述:一条"分拣流水线"
2.1 核心思想
如果把传统 Transformer 比作一个"所有人都要开会讨论"的决策模式,那 Avey-B 更像一条高效的快递分拣流水线:
- 分拣员(Sorter/Ranker):先把大量包裹(token)按目的地(语义相似度)分组,只把相关的包裹放在一起处理
- 处理器(Neural Processor):对每组包裹进行精细处理——先展开检查(Enricher),再在组内传递信息(Contextualizer),最后打包整合(Fuser)
这种"先分拣再处理"的模式,避免了"所有 token 两两交互"的巨大开销。
2.2 整体架构
Avey-B 的工作流程如下:
输入 → 分词 & 嵌入 → Sorter/Ranker(分组 + 压缩) → Neural Processor(丰富 + 上下文化 + 融合) → 输出
其中 Sorter/Ranker 负责"从全局中找到与每个片段最相关的上下文",Neural Processor 负责"在有限的局部上下文中深度处理信息"。
三、技术细节:深入"分拣流水线"的每个环节
3.1 Sorter/Ranker:智能分拣员
3.1.1 序列分片
给定一个长度为 \(N\) 的输入序列,Sorter/Ranker 首先将其切分为 \(N/S\) 个大小相等的片段(splits),每个片段包含 \(S\) 个 token。论文中默认设置 \(S = 256\)。
3.1.2 MaxSim 相似度计算
对于每个片段,Sorter/Ranker 需要找到与它最相关的其他片段。这里使用的是 MaxSim 相似度——一种源自信息检索领域 ColBERT 的经典方法:
简单来说,对于查询片段 \(q_i\) 中的每个 token,找到文档片段 \(d_j\) 中与它最相似的 token,取其余弦相似度,然后对所有 token 的相似度取平均。
这种方法的好处是:它能捕捉细粒度的 token 级别匹配,而不仅仅是粗粒度的片段级别匹配。就像一个经验丰富的分拣员,不是看包裹外面的标签就随便归类,而是会翻开看看里面的具体物品。
3.1.3 Top-k 选择与上下文构建
计算出所有片段对之间的 MaxSim 相似度后,对每个片段选择与它最相似的 Top-k 个片段(论文中 \(k = 3\))。然后将这 \(k\) 个片段与当前片段拼接,形成一个扩展的上下文窗口:
这样每个片段的处理上下文从 \(S\) 扩展到了 \((k+1) \times S\) 个 token。
3.1.4 神经压缩(Neural Compression)
这里有一个关键创新:扩展上下文有 \((k+1)S\) 个 token,但我们只需要输出 \(S\) 个 token 的表示。如何压缩?
Avey-B 使用了一个学习型线性投影 + 残差连接的压缩模块:
其中 \(f_\theta\) 是一个可学习的线性映射,将 \((k+1)S\) 维的拼接表示压缩回 \(S\) 维。残差连接确保了当前片段的原始信息不会在压缩过程中丢失。
这个压缩操作的计算复杂度是 \(O(N)\)——因为每个片段的压缩是独立且固定大小的。
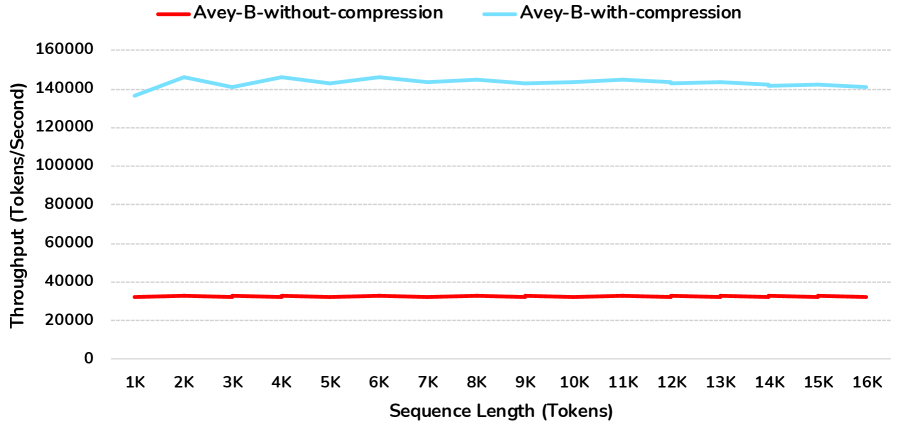
图:有无神经压缩模块的吞吐量对比。蓝色线(有压缩)的吞吐量约为红色线(无压缩)的 4.37 倍,且在不同序列长度下几乎保持恒定,验证了 O(N) 线性复杂度的实际效果。
3.2 Neural Processor:精细处理器
Sorter/Ranker 输出的压缩表示被送入 Neural Processor,后者包含三个子组件:
3.2.1 Enricher(丰富器)
Enricher 对每个位置的 token 表示进行特征扩展。可以理解为"给每个包裹贴上更详细的标签"。这是一个逐位置的前馈操作,为后续的上下文交互提供更丰富的特征表示。
3.2.2 Contextualizer(上下文化器)——核心创新
Contextualizer 是 Avey-B 最核心的技术创新所在。它由多层交替排列的静态层(Static Layer)和动态层(Dynamic Layer)组成,用于替代 Transformer 中的自注意力机制。
静态层(Static Layer)
静态层使用可学习的权重矩阵 \(W\) 对输入进行线性变换:
这些权重 \(w\) 是与输入无关的——不管输入什么文本,权重矩阵都是一样的。静态层的作用类似于 FFN(前馈网络),捕捉通用的位置相关模式。
动态层(Dynamic Layer)
动态层基于余弦相似度来决定 token 之间的信息混合比例:
注意这里的关键:动态层的混合权重 \(s\) 完全由输入决定——对于不同的输入文本,权重分布会不同。两个语义接近的 token 会有更高的混合权重,从而更多地交换信息。
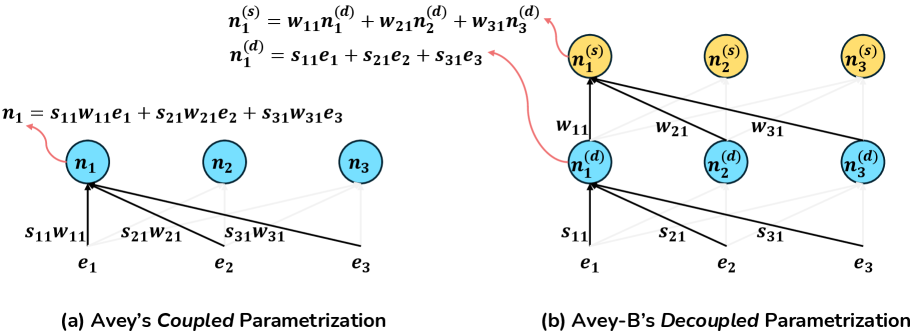
图:耦合参数化(左,Avey原始方案)与解耦参数化(右,Avey-B方案)的对比。在耦合方案中,每个输出 \(n_1\) 由静态权重 \(w\) 和动态相似度 \(s\) 的乘积共同决定;在解耦方案中,静态层和动态层被分开,各自独立计算后交替叠加。
3.2.3 为什么要"解耦"?——避免相关性单调性破坏
这是本文最精彩的理论分析之一。
在前作 Avey("Don't Pay Attention",arXiv:2506.11305)中,静态权重和动态相似度是耦合在一起的:
作者发现,这种耦合设计会破坏一个重要的性质——相关性单调性(Relevance Monotonicity):如果 token A 与 token C 的语义相似度高于 token B 与 token C 的语义相似度,那么 A 对 C 的贡献应该大于 B 对 C 的贡献。
但在耦合方案中,静态权重 \(w\) 可能"翻转"动态相似度 \(s\) 建立的排序。比如 \(s_{A,C} > s_{B,C}\),但如果 \(w_{A,C}\) 很小而 \(w_{B,C}\) 很大,最终 \(s_{A,C} \cdot w_{A,C}\) 可能反而小于 \(s_{B,C} \cdot w_{B,C}\)。
打个生活中的比方:你在图书馆找参考文献,理应优先看与你课题最相关的论文。但如果图书管理员(静态权重)强行按出版社优先级重新排了序,结果你先看了一堆不太相关但出版社"权重高"的论文——这就是相关性单调性被破坏的后果。
解耦参数化通过将静态层和动态层完全分开,消除了这种干扰:
- 动态层严格按照语义相似度混合信息——相关性单调性得到保证
- 静态层独立地学习位置相关的特征变换——不会干扰相似度排序
两类层交替排列(如 Static → Dynamic → Static → Dynamic → ...),既保留了动态的语义敏感性,又保留了静态的位置模式学习能力。
3.2.4 行归一化(Row Normalization)——稳定训练的关键
在动态层中,余弦相似度分数需要进行归一化。作者对比了三种方案:
| 归一化方法 | MNLI | QQP | SST-2 | CoNLL | SQuAD |
|---|---|---|---|---|---|
| Softmax | 88.3 | 90.9 | 95.4 | 92.1 | 89.5 |
| RMS | 发散 | 发散 | 发散 | 发散 | 发散 |
| 行归一化(Row Norm) | 89.7 | 91.4 | 95.8 | 93.2 | 90.8 |
结果很明确:RMS 归一化直接导致训练发散,Softmax 可以工作但不如行归一化。
行归一化的公式是:
分母取的是所有余弦相似度的绝对值之和,这保证了归一化后的值域在 \([-1, 1]\) 之间,且总和的绝对值不超过 1。与 Softmax 相比,行归一化保留了负相似度的信息——如果两个 token 语义相反,它们的混合权重可以是负的,这提供了更丰富的表达能力。
3.2.5 Fuser(融合器)
最后,Fuser 将 Contextualizer 的输出与一条旁路(bypass)特征进行融合。旁路特征来自 Enricher 的输出,通过残差连接保留了未经上下文化的原始信息。这种设计确保了模型在深层上下文化的同时,不会丢失浅层的局部特征。
3.2.6 层可视化
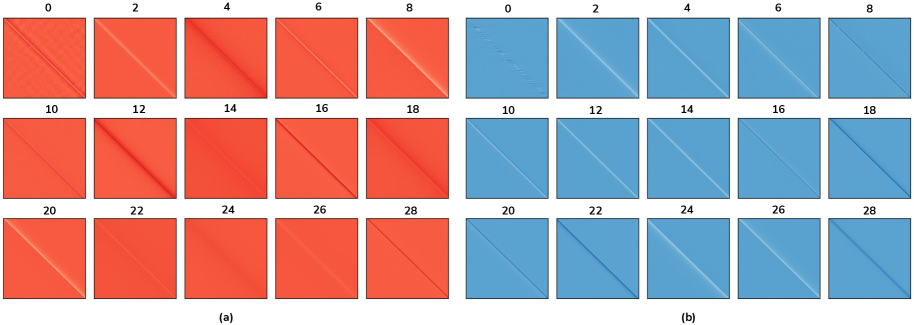
图:Avey-B 15 个层的相似度矩阵可视化。(a) 红色矩阵:静态层学到的权重模式,呈现出明显的对角线结构和块状模式,说明静态层倾向于捕捉局部位置关系。(b) 蓝色矩阵:动态层的余弦相似度模式,同样呈现对角线主导的结构,但模式随层深度变化,说明动态层在不同层级捕捉不同粒度的语义关系。
从可视化中可以观察到两个有趣的现象:
- 静态层的权重模式跨层相对稳定:前几层和后几层的红色矩阵结构类似,说明位置相关的模式是相对固定的
- 动态层的相似度模式随层深度演变:浅层的蓝色矩阵对角线更集中(关注局部),深层逐渐分散(关注全局),这与 Transformer 中注意力头从浅层到深层的行为模式一致
3.3 复杂度分析
| 操作 | Transformer (Self-Attention) | Avey-B |
|---|---|---|
| 全局交互 | \(O(N^2)\) | \(O(N/S \times (N/S))\) ≈ \(O(N^2/S^2)\)(仅在分片间) |
| 局部处理 | - | \(O((k+1)S \times S)\) per split |
| 压缩 | - | \(O(N)\) |
| 总体 | \(O(N^2)\) | \(O(N)\)(当 \(S\), \(k\) 为常数时) |
关键洞察:Sorter/Ranker 的 MaxSim 计算虽然涉及片段间的两两比较,但由于片段数量为 \(N/S\),每个片段大小固定为 \(S\),所以实际复杂度是 \(O(N^2/S^2 \times S) = O(N^2/S)\)。当 \(S\) 足够大(如 256),这个项远小于 \(O(N^2)\)。而 Neural Processor 中的 Contextualizer 只在固定大小 \(S\) 的片段内操作,复杂度为 \(O(S^2)\) per split,总计 \(O(N \times S) = O(N)\)。
四、预训练设置
4.1 训练配置
| 配置项 | 设定值 |
|---|---|
| 预训练语料 | FineWeb |
| 训练token数 | 180B |
| 序列长度 | 2048 |
| 片段大小 \(S\) | 256 |
| Top-k | 3 |
| 掩码率 | 20% |
| 模型参数量 | 149M |
| Sorter/Ranker 层数 | 1 |
| Neural Processor 层数 | 30(15 static + 15 dynamic) |
| 隐藏维度 | 768 |
| 训练硬件 | 8×H100 GPU |
一个关键事实:Avey-B 的训练规模(180B tokens)显著小于 ModernBERT(2T tokens)和 NeoBERT(2.1T tokens),分别只有它们的 9% 和 8.6%。这意味着 Avey-B 的性能还有很大的提升空间——如果用同等规模的数据训练,结果会更值得期待。
4.2 与基线模型的对比
| 模型 | 参数量 | 最大上下文 | 训练数据 | 架构特点 |
|---|---|---|---|---|
| BERT-base | 110M | 512 | 16GB | 原始 Transformer |
| RoBERTa-base | 125M | 512 | 160GB | 优化预训练策略 |
| ModernBERT-base | 149M | 8192 | 2T tokens | RoPE + GeGLU + Flash Attention |
| NeoBERT | 250M | 4096 | 2.1T tokens | 现代 Transformer + 大数据 |
| Avey-B | 149M | 2048+ | 180B tokens | 无注意力 + Sorter/Ranker |
ModernBERT 是 Answer.AI 和 NVIDIA 于 2024 年联合推出的现代化编码器,引入了旋转位置编码(RoPE)、GeGLU 激活函数和 Flash Attention 等现代技术,将上下文窗口扩展到 8192 tokens,在 2T tokens 上训练。NeoBERT 则是 Mila 和蒙特利尔理工学院的作品,拥有 250M 参数,在 2.1T tokens 上训练,一度在 MTEB 排行榜上登顶。
五、实验结果:四大战场的全面对决
5.1 序列分类(Sequence Classification)
| 模型 | MNLI (m/mm) | QQP (Acc/F1) | SST-2 |
|---|---|---|---|
| BERT-base | 84.5/84.6 | 91.3/88.2 | 92.7 |
| RoBERTa-base | 87.6/87.3 | 91.9/89.2 | 94.8 |
| ModernBERT-base | 89.5/89.6 | 92.3/89.9 | 95.3 |
| NeoBERT | 89.8/89.9 | 92.3/90.2 | 96.0 |
| Avey-B | 89.7/89.8 | 91.4/88.5 | 95.8 |
分析:Avey-B 在 MNLI 和 SST-2 上与 ModernBERT/NeoBERT 基本持平,仅在 QQP 上略有差距。考虑到 Avey-B 的训练数据只有对手的不到 10%,这个成绩令人印象深刻。
5.2 Token 分类(Token Classification)
| 模型 | CoNLL-2003 | OntoNotes 5.0 | UNER |
|---|---|---|---|
| BERT-base | 91.2 | 89.4 | 86.5 |
| RoBERTa-base | 92.3 | 90.0 | 87.8 |
| ModernBERT-base | 93.4 | 91.1 | 89.3 |
| NeoBERT | 93.7 | 90.9 | 89.5 |
| Avey-B | 93.2 | 90.7 | 89.2 |
分析:Token 分类任务需要精细的位置感知能力,Avey-B 在没有显式位置编码(如 RoPE)的情况下,仅通过静态层学到的位置模式就达到了接近 SOTA 的水平。
5.3 问答(Question Answering)
| 模型 | ReCoRD (F1/EM) | SQuAD (F1/EM) | SQuAD-v2 (F1/EM) |
|---|---|---|---|
| BERT-base | 71.2/70.4 | 88.5/81.2 | 76.3/73.4 |
| RoBERTa-base | 89.0/88.1 | 91.5/84.6 | 83.6/80.5 |
| ModernBERT-base | 91.0/90.2 | 92.4/85.5 | 87.4/84.2 |
| NeoBERT | 90.2/89.6 | 92.6/86.2 | 86.8/83.9 |
| Avey-B | 90.8/89.9 | 92.1/85.1 | 86.5/83.1 |
分析:问答任务是对模型上下文理解能力的综合考验。Avey-B 在 ReCoRD 上紧追 ModernBERT,在 SQuAD 系列上与两大基线模型差距在 1% 以内。
5.4 信息检索(Information Retrieval)
| 模型 | MLDR (nDCG@10) | MS MARCO (MRR@10) | NQ (nDCG@10) |
|---|---|---|---|
| BERT-base | 32.1 | 33.5 | 44.2 |
| RoBERTa-base | 35.4 | 34.8 | 47.1 |
| ModernBERT-base | 44.2 | 39.4 | 55.6 |
| NeoBERT | 43.5 | 38.2 | 54.8 |
| Avey-B | 43.8 | 38.9 | 55.1 |
分析:信息检索要求模型能生成高质量的文本表示,Avey-B 在三个检索基准上均达到了与 ModernBERT 相当的水平。
5.5 总体评价
综合四大任务的 12 个基准,Avey-B 的平均表现与 ModernBERT-base 基本持平,略低于 NeoBERT(后者参数量多出 68%,训练数据多出 11.7 倍)。用不到 10% 的训练数据和完全不同的架构,达到了与精心优化的 Transformer 模型相当的效果——这本身就是对"注意力是否不可替代"这一问题的有力回答。
六、效率分析:速度才是硬道理
6.1 吞吐量对比

图:三个模型在不同序列长度下的吞吐量(tokens/sec)对比。(a) 系统优化设置,(b) 非系统优化设置。蓝色为 Avey-B,黄色为 ModernBERT,红色为 NeoBERT。Avey-B 在所有序列长度下均保持最高吞吐量,且随序列长度增加,优势越发显著。
几个关键数字:
| 序列长度 | Avey-B | ModernBERT | NeoBERT | Avey-B vs ModernBERT | Avey-B vs NeoBERT |
|---|---|---|---|---|---|
| 2K | ~1,600K tok/s | ~1,200K tok/s | ~500K tok/s | 1.33x | 3.20x |
| 8K | ~1,400K tok/s | ~800K tok/s | ~200K tok/s | 1.75x | 7.00x |
| 96K | ~600K tok/s | ~180K tok/s | ~52K tok/s | 3.38x | 11.63x |
6.2 吞吐量衰减分析
作者引入了一个有趣的衰减指数 \(\alpha\) 来量化模型处理长序列时的效率退化程度:
| 模型 | 衰减指数 \(\alpha\) | 含义 |
|---|---|---|
| ModernBERT | 0.77 | 序列长度翻倍,吞吐量下降约 41% |
| NeoBERT | 0.81 | 序列长度翻倍,吞吐量下降约 43% |
| Avey-B | 0.44 | 序列长度翻倍,吞吐量仅下降约 26% |
Avey-B 的衰减指数几乎只有 Transformer 模型的一半,这直接体现了 \(O(N)\) 线性复杂度的实际优势。
6.3 延迟对比
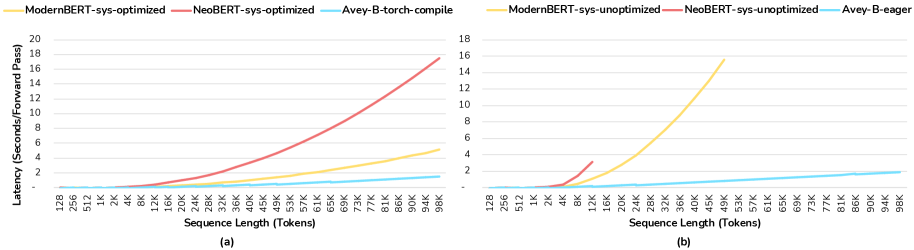
图:三个模型在不同序列长度下的延迟(秒)对比。NeoBERT 在 96K tokens 时延迟飙升至约 18 秒,ModernBERT 约 5 秒,而 Avey-B 仅约 1 秒。
在 96K tokens 的长文本场景下,Avey-B 的延迟优势极为显著——只有 NeoBERT 的约 1/18,ModernBERT 的约 1/5。对于需要实时处理长文档的应用场景(如在线检索、长文本摘要),这个差距具有实际的工程意义。
6.4 长上下文泛化:Needle-in-a-Haystack
一个令人惊喜的发现:Avey-B 仅在 2048 tokens 的序列上训练,却能成功泛化到 96K tokens 的长上下文。在 Needle-in-a-Haystack 测试中(在超长文本中找到插入的特定句子),Avey-B 在 96K tokens 下仍能保持稳定的检索性能。
这得益于两个设计: 1. Sorter/Ranker 的分片机制:不管全局序列多长,每个片段的大小始终是固定的 \(S = 256\),模型只需处理固定大小的局部上下文 2. 余弦相似度的泛化性:与学习到的位置编码不同,余弦相似度不依赖于绝对位置,天然具备长度泛化能力
这就像一个快递分拣员——不管仓库里堆了 1000 个还是 10 万个包裹,他每次只需要处理手边的一小批,效率几乎不受总量影响。
七、消融实验:每个设计都有道理
7.1 解耦 vs 耦合参数化
| 方案 | MNLI | SQuAD | 训练稳定性 |
|---|---|---|---|
| 耦合(Avey 原始) | 87.9 | 89.3 | 中等 |
| 解耦(Avey-B) | 89.7 | 92.1 | 高 |
解耦参数化在所有任务上都带来了显著提升,同时训练过程更加稳定。
7.2 归一化方法对比
如前文所述,行归一化(Row Norm)全面优于 Softmax,而 RMS 归一化直接导致训练发散。
作者分析原因:RMS 归一化不保证输出的总和有界,当余弦相似度分布不均匀时,RMS 归一化后的值可能出现极端情况,导致梯度爆炸。Softmax 虽然保证了非负性和归一化,但强制将负相似度映射为正值,丢失了"语义相反"的信息。行归一化在保持数值稳定的同时,保留了完整的相似度符号信息。
7.3 Top-k 选择的影响
| Top-k | 内存占用 | MNLI | SQuAD | 吞吐量 |
|---|---|---|---|---|
| k=1 | 低 | 88.5 | 90.2 | 最高 |
| k=2 | 中 | 89.2 | 91.5 | 高 |
| k=3 | 中高 | 89.7 | 92.1 | 中 |
| k=5 | 高 | 89.8 | 92.2 | 低 |
k=3 是一个很好的平衡点:从 k=1 到 k=3,性能提升显著;但从 k=3 到 k=5,提升微乎其微,而内存和计算开销增长明显。
7.4 Neural Compression 的必要性
| 设置 | 吞吐量 (tok/s) | 提升倍数 |
|---|---|---|
| 无压缩 | ~32,000 | 1x |
| 有压缩 | ~140,000 | 4.37x |
Neural Compression 带来了 4.37 倍的吞吐量提升,且几乎不损失精度。这是因为压缩操作是一个简单的线性投影加残差连接,参数量和计算量都很小,但它将 Contextualizer 的输入长度从 \((k+1)S\) 减少到了 \(S\),大幅减少了后续所有层的计算量。
八、个人评价与思考
8.1 这篇论文做对了什么?
第一,敢于挑战基础架构。 在 Transformer 已经统治 NLP 近十年的今天,大多数工作都在注意力机制内部做优化——稀疏化、线性化、分组、缓存……Avey-B 直接说"我不用注意力",这种从根本上重新思考问题的勇气值得赞赏。
第二,理论与工程的结合很扎实。 解耦参数化不是拍脑袋想出来的——作者通过"相关性单调性"这个清晰的理论框架解释了为什么耦合方案有问题,为什么解耦方案更好。这种"先找到问题的本质,再设计解决方案"的研究路径,比纯粹靠实验试错要可靠得多。
第三,效率的提升是实打实的。 不是理论上的 \(O(N)\) vs \(O(N^2)\) 的渐进分析,而是在实际硬件上跑出了 3.38 倍到 11.63 倍的加速。吞吐量衰减指数 \(\alpha = 0.44\) vs \(0.77/0.81\) 这个数字极具说服力。
8.2 局限性与未来方向
训练规模的差距是最大的变量。 Avey-B 用 180B tokens 训练,而 ModernBERT 用了 2T,NeoBERT 用了 2.1T。在训练数据差 10 倍以上的情况下,Avey-B 与它们打成平手,这到底意味着"Avey-B 架构本身更好"还是"还没训够所以平手"?需要同等数据量下的公平对比才能下结论。
MaxSim 的片段间比较仍有 \(O(N^2/S^2)\) 的隐含成本。 当序列长度进一步增加到百万级别时,即使 \(S = 256\),片段数也会达到数千,片段间的两两比较可能成为新的瓶颈。未来可能需要引入层次化的分拣策略来解决这个问题。
缺乏生成能力的评估。 作为双向编码器,Avey-B 目前只能用于 NLU 任务。但 Avey 系列的核心思想——排序-处理流水线——理论上也可以适配到因果语言模型(decoder)中。如果能在生成任务上也展示竞争力,影响力会更大。
位置信息的隐式编码值得深入研究。 Avey-B 没有显式的位置编码(如 RoPE 或 ALiBi),而是通过静态层隐式学习位置模式。从可视化中可以看到静态层确实学到了对角线结构(局部位置关系),但这种隐式编码的容量和泛化能力是否足够,还需要更多分析。
8.3 对工程实践的启示
长文档处理场景值得立刻尝试。 对于检索增强生成(RAG)中的文档编码、法律合同分析、论文全文理解等需要处理长文本的场景,Avey-B 的线性复杂度和长上下文泛化能力是实际可用的。一个处理 96K tokens 的编码器只需 1 秒而非 18 秒,这在工程上可以将批处理任务从"小时级"压缩到"分钟级"。
分拣-处理的流水线思想可以迁移。 即使不直接使用 Avey-B,其"先粗筛再精处理"的设计思想可以应用到很多系统中。例如在推荐系统中,先用轻量的 MaxSim 召回相关候选,再用重量级模型做精排——这与 Avey-B 的 Sorter/Ranker + Neural Processor 是同一套哲学。
模型压缩的新思路。 传统的模型压缩(蒸馏、量化、剪枝)都是在 Transformer 架构内部做减法。Avey-B 提供了另一条路:换一个计算复杂度更低的架构,然后用同等参数量获得更快的推理速度。149M 参数的 Avey-B 在效率上远超 250M 参数的 NeoBERT,这说明"换架构"可能比"压缩模型"更有效。
九、总结
Avey-B 向我们展示了一种令人耳目一新的 NLU 架构设计思路:不需要自注意力,也能做好双向语言理解。通过精心设计的排序器-处理器流水线、解耦参数化策略和行归一化技术,Avey-B 在保持与 SOTA Transformer 模型相当性能的同时,实现了真正的线性复杂度和数倍的效率提升。
尽管 Avey-B 还面临训练规模不对等、超长序列瓶颈等挑战,但它清晰地传达了一个信号:自注意力并非 NLU 的唯一出路,甚至可能不是最优出路。随着训练规模的扩大和架构的持续优化,"无注意力编码器"有潜力成为下一代 NLU 模型的重要范式。
在 Transformer 统治 NLP 近十年后,Avey-B 可能是第一个真正有说服力的挑战者——不是通过修改注意力来与 Transformer 竞争,而是通过彻底抛弃注意力来开辟新路。正如论文标题所言:Don't Pay Attention(别再用注意力了)。
声明:本文基于论文原文内容进行解读和分析,实验数据均来自论文原文。个人评价部分仅代表作者观点。